【神经网络手写数字识别-最全源码(pytorch)】
Torch安装的方法

学习方法
- 1.边用边学,torch只是一个工具,真正用,查的过程才是学习的过程
- 2.直接就上案例就行,先来跑,遇到什么来解决什么
Mnist分类任务:
-
网络基本构建与训练方法,常用函数解析
-
torch.nn.functional模块
-
nn.Module模块
读取Mnist数据集
- 会自动进行下载
# 查看自己的torch的版本
import torch
print(torch.__version__)
%matplotlib inline
# 前两步,不用管是在网上下载数据,后续的我们都是在本地的数据进行操作
from pathlib import Path
import requestsDATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"PATH.mkdir(parents=True, exist_ok=True)URL = "http://deeplearning.net/data/mnist/"
FILENAME = "mnist.pkl.gz"if not (PATH / FILENAME).exists():content = requests.get(URL + FILENAME).content(PATH / FILENAME).open("wb").write(content)
import pickle
import gzipwith gzip.open((PATH / FILENAME).as_posix(), "rb") as f:((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
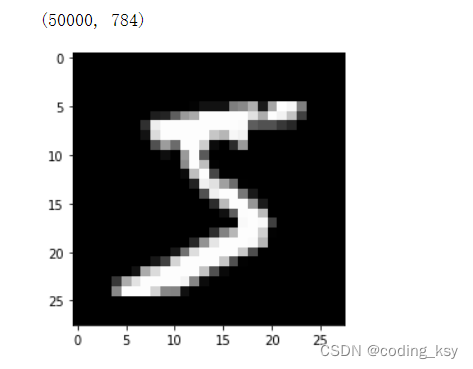
784是mnist数据集每个样本的像素点个数
from matplotlib import pyplot
import numpy as nppyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
print(x_train.shape)
全连接神经网络的结构
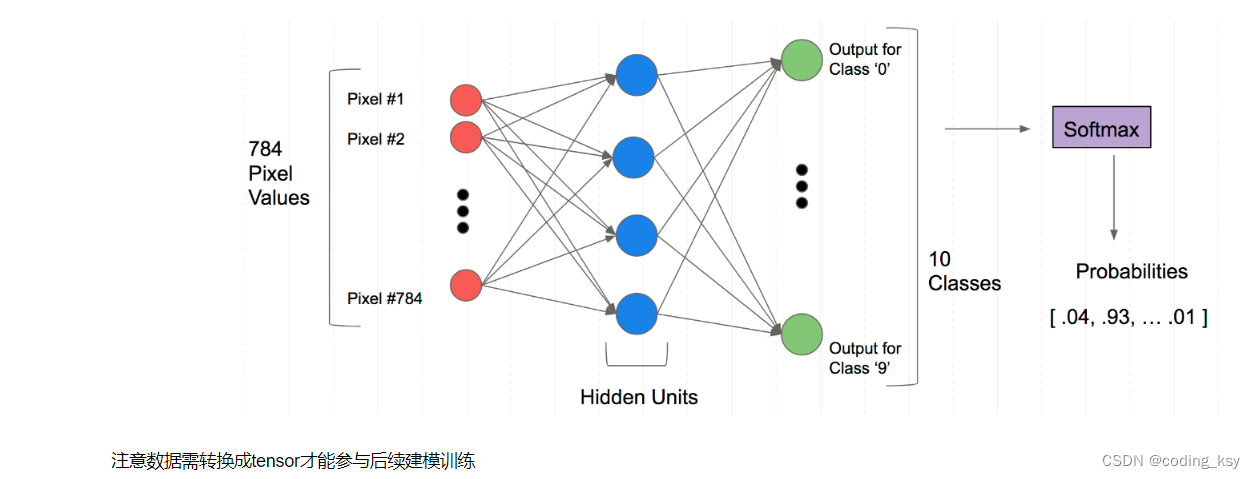 注意数据需转换成tensor才能参与后续建模训练
注意数据需转换成tensor才能参与后续建模训练
import torchx_train, y_train, x_valid, y_valid = map(torch.tensor, (x_train, y_train, x_valid, y_valid)
)
n, c = x_train.shape
x_train, x_train.shape, y_train.min(), y_train.max()
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())
