Java爬虫—WebMagic
一,WebMagic介绍
WebMagic企业开发,比HttpClient和JSoup更方便
一),WebMagic架构介绍
WebMagic有DownLoad,PageProcessor,Schedule,Pipeline四大组件,并有Spider将他们组织起来,这四大组件对应就是爬虫的下载,处理,管理,持久化等功能。
Spider将这几个组件串联起来,让他们可以相互交互,流程化执行,可以认为Spider是一个巨大的容器,他也是webMagic逻辑的核心
WebMagic框架:
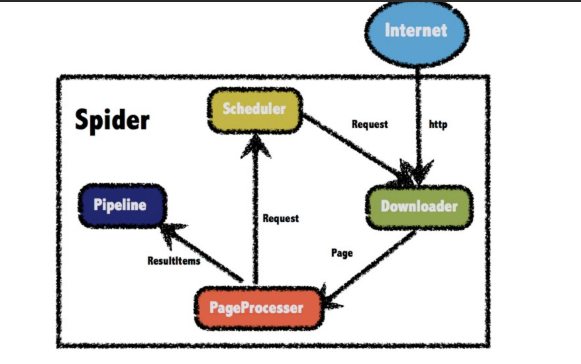
1,DownLoad负责从互联网上下载页面交给PageProcessor处理,WebMagic使用Apache HttpClient作为下载工具。
2,PageProcessor负责解析页面,抽取有用数据,以及发现新的链接。WebMagic使用Jsoup作为解析HTML工具,并基于其开发了解析Xpath的Xsoup。
四个组件中,PageProcessor对于每个站点都不一样,需要使用者自行定义。
3,Schedule负责管理抓取的URL,以及一些去重工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合进行去重。也支持Redis的分布式管理。
4,Pipeline负责抽取结果的计算,持久化到文件,数据库等。WebMagic默认提供“输出到控制台”和保存到文件两种处理方案。
如果需要保存到数据库,则需要编写对应的Pipeline,对于一类需求,一般只需要编写一个Pipeline。
二),用于数据流转的对象
1,request
request是对URL地址的一层封装,一个request对应一个URL;
他是PageProcessor和DownLoad交互的载体,也是PageProdessor控制Download的唯一方式。
除了URL本身,还包含一盒key-value结构的完整字段extra,可以在extra中保存一些特殊的属性,然后在其他地方进行读取,以及完成不同的功能。
2,page
Page及使用Download下载的页面——可能是一个HTML,也可能是JSON或者其他文本。
Page是WebMagic抽取数据的核心对象,他提供了一些方法可供抽取、结果保存等。
3,ResuleItems
ResultItems相当于一个Map,他用于保存PageProcessor处理的结果,供Pipeline使用。他的API和Map类似,但有一个字段skip,若设置为true,则不会被Pipeline处理。
二,入门程序
添加打印日志配置文件
log4j.rootLogger=INFO,A1 log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH🇲🇲ss,SSS} [%t] [%c]-[%p] %m%n
引入WebMagic的依赖
<!--webMagic依赖--><dependency><groupId>us.codecraft</groupId><artifactId>webmagic-core</artifactId><version>0.7.4</version></dependency><dependency><groupId>us.codecraft</groupId><artifactId>webmagic-extension</artifactId><version>0.7.4</version></dependency>public class JobProcessor implements PageProcessor {//page:解析的页面,由Spider容器处理。public void process(Page page) {//解析page,并将结果以key——value的形式保存在ResultItems中//page.getHtml():获取html,也就是dom文档//.css():selector选择器//"head > title":head的直接子标签//以css方式获取page.putField("title",page.getHtml().css("head > title"));//Xpath方式获取page.putField("div",page.getHtml().xpath("//div[@id=shortcut-2014]/div/ul/li/a"));//css方式获取page.putField("div1",page.getHtml().css("div#shortcut-2014 div.w ul.fr > li > a"));//正则表达式page.putField("div2",page.getHtml().css("div#shortcut-2014 div.w ul.fr > li > a").regex(".*你好.*").all());}private Site site = Site.me();public Site getSite() {return site;}public static void main(String[] args) {Spider.create(new JobProcessor()).addUrl("https://kuaibao.jd.com/")//添加需要爬取的网页url.run();//执行//不需要执行打印,不设置输入流的位置,WebMagic默认输出在控制台}
}三,PageProcessor分析抽取页面元素
Xpath, 使用路径表达式来选取 XML 文档中的节点或节点集
CSS选择器 (同jquery选择器用法)
