字符串匹配 - 模式预处理:BM 算法 (Boyer-Moore)
各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法,效率非常高。
算法简介
在 1977 年,Robert S. Boyer (Stanford Research Institute) 和 J Strother Moore (Xerox Palo Alto Research Center) 共同发表了文章《A Fast String Searching Algorithm》,介绍了一种新的快速字符串匹配算法。这种算法在逻辑上相对于现有的算法有了显著的改进,它对要搜索的字符串进行倒序的字符比较,并且当字符比较不匹配时无需对整个模式串再进行搜索。
Boyer-Moore 算法的主要特点有:
对模式字符的比较顺序时从右向左;
预处理需要 O(m + σ) 的时间和空间复杂度;
匹配阶段需要 O(m × n) 的时间复杂度;
匹配阶段在最坏情况下需要 3n 次字符比较;
最优复杂度 O(n/m);
在 Naive 算法中,对文本 T 和模式 P 字符串均未做预处理。而在 KMP 算法中则对模式 P 字符串进行了预处理操作,以预先计算模式串中各位置的最长相同前后缀长度的数组。Boyer–Moore 算法同样也是对模式 P 字符串进行预处理。
我们知道,在 Naive 算法中,如果发现模式 P 中的字符与文本 T 中的字符不匹配时,需要将文本 T 的比较位置向后滑动一位,模式 P 的比较位置归 0 并从头开始比较。而 KMP 算法则是根据预处理的结果进行判断以使模式 P 的比较位置可以向后滑动多个位置。Boyer–Moore 算法的预处理过程也是为了达到相同效果。
Boyer–Moore 算法在对模式 P 字符串进行预处理时,将采用两种不同的启发式方法。这两种启发式的预处理方法称为:
坏字符(Bad Character Heuristic):当文本 T 中的某个字符跟模式 P 的某个字符不匹配时,我们称文本 T 中的这个失配字符为坏字符。
好后缀(Good Suffix Heuristic):当文本 T 中的某个字符跟模式 P 的某个字符不匹配时,我们称文本 T 中的已经匹配的字符串为好后缀。
Boyer–Moore 算法在预处理时,将为两种不同的启发法结果创建不同的数组,分别称为 Bad-Character-Shift(or The Occurrence Shift)和 Good-Suffix-Shift(or Matching Shift)。当进行字符匹配时,如果发现模式 P 中的字符与文本 T 中的字符不匹配时,将比较两种不同启发法所建议的移动位移长度,选择最大的一个值来对模式 P 的比较位置进行滑动。
此外,Naive 算法和 KMP 算法对模式 P 的比较方向是从前向后比较,而 Boyer–Moore 算法的设计则是从后向前比较,即从尾部向头部方向进行比较。
图例分析
例子来源于阮一峰的 字符串匹配的Boyer-Moore算法
下面,我根据Moore教授自己的例子来解释这种算法。

假定字符串为"HERE IS A SIMPLE EXAMPLE",搜索词为"EXAMPLE"。

首先,"字符串"与"搜索词"头部对齐,从尾部开始比较。
这是一个很聪明的想法,因为如果尾部字符不匹配,那么只要一次比较,就可以知道前7个字符(整体上)肯定不是要找的结果。
我们看到,"S"与"E"不匹配。这时,"S"就被称为"坏字符"(bad character),即不匹配的字符。我们还发现,"S"不包含在搜索词"EXAMPLE"之中,这意味着可以把搜索词直接移到"S"的后一位。

依然从尾部开始比较,发现"P"与"E"不匹配,所以"P"是"坏字符"。但是,"P"包含在搜索词"EXAMPLE"之中。所以,将搜索词后移两位,两个"P"对齐。
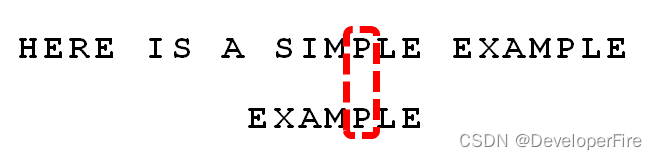
我们由此总结出"坏字符规则":
后移位数 = 坏字符的位置 - 搜索词中的上一次出现位置
如果"坏字符"不包含在搜索词之中,则上一次出现位置为 -1。
以"P"为例,它作为"坏字符",出现在搜索词的第6位(从0开始编号),在搜索词中的上一次出现位置为4,所以后移 6 - 4 = 2位。再以前面第二步的"S"为例,它出现在第6位,上一次出现位置是 -1(即未出现),则整个搜索词后移 6 - (-1) = 7位。

