28.Netty源码之缓存一致性协议
Mpsc Queue 基础知识
Mpsc 的全称是 Multi Producer Single Consumer,多生产者单消费者。Mpsc Queue 可以保证多个生产者同时访问队列是线程安全的,而且同一时刻只允许一个消费者从队列中读取数据。 Netty Reactor 线程中任务队列 taskQueue 必须满足多个生产者可以同时提交任务,所以 JCTools 提供的 Mpsc Queue 非常适合 Netty Reactor 线程模型。
Mpsc Queue 有多种的实现类,例如 MpscArrayQueue、MpscUnboundedArrayQueue、MpscChunkedArrayQueue 等。我们先抛开一些提供特性功能的队列,聚焦在最基础的 MpscArrayQueue,回过头再学习其他类型的队列会事半功倍。
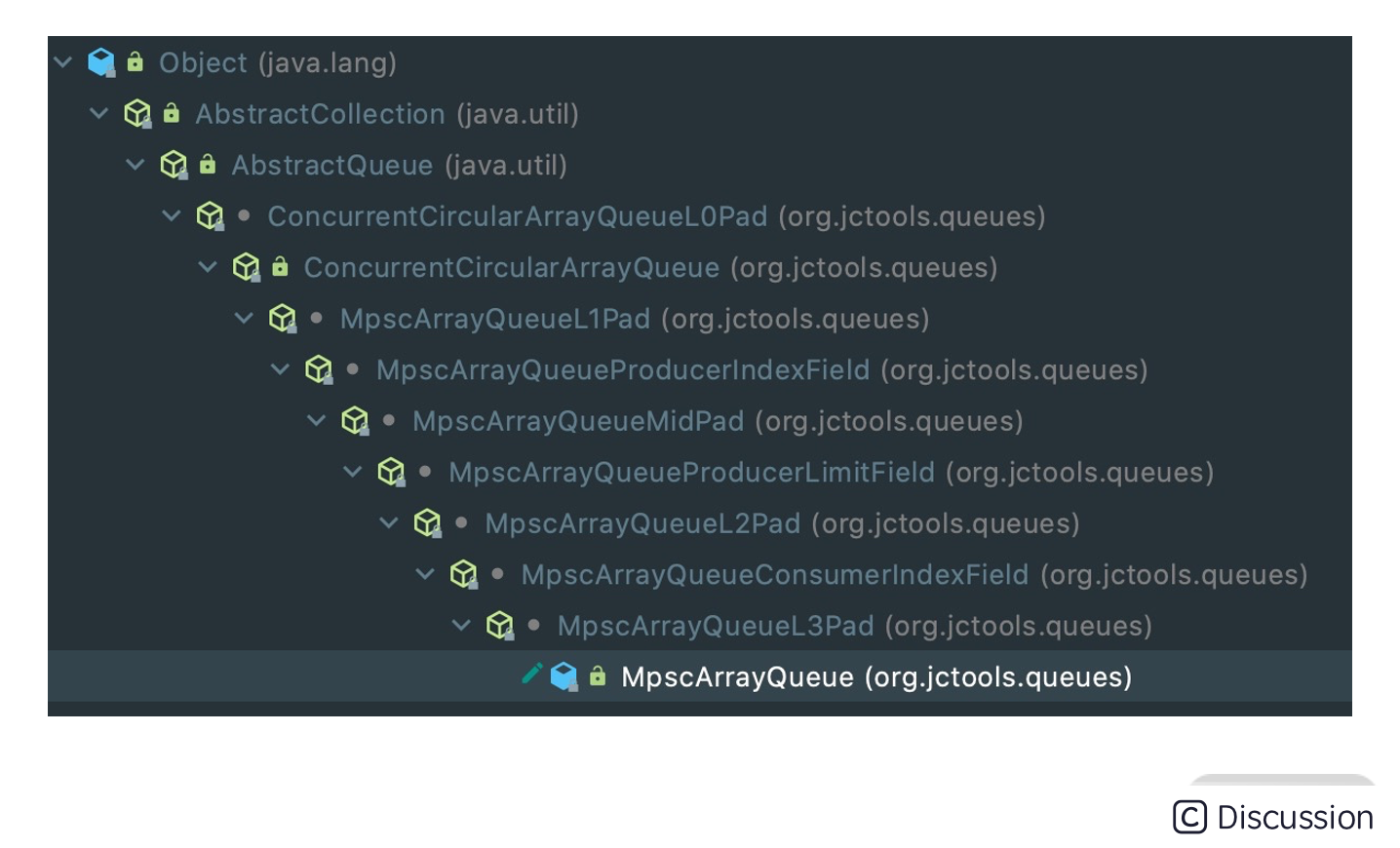
首先我们看下 MpscArrayQueue 的继承关系,会发现相当复杂,如下图所示。
伪共享
除了顶层 JDK 原生的 AbstractCollection、AbstractQueue,MpscArrayQueue 还继承了很多类似于 MpscXxxPad 以及 MpscXxxField 的类。我们可以发现一个很有意思的规律,每个有包含属性的类后面都会被 MpscXxxPad 类隔开。MpscXxxPad 到底起到什么作用呢?我们自顶向下,将所有类的字段合并在一起,看下 MpscArrayQueue 的整体结构。
// ConcurrentCircularArrayQueueL0Pad long p01, p02, p03, p04, p05, p06, p07; long p10, p11, p12, p13, p14, p15, p16, p17; // ConcurrentCircularArrayQueue protected final long mask; protected final E[] buffer; // MpmcArrayQueueL1Pad long p00, p01, p02, p03, p04, p05, p06, p07; long p10, p11, p12, p13, p14, p15, p16; // MpmcArrayQueueProducerIndexField private volatile long producerIndex; // MpscArrayQueueMidPad long p01, p02, p03, p04, p05, p06, p07; long p10, p11, p12, p13, p14, p15, p16, p17; // MpscArrayQueueProducerLimitField private volatile long producerLimit; // MpscArrayQueueL2Pad long p00, p01, p02, p03, p04, p05, p06, p07; long