数据库管理-第九十八期 统计信息是多么重要(20230812)
数据库管理-第九十八期 统计信息是多么重要(20230812)
每天通过EM可视化巡视数据库执行情况,发现那些执行比较长的语句要么是索引没用上、要么是索引没建。但更多的是发现执行计划中“估计的行数”与“行数”(执行的)差距很大(长时间执行后前者远大于后者or后者远大于前者)、大表联查用的nested loop、活动查询发现只分了1个单位的CPU资源在慢慢跑等等。这种情况下往往是对应表或索引的统计信息出现了问题。
其实在以前的文章中也经常提到统计信息的重要性,但是无论我多么努力、用心的强调统计信息的重要性,但业务厂商那边依然经常因此出现问题,这次是在忍不住了,详细的说一下。
1 概念
统计信息,又称优化器统计信息(Optimizer Statistics),Oracle数据库的优化器统计信息是对数据库以及其对象(object)的细节的描述。
优化器成本模型依赖于收集的有关查询中涉及的对象以及运行查询的数据库和主机的统计信息。
优化器使用统计信息来估计从表、分区或索引中检索到的行数(和字节数)。优化器估计访问的成本,确定可能的计划的成本,然后选择成本最低的执行计划。
表、列、索引和系统的统计信息存放在数据字典中,并通过数据字典视图进行访问。
从统计信息的概念来看,优化器制定它认为最优的执行计划需要通过统计信息的内容来生成,除了语句的执行流程以外,还会根据各类统计信息来分配软硬件资源,比如CPU、IO和内存等。
2 统计信息类型
统计信息有以下一些类型:
- 表统计信息:
- 行数量
- 块数量
- 平均行长度
- 列统计信息
- 列中唯一值(NDV)数量
- 空值数量
- 数据分布(直方图)
- 扩展统计信息
- 索引统计信息
- 叶块数量
- 索引层级数量(高度)
- 索引聚簇因子
- 系统统计信息
- IO性能与占用率
- CPU性能与占用率
3 收集统计信息的方法
3.1 DBMS_STATS包
使用DBMS_STATS PL/SQL包来手机和管理统计信息。可以控制收集统计信息的内容和方式,包括并行度、采样模式以及分区表统计信息收集粒度。
一般来说数据库会通过自动统计信息收集任务在规定的窗口时间段内来收集、更新数据库相关的统计信息,并可通过下面的语句来开启、关闭此任务和查询此任务状态:
BEGINDBMS_AUTO_TASK_ADMIN.ENABLE ( client_name => 'auto optimizer stats collection'
, operation => NULL
, window_name => NULL
);
END;
/BEGINDBMS_AUTO_TASK_ADMIN.DISABLE ( client_name => 'auto optimizer stats collection'
, operation => NULL
, window_name => NULL
);
END;
/COL CLIENT_NAME FORMAT a31
SELECT CLIENT_NAME, STATUS FROM DBA_AUTOTASK_CLIENT WHERE CLIENT_NAME = 'auto optimizer stats collection';
这里需要注意的一点,如果数据库足够大,在单次(即一天)的窗口时间内,自动统计信息收集任务只能完成部分数据库对象的统计信息,因此可能出现维护窗口后仍有部分表统计信息不准确的情况。
3.2 额外的动态统计信息
默认情况下,当优化器统计信息丢失、过时或不足时,数据库会在解析过程中自动收集动态统计信息。数据库使用递归SQL来扫描表块的随机小样本。
一般来说我们不建议数据库使用过程中触发动态统计信息,因为它会对语句造成额外的开销。但在下列情况中动态统计信息是有用的:
- 由于谓词复杂,执行计划是次优的。
- 采样时间只是查询总执行时间的一小部分。
- 查询执行多次,以便摊销采样时间。
3.3 在线统计信息收集
在某些情况下,DDL和DML操作会触发在线统计信息收集:
3.3.1 批量数据处理的在线统计信息收集
数据库可以在以下类型的大量数据加载期间自动收集表统计信息: INSERT INTO … SELECT使用direct path插入和CREATE TABLE AS SELECT时。
默认情况下,并行插入使用direct path插入。您可以通过添加hint /*+APPEND*/的方式强制direct path插入。
3.3.2 目的
分析类应用通常需要将大量数据加载到数据库中。在12c之前版本最佳实践是在操作后手动收集统计信息。但是,由于疏忽或等待自动统计信息收集任务执行,许多统计信息没有及时收集。这是执行计划欠佳的主要原因。(当然在实际使用过程中,发现及时是12c之后的版本依然会出现相关操作后统计信息未更新的现象,部分源自于下面“限制”部分,但也有小概率不是)
带来的好处:
- 提升性能:在加载期间收集统计信息可以避免额外的表扫描来收集表的统计信息。
- 改进可管理型:无需用户干预可以在批量数据加载后收集统计信息。
3.3.3 插入分区表时收集全局统计信息
在将数据插入分区时,数据库会在插入过程中收集分区表的全局统计信息。
3.3.4 批量数据加载后创建直方图
在线统计信息收集后,数据库不会自动创建直方图,如果直方图是需要的可以通过下面的语句实现自动收集直方图统计信息:
EXEC DBMS_STATS.GATHER_TABLE_STATS(user, 'MYT', options=>'GATHER AUTO');
3.3.5 限制
在某些情况下,大数据量加载不会自动收集统计信息。
具体来说,当系列任何条件适用于目标表、分区或子分区时,大数据量加载不会自动收集统计信息:
- 对象已包含数据。大数据量加载仅在对象为空时自动在线收集统计信息。
- 它在Oracle拥有的schema中,如sys。
- 下列类型之一:嵌套表、索引组织表(IOT)、外部表或者定义为ON COMMIT DELETE ROWS的全局临时表。
- PUBLISH设置为FALSE。
- 其他统计信息已锁定。
- 使用多个insert语句加载数据。
3.3.6 用户控制的大数据量加载后的在线统计信息收集
可以使用hint GATHER_OPTIMIZER_STATISTICS来关闭默认启用的大数据量加载后的在线统计信息收集:
CREATE TABLE employees2 AS SELECT /*+NO_GATHER_OPTIMIZER_STATISTICS*/ * FROM employees
3.4 分区维护操作在线统计信息收集
Oracle 数据库在特定分区维护操作期间为联机统计信息提供类似的支持。
对于MOVE、COALESCE和MERGE操作,数据库在下列情况下在全局和分区层面维护统计信息:
- 如果分区使用增量或非增量统计信息,数据库会直接更新全局统计信息中的块数量的值。需要注意这个操作不是统计信息收集操作。
- 数据库为新生成的分区收集统计信息。如果启用增量统计信息,则数据库维护分区概要。
对于TRUNCATE或DROP PARTITION,数据库会更新全局统计信息中的块数量和行数量的值。这个操作同样不是统计信息收集操作,统计信息更新同样在使用增量或非增量统计信息情况下。
3.5 实时统计信息收集
Oracle可以在常规DML操作期间自动收集统计信息。其主要作用是减少优化器被过时统计信息误导的可能性。在DML操作时,数据库会动态计算最基本统计信息的值。这里需要注意的是实时统计信息收集是增强而不是取代传统统计信息,仍要确保自动统计信息收集任务正确执行。
这个作为19c带来的新特性,在Oracle数据库管理每周一例-第十四期 19c需要调整的参数及操作中也提到过,祖上一些版本开启该功能会出现锁表的现象,所以我一般是通过OPTIMIZER_REAL_TIME_STATISTICSTRUEFALSE初始化参数关闭的。
如有需详细了解相关内容可查阅官方文档10.3.3.3 Real-Time Statistics。
4 统计信息来源
数据库在不同时间、从不同来源收集统计信息。
主要来自:
- DBMS_STATS执行(自动或手动)
这个PL/SQL包是收集统计信息的主要方法。 - SQL编译
在 SQL 编译期间,数据库可以扩充以前由DBMS_STATS收集的统计信息。在此阶段,数据库运行其他查询,以获取有关表中有多少行满足 SQL 语句中的WHERE子句谓词的更准确信息。 - SQL执行
在执行期间,数据库可以进一步扩充以前收集的统计信息。在此阶段,Oracle 数据库收集 SQL 语句执行过程中每个行源生成的行数。在执行结束时,优化程序确定估计的行数是否足够准确,以保证在下一次语句执行时重新解析。如果将游标标记为重新分析,则优化程序将使用上一次执行的实际行计数,而不是估计值。 - SQL Profile
SQL Profile是查询的辅助统计信息的集合。配置文件将这些补充统计信息存储在数据字典中。优化程序在优化期间使用 SQL 配置文件来确定最佳计划。
数据库将优化器统计信息存储在数据字典中,并根据需要更新或替换它们。您可以在数据字典视图中查询统计信息。
更多的关于数据库是如何收集统计信息的内容可以查看官方文档When the Database Gathers Optimizer Statistics。
5 DBMS_STATS
这里主要引申几个常见的统计信息收集语句(其余可以详见173 DBMS_STATS):
5.1 收集数据库统计信息
DBMS_STATS.GATHER_DATABASE_STATS (estimate_percent NUMBER DEFAULT to_estimate_percent_type (get_param('ESTIMATE_PERCENT')),block_sample BOOLEAN DEFAULT FALSE,method_opt VARCHAR2 DEFAULT get_param('METHOD_OPT'),degree NUMBER DEFAULT to_degree_type(get_param('DEGREE')),granularity VARCHAR2 DEFAULT GET_PARAM('GRANULARITY'), cascade BOOLEAN DEFAULT to_cascade_type(get_param('CASCADE')),stattab VARCHAR2 DEFAULT NULL, statid VARCHAR2 DEFAULT NULL,options VARCHAR2 DEFAULT 'GATHER',objlist OUT ObjectTab,statown VARCHAR2 DEFAULT NULL,gather_sys BOOLEAN DEFAULT TRUE,no_invalidate BOOLEAN DEFAULT to_no_invalidate_type (get_param('NO_INVALIDATE')),obj_filter_list ObjectTab DEFAULT NULL);DBMS_STATS.GATHER_DATABASE_STATS (estimate_percent NUMBER DEFAULT to_estimate_percent_type (get_param('ESTIMATE_PERCENT')), block_sample BOOLEAN DEFAULT FALSE,method_opt VARCHAR2 DEFAULT get_param('METHOD_OPT'),degree NUMBER DEFAULT to_degree_type(get_param('DEGREE')),granularity VARCHAR2 DEFAULT GET_PARAM('GRANULARITY'), cascade BOOLEAN DEFAULT to_cascade_type(get_param('CASCADE')),stattab VARCHAR2 DEFAULT NULL, statid VARCHAR2 DEFAULT NULL,options VARCHAR2 DEFAULT 'GATHER',statown VARCHAR2 DEFAULT NULL,gather_sys BOOLEAN DEFAULT TRUE,no_invalidate BOOLEAN DEFAULT to_no_invalidate_type (get_param('NO_INVALIDATE')),obj_filter_list ObjectTab DEFAULT NULL);-- 一般执行:
exec dbms_stats.gather_database_stats(cascade=>true,degree=>32);
5.2 收集schema统计信息
