【基于IDEA + Spark 3.4.1 + sbt 1.9.3 + Spark MLlib 构建逻辑回归鸢尾花分类预测模型】
逻辑回归进行鸢尾花分类的案例
背景说明:
基于IDEA + Spark 3.4.1 + sbt 1.9.3 + Spark MLlib 构建逻辑回归鸢尾花分类预测模型,这是一个分类模型案例,通过该案例,可以快速了解Spark MLlib分类预测模型的使用方法。
依赖
ThisBuild / version := "0.1.0-SNAPSHOT" ThisBuild / scalaVersion := "2.13.11" lazy val root = (project in file(".")) .settings( name := "SparkLearning", idePackagePrefix := Some("cn.lh.spark"), libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.4.1", libraryDependencies += "org.apache.spark" %% "spark-core" % "3.4.1", libraryDependencies += "org.apache.hadoop" % "hadoop-auth" % "3.3.6", libraryDependencies += "org.apache.spark" %% "spark-streaming" % "3.4.1", libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka-0-10" % "3.4.1", libraryDependencies += "org.apache.spark" %% "spark-mllib" % "3.4.1", libraryDependencies += "mysql" % "mysql-connector-java" % "8.0.30"
)
代码如下:
package cn.lh.spark import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.{LogisticRegression, LogisticRegressionModel}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, StringIndexerModel, VectorIndexer, VectorIndexerModel}
import org.apache.spark.ml.linalg.{Vectors,Vector}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession} case class Iris(features: org.apache.spark.ml.linalg.Vector, label: String) /** * 二项逻辑斯蒂回归来解决二分类问题 */
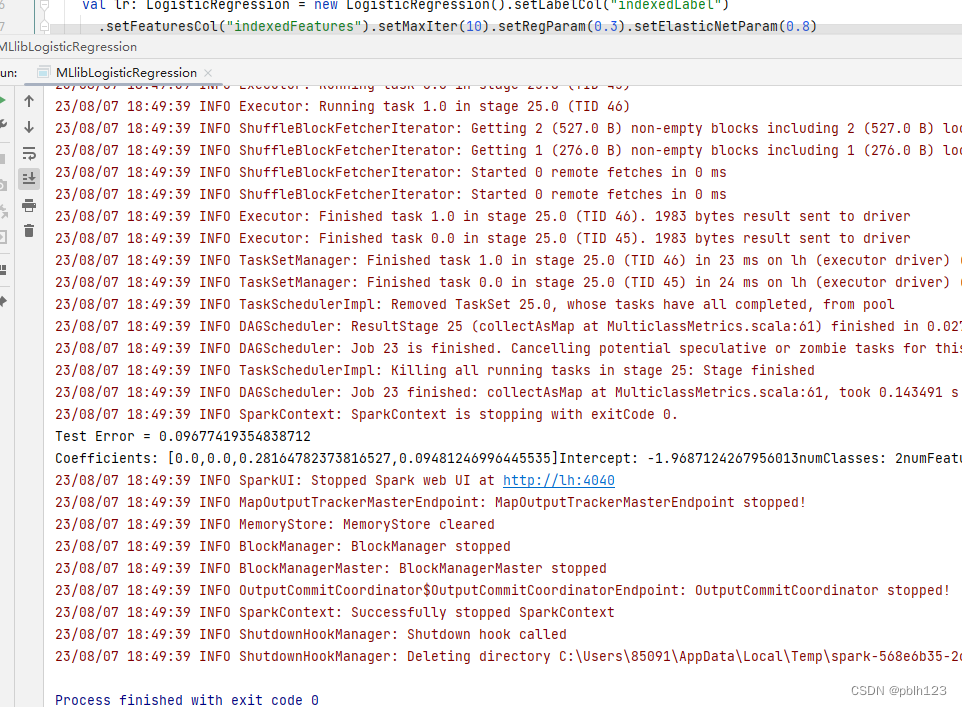
object MLlibLogisticRegression { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder().master("local[2]") .appName("Spark MLlib Demo List").getOrCreate() val irisRDD: RDD[Iris] = spark.sparkContext.textFile("F:\\niit\\2023\\2023_2\\Spark\\codes\\data\\iris.txt") .map(_.split(",")).map(p => Iris(Vectors.dense(p(0).toDouble, p(1).toDouble, p(2).toDouble, p(3).toDouble), p(4).toString())) import spark.implicits._ val data: DataFrame = irisRDD.toDF() data.show() data.createOrReplaceTempView("iris") val df: DataFrame = spark.sql("select * from iris where label != 'Iris-setosa'") df.map(t => t(1)+":"+t(0)).collect().foreach(println) // 构建ML的pipeline val labelIndex: StringIndexerModel = new StringIndexer().setInputCol("label") .setOutputCol("indexedLabel").fit(df) val featureIndexer: VectorIndexerModel = new VectorIndexer().setInputCol("features") .setOutputCol("indexedFeatures").fit(df) // 划分数据集 val Array(trainingData, testData) = df.randomSplit(Array(0.7, 0.3)) // 设置逻辑回归模型参数 val lr: LogisticRegression = new LogisticRegression().setLabelCol("indexedLabel") .setFeaturesCol("indexedFeatures").setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8) // 设置一个labelConverter,目的是把预测的类别重新转化成字符型的 val labelConverter: IndexToString = new IndexToString().setInputCol("prediction") .setOutputCol("predictedLabel").setLabels(labelIndex.labels) // 构建pipeline,设置stage,然后调用fit()来训练模型 val lrPipeline: Pipeline = new Pipeline().setStages(Array(labelIndex, featureIndexer, lr, labelConverter)) val lrmodle: PipelineModel = lrPipeline.fit(trainingData) val lrPredictions: DataFrame = lrmodle.transform(testData) lrPredictions.select("predictedLabel", "label", "features", "probability") .collect().foreach { case Row(predictedLabel: String, label: String, features: Vector, prob: Vector) => println(s"($label, $features) --> prob=$prob, predicted Label=$predictedLabel")} // 模型评估 val evaluator: MulticlassClassificationEvaluator = new MulticlassClassificationEvaluator() .setLabelCol("indexedLabel").setPredictionCol("prediction") val lrAccuracy: Double = evaluator.evaluate(lrPredictions) println("Test Error = " + (1.0 - lrAccuracy)) val lrmodel2: LogisticRegressionModel = lrmodle.stages(2).asInstanceOf[LogisticRegressionModel] println("Coefficients: " + lrmodel2.coefficients+"Intercept: " + lrmodel2.intercept+"numClasses: "+lrmodel2.numClasses+"numFeatures: "+lrmodel2.numFeatures) spark.stop() } }
运行结果如下:
相关文章:
【基于IDEA + Spark 3.4.1 + sbt 1.9.3 + Spark MLlib 构建逻辑回归鸢尾花分类预测模型】
逻辑回归进行鸢尾花分类的案例 背景说明: 基于IDEA Spark 3.4.1 sbt 1.9.3 Spark MLlib 构建逻辑回归鸢尾花分类预测模型,这是一个分类模型案例,通过该案例,可以快速了解Spark MLlib分类预测模型的使用方法。 依赖 ThisBui…...
资深测试老鸟整理,性能测试-常见调优详细,卷起来...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 常见的一些性能缺…...
【第五章 flutter学习之flutter进阶组件-上篇】
文章目录 一、列表组件1.常规列表2.动态列表 二、FridView组件三、Stack层叠组件四、AspectRatio Card CircleAvatar组件五、按钮组件六、Stack组件七、Wrap组件八、StatefulWidget有状态组件总结 一、列表组件 1.常规列表 children: const <Widget>[ListTile(leading: …...