正则表达式, 一般用于获取url地址
WebMagic下Selectable抽取元素API
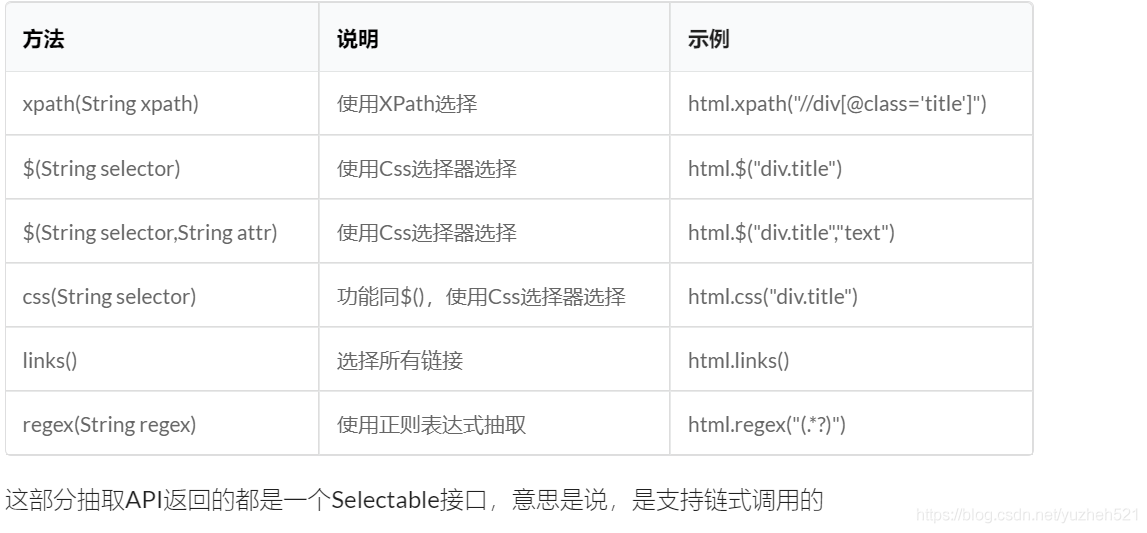
WebMagic处理结果的API
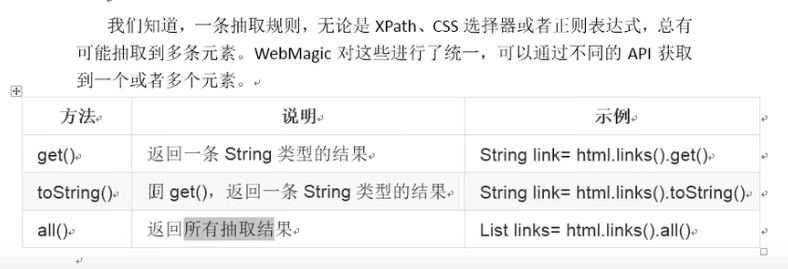
page.putField("div3",page.getHtml().xpath("//div[@id=shortcut-2014]/div/ul/li/a").get());//在结果中抽取一条数据,默认第一条page.putField("div3",page.getHtml().xpath("//div[@id=shortcut-2014]/div/ul/li/a").toString());//在结果中抽取一条数据,默认第一条page.putField("div3",page.getHtml().xpath("//div[@id=shortcut-2014]/div/ul/li/a").all());//获取结果的全部数据Schedule获取链接:page.addTargetRequest()
page.addTargetRequest(page.getHtml().xpath("//div[@id=shortcut-2014]/div/ul/li/a").links().get());//获取查询结果的第一条超链接page.putField("title",page.getHtml().css("head > title"));
四,Pipeline保存结果
WebMagic用于保存结果的组件叫做Pipeline,默认输出到控制是同一个内置的Pipeline——consolePipeline,如果想要输出到文件,只讲Pipeline换成FilePipeline就可以。
public static void main(String[] args) {Spider.create(new JobProcessor()).addUrl("https://kuaibao.jd.com/")//添加需要爬取的网页url//不添加addPipeline则会将结果输出在控制台.addPipeline(new FilePipeline("C:\\Users\\admin\\Desktop\\result\\"))//将结果保存在文件中.thread(5)//设置多线程.run();//执行//不需要执行打印,不设置输入流的位置,WebMagic默认输出在控制台}五,爬虫的配置、启动和终止
Sipder是爬虫启动的入口,我们需要在启动爬虫前使用一个pageProcessor创建一个Spider对象,然后使用run()启动。
设置Spider组件都可以采用set方法进行设置
爬虫设置Site
Site.me()可以对爬虫进行一些配置,包括编码,抓取间隔,超时时间,重复次数等。
private Site site = Site.me().setCharset("utf8") //设置编码.setTimeOut(10 * 1000) //设置超时间.setRetryTimes(3) // 设置重复次数.setRetrySleepTime(3 * 1000); // 设置重试时间间隔public Site getSite() {return site;}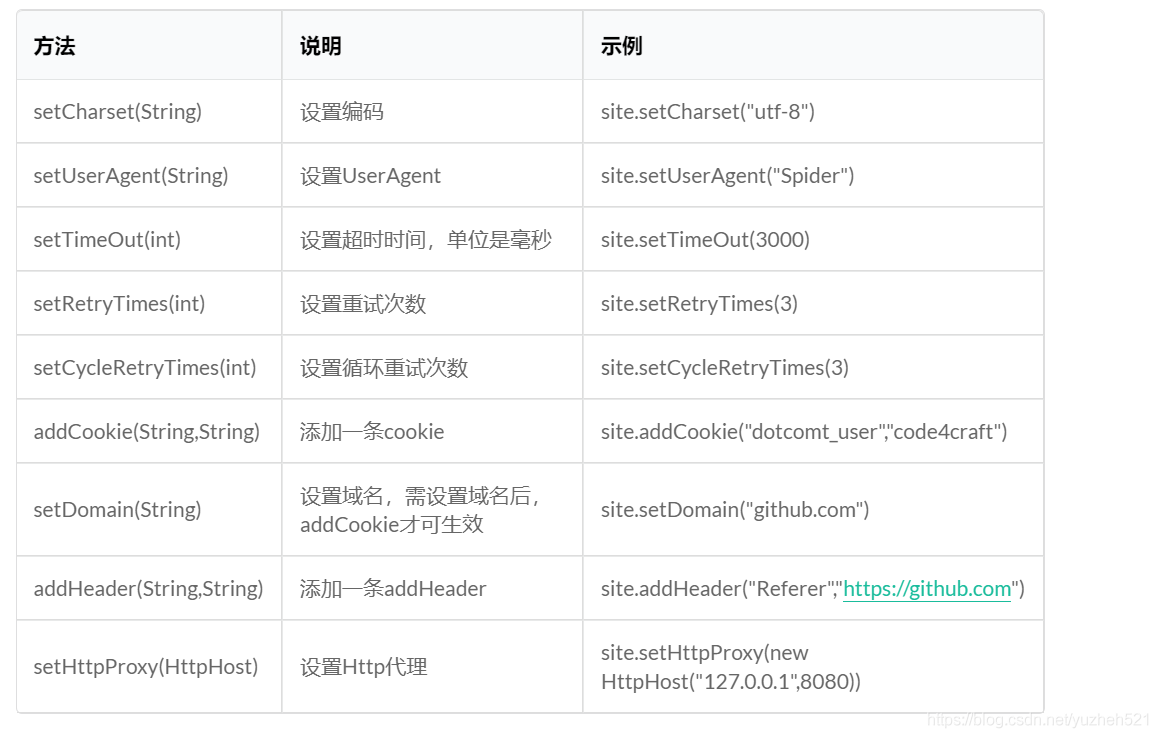
六, 爬虫分类
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的
通用网络爬虫
通用网络爬虫又称全网爬虫(Scalable Web Crawler),爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。
这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,但需要较长时间才能刷新一次页面。 简单的说就是互联网上抓取所有数据。
聚焦网络爬虫
聚焦网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler),是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。
和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求 。简单的说就是互联网上只抓取某一种数据。
增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是 指 对 已 下 载 网 页 采 取 增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。简单的说就是互联网上只抓取刚刚更新的数据。
Deep Web 爬虫
Web 页面按存在方式可以分为表层网页(Surface Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。
表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面。Deep Web 是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词或者登陆后才能获得的 Web 页面
相关文章:
Java爬虫—WebMagic
一,WebMagic介绍WebMagic企业开发,比HttpClient和JSoup更方便一),WebMagic架构介绍WebMagic有DownLoad,PageProcessor,Schedule,Pipeline四大组件,并有Spider将他们组织起来…...

