kafka权威指南(阅读摘录)

零复制
Kafka 使用零复制技术向客户端发送消息——也就是说,Kafka 直接把消息从文件(或者更确切地说是 Linux 文件系统缓存)里发送到网络通道,而不需要经过任何中间缓冲区。这是 Kafka 与其他大部分数据库系统不一样的地方,其他数据库在将数据发送给客户端之前会先把它们保存在本地缓存里。这项技术避免了字节复制,也不需要管理内存缓冲区,从而获得更好的性能。
如何选定分区数量
为主题选定分区数量并不是一件可有可无的事情,在进行数量选择时,需要考虑如下几个因素。
-
主题需要达到多大的吞吐量?例如,是希望每秒钟写入 100KB 还是 1GB ?
-
从单个分区读取数据的最大吞吐量是多少?每个分区一般都会有一个消费者,如果你知道消费者将数据写入数据库的速度不会超过每秒 50MB,那么你也该知道,从一个分区读取数据的吞吐量不需要超过每秒 50MB。
-
可以通过类似的方法估算生产者向单个分区写入数据的吞吐量,不过生产者的速度一般比消费者快得多,所以最好为生产者多估算一些吞吐量。
-
每个 broker 包含的分区个数、可用的磁盘空间和网络带宽。
-
如果消息是按照不同的键来写入分区的,那么为已有的主题新增分区就会很困难。
-
单个 broker 对分区个数是有限制的,因为分区越多,占用的内存越多,完成首领选举需要的时间也越长。
消费者数量
我们有必要为主题创建大量的分区,在负载增长时可以加入更多的消费者。不过要注意,不要让消费者的数量超过主题分区的数量,多余的消费者只会被闲置。
跟随者副本
首领以外的副本都是跟随者副本。跟随者副本不处理来自客户端的请求,它们唯一的任务就是从首领那里复制消息,保持与首领一致的状态。如果首领发生崩溃,其中的一个跟随者会被提升为新首领。
Kafka 可以在哪些方面作出保证呢?
- Kafka 可以保证分区消息的顺序。如果使用同一个生产者往同一个分区写入消息,而且消息 B 在消息 A 之后写入,那么 Kafka 可以保证消息 B 的偏移量比消息 A 的偏移量大,而且消费者会先读取消息 A 再读取消息 B。
- 只有当消息被写入分区的所有同步副本时(但不一定要写入磁盘),它才被认为是“已提交”的。生产者可以选择接收不同类型的确认,比如在消息被完全提交时的确认,或者在消息被写入首领副本时的确认,或者在消息被发送到网络时的确认。
- 只要还有一个副本是活跃的,那么已经提交的消息就不会丢失。
- 消费者只能读取已经提交的消息。
复制机制和分区的多副本架构
Kafka 的复制机制和分区的多副本架构是 Kafka 可靠性保证的核心。把消息写入多个副本可以使 Kafka 在发生崩溃时仍能保证消息的持久性。
使用 Kafka 构建数据管道
在使用 Kafka 构建数据管道时,通常有两种使用场景:第一种,把 Kafka 作为数据管道的两个端点之一,例如,把 Kafka 里的数据移动到 S3 上,或者把 MongoDB 里的数据移动到 Kafka 里;第二种,把 Kafka 作为数据管道两个端点的中间媒介,例如,为了把 Twitter 的数据移动到 ElasticSearch 上,需要先把它们移动到 Kafka 里,再将它们从 Kafka 移动到 ElasticSearch 上。
Kafka 为数据管道带来的主要价值
Kafka 为数据管道带来的主要价值在于,它可以作为数据管道各个数据段之间的大型缓冲区,有效地解耦管道数据的生产者和消费者。Kafka 的解耦能力以及在安全和效率方面的可靠性,使它成为构建数据管道的最佳选择。
ETL 和 ELT
数据管道的构建可以分为两大阵营,即 ETL 和 ELT。 ETL 表示提取—转换—加载(Extract-Transform-Load),也就是说,当数据流经数据管道时,数据管道会负责处理它们。这种方式为我们节省了时间和存储空间,因为不需要经过保存数据、修改数据、再保存数据这样的过程。不过,这种好处也要视情况而定。有时候,这种方式会给我们带来实实在在的好处,但也有可能给数据管道造成不适当的计算和存储负担。这种方式“有一个明显不足,就是数据的转换会给数据管道下游的应用造成一些限制,特别是当下游的应用希望对数据进行进一步处理的时候。假设有人在 MongoDB 和 MySQL 之间建立了数据管道,并且过滤掉了一些事件记录,或者移除了一些字段,那么下游应用从 MySQL 中访问到的数据是不完整的。如果它们想要访问被移除的字段,只能重新构建管道,并重新处理历史数据(如果可能的话)。
