【目标检测系列】YOLOV2解读
为更好理解YOLOv2模型,请先移步,了解YOLOv1后才能更好的理解YOLOv2所做的改进。
前情回顾:【目标检测系列】YOLOV1解读_怀逸%的博客-CSDN博客
背景
通用的目标检测应该具备快速、准确且能过识别各种各样的目标的特点。自从引入神经网络以来,检测框架已经变得越来越块和准确,但是受限于数据集规模的大小,检测方法仍被限制在小部分目标中。
目标检测数据集标注难度远大于分类任务,常见数据集的规模包含几千到数十万张图象,有几十到几百个标签,和分类任务数以百万计的图像及数十万的类别相比,远远不足。我们是希望检测能够达到目标分类的水平。
因此本文的主要工作就是在YOLOV1的基础上进行改进提出了YOLOv2。并提出了一种联合训练方法,在ImageNet的9000多个类别以及COCO的检测数据集上训练一个能够检测9000种类别的模型YOLO9000。
下面是具体的改进措施,从更好、更块、更强三个方向进行改进
更好
Batch Normalization——批量归一化
通过在YOLO的所有卷积层上添加BatchNorm,我们在mAP上的到了2%的改善。BatchNorm也有助于规范化模型,可以在舍弃dropout优化后依然不会过拟合。
Batch Normalization 原理解释
High Resolution Classifier——高分辨率分类器
16年的时候分类任务的发展速度远超于目标检测任务,因此在当时的背景下,所有最先进的目标检测方法都是使用在ImageNet上预训练的分类器作为预训练模型,然后迁移到目标检测任务中,使用目标检测数据集进行微调。但是,在最初的时候,像是AlexNet这样的分类器,都是在分辨率小于256*256的输入图像上进行运行的。
因此,在YOLOV1版本中,是先使用分辨率为224*224的分类器作为预训练模型,然后迁移到目标检测领域,使用448*448的完整分辨率进行微调。
YOLOv2对此的改进是,是先在ImageNet数据集中,以448*448的分辨率对分类网络进行微调,微调后的网络能够完成448*448分辨率图像的分类任务,最后将微调好的分类器迁移到目标检测任务中。
概括就是:YOLOv1使用224*224的分类器直接迁移到448*448的目标检测任务中。YOLOv2是先将分类器微调成448*448,然后再迁移到目标检测任务中。
最终效果mAP增加4%
Convolutional With Anchor Boxes——带有Anchor Boxes的卷积
Anchor: Anchor(先验框)就是一组预设的边界框,可以由横纵比和边框面积来定义,代表了开发人员凭借先验知识认为的待检测物体的形状大小。相当于,开发人员凭借先验知识,设计若干的Anchor,在可能的位置先将目标框出来,然后再在这些Anchor的基础上进行调整。
一个Anchor Box可以由边框的横纵比和边框的面积来定义,至于位置一般不需要定义,目标可能出现在图像的任意位置,因此Anchor Box通常是以CNN提取到的Feature Map的点为中心位置,按照预设大小生成边框。
下面来说一下YOLOv1中存在的问题,YOLOv1中每个cell存在B个框,只能预测一个类别,因此对小尺度的图像效果不佳;同时YOLOv1在训练过程中学习适应同一物体的不同形状是比较困难的,这也导致了YOLOv1在精确定位方面表现较差。之所以这样,是因为YOLOv1直接使用全连接层来预测边界框,要知道全连接层需要固定大小的输入,这也就导致了YOLOv1难以泛化到不同的尺度。
为此YOLOv2删掉了全连接层和最后一个Pooling层,使得最后卷积层可以有更高分辨率的特征;同时将网络的输入分辨率降为416*416
使用416*416而不是448*448的原因是因为YOLOv2下采样步长为32,对于416*416的图片,特征图为13*13,奇数给位置,确保在特征图正中间会存在一个中心单元格(大多数图像中,目标往往会占据图像中间位置)
同时YOLOv2的输出含义也发生变化
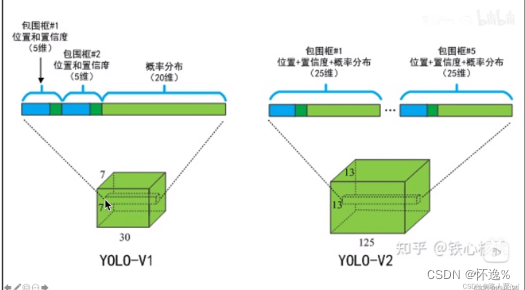
YOLOv1输出:S*S*(B*5+C)
YOLOv2输出:S*S*(B*(5+C)) 不再是每个cell只能预测一个类别,而是每个box能单独预测一个类别
Dimension Clusters——维度聚类(K-means聚类确定Anchor初始值)
如果想要在YOLO中使用锚框,需要解决两个问题:第一个问题,锚框的尺寸应该如何选择,总不能每次都要开发人员去手动设计吧,这与YOLO的设计初衷不符。针对这个问题具体的结局方案就是使用K-means聚类方法,自动找到较好的训练参数。
具体来说,就是针对训练集中的真实框做K-means聚类算法,自动找到符合该训练集的锚框尺寸。同时针对K-means算法做了一点改进,使其更加符合目标检测算法的需求。具体来说,如果像标准K-means算法中一样,使用欧氏距离的话,大的锚框会比小的锚框产生更多的误差,因此,希望关于距离的度量与框的大小无关,所以采用交并比替换欧氏距离,距离度量公式改为d(box, centroid) = 1 - IOU(box, centroid)