[软件工程导论(第六版)]第2章 可行性研究(复习笔记)
文章目录2.1 可行性研究的任务2.2 可行性研究过程2.3 系统流程图2.4 数据流图概念2.5 数据字典2.6 成本/效益分析2.1 可行性研究的任务 可行性研究的目的 用最小的代价在尽可能短的时间内确定问题是否能够解决。 可行性研究的3个方面 (1)技术可行性&…...
Mac下安装Tomcat以及IDEA中的配置
安装brew 打开终端输入以下命令: /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" 搜索tomcat版本,输入以下命令: brew search tomcat 安装自己想要的版本,例…...
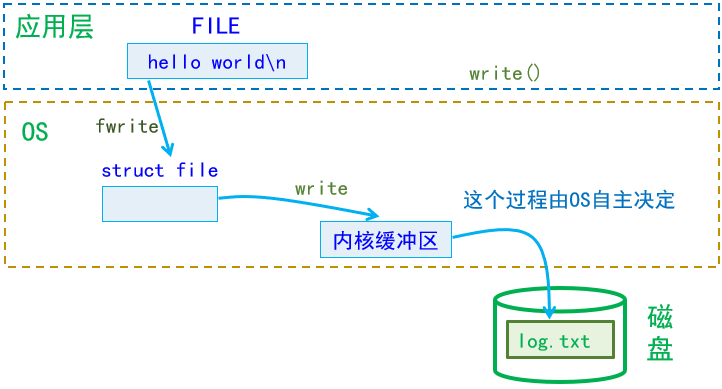
【Linux详解】——文件基础(I/O、文件描述符、重定向、缓冲区)
📖 前言:本期介绍文件基础I/O。 目录🕒 1. 文件回顾🕘 1.1 基本概念🕘 1.2 C语言文件操作🕤 1.2.1 概述🕤 1.2.2 实操🕤 1.2.3 OS接口open的使用(比特位标记)…...