ELT 表示提取—加载—转换(Extract-Load-Transform)。在这种模式下,数据管道只做少量的转换(主要是数据类型转换),确保到达数据池的数据尽可能地与数据源保持一致。这种情况也被称为高保真(high fidelity)数据管道或数据湖(data lake)架构。目标系统收集“原始数据”,并负责处理它们。这种方式为目标系统的用户提供了最大的灵活性,因为它们可以访问到完整的数据。在这些系统里诊断问题也变得更加容易,“因为数据被集中在同一个系统里进行处理,而不是分散在数据管道和其他应用里。这种方式的不足在于,数据的转换占用了目标系统太多的 CPU 和存储资源。有时候,目标系统造价高昂,如果有可能,人们希望能够将计算任务移出这些系统。
数据管道
数据管道最重要的作用之一是解耦数据源和数据池。
留待实战内容
连接器示例——从MySQL到ElasticSearch
broker最重要的度量指标
如果说 broker 只有一个可监控的度量指标,那么它一定是指非同步分区的数量。该度量指明了作为首领的 broker 有多少个分区处于非同步状态。这个度量可以反映 Kafka 的很多内部问题,从 broker 的崩溃到资源的过度消耗。
集群问题
集群问题一般分为以下两类:
- 不均衡的负载。
- 资源过度消耗。
流入和流出速率
流出速率也包括副本流量,也就是说,如果所有主题都设置了复制系数 2,那么在没有消费者客户端的情况下,流出速率与流入速率是一样的。
流式处理
流式处理是指实时地处理一个或多个事件流。流式处理是一种编程范式,就像请求与响应范式和批处理范式那样。
只要持续地从一个无边界的数据集读取数据,然后对它们进行处理并生成结果,那就是在进行流式处理。重点是,整个处理过程必须是持续的。
表与流
在将表与流进行对比时,可以这么想:流包含了变更——流是一系列事件,每个事件就是一个变更。表包含了当前的状态,是多个变更所产生的结果。所以说,表和流是同一个硬币的两面——世界总是在发生变化,用户有时候关注变更事件,有时候则关注世界的当前状态。如果一个系统允许使用这两种方式来查看数据,那么它就比只支持一种方式的系统强大。
时间窗口
如果“移动间隔”与窗口大小相等,这种情况被称为“滚动窗口(tumbling window)”。如果窗口随着每一条记录移动,这种情况被称为“滑动窗口(sliding window)”。
变更数据捕捉(Change Data Capture)
如果能够捕捉数据库的变更事件,并形成事件流,流式处理作业就可以监听事件流,并及时更新缓存。捕捉数据库的变更事件并形成事件流,这个过程被称为 CDC——变更数据捕捉(Change Data Capture)。
基于时间窗口的连接(windowed-join)
如果要连接两个流,那么就是在连接所有的历史事件——将两个流里具有相同键和发生在相同时间窗口内的事件匹配起来。这就是为什么流和流的连接也叫作基于时间窗口的连接(windowed-join)。
相关文章:
kafka权威指南(阅读摘录)
零复制 Kafka 使用零复制技术向客户端发送消息——也就是说,Kafka 直接把消息从文件(或者更确切地说是 Linux 文件系统缓存)里发送到网络通道,而不需要经过任何中间缓冲区。这是 Kafka 与其他大部分数据库系统不一样的地方&#…...
【爬虫实践】使用Python从网站抓取数据
一、说明 本周我不得不为客户抓取一个网站。我意识到我做得如此自然和迅速,分享它会很有用,这样你也可以掌握这门艺术。【免责声明:本文展示了我的抓取做法,如果您有更多相关做法请在评论中分享】 二、计划策略 2.1 策划 确定您…...
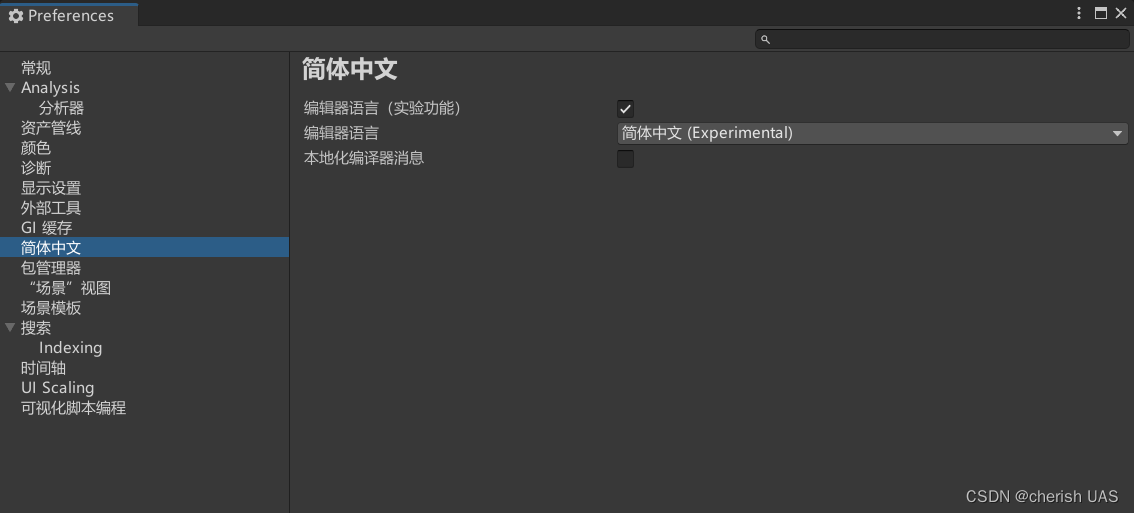
win10 2022unity设置中文
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言解决方法 前言 在Edit->preferences里找不到language选项。 解决方法 【1】打开下面地址 注意 :把{version}换成你当前安装的版本,比如说如果…...