DBMS_STATS.GATHER_SCHEMA_STATS ( ownname VARCHAR2, estimate_percent NUMBER DEFAULT to_estimate_percent_type (get_param('ESTIMATE_PERCENT')), block_sample BOOLEAN DEFAULT FALSE, method_opt VARCHAR2 DEFAULT get_param('METHOD_OPT'),degree NUMBER DEFAULT to_degree_type(get_param('DEGREE')), granularity VARCHAR2 DEFAULT GET_PARAM('GRANULARITY'), cascade BOOLEAN DEFAULT to_cascade_type(get_param('CASCADE')), stattab VARCHAR2 DEFAULT NULL, statid VARCHAR2 DEFAULT NULL, options VARCHAR2 DEFAULT 'GATHER', objlist OUT ObjectTab,statown VARCHAR2 DEFAULT NULL, no_invalidate BOOLEAN DEFAULT to_no_invalidate_type (get_param('NO_INVALIDATE')),force BOOLEAN DEFAULT FALSE,obj_filter_list ObjectTab DEFAULT NULL);DBMS_STATS.GATHER_SCHEMA_STATS ( ownname VARCHAR2, estimate_percent NUMBER DEFAULT to_estimate_percent_type (get_param('ESTIMATE_PERCENT')), block_sample BOOLEAN DEFAULT FALSE, method_opt VARCHAR2 DEFAULT get_param('METHOD_OPT'), degree NUMBER DEFAULT to_degree_type(get_param('DEGREE')), granularity VARCHAR2 DEFAULT GET_PARAM('GRANULARITY'), cascade BOOLEAN DEFAULT to_cascade_type(get_param('CASCADE')), stattab VARCHAR2 DEFAULT NULL, statid VARCHAR2 DEFAULT NULL, options VARCHAR2 DEFAULT 'GATHER', statown VARCHAR2 DEFAULT NULL, no_invalidate BOOLEAN DEFAULT to_no_invalidate_type (get_param('NO_INVALIDATE'), force BOOLEAN DEFAULT FALSE,obj_filter_list ObjectTab DEFAULT NULL);-- 一般执行:
exec dbms_stats.gather_schema_stats(ownname=>'USERNAME',cascade=>true,degree=>32);
5.3 收集表统计信息
DBMS_STATS.GATHER_TABLE_STATS (ownname VARCHAR2, tabname VARCHAR2, partname VARCHAR2 DEFAULT NULL,estimate_percent NUMBER DEFAULT to_estimate_percent_type (get_param('ESTIMATE_PERCENT')),block_sample BOOLEAN DEFAULT FALSE,method_opt VARCHAR2 DEFAULT get_param('METHOD_OPT'),degree NUMBER DEFAULT to_degree_type(get_param('DEGREE')),granularity VARCHAR2 DEFAULT GET_PARAM('GRANULARITY'), cascade BOOLEAN DEFAULT to_cascade_type(get_param('CASCADE')),stattab VARCHAR2 DEFAULT NULL, statid VARCHAR2 DEFAULT NULL,statown VARCHAR2 DEFAULT NULL,no_invalidate BOOLEAN DEFAULT to_no_invalidate_type (get_param('NO_INVALIDATE')),stattype VARCHAR2 DEFAULT 'DATA',force BOOLEAN DEFAULT FALSE,context DBMS_STATS.CCONTEXT DEFAULT NULL, -- non operativeoptions VARCHAR2 DEFAULT get_param('OPTIONS'));-- 一般执行:
exec dbms_stats.gather_table_stats(ownname=>'USERNAME',tabname=>'TABLE_NAME',cascade=>true,degree=>8,method_opt=>'xxxx');
-- 其中method_opt可以指定收集统计信息的方式,比如多列统计信息、直方图统计信息等。
5.4 收集索引统计信息
DBMS_STATS.GATHER_INDEX_STATS (ownname VARCHAR2, indname VARCHAR2, partname VARCHAR2 DEFAULT NULL,estimate_percent NUMBER DEFAULT to_estimate_percent_type (GET_PARAM('ESTIMATE_PERCENT')),stattab VARCHAR2 DEFAULT NULL, statid VARCHAR2 DEFAULT NULL,statown VARCHAR2 DEFAULT NULL,degree NUMBER DEFAULT to_degree_type(get_param('DEGREE')),granularity VARCHAR2 DEFAULT GET_PARAM('GRANULARITY'),no_invalidate BOOLEAN DEFAULT to_no_invalidate_type (GET_PARAM('NO_INVALIDATE')),force BOOLEAN DEFAULT FALSE);-- 我一般是在收集表统计信息的同时收集索引统计信息
总结
没啥说的,知道写了些啥。
相关文章:
)
数据库管理-第九十八期 统计信息是多么重要(20230812)
数据库管理-第九十八期 统计信息是多么重要(20230812) 每天通过EM可视化巡视数据库执行情况,发现那些执行比较长的语句要么是索引没用上、要么是索引没建。但更多的是发现执行计划中“估计的行数”与“行数”(执行的)…...
山西电力市场日前价格预测【2023-08-13】
日前价格预测 预测明日(2023-08-13)山西电力市场全天平均日前电价为351.64元/MWh。其中,最高日前电价为404.00元/MWh,预计出现在19: 30。最低日前电价为306.39元/MWh,预计出现在13: 15。 价差方向预测 1: 实…...