Direct location prediction——直接的位置预测
需要解决的第二个问题:模型的不稳定。基于Anchor的方法再回归锚框时,并非直接得到最终坐标,实际上真正需要学习的是目标与预设Anchor的坐标偏移量,下面是公式 预测框中心坐标= 输出的偏移量×Anchor宽高+Anchor中心坐标,偏移量才是要学习的内容。这也就导致了一个问题,因为目标可能会出现在图像中的任意位置,在随机初始化的条件下,模型需要很长时间才能稳定的预测到合理的便宜量。
解决这个问题的办法就是,将预测边界框的偏移量由全图偏移量改成对象cell的左上角的相对偏移量,将预测框的偏移范围控制在每个cell中,做到每个Anchor只负责检测周围正负一个单位内的cell。这样可以使模型训练更加稳定。
Fine-Grained Features——细粒度的特征
YOLOv2使用13*13的特征图进行检测,虽然检测大的目标够用了,但是对于较小的对象来说,更细粒度的特性可能会使得检测效果更好。
与Faster R-CNN等使用多尺度的特征图不同,YOLOv2简单的增加了一个直通层,获得前层26*26分辨率特征。
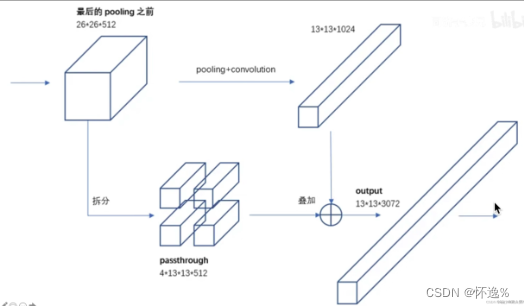
具体操作:前层26*26分辨率特征图拆分成4块,沿通道拼接到13*13的特征图中
Multi-Scale Training——多尺度训练
YOLOv1固定448*448的分辨率作为输入,上面加入锚框操作后,我们将分辨率改成了416*416操作。在实际的应用中,我们需要先将图片放缩到416*416的固定大小,才可以保证网络正确检测到目标。但是,我们希望YOLOv2能够鲁棒的运行在不同尺寸的图像中,不要对数据进行放缩处理。
解决方案是利用YOLOv2只使用了卷积和池化层的特点,这意味着输入图像的大小并不会影响模型的正常运行。因此具体做法就是:网络训练过程中每隔10个epoch就随机一个新的尺寸的图像作为输入训练,这样整个训练流程下来,模型见到过各种尺寸的输入,自然能在不同尺寸在正常执行检测任务。由于模型的下采样采用了32倍,那么训练模型所用的图像分辨率就从{320,352,。。。,608}等中选择。
更快
除了检测更加准确之外,我们还希望能够以更快的速度运行,具体方法在本文中新提出了一个Darknet-19的网络
在YOLOv1中用的是GooLeNet(4个卷积层和2个全连接层),YOLOv2改用Darknet-19(19个卷积层和5个maxpooling层)
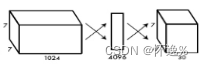
在YOLOv1中最后使用全连接层将7*7*1024的特征图变成7*7*30的特征图,但是这种变化完全可以通过卷积实现,从而大幅度减少参数量。
更强
作者提出了一种对分类和检测数据进行联合训练的机制。在此之前,先介绍下YOLOv2和YOLO9000的区别
YOLOv2:是在YOLOv1的基础上进行改进,特点是“更好、更快、更强”
YOLO9000:主要检测网络也是YOLOv2,同时使用联合优化技术进行训练,最终使得YOLO9000的网络结构允许实时的检测超过9000种物体分类,进一步缩小了检测数据集和分类数据集之间的大小代沟。
具体方法:
- 输入的图片若为目标检测标签的,则在模型中反向传播目标检测的损失函数
- 输入的图片若为分类标签的,则反向传播分类的损失函数
这样做的原理是因为虽然目标检测的数据集规模相对较小,但其实已经能够覆盖大多数物体的形状,例如:猫科动物中,狮子、老虎、豹子等体型类似,检测模型能够检测出这些物体所在的位置,缺乏的只是进一步分类的能力。而分类数据集要丰富得多,关于类别的标准要远远超过检测数据集。
综上,检测数据集可以为绝大多数物体提供位置信息,但缺少细分类的能力;分类数据集为更多物体提供最准确的类别信息,但缺少位置信息,二者结合则得到了YOLO9000
论文链接:https://arxiv.org/abs/1612.08242
源码地址:mirrors / alexeyab / darknet · GitCode
参考内容:【YOLO系列】YOLOv2论文超详细解读(翻译 +学习笔记)_路人贾'ω'的博客-CSDN博客
相关文章:
【目标检测系列】YOLOV2解读
为更好理解YOLOv2模型,请先移步,了解YOLOv1后才能更好的理解YOLOv2所做的改进。 前情回顾:【目标检测系列】YOLOV1解读_怀逸%的博客-CSDN博客 背景 通用的目标检测应该具备快速、准确且能过识别各种各样的目标的特点。自从引入神经网络以来&a…...
第一章 算法小白从0开始】)
【深入浅出程序设计竞赛(基础篇)第一章 算法小白从0开始】
深入浅出程序设计竞赛(基础篇)第一章 算法小白从0开始 第一章 例题例1-1例1-2例1-3例1-4例1-5例1-6例1-7例1-8例1-9例1-10例1-11 第一章 课后习题1-11-21-31-4 第一章 例题 例1-1 #include<iostream> using namespace std;int main(){cout <&…...

