【MySQL进阶-08】深入理解innodb存储格式,双写机制,buffer pool底层结构和淘汰策略
MySql系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解mysql索引本质 | https://blog.csdn.net/zhenghuishengq/article/details/121027025 |
| 【二】深入理解mysql索引优化以及explain关键字 | https://blog.csdn.net/zhenghuishengq/article/details/124552080 |
| 【三】深入理解mysql的索引分类,覆盖索引(失效),回表,MRR | https://blog.csdn.net/zhenghuishengq/article/details/128273593 |
| 【四】深入理解mysql事务本质 | https://blog.csdn.net/zhenghuishengq/article/details/127753772 |
| 【五】深入理解mvcc机制 | https://blog.csdn.net/zhenghuishengq/article/details/127889365 |
| 【六】深入理解mysql的内核查询成本计算 | https://blog.csdn.net/zhenghuishengq/article/details/128820477 |
| 【七】深入理解mysql性能优化以及解决慢查询问题 | https://blog.csdn.net/zhenghuishengq/article/details/128854433 |
| 【八】深入理解innodb和buffer pool底层结构和原理 | https://blog.csdn.net/zhenghuishengq/article/details/128993871 |
| 【九】深入理解mysql执行的底层机制 | https://blog.csdn.net/zhenghuishengq/article/details/128100377 |
| 【十】深入理解mysql集群的高可用机制 | https://blog.csdn.net/zhenghuishengq/article/details/126239652 |
| 【彩蛋篇】深入理解顺序io和随机io | https://blog.csdn.net/zhenghuishengq/article/details/129080088 |
深入理解innodb的底层原理
- 一,innodb数据存储结构
- 1,innodb磁盘页存储数据方式
- 1.1,行格式
- 1.2,索引页格式
- 2,innodb的磁盘组成部分
- 2.1,System Tablespace(系统表空间)
- 2.2,File-Per-Table Tablespaces(独立表空间)
- 2.3,Doublewrite Buffer(双写缓冲区)(重点)
- 2.3.1,数据恢复问题
- 2.4,Innodb Data Dictionary(数据字典)
- 3,innodb内存组成部分
- 3.1,buffer pool的基本信息
- 3.2,buffer pool的底层结构
- 3.3,buffer pool的存储方式
- 3.3.1,free链表
- 3.3.2,flush链表
- 3.4,buffer pool的淘汰策略
- 3.4.1,划分区域的LRU链表
- 3.5,多个buffer pool实例
一,innodb数据存储结构
innoDB 是一个将表中的数据存储到磁盘上的存储引擎,在真正处理数据的时候,是在内存中处理的,因此需要将数据从磁盘读取到内存中,在处理写入或者修改操作之后,也需要进行一个刷盘的操作,将数据从内存刷新到磁盘上。因此在磁盘上的数据,也是其对应的存储结构的,并且其innodb是以页单位存储数据的,一页数据为16kb。
1,innodb磁盘页存储数据方式
1.1,行格式
在innodb中,主要通过行格式这种方式来存储数据,并且该殷勤设计了四种不同类型的行格式,分别是Compact,Redundant(废弃),Dynamic和Compress。这四种在本质上,没有太大的差别,因此以下主要是讲解这个Compact这种类型
在mysql中,有很多类型的字段,如char,int,bigint等。但是如果是varchar,text,blob这些变长字段,那么就不能像其他的固定长度字段一样那么好的去存储,因此mysql在保存这些记录的时候,通过以下的规则进行保存