AtCoder Beginner Contest 313D题题解
文章目录 [ Odd or Even](https://atcoder.jp/contests/abc313/tasks/abc313_d)问题建模问题分析1.分析每次查询的作用2.利用异或运算的性质设计查询方法 Odd or Even 问题建模 有n个数,每个数为0或者1,最多可以进行n次询问,每次询问选择k个…...

mybatis 中的<![CDATA[ ]]>用法及说明
<![CDATA[ ]]>作用 <![CDATA[ ]]> 在mybatis、ibatis等书写SQL的xml中比较常见,是一种XML语法,他的作用是 可以忽略xml的转义(在该标签中的语句和字符原本是什么样的,在拼接成SQL后还是什么样的) 使用&a…...

从零学算法34
34.给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。 如果数组中不存在目标值 target,返回 [-1, -1]。 你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。 示例 1࿱…...
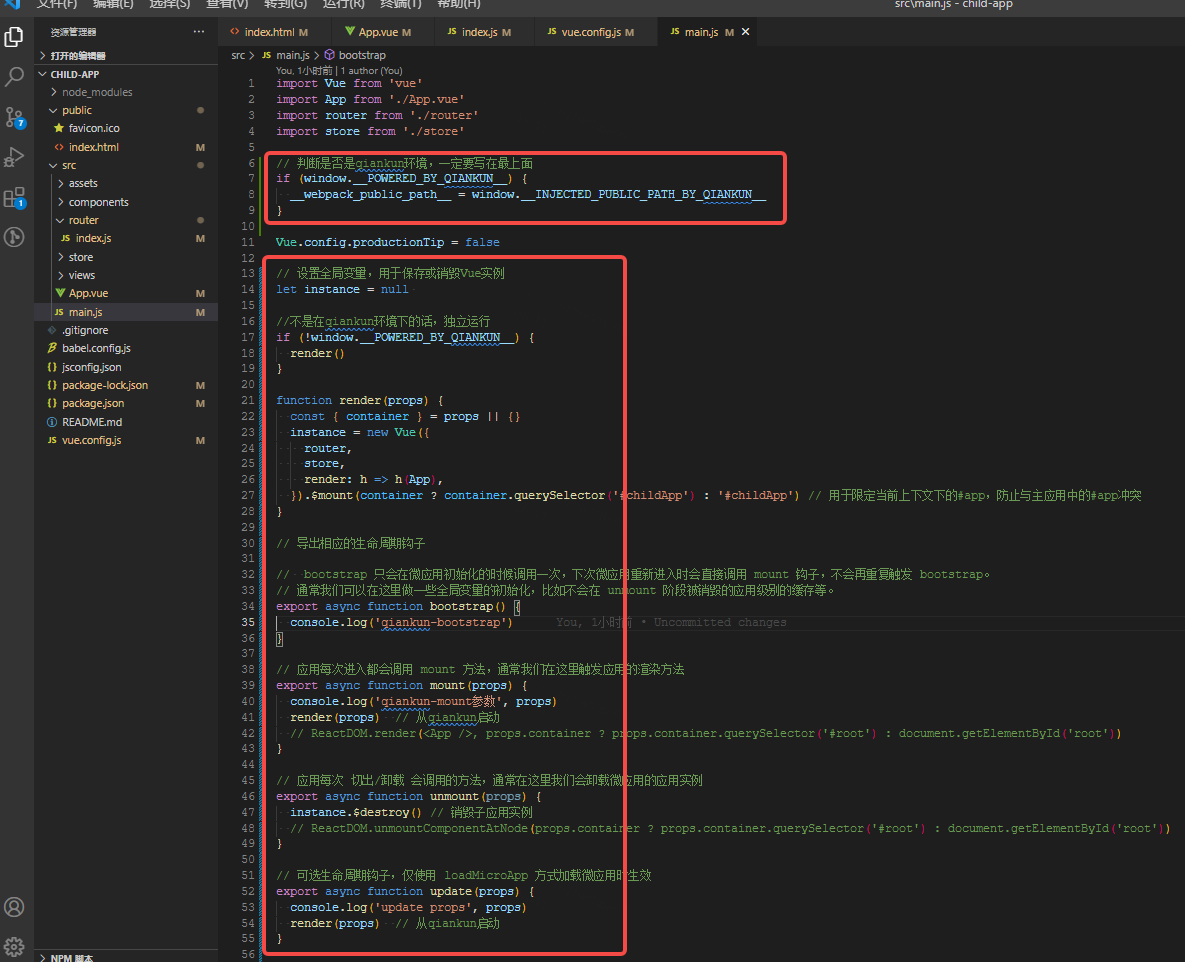
qiankun-微前端--vue2
项目结构 主应用技术: vue2 子应用技术:vue2 项目目录 这里是特意将主子项目分开来的,方便管理 主应用 安装 qiankun npm install qiankun重新定义一个启动端口,防止和其它子应用共用同一个端口(vue.config.js&…...
Win7累积补丁更新包_UpdatePack7R2-23.8.10
UpdatePack7是最新的Win7补丁累积更新包,Windows 7更新补丁安装包,Win7累积更新离线安装包包括所有关键更新和安全更新及Internet Explorer所有版本的更新,此外还集成了NVMe驱动和USB3.0驱动,使用它还可以将累积更新封装到系统内&…...
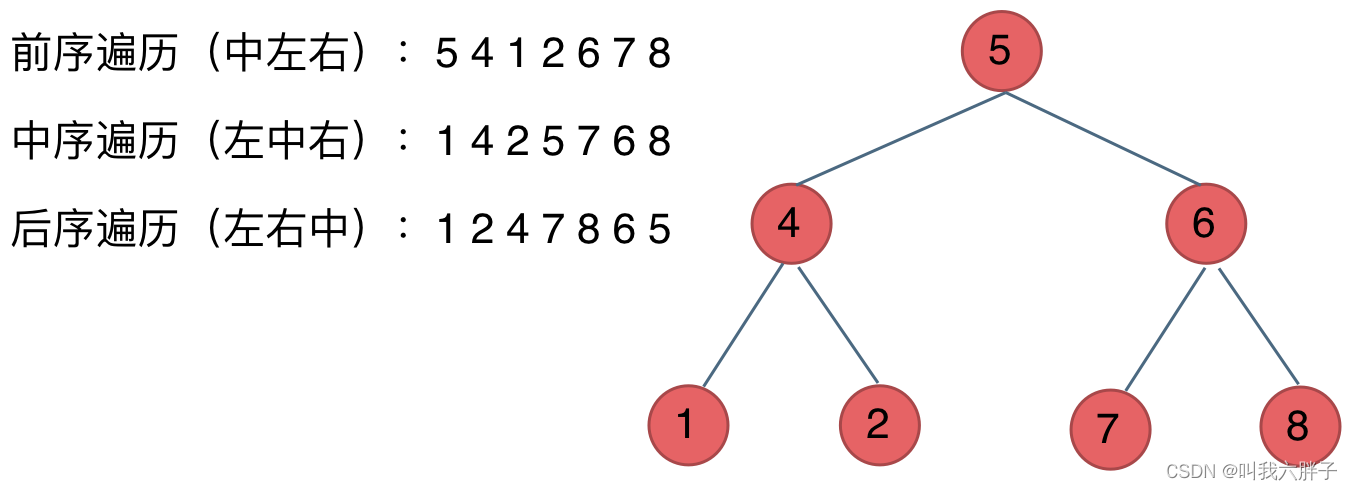
【二叉树】1-5,理论基础、前中后序遍历的递归法和迭代法、层序遍历
理论基础、前中后序遍历的递归法和迭代法、层序遍历 1,二叉树的种类满二叉树完全二叉树二叉搜索树平衡二叉搜索树 2,存储方式链式存储线式存储 3,二叉树的遍历深度优先搜索前序遍历(递归法、迭代法)中序遍历࿰…...