torch.nn.functional 很多层和函数在这里都会见到
torch.nn.functional中有很多功能,后续会常用的。那什么时候使用nn.Module,什么时候使用nn.functional呢?一般情况下,如果模型有可学习的参数,最好用nn.Module,其他情况nn.functional相对更简单一些
import torch.nn.functional as Floss_func = F.cross_entropydef model(xb):return xb.mm(weights) + bias
bs = 64
xb = x_train[0:bs] # a mini-batch from x
yb = y_train[0:bs]
weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)
bs = 64
bias = torch.zeros(10, requires_grad=True)print(loss_func(model(xb), yb))
创建一个model来更简化代码
- 必须继承nn.Module且在其构造函数中需调用nn.Module的构造函数
- 无需写反向传播函数,nn.Module能够利用autograd自动实现反向传播
- Module中的可学习参数可以通过named_parameters()或者parameters()返回迭代器
from torch import nnclass Mnist_NN(nn.Module):# 构造函数def __init__(self):super().__init__()self.hidden1 = nn.Linear(784, 128)self.hidden2 = nn.Linear(128, 256)self.out = nn.Linear(256, 10)self.dropout = nn.Dropout(0.5)#前向传播自己定义,反向传播是自动进行的def forward(self, x):x = F.relu(self.hidden1(x))x = self.dropout(x)x = F.relu(self.hidden2(x))x = self.dropout(x)#x = F.relu(self.hidden3(x))x = self.out(x)return x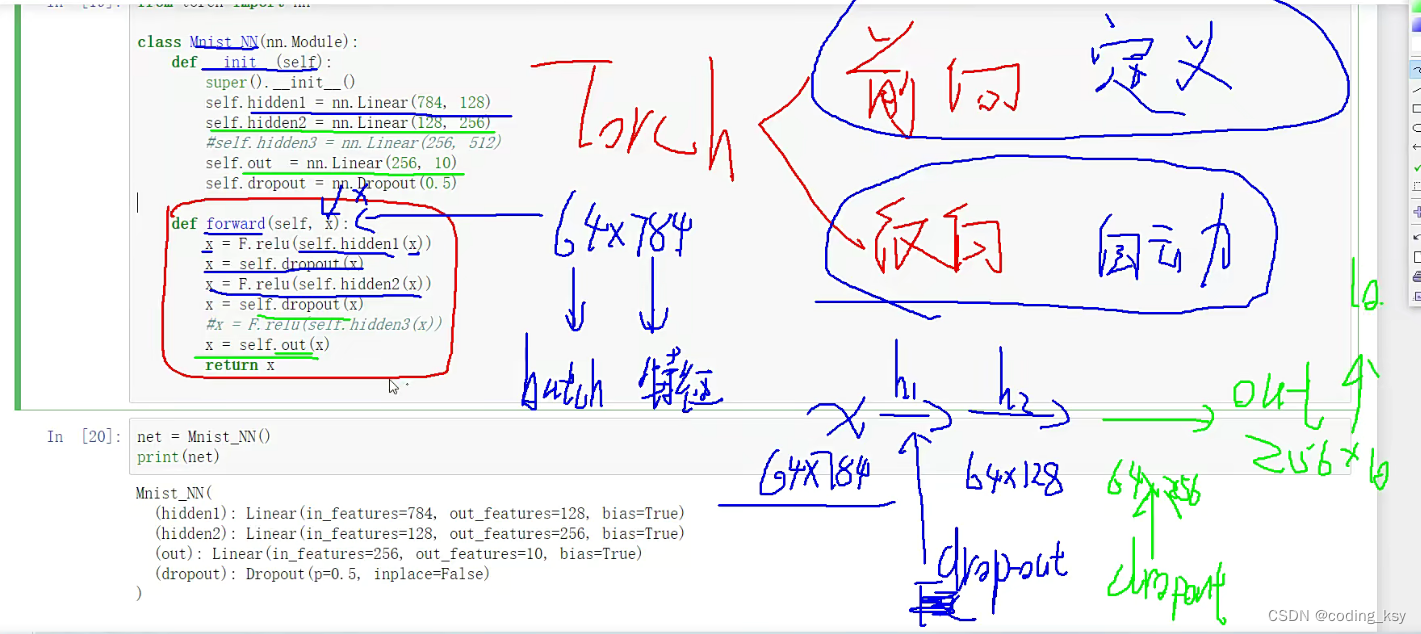
net = Mnist_NN()
print(net)
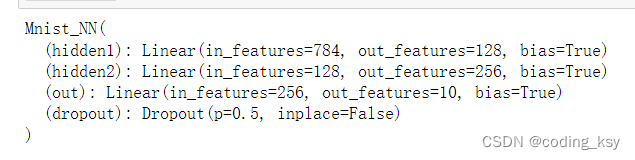
可以打印我们定义好名字里的权重和偏置项
for name,parameter in net.named_parameters():print(name, parameter,parameter.size())
使用TensorDataset和DataLoader来简化