1,记录的真实数据
如上图中,右边就是记录真实的数据,在数据库中我们是肉眼可看的,如列一的值为id,列2的值为name等,每一列都需要一个单独的空间存。如果列一是用雪花算法生成的id,其是一个bigint数据类型的固定大小的数据,那么列一就可以在磁盘中从某个字节开始,固定的读取多少个字节数,获取到的磁盘中的数据就是id;但是第二列这个name是一个varchar字段的类型数据,其数据本身就是一个不固定长度的,因此不能想列一一样,直接固定的读取多少个字节数,而是需要计算每条数据该值对应的长度,然后再通过长度去读取对应的字节数获取磁盘中的数据。
2,记录的额外信息
因此,除了用来记录本身的真实数据之外,该存储引擎还有专门用来记录额外信息的记录头。如上图可知,里面有一个字段叫做变长字段的长度列表,该字段除了记录哪一列是变长字段之外,还记录了该字段的值对应的长度,即对应的offset偏移量。
除了记录这个变长字段的长度列表之外,该记录头中还存储了NULL值列表,用0和1来表示;那些可以允许为空的字段和不允许为空的字段,该列表都会记录。
除了上面两个重要的记录,还存储了一些记录头信息,主要记录对应表中的整条数据的部分信息,如一些预留位,以及这条数据在删除之后,不会立马物理删除,而是给这个delete mask这个字段打一个删除标志位,后续再进行删除操作,还有后面的一些min rec mask等等。
3,内部的隐藏字段
在上图的中间部分,有几个字段,分别是DB_ROW_ID,DB_TRX_ID,DB_ROLL_PTR这三个字段,这三个字段就是隐藏在mysql的内部字段。
DB_ROW_ID:如上图可以发现,该字段用了一个虚线表示,表示该字段是一个非必须字段。该字段主要就是用来表示表中的聚簇索引,如果表中没有建主键和唯一索引时,那么这个隐藏的字段就作为全局的主键索引。
DB_TRX_ID:这个id表示的是一个事务id,在用了事务时,他就会用来记录对应的数据。
DB_ROLL_PTR:这个表示回滚指针,就是redolog的版本日志链,如果发生数据回滚时,就会用到该回滚指针。详情可以查看这个mvvc篇。
4,数据溢出问题
依旧是上面的四种行格式,这个Redundant格式基本废弃,因此这里不考虑。在Dynamic和Compress这两种类型数据中,Compress就是这个Dynamic的升级版,因此可以认为这二者本质是基本一致的,唯一的不同点就是,前者在记录数据是记录完整的数据,后者记录的是压缩的数据。
因此这里主要分析Compact和这二者的区别。在定义一个varchar字段的时候,varchar可以定义的最大长度为65535,因此可以设置一个20000长度的字段
name varchar(20000) DEFAULT NULL COMMENT '名称',
但是mysql是以页为单位存储数据的,一页的数据为16kb,即 16 x 1024 = 16384个字节,那么就会出现数据溢出的现象,即一页数据不能全部存储完全部数据。那么这几个不同的类型就会有不同的处理方法,Compact会将前768个字节存储在本页内,剩余的存储在其他页面中,然后通过指针找到对应的存储在其他页的数据;而这个Dynamic和Compress两种类型就是直接将全部的数据直接存储在其他的页面上,然后该页面内只存储指向其他页面的指针。
这几种类型除了有点上面的差别之外,其他的数据差别不大。
1.2,索引页格式
上面主要讲述了这个每一行数据是如何存储的,接下来主要是分析这个每一页中的数据是如何存储的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QUEPyty3-1676178216946)(img/1675671452935.png)]](https://img-blog.csdnimg.cn/2456811313284423bad892775d961c45.png)
如上图左半部分,主要由File Header,Page Header,Infimum + Supremum,User Records,Free Space,Page Directory,File Trailer文件尾部等部分组成。
File Header:文件头,主要存储一些页面的通用信息,所有的页都有这个文件头。
Page Header:页面头,主要存储数据页专有的一些信息。
Infimum + Supremum:最小记录和最大记录,由内部所维护的虚拟记录。
User Records:用户记录,实际存储的行记录内容。上面的那些数据就是存在这个位置的
Free Space:空闲空间,页面中还没有使用完的空间
Page Directory:页面目录,某些数据的相对位置的记录
File Trailer:文件尾部
1,User Records
这个部分主要是用来保存上面的行格式的数据,就是每一行的数据主要是存储在这个字段里面。在一开始生成页的时候,这个字段是暂时没有的,直到插入一条数据之后,才会有这个字段,主要是向Free Space的空闲空间中申请一个空间,然后将值存储在申请的空间中,直到该页的剩余空间用完或者不够用时,才回会去申请新的空间。
在整个页数据中,其数据存储空间主要是由 User Records + Free Space两部分组成。
2,Page Directory
在这一页数据中,会有一个Infimum +和Supremum的最大记录和最小记录,分别是对应这所有存在数据的链表头部和链表尾部,然后其他的数据以链表的形式,存储在这两个结点之间,从而将页中的所有数据形成一个单链表。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dn3cCIgn-1676178216948)(img/1675673163970.png)]](https://img-blog.csdnimg.cn/8eee81191f504de489cc24acd546cc4c.png)
因此在删除记录时是非常快的,只需要修改连链表与链表之间的指针指向即可。但是链表也有缺点,就是查询的效率是比较慢的,每次查询都需要从头开始遍历,如果每一行的数据都比较小,那么一页数据存储的值就比较多,那么需要遍历的时间就久。
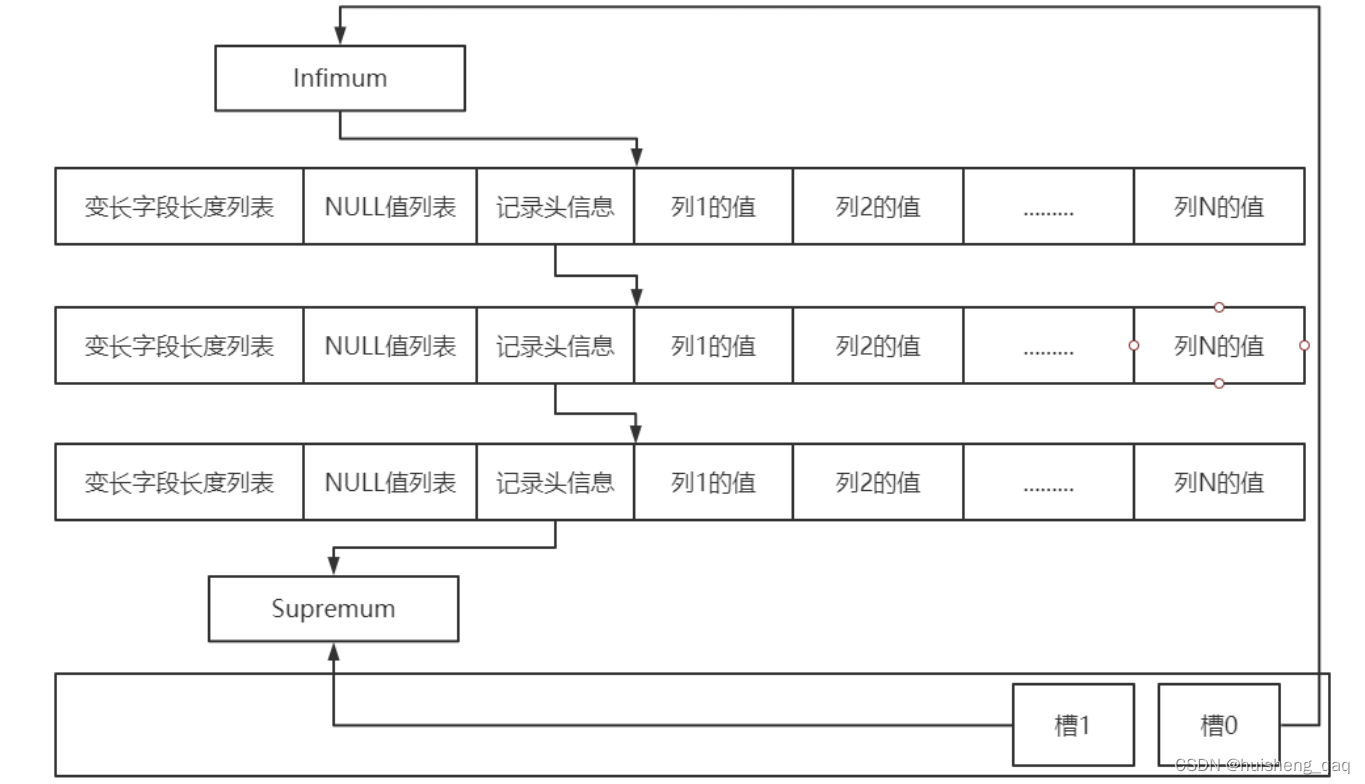
当然mysql的开发和维护人员肯定也是能想到的,因此在内部也做了相应的调整和优化。其优化方式就是在一页数据中,如果数据量很大,那么就会将里面的数据进行一个分组操作,每个组被称为槽,每个组中存放一些数据,每条数据尽量控制在4-8条,然后将每组中的最后一条数据提取出来,存放到这个Page Directory里面,简单来说就是:在每一页的数据中,内部又会增加一个索引,用来解决这个查询效率慢的问题。这个page Directory就是类似于一个页目录,链表中的数据肯定是遵循b+树原则的,因此是排好序的,所以提出每组数据的最后一个值,就类似于b+树中的第二层结点,然后直接通过定位第二层来查找数据,即类似于通过B+树来查找数据。
这样只需两次就可以找到对应的数据,就不存在数据在链表尾部需要查找的时间更久了。
3,Page Header
该字段主要存放上面这个page Directory的一些数据,本页中已经存储了多少条记录,第一条记录所对应的地址是什么,以及页目录中存储了多少个槽等。
4,File Header
所有的页都有该字段,主要存放页面上的通用信息,如一些页的编号,页的类型,上一个页下一个页是谁,页的检验和等等。
2,innodb的磁盘组成部分
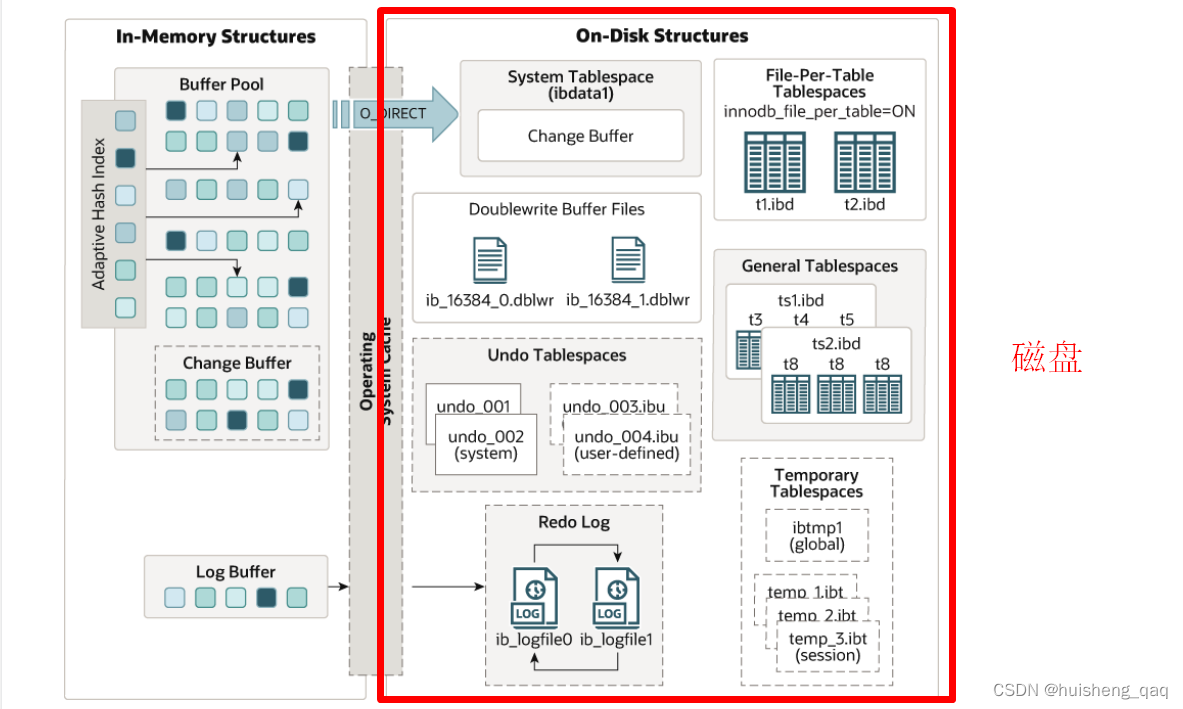
在mysql官网中,也详细的画了这个innodb的体系结构图,这里主要详细描述的是8.0版本,其官网地址如下:https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