Mybatis-plus动态条件查询QueryWrapper的使用
Mybatis-plus动态条件查询QueryWrapper的使用 一:queryWrapper介绍 queryWrapper是mybatis plus中实现查询的对象封装操作类,可以封装sql对象,包括where条件,order by排序,select哪些字段等等,他的层级关…...
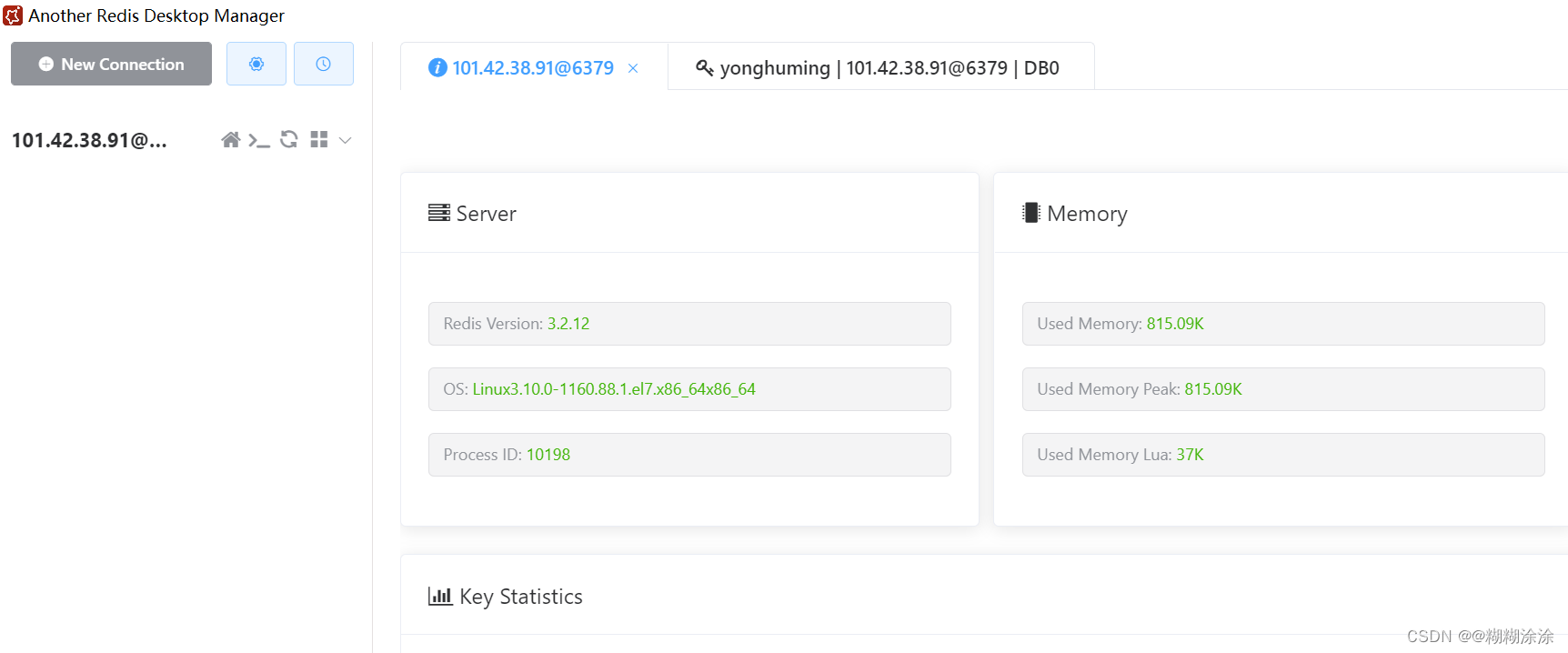
Redis安装配置远程连接
1. yum 安装 redis: 直接使用命令,将 redis 安装到 linux 服务器中: yum -y install redis 2. 启动 redis: 在 xshell 里,可以使用下面命令,以后台方式启动 redis: [rootVM-8-17-centos /]…...
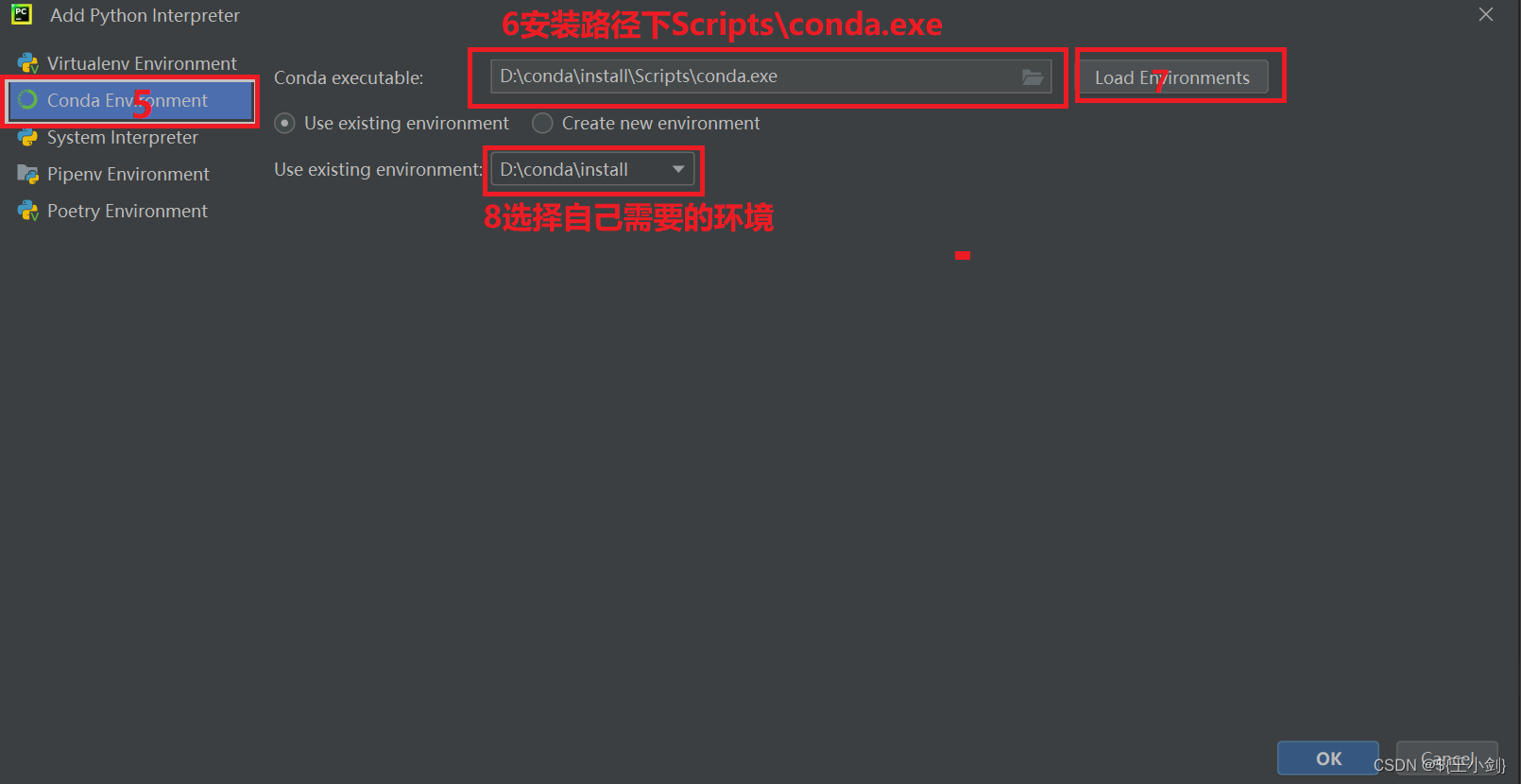
pycharm中配置conda