HomMat2d
1.affine_trans_region(区域的任意变换) 2.hom_mat2d_identity(创建二位变换矩阵) 3.hom_mat2d_translate(平移) 4.hom_mat2d_scale(缩放) 5.hom_mat2d_rotate(旋转 &…...
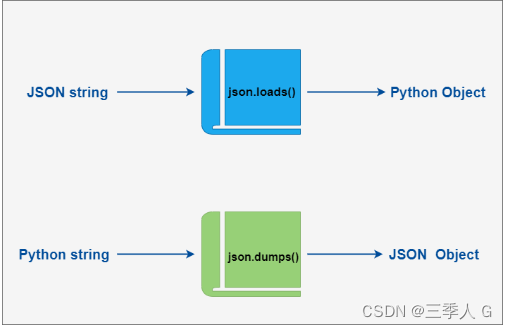
Python3 JSON 数据解析
Python3 JSON 数据解析 JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。 Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数: json.dumps(): 对数据进行编码。json.loads(): 对数据进行解码。 在 json 的编解码…...
Homebrew 安装遇到的问题
Homebrew 安装遇到的问题 例如:第一章 Python 机器学习入门之pandas的使用 文章目录Homebrew 安装遇到的问题前言一、安装二、遇到的问题1.提示 zsh: command not found: brew三、解决问题前言 使用 Homebrew 能够 安装 Apple(或您的 Linux 系统&#…...

