K最近邻算法:简单高效的分类和回归方法(三)
文章目录
- 🍀引言
- 🍀训练集和测试集
- 🍀sklearn中封装好的train_test_split
- 🍀超参数
🍀引言
本节以KNN算法为主,简单介绍一下训练集和测试集、超参数
🍀训练集和测试集
训练集和测试集是机器学习和深度学习中常用的概念。在模型训练过程中,通常将数据集划分为训练集和测试集,用于训练和评估模型的性能。
训练集是用于模型训练的数据集合。模型通过对训练集中的样本进行学习和参数调整来提高自身的预测能力。训练集应该尽可能包含各种不同的样本,以使模型能够学习到数据集中的模式和规律,并能够适应新的数据。
测试集是用于评估模型性能的数据集合。模型训练完成后,使用测试集中的样本进行预测,并与真实标签进行对比,以评估模型的精度、准确度和其他性能指标。测试集应该与训练集相互独立,以确保对模型的泛化能力进行准确评估。
一般来说,训练集和测试集的划分比例是80:20或者70:30。有时候还会引入验证集,用于在训练过程中调整模型的超参数。训练集、验证集和测试集是机器学习中常用的数据集拆分方式,以确保模型的准确性和泛化能力。
接下来我们回顾一下KNN算法的简单原理,选取离待预测最近的k个点,再使用投票进行预测结果
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
from sklearn.datasets import load_iris # 因为我们并没有数据集,所以从库里面调出来一个
iris = load_iris()
X = iris.data
y = iris.target
knn_clf.fit(X,y)
knn_clf.predict()
那么我们如何评价KNN模型的好坏呢?
这里我们将数据集分为两部分,一部分为训练集,一部分为测试集,因为这里的训练集和测试集都是有y的,所以我们只需要将训练集进行训练,然后产生的模型应用到测试集,再将预测的y和原本的y进行对比,这样就可以了
接下来进行简易代码演示讲解
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
我们可以把y打印出来看看

这里我们不妨思考一下,如果训练集和测试集是8:2的话,测试集的y岂不是都是2了,那么还有啥子意义,所以我们需要将其打乱一下下,当然我们这里打乱的是index也就是下标,可不要自以为是的将y打乱了
import numpy as np
indexs = np.random.permutation(len(X))
导入必要的库后,我们将数据集下标进行打乱并保存于indexs中,接下来迎来重头戏分割数据集
test_ratio = 0.2
test_size = int(len(X) * test_ratio)
test_indexs = shuffle_indexs[:test_size] # 测试集
train_indexs = shuffle_indexs[test_size:] # 训练集
不信的小伙伴可以使用如下代码进行检验
test_indexs.shape
train_indexs.shape

接下来将打乱的下标进行分别赋值
X_train = X[train_indexs]
y_train = y[train_indexs]
X_test = X[test_indexs]
y_test = y[test_indexs]
分割好数据集后,我们就可以使用KNN算法进行预测了
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train,y_train)
y_predict = knn_clf.predict(X_test)
我们这里可以打印一下y_predict和y_test进行肉眼对比一下


最后一步就是将精度求出来
np.sum(np.array(y_predict == y_test,dtype='int'))/len(X_test)

🍀sklearn中封装好的train_test_split
上面我们只是简单演示了一下,接下来我们使用官方的train_test_split
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y) # 注意这里返回四个结果
这里你可以试着看一眼,分割的比例与之前手动分割的比例大不相同
最后按部就班来就行
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train,y_train)
knn_clf.predict(X_test)
knn_clf.score(X_test,y_test)