安装好pycharm和conda后,打开pycharm:...
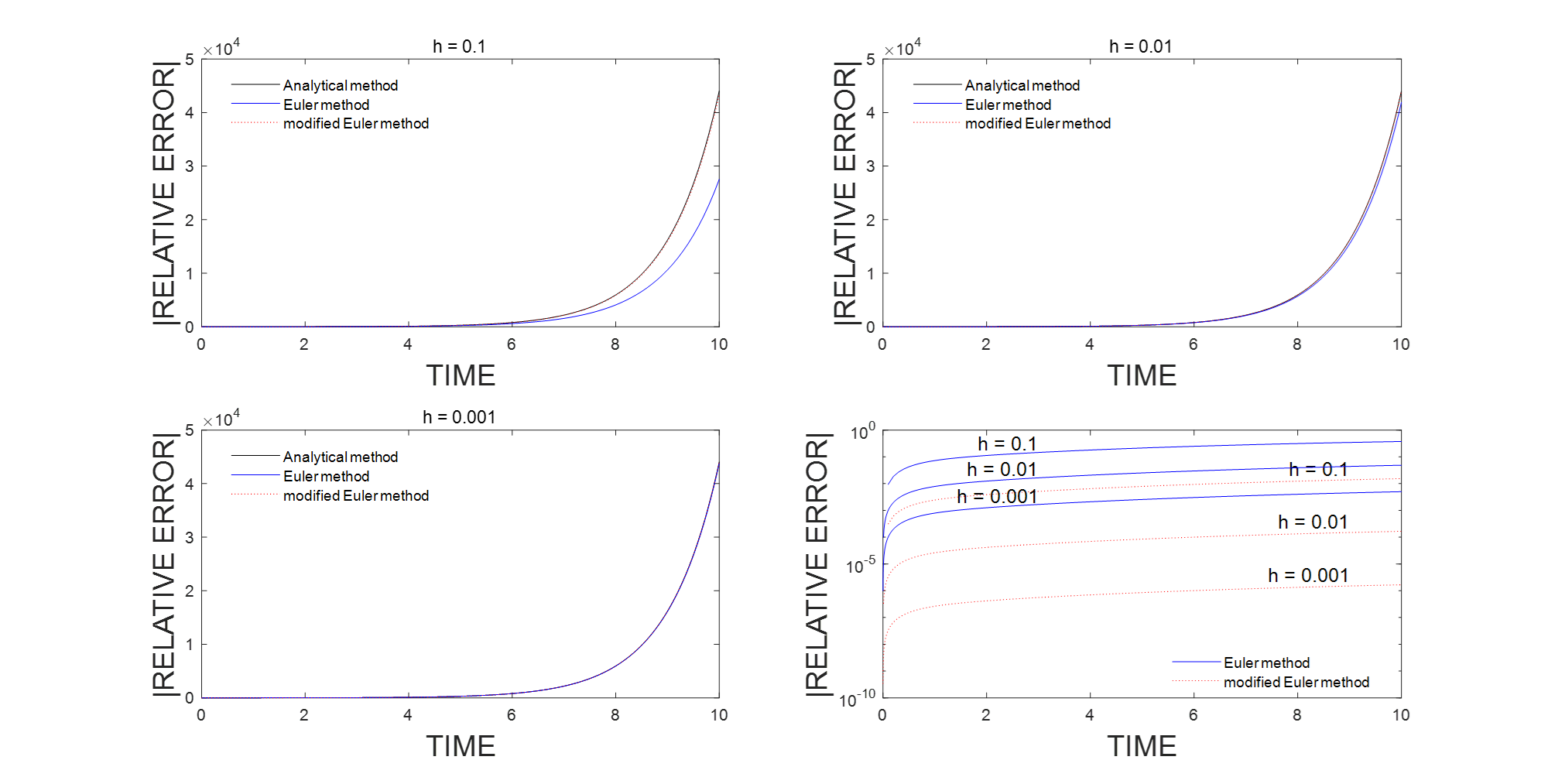
matlab解常微分方程常用数值解法1:前向欧拉法和改进的欧拉法
总结和记录一下matlab求解常微分方程常用的数值解法,本文先从欧拉法和改进的欧拉法讲起。 d x d t f ( x , t ) , x ( t 0 ) x 0 \frac{d x}{d t}f(x, t), \quad x\left(t_{0}\right)x_{0} dtdxf(x,t),x(t0)x0 1. 前向欧拉法 前向欧拉法使用了泰勒展开的第…...
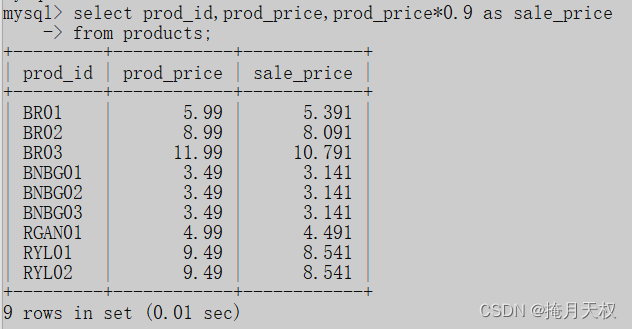
SQL | 计算字段
7-创建计算字段 7.1-计算字段 存储在数据库中的数据一般不是我们所需要的字段格式, 需要公司名称,同时也需要公司地址,但是这两个数据存储在不同的列中。 省,市,县和邮政编码存储在不同的列中,但是当我们…...