并且官网中的图如下所示,innodb体系主要由两部分组成:左半部分是将数据存储在这个内存中,如将磁盘中的数据读取到buffer pool中,以及一些热点数据也存储在这里面;右半部分是将数据存储在这个磁盘中,如一些系统的表空间,redolog日志文件等等。
2.1,System Tablespace(系统表空间)
顾名思义,这个指的是系统的表空间。在innodb中,表空间是一个抽象的概念,即一个表空间就是对应着一个文件,该文件记录在数据库中的data目录下,每一张表都有一个对应的表空间,其名为表名.ibd存储在data目录下。
因此在这个页格式中,每个页都有一个Page Header,用来存储这个页号,这样就可以实现磁盘中的表空间,即使内存地址不连续,也可以通过对应的页号找到对应的页目录,从而实现页与页之间的连接。任何数据类型的页都有对应的表空间,并且每个表空间的每一个页都对应着一个页号,这个页号由4个字节组成,每个字节对应着8个比特位,因此一个表空间最多可以拥有2^32 次方个页,那么一张表可以支持的数据为 2^32 x 16kb ,即为64Tb的数据。
2.2,File-Per-Table Tablespaces(独立表空间)
这个指的是独立表空间。由于一个表中可以有2^32次方个页,因此为了更好的对这些页进行管理,将全部的页进行了拆分,即每64个页划分为一个区,每256个区被划分为一个组。一个区的大小为 64 x 16kb,即1M,一个组的大小为 256 x 1M,即256M。而做这些区、组这种优化的方式,主要是为了将更多的随机IO改成顺序IO。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7TlfxE8E-1676178216954)(img/1675742173286.png)]](https://img-blog.csdnimg.cn/f2d9f230c387467081cca54029777ebc.png)
如上图,除了区和组之外,还有一个段,在所有数据中,叶子结点会在同一个段里面,非叶子结点会在同一个段里面,并且这个段也不是指连续的物理内存,而是对应的连续的逻辑地址。这样在直接使用全表扫描的时候,只需要扫描叶子结点对应的段就可以了。
2.3,Doublewrite Buffer(双写缓冲区)(重点)
双写缓冲区,自适应hash索引和BufferPool一起被称为innodb的三大特性。 在这个磁盘的System Tablespace系统表空间当中,有着这个双写缓冲区,主要是保证写数据的可靠性。除了磁盘中有这个双写缓冲区之外,bufferpool中也有对应的双写缓冲区。
双写缓冲区,顾名思义就是写了两份数据。 在没有这个双写机制之前,那么数据在新增或者更新的时候,就会直接进行一个刷盘操作,这样就会有一个问题,如果在刷盘的过程中发生意外崩溃,如断电或者系统直接崩溃,那么数据就会直接丢失,就会出现部分页写入问题。
为了防止数据出现丢失的问题,innodb的系统表中就增加了这个双写缓冲区,其本质也是一个文件,那么在mysql新增或者更新数据时,先将一份数据先保存在这个Doublewrite Buffer的这个文件中,保存完成之后,再进行一个刷盘的操作,如果期间发生意外崩溃的情况,导致某一页数据直接发生损坏,那么直接通过这个Doublewrite Buffer 中的数据来进行恢复即可,这样就可以解决innodb存储引擎数据丢失的问题。
但是在引入双写机制之后,相比之前只写一次要多一次写 Doublewrite Buffer 的时间,但是由于写入这个双写缓冲区的方式是顺序写入的,因此实际时间只比之前的时间多5%-10%左右,这个具体详细细节可以从官网查看。并且这个双写机制也可以在适当的时机将他关闭调,如在实现主从复制,读写分离的时候,从库只需要进行读取,不需要进行数据的写入,那么就可以将这个双写机制给关掉。
2.3.1,数据恢复问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ISdc9p9I-1676178216957)(img/1675931690240.png)]](https://img-blog.csdnimg.cn/51b35b6239fd46ad9646500e3656d704.png)
写双写缓冲区出现问题
如果出现非常的极端,就是在写Doublewrite Buffer和写磁盘两步都失败的情况下,由于其顺序是先存这个双写缓存中,再存磁盘中,如果再双写阶段就失败了,那么数据也没有存储到这个磁盘中,那么页不会出现数据页的问题,也不会出现脏数据的问题,那么innodb要恢复数据只能通过redolog进行数据的恢复了
写磁盘出现问题
如果是在写这个双写缓冲区没问题,而是在写磁盘阶段就出现问题,这就要引入为什么innodb存储引擎要设计这个Doublewrite Buffer这个双写缓冲区了。
假设没有这个双写缓冲区,就是直接在redolog持久化之后,就将数据刷盘到磁盘,那么在刷盘的阶段,如果出现故障之类的,那么就可能出现页损坏的情况。假设一个磁盘8个扇区,每个扇区存512kb数据,那么每一次刷盘可以存 8 x 512b数据,即4kb数据,一页数据为16kb,需要io四次才能存满。在这四次io期间,如果出现断电,那么这一页还没存满,但是由于操作系统是并没有回滚操作的,那么可能只io了一次,就直接故障了,那么这一页就会直接出现损坏的情况,由于这是系统故障导致mysql给重启了,在重启的时候,mysql内部就会检查,可以发现这一页数据已经损坏了,但是虽然说redolog里面有全部的物理逻辑日志,但是由于数据页已经损坏,redolog也恢复不了,除非手动去恢复,因此也不能指望直接通过redolog自动的去恢复数据了。
那么就引入这个Doublewrite Buffer,双写缓冲区,由于提前在这里面写了一份,并且这页数据中也会记录存储在磁盘中对应页数据的页号以及全部数据,因此即使那一页数据坏了(只要数据不完整就会被认为损坏),那么可以通过存储在这个双写缓冲区的数据,直接覆盖损坏的那一页的数据,并且不需要经过io的替换,只需要通过复制操作即可恢复之前已损坏的数据,这样就大大的降低了数据恢复的时间以及提升了数据的安全性。
在数据库异常关闭的情况下启动时,都会做数据库恢复(redo)操作,恢复的过程中,数据库都会检查页面是不是合法(校验等等),如果发现一个页面校验结果不一致,则此时会用到双写这个功能。
总结来说:提高了安全性,减少了io
2.4,Innodb Data Dictionary(数据字典)
就是innodb的一个数据字典,里面通过键值对的方式存储了很多mysql的相关信息,如一些表信息,列信息,索引信息,外键信息等。除了存放的东西之外,还会存放一个rowid,即隐藏主键。
SYS_TABLES 整个InnoDB存储引擎中所有的表的信息
SYS_COLUMNS 整个InnoDB存储引擎中所有的列的信息
SYS_INDEXES 整个InnoDB存储引擎中所有的索引的信息
SYS_FIELDS 整个InnoDB存储引擎中所有的索引对应的列的信息
SYS_FOREIGN 整个InnoDB存储引擎中所有的外键的信息
SYS_FOREIGN_COLS 整个InnoDB存储引擎中所有的外键对应列的信息
SYS_TABLESPACES 整个InnoDB存储引擎中所有的表空间信息
SYS_DATAFILES 整个InnoDB存储引擎中所有的表空间对应文件系统的文件路径信息
SYS_VIRTUAL 整个InnoDB存储引擎中所有的虚拟生成列的信息
并且系统表空间的数据,不可以修改,这些文件都是一些只读表。并且有些表并不是真正的物理表,而是在mysql启动的时候,通过读取系统的一些内部信息生成的一张表。
3,innodb内存组成部分