p10, p11, p12, p13, p14, p15, p16; // MpscArrayQueueConsumerIndexField protected long consumerIndex; // MpscArrayQueueL3Pad long p01, p02, p03, p04, p05, p06, p07; long p10, p11, p12, p13, p14, p15, p16, p17;
可以看出,MpscXxxPad 类中使用了大量 long 类型的变量,其命名没有什么特殊的含义,只是起到填充的作用。如果你也读过 Disruptor 的源码,会发现 Disruptor 也使用了类似的填充方法。Mpsc Queue 和 Disruptor 之所以填充这些无意义的变量,是为了解决伪共享(false sharing)问题。
什么是伪共享呢?我们有必要补充这方面的基础知识。在计算机组成中,CPU 的运算速度比内存高出几个数量级,为了 CPU 能够更高效地与内存进行交互,在 CPU 和内存之间设计了多层缓存机制,如下图所示。
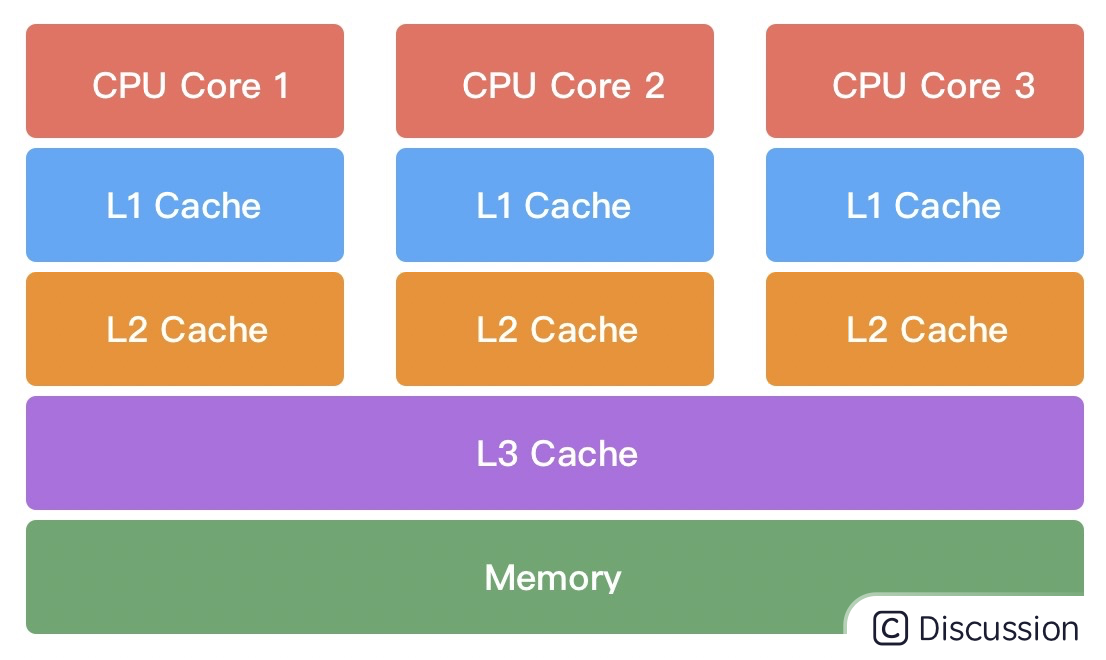
一般来说,CPU 会分为三级缓存,分别为L1 一级缓存、L2 二级缓存和L3 三级缓存。
越靠近 CPU 的缓存,速度越快,但是缓存的容量也越小。
所以从性能上来说,L1 > L2 > L3,容量方面 L1 < L2 < L3。CPU 读取数据时,首先会从 L1 查找,如果未命中则继续查找 L2,如果还未能命中则继续查找 L3,最后还没命中的话只能从内存中查找,读取完成后再将数据逐级放入缓存中。
此外,多线程之间共享一份数据的时候,需要其中一个线程将数据写回主存,其他线程访问主存数据。
由此可见,引入多级缓存是为了能够让 CPU 利用率最大化。如果你在做频繁的 CPU 运算时,需要尽可能将数据保持在缓存中。那么 CPU 从内存中加载数据的时候,是如何提高缓存的利用率的呢?
这就涉及缓存行(Cache Line)的概念,Cache Line 是 CPU 缓存可操作的最小单位,CPU 缓存由若干个 Cache Line 组成。
Cache Line 的大小与 CPU 架构有关,在目前主流的 64 位架构下 ,Cache Line 的大小通常为 64 Byte。Java 中一个 long 类型是 8 Byte,所以一个 Cache Line 可以存储 8 个 long 类型变量。
CPU 在加载内存数据时,会将相邻的数据一同读取到 Cache Line 中,因为相邻的数据未来被访问的可能性最大,这样就可以避免 CPU 频繁与内存进行交互了。
伪共享问题是如何发生的呢?它又会造成什么影响呢?我们使用下面这幅图进行讲解。
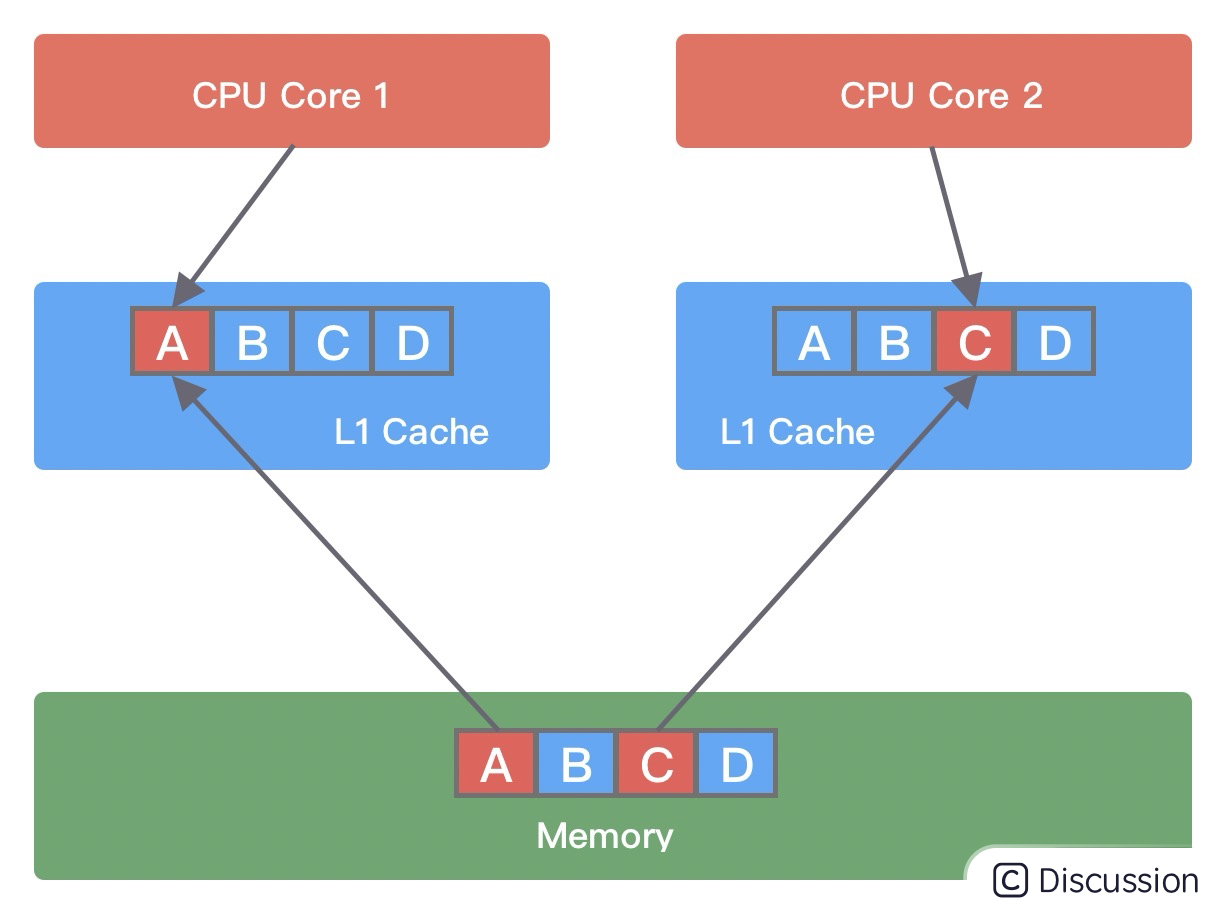
假设变量 A、B、C、D 被C1和C2加载到同一个 Cache Line,它们会被高频地修改。
当线程 1 在 CPU Core1 中中对变量 A 进行修改,修改完成后 CPU Core1 会通知其他 CPU Core 该缓存行已经失效。