鸿蒙边缘计算网关正式开售
IDO-IPC3528鸿蒙边缘计算网关基于RK3568研发设计,采用22nm先进工艺制程,四核A55 CPU,主频高达2.0GHz,支持高达8GB高速LPDDR4,1T算力NPU,4K H.265/H264硬解码;视频输出接口HDMI2.0,双…...

Bytebase 2.5.0 - VCS 集成支持 Azure DevOps,支持达梦数据库
🚀 新功能 VCS 集成支持 Azure DevOps。研发版本支持达梦数据库。允许用户设置需要重新登录的频率。支持选择并导出数据库变更历史。新增 MySQL Schema 设计器。支持字段模板库。 🎄 改进 在 SQL 编辑器中,优化 MongoDB 的查询结果。优化 …...

tomcat通过systemctl启动时报错Cannot find /usr/local/tomcat/bin/setclasspath.sh
解决方法,检查自己的CATALINA_HOME和TOMCAT_HOME配置情况 我的配置在/etc/profile下的如下 使其立即生效 后将/usr/lib/systemd/system/tomcat.service中的CATALINA_HOME和TOMCAT_HOME和/etc/profile改一致 重新加载再重启解决 解决方法,检查自己的C…...
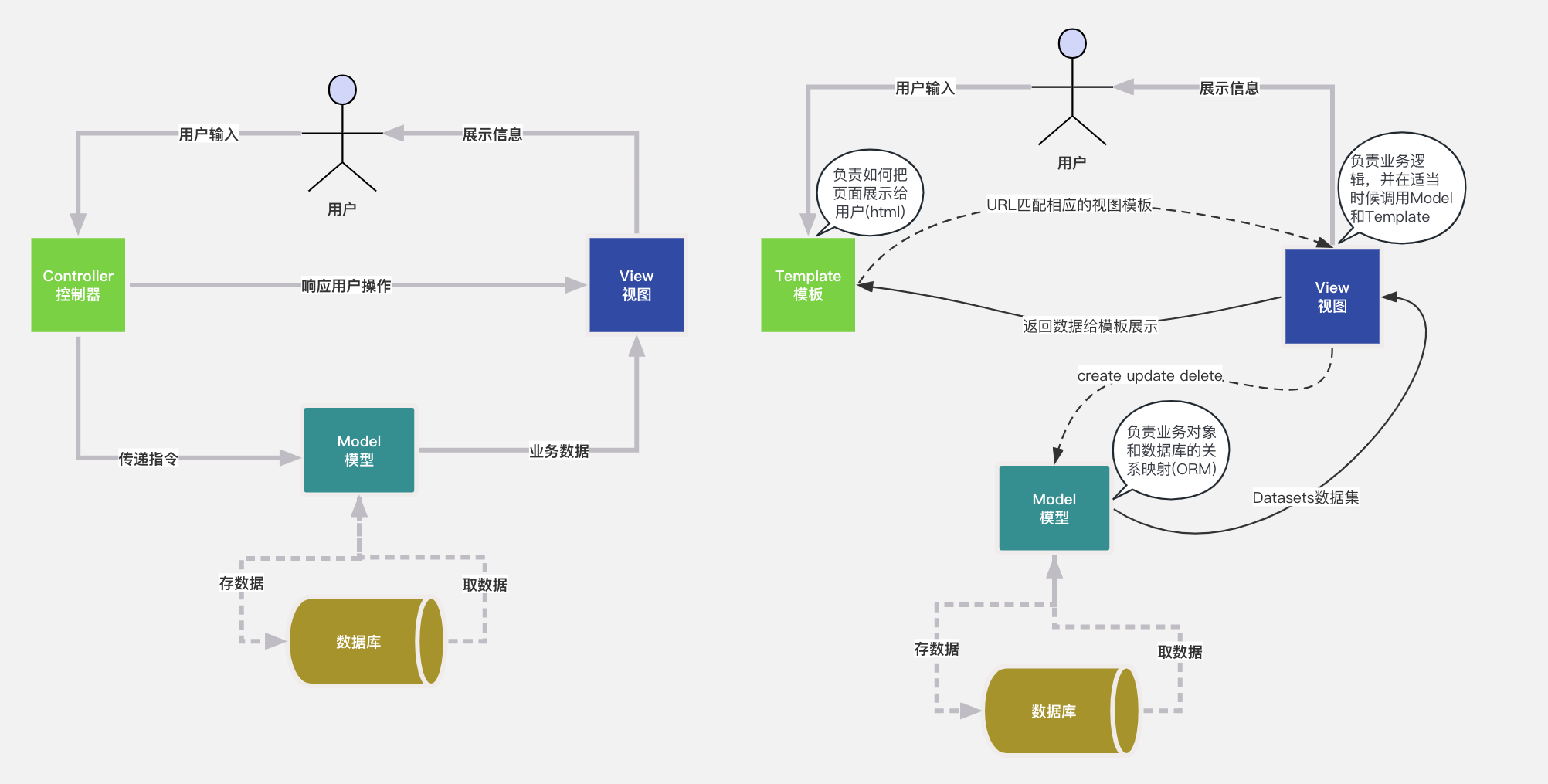
Django架构图
1. Django 简介 基本介绍 Django 是一个由 Python 编写的一个开放源代码的 Web 应用框架 使用 Django,只要很少的代码,Python 的程序开发人员就可以轻松地完成一个正式网站所需要的大部分内容,并进一步开发出全功能的 Web 服务 Django 本身…...
vue- 创建wms-web项目
vue 发展历程 安装vite 第一步 创建wms-web项目 第二步 打开文件夹并安装所有开发环境的依赖 都可以放静态资源 public>vite.svg 