【爬虫实践】使用Python从网站抓取数据
一、说明
本周我不得不为客户抓取一个网站。我意识到我做得如此自然和迅速,分享它会很有用,这样你也可以掌握这门艺术。【免责声明:本文展示了我的抓取做法,如果您有更多相关做法请在评论中分享】
二、计划策略
2.1 策划
- 确定您的目标:一个简单的 html 网站
- 在 Python 中设计抓取方案
- 跑起代码,让魔术运转

您需要多少时间来抓取网站?从业者需要~10分钟为一个简单的html网站准备Python脚本。
2.2 第一部分:找到你的目标(一个网站)
就我而言,我需要从 SWIFT 代码(或法国 BIC 代码)中收集银行名称。该网站 http://bank-code.net/country/FRANCE-%28FR%29.html 有一个4000+ SWIFT代码的列表以及相关的银行名称。问题是它们每页仅显示 15 个结果。浏览所有页面并一次复制粘贴 15 个结果不是一种选择。刮擦在这项任务中派上了用场。
首先,使用Chrome“检查”选项来确定您需要获取的html部分。将鼠标移动到检查窗口中的不同项目上(右侧),然后跟踪代码突出显示的网站部分(左侧)。选择项目后,在检查窗口中,使用“复制/复制元素”并将 html 代码粘贴到 python 编码工具中。
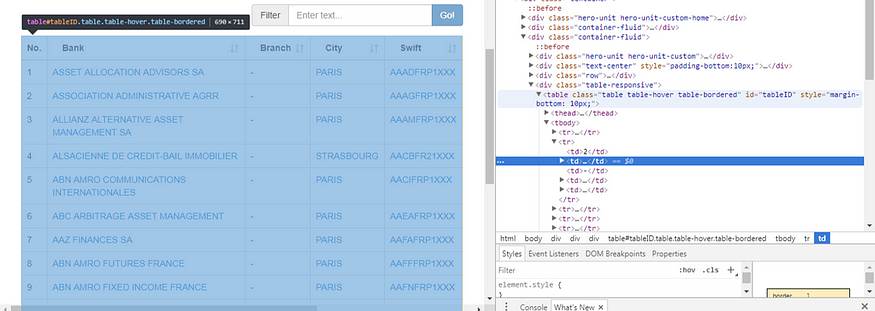
右侧是谷歌浏览器的“检查窗口”,您在使用右键单击/检查时获得
就我而言,具有 15 个 SWIFT 代码的所需项目是一个“表”
<table class="table table-hover table-bordered" id="tableID" style="margin-bottom: 10px;">
</table>2.3 第二部分:在 Python 中设计抓取方案
a)scrape第一页
import requests
url = "http://bank-code.net/country/FRANCE-%28FR%29/"
page = requests.get(url)就是这样,3行代码和Python已经收到了网页。现在,您需要正确解析html并检索所需的项目。
记住所需的 html :
<table class="table table-hover table-bordered" id="tableID" style="margin-bottom: 10px;">
</table>它是一个“table”元素,id为“tableID”。它有一个id属性的事实很好,因为这个网页上没有其他html元素可以有这个id。这意味着如果我在 html 中查找此 id,除了所需的元素之外,我找不到任何其他内容。它节省了时间。
让我们在 Python 中正确地做到这一点
import bs4
soup = bs4.BeautifulSoup(page.content, 'lxml')
table = soup.find(name='table', attrs={'id':'tableID'})所以现在我们得到了所需的 html 元素。但是我们仍然需要获取 html 中的 SWIFT 代码,然后将其存储在 Python 中。我选择把它存放在熊猫里。数据帧对象,但只有一个列表列表也可以解决。
为此,请返回Chrome检查窗口,分析html树的结构,并注意您必须转到哪个元素。就我而言,所需的数据位于“tbody”元素中。每个银行及其SWIFT代码都包含在一个“tr”元素中,每个“tr”元素有多个“td”元素。“td”元素包含我正在寻找的数据。