🍀超参数
什么是超参数,可以点击链接查看
在pycharm中我们可以查看一些参数

接下来通过简单的演示来介绍一下
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
knn_clf = KNeighborsClassifier(weights='distance')
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris.data
y = iris.target
X_train,X_test,y_train,y_test = train_test_split(X,y)
上面是老熟人了就不一一赘述了,但是注意这里面有个超参数(weights),这个参数有两种,一个是distance一个是uniform,前者和距离有关联,后者无关
首先测试一下n_neighbors这个参数代表的就行之前的那个k,邻近点的个数
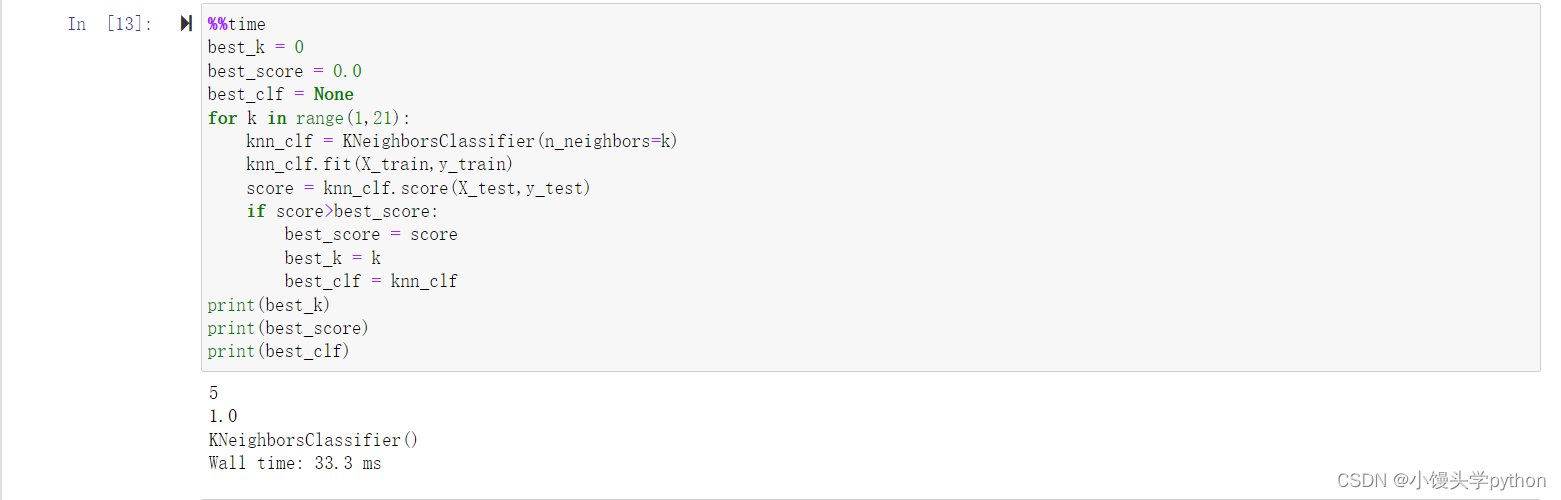
%%time
best_k = 0
best_score = 0.0
best_clf = None
for k in range(1,21):knn_clf = KNeighborsClassifier(n_neighbors=k)knn_clf.fit(X_train,y_train)score = knn_clf.score(X_test,y_test)if score>best_score:best_score = scorebest_k = kbest_clf = knn_clf
print(best_k)
print(best_score)
print(best_clf)
测试完参数n_neighbors,我们再来试试weights
%%time
best_k = 0
best_score = 0.0
best_clf = None
best_method = None
for weight in ['uniform','distance']:for k in range(1,21):knn_clf = KNeighborsClassifier(n_neighbors=k,weights=weight)knn_clf.fit(X_train,y_train)score = knn_clf.score(X_test,y_test)if score>best_score:best_score = scorebest_k = kbest_clf = knn_clfbest_method = weight
print(best_k)
print(best_score)
print(best_clf)
print(best_method)

最后我们测试一下参数p
%%time
best_k = 0
best_score = 0.0
best_clf = None
best_p = None
for p in range(1,6):for k in range(1,21):knn_clf = KNeighborsClassifier(n_neighbors=k,weights='distance',p=p)knn_clf.fit(X_train,y_train)score = knn_clf.score(X_test,y_test)if score>best_score:best_score = scorebest_k = kbest_clf = knn_clfbest_p = pprint(best_k)
print(best_score)
print(best_clf)
print(best_p)
或许大家不知道这个参数p的含义,下面我根据几个公式带大家简单了解一下
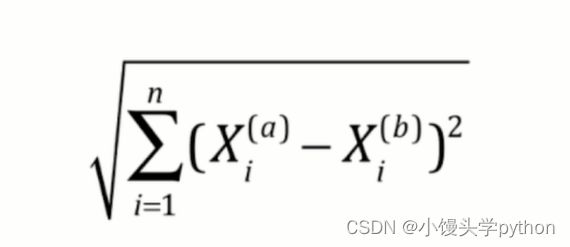
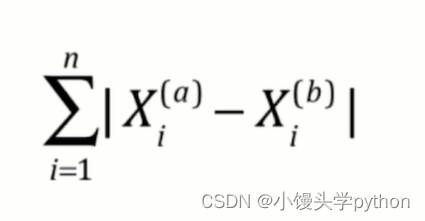
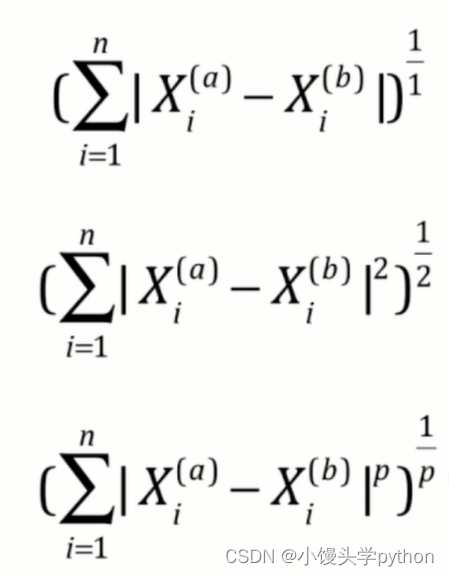
三张图分别代表欧拉距离、曼哈顿距离、明科夫斯基距离,细心的小伙伴就可以发现了,p=1位曼哈顿距离,p=2位欧拉距离,这里不做详细的说明,感兴趣的小伙伴可以翻阅相关数学书籍