python表白代码大全可复制,python表白代码大全简单
大家好,小编来为大家解答以下问题,python表白代码大全可复制,python表白程序代码完整版,现在让我们一起来看看吧! 今天是20230520,有人说:5代表的是人生五味,酸甜苦辣咸;…...

wordpress 打开缓慢处理
gravatar.com 头像网站被墙 追踪发现请求头像时长为21秒 解决方案一 不推荐,容易失效,网址要是要稳定为主,宁愿头像显示异常,也不能网址打不开 网上大部分搜索到的替换的CDN网址都过期了,例如:gravatar.du…...
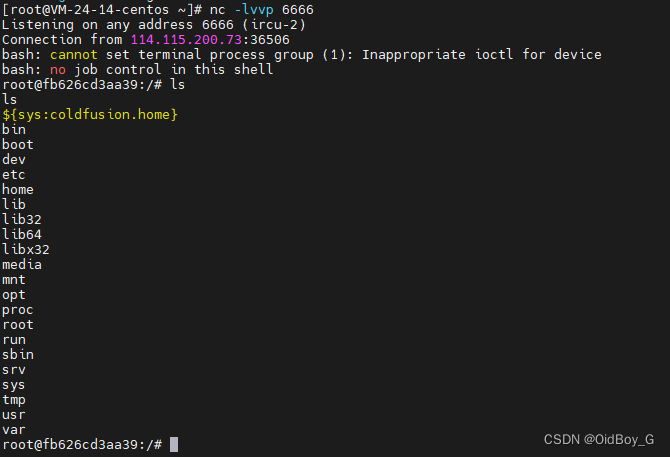
Adobe ColdFusion 反序列化漏洞复现(CVE-2023-29300)
0x01 产品简介 Adobe ColdFusion是美国奥多比(Adobe)公司的一套快速应用程序开发平台。该平台包括集成开发环境和脚本语言。 0x02 漏洞概述 Adobe ColdFusion存在代码问题漏洞,该漏洞源于受到不受信任数据反序列化漏洞的影响,攻击…...