openGauss学习笔记-36 openGauss 高级数据管理-TRUNCATE TABLE语句
文章目录 openGauss学习笔记-36 openGauss 高级数据管理-TRUNCATE TABLE语句36.1 语法格式36.2 参数说明36.3 示例 openGauss学习笔记-36 openGauss 高级数据管理-TRUNCATE TABLE语句 清理表数据,TRUNCATE TABLE用于删除表的数据,但不删除表结构。也可以…...

ChatGPT生成文本检测器算法挑战大赛
ChatGPT生成文本检测器算法挑战大 比赛链接:2023 iFLYTEK A.I.开发者大赛-讯飞开放平台 (xfyun.cn) 1、数据加载和预处理 import numpy as np import pandas as pd from sklearn.model_selection import train_test_split, cross_val_predict from sklearn.linea…...
O2OA开发平台实施入门指南
O2OA(翱途)开发平台,是一款适用于协同办公系统开发与实施的基础平台,说到底,它也是一款快速开发平台。开发者可以基于平台提供的能力完成门户、流程、信息相关的业务功能开发。 既然定位为开发平台,那么开…...

服装行业多模态算法个性化产品定制方案 | 京东云技术团队
一、项目背景 AI赋能服装设计师,设计好看、好穿、好卖的服装 传统服装行业痛点 • 设计师无法准确捕捉市场趋势,抓住中国潮流 • 上新周期长,高库存滞销风险大 • 基本款居多,难以满足消费者个性化需求 解决方案 • GPT数据…...