html 树可以描述如下:table, tbody, tr, td
我在一行中做到了,如下所示:
result = pd.DataFrame([[td.text for td in row.findAll('td')] for row in table.tbody.findAll('tr')])
b) 准备自动化
现在我们已经抓取了第一个网页,我们需要考虑如何抓取我们尚未看到的新网页。我这样做的方法是复制人类行为:存储一页的结果,然后转到下一页。现在让我们专注于下一个网页。
在页面底部,有一个菜单,允许您进入 swift 代码表的特定页面。让我们检查检查器窗口中的“下一页”按钮。
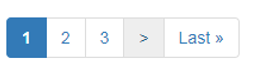
“>”符号将引导我们进入下一页
这给出了以下 html 元素:
<a href="//bank-code.net/country/FRANCE-%28FR%29/15" data-ci-pagination-page="2" rel="next">></a>
现在在 Python 中获取 url 很简单:
"http:" + soup.find('a', attrs={'rel':'next'}).get('href')我们快到了。
到目前为止,我们已经:
- 开发了一页表格的抓取 - 确定了下一页
的 url 链接
我们只需要做一个循环,然后运行代码。我建议遵循以下两种最佳实践:
1. 登陆新网页时打印出来:知道您的代码处于流程的哪个阶段(抓取代码可以运行数小时)
2.定期保存结果:避免在出现错误时丢失所有抓取的内容
只要我不知道何时停止抓取,我就会使用惯用的“while True:”语法循环。我在每一步打印出计数器值。而且我也在每一步将结果保存在csv文件中。这实际上可能会浪费时间,例如,更好的方法是每 10 或 20 步存储一次数据。但我追求快速实施。
三、完整代码
代码是这样的:
import os, bs4, requests
import pandas as pdPATH = os.path.join("C:\\","Users","xxx","Documents","py") # you need to change to your local path
res = pd.DataFrame()
url = "http://bank-code.net/country/FRANCE-%28FR%29/"
counter = 0def table_to_df(table): return pd.DataFrame([[td.text for td in row.findAll('td')] for row in table.tbody.findAll('tr')])def next_page(soup): return "http:" + soup.find('a', attrs={'rel':'next'}).get('href')while True:print(counter)page = requests.get(url)soup = bs4.BeautifulSoup(page.content, 'lxml')table = soup.find(name='table', attrs={'id':'tableID'})res = res.append(table_to_df(table))res.to_csv(os.path.join(os.path.join(PATH,"table.csv")), index=None, sep=';', encoding='iso-8859–1')url = next_page(soup)counter += 1完整的代码(只有26行)可以在这里找到:https://github.com/FelixChop/MediumArticles/blob/master/Scraping_SWIFT_codes_Bank_names.py
相关文章:
【爬虫实践】使用Python从网站抓取数据
一、说明 本周我不得不为客户抓取一个网站。我意识到我做得如此自然和迅速,分享它会很有用,这样你也可以掌握这门艺术。【免责声明:本文展示了我的抓取做法,如果您有更多相关做法请在评论中分享】 二、计划策略 2.1 策划 确定您…...
win10 2022unity设置中文
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言解决方法 前言 在Edit->preferences里找不到language选项。 解决方法 【1】打开下面地址 注意 :把{version}换成你当前安装的版本,比如说如果…...

python表白代码大全可复制,python表白代码大全简单
大家好,小编来为大家解答以下问题,python表白代码大全可复制,python表白程序代码完整版,现在让我们一起来看看吧! 今天是20230520,有人说:5代表的是人生五味,酸甜苦辣咸;…...

wordpress 打开缓慢处理
gravatar.com 头像网站被墙 追踪发现请求头像时长为21秒 解决方案一 不推荐,容易失效,网址要是要稳定为主,宁愿头像显示异常,也不能网址打不开 网上大部分搜索到的替换的CDN网址都过期了,例如:gravatar.du…...
Adobe ColdFusion 反序列化漏洞复现(CVE-2023-29300)
0x01 产品简介 Adobe ColdFusion是美国奥多比(Adobe)公司的一套快速应用程序开发平台。该平台包括集成开发环境和脚本语言。 0x02 漏洞概述 Adobe ColdFusion存在代码问题漏洞,该漏洞源于受到不受信任数据反序列化漏洞的影响,攻击…...