根据上面的结构体系图可以发现,内存中主要是由这个buffer pool组成的,接下来就详细的了解一下buffer pool这个缓冲池
3.1,buffer pool的基本信息
该缓存池中主要是存放一些将磁盘加载到内存的数据,并且绝大多数的增删改查都是在这个缓冲区中完成的。可以通过以下命令知道,默认的buffer pool缓冲池的大小为 128M。
show variables like 'innodb_buffer_pool_size'
也可以在启动服务器的时候配置innodb_buffer_pool_size参数的值,如下,将他的大小设置成 256M
innodb_buffer_pool_size = 268435456
在mysql官网中也有提到这个buffer pool大小的设置,其官网认为,给buffer pool设置的机器内存的60%左右。
3.2,buffer pool的底层结构
在buffer pool中,也是将磁盘中加载过来的数据是直接按页存储的,除了存储对应的页数据之外,其内部还分配了一个控制块来存储对应的缓存页的信息,每个控制块都会对应一个缓存页,控制块中会存储一些对应的页号,缓存页对应的地址等等。因此在上面设置buffer pool为256M的大小,然而其实际占用的大小是大于256M的,大5%左右,该大出来的部分主要是存储控制块中的信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mKoqXttq-1676178216959)(img/1676052460873.png)]](https://img-blog.csdnimg.cn/7de951c7705d4415a3a33d56a3b1b444.png)
3.3,buffer pool的存储方式
buffer pool是在mysql启动的时候,向操作系统申请的一块连续的内存空间,在第一次启动的时候,由于数据还没有从磁盘中加载到内存中,此时的数据是空的。当数据加载进来buffer pool的时候,在内部需要对空间进行一个维护,在存储数据时需要判断哪些空间已经被使用,哪些空间可以使用。其维护空间的方式主要有以下几种。
3.3.1,free链表
在innodb内部,使用了一个free的空闲链表来解决空间问题的,并且该链表是一个双向链表,顾名思义,该链表是用来存储空闲的结点的。在buffer pool还未加载数据时,假设128M的buffer pool大小,每一页数据是16kb,其大概就是可以分128 x 64 = 8192 个页面,每个页面都有一个对应的 控制块,那么就会有8192个控制块,然后将这些8192个控制块组成一个双向链表,并且此时链表中的控制块结点都是未使用的。
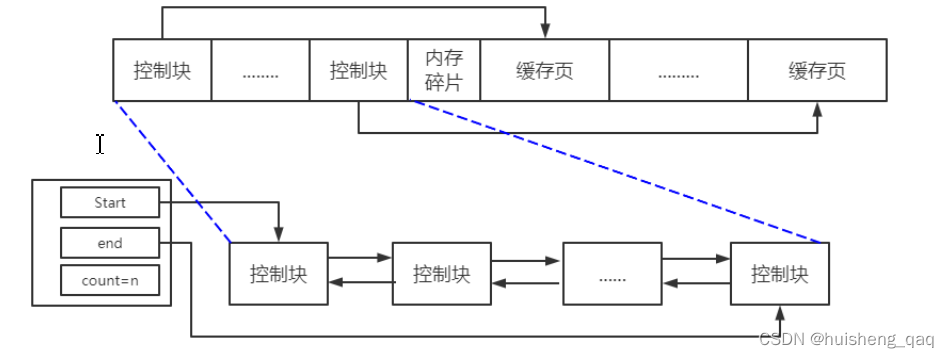
在有数据加载到buffer pool时,加载进来的数据是按页加载进来的,假设加载一页,那么就会使用buffer pool中的一个控制块,控制块中是会记录对应页的数据的,当页数据被使用时,那么指向该页的控制块就会从链表中移除,就是不在链表中的控制块的结点就是已经使用的结点。在这就可以发现这个控制块的作用了。总而言之,就是链表是提前加载的,链表中的结点控制块是和缓存页一一对应的,当缓存页被使用后,那么对应的控制块就会直接从这个双向链表中删除,不在链表中的控制块则代表其对应的缓存页已经被使用了。
3.3.2,flush链表
上面的这个free列表是用来记录哪些空间是被使用,哪些空间是未使用的,在buffer pool内部,还有一个flush的链表,主要是用来记录修改过缓存页中的数据之后,如一条update语句,但是还没有刷盘到内存的这些缓存页。
在innodb内部,为了提升内部的性能,在一条更新语句之后,不会立即的进行一个刷盘操作,而是会将这个被修改过的页,被称为**“脏页”**,其对应的这个控制块加入到一个链表中,这个链表就是flush链表,就是一个待刷盘的链表。然后内部会开启一个定时任务,进行一个刷盘操作。其双向链表的结构和free链表的结构是差不多的,并且存储的内容都是这个控制块。
3.4,buffer pool的淘汰策略
由于是缓存,因此肯定会有一个淘汰策略,来解决空间不足的问题。在innodb中,主要是使用这个LRU算法来实现这个淘汰策略。
LRU算法主要是将最长时间未使用的给删除,如一级缓存LoaclCache,volatile,还有redis中都有使用到该算法。比如说在一个链表中,将最近使用的结点存放在链表的头部,那么长时间未使用的结点自然就会在链表的尾部,那么在数据清除的时候,将链表尾部的数据删除即可,这样就简单的实现了一个LRU算法。
3.4.1,划分区域的LRU链表
在innodb中,如果一条sql语句,走了全表扫描,type类型为all,那么就会重新的把磁盘里面所有关于该表的数据全部加载到buffer pool中,如果表中的数据量特别大,那么需要的页就特别多,buffer pool的空间是有限的,如果还是使用简单的LRU算法,那么原先在buffer pool的数据就会全部被淘汰掉,从而来存储刚刚全表扫描加进来的页。如果其他表的sql语句又来buffer pool中查询或者更新sql语句,那么又得从磁盘中将数据加载到磁盘中,这样不仅仅会效率低,而且有时候全表扫描进来的是一些冷数据,而直接将buffer pool中的热点数据给直接淘汰了,那么肯定是非常的影响mysql的性能的,大大的降低了buffer pool的缓存命中率。
除了上面的这种方式可能出现冷数据替换掉热点数据之外,预读方式也可能加载进不需要的数据,然后在数据足够多的情况下,将buffer pool中的数据给全部替换掉,从而将这个热点数据给淘汰掉。
因此为了解决这个热点数据被淘汰的情况,innodb通过划分区域的LRU链表来解决这个淘汰策略的问题。