MySQL表空间结构与页、区、段的定义
文章目录 一、概念引入1、页2、区3、段 二、页的结构1、File Header2、FIle Trailer 三、区的结构1、分类2、XDES Entry3、XDES Entry链表 四、段的结构五、独立表空间1、FSP_HDR页2、XDES页3、IBUF_BITMAP页4、INODE页5、INDEX页 六、系统表空间 一、概念引入 1、页 InnoDB是…...
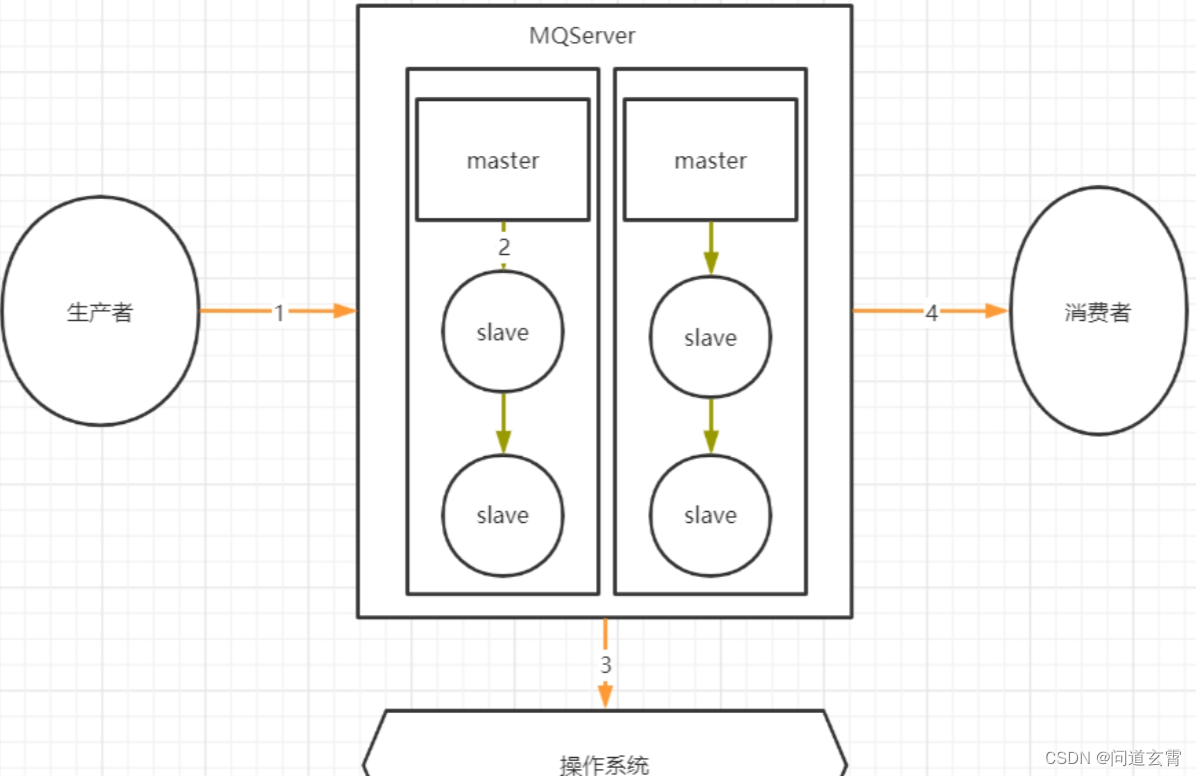
RaabitMQ(三) - RabbitMQ队列类型、死信消息与死信队列、懒队列、集群模式、MQ常见消息问题
RabbitMQ队列类型 Classic经典队列 这是RabbitMQ最为经典的队列类型。在单机环境中,拥有比较高的消息可靠性。 经典队列可以选择是否持久化(Durability)以及是否自动删除(Auto delete)两个属性。 Durability有两个选项,Durable和Transient。 Durable表…...

