c++中超级详细的一些知识,新手快来
目录
2.文章内容简介
3.理解虚函数表
3.1.多态与虚表
3.2.使用指针访问虚表
4.对象模型概述
4.1.简单对象模型
4.2.表格驱动模型
4.3.非继承下的C++对象模型
5.继承下的C++对象模型
5.1.单继承
5.2.多继承
5.2.1一般的多重继承(非菱形继承)
5.2.2 菱形继承
6.虚继承
6.1.虚基类表解析
6.3.虚拟菱形继承
7.一些问题解答
7.1.C++封装带来的布局成本是多大?
7.2.下面这个空类构成的继承层次中,每个类的大小是多少?
有两个概念可以解释C++对象模型:
- 语言中直接支持面向对象程序设计的部分。
- 对于各种支持的底层实现机制。
直接支持面向对象程序设计,包括了构造函数、析构函数、多态、虚函数等等,这些内容在很多书籍上都有讨论,也是C++最被人熟知的地方(特性)。而对象模型的底层实现机制却是很少有书籍讨论的。对象模型的底层实现机制并未标准化,不同的编译器有一定的***来设计对象模型的实现细节。在我看来,对象模型研究的是对象在存储上的空间与时间上的更优,并对C++面向对象技术加以支持,如以虚指针、虚表机制支持多态特性。
2.文章内容简介
这篇文章主要来讨论C++对象在内存中的布局,属于第二个概念的研究范畴。而C++直接支持面向对象程序设计部分则不多讲。文章主要内容如下:
- 虚函数表解析。含有虚函数或其父类含有虚函数的类,编译器都会为其添加一个虚函数表,vptr,先了解虚函数表的构成,有助对C++对象模型的理解。
- 虚基类表解析。虚继承产生虚基类表(vbptr),虚基类表的内容与虚函数表完全不同,我们将在讲解虚继承时介绍虚函数表。
- 对象模型概述:介绍简单对象模型、表格驱动对象模型,以及非继承情况下的C++对象模型。
- 继承下的C++对象模型。分析C++类对象在下面情形中的内存布局:
- 单继承:子类单一继承自父类,分析了子类重写父类虚函数、子类定义了新的虚函数情况下子类对象内存布局。
- 多继承:子类继承于多个父类,分析了子类重写父类虚函数、子类定义了新的虚函数情况下子类对象内存布局,同时分析了非虚继承下的菱形继承。
- 虚继承:分析了单一继承下的虚继承、多重继承下的虚继承、重复继承下的虚继承。
- 理解对象的内存布局之后,我们可以分析一些问题:
- C++封装带来的布局成本是多大?
- 由空类组成的继承层次中,每个类对象的大小是多大?
至于其他与内存有关的知识,我假设大家都有一定的了解,如内存对齐,指针操作等。本文初看可能晦涩难懂,要求读者有一定的C++基础,对概念一有一定的掌握。
3.理解虚函数表
3.1.多态与虚表
C++中虚函数的作用主要是为了实现多态机制。多态,简单来说,是指在继承层次中,父类的指针可以具有多种形态——当它指向某个子类对象时,通过它能够调用到子类的函数,而非父类的函数。
class Base { virtual void print(void); }
class Drive1 :public Base{ virtual void print(void); }
class Drive2 :public Base{ virtual void print(void); }
Base * ptr1 = new Base; Base * ptr2 = new Drive1; Base * ptr3 = new Drive2;
ptr1->print(); //调用Base::print() prt2->print();//调用Drive1::print() prt3->print();//调用Drive2::print()
这是一种运行期多态,即父类指针唯有在程序运行时才能知道所指的真正类型是什么。这种运行期决议,是通过虚函数表来实现的。
3.2.使用指针访问虚表
如果我们丰富我们的Base类,使其拥有多个virtual函数:
class Base
{
public:Base(int i) :baseI(i){};virtual void print(void){ cout << "调用了虚函数Base::print()"; }virtual void setI(){cout<<"调用了虚函数Base::setI()";}virtual ~Base(){}private:int baseI;};
当一个类本身定义了虚函数,或其父类有虚函数时,为了支持多态机制,编译器将为该类添加一个虚函数指针(vptr)。虚函数指针一般都放在对象内存布局的第一个位置上,这是为了保证在多层继承或多重继承的情况下能以最高效率取到虚函数表。
当vprt位于对象内存最前面时,对象的地址即为虚函数指针地址。我们可以取得虚函数指针的地址:
Base b(1000); int * vptrAdree = (int *)(&b); cout << "虚函数指针(vprt)的地址是:\t"<<vptrAdree << endl;
我们运行代码出结果:
我们强行把类对象的地址转换为 int* 类型,取得了虚函数指针的地址。虚函数指针指向虚函数表,虚函数表中存储的是一系列虚函数的地址,虚函数地址出现的顺序与类中虚函数声明的顺序一致。对虚函数指针地址值,可以得到虚函数表的地址,也即是虚函数表第一个虚函数的地址:
typedef void(*Fun)(void);Fun vfunc = (Fun)*( (int *)*(int*)(&b));cout << "第一个虚函数的地址是:" << (int *)*(int*)(&b) << endl;cout << "通过地址,调用虚函数Base::print():";vfunc();