依然从尾部开始比较,"E"与"E"匹配。
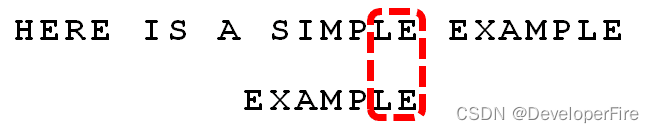
比较前面一位,"LE"与"LE"匹配。
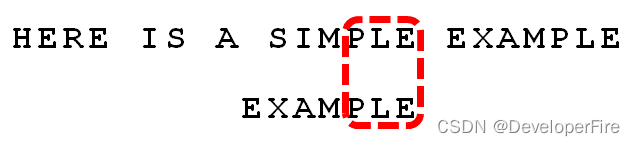
比较前面一位,"PLE"与"PLE"匹配。

比较前面一位,"MPLE"与"MPLE"匹配。我们把这种情况称为"好后缀"(good suffix),即所有尾部匹配的字符串。注意,"MPLE"、"PLE"、"LE"、"E"都是好后缀。
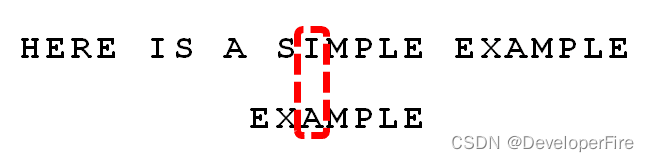
比较前一位,发现"I"与"A"不匹配。所以,"I"是"坏字符"。
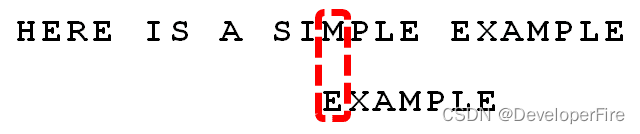
根据"坏字符规则",此时搜索词应该后移 2 - (-1)= 3 位。问题是,此时有没有更好的移法?

我们知道,此时存在"好后缀"。所以,可以采用"好后缀规则":
后移位数 = 好后缀的位置 - 搜索词中的上一次出现位置
举例来说,如果字符串"ABCDAB"的后一个"AB"是"好后缀"。那么它的位置是5(从0开始计算,取最后的"B"的值),在"搜索词中的上一次出现位置"是1(第一个"B"的位置),所以后移 5 - 1 = 4位,前一个"AB"移到后一个"AB"的位置。
再举一个例子,如果字符串"ABCDEF"的"EF"是好后缀,则"EF"的位置是5 ,上一次出现的位置是 -1(即未出现),所以后移 5 - (-1) = 6位,即整个字符串移到"F"的后一位。
这个规则有三个注意点:
"好后缀"的位置以最后一个字符为准。假定"ABCDEF"的"EF"是好后缀,则它的位置以"F"为准,即5(从0开始计算)。
如果"好后缀"在搜索词中只出现一次,则它的上一次出现位置为 -1。比如,"EF"在"ABCDEF"之中只出现一次,则它的上一次出现位置为-1(即未出现)。
如果"好后缀"有多个,则除了最长的那个"好后缀",其他"好后缀"的上一次出现位置必须在头部。比如,假定"BABCDAB"的"好后缀"是"DAB"、"AB"、"B",请问这时"好后缀"的上一次出现位置是什么?回答是,此时采用的好后缀是"B",它的上一次出现位置是头部,即第0位。这个规则也可以这样表达:如果最长的那个"好后缀"只出现一次,则可以把搜索词改写成如下形式进行位置计算"(DA)BABCDAB",即虚拟加入最前面的"DA"。
回到上文的这个例子。此时,所有的"好后缀"(MPLE、PLE、LE、E)之中,只有"E"在"EXAMPLE"还出现在头部,所以后移 6 - 0 = 6位。

