python图片爬虫
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import argparse
import os
import re
import sys
import urllib
import json
import socket
import urllib.request
import urllib.parse
import urllib.error
# 设置超时
import timetimeout = 5
socket.setdefaulttimeout(timeout)class Crawler:# 睡眠时长__time_sleep = 0.1__amount = 0__start_amount = 0__counter = 0headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0', 'Cookie': ''}__per_page = 30# 获取图片url内容等# t 下载图片时间间隔def __init__(self, t=0.1):self.time_sleep = t# 获取后缀名@staticmethoddef get_suffix(name):m = re.search(r'\.[^\.]*$', name)if m.group(0) and len(m.group(0)) <= 5:return m.group(0)else:return '.jpeg'@staticmethoddef handle_baidu_cookie(original_cookie, cookies):""":param string original_cookie::param list cookies::return string:"""if not cookies:return original_cookieresult = original_cookiefor cookie in cookies:result += cookie.split(';')[0] + ';'result.rstrip(';')return result# 保存图片def save_image(self, rsp_data, word):if not os.path.exists("./" + word):os.mkdir("./" + word)# 判断名字是否重复,获取图片长度self.__counter = len(os.listdir('./' + word)) + 1for image_info in rsp_data['data']:try:if 'replaceUrl' not in image_info or len(image_info['replaceUrl']) < 1:continueobj_url = image_info['replaceUrl'][0]['ObjUrl']thumb_url = image_info['thumbURL']url = 'https://image.baidu.com/search/down?tn=download&ipn=dwnl&word=download&ie=utf8&fr=result&url=%s&thumburl=%s' % (urllib.parse.quote(obj_url), urllib.parse.quote(thumb_url))time.sleep(self.time_sleep)suffix = self.get_suffix(obj_url)# 指定UA和referrer,减少403opener = urllib.request.build_opener()opener.addheaders = [('User-agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'),]urllib.request.install_opener(opener)# 保存图片filepath = './%s/%s' % (word, str(self.__counter) + str(suffix))urllib.request.urlretrieve(url, filepath)if os.path.getsize(filepath) < 5:print("下载到了空文件,跳过!")os.unlink(filepath)continueexcept urllib.error.HTTPError as urllib_err:print(urllib_err)continueexcept Exception as err:time.sleep(1)print(err)print("产生未知错误,放弃保存")continueelse:print("+1,已有" + str(self.__counter) + "张")self.__counter += 1return# 开始获取def get_images(self, word):search = urllib.parse.quote(word)# pn int 图片数pn = self.__start_amountwhile pn < self.__amount:url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%s&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%s&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=%s&rn=%d&gsm=1e&1594447993172=' % (search, search, str(pn), self.__per_page)# 设置header防403try:time.sleep(self.time_sleep)req = urllib.request.Request(url=url, headers=self.headers)page = urllib.request.urlopen(req)self.headers['Cookie'] = self.handle_baidu_cookie(self.headers['Cookie'], page.info().get_all('Set-Cookie'))rsp = page.read()page.close()except UnicodeDecodeError as e:print(e)print('-----UnicodeDecodeErrorurl:', url)except urllib.error.URLError as e:print(e)print("-----urlErrorurl:", url)except socket.timeout as e:print(e)print("-----socket timout:", url)else:# 解析jsonrsp_data = json.loads(rsp, strict=False)if 'data' not in rsp_data:print("触发了反爬机制,自动重试!")else:self.save_image(rsp_data, word)# 读取下一页print("下载下一页")pn += self.__per_pageprint("下载任务结束")returndef start(self, word, total_page=1, start_page=1, per_page=30):"""爬虫入口:param word: 抓取的关键词:param total_page: 需要抓取数据页数 总抓取图片数量为 页数 x per_page:param start_page:起始页码:param per_page: 每页数量:return:"""self.__per_page = per_pageself.__start_amount = (start_page - 1) * self.__per_pageself.__amount = total_page * self.__per_page + self.__start_amountself.get_images(word)if __name__ == '__main__':if len(sys.argv) > 1:parser = argparse.ArgumentParser()parser.add_argument("-w", "--word", type=str, help="抓取关键词", required=True)parser.add_argument("-tp", "--total_page", type=int, help="需要抓取的总页数", required=True)parser.add_argument("-sp", "--start_page", type=int, help="起始页数", required=True)parser.add_argument("-pp", "--per_page", type=int, help="每页大小", choices=[10, 20, 30, 40, 50, 60, 70, 80, 90, 100], default=30, nargs='?')parser.add_argument("-d", "--delay", type=float, help="抓取延时(间隔)", default=0.05)args = parser.parse_args()crawler = Crawler(args.delay)crawler.start(args.word, args.total_page, args.start_page, args.per_page) # 抓取关键词为 “美女”,总数为 1 页(即总共 1*60=60 张),开始页码为 2else:# 如果不指定参数,那么程序会按照下面进行执行crawler = Crawler(0.05) # 抓取延迟为 0.05crawler.start('美女', 10, 2, 30) # 抓取关键词为 “美女”,总数为 1 页,开始页码为 2,每页30张(即总共 2*30=60 张)# crawler.start('二次元 美女', 10, 1) # 抓取关键词为 “二次元 美女”# crawler.start('帅哥', 5) # 抓取关键词为 “帅哥”
使用方法:
百度图片爬虫,基于python3
需要安装python版本 >= 3.6
使用方法
$ python crawling.py -h
usage: crawling.py [-h] -w WORD -tp TOTAL_PAGE -sp START_PAGE[-pp [{10,20,30,40,50,60,70,80,90,100}]] [-d DELAY]optional arguments:-h, --help show this help message and exit-w WORD, --word WORD 抓取关键词-tp TOTAL_PAGE, --total_page TOTAL_PAGE需要抓取的总页数-sp START_PAGE, --start_page START_PAGE起始页数-pp [{10,20,30,40,50,60,70,80,90,100}], --per_page [{10,20,30,40,50,60,70,80,90,100}]每页大小-d DELAY, --delay DELAY抓取延时(间隔)
开始爬取图片
python crawling.py --word "丁真" --total_page 10 --start_page 1 --per_page 30
另外也可以在crawling.py最后一行修改编辑查找关键字
图片默认保存在项目路径
运行爬虫:
python crawling.py
相关文章:

python图片爬虫
#!/usr/bin/env python # -*- coding:utf-8 -*- import argparse import os import re import sys import urllib import json import socket import urllib.request import urllib.parse import urllib.error # 设置超时 import timetimeout 5 socket.setdefaulttimeout(time…...
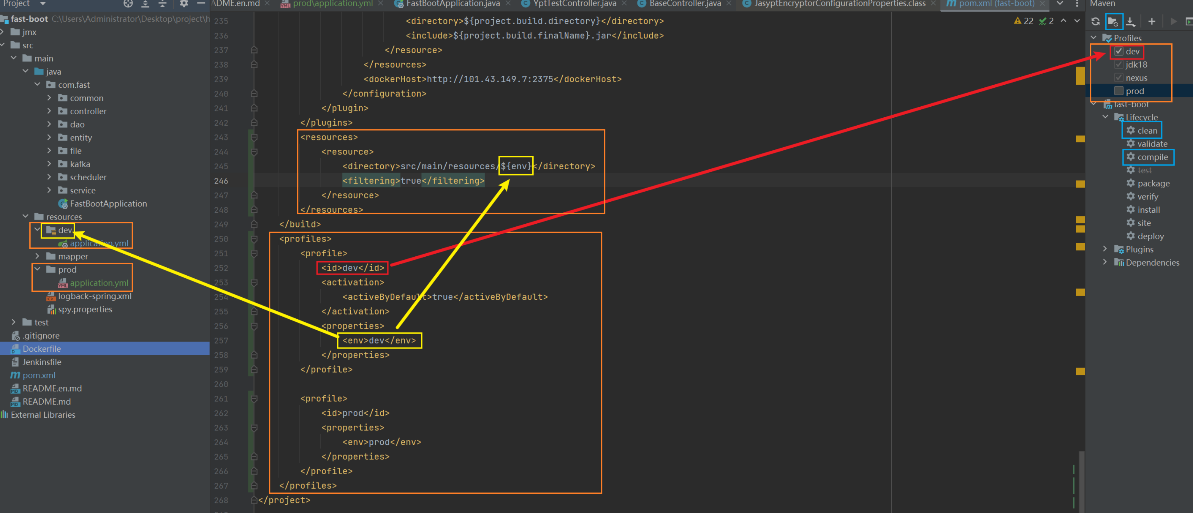
SpringBoot系列---【SpringBoot在多个profiles环境中自由切换】
SpringBoot在多个profiles环境中自由切换 1.在resource目录下新建dev,prod两个目录,并分别把dev环境的配置文件和prod环境的配置文件放到对应目录下,可以在配置文件中指定激活的配置文件,也可以默认不指定。 2.在pom.xml中最后位置…...
Transformer架构
Transformer架构是一种重要的神经网络模型架构,最初由Vaswani等人在2017年提出,并在机器翻译任务上取得了显著的性能提升。Transformer架构在自然语言处理领域得到广泛应用,特别是在语言模型、机器翻译和文本生成等任务中。 Transformer架构…...