如上图,对这个指向缓存页的控制块形成的双向链表分两个区域,一个是存热点数据的地方,一个是存冷点数据的地方,类似于jvm的新生代和老年代。如果是热点数据,就将数据存在前半部分的链表,如果是冷数据就存放在后半部分的链表,刚从磁盘中加载进来的数据也是存储在这个后半部分的链表上的。热点数据的含义就是在1s内被访问了三次,冷数据也可以变为热点数据,热点数据如果长时间未访问,也会变为冷门数据,存放在这个双向链表的后半部分。
3.5,多个buffer pool实例
在多线程环境下,访问Buffer Pool中的各种链表都需要加锁处理,在Buffer Pool特别大而且多线程并发访问特别高的情况下,单一的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大的时候,我们可以把它们拆分成若干个小的Buffer Pool,每个Buffer Pool都称为一个实例,它们都是独立的,独立的去申请内存空间,独立的管理各种链表,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。
可以通过设置以下的值来设置buffer pool的个数,以及获取每个实例的大小
#设置buffer poool实例的个数
innodb_buffer_pool_instances;
#获取每个实例的大小
innodb_buffer_pool_size/innodb_buffer_pool_instances
当然这个个数也不是说设置越多越好,mysql内部要进行管理,因此mysql规定这个buffer pool的个数最少为1个,最多64个。可以通过以下的命令来查看buffer pool的全部信息。
SHOW ENGINE INNODB STATUS\G
相关文章:
【MySQL进阶-08】深入理解innodb存储格式,双写机制,buffer pool底层结构和淘汰策略
MySql系列整体栏目 内容链接地址【一】深入理解mysql索引本质https://blog.csdn.net/zhenghuishengq/article/details/121027025【二】深入理解mysql索引优化以及explain关键字https://blog.csdn.net/zhenghuishengq/article/details/124552080【三】深入理解mysql的索引分类&a…...