然后线程 2 在 CPU Core2 中对变量 C 进行修改时,发现 Cache line 已经失效,此时 CPU Core1 会将数据重新写回内存,CPU Core2 再从内存中读取数据加载到当前 Cache line 中。
由此可见,如果同一个 Cache line 被越多的线程修改,那么造成的写竞争就会越激烈,数据会频繁写入内存,导致性能浪费。
所以如何让一个缓存行尽量被更少的线程修改呢?
原来一个缓存行被多个线程修改,是因为一个缓存行存储了多个数据,每个数据可能由不同的线程修改。
所以我们可以让一个缓存行只存储一个数据。这样可以降低多个线程同时访问一个数据的概率。
题外话,多核处理器中,每个核的缓存行内容是如何保证一致的呢?
有兴趣的同学可以深入学习下缓存一致性协议 MESI。
对于伪共享问题,我们应该如何解决呢?Disruptor 和 Mpsc Queue 都采取了空间换时间的策略,让不同线程共享的对象加载到不同的缓存行即可。下面我们通过一个简单的例子进行说明。
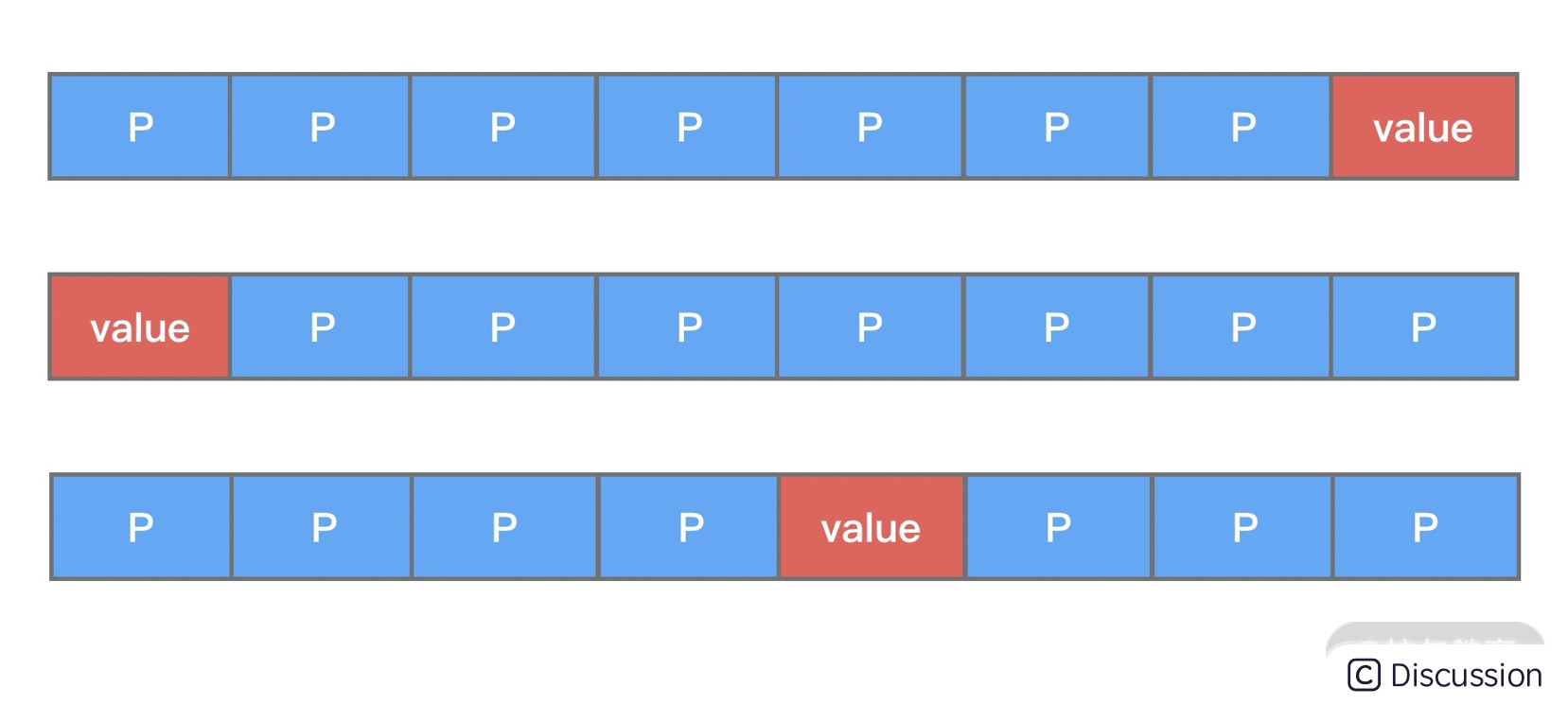
public class FalseSharingPadding { protected long p1, p2, p3, p4, p5, p6, p7; protected volatile long value = 0L; protected long p9, p10, p11, p12, p13, p14, p15; }
从上述代码中可以看出,变量 value 前后都填充了 7 个 long 类型的变量。这样不论在什么情况下,都可以保证在多线程访问 value 变量时,value 与其他不相关的变量处于不同的 Cache Line,如下图所示。
伪共享问题一般是非常隐蔽的,在实际开发的过程中,并不是项目中所有地方都需要花费大量的精力去优化伪共享问题。CPU Cache 的填充本身也是比较珍贵的,我们应该把精力聚焦在一些高性能的数据结构设计上,把资源用在刀刃上,使系统性能收益最大化。
使用缓存行的对齐能够提高效率,也就是让数据位于同一缓存行,会浪费内存(会定义很多变量),但是能提升效率。
Java 8 中已经提供了官方的解决方案,Java 8 中新增了一个注解: @sun.misc.Contended。加上这个注解的类会自动补齐缓存行,需要注意的是此注解默认是无效的,需要在 jvm 启动时设置 -XX:-RestrictContended 才会生效。
@sun.misc.Contended public final static class VolatileLong { public volatile long value = 0L; //public long p1, p2, p3, p4, p5, p6; }
至此,我们知道 Mpsc Queue 为了解决伪共享问题填充了大量的 long 类型变量,造成源码不易阅读。
因为变量填充只是为了提升 Mpsc Queue 的性能,与 Mpsc Queue 的主体功能无关。