Metasploit框架基础(二)
文章目录前言一、Meatsplooit的架构二、目录结构datadocumentationlibmodulesplugins三、Measploit模块四、Metasploit的使用前言 Metasploit是用ruby语言开发的,所以你打开软件目录,会发现很多.rb结尾的文件。ruby是一门OOP的语言。 一、Meatsplooit的…...

c++容器
1、vector容器 1.1性质 a)该容器的数据结构和数组相似,被称为单端数组。 b)在存储数据时不是在原有空间上往后拓展,而是找到一个新的空间,将原数据深拷贝到新空间,释放原空间。该过程被称为动态拓展。 vec…...

Vue.js如何实现对一千张图片进行分页加载?
目录 vue处理一千张图片进行分页加载 分页加载、懒加载---概念介绍: 思路: 开发过程中,如果后端一次性返回你1000多条图片或数据,那我们前端应该怎么用什么思路去更好的渲染呢? 第一种:我们可以使用分页…...
)
计算机网络复习(六)
考点:MIME及其编码(base64,quoted-printable)网络协议http是基于什么协议,应用层到网络层基于什么协议6-27.试将数据 11001100 10000001 00111000 进行 base64 编码,并得到最后传输的 ASCII 数据。答:先将 24 比特的二…...

Redis进阶:布隆过滤器(Bloom Filter)及误判率数学推导
1 缘起 有一次偶然间听到有同事在说某个项目中使用了布隆过滤器, 哎呦,我去,我竟然不知道啥是布隆过滤器, 这我哪能忍?其实,也可以忍,但是,可能有的面试官不能忍!&#…...
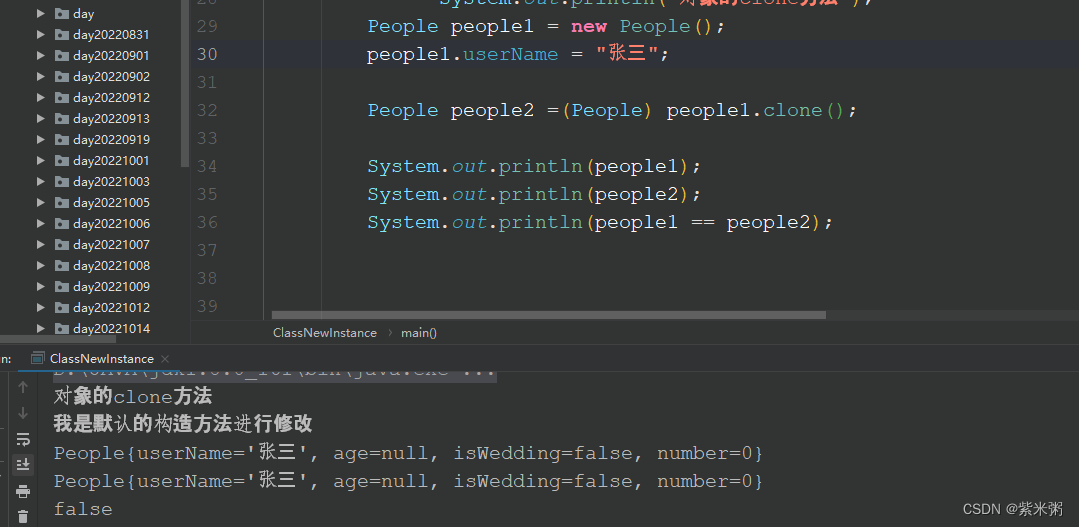
Java创建对象的方式
Java创建对象的五种方式: (1)使用new关键字 (2)使用Object类的clone方法 (3)使用Class类的newInstance方法 (4)使用Constructor类中的newInstance方法 (5&am…...