5. AOP
一、如何定义一个MethodHandler? 1.Controller注解修饰的类 1.注册成Spring Bean 2.表示它是一个SpringMVC下的Controller 2.在这个类下的方法中,只要被RequestMapping修饰&&方法的形参符合规定(需要看文档) 方法的返回值符合规定…...

ubuntu上尝试libpqxx库链接人大金仓
ubuntu上尝试libpqxx库链接人大金仓 C的项目让使用国产数据库 运维给架了一个人大金仓数据库, Kingbase 8 是基于 PostgreSQL 9.6 做的, 尝试直接使用libpqxx链接数据库。 文章目录ubuntu上尝试libpqxx库链接人大金仓第一步 搭建libpqxx开发环境搜索lib…...
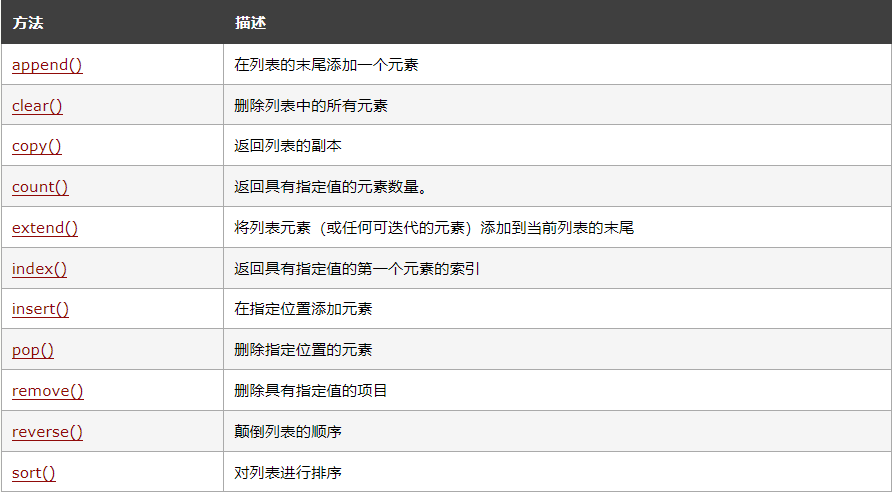
【Python入门第十二天】Python 列表
Python 集合(数组) Python 编程语言中有四种集合数据类型: 列表(List)是一种有序和可更改的集合。允许重复的成员。元组(Tuple)是一种有序且不可更改的集合。允许重复的成员。集合(…...