接下来我们先忽略填充变量,开始分析 Mpsc Queue 的基本实现原理。
缓存一致性协议(MESI)
在目前主流的计算机中,cpu执行计算的主要流程如图所示:
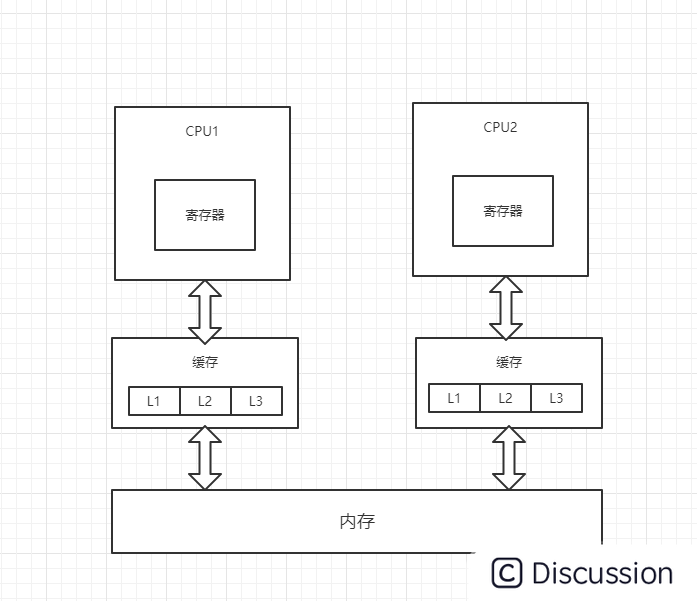
数据加载的流程如下:
1.将程序和数据从硬盘加载到内存中
2.将程序和数据从内存加载到缓存中(目前三级缓存,数据加载顺序:L3->L2->L1)
3.CPU将缓存中的数据加载到寄存器中,并进行运算
4.CPU会将数据刷新回缓存,并在一定的时间周期之后刷新回内存
缓存一致性协议发展背景
现在的CPU基本都是多核CPU,服务器更是提供了多CPU的支持,而每个核心也都有自己独立的缓存,当多个核心同时操作多个线程对同一个数据进行更新时,如果核心2在核心1还未将更新的数据刷回内存之前读取了数据,并进行操作,就会造成程序的执行结果造成随机性的影响,这对于我们来说是无法容忍的。
而总线加锁是对整个内存进行加锁,在一个核心对一个数据进行修改的过程中。
其他的核心也无法修改内存中的其他数据,这样对导致CPU处理性能严重下降。
缓存一致性协议提供了一种高效的内存数据管理方案。
它只会对单个缓存行(缓存行是缓存中数据存储的基本单元)的数据进行加锁,不会影响到内存中其他数据的读写。
因此,我们引入了缓存一致性协议来对内存数据的读写进行管理。
MESI协议
缓存一致性协议有MSI,MESI,MOSI,Synapse,Firefly及DragonProtocol等等,接下来我们主要介绍MESI协议。
MESI分别代表缓存行数据所处的四种状态,通过对这四种状态的切换,来达到对缓存数据进行管理的目的。
| 状态 | 描述 | 监听任务 | | ------------------ | ------------------------------------ | ------------------------------------------------------------------ | | M 修改(Modify) | 该缓存行有效,数据被修改了,和内存中的数据不一致,数据只存在于本缓存行中 | 缓存行必须时刻监听所有试图读该缓存行相对应的内存的操作,其他缓存须在本缓存行写回内存并将状态置为E之后才能操作该缓存行对应的内存数据 | | E 独享、互斥(Exclusive) | 该缓存行有效,数据和内存中的数据一致,数据只存在于本缓存行中 | 缓存行必须监听其他缓存读主内存中该缓存行相对应的内存的操作,一旦有这种操作,该缓存行需要变成S状态 | | S 共享(Shared) | 该缓存行有效,数据和内存中的数据一致,数据同时存在于其他缓存中 | 缓存行必须监听其他缓存是该缓存行无效或者独享该缓存行的请求,并将该缓存行置为I状态 | | I 无效(Invalid) | 该缓存行数据无效 | 无 |
备注