不会重新编译成其他名字 assets>vue.svg 会重新编译成一个随机的名称 重新编译 启动 第三步 spa 单页渲染 第四步 安装路由 第五步 …...
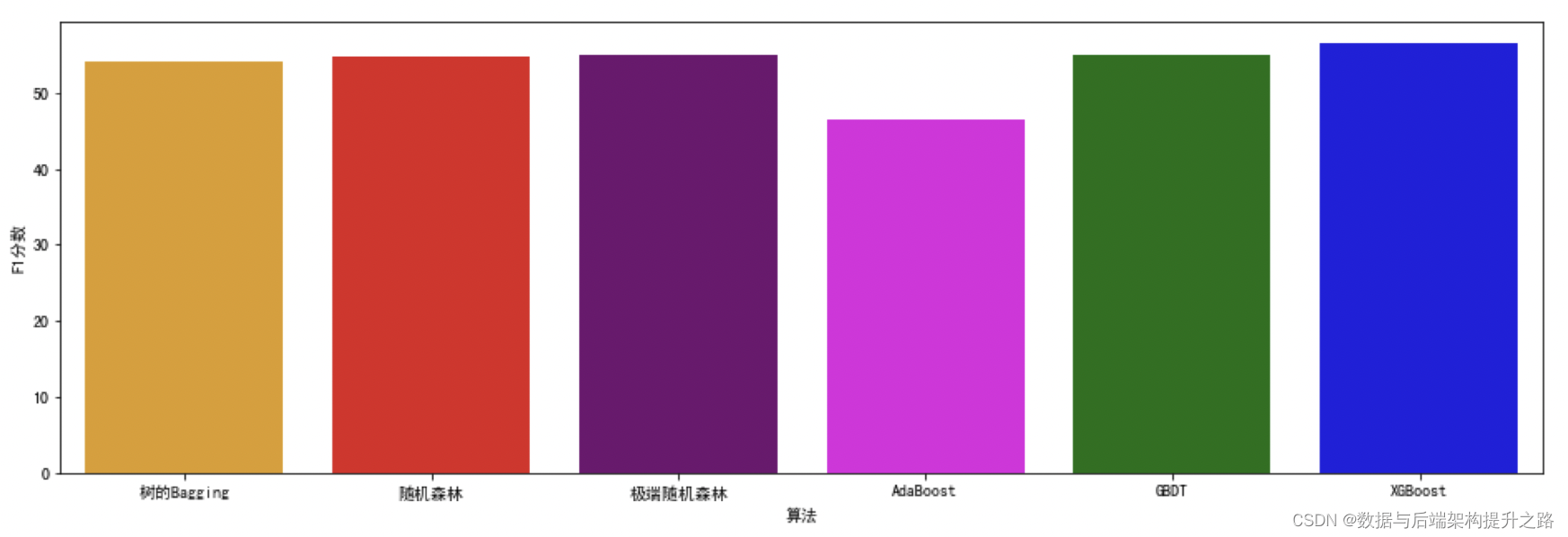
集成学习:机器学习模型如何“博采众长”
前置概念 偏差 指模型的预测值与真实值之间的差异,它反映了模型的拟合能力。 方差 指模型在不同的训练集上产生的预测结果的差异,它反映了模型的稳定性。 方差和偏差对预测结果所造成的影响 在机器学习中,我们通常希望模型的偏差和方差都…...
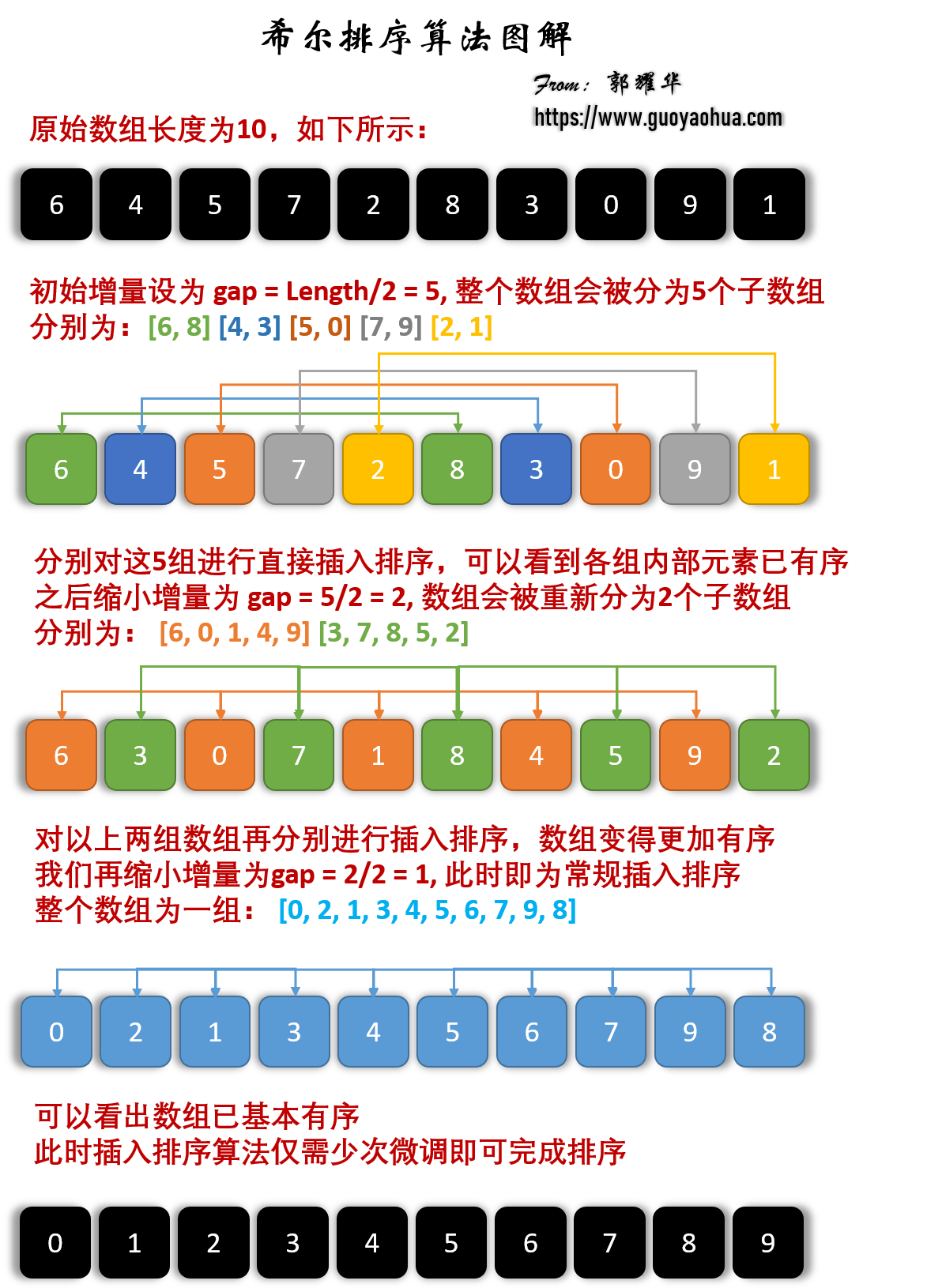
排序算法(二)
1.希尔排序-Shell Sort 1.算法原理 将未排序序列按照增量gap的不同分割为若干个子序列,然后分别进行插入排序,得到若干组排好序的序列; 缩小增量gap,并对分割为的子序列进行插入排序;最后一次的gap1,即整个…...