dom基本操作
1、style修改样式 基本语法: 元素.style.样式’值‘ 注意: 1.修改样式通过style属性引出 2.如果属性有-连接符,需要转换为小驼峰命名法 3.赋值的时候,需要的时候不要忘记加css单位 4.后面的值必须是字符串 <div></div> // 1、…...

如何将python训练的XGBoost模型部署在C++环境推理
当前环境:Ubuntu,xgboost1.7.4过程介绍:首先用python训练XGBoost模型,在训练完成后注意使用xgb_model.save_model(checkpoint.model)进行模型的保存。找到xgboost的动态链接库和头文件动态链接库:如果你在conda环境下面…...
About Oracle Database Performance Method
bottleneck(瓶颈): a point where resource contention is highest throughput(吞吐量): the amount of work that can be completed in a specified time. response time (响应时间): the time to complete a spec…...
)
JavaScript 日期和时间的格式化大汇总(收集)
一、日期和时间的格式化 1、原生方法 1.1、使用 toLocaleString 方法 Date 对象有一个 toLocaleString 方法,该方法可以根据本地时间和地区设置格式化日期时间。例如: const date new Date(); console.log(date.toLocaleString(en-US, { timeZone: …...
【Python】缺失值可视化工具库:missingno
文章目录一、前言二、下载二、使用介绍2.1 绘制缺失值条形图2.2 绘制缺失值热力图2.3 缺失值树状图三、参考资料一、前言 在我们进行机器学习或者深度学习的时候,我们经常会遇到需要处理数据集缺失值的情况,那么如何可视化数据集的缺失情况呢࿱…...

【代码随想录二刷】Day18-二叉树-C++
代码随想录二刷Day18 今日任务 513.找树左下角的值 112.路径总和 113.路径总和ii 106.从中序与后序遍历序列构造二叉树 105.从前序与中序遍历序列构造二叉树 语言:C 513.找树左下角的值 链接:https://leetcode.cn/problems/find-bottom-left-tree-va…...
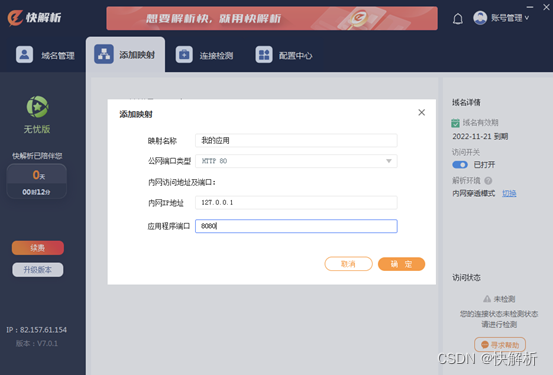
制造业的云ERP在外网怎么访问?内网服务器一步映射到公网
随着企业信息化、智能化时代的到来,很多制造业企业都在用云ERP。用友U 9cloud通过双版本公有云专属、私有云订阅、传统软件购买三种模式满足众多制造业企业的需求,成为一款适配中型及中大型制造业的云ERP,是企业数智制造的创新平台。 用友U 9…...