TVS二极管失效分析
摘要:常用电路保护器件的主要失效模式为短路,瞬变电压抑制器(TvS)亦不例外。TvS 一旦发生短路失效,释放出的高能量常常会将保护的电子设备损坏.这是 TvS 生产厂家和使用方都想极力减少或避免的情况。通过对 TVS 筛选和使用短路失效…...
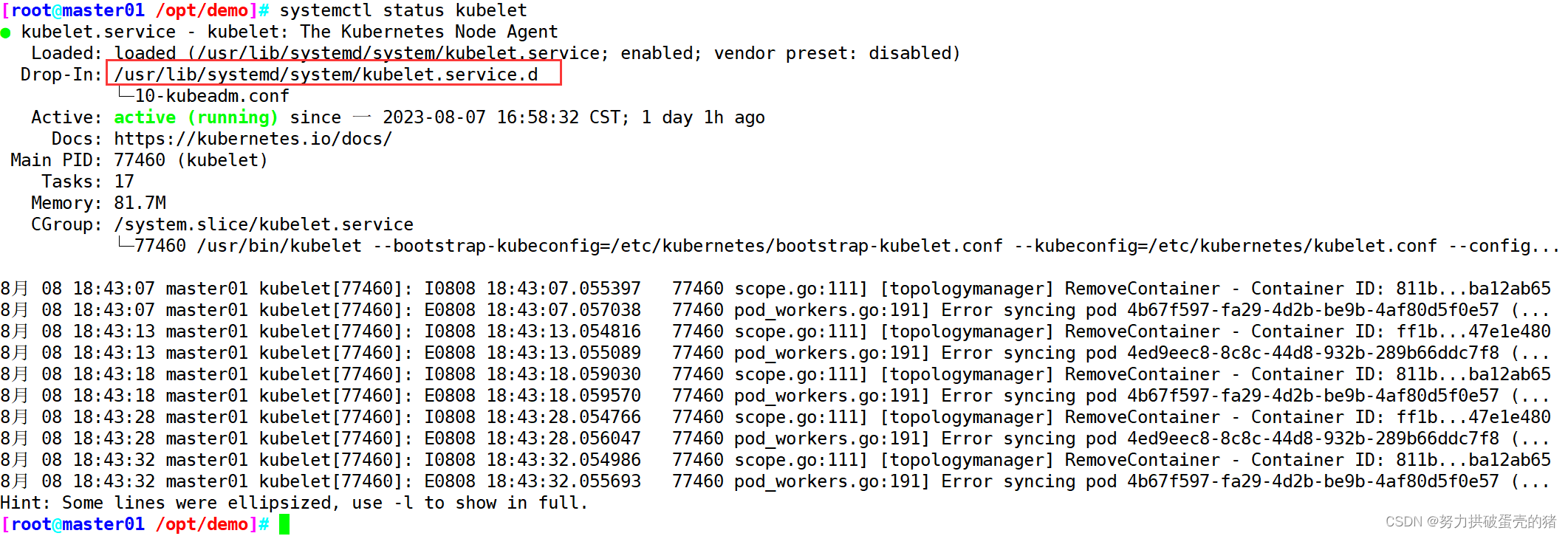
k8s --pod详解
目录 一、Pod基础概念 1、pod简介 2、在Kubrenetes集群中Pod有如下两种使用方式 3、pause容器使得Pod中的所有容器可以共享两种资源:网络和存储。 (1)网络 (2)存储 4、kubernetes中的pause容器主要为每个容器提供…...
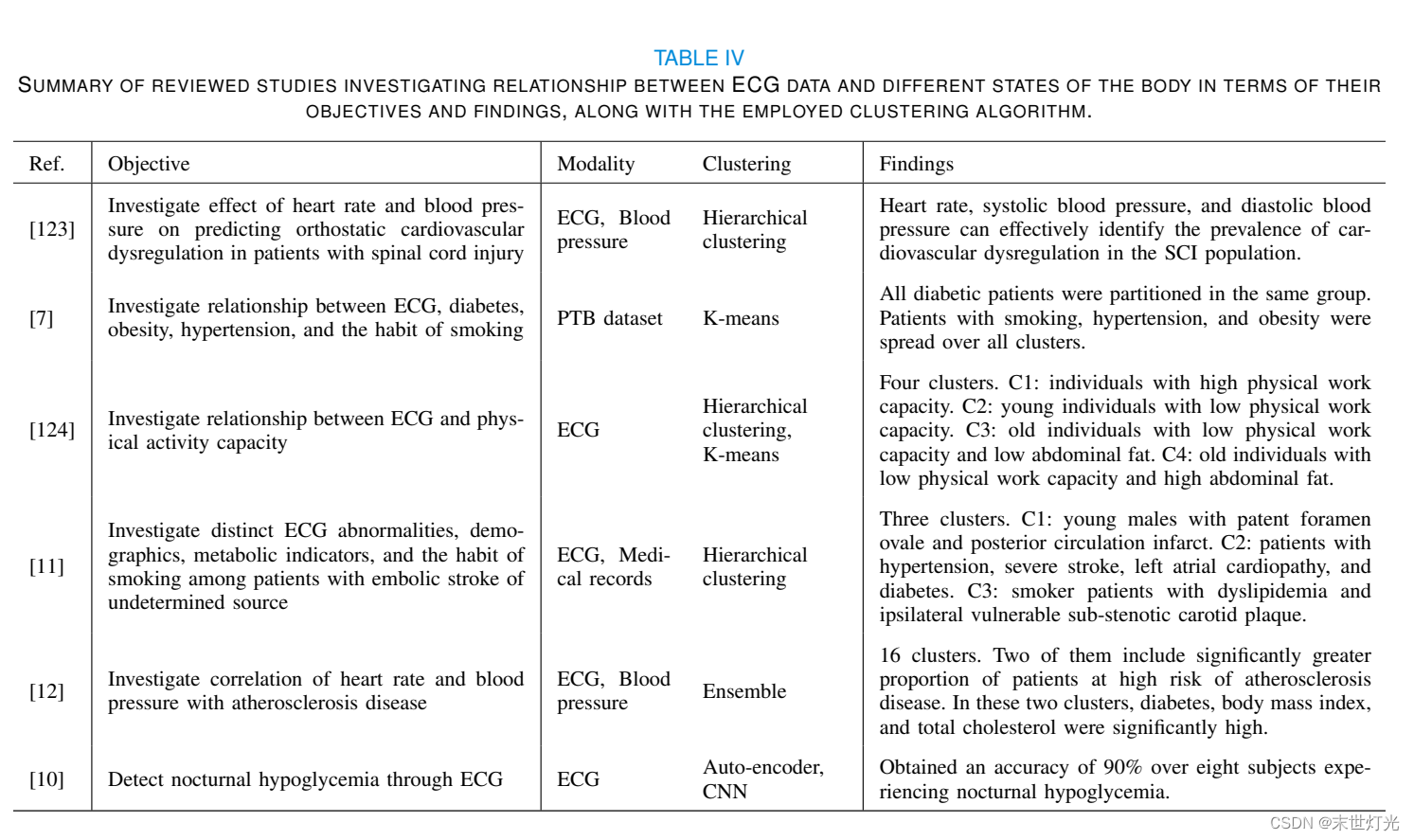
论文阅读---《Unsupervised ECG Analysis: A Review》
题目 无监督心电图分析一综述 摘要 电心图(ECG)是检测异常心脏状况的黄金标准技术。自动检测心电图异常有助于临床医生分析心脏监护仪每天产生的大量数据。由于用于训练监督式机器学习模型的带有心脏病专家标签的异常心电图样本数量有限,对…...