挑战与创造都是很痛苦的,但是很充实。
相关文章:
K最近邻算法:简单高效的分类和回归方法(三)
文章目录 🍀引言🍀训练集和测试集🍀sklearn中封装好的train_test_split🍀超参数 🍀引言 本节以KNN算法为主,简单介绍一下训练集和测试集、超参数 🍀训练集和测试集 训练集和测试集是机器学习和深…...

【数据分析专栏之Python篇】五、pandas数据结构之Series
前言 大家好!本期跟大家分享的知识是 Pandas 数据结构—Series。 一、Series的创建 Series 是一种类似于一维数组的对象,由下面两部分组成: values:一组数据,ndarray 类型index:数据索引 顾名思义&…...
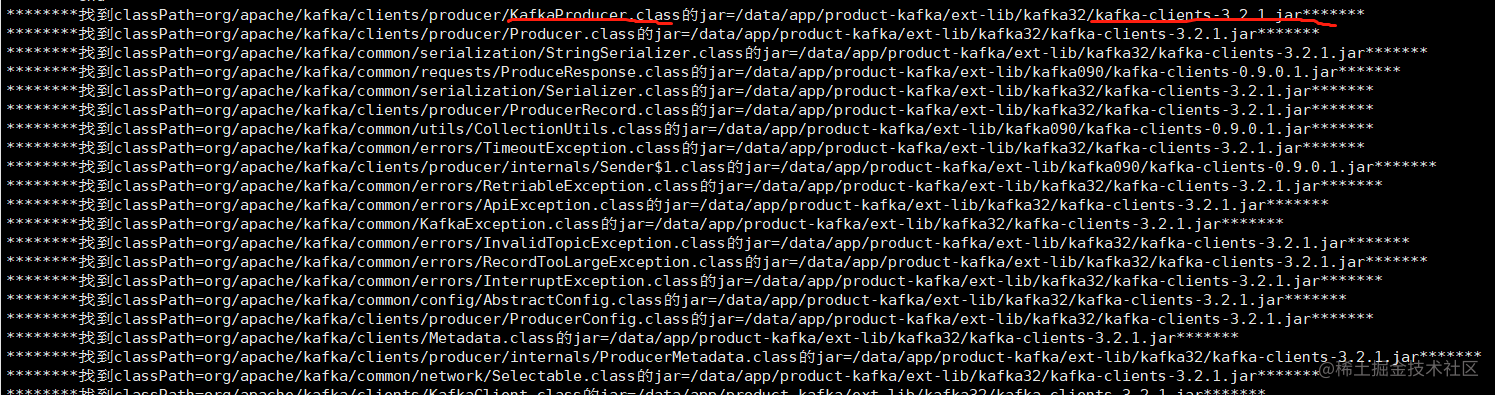
中间件多版本冲突的4种解决方案和我们的选择
背景 在小小的公司里面,挖呀挖呀挖。最近又挖到坑里去了。一个稳定运行多年的应用,需要在里面支持多个版本的中间件客户端;而多个版本的客户端在一个应用里运行时会有同名类冲突的矛盾。在经过询问chatGPT,百度,googl…...

对 async/await 的理解
async/await 的理解 async/await 其实是 Generator 的语法糖,它能实现的效果都能用then 链来实现,它是为优化 then 链而开发出来的。从字面上来看,async 是“异步”的简写,await 则为等待,所以很好理解async用于申明一…...