基于规则引擎与AI Agent的Google Ads自动化营销系统设计与实践
1. 项目概述:当AI遇上Google Ads,一个自动化营销引擎的诞生最近在折腾一个挺有意思的项目,起因是发现很多团队在管理Google Ads广告时,依然在重复着大量手动、低效的操作。无论是关键词的日常拓词、否定关键词的筛选,还…...

到底如何?大跨度“玻璃肋”幕墙,安全吗?
到底如何?大跨度“玻璃肋”幕墙,安全吗? 1 概述 自玻璃诞生之日起,这种无色透明的物质便与建筑结下了不解之缘。随着“苹果店”的火热,通透、纯净的全玻结构系统使玻璃的材料特性发挥到了极致。当我们乐见于越来越大的玻璃幅面、越来越高的幕墙跨度时,全玻结构所具有的…...

零代码构建HomeKit运动检测系统:Adafruit IO与itsaSNAP实战指南
1. 项目概述:零代码构建HomeKit运动检测系统想给家里的走廊、储物间或者车库入口加个自动感应灯,但又不想折腾复杂的编程和服务器搭建?或者,你手头有一些非HomeKit原生设备,希望通过苹果的“家庭”App进行统一管理&…...

别再瞎猜了!LaTeX排版中em、ex、pt、px到底该用哪个?一篇讲透所有单位
LaTeX排版单位全指南:从em到px的精准选择法则 当你第一次打开LaTeX文档,准备调整行距或设置边距时,那些神秘的缩写——em、ex、pt、px——是否让你感到困惑?每个单位似乎都有其存在的理由,但何时使用哪个才是最合适的&…...

基于Codebender在线IDE快速开发Adafruit FLORA可穿戴硬件项目
1. 项目概述:为什么选择在线IDE来玩转可穿戴硬件?如果你和我一样,是个喜欢鼓捣硬件的创客,那么对Arduino、树莓派这类开发板一定不陌生。每次开始一个新项目,最头疼的往往不是写代码,而是配环境:…...

别再只懂install_github了!深入聊聊R包管理:GitHub PAT、依赖与Linux系统库的那些事儿
别再只懂install_github了!深入聊聊R包管理:GitHub PAT、依赖与Linux系统库的那些事儿 在数据科学和统计分析的世界里,R语言凭借其强大的包生态系统和活跃的开源社区,已经成为许多专业人士的首选工具。然而,当我们从个…...

终极指南:如何快速解决LaTeX中文排版字体问题
终极指南:如何快速解决LaTeX中文排版字体问题 【免费下载链接】latex-chinese-fonts Simplified Chinese fonts for the LaTeX typesetting. 项目地址: https://gitcode.com/gh_mirrors/la/latex-chinese-fonts 还在为LaTeX中文排版时遇到的字体缺失、样式混…...

鼠标点击也能如此惊艳!ClickShow让你的Windows操作充满视觉魔力 ✨
鼠标点击也能如此惊艳!ClickShow让你的Windows操作充满视觉魔力 ✨ 【免费下载链接】ClickShow 鼠标点击特效 项目地址: https://gitcode.com/gh_mirrors/cl/ClickShow 还在为枯燥的鼠标点击操作感到乏味吗?每天重复的点击、拖拽、选择࿰…...

画图工具2.0
在上篇文章中,我们已经对简易画图工具有了一个初步了解,下面我们要对一些具体细节进行完善并加上一些新的功能,我们直接来看升级点:1.界面类加上颜色按钮Color[] colors {Color.BLACK, Color.RED, Color.GREEN, Color.BLUE, Colo…...

观察Taotoken在多日连续调用中的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多日连续调用中的延迟与稳定性表现 在需要连续多日、高频率调用大模型API的场景中,例如持续性的内容生成…...