npm四种下载方式的区别
npm install moduleName 命令 安装模块到项目node_modules目录下。 不会将模块依赖写入devDependencies或dependencies 节点。 运行 npm install 初始化项目时不会下载模块。npm install -g moduleName 命令 安装模块到全局,不会在项目node_modules目录中保存模块包…...

04_Hudi 集成 Spark、保存数据至Hudi、集成Hive查询、MergeInto 语句
本文来自"黑马程序员"hudi课程 4.第四章 Hudi 集成 Spark 4.1 环境准备 4.1.1 安装MySQL 5.7.31 4.1.2 安装Hive 2.1 4.1.3 安装Zookeeper 3.4.6 4.1.4 安装Kafka 2.4.1 4.2 滴滴运营分析 4.2.1 需求说明 4.2.2 环境准备 4.2.2.1 工具类SparkUtils 4.2.2.2 日期转换…...

【ARM64 常见汇编指令学习 15 -- ARM 标志位的学习】
文章目录 ARM 标志位介绍Zero Condition flag(零标志位)零标志位判断实例 上篇文章:ARM64 常见汇编指令学习 14 – ARM 汇编 .balign,.balignw,.balign 伪指令学习 下篇文章:ARM64 常见汇编指令学习 16 – ARM64 SMC 指令 ARM 标志位介绍 在ARM架构中&am…...

【论文阅读】基于深度学习的时序预测——FEDformer
系列文章链接 论文一:2020 Informer:长时序数据预测 论文二:2021 Autoformer:长序列数据预测 论文三:2022 FEDformer:长序列数据预测 论文四:2022 Non-Stationary Transformers:非平…...
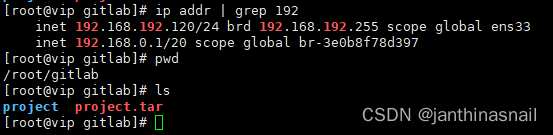
编写简单的.gitlab-ci.yml打包部署项目
服务器说明: 192.168.192.120:项目服务器 192.168.192.121:GitLab 为了可以使用gitlab的cicd功能,我们需要先安装GitLab Runner 安装GitLab Runner参考: GitLab实现CICD自动化部署_gitlab cidi_程序员xiaoQ的博客-CS…...
哪些CRM的报价公开且透明?
企业在选型时,会发现很多品牌的CRM系统价格并不透明,往往都是需要跟产品顾问沟通后才能了解。下面推荐一款价格实在的CRM系统,所有报价公开透明,那就是Zoho CRM。 Zoho CRM是什么? Zoho CRM是一款在线CRM软件&#x…...

springmvc下完成文件上传,使静态资源生效的三种方法
1.上传文件multipart/form-data才可以通过表单提交上传 如果要完成上传功能,必须要开启springmvc的配置功能 !--上传功能bean的id写死id"multipartResolver" class后面配置就是MultipartResolve手动打开上传适配器 1.文件上传实现步骤 1.配置springmvc文件…...