可以看到,"坏字符规则"只能移3位,"好后缀规则"可以移6位。所以,Boyer-Moore算法的基本思想是,每次后移这两个规则之中的较大值。
更巧妙的是,这两个规则的移动位数,只与搜索词有关,与原字符串无关。因此,可以预先计算生成《坏字符规则表》和《好后缀规则表》。使用时,只要查表比较一下就可以了。

继续从尾部开始比较,"P"与"E"不匹配,因此"P"是"坏字符"。根据"坏字符规则",后移 6 - 4 = 2位。

从尾部开始逐位比较,发现全部匹配,于是搜索结束。如果还要继续查找(即找出全部匹配),则根据"好后缀规则",后移 6 - 0 = 6位,即头部的"E"移到尾部的"E"的位置。
从上面的示例描述可以看出,Boyer–Moore 算法的精妙之处在于,其通过两种启示规则来计算后移位数,且其计算过程只与模式 P 有关,而与文本 T 无关。因此,在对模式 P 进行预处理时,可预先生成 "坏字符规则之向后位移表" 和 "好后缀规则之向后位移表",在具体匹配时仅需查表比较两者中最大的位移即可。
相关文章:
字符串匹配 - 模式预处理:BM 算法 (Boyer-Moore)
各种文本编辑器的"查找"功能(CtrlF),大多采用Boyer-Moore算法,效率非常高。算法简介在 1977 年,Robert S. Boyer (Stanford Research Institute) 和 J Strother Moore (Xerox Palo Alto Research Center) 共…...

RV1126笔记三十:freetype显示矢量字体
若该文为原创文章,转载请注明原文出处。 在前面介绍了使用取模软件,可以自定义OSD,这种做法相对不灵活,也无法变更,适用大部分场景。 如果使用opencv需要移植opencv,芯片资源相对要相比好,而且移植比freetype复杂。 这里记录下如何使用freetype显示矢量字体,使用fre…...

polkit pkexec 本地提权漏洞修复方案
polkit pkexec 本地提权漏洞 漏洞细节,polkit pkexec 中对命令行参数处理有误,导致参数注入,能够导致本地提权。 解决建议 1、无法升级软件修复包的,可使用以下命令删除pkexec的SUID-bit权限来规避漏洞风险: chmod 0…...

es-06聚合查询
聚合查询 概念 聚合(aggs)不同于普通查询,是目前学到的第二种大的查询分类,第一种即“query”,因此在代码中的第一层嵌套由“query”变为了“aggs”。用于进行聚合的字段必须是exact value,分词字段不可进行…...