林【2018】
关键字: BST插入叶子结点、ADT结伴操作、队列插入前r-1、哈希函数二次探测法(1,-1,4,-4)、队列元素个数、折半查找失败次数、广义表链表结构、B-树构建、单链表指定位置插入数组元素 一、判断 二、单选 h(49)+1,-1,+4,-4...
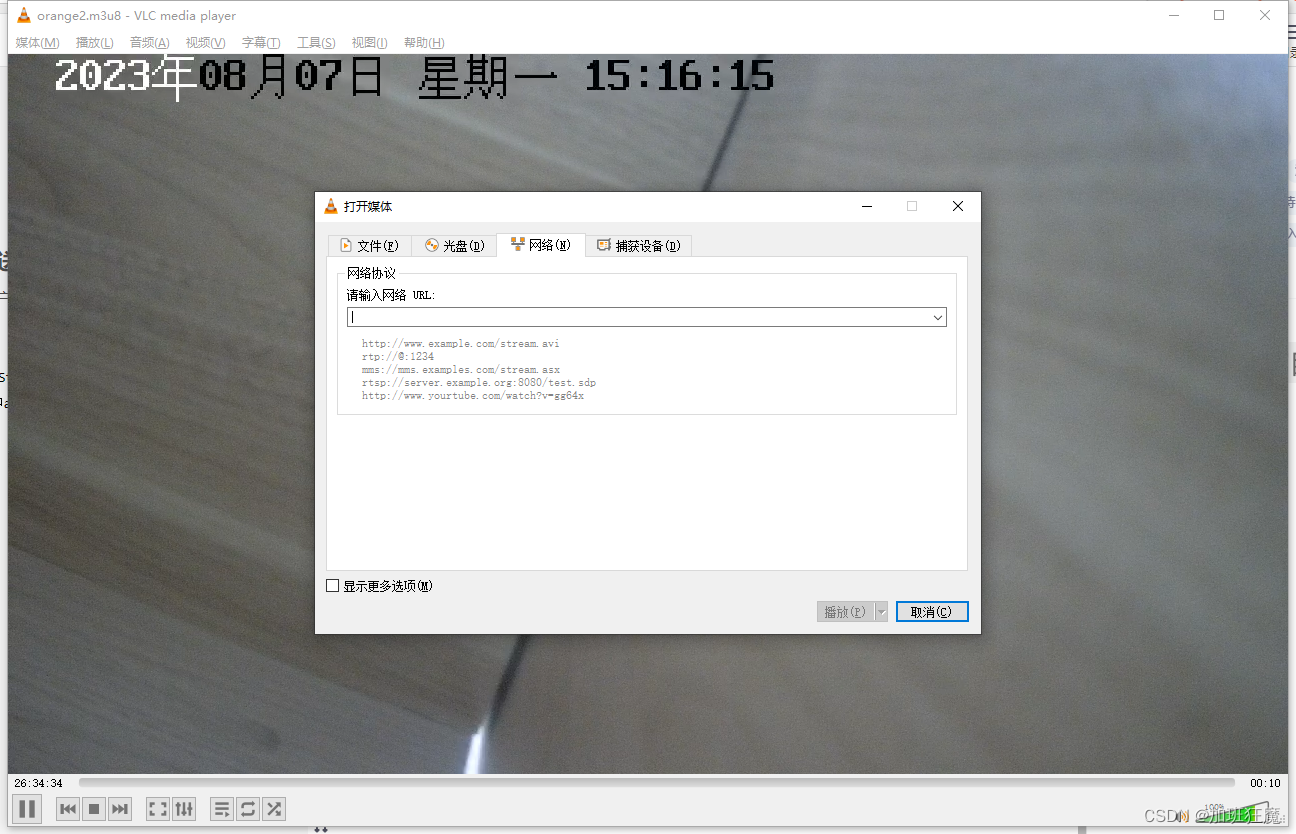
ffmpeg+nginx实现rtsp协议摄像头web端播放
ffmpegnginx实现rtsp协议摄像头web端播放 环境准备准备nginx环境添加rtmp模块添加hls转发 使用ffmpeg,将摄像头rtsp转为rtmp并推送到nginxVLC播放验证 环境准备 nginx(需要安装rtmp模块)ffmpeg 6.0vlc播放器(本地播放验证&#x…...