林【2018】
关键字: BST插入叶子结点、ADT结伴操作、队列插入前r-1、哈希函数二次探测法(1,-1,4,-4)、队列元素个数、折半查找失败次数、广义表链表结构、B-树构建、单链表指定位置插入数组元素 一、判断 二、单选 h(49)+1,-1,+4,-4...
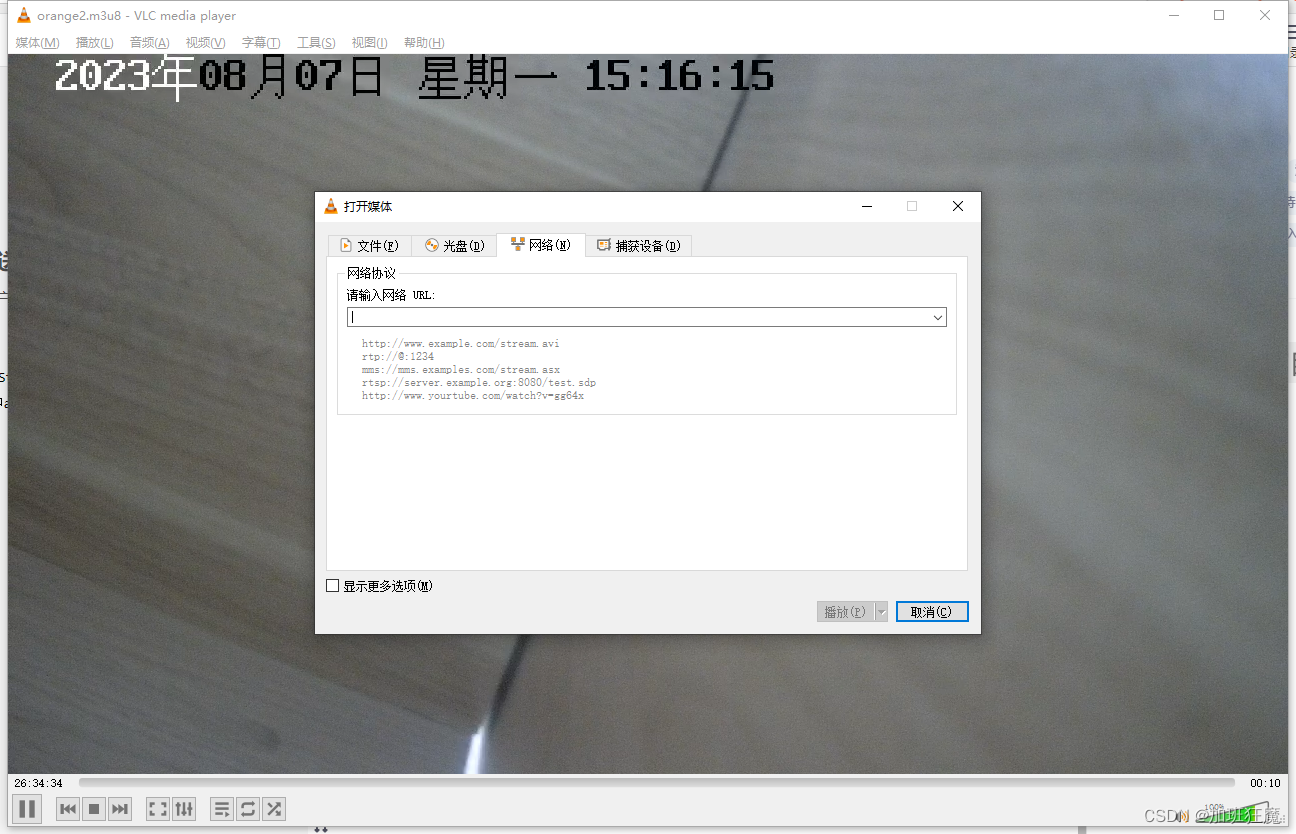
ffmpeg+nginx实现rtsp协议摄像头web端播放
ffmpegnginx实现rtsp协议摄像头web端播放 环境准备准备nginx环境添加rtmp模块添加hls转发 使用ffmpeg,将摄像头rtsp转为rtmp并推送到nginxVLC播放验证 环境准备 nginx(需要安装rtmp模块)ffmpeg 6.0vlc播放器(本地播放验证&#x…...