leetcode做题笔记67
给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 思路一:模拟题意 void reserve(char* s) {int len strlen(s);for (int i 0; i < len / 2; i) {char t s[i];s[i] s[len - i - 1], s[len - i - 1] t;} }char* addBinary(cha…...
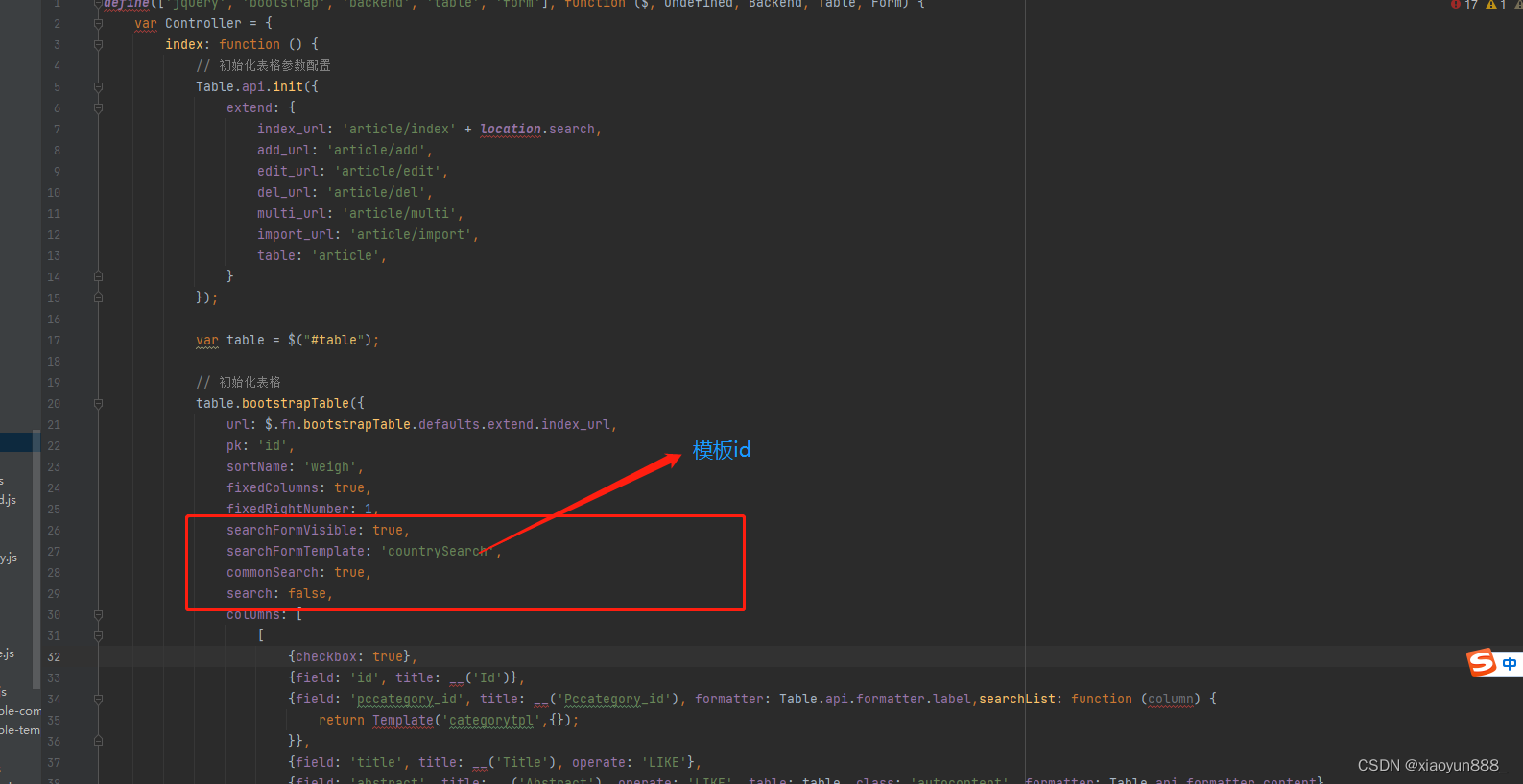
fastadmin 自定义搜索分类和时间范围
1.分类搜索,分类信息获取----php 2.对应html页面,页面底部加搜索提交代码(这里需要注意:红框内容) 图上代码----方便直接复制使用 <script id"countrySearch" type"text/html"><!--form…...