1.MESI协议只对汇编指令中执行加锁操作的变量有效,表现到java中为使用voliate关键字定义变量或使用加锁操作。volatile是Java这种高级语言中的一个关键字,要实现这个volatile的功能,需要借助MESI! CPU有缓存一致性协议:MESI,这不错。但MESI并非是无条件生效的! 不是说CPU支持MESI,那么你的变量就默认能做到缓存一致了。 https://www.zhihu.com/question/296949412 2.对于汇编指令中执行加锁操作的变量,MESI协议在以下两种情况中也会失效: 一、CPU不支持缓存一致性协议。 二、该变量超过一个缓存行的大小,缓存一致性协议是针对单个缓存行进行加锁,此时,缓存一致性协议无法再对该变量进行加锁,只能改用总线加锁的方式。 其实这里也是分段加锁 提高并发度。
MESI工作原理:(此处统一默认CPU为单核CPU,在多核CPU内部执行过程和下面流程一致)
1、CPU1从内存中将变量a加载到缓存中,并将变量a的状态改为E(独享),并通过总线嗅探机制对内存中变量a的操作进行嗅探
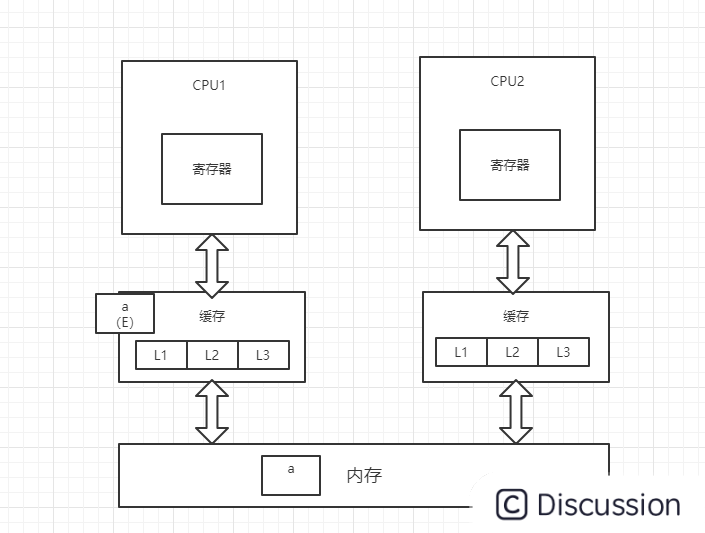
2、此时,CPU2读取变量a,总线嗅探机制会将CPU1中的变量a的状态置为S(共享),并将变量a加载到CPU2的缓存中,状态为S
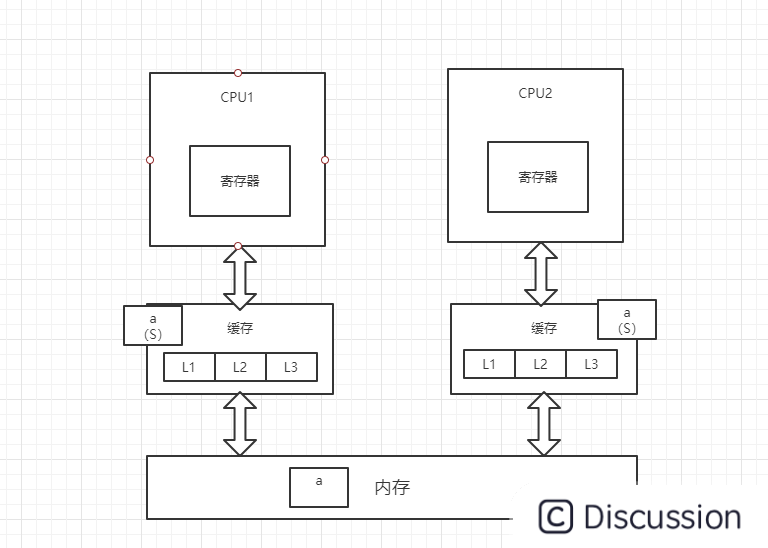
3、CPU1对变量a进行修改操作,此时CPU1中的变量a会被置为M(修改)状态,而CPU2中的变量a会被通知,改为I(无效)状态,此时CPU2中的变量a做的任何修改都不会被写回内存中(高并发情况下可能出现两个CPU同时修改变量a,并同时向总线发出将各自的缓存行更改为M状态的情况,此时总线会采用相应的裁决机制进行裁决,将其中一个置为M状态,另一个置为I状态,且I状态的缓存行修改无效)
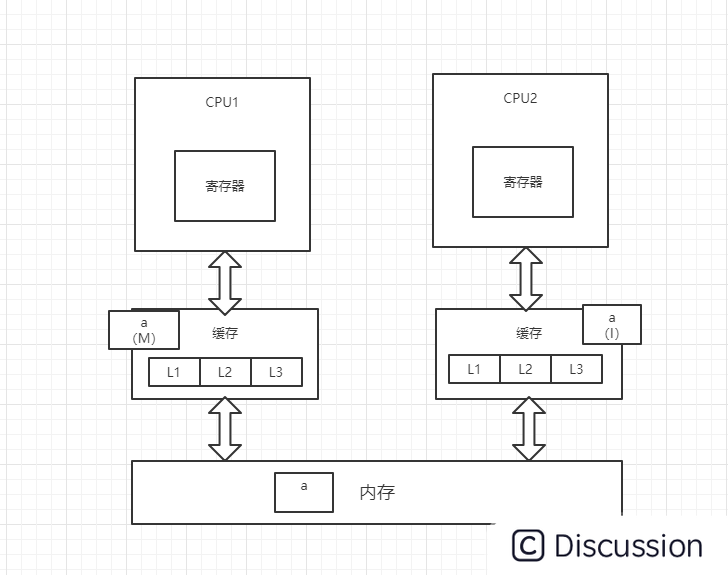
4、CPU1将修改后的数据写回内存,并将变量a置为E(独占)状态
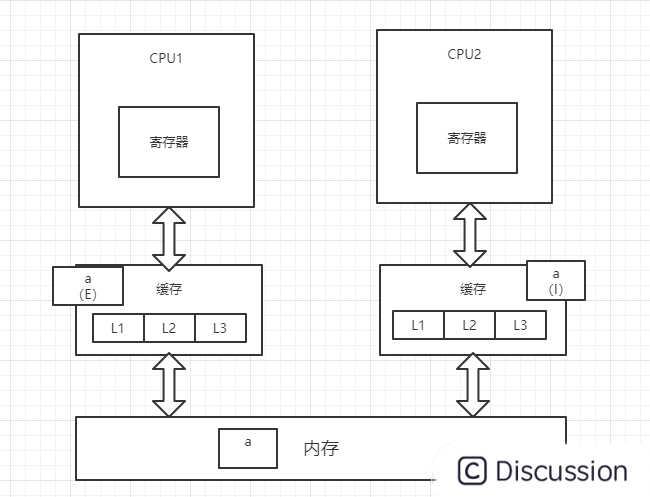
5、此时,CPU2通过总线嗅探机制得知变量a已被修改,会重新去内存中加载变量a,同时CPU1和CPU2中的变量a都改为S状态
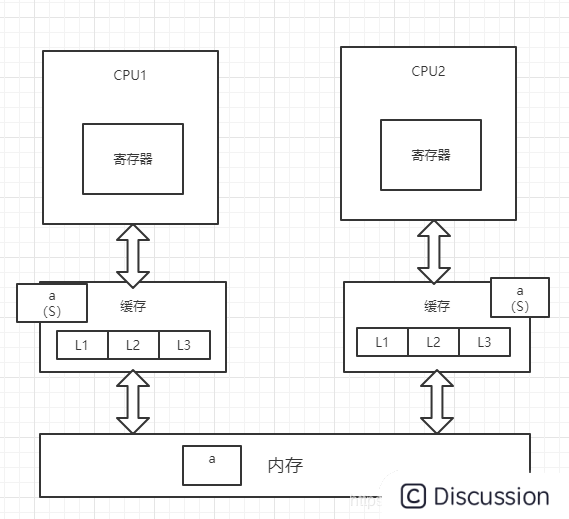
在上述过程第3步中,CPU2的变量a被置为I(无效)状态后,只是保证变量a的修改不会被写回内存,但CPU2有可能会在CPU1将变量a置为E(独占)状态之前重新读取内存中的变量a,这个取决于汇编指令是否要求CPU2重新加载内存。
总结
以上就是MESI的执行原理,MESI协议只能保证并发编程中的可见性,并未解决原子性和有序性的问题,所以只靠MESI协议是无法完全解决多线程中的所有问题。
相关文章:
28.Netty源码之缓存一致性协议
Mpsc Queue 基础知识 Mpsc 的全称是 Multi Producer Single Consumer,多生产者单消费者。Mpsc Queue 可以保证多个生产者同时访问队列是线程安全的,而且同一时刻只允许一个消费者从队列中读取数据。 Netty Reactor 线程中任务队列 taskQueue 必须满足多个…...