【周赛第69期】满分题解 软件工程选择题 枚举 dfs
目录 选择题1.2.3.4.面向对象设计七大原则 编程题S数最小H值 昨晚没睡好,脑子不清醒,痛失第1名 选择题 1. 关于工程效能,以下哪个选项可以帮助提高团队的开发效率? A、频繁地进行代码审查 B、使用自动化测试工具 C、使用版本控…...

P2015 二叉苹果树
P2015 二叉苹果树 类似于带限制背包问题,但不知道也能做。 n , q n,q n,q 范围小,大胆设 dp 状态。设 f u , i \large f_{u,i} fu,i 表示 u u u 子树内保留 i i i 根树枝的最大苹果数,可得状态转移方程 f u , i f u , j f v , i − …...

Linux 内核音频数据传递主要流程
Linux 用户空间应用程序通过声卡驱动程序(一般牵涉到多个设备驱动程序)和 Linux 内核 ALSA 框架导出的 PCM 设备文件,如 /dev/snd/pcmC0D0c 和 /dev/snd/pcmC0D0p 等,与 Linux 内核音频设备驱动程序和音频硬件进行数据传递。PCM 设…...

torch.device函数
torch.device 是 PyTorch 中用于表示计算设备(如CPU或GPU)的类。它允许你在代码中指定你希望在哪个设备上执行张量和模型操作,本文主要介绍了 torch.device 函数的用法和功能。 本文主要包含以下内容: 1.创建设备对象2.将张量和模…...
火车头采集器AI伪原创【php源码】
大家好,本文将围绕python作业提交什么文件展开说明,python123怎么提交作业是一个很多人都想弄明白的事情,想搞清楚python期末作业程序需要先了解以下几个事情。 火车头采集ai伪原创插件截图: I have a python project, whose fold…...