Unity3D GPU Selector/Picker
Unity3D GPU Selector/Picker 一、概述 1.动机 Unity3D中通常情况下使用物理系统进行物体点击选择的基础,对于含大量对象的场景,添加Collider组件会增加内容占用,因此使用基于GPU的点击选择方案 2.实现思路 对于场景的每个物体,…...
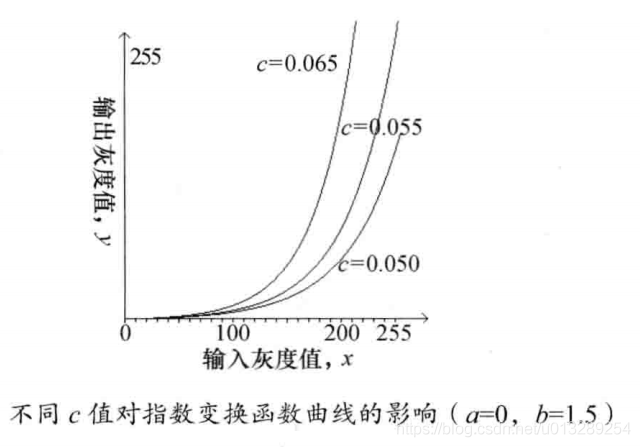
灰度非线性变换之c++实现(qt + 不调包)
本章介绍灰度非线性变换,具体内容包括:对数变换、幂次变换、指数变换。他们的共同特点是使用非线性变换关系式进行图像变换。 1.灰度对数变换 变换公式:y a log(1x) / b,其中,a控制曲线的垂直移量;b为正…...

轻量级Web框架Flask
Flask-SQLAlchemy MySQL是免费开源软件,大家可以自行搜索其官网(https://www.MySQL.com/downloads/) 测试MySQL是否安装成功 在所有程序中,找到MySQL→MySQL Server 5.6下面的命令行工具,然后单击输入密码后回车&am…...

【gridsample】地平线如何支持gridsample算子
文章目录 1. grid_sample算子功能解析1.1 理论介绍1.2 代码分析1.2.1 x,y取值范围[-1,1]1.2.2 x,y取值范围超出[-1,1] 2. 使用grid_sample算子构建一个网络3. 走PTQ进行模型转换与编译 实操以J5 OE1.1.60对应的docker为例 1. grid_sample算子功能解析 该段主要参考:…...
JPA实现存储实体类型信息
本文已收录于专栏 《Java》 目录 背景介绍概念说明DiscriminatorValue 注解:DiscriminatorColumn 注解:Inheritance(strategy InheritanceType.SINGLE_TABLE) 注解: 实现方式父类子类执行效果 总结提升 背景介绍 在我们项目开发的过程中经常…...

阿里云快速部署开发环境 (Apache + Mysql8.0+Redis7.0.x)
本文章的内容截取于云服务器管理控制台提供的安装步骤,再整合前人思路而成,文章末端会提供原文连接 ApacheMysql 8.0部署MySQL数据库(Linux)步骤一:安装MySQL步骤二:配置MySQL步骤三:远程访问My…...
语音秘书:让录音转文字识别软件成为你的智能工作助手
每当在需要写文章的深夜,我的思绪经常跟不上我的笔,即便是说出来用录音机录下,再书写出来,也需要耗费大量时间。这个困扰了我很久的问题终于有了解决的办法,那就是录音转文字软件。它像个语言魔术师,将我所…...
【腾讯云 Cloud Studio 实战训练营】用于编写、运行和调试代码的云 IDE泰裤辣
文章目录 一、引言✉️二、什么是腾讯云 Cloud Studio🔍三、Cloud Studio优点和功能🌈四、Cloud Studio初体验(注册篇)🎆五、Cloud Studio实战演练(实战篇)🔬1. 初始化工作空间2. 安…...

[C#] 简单的俄罗斯方块实现
一个控制台俄罗斯方块游戏的简单实现. 已在 github.com/SlimeNull/Tetris 开源. 思路 很简单, 一个二维数组存储当前游戏的方块地图, 用 bool 即可, true 表示当前块被填充, false 表示没有. 然后, 抽一个 “形状” 类, 形状表示当前玩家正在操作的一个形状, 例如方块, 直线…...
postman官网下载安装登录详细教程
目录 一、介绍 二、官网下载 三、安装 四、注册登录postman账号(不注册也可以) postman注册登录和不注册登录的使用区别 五、关于汉化的说明 一、介绍 简单来说:是一款前后端都用来测试接口的工具。 展开来说:Postman 是一个…...