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoadertrain_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
def get_data(train_ds, valid_ds, bs):return (DataLoader(train_ds, batch_size=bs, shuffle=True),DataLoader(valid_ds, batch_size=bs * 2),)
- 一般在训练模型时加上model.train(),这样会正常使用Batch Normalization和 Dropout
- 测试的时候一般选择model.eval(),这样就不会使用Batch Normalization和 Dropout
import numpy as npdef fit(steps, model, loss_func, opt, train_dl, valid_dl):for step in range(steps):model.train() # 训练的时候需要更新权重参数for xb, yb in train_dl:loss_batch(model, loss_func, xb, yb, opt)model.eval() # 验证的时候不需要更新权重参数with torch.no_grad():losses, nums = zip(*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl])val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)print('当前step:'+str(step), '验证集损失:'+str(val_loss))
zip的用法
a = [1,2,3]
b = [4,5,6]
zipped = zip(a,b)
print(list(zipped))
a2,b2 = zip(*zip(a,b))
print(a2)
print(b2)
from torch import optim
def get_model():model = Mnist_NN()return model, optim.SGD(model.parameters(), lr=0.001)
def loss_batch(model, loss_func, xb, yb, opt=None):loss = loss_func(model(xb), yb)if opt is not None:loss.backward()opt.step()opt.zero_grad()return loss.item(), len(xb)
三行搞定!
train_dl,valid_dl = get_data(train_ds, valid_ds, bs)
model, opt = get_model()
fit(100, model, loss_func, opt, train_dl, valid_dl)