造个轮子-任务调度执行小框架-任务清单执行恢复实现
文章目录 前言恢复执行流程失败任务执行重启执行中任务恢复执行修复组件整合组件整合容器启动类总结前言 okey,通过前面的两篇文章,关于这个任务执行这一块,我想应该是明白了。但是这里的话,还是不够的。我们希望对于任务还可以做到执行失败的重试执行,关于这个意外宕机的…...

若依部署前后端
打包项目 前端打包 npm run build:prod将代码上传到指定目录 配置nginx转发 server{listen 8090;server_name localhost;location / {root /home/cc_library/dist;index index.html index.htm;# 配置 history模式,刷新页面会404,,因为服…...

2009年上半年 软件设计师 下午试卷
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战,博主也曾写过优秀论文,查重率极低,在这方面有丰富的经验…...

SpringBoot使用自定义事件监听器的demo
记录一下SpringBoot自定义事件监听器的使用方法 案例源码:SpringBoot使用自定义事件监听器的demo 使用的SpringBoot2.0.x版本 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><…...

arcgis定义投影与投影
1、定义 地理坐标系(GCS):利用地球表面的经纬度表示的坐标系统。一般单位为度。投影坐标系(PCS):利用数学换算将三维地球表面上的经纬度坐标转换到二维平面上的坐标系统。一般单位为米。可以认为ÿ…...
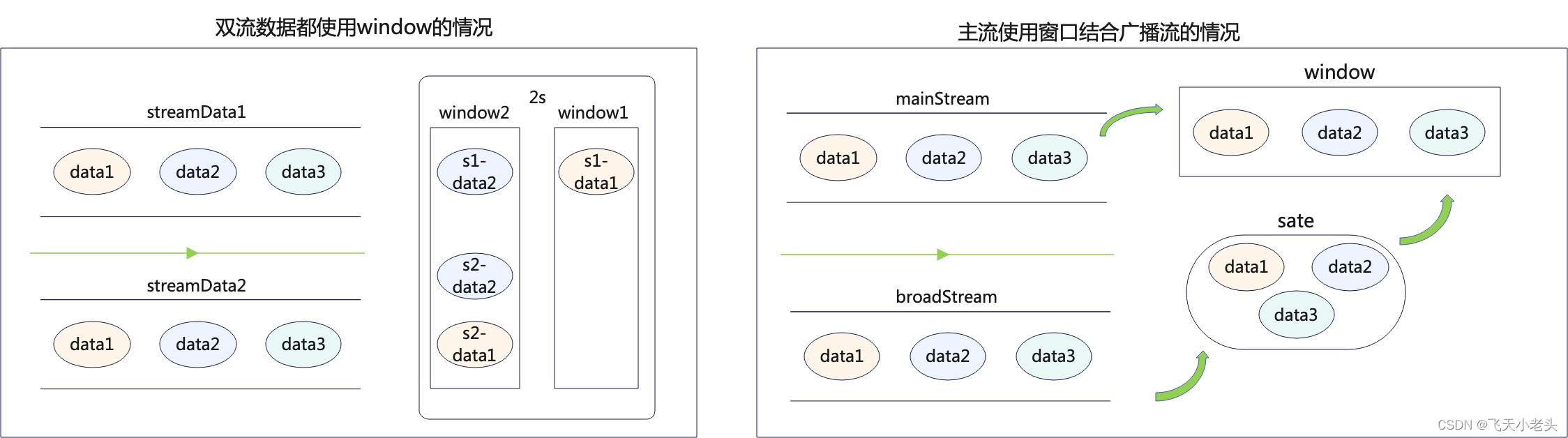
Flink多流处理之Broadcast(广播变量)
写过Spark批处理的应该都知道,有一个广播变量broadcast这样的一个算子,可以优化我们计算的过程,有效的提高效率;同样在Flink中也有broadcast,简单来说和Spark中的类似,但是有所区别,首先Spark中的broadcast是静态的数据,而Flink中的broadcast是动态的,也就是源源不断的数据流.在…...
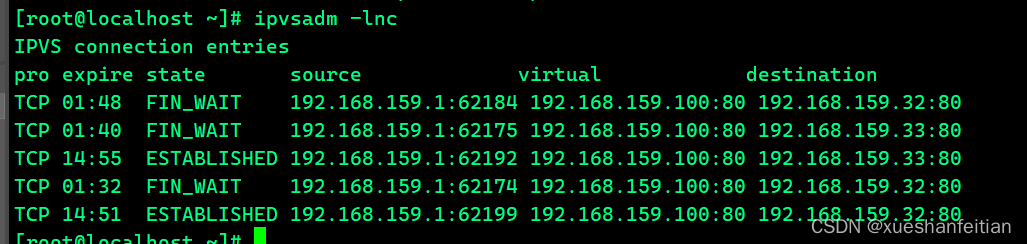
LVS/DR+Keepalived负载均衡实战(一)
引言 负载均衡这个概念对于一个IT老鸟来说再也熟悉不过了,当听到此概念的第一反应是想到举世闻名的nginx,但殊不知还有一个大名鼎鼎的负载均衡方案可能被忽略了,因为对于一般系统来说,很多应用场合中采用nginx基本已经满足需求&a…...