Python中常见的6种数据类型
数字(Numbers):数字类型用于表示数值,包括整数(int)和浮点数(float)。 字符串(Strings):字符串类型用于表示文本,由一系列字符组成。字…...
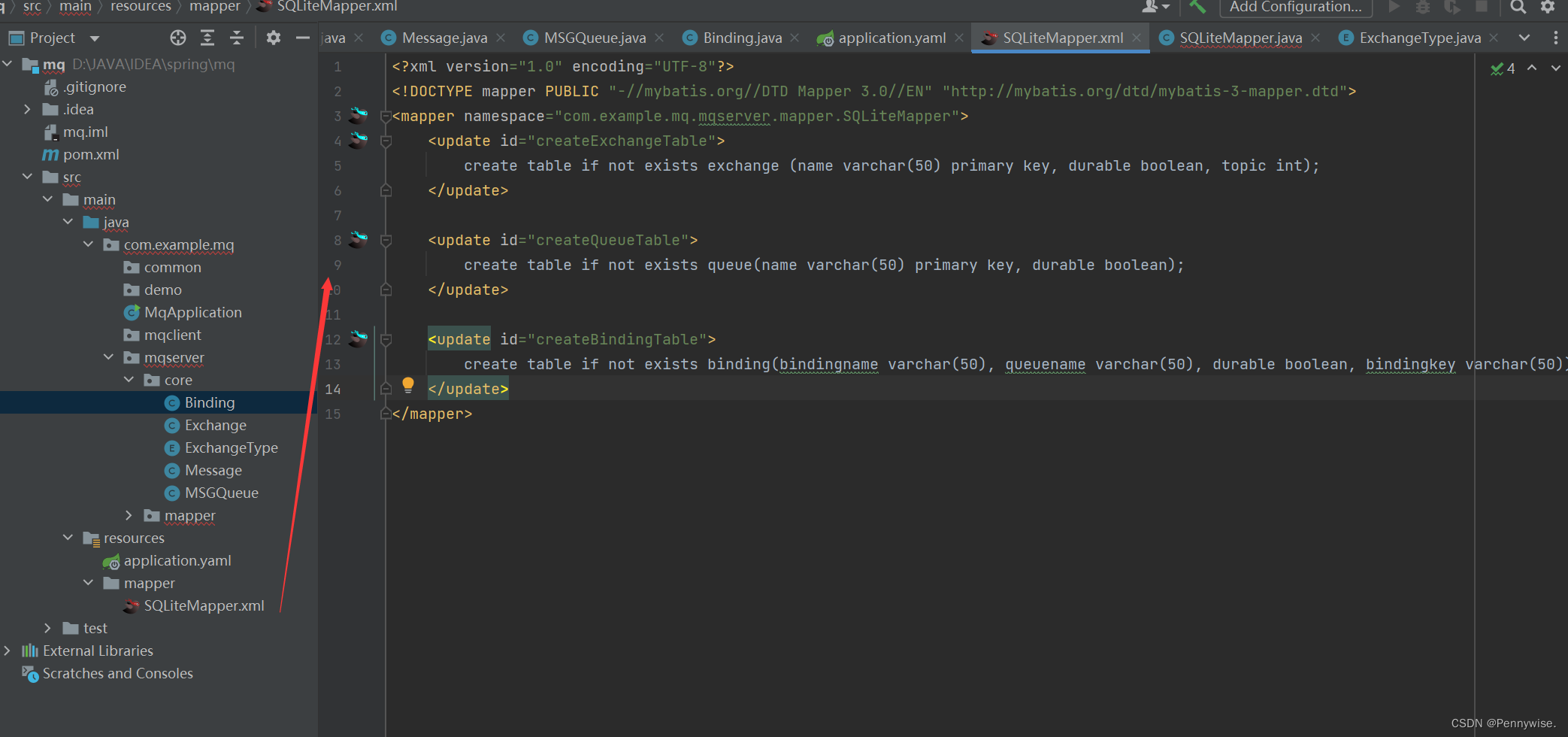
消息队列项目(2)
我们使用 SQLite 来进行对 Exchange, Queue, Binding 的硬盘保存 对 Message 就保存在硬盘的文本中 SQLite 封装 这里是在 application.yaml 中来引进对 SQLite 的封装 spring:datasource:url: jdbc:sqlite:./data/meta.dbusername:password:driver-class-name: org.sqlite.…...
解决MAC M1处理器运行Android protoc时出现的错误
Protobuf是Google开发的一种新的结构化数据存储格式,一般用于结构化数据的序列化,也就是我们常说的数据序列化。这个序列化协议非常轻量级和高效,并且是跨平台的。目前,它支持多种主流语言,比传统的XML、JSON等方法更具…...

C#使用SnsSharp实现鼠标键盘钩子,实现全局按键响应
gitee下载地址:https://gitee.com/linsns/snssharp 一、键盘事件,使用SnsKeyboardHook 按键事件共有3个: KeyDown(按键按下) KeyUp(按键松开) KeyPress(按键按下并松开) 以KeyDown事件为例,使用代码如下&…...

Zookeeper基础操作
搭建Zookeeper服务器 windows下部署 下载地址: https://mirrors.cloud.tencent.com/apache/zookeeper/zookeeper-3.7.1/ 修改配置文件 打开conf目录,将 zoo_sample.cfg复制一份,命名为 zoo.cfg打开 zoo.cfg,修改 dataDir路径,…...
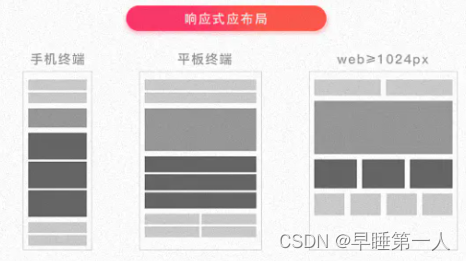
【CSS】说说响应式布局
目录 一、是什么 二、怎么实现 1、媒体查询 2、百分比 3、vw/vh 4、小结 三、总结 一、是什么 响应式设计简而言之,就是一个网站能够兼容多个终端——而不是为每个终端做一个特定的版本。 响应式网站常见特点: 同时适配PC 平板 手机等…...
数据结构 | 利用二叉堆实现优先级队列
目录 一、二叉堆的操作 二、二叉堆的实现 2.1 结构属性 2.2 堆的有序性 2.3 堆操作 队列有一个重要的变体,叫作优先级队列。和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的。优先级最高的元素在最前ÿ…...
)
5G随机接入第一步:用Matlab手把手仿真ZC序列的preamble检测(附完整代码)
5G随机接入第一步:用Matlab手把手仿真ZC序列的preamble检测(附完整代码) 在5G NR系统中,随机接入过程是终端设备与基站建立连接的关键第一步。而其中ZC序列作为preamble的核心组成部分,其特性直接决定了随机接入的性能…...