Vue 整合 Element UI 、路由嵌套、参数传递、重定向、404和路由钩子(五)
一、整合 Element UI 1.1 工程初始化 使用管理员的模式进入 cmd 的命令行模式,创建一个名为 hello-vue 的工程,命令为: # 1、目录切换 cd F:\idea_home\vue# 2、项目的初始化,记得一路的 no vue init webpack hello-vue 1.2 安装…...

修改 Ubuntu 系统的时区
修改 Ubuntu 系统的时区 如果 Ubuntu 系统的时区设置不正确,您可以按照以下步骤进行调整: 1. 查看当前的时区设置,可以使用以下命令: timedatectl 这将显示当前系统的日期、时间和时区信息。 2. 如果时区设置不正…...

如何离线安装ModHeader - Modify HTTP headers Chrome插件?
如何离线安装ModHeader - Modify HTTP headers Chrome插件? 1.1 前言1.2 打开Chrome浏览器的开发者模式1.3 下载并解压打包好的插件1.4 解压下载好的压缩包1.5 加载插件1.6 如何使用插件? 1.1 前言 ModHeader 是一个非常好用的Chrome浏览器插件,可以用…...
在Linux中安装MySQL
在Linux中安装MySQL 检测当前系统中是否安装MySQL数据库 命令作用rpm -qa查询当前系统中安装的所有软件rpm -qa|grep mysql查询当前系统中安装的名称带mysql的软件rpm -qa | grep mariadb查询当前系统中安装的名称带mariadb的软件 RPM ( Red-Hat Package Manager )RPM软件包管理…...

python --windows获取启动文件夹路径/获取当前用户名/添加自启动文件
如何使用Python获取计算机用户名 一、Python自带的getpass模块可以用于获取用户输入的密码,但是它同样可以用来获取计算机用户名。 import getpassuser getpass.getuser() print("计算机用户名为:", user)二、使用os模块获取用户名 Python的…...

微信云托管(本地调试)⑥:nginx、vue刷新404问题
一、nginx默认路径 1.1、默认配置文件路径:/etc/nginx/nginx.conf 1.2、默认资源路径:/usr/share/nginx/html/index.html 二、修改nginx.conf配置 (注意配置中的:include /etc/nginx/conf.d/*.conf; 里面包了一个server配置文件…...

数据结构 二叉树(一篇基本掌握)
绪论 雄关漫道真如铁,而今迈步从头越。 本章将开始学习二叉树(全文共一万两千字),二叉树相较于前面的数据结构来说难度会有许多的攀升,但只要跟着本篇博客深入的学习也可以基本的掌握基础二叉树。 话不多说安全带系好&…...
-南丁格尔玫瑰图(二))
可视化绘图技巧100篇高级篇(四)-南丁格尔玫瑰图(二)
目录 前言 适用场景 不适用场景 堆积式南丁格尔玫瑰图( Nightingale Rose Diagram)...

Stable Diffusion - Candy Land (糖果世界) LoRA 提示词配置与效果展示
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/132145248 糖果世界 (Candy Land) 是一个充满甜蜜和奇幻的地方,由各种各样的糖果和巧克力构成。在糖果世界,可以看到&…...

ES6学习-module语法
Module语法 CommonJS模块 let { readfile } require(fs) # 等同于 let _fs require(fs) let readfile _fs.readfile //这种加载称为“运行时加载”ES6模块 import { stat, exists, readFile } from fs;这种加载称为“编译时加载”或者静态加载 静态加载带来的各种好处 …...

Flutter 实现按位置大小比例布局的控件
文章目录 前言一、如何实现?1、数值转成分数2、RowFlexible布局横向3、ColumnFlexible布局纵向 二、完整代码三、使用示例1、基本用法2、四分屏3、六分屏4、八分屏5、九分屏6、414分屏 总结 前言 做视频监控项目时需要需要展示多分屏,比如2x2、3x3、414…...

ES6 - 对象新增的一些常用方法
文章目录 1,Object.is()2,Object.asign()3,Object.getOwnPropertyDescriptors()4,Object.setPrototypeOf()和getPrototypeOf()5,Object.keys()、values() 和 entries()6,Object.fromEntries()7,…...

半导体存储电路
存储电路 存储单元:只能存储一位数据 寄存器:存储一组数据 存储单元 静态存储单元:包含锁存器和触发器,只要不断电,静态存储单元的状态会一直保持下去。 动态存储单元:利用电容的电荷存储效应来存储数据。…...

web前端之CSS操作
文章目录 一、CSS操作1.1 html元素的style属性1.2 元素节点的style属性1.3 cssText属性 二、事件2.1 事件处理程序2.1.1 html事件2.1.2 DOM0事件(适合单个事件)2.1.3 DOM2事件(适合多个事件) 2.2 事件之鼠标事件2.3 事件之Event事…...
Python SQLAlchemy ( ORM )
From Python中强大的通用ORM框架:SQLAlchemy:https://zhuanlan.zhihu.com/p/444930067Python ORM之SQLAlchemy全面指南:https://zhuanlan.zhihu.com/p/387078089 SQLAlchemy 文档:https://www.sqlalchemy.org/ SQLAlchemy入门和…...