【周赛第69期】满分题解 软件工程选择题 枚举 dfs
目录 选择题1.2.3.4.面向对象设计七大原则 编程题S数最小H值 昨晚没睡好,脑子不清醒,痛失第1名 选择题 1. 关于工程效能,以下哪个选项可以帮助提高团队的开发效率? A、频繁地进行代码审查 B、使用自动化测试工具 C、使用版本控…...

P2015 二叉苹果树
P2015 二叉苹果树 类似于带限制背包问题,但不知道也能做。 n , q n,q n,q 范围小,大胆设 dp 状态。设 f u , i \large f_{u,i} fu,i 表示 u u u 子树内保留 i i i 根树枝的最大苹果数,可得状态转移方程 f u , i f u , j f v , i − …...

Linux 内核音频数据传递主要流程
Linux 用户空间应用程序通过声卡驱动程序(一般牵涉到多个设备驱动程序)和 Linux 内核 ALSA 框架导出的 PCM 设备文件,如 /dev/snd/pcmC0D0c 和 /dev/snd/pcmC0D0p 等,与 Linux 内核音频设备驱动程序和音频硬件进行数据传递。PCM 设…...

torch.device函数
torch.device 是 PyTorch 中用于表示计算设备(如CPU或GPU)的类。它允许你在代码中指定你希望在哪个设备上执行张量和模型操作,本文主要介绍了 torch.device 函数的用法和功能。 本文主要包含以下内容: 1.创建设备对象2.将张量和模…...
火车头采集器AI伪原创【php源码】
大家好,本文将围绕python作业提交什么文件展开说明,python123怎么提交作业是一个很多人都想弄明白的事情,想搞清楚python期末作业程序需要先了解以下几个事情。 火车头采集ai伪原创插件截图: I have a python project, whose fold…...