面试知识点准备与总结——(并发篇)
目录线程有哪些状态线程池的核心参数sleep和wait的区别lock 与 synchronized 的异同volatile能否保证线程安全悲观锁和乐观锁的区别Hashtable 与 ConcurrentHashMap 的区别ConcurrentHashMap1.7和1.8的区别ThreadLocal的理解ThreadLocalMap中的key为何要设置为弱引用线程有哪些…...
Django框架之模型视图-URLconf
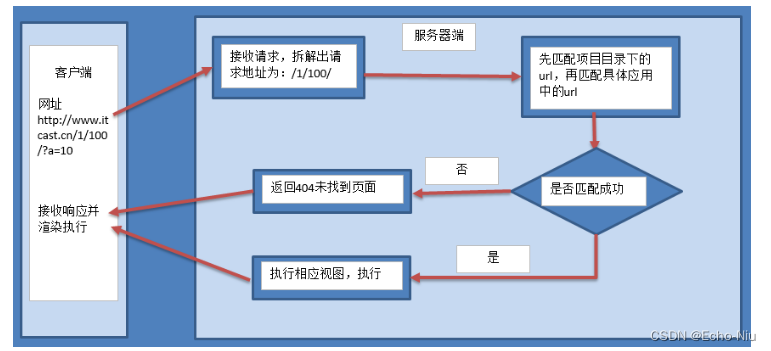
URLconf 浏览者通过在浏览器的地址栏中输入网址请求网站对于Django开发的网站,由哪一个视图进行处理请求,是由url匹配找到的 配置URLconf 1.settings.py中 指定url配置 ROOT_URLCONF 项目.urls2.项目中urls.py 匹配成功后,包含到应用的urls…...
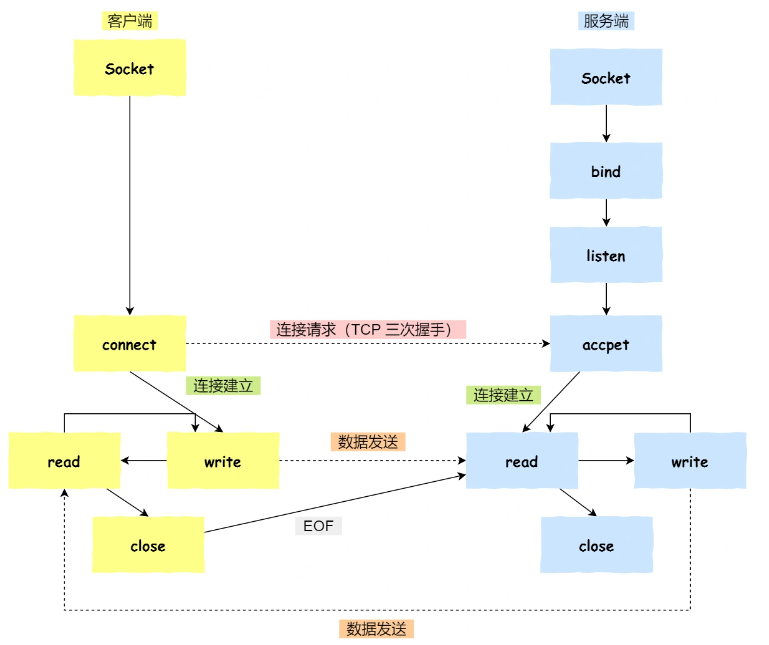
操作系统闲谈06——进程管理
操作系统闲谈06——进程管理 一、进程调度 01 时间片轮转 给每一个进程分配一个时间片,然后时间片用完了,把cpu分配给另一个进程 时间片通常设置为 20ms ~ 50ms 02 先来先服务 就是维护了一个就绪队列,每次选择最先进入队列的进程&#…...

DaVinci 偏好设置:用户 - UI 设置
偏好设置 - 用户/ UI 设置Preferences - User/ UI Settings工作区选项Workspace Options语言Language指定 DaVinci Resolve 软件界面所使用的语言。目前支持英语、简体中文、日语、西班牙语、葡萄牙语、法语、俄语、泰语和越南语等等。启动时重新加载上一个工作项目Reload last…...
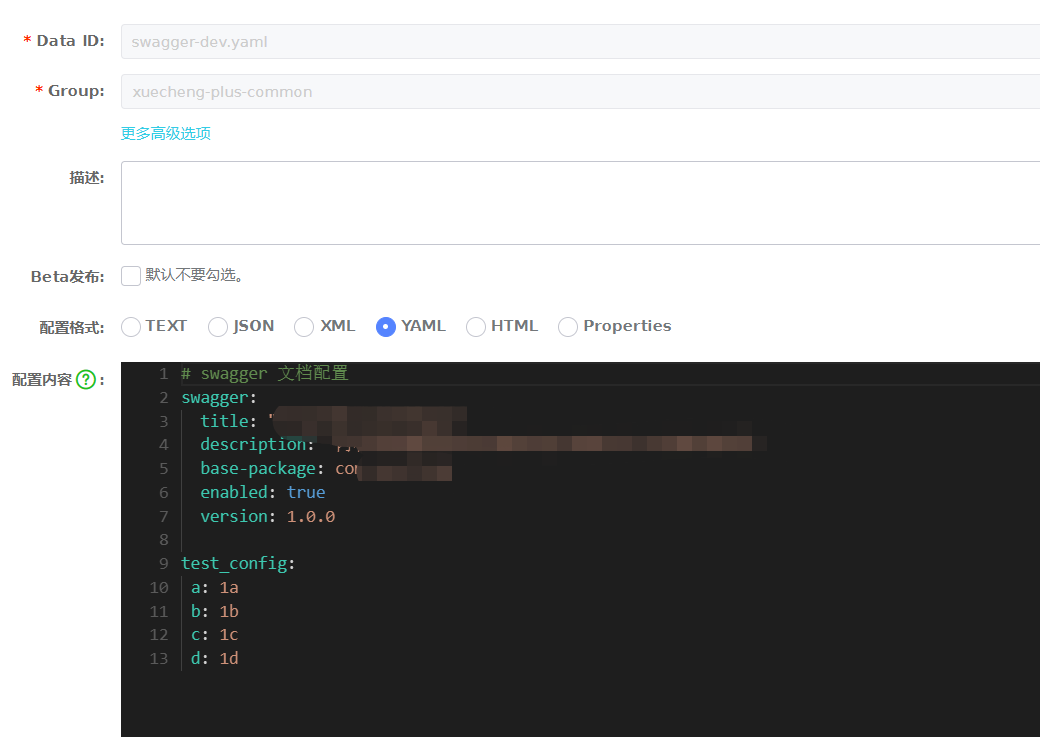
Nacos超简单-管理配置文件
优点理论什么的就不说了,按照流程开始配配置吧。登录Centos,启动Naocs,使用sh /data/soft/restart.sh将自动启动Nacos。访问:http://192.168.101.65:8848/nacos/账号密码:nacos/nacos分为两部分,第一部分准…...
基于微信小程序的中国各地美食推荐平台小程序
文末联系获取源码 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.…...