测试DWPose的onnx +Unity barracuda
环境: Unity Barracuda 3.0.1 从github直接拉取的barracuda仓库才能装到这个版本Barracuda以后不再升级了,会迁移到Unity AI大计划里的Sentis 我想申请的来着但好像已经不开放了 Unity 2021.3.20模型:dw-ll_ucoco_384.onnx 报了一些错&…...
轻装上阵,不调用jar包,用C#写SM4加密算法【卸载IKVM 】
前言 记得之前写了一个文章,是关于java和c#加密不一致导致需要使用ikvm的方式来进行数据加密,主要是ikvm把打包后的jar包打成dll包,然后Nuget引入ikvm,从而实现算法的统一,这几天闲来无事,网上找了一下加密…...
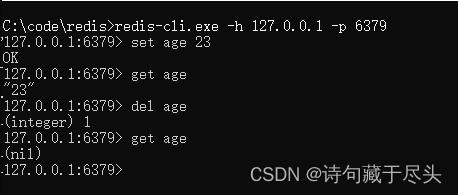
redis学习笔记(一)
文章目录 一、引言二、redis介绍2.1、定义2.2、Redis的数据类型及主要特性2.3、Redis的应用场景有哪些? 三、redis环境安装3.1、下载和安装 一、引言 在Web应用发展的初期,那时关系型数据库受到了较为广泛的关注和应用,原因是因为那时候Web站…...

最优化问题 - 拉格朗日对偶
primal 原问题 dual 对偶问题 目标函数 约束条件 可行域D 对偶专题 “拉格朗日对偶问题”如何直观理解?“KKT条件” “Slater条件” “凸优化”打包理解——bilibili 王木头 拉格朗日乘子法与对偶问题...
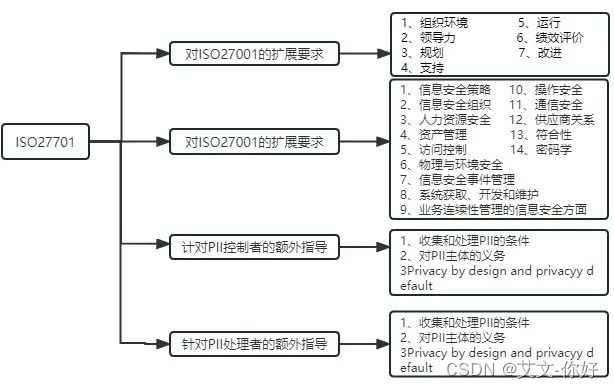
关于ISO27701隐私信息安全管理体系介绍
01 什么是ISO27701 ISO27701是对ISO27001信息安全管理和ISO27002安全控制的隐私扩展,全称《安全技术—扩展ISO27001和ISO27002的隐私信息管理—要求与指南》,是ISO标准委员会以ISO 27001为基准,以ISO27552为蓝本,建立发布的隐私…...
C语言案例 分数列求和-11
题目:有一分数列:2 / 1,3 / 2,5 / 3,8 / 5,13 / 8,21 / 13 …求出这个数列的前20项之和。 程序分析 这是一个典型的分数列数学逻辑题,考究这类题目是需要从已知的条件中找到它们的分布规律 我们把前6荐的分子与分母分别排列出来,…...
Git 入门
一、版本控制 1.1 什么是版本控制 版本控制(Revision control)是一种在开发的过程中用于管理我们对文件、目录或工程等内容的修改历史,方便查看更改历史记录,备份以便恢复以前的版本的软件工程技术。简单说就是用于管理多人协同开…...