Android 异步操作库 RxJava
RxJava概述 RxJava 是一种响应式编程,来创建基于事件的异步操作库。基于事件流的链式调用、逻辑清晰简洁。 RxJava 我的理解是将事件从起点(上游)流向终点(下游),中间有很多卡片对数据进操作并传递&#x…...
等级考试试卷(六级)解析)
2021-12-05青少年软件编程(C语言)等级考试试卷(六级)解析
2021-12-05青少年软件编程(C语言)等级考试试卷(六级)解析T1. 电话号码 给你一些电话号码,请判断它们是否是一致的,即是否有某个电话是另一个电话的前缀。比如: Emergency 911 Alice 97 625 999 Bob 91 12 54 26 在这个例子中,我们不可能拨通Bob的电话,因为Emergency的…...
github 使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录一、git与github二、出错的地方1.GitHub没有css样式2、git clone出现错误3、明明创建了responsibility 但git 不显示一、git与github 这个博客写的很好!…...
Kubernetes集群维护—备份恢复与升级
Etcd数据库备份与恢复 需要先安装etcd备份工具yum install etcd -y按不同安装方式执行不同备份与恢复kubeadm部署方式: 备份:ETCDCTL_API3 etcdctl snapshot save snap.db --endpointshttps://127.0.0.1:2379 --cacert/etc/kubernetes/pki/etcd/ca.cr…...
前端开发常用案例(二)
这里写目录标题1.loding加载动画2.全屏加载动画效果3.吃豆豆4.鼠标悬停3D翻转效果5.3D旋转木马效果6.flex弹性布局-酷狗音乐播放列表flex弹性布局-今日头条首页热门视频栏grid网格布局-360图片展示小米商城左侧二级菜单1.loding加载动画 代码如下: <!DOCTYPE h…...

基于springboot+vue的儿科保健计划免疫系统
基于springbootvue的儿科保健计划免疫系统 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背…...

1.两数之和
难度简单给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。你可以按任意顺序…...

字符串匹配 - 模式预处理:KMP 算法(Knuth-Morris-Pratt)
Knuth-Morris-Pratt算法(简称KMP)是最常用的字符串匹配算法之一。算法简介如下算法解释主要来源于这里,但是通常很难阅读完全,我推荐你直接进入下一节 图例解释部分。我们来观察一下朴素的字符串匹配算法的操作过程。如下图&#…...
工程师手册:电源设计中的电容选用规则
摘要 电源往往是我们在电路设计过程中最容易忽略的环节。作为一款优秀的设计,电源设计应当是很重要的,它很大程度影响了整个系统的性能和成本。电源设计中的电容使用,往往又是电源设计中最容易被忽略的地方。一、电源设计中电容的工作原理 在…...

【安全开发】专栏文章汇总
安全开发–1–TCP和UDP网络编程 安全开发–2–嗅探邮箱协议口令 安全开发–3–Python实现ARP缓存投毒 安全开发–4–SSH通信工具开发 安全开发–5–编写简单的netcat工具 安全开发–6–一个简单的TCP代理工具开发 安全开发–7–SSH隧道工具开发 安全开发–8–Python实现流量数据…...

视频监控流程图4
<html> <head> <meta http-equiv"Content-Type" content"text/html; charsetUTF-8"/> <link rel"stylesheet" type"text/css" href"visio.css"/> <title> 视频监控流程图 </title> <…...
)
「JVM 编译优化」Java 语法糖(泛型、自动装箱/拆箱、条件编译)
「JVM 编译优化」Java 语法糖(泛型、自动装箱/拆箱、条件编译) 语法糖可以看做事前端编译期的一些小把戏;虽不会提供实质性的功能改进,但它们或能提高效率,或能提升语法的严谨性,或能减少编码出错的机会&a…...
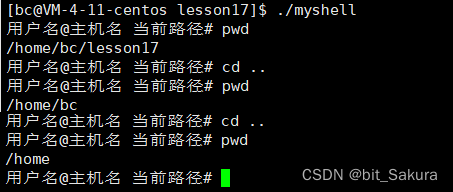
Linux下的进程控制
目录 退出码 终止进程 进程等待 进程程序替换 自己实现简易shell命令行 内建命令 退出码 在编写代码时main函数内部我们通常都使用return 0;结尾,以此标识正常退出。这里的return 0就是所谓的退出码,Linux下也是一样: 看这个小程序&…...
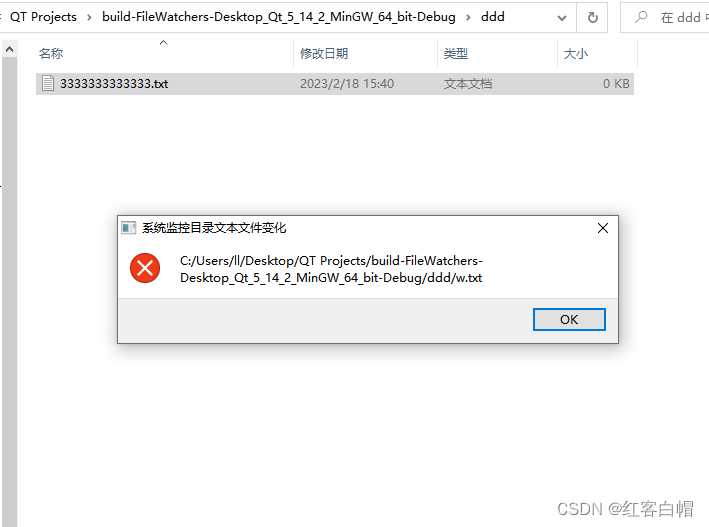
QT 文件监视系统QFileSystemWatcher监视目录的改变directoryChanged和监视文件的改变fileChanged
QT 文件监视系统QFileSystemWatcher监视目录的改变相关操作说明mainwindow.hmainwindow.cpp调试结果相关操作说明 添加头文件 Header: #include qmake: QT core bool QFileSystemWatcher::addPath(const QString &path)如果路径存在,则会向文件系统监视器添…...
)
Typescript基础知识(类型断言、类型别名、字符串字面量类型、枚举、交叉类型)
系列文章目录 引入一:Typescript基础引入(基础类型、元组、枚举) 引入二:Typescript面向对象引入(接口、类、多态、重写、抽象类、访问修饰符) 第一章:Typescript基础知识(Typescri…...
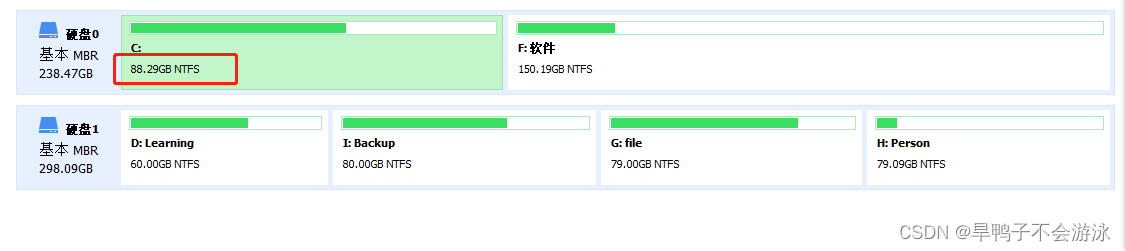
Windows系统扩充C盘空间系列方法总结
目录前言方法一 使用自带的Windows的DiskPart扩充C盘1. 打开cmd2.三步命令方法二:使用Windows系统内置磁盘管理扩展C盘方法三. 使用专业磁盘分区工具总结前言 本教程是总结Windows系统进行C盘(系统盘)扩充空间的系列方法,一般来讲…...