如何优雅的导出函数
在开发过程中,经常会引用外部函数。方法主要有两种: 方法一:包含头文件并制定lib位置 优点:使用简单缺点:lib和vs版本有关,不同的版本和编译模式可能导致编译失败 方法二:GetProcAddress 优…...

c++多重继承
1.概论多重继承是否有必要吗?这个问题显然是一个哲学问题,正确的解答方式是根据情况来看,有时候需要,有时候不需要,这显然是一句废话,有点像上马克思主义哲学或者中庸思。但是这个问题和那些思想一样&#…...
15_FreeRtos计数信号量优先级翻转互斥信号量
目录 计数型信号量 计数型信号量相关API函数 计数型信号量实验源码 优先级翻转简介 优先级翻转实验源码 互斥信号量 互斥信号量相关API函数 互斥信号量实验源码 计数型信号量 计数型信号量相当于队列长度大于1的队列,因此计数型信号量能够容纳多个资源,这在…...
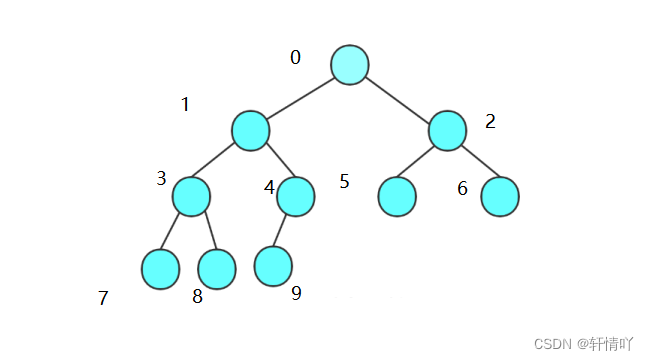
二叉树(一)
二叉树(一)1.树的概念2.树的相关概念3.树的表示4.树在实际中的运用5.二叉树概念及结构6.特殊的二叉树7.二叉树的性质🌟🌟hello,各位读者大大们你们好呀🌟🌟 🚀🚀系列专栏…...
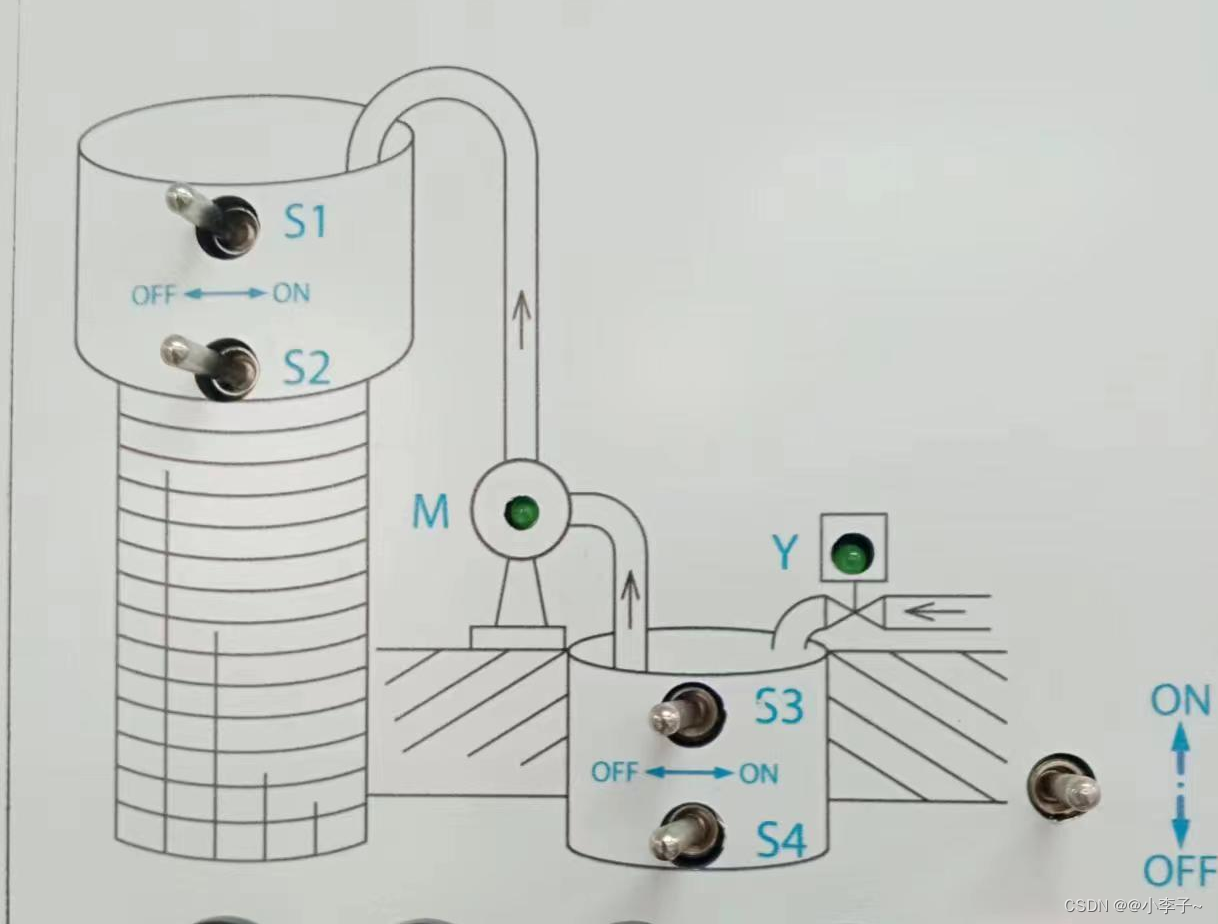