correct = 0
total = 0
for xb,yb in valid_dl:outputs = model(xb)_,predicted = torch.max(outputs.data,1)total += yb.size(0)correct += (predicted == yb).sum().item()
print(f"Accuracy of the network the 10000 test imgaes {100*correct/total}")
】
Torch安装的方法 学习方法 1.边用边学,torch只是一个工具,真正用,查的过程才是学习的过程2.直接就上案例就行,先来跑,遇到什么来解决什么 Mnist分类任务: 网络基本构建与训练方法,常用函数解析…...

React、Vue和Angular的优缺点
React React 是一个用于构建用户界面的 JAVASCRIPT 库。React 主要用于构建 UI,很多人认为 React 是 MVC 中的 V(视图)。React 起源于 Facebook 的内部项目,用来架设 Instagram 的网站,并于 2013 年 5 月开源。React …...
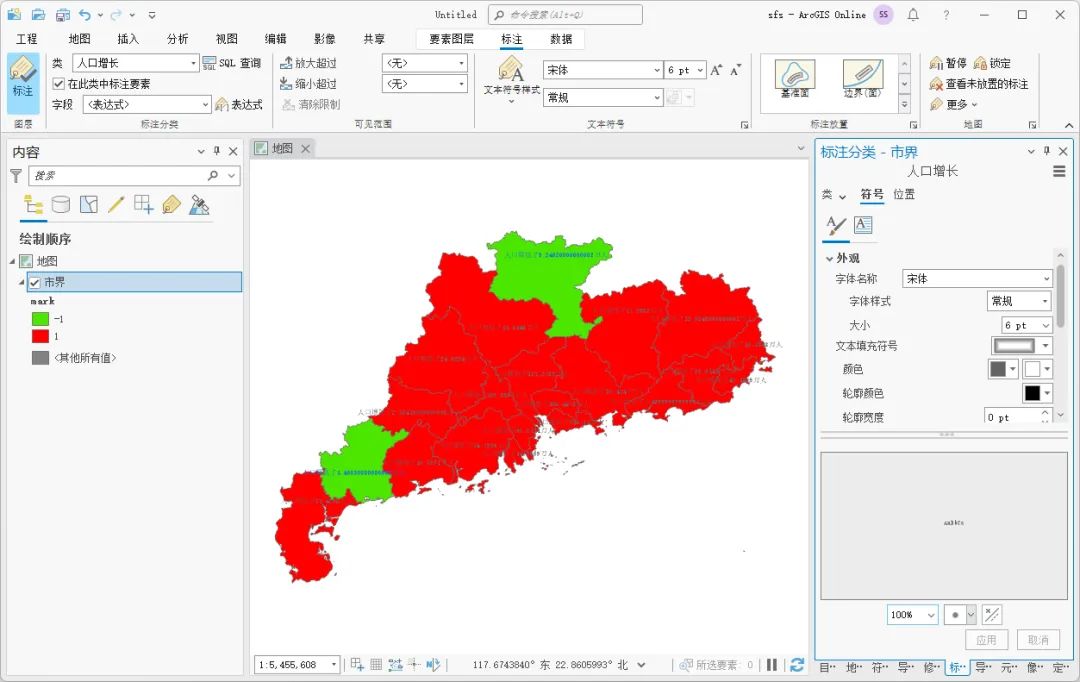
ArcGIS Pro根据不同条件显示不同标注
在某些情况下,我们需要根据不同的条件在地图上进行标注,比如我们想要在地图上显示广东省人口从2005年到2010年的变化情况,可以使用ArcGIS Pro的标注类功能实现,这里为大家介绍一下制作方法,希望能对你有所帮助。 标注分…...

DynamicsCRM专栏导览
不知不觉,专栏已经有5个订阅了。很高兴,自己的付出有了回报。很感谢大家的信任。 大家的订阅给了我很好的正反馈,也让我有了更强的动力,更大的责任感,去把这个专栏做好。 于是就有了这篇导览。这篇导览是我根据过往的开发经验总结出来的一个学习的框架。有些部分可能还没…...
Vue自定义指令使用
本篇文章讲述使用Vue自定义指令,并在项目中完成相应功能。 在平常Vue脚手架项目中,使用到 自定义指令较少,一般都是使用的自带指令,比如 v-show 、v-if 、 v-for 、 v-bind 之类的。这些已经能够满足大多数项目使用。更多的可能也…...

python爬虫之scrapy框架介绍
一、Scrapy框架简介 Scrapy 是一个开源的 Python 库和框架,用于从网站上提取数据。它为自从网站爬取数据而设计,也可以用于数据挖掘和信息处理。Scrapy 可以从互联网上自动爬取数据,并将其存储在本地或在 Internet 上进行处理。Scrapy 的目标…...

winform中嵌入cefsharp, 并使用selenium控制
正常说, 需要安装的包 下面是所有的包 全部代码 using OpenQA.Selenium.Chrome; using OpenQA.Selenium; using System; using System.Windows.Forms; using CefSharp.WinForms; using CefSharp;namespace WindowsFormsApp2 {public partial class Form1 : Form{//…...
)
【leetcode】349. 两个数组的交集(easy)
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。 思路: 先遍历nums1将其元素不重复地添加到哈希表a中;建立哈希表dup用于存储b和a重复的元素;遍历nums2…...