(贪心) 剑指 Offer 14- I. 剪绳子 ——【Leetcode每日一题】
❓剑指 Offer 14- I. 剪绳子 难度:中等 给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n > 1 并且 m > 1),每段绳子的长度记为 k[0],k[1]...k[m-1] 。请问 k[0]*k[1]*...*k[m…...
如何将Linux上的cpolar内网穿透设置成 - > 开机自启动
如何将Linux上的cpolar内网穿透设置成 - > 开机自启动 文章目录 如何将Linux上的cpolar内网穿透设置成 - > 开机自启动前言一、进入命令行模式二、输入token码三、输入内网穿透命令 前言 我们将cpolar安装到了Ubuntu系统上,并通过web-UI界面对cpolar的功能有…...

OpenGL多线程踩坑实录:EGL_BAD_ACCESS错误排查与修复指南
OpenGL多线程开发中的EGL_BAD_ACCESS:从原理到实战解决方案 当你在深夜调试一个复杂的OpenGL多线程应用时,突然在终端看到EGL_BAD_ACCESS错误提示,那种感觉就像在高速公路上爆胎——既焦虑又无助。这个错误在多线程OpenGL开发中极为常见&…...

聊一聊 C# 中的闭包陷阱:foreach 循环的坑你还记得吗?敖
. GIF文件结构 相比于 WAV 文件的简单粗暴,GIF 的结构要精密得多,因为它天生是为了网络传输而设计的(包含了压缩机制)。 当我们用二进制视角观察 GIF 时,它是由一个个 数据块(Block) 组成的&…...

告别卡顿!在Vue项目中优化HLS/FLV播放的5个实战技巧与避坑指南
告别卡顿!在Vue项目中优化HLS/FLV播放的5个实战技巧与避坑指南 视频播放卡顿、首屏加载缓慢、内存泄漏——这些看似小问题,却能让用户体验断崖式下跌。当你的Vue项目从demo走向生产环境,面对高并发访问和复杂网络环境时,基础播放功…...

从Flannel迁移到Calico:Kubernetes网络插件实战切换指南
1. 为什么需要从Flannel迁移到Calico? 很多刚开始接触Kubernetes的朋友都会选择Flannel作为默认网络插件,毕竟它简单易用,开箱即配。但当你需要更精细的网络控制时,Flannel就显得力不从心了。我去年负责的一个电商项目就遇到了这个…...

FastbootEnhance完整指南:Windows平台最友好的Fastboot工具箱实战解析
FastbootEnhance完整指南:Windows平台最友好的Fastboot工具箱实战解析 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance FastbootEnhanc…...

SSTI漏洞学习笔记
一,SSTI漏洞原理 SSTI(Server-Side Template Injection)是一种服务器端模板注入漏洞,发生在应用程序使用模板引擎渲染用户输入时未能正确过滤或转义用户提供的内容。 服务端模板:有很多网页是使用模板生成的html页面…...

告别手动注册:nb_conda_kernels插件如何智能管理你的Jupyter多环境内核
1. 为什么你需要nb_conda_kernels插件 每次新建一个Conda环境都要手动注册Jupyter内核?这就像每次搬家都要重新办身份证一样麻烦。作为经常在数据分析、机器学习和Web开发多个领域切换的老手,我深刻理解手动管理内核的痛苦。直到发现nb_conda_kernels这个…...

YOLO12镜像问题解决:服务异常重启、参数调整技巧
YOLO12镜像问题解决:服务异常重启、参数调整技巧 1. YOLO12镜像常见问题诊断 1.1 服务异常重启问题排查 YOLO12镜像采用Supervisor进行进程管理,当遇到服务异常时,可以按照以下步骤排查: 检查服务状态: supervisorc…...

在ubuntu上安装docker和docker compose
1. 更新系统包 首先,确保系统包是最新的: sudo apt update sudo apt upgrade -y2. 安装依赖包 安装 Docker 所需的依赖包: sudo apt install -y apt-transport-https ca-certificates curl software-properties-common3. 添加 Docker 官方…...

7种高效连接方式全解析:php-amqplib连接RabbitMQ的终极指南
7种高效连接方式全解析:php-amqplib连接RabbitMQ的终极指南 【免费下载链接】php-amqplib The most widely used PHP client for RabbitMQ 项目地址: https://gitcode.com/gh_mirrors/ph/php-amqplib php-amqplib作为最广泛使用的PHP RabbitMQ客户端…...