【SCL】1200案例:天塔之光数码管显示液体混合水塔水位
使用scl编写天塔之光&数码管显示&液体混合&水塔水位 文章目录 目录 文章目录 前言 一、案例1:天塔之光 1.控制要求 2.编写程序 3.效果 二、案例2:液体混合 1.控制要求 2.编写程序 三、案例3:数码管显示 1.控制要求 2.编写程序 3…...
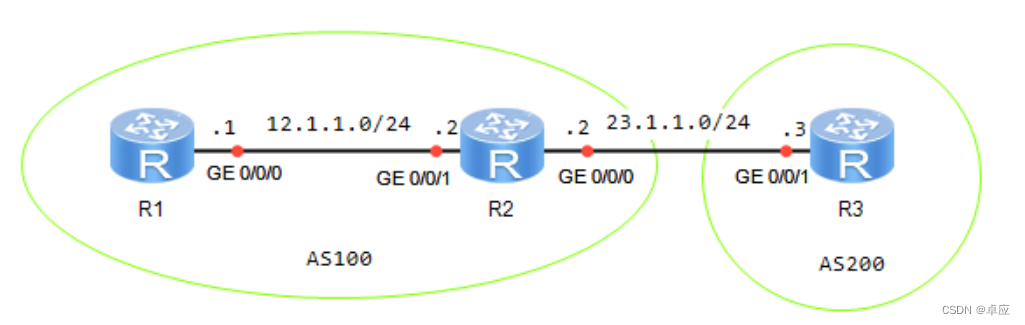
5.1配置IBGP和EBGP
5.2.1实验1:配置IBGP和EBGP 实验目的 熟悉IBGP和EBGP的应用场景掌握IBGP和EBGP的配置方法 实验拓扑 实验拓扑如图5-1所示: 图5-1:配置IBGP和EBGP 实验步骤 IP地址的配置 R1的配置 <Huawei>system-view Enter system view, return …...
c++中超级详细的一些知识,新手快来
目录 2.文章内容简介 3.理解虚函数表 3.1.多态与虚表 3.2.使用指针访问虚表 4.对象模型概述 4.1.简单对象模型 4.2.表格驱动模型 4.3.非继承下的C对象模型 5.继承下的C对象模型 5.1.单继承 5.2.多继承 5.2.1一般的多重继承(非菱形继承) 5.2…...