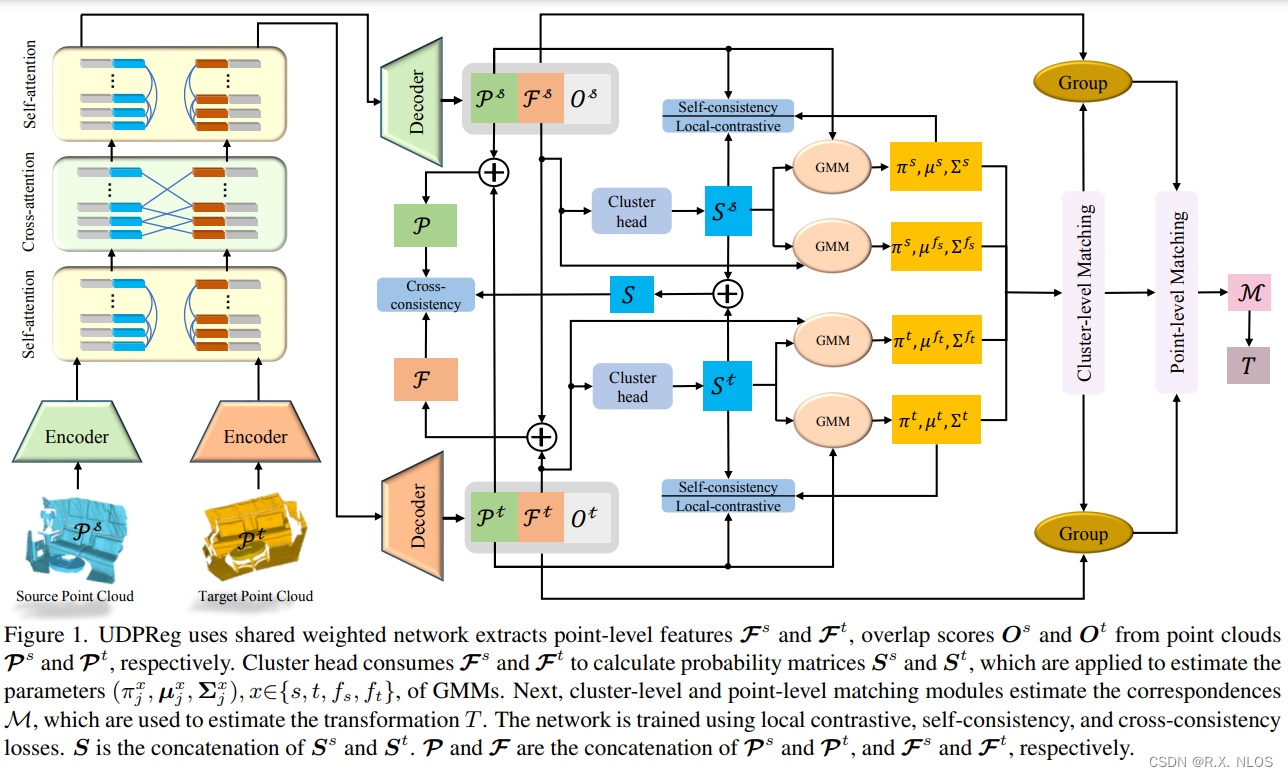
CVPR 2023 | 无监督深度概率方法在部分点云配准中的应用
注1:本文系“计算机视觉/三维重建论文速递”系列之一,致力于简洁清晰完整地介绍、解读计算机视觉,特别是三维重建领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, TPAMI, IJCV 等)。本次介绍的论文是:2023年,CVPR,…...
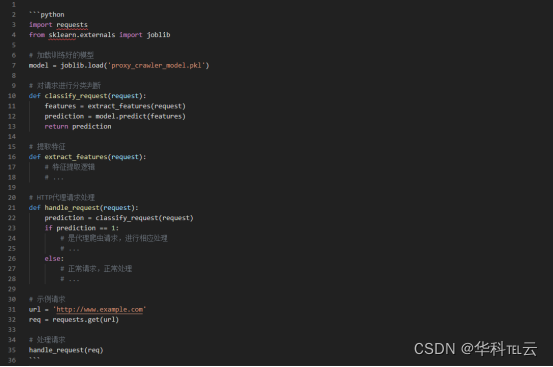
HTTP隧道识别与防御:机器学习的解决方案
随着互联网的快速发展,HTTP代理爬虫已成为数据采集的重要工具。然而,随之而来的是恶意爬虫对网络安全和数据隐私的威胁。为了更好地保护网络环境和用户数据,我们进行了基于机器学习的HTTP代理爬虫识别与防御的研究。以增强对HTTP代理爬虫的识…...
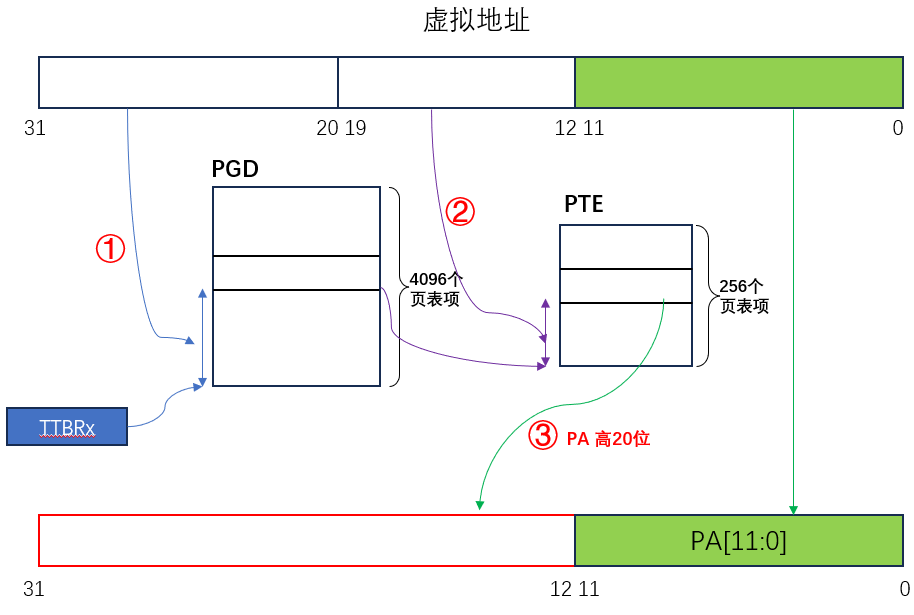