leetcode 2616. 最小化数对的最大差值
在数组nums中找到p个数对,使差值绝对值的和最小。 思路: 最小差值应该是数值相近的一对数之间产生,让数值相近的数字尽量靠在一起方便计算,所以需要排序。 这里不去直接考虑一对对的数字,而是直接考虑差值的取值。 …...

npm install 安装慢的问题处理
原因 npm install 默认使用的安装镜像时国外的镜像,国内使用会受到网络的限制。 解决方案 更换网络更换npm的安装镜像为国内,比如: npm config set registry https://registry.npm.taobao.org...
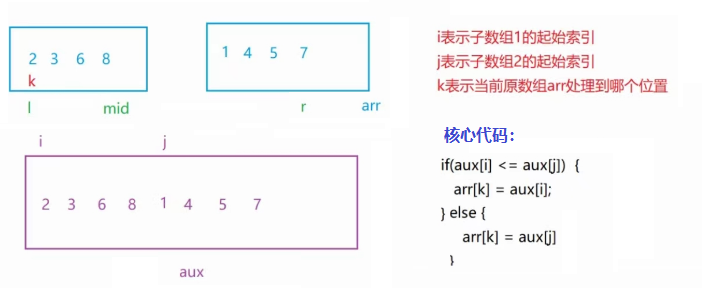
【JAVA】七大排序算法(图解)
稳定性: 待排序的序列中若存在值相同的元素,经过排序之后,相等元素的先后顺序不发生改变,称为排序的稳定性。 思维导图: (排序名称后面蓝色字体为时间复杂度和稳定性) 1.直接插入排序 核心思…...
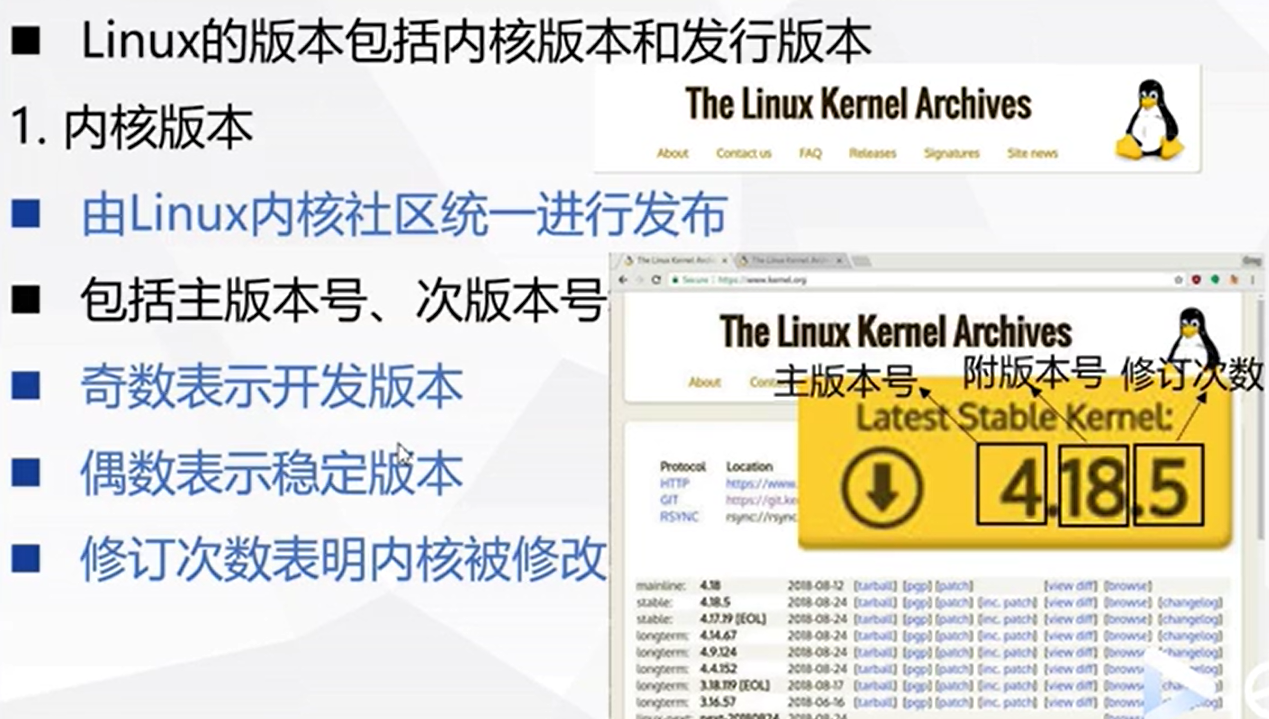
UNIX 系统概要
UNIX 家族UNIX 家谱家族后起之秀 LinuxUNIX vs LinuxUNIX/Linux 应用领域 UNIX 操作系统诞生与发展UNIX 操作系统概要内核常驻模块shell虚拟计算机特性 其他操作系统 LinuxRichard StallmanGNU 项目FSF 组织GPL 协议Linus Torvalds UNIX 家族 有人说,这个世界上只有…...