数据归一化:优化数据处理的必备技巧
文章目录 🍀引言🍀数据归一化的概念🍀数据归一化的应用🍀数据归一化的注意事项与实践建议🍀代码演示🍀在sklearn中使用归一化🍀结语 🍀引言 在当今数据驱动的时代,数据的…...
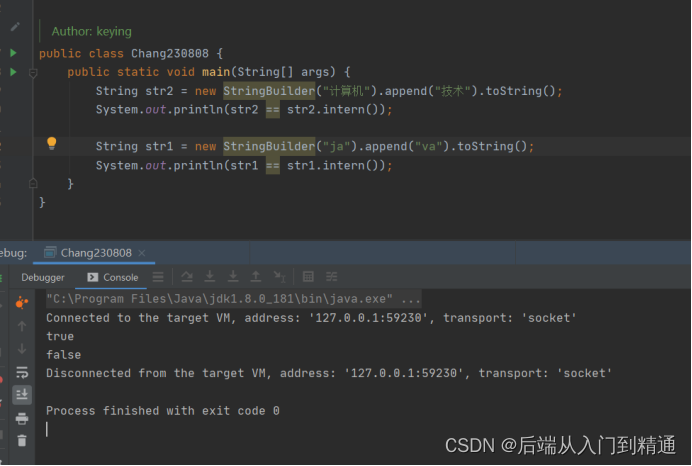
常量池-JVM(十九)
上篇文章说gc日志以及arthas。 Arthas & GC日志-JVM(十八) 一、常量池 常量池主要放两大类:字面量和符号引用。 字面量就是由字母、数字等构成的字符串或者数值常量。 符号引用主要包含三类常量。 类和接口的全限定名。字段的名称和…...

java+springboot+mysql智能社区管理系统
项目介绍: 使用javaspringbootmysql开发的社区住户综合管理系统,系统包含超级管理员、管理员、住户角色,功能如下: 超级管理员:管理员管理;住户管理;房屋管理(楼栋、房屋ÿ…...

pve组网实现公网访问pve,访问电脑,访问pve中的openwrt同时经过openwrt穿透主路由地址nginx全公网访问最佳办法测试研究...
一台路由器 做主路由 工控机 装pve虚拟机 虚拟机里面装一个openwrt, 外网可以直接访问pve,可以访问pve里的openwrt 一台主机 可选择连 有4个口,分别eth0,eth1,eth2,eth3 pve有管理口 这个情况下 ,没有openwrt 直接电脑和pve管理口连在一起就能进pve管理界…...
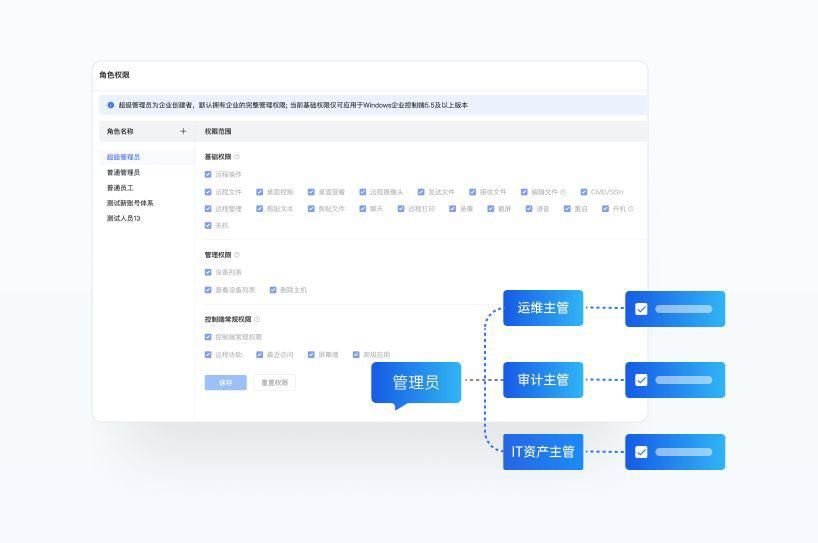
远程运维大批量IT设备?向日葵批量部署、分组授权与安全功能解析
数字化转型的不断推进,给予了企业全方位的赋能,但任何发展都伴随着成本与代价,比如在数字化转型过程中企业内部办公与外部业务所需的不断增加的IT设备数量,就为日常的运维工作提出了更大的挑战。 针对企业面对海量IT设备时的运维…...