【MMU】认识 MMU 及内存映射的流程
MMU(Memory Manager Unit),是内存管理单元,负责将虚拟地址转换成物理地址。除此之外,MMU 实现了内存保护,进程无法直接访问物理内存,防止内存数据被随意篡改。 目录 一、内存管理体系结构 1、…...
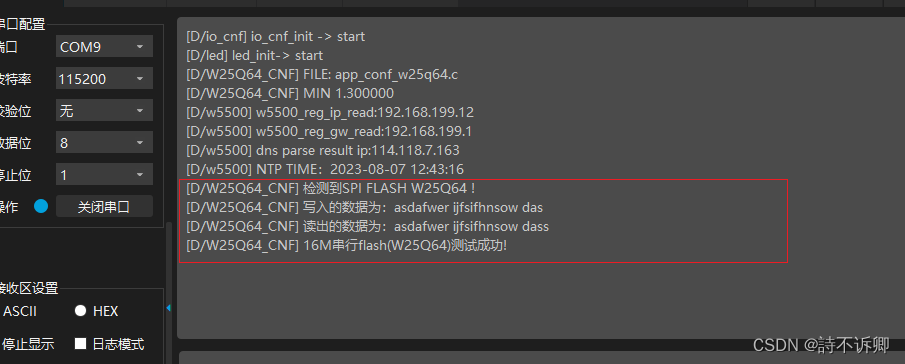
Clion开发Stm32之存储模块(W25Q64)驱动编写
前言 涵盖之前文章: Clion开发STM32之HAL库SPI封装(基础库) W25Q64驱动 头文件 #ifndef F1XX_TEMPLATE_MODULE_W25Q64_H #define F1XX_TEMPLATE_MODULE_W25Q64_H#include "sys_core.h" /* Private typedef ---------------------------------------------------…...