Unity 基础函数
Mathf: //1.π-PI print(Mathf.PI); //2.取绝对值-Abs print(Mathf.Abs(-10)); print(Mathf.Abs(-20)); print(Mathf.Abs(1)); //3.向上取整-Ce il To In t float f 1.3f; int i (int)f; …...
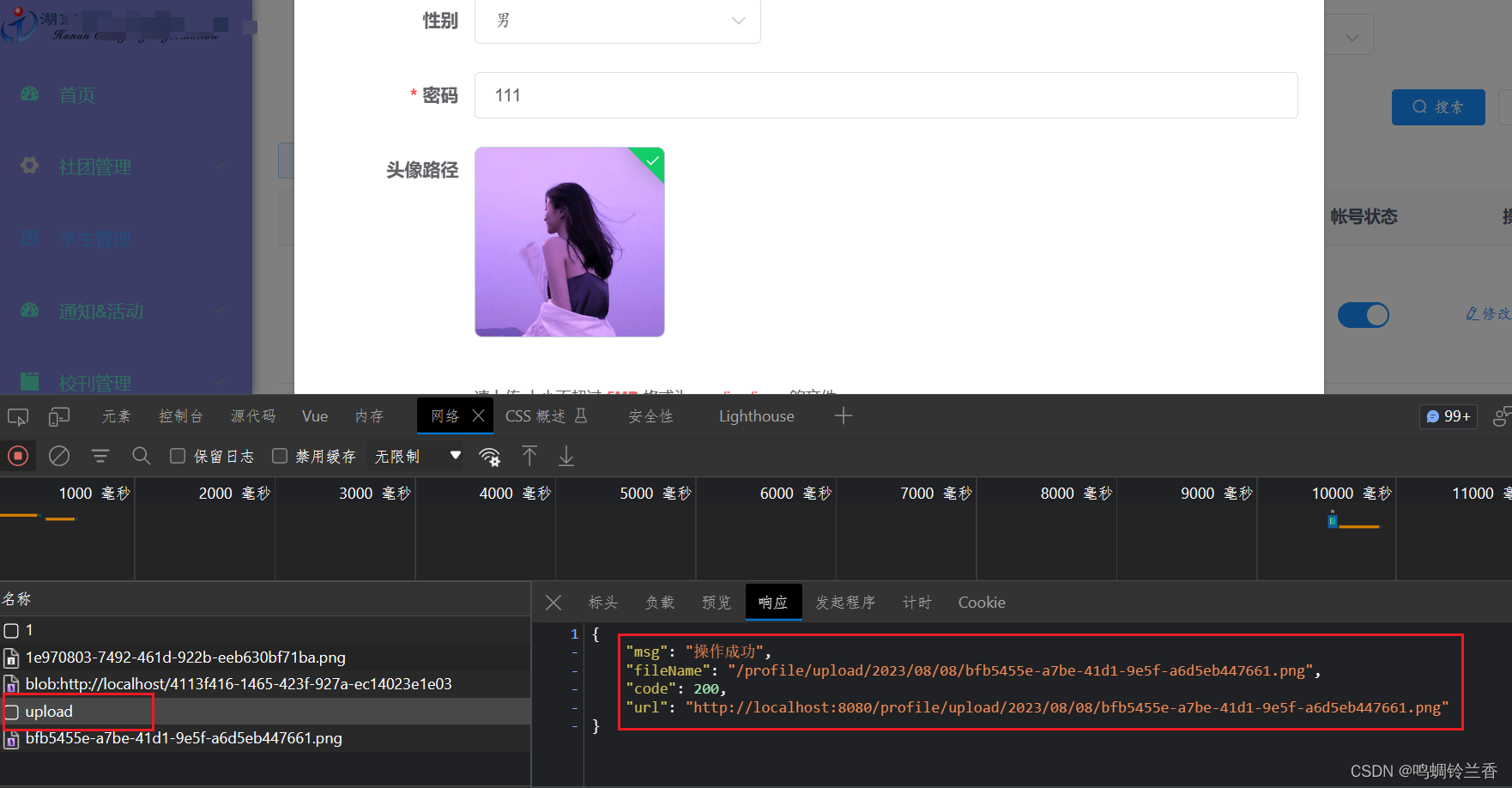
【学习】若依源码(前后端分离版)之 “ 上传图片功能实现”
大型纪录片:学习若依源码(前后端分离版)之 “ 上传图片功能实现” 前言前端部分后端部分结语 前言 图片上传也基本是一个项目的必备功能了,所以今天和大家分享一下我最近在使用若依前后端分离版本时,如何实现图片上传…...
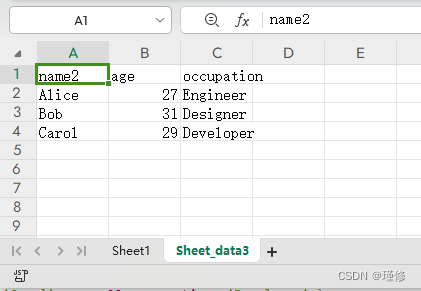
vue3 excel 导出功能
1.安装 xlsx 库 npm install xlsx2.创建导出函数 src/utils/excelUtils.js import * as XLSX from xlsx;const exportToExcel (fileName, datas, sheetNames) > {// 创建工作簿const wb XLSX.utils.book_new()for (let i 0; i < datas.length; i) {let data datas…...