龙虾热降温,我们到底需要什么样的 Agent?
责编 | 《AI 进化论》栏目组出品 | CSDN(ID:CSDNnews)过去几个月,AI Agent 无疑是技术圈最火热的词。我们聊颠覆、聊入口、聊取代……仿佛一夜之间,一个无所不能的“数字员工”就能接管我们的一切工作。热度之下&#…...

从方程到应用:激光雷达核心参数与激光器选型指南
1. 激光雷达方程:从数学公式到物理意义 第一次接触激光雷达方程时,我也被那一堆希腊字母和下标搞得头晕眼花。但后来发现,这个看似复杂的方程其实就像买菜算账一样简单直白。激光雷达方程本质上是个"能量收支平衡表",它…...

当AI的键值记忆遇上大脑:原来我们和AI共享同一套记忆逻辑
导语在日常经验中,我们常把“遗忘”理解为信息的流失:时间久了,记忆就会慢慢消失;学习新知识,也可能覆盖旧内容。然而,从短视频推荐到大语言模型,再到人类被线索唤醒的记忆体验,这些…...
)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流(附常用场景脚本)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流 在Linux系统中管理多显示器配置,xrandr无疑是最强大的命令行工具之一。但每次手动输入复杂的xrandr命令来调整显示器布局,对于追求效率的高级用户来说,无疑是一种时间…...

2026女性入局IT:这10张证书最吃香
一、引言:数字化转型背景下的IT职业性别结构变迁根据Gartner 2025年度全球数字化劳动力报告显示,女性在IT领域的参与度正从传统的“软件开发与测试”向“数据驱动决策”、“产品与项目管理”以及“用户体验设计”迁移。这一结构性变化主要归因于企业对数…...

从数据到角度:手把手调试大疆C板BMI088,解决姿态解算精度跳动的那些坑
从数据到角度:手把手调试大疆C板BMI088,解决姿态解算精度跳动的那些坑 调试嵌入式系统中的传感器数据,尤其是姿态解算这类对精度要求极高的应用,往往需要开发者具备跨领域的知识储备和丰富的实战经验。本文将分享我在使用大疆C板搭…...

Eviews面板数据建模保姆级教程:从Hausman检验到模型选择,一次讲透固定效应与随机效应
Eviews面板数据建模实战指南:从数据导入到模型选择的完整流程 面板数据分析作为计量经济学中的重要工具,能够同时捕捉时间和个体维度的信息。对于刚接触Eviews的研究者来说,如何正确建立面板模型往往令人困惑——从数据准备到模型选择&#x…...

别再手动导数据了!用Python的pandas+pyarrow,3行代码搞定Parquet转JSON
3行代码解锁数据自由:用Python极简实现Parquet到JSON的优雅转换 数据工程师的日常总是与格式转换纠缠不清。当你在凌晨两点收到紧急需求:"立刻把数据仓库里50GB的用户行为Parquet文件转成JSON供下游系统调用",是选择打开文档逐行编…...

车载以太网之要火系列 - 第43篇:郭大侠学SOME/IP :服务写死痛点多,SD出山更灵活
写在开篇蓉儿挖新坑上回说到,郭靖搞清楚了SOME/IP的报文头、Service ID、Instance ID、Method、Event、Field……学了一大堆。郭靖合上笔记本,信心满满:“蓉儿,SOME/IP我算是学完了!车窗服务用0x0300,左前窗…...

告别窄带!用ADS仿真带你搞懂Doherty放大器带宽瓶颈与三种宽带方案
突破Doherty放大器带宽限制:ADS仿真实战与三大宽带方案解析 在射频功率放大器设计中,Doherty结构因其高效率特性成为5G基站和现代通信系统的核心组件。然而传统设计面临严峻的带宽挑战——当信号频率偏离中心频点时,效率可能骤降30%以上。本文…...