鉴源实验室丨汽车网络安全运营
作者 | 苏少博 上海控安可信软件创新研究院汽车网络安全组 来源 | 鉴源实验室 社群 | 添加微信号“TICPShanghai”加入“上海控安51fusa安全社区” 01 概 述 1.1 背景 随着车辆技术的不断进步和智能化水平的提升,车辆行业正经历着快速的变革和技术进步。智能化…...

如何快速实现 CoffeeScript 实时编译和预览:vim-coffee-script 终极指南 [特殊字符]
如何快速实现 CoffeeScript 实时编译和预览:vim-coffee-script 终极指南 🚀 【免费下载链接】vim-coffee-script CoffeeScript support for vim 项目地址: https://gitcode.com/gh_mirrors/vi/vim-coffee-script 对于 CoffeeScript 开发者来说&am…...

WT32-S3-DK开发板全解析:从硬件设计到物联网项目实战
1. 项目概述:一块“小而全”的物联网开发板最近在捣鼓一个智能家居的传感器节点项目,需要一块性能足够、接口丰富、最好还带屏幕的开发板。市面上ESP32-S3的方案很多,但要么是核心板,需要自己配底板和屏幕,要么就是功能…...

全志T113-i平台UB37三模无线模组驱动移植与调试实战
1. 项目概述:当国产工业芯遇上新一代无线技术最近在做一个挺有意思的项目,客户想在一块国产的工业级核心板上,集成最新的星闪(NearLink)无线通信功能。核心板用的是全志的T113-i,无线模组是支持Wi-Fi 6、蓝…...

GOM三维扫描在GDT分析中的应用:几何公差评价为何越来越依赖全场数据
随着工业产品结构复杂度持续提高,传统基于尺寸链的质量控制方式正在逐步向几何公差控制体系演进。尤其在汽车制造、精密模具、航空零部件及新能源结构件等领域,产品质量评价已不仅取决于尺寸是否符合要求,更关注零件在真实装配条件下的几何状…...

【习题05】求n的阶乘
题目: 分别利用递归和非递归的方法求n的阶乘 1、题目分析 规定:0的阶乘为1。 非递归: 我们先列举几个求阶乘的案例,从中找寻规律。 0! 11! 12! 1 * 23! 1 * 2 * 3 从上述几个例子可…...

3分钟完成Excel批量查询:智能多文件搜索工具完整指南
3分钟完成Excel批量查询:智能多文件搜索工具完整指南 【免费下载链接】QueryExcel 多Excel文件内容查询工具。 项目地址: https://gitcode.com/gh_mirrors/qu/QueryExcel 还在为处理海量Excel文件而烦恼吗?面对成百上千个表格文件,传统…...

24V直流电源的大地与正极连接导致的问题
现象: #1, LED控制板的螺丝把24V与机械壳体连接了,壳体放到金属台子上了,电脑的直流地与大地直连。导致烧毁烧糊功率计&电脑; #2, 直流电源的24V与金属壳体短接,其他电源负极与金属台子直接…...

豆包生成的流程图怎么导出
标题:不只是聊天:深度解析豆包——从AI助手到数字生活的“协作者” 在当前大模型应用百花齐放的时代,豆包,作为字节跳动推出的AI对话助手,已悄然成为许多用户日常工作与生活中的“数字伙伴”。它不仅仅是一个能回答问题…...
进程篇·三:深度硬核!全面起底 Linux 进程状态变化与内核链表动态解绑)
Re: Linux系统篇(十八)进程篇·三:深度硬核!全面起底 Linux 进程状态变化与内核链表动态解绑
◆ 博主名称: 晓此方-CSDN博客 大家好,欢迎来到晓此方的博客。 ⭐️Linux系列个人专栏: 【主题曲】Linux ⭐️此方的GitHub: github_此方 ⭐️Re系列专栏:我们思考 (Rethink) 我们重建 (Rebuild) 我们记录 (Record…...

初次使用Taotoken从注册到发出第一个API请求的全流程耗时记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken从注册到发出第一个API请求的全流程耗时记录 1. 流程概览与预期 对于初次接触大模型聚合平台的开发者而言&#…...