Python中常见的6种数据类型
数字(Numbers):数字类型用于表示数值,包括整数(int)和浮点数(float)。 字符串(Strings):字符串类型用于表示文本,由一系列字符组成。字…...
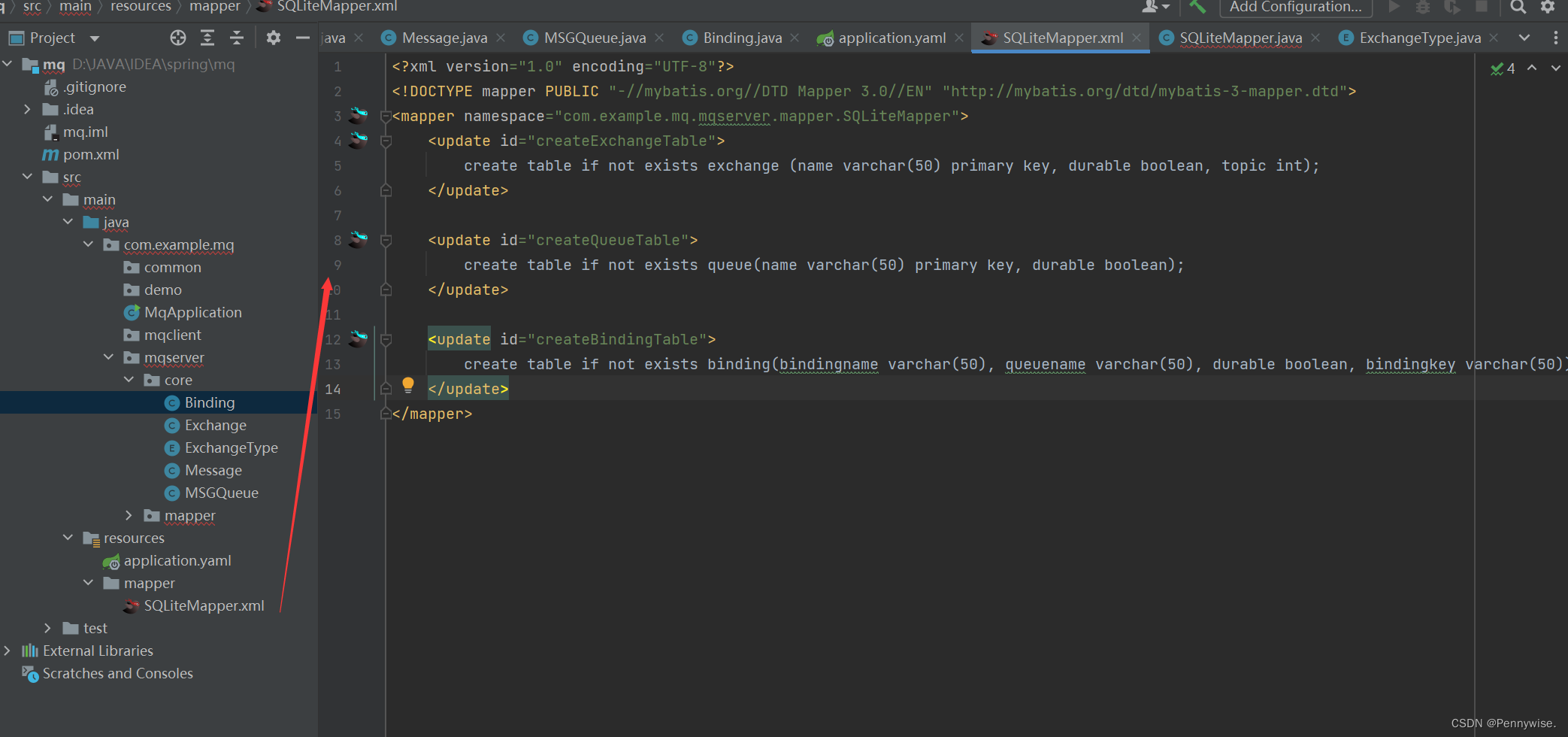
消息队列项目(2)
我们使用 SQLite 来进行对 Exchange, Queue, Binding 的硬盘保存 对 Message 就保存在硬盘的文本中 SQLite 封装 这里是在 application.yaml 中来引进对 SQLite 的封装 spring:datasource:url: jdbc:sqlite:./data/meta.dbusername:password:driver-class-name: org.sqlite.…...
解决MAC M1处理器运行Android protoc时出现的错误
Protobuf是Google开发的一种新的结构化数据存储格式,一般用于结构化数据的序列化,也就是我们常说的数据序列化。这个序列化协议非常轻量级和高效,并且是跨平台的。目前,它支持多种主流语言,比传统的XML、JSON等方法更具…...

C#使用SnsSharp实现鼠标键盘钩子,实现全局按键响应
gitee下载地址:https://gitee.com/linsns/snssharp 一、键盘事件,使用SnsKeyboardHook 按键事件共有3个: KeyDown(按键按下) KeyUp(按键松开) KeyPress(按键按下并松开) 以KeyDown事件为例,使用代码如下&…...

Zookeeper基础操作
搭建Zookeeper服务器 windows下部署 下载地址: https://mirrors.cloud.tencent.com/apache/zookeeper/zookeeper-3.7.1/ 修改配置文件 打开conf目录,将 zoo_sample.cfg复制一份,命名为 zoo.cfg打开 zoo.cfg,修改 dataDir路径,…...
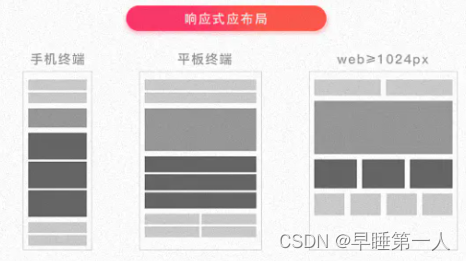
【CSS】说说响应式布局
目录 一、是什么 二、怎么实现 1、媒体查询 2、百分比 3、vw/vh 4、小结 三、总结 一、是什么 响应式设计简而言之,就是一个网站能够兼容多个终端——而不是为每个终端做一个特定的版本。 响应式网站常见特点: 同时适配PC 平板 手机等…...
数据结构 | 利用二叉堆实现优先级队列
目录 一、二叉堆的操作 二、二叉堆的实现 2.1 结构属性 2.2 堆的有序性 2.3 堆操作 队列有一个重要的变体,叫作优先级队列。和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的。优先级最高的元素在最前ÿ…...