[答疑]经营困难时期谈建模和伪创新-长点心和长点良心
leonll 2022-11-26 9:53 我们今年真是太难了……(此处删除若干字)……去年底就想着邀请您来给我们讲课,现在也没有实行。我想再和我们老大提,您觉得怎么说个关键理由,这样的形势合适引进UML开发流程? UML…...

计算机基础知识
计算机网络的拓扑结构 一、OSI 7层网络模型是指什么? 7层分别是什么?每层的作用是什么? OSI7层模型是 国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系。 每层功能:(自底向上) 物理层:建立、…...
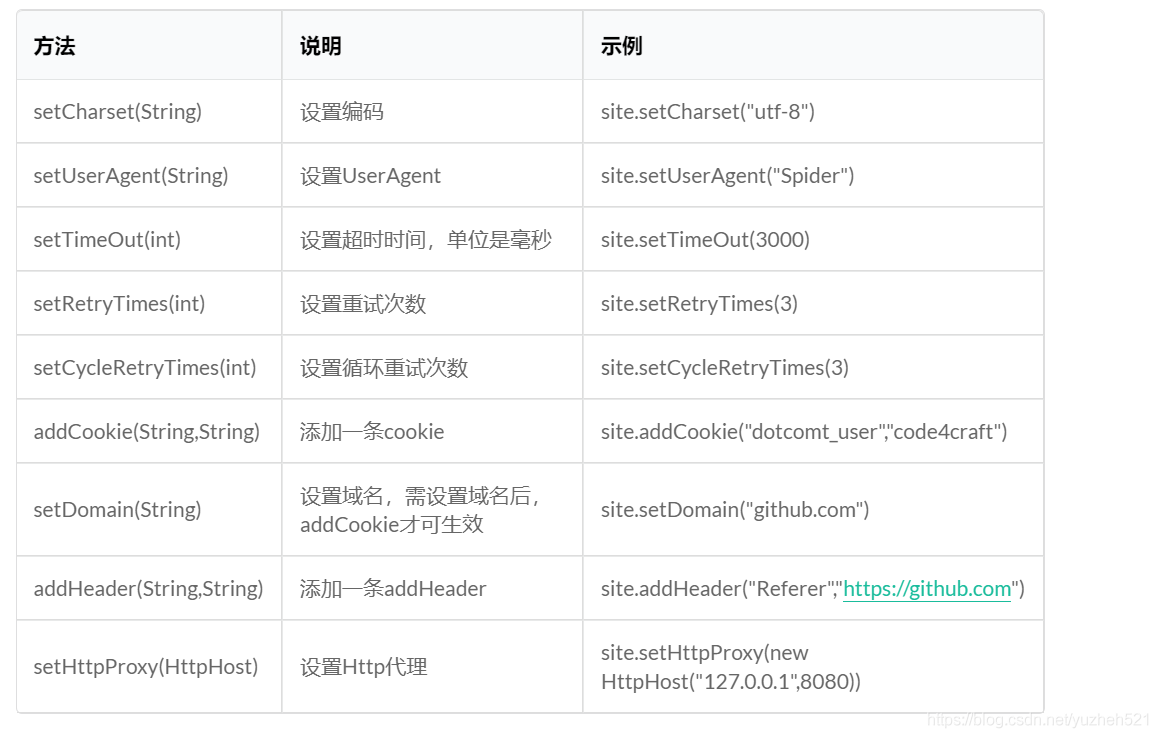
Java爬虫—WebMagic
一,WebMagic介绍WebMagic企业开发,比HttpClient和JSoup更方便一),WebMagic架构介绍WebMagic有DownLoad,PageProcessor,Schedule,Pipeline四大组件,并有Spider将他们组织起来…...