SpringBoot动态切换数据源
SpringBoot整合多数据源,动态添加新数据源并切换 1.需求2.创建数据源配置类3.切换数据源4.切换数据源管理类5.使用案例5.AOP切面拦截 1.需求 低代码服务需要给多套系统进行功能配置,要求表结构必须生成在对应系统的数据库中,所以表结构的生成…...

[C++项目] Boost文档 站内搜索引擎(4): 搜索的相关接口的实现、线程安全的单例index接口、cppjieba分词库的使用、综合调试...
有关Boost文档搜索引擎的项目的前三篇文章, 已经分别介绍分析了: 项目背景: 🫦[C项目] Boost文档 站内搜索引擎(1): 项目背景介绍、相关技术栈、相关概念介绍…文档解析、处理模块parser的实现: 🫦[C项目] Boost文档 站内搜索引擎(2): 文档文本解析模块…...

SAP ABAP元素域值描述通过函数(DD_DOMVALUE_TEXT_GET)获取
代码如下: PERFORM FRM_GET_DOMVALUE_TEXT USING ZMMD_ZFLZQ <GFS_DATA>-ZFLZQ CHANGING <GFS_DATA>-ZZQTEXT .IF <GFS_DATA>-ZXYLX IS NOT INITIAL .PERFORM FRM_GET_DOMVALUE_TEXT USING ZMMD_ZXYLX <GFS_DATA>-ZXYLX CHANGING <GFS_…...