Javascript怎样阻止事件传播?
在 JavaScript 中,可以使用事件对象的方法来阻止事件传播。事件传播指的是当一个元素上触发了一个事件,该事件会在事件流中传播到父元素或祖先元素,从而影响到它们。 事件传播有三个阶段:捕获阶段、目标阶段和冒泡阶段。阻止事件…...

别再只刷Demo了!手把手教你用CCS给AWR1843毫米波雷达写自己的‘大脑’
从Demo玩家到雷达开发者:AWR1843毫米波雷达CCS深度开发实战 毫米波雷达技术正在智能驾驶、工业检测等领域掀起革命浪潮。作为TI明星产品,AWR1843凭借其高性价比和丰富功能成为众多开发者的首选。但大多数用户止步于运行官方Demo,未能真正释放…...

第十五篇:《压测结果分析与调优实践:瓶颈定位与性能优化》
压测执行只是开始,真正的价值在于从结果中定位瓶颈并推动优化。面对一堆响应时间、TPS、错误率曲线,如何判断系统哪里出了问题?如何区分是代码、数据库、中间件还是硬件瓶颈?本文将系统讲解压测结果的分析方法,结合监控…...

Nginx Server Configs Node.js配置:Node应用部署最佳实践终极指南
Nginx Server Configs Node.js配置:Node应用部署最佳实践终极指南 【免费下载链接】server-configs-nginx Nginx HTTP server boilerplate configs 项目地址: https://gitcode.com/gh_mirrors/se/server-configs-nginx Node.js应用部署常常面临性能优化、安全…...
)
告别重装系统!在Ubuntu 22.04上从零到一搞定ROS2 Humble(附小乌龟测试)
告别重装系统!在Ubuntu 22.04上从零到一搞定ROS2 Humble(附小乌龟测试) 每次看到论坛里"ROS2请用Ubuntu 20.04"的推荐,我都忍不住想:难道新系统就注定与机器人开发无缘?去年我将工作站升级到22.0…...

掌握Flash逆向工程:JPEXS免费反编译工具完全指南
掌握Flash逆向工程:JPEXS免费反编译工具完全指南 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler 在Flash技术逐渐淡出历史舞台的今天,无数经典的Flash动画、游戏…...

CloudCompare点云标注实战:从数据载入到标签修正的完整指南
1. CloudCompare简介与安装指南 点云数据处理是三维视觉领域的基础工作,而CloudCompare(简称CC)作为一款开源的点云处理软件,凭借其轻量级和丰富的功能,成为许多研究者和工程师的首选工具。我第一次接触这款软件是在处…...

ItsyBitsy RP2040与CircuitPython实战:从硬件解析到环境数据记录仪项目
1. 项目概述:为什么选择ItsyBitsy RP2040?如果你玩过树莓派Pico,或者用过Adafruit的Feather系列开发板,那么第一次拿到ItsyBitsy RP2040时,你可能会和我有同样的感觉:这东西也太小了。它的尺寸只有1.4英寸长…...

Claude与OpenClaw整合指南:AI代码生成与自动化执行实战
1. 项目概述与核心价值最近在开发者社区里,一个名为“Claude-Code-x-OpenClaw-Guide-Zh”的项目引起了我的注意。乍一看这个标题,可能有些朋友会觉得它像是一个普通的工具集合或者文档翻译。但当我深入探究其背后的代码仓库和社区讨论后,我发…...

从Git历史到数据洞察:构建代码仓库统计分析工具的设计与实践
1. 项目概述:一个为开发者量身定制的代码统计工具 在软件开发的日常中,无论是个人复盘、团队汇报,还是项目交接,我们常常会遇到一个看似简单却颇为棘手的问题:如何客观、量化地评估一个代码仓库的“工作量”或“活跃度…...

深度解析开源小红书采集工具:XHS-Downloader技术架构与实战应用指南
深度解析开源小红书采集工具:XHS-Downloader技术架构与实战应用指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、…...