Harbor内网离线安装使用HTTPS访问
重要提醒:使用的是域名形式访问Harbor。通过https://harbor.top访问网址。 1、首先在自己windows电脑 “此磁盘C->Windows->System32->drivers->etc” 修改hosts文件 添加“ip harbor.top”例如:“172.33.33.33 harbor.top” 2、进入内网服务…...

Python“牵手”京东工业商城商品详情数据方法介绍
京东工业平台(imall.jd.com)是一个 B2B 电商平台,提供了丰富的工业品类商品,涵盖了机械、化工、建材、劳保用品等品类。如果您需要采集京东工业平台的商品详情数据,可以尝试以下步骤: 选定目标品类和 SKU …...

MiniCPM-O-4_5-GGUF 全解析
一、模型简介MiniCPM-O-4_5-GGUF 是面壁智能(OpenBMB)推出的 MiniCPM-O-4.5 全模态大模型的轻量化量化版本,采用 GGUF 格式优化,专为端侧与低资源设备设计,是当前开源社区中性能最强、部署门槛最低的全模态小参数模型之…...

AMD Ryzen 处理器功耗调校终极指南:RyzenAdj 完整教程
AMD Ryzen 处理器功耗调校终极指南:RyzenAdj 完整教程 【免费下载链接】RyzenAdj Adjust power management settings for Ryzen APUs 项目地址: https://gitcode.com/gh_mirrors/ry/RyzenAdj RyzenAdj 是一款功能强大的开源工具,专门为 AMD Ryzen…...

诊断测试效率翻倍:深度解析CDD文件在CANoe、Diva与VTsystem中的核心配置项
诊断测试效率翻倍:深度解析CDD文件在CANoe、Diva与VTsystem中的核心配置项 在汽车电子诊断测试领域,CDD文件的质量直接影响着自动化测试的效率和可靠性。对于使用Vector工具链(CANoe/Diva/VTsystem)的中高级工程师而言,…...
)
告别Eclipse臃肿!5分钟搞定VS Code搭建RISC-V开发环境(含GCC/OpenOCD配置)
告别Eclipse臃肿!5分钟搞定VS Code搭建RISC-V开发环境(含GCC/OpenOCD配置) 如果你正在寻找一种更轻量、更现代化的RISC-V开发体验,那么VS Code可能是你一直在等待的解决方案。与传统的Eclipse相比,VS Code以其快速的启…...

探索Nintendo Switch游戏备份神器:nxdumptool深度解析与实战指南
探索Nintendo Switch游戏备份神器:nxdumptool深度解析与实战指南 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_m…...

255Mesh LoRa模块实战:从零搭建低功耗传感网络
1. 认识255Mesh LoRa模块:低功耗传感网络的基石 第一次接触255Mesh LoRa模块时,我被它的低功耗特性惊艳到了。这个火柴盒大小的无线模块,能在农业大棚里连续工作3年不换电池,简直就是物联网项目的"节能冠军"。它由终端&…...

告别虚拟机!APK Installer:在Windows上直接运行Android应用的3种革命性方法
告别虚拟机!APK Installer:在Windows上直接运行Android应用的3种革命性方法 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过在Wi…...

Maya glTF插件完整指南:如何高效解决3D模型跨平台导出难题
Maya glTF插件完整指南:如何高效解决3D模型跨平台导出难题 【免费下载链接】maya-glTF glTF 2.0 exporter for Autodesk Maya 项目地址: https://gitcode.com/gh_mirrors/ma/maya-glTF 在当今多平台3D内容创作时代,Maya glTF插件已成为连接Autode…...

投稿赢好礼!金仓社区知识库共建计划第二期开启
供稿:社区运营部编辑:格格审核:日尧...

终极游戏模组管理解决方案:XXMI启动器完整使用指南
终极游戏模组管理解决方案:XXMI启动器完整使用指南 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 你是否厌倦了为不同游戏安装模组时的繁琐步骤?每次切换…...