原型模式与享元模式:提升系统性能的利器
原型模式和享元模式,前者是在创建多个实例时,对创建过程的性能进行调优;后者是用减 少创建实例的方式,来调优系统性能。这么看,你会不会觉得两个模式有点相互矛盾呢? 在有些场景下,我们需要重复…...

uniapp封装手写签名
组件代码 cat-signature <template><view v-if"visibleSync" class"cat-signature" :class"{visible:show}" touchmove.stop.prevent"moveHandle"><view class"mask" tap"close" /><view c…...

掌握 JVM 调优命令
常用命令 1、jps查看当前 java 进程2、jinfo实时查看和调整 JVM 配置参数3、jstat查看虚拟机统计信息4、jstack查看线程堆栈信息5、jmap查看堆内存的快照信息 JVM 日常调优总结起来就是:首先通过 jps 命令查看当前进程,然后根据 pid 通过 jinfo 命令查看…...

SLO-Warden:云原生时代SLO自动化管理的工程实践
1. 项目概述:当SLO成为运维的“紧箍咒”在云原生和微服务架构成为主流的今天,服务的稳定性和可靠性不再是锦上添花,而是业务的生命线。对于运维工程师和SRE(站点可靠性工程师)而言,我们每天都在和各种指标、…...

免ROOT实现安卓摄像头HOOK:探索微信QQ等主流App虚拟视频替换方案
1. 免ROOT实现安卓摄像头HOOK的核心原理 安卓系统的摄像头调用流程其实就像是一个快递配送系统。当你在微信里点击视频通话按钮时,应用程序会向系统发出一个"取快递"请求(Camera.open()),系统会分配一个快递员ÿ…...

Rust命令行工具开发实战:从架构设计到工程化发布
1. 项目概述:为什么是Rust,为什么是命令行工具?最近几年,如果你关注过系统编程或者高性能工具领域,Rust这个词出现的频率会越来越高。它不再是一个“未来之星”,而是实实在在地在重塑我们手中的工具链。我自…...

【Java用法】jar包运行后显示 没有主清单属性
jar包运行后显示 没有主清单属性一、问题现象二、问题分析三、解决方案3.1 添加 spring-boot-maven-plugin 插件3.2 修改 spring-boot 父级依赖3.3 配置IDEA开发工具一、问题现象 jar包运行后显示 没有主清单属性!如下图所示: 前些天发现了一个特别好用…...

Visual C++运行库终极指南:如何一键修复所有Windows程序依赖问题
Visual C运行库终极指南:如何一键修复所有Windows程序依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突然弹出&…...

Python实战:从时序数据到ARIMA预测的完整建模指南
1. 时间序列分析与ARIMA模型入门 时间序列分析就像是一位经验丰富的老中医把脉——通过观察数据随时间变化的"脉搏",我们能诊断出背后的规律并预测未来走势。ARIMA模型正是其中最经典的"听诊器"之一,我在处理销售预测、库存管理等项…...

STM32F407霸天虎实战:用硬件I2C点亮OLED,顺便聊聊软件模拟I2C的坑
STM32F407硬件I2C驱动OLED全攻略:从原理到避坑指南 在嵌入式开发中,显示模块的选择往往决定了用户体验的上限。0.96寸OLED凭借其高对比度、低功耗和轻薄特性,成为众多项目的首选。但如何为它选择合适的通信方式?本文将带你深入STM…...

批量转账工具评测:GTokenTool 凭什么成为 Web3 首选?
GTokenTool 是一个支持多链、不涉及代码操作的综合性 Web3 工具箱。它的批量转账功能支持一键分发 ERC-20 和 NFT 代币,特别适合用来高效完成各类代币分发任务,最高能节省 90% 的 Gas 费,且其合约模板已通过多重安全审计。 下面我按照新手最关…...

Latest-adb-fastboot-installer-for-windows:基于自动化驱动管理架构的Android开发环境配置工具深度解析
Latest-adb-fastboot-installer-for-windows:基于自动化驱动管理架构的Android开发环境配置工具深度解析 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) …...

从零构建智能体工作流引擎:核心架构、实现与生产级实践
1. 项目概述:从零构建一个智能体工作流引擎最近在GitHub上看到一个名为agentkit的项目,来自BCG X的官方仓库。这个标题立刻引起了我的兴趣,因为它直指当前AI应用开发中的一个核心痛点:如何高效、可靠地编排和管理多个AI智能体&…...