python 相关框架事务开启方式
前言 对于框架而言,各式API接口少不了伴随着事务的场景,下面就列举常用框架的事务开启方法 一、Django import traceback from django.db import transaction from django.contrib.auth.models import User try:with transaction.atomic(): # 在with…...

vue使用ElementUI
1.安装 npm i element-ui -S 2.引入 2.1完整引入 import Vue from vue; import ElementUI from element-ui; import element-ui/lib/theme-chalk/index.css; import App from ./App.vue;Vue.use(ElementUI); 2.2按需引入 说明:为了输入时候有提示,建…...

Python做一个绘图系统3:从文本文件导入数据并绘图
文章目录 导入数据文件对话框修改绘图逻辑源代码 Python绘图系统系列:将matplotlib嵌入到tkinter 简单的绘图系统 导入数据 单纯从作图的角度来说,更多情况是已经有了一组数据,然后需要将其绘制。这组数据可能是txt格式的,也可能…...

flutter开发实战-获取Widget的大小及位置
flutter开发实战-获取Widget的大小及位置 最近开发过程中需要获取Widget的大小及位置,这时候就需要使用到了GlobalKey了和WidgetsBinding.instance.addPostFrameCallback了 一、addPostFrameCallback 该函数的作用: flutter中的界面组件Widget每一帧…...