录音转文字在线版有哪些?这几款免费录音转文字在线工具怎么选?
很多人做录音转文字的时候默认用专业级的转录服务,其实像提词匠这样的轻量工具已经够用了。特别是如果你只是偶尔需要把会议录音、课堂笔记、视频素材转成文字,不必非要上手深度学习复杂的专业软件。下面我梳理了目前市面上主流的录音转文字在线版工具,既有微信小程序也有网页版…...

中兴光猫终极管理工具:快速开启工厂模式与永久Telnet指南
中兴光猫终极管理工具:快速开启工厂模式与永久Telnet指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu zteOnu是一款专为中兴光猫设备设计的专业管理工具,能够…...

胶片颗粒≠随机噪点,35mm风格出图翻车全解析,深度拆解ISO模拟、过期胶卷色偏与显影液残留建模逻辑
更多请点击: https://intelliparadigm.com 第一章:胶片颗粒≠随机噪点,35mm风格出图翻车全解析 胶片摄影的颗粒感(Grain)是银盐晶体在显影过程中形成的物理性、非均匀、结构化纹理,而数字图像中常见的“噪…...

WechatSogou微信公众号爬虫实战指南:高效获取公众号数据的Python解决方案
WechatSogou微信公众号爬虫实战指南:高效获取公众号数据的Python解决方案 【免费下载链接】WechatSogou 基于搜狗微信搜索的微信公众号爬虫接口 项目地址: https://gitcode.com/gh_mirrors/we/WechatSogou 在信息爆炸的时代,微信公众号已成为内容…...

JSON Lint for PHP:如何构建企业级JSON数据验证解决方案?
JSON Lint for PHP:如何构建企业级JSON数据验证解决方案? 【免费下载链接】jsonlint JSON Lint for PHP 项目地址: https://gitcode.com/gh_mirrors/jso/jsonlint 在现代Web开发和API设计中,JSON数据验证是确保系统稳定性的关键环节。…...

避开这些坑!RT-Thread+lwip网卡驱动开发中的5个常见误区与实战解法
RT-Thread与lwIP网卡驱动开发中的五大性能陷阱与实战突围 在嵌入式网络开发领域,RT-Thread与lwIP的组合已经成为许多开发者的首选方案。然而,这套看似成熟的网络协议栈背后,却隐藏着诸多性能陷阱。本文将揭示五个最常见的开发误区,…...

基于dpro-hyperliquid的Hyperliquid链上永续合约自动化交易开发指南
1. 项目概述与核心价值 最近在DeFi和链上交易领域,一个名为“dProLabs/dpro-hyperliquid”的项目引起了我的注意。简单来说,这是一个专门为Hyperliquid链上永续合约交易所设计的自动化交易工具包或策略框架。如果你是一名链上交易者,尤其是对…...

2026年,你的企业为什么还不会用AI发稿?技术人深度拆解Infoseek媒体库
最近GitHub上又一个开源项目火了,能自动生成并发布技术博客。这让我想到,在我们讨论AI取代程序员的同时,另一个领域的“自动化”早已跑在了前面——企业的媒体内容发布。很多技术团队还在手动找渠道、求小编,而一些市场部同事&…...

深度解析开源小红书采集工具:XHS-Downloader技术架构与实战应用指南
深度解析开源小红书采集工具:XHS-Downloader技术架构与实战应用指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、…...