PAT 1010 Radix
个人学习记录,代码难免不尽人意 Given a pair of positive integers, for example, 6 and 110, can this equation 6 110 be true? The answer is yes, if 6 is a decimal number and 110 is a binary number. Now for any pair of positive integers N 1and N 2…...
ruoyi-cloud微服务新建子模块
目录 相关文章1、复制system模块2、在modules下的 pom.xml文件中添加子模块 test3、进入 test模块修改 pom.xml4、修改对应的包名、目录名和启动应用程序为test5、修改bootstrap.yml文件中的端口号和应用名称6、nacos中克隆 system-dev.yml的配置,修改名称为 test-d…...
)
Dijkstra(求最短路)
时间复杂是 O(n2m) ,n 表示点数,m 表示边数 模板(朴素法一般m等于n^2的时候使用) #include<bits/stdc.h> #include<algorithm> using namespace std; const int N510; int g[N][N]; //为稠密阵所以用邻接矩阵存储 int dist[N]; //用…...

React 脚手架
1.React 定义 React 脚手架(React boilerplate)是一种预先设置好的、可以快速启动 React 项目的工具。脚手架已经包含了 React、Webpack、Babel、ESLint、Jest 等一些常用的工具和库,并已经配置好了这些工具的参数,可以直接使用和…...

CTFSHOW php命令执行
目录 web29 过滤flag web30 过滤system php web31 过滤 cat|sort|shell|\. 这里有一个新姿势 可以学习一下 web32 过滤 ; . web33 web34 web35 web36 web37 data伪协议 web38 短开表达式 web39 web40 __FILE__命令的扩展 web41 web42 重定向…...

MLP、CNN与RNN选型指南:深度学习三大经典网络解析
1. 神经网络选型指南:MLP、CNN与RNN的适用场景解析作为从业十余年的深度学习工程师,我经常被问到同一个问题:"我的项目该用哪种神经网络?"这确实是个值得深入探讨的话题。在本文中,我将结合工业界实战经验&a…...

ARM RealView Debugger指令追踪技术详解与应用
1. ARM RealView Debugger中的指令追踪技术概述在嵌入式系统开发中,指令追踪(Instruction Trace)是最强大的调试手段之一。与传统的断点调试不同,指令追踪能够非侵入式地记录处理器的完整执行流程,这对实时系统调试、性能优化和异常诊断至关重…...

Kindle Comic Converter终极指南:三步解决漫画阅读适配难题
Kindle Comic Converter终极指南:三步解决漫画阅读适配难题 【免费下载链接】kcc KCC (a.k.a. Kindle Comic Converter) is a comic and manga converter for ebook readers. 项目地址: https://gitcode.com/gh_mirrors/kc/kcc Kindle Comic Converter&#…...

VR-Reversal:将3D全景视频转换为2D普通视频的完整指南
VR-Reversal:将3D全景视频转换为2D普通视频的完整指南 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.com/gh_mi…...

测试工程师真的比开发低一等吗?
很多在校生第一次了解软件行业时,脑子里大概会有一个排序:开发最好,算法更高级,测试像是退而求其次。甚至还有人会觉得:“我代码不太强,是不是只能去做测试?”这句话听上去很现实,但…...

AiPy帮我工作后,我开始躺平摸鱼
作为一名某互联网公司摸爬滚打三年的运营分析师,我最近上班幸福感直线上升——没有涨工资,leader也没有请假,是因为我找到工作摸鱼的真神:AiPy。体验了不到一个月,就已经为我解决了太多工作痛点,让我从无休…...
已弃用,手把手教你改用hasText())
Spring Boot项目里别再踩坑了!StringUtils.isEmpty()已弃用,手把手教你改用hasText()
Spring Boot开发者必看:StringUtils.isEmpty()弃用背后的深度解析与最佳实践 当你在IntelliJ IDEA中敲下StringUtils.isEmpty()时,那条刺眼的删除线是否曾让你停顿?这不是普通的API弃用通知,而是Spring团队对字符串处理规范的一次…...

终极指南:如何快速上手causal-conv1d因果卷积库的完整教程
终极指南:如何快速上手causal-conv1d因果卷积库的完整教程 【免费下载链接】causal-conv1d Causal depthwise conv1d in CUDA, with a PyTorch interface 项目地址: https://gitcode.com/gh_mirrors/ca/causal-conv1d causal-conv1d是一个专为时间序列数据优…...

ConvLSTM_pytorch未来路线图:社区贡献与功能增强计划
ConvLSTM_pytorch未来路线图:社区贡献与功能增强计划 【免费下载链接】ConvLSTM_pytorch Implementation of Convolutional LSTM in PyTorch. 项目地址: https://gitcode.com/gh_mirrors/co/ConvLSTM_pytorch ConvLSTM_pytorch是一个基于PyTorch的卷积LSTM实…...

Minideb实战手册:快速部署PHP、Node.js、Ruby等语言环境
Minideb实战手册:快速部署PHP、Node.js、Ruby等语言环境 【免费下载链接】minideb A small image based on Debian designed for use in containers 项目地址: https://gitcode.com/gh_mirrors/mi/minideb Minideb是一款基于Debian的极简容器基础镜像&#x…...