Oracle Data Redaction与Data Pump
如果表定义了Redaction Policy,导出时数据会脱敏吗?本文解答这个问题。 按照Oracle文档Advanced Security Guide第13章,13.6.5的Tutorial,假设表HR.jobs定义了Redaction Policy。 假设HR用户被授予了访问目录对象的权限…...

设计模式(6)原型模式
一、介绍 Java中自带的原型模式是clone()方法。该方法是Object的方法,native类型。他的作用就是将对象的在内存的那一块内存数据一字不差地再复制一个。我们写简单类的时候只需要实现Cloneable接口,然后调用Object::clone方法就可实现克隆功能。这样实现…...

pywinauto结合selenium实现文件上传
简介 PC端-Windows上的元素识别可用viewWizard工具 PC端-Windows上的元素操作可用pywinauto库 浏览器上网页的元素识别可用selenium 安装 pip installer pywinauto 使用须知 pywinauto官方文档 确定app的可访问技术 1、win32 API(backend=“win32”) 一般是MFC、VB6、VC…...
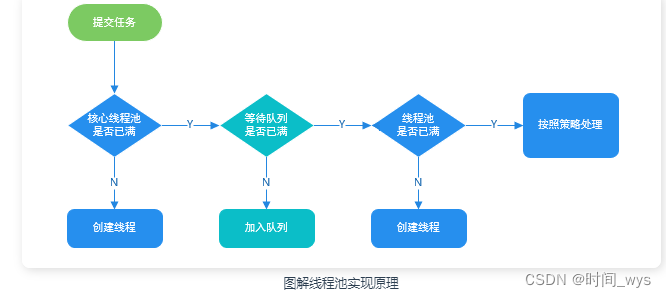
【Java多线程学习7】Java线程池技术
线程池技术 一、什么是线程池 线程池顾名思义是管理一组线程的池子。当有任务要处理时,直接从线程池中获取线程来处理,处理完之后线程不会立即销毁,而是等待下一个任务。 二、为什么要使用线程池? 线程池的作用? 1、降低资源…...
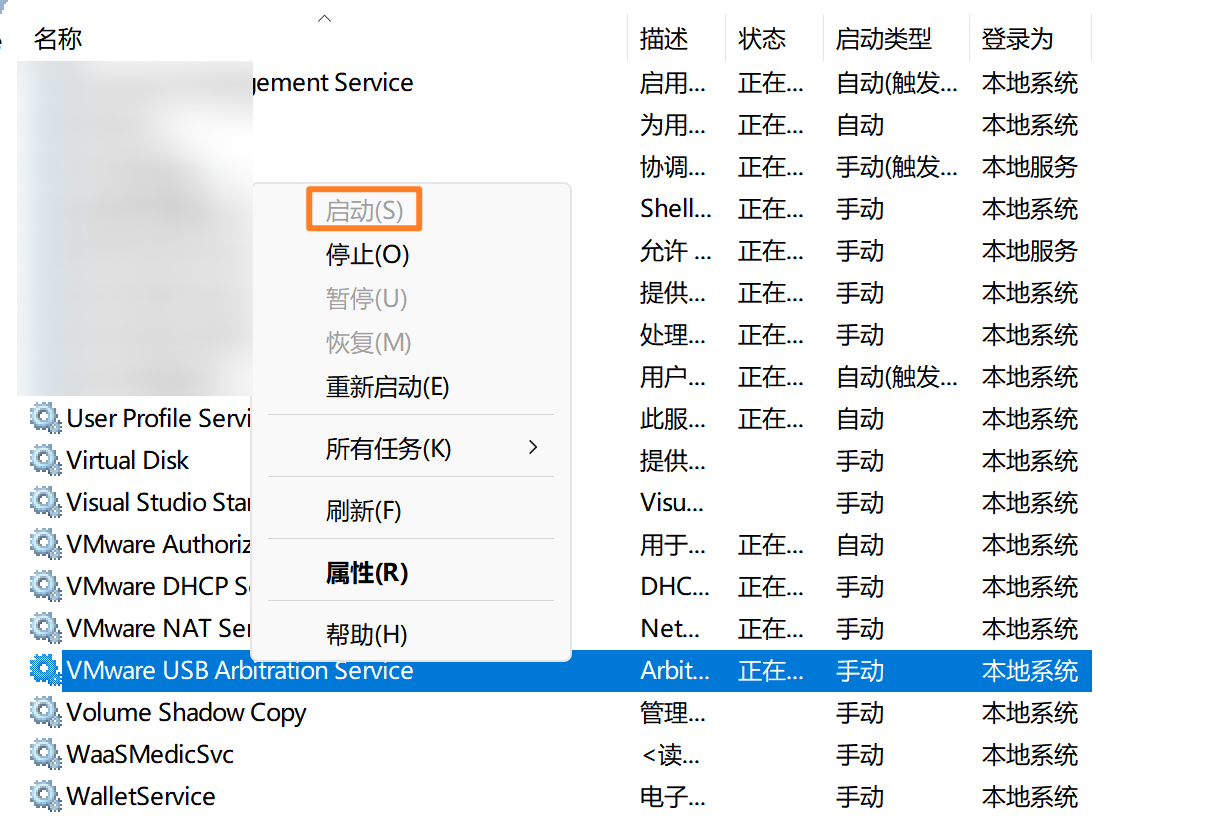
VMware虚拟机NAT模式Ubuntu无法上网解决方案
发现只要NAT模式,ping地址时就报网络不可达,且右上方网络图标消失,但是外部USB网络设备又只能在NAT模式下使用。。。 博主的解决方案如下: 按WinR键入services.msc, 找到VMware DHCP Service、VMware NAT Service和V…...

如何高效在Windows上安装安卓应用:APK安装器完全指南
如何高效在Windows上安装安卓应用:APK安装器完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了笨重的安卓模拟器?想要在Wind…...

高通Camera HAL3开发调试:手把手教你给CAMX节点添加YUV/RAW数据Dump功能
高通Camera HAL3深度调试:CAMX节点YUV/RAW数据Dump实战指南 在移动影像系统的开发中,数据验证环节往往决定着整个图像处理管道的可靠性。当算法效果出现偏差、图像出现异常时,开发者最需要的是能够直接获取原始数据的能力。本文将深入探讨如何…...

Java的@jdk.internal.ValueBased:值对象类的提示注解
Java的jdk.internal.ValueBased注解是JDK内部用于标记值对象类的重要元数据,它为开发者提供了关于不可变性和线程安全的隐式契约。随着函数式编程和不可变对象在现代Java开发中的普及,理解这一注解的深层含义变得尤为关键。本文将深入解析其设计意图、典…...

如何免费解锁八大网盘满速下载:LinkSwift网盘助手完整指南
如何免费解锁八大网盘满速下载:LinkSwift网盘助手完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...
)
告别复制粘贴!实战派教你用Allegro2Altium.bat脚本搞定AD文件转换(附环境变量避坑指南)
告别复制粘贴!实战派教你用Allegro2Altium.bat脚本搞定AD文件转换(附环境变量避坑指南) 在PCB设计领域,文件格式转换一直是工程师们绕不开的痛点。特别是当项目需要从Cadence Allegro迁移到Altium Designer时,网上的教…...

别再只给Gerber了!资深PCB工程师教你用Allegro准备‘板厂友好型’生产文件包
资深PCB工程师的Allegro生产文件包优化指南:从基础导出到板厂友好型交付 在高速PCB设计领域,导出Gerber文件只是与制造厂协作的第一步。真正体现工程师专业度的,是如何将设计意图通过完整的生产文件包准确传达给板厂。我曾见过太多案例——设…...

Claude Code Routines 深度解析:重新定义 AI 辅助编程的工作流自动化
Claude Code Routines 深度解析:重新定义 AI 辅助编程的工作流自动化 在 AI 辅助编程工具井喷的今天,我们正处于一个微妙的转折点。开发者们已经不再满足于简单的"问答式"编程辅助,也不愿仅仅将 AI 作为一个稍微智能一点的代码补全…...

别再乱选TVS管了!手把手教你从USB接口保护案例看懂VRWM、VCL、IPP怎么选
别再乱选TVS管了!手把手教你从USB接口保护案例看懂VRWM、VCL、IPP怎么选 当你的USB设备突然失灵,排除了软件问题后,很可能是接口电路遭遇了瞬态电压冲击。作为硬件工程师,我们每天都在与这些看不见的"电路杀手"搏斗。TV…...

Numbat静态类型系统深度解析:确保科学计算的准确性
Numbat静态类型系统深度解析:确保科学计算的准确性 【免费下载链接】numbat A statically typed programming language for scientific computations with first class support for physical dimensions and units 项目地址: https://gitcode.com/gh_mirrors/nu/n…...

Office自定义界面编辑器:3步打造你的专属Office工作区
Office自定义界面编辑器:3步打造你的专属Office工作区 【免费下载链接】office-custom-ui-editor Standalone tool to edit custom UI part of Office open document file format 项目地址: https://gitcode.com/gh_mirrors/of/office-custom-ui-editor 你是…...