学习信息系统项目管理师我们以什么视角学习?
如果你只是死记硬背那些定义,你会觉得这本书枯燥乏味,而且做题时很容易掉进陷阱。但如果你**“入戏”**,把自己当成那个掌握全局的项目经理,很多答案你凭直觉就能选对。为了帮你把“入戏”进行到底,我给你三个**“入戏…...

【UE5】EnhancedInput进阶实战:从基础绑定到模块化设计
1. EnhancedInput系统概述与核心优势 第一次接触UE5的EnhancedInput系统时,我完全被它的灵活性震惊了。相比传统输入处理方式,这套系统就像从手动挡汽车升级到了自动驾驶——不仅能识别简单的按键动作,还能精确捕捉输入设备的压力感应、手势轨…...

pgwatch2监控指标详解:从基础性能到高级洞察
pgwatch2监控指标详解:从基础性能到高级洞察 【免费下载链接】pgwatch2 PostgreSQL metrics monitor/dashboard 项目地址: https://gitcode.com/gh_mirrors/pg/pgwatch2 pgwatch2是一款功能强大的PostgreSQL metrics monitor/dashboard工具,它能够…...

Pinia Colada:革命性Vue数据获取层的完整入门指南
Pinia Colada:革命性Vue数据获取层的完整入门指南 【免费下载链接】pinia-colada 🍹 The smart data fetching layer for Vue 项目地址: https://gitcode.com/gh_mirrors/pi/pinia-colada Pinia Colada是Vue生态系统中一款革命性的数据获取层解决…...

H3C HCL模拟器实战:IS-IS单区域基础配置与排错指南
1. 实验目标与网络环境准备如果你正在学习网络路由协议,特别是运营商级网络常用的IS-IS,那么通过模拟器进行实操是绕不开的一步。这次我用H3C的HCL模拟器,带大家走一遍IS-IS单区域的基本配置。这个实验的目标很明确:不是让你死记硬…...

Win11Debloat终极指南:如何轻松优化Windows 11系统性能
Win11Debloat终极指南:如何轻松优化Windows 11系统性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and c…...

GDB断点管理保姆级指南:从查看、删改到批量操作,告别调试混乱
GDB断点管理保姆级指南:从查看、删改到批量操作,告别调试混乱 调试大型C/C项目时,断点管理往往成为工程师的痛点。想象一下,当你在一个包含数十个源文件的项目中设置了50多个断点,每次调试时都要在密密麻麻的断点列表中…...

构筑城市“数字底座”!全要素数据标准建设
城市运行管理服务平台的核心竞争力在于其建立了统一、规范的城市运行管理服务数据库。依据《城市运行管理服务平台数据标准》(CJ/T545),我们的技术方案实现了对城市管理全要素的数字化映射。这不仅仅是简单的数据录入,而是构建了一…...

对比直接采购使用Taotoken Token Plan套餐在长期开发中的成本优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接采购与使用Taotoken Token Plan套餐在长期开发中的成本优势 在长期的技术项目开发中,模型API调用成本是团队必…...

C++定时器实战:从线程轮询到时间轮算法的演进与选型
1. 定时器技术选型的核心痛点 当我们需要在C项目中实现定时任务调度时,最直观的做法可能就是直接开个线程轮询了。我刚开始做网络服务开发时也这么干过,结果上线后CPU直接飙到90%——这就是典型的"新手陷阱"。实际上,定时器的实现方…...