软件测试工程师面试如何描述自动化测试是怎么实现的?
软件测试工程师面试的时候,但凡简历中有透露一点点自己会自动化测试的技能点的描述,都会被面试官问,那你结合你的测试项目说说自动化测试是怎么实现的?一到这里,很多网友,包括我的学生,也都一脸…...

2026年4月OpenClaw如何集成?云端4分钟保姆级方法+大模型APIKey、Skill集成
OpenClaw是什么?OpenClaw能干什么?OpenClaw怎么部署使用?本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程,包含环境配置、服务启动、…...

2025物联网通信毕业设计:聚焦LoRa与ZigBee的智慧农业创新应用
1. 为什么选择LoRa与ZigBee做智慧农业? 最近几年帮学生指导毕业设计时,发现越来越多的同学开始关注智慧农业这个方向。说实话,这个选题确实很值得做——既能结合当下热门的物联网技术,又能解决实际农业生产中的痛点。在众多无线通…...

三、Skills—— 模型能力的模块化专家技能,实现专业能力复用与扩展
一、Claude Skills 介绍1. 核心定义Claude Skills 是 Anthropic 为 Claude 推出的「模块化、可复用、可落地的能力扩展工具」,本质是用「YAML配置Markdown流程可选脚本」,将复杂操作、系统调用、业务流程封装成“能力包”,导入Claude后&#…...

华为ensp和华三模拟器HCL-cloud安装启动软件问题
先将账号提权到管理员使非内置管理员的管理员生效华三设备启动设备关闭hyber-V通过命令关闭先进入bios,关闭系统的安全启动(Secure Boot)设置然后输入下面的命令# 禁用 Hyper-V 全量功能Disable-WindowsOptionalFeature -Online -FeatureName…...
)
robust互斥锁实现原理(futex内核态源码分析)
由于OOM,avm一直被内核kill -9杀掉。最终会出现avm重启报错 bos_em_service: Fatal glibc error: pthread_mutex_lock.c:450 (__pthread_mutex_lock_full): assertion failed: e ! ESRCH || !robust。这个锁是共享内存上的一个robust互斥锁。 而且该BUG报了好几例。…...
)
算法7-中级提升班2(实战篇)
问题1:机器物品平均问题 这道题使用贪心算法。 计算出数组位置的平均值。对于每一个位置,可以分别计算出左部分和右部分缺少或多出的数量,不同情况需要移动的最大次数如上图所示。 例如对于数组[100,0,0,0],对于位置0的100,右部分的值为-75,需要往右侧移动75件物品;对于…...

2024全新3种突破方案解决付费墙限制:Bypass Paywalls Clean全方位应用指南
2024全新3种突破方案解决付费墙限制:Bypass Paywalls Clean全方位应用指南 在信息爆炸的数字时代,付费墙如同一道道无形的关卡,阻挡着我们获取有价值的内容。无论是研究人员需要查阅最新学术论文,还是普通读者想要了解深度新闻报道…...

Java 19+ Loom生产事故复盘:某银行核心交易链路OOM崩溃始末,5个致命配置反模式曝光
第一章:Java Loom响应式编程转型的必要性与战略定位在高并发、低延迟、资源敏感型现代服务架构中,传统基于线程池的阻塞式I/O与回调驱动的响应式模型正面临双重瓶颈:JVM线程成本高企,而Project Reactor或RxJava等响应式库又引入了…...

广告行业里,喷绘什么场合用的比较多一点?
在广告行业中,喷绘凭借其色彩丰富、表现力强、成本相对较低等特点,在众多场合广泛应用一、商业促销与活动场合 商场与店铺:商场在节假日或店庆等促销活动期间,会大量使用喷绘。如商场外立面悬挂大幅喷绘海报,宣传活…...

Omni-Vision Sanctuary 长短期记忆网络应用:时间序列预测与文本生成
Omni-Vision Sanctuary 长短期记忆网络应用:时间序列预测与文本生成 1. 序列数据处理的挑战与机遇 在当今数据驱动的世界中,序列数据无处不在——从股票市场的价格波动到人类语言的文字排列,再到视频中的连续帧。这些数据都有一个共同特点&…...