- 我们把虚表指针的值取出来: *(int*)(&b),它是一个地址,虚函数表的地址
- 把虚函数表的地址强制转换成 int* : ( int *) *( int* )( &b )
- 再把它转化成我们Fun指针类型 : (Fun )*(int *)*(int*)(&b)
这样,我们就取得了类中的第一个虚函数,我们可以通过函数指针访问它。
运行结果:
同理,第二个虚函数setI()的地址为:
(int * )(*(int*)(&b)+1)
同样可以通过函数指针访问它,这里留给读者自己试验。
到目前为止,我们知道了类中虚表指针vprt的由来,知道了虚函数表中的内容,以及如何通过指针访问虚函数表。下面的文章中将常使用指针访问对象内存来验证我们的C++对象模型,以及讨论在各种继承情况下虚表指针的变化,先把这部分的内容消化完再接着看下面的内容。
4.对象模型概述
在C++中,有两种数据成员(class data members):static 和nonstatic,以及三种类成员函数(class member functions):static、nonstatic和virtual:
现在我们有一个类Base,它包含了上面这5中类型的数据或函数:
class Base
{
public:Base(int i) :baseI(i){};int getI(){ return baseI; }static void countI(){};virtual void print(void){ cout << "Base::print()"; }virtual ~Base(){}private:int baseI;static int baseS;
};
那么,这个类在内存中将被如何表示?5种数据都是连续存放的吗?如何布局才能支持C++多态? 我们的C++标准与编译器将如何塑造出各种数据成员与成员函数呢?
4.1.简单对象模型
说明:在下面出现的图中,用蓝色边框框起来的内容在内存上是连续的。
这个模型非常地简单粗暴。在该模型下,对象由一系列的指针组成,每一个指针都指向一个数据成员或成员函数,也即是说,每个数据成员和成员函数在类中所占的大小是相同的,都为一个指针的大小。这样有个好处——很容易算出对象的大小,不过赔上的是空间和执行期效率。想象一下,如果我们的Point3d类是这种模型,将会比C语言的struct多了许多空间来存放指向函数的指针,而且每次读取类的数据成员,都需要通过再一次寻址——又是时间上的消耗。
所以这种对象模型并没有被用于实际产品上。
4.2.表格驱动模型
这个模型在简单对象模型的基础上又添加一个间接层,它把类中的数据分成了两个部分:数据部分与函数部分,并使用两张表格,一张存放数据本身,一张存放函数的地址(也即函数比成员多一次寻址),而类对象仅仅含有两个指针,分别指向上面这两个表。这样看来,对象的大小是固定为两个指针大小。这个模型也没有用于实际应用于真正的C++编译器上。
4.3.非继承下的C++对象模型
概述:在此模型下,nonstatic 数据成员被置于每一个类对象中,而static数据成员被置于类对象之外。static与nonstatic函数也都放在类对象之外,而对于virtual 函数,则通过虚函数表+虚指针来支持,具体如下:
- 每个类生成一个表格,称为虚表(virtual table,简称vtbl)。虚表中存放着一堆指针,这些指针指向该类每一个虚函数。虚表中的函数地址将按声明时的顺序排列,不过当子类有多个重载函数时例外,后面会讨论。
- 每个类对象都拥有一个虚表指针(vptr),由编译器为其生成。虚表指针的设定与重置皆由类的复制控制(也即是构造函数、析构函数、赋值操作符)来完成。vptr的位置为编译器决定,传统上它被放在所有显示声明的成员之后,不过现在许多编译器把vptr放在一个类对象的最前端。关于数据成员布局的内容,在后面会详细分析。
另外,虚函数表的前面设置了一个指向type_info的指针,用以支持RTTI(Run Time Type Identification,运行时类型识别)。RTTI是为多态而生成的信息,包括对象继承关系,对象本身的描述等,只有具有虚函数的对象在会生成。
在此模型下,Base的对象模型如图:
先在VS上验证类对象的布局:
Base b(1000);
可见对象b含有一个vfptr,即vprt。并且只有nonstatic数据成员被放置于对象内。我们展开vfprt:
vfptr中有两个指针类型的数据(地址),第一个指向了Base类的析构函数,第二个指向了Base的虚函数print,顺序与声明顺序相同。
这与上述的C++对象模型相符合。也可以通过代码来进行验证:
void testBase( Base&p)
{cout << "对象的内存起始地址:" << &p << endl;cout << "type_info信息:" << endl;RTTICompleteObjectLocator str = *((RTTICompleteObjectLocator*)*((int*)*(int*)(&p) - 1));string classname(str.pTypeDescriptor->name);classname = classname.substr(4, classname.find("@@") - 4);cout << "根据type_info信息输出类名:"<< classname << endl;cout << "虚函数表地址:" << (int *)(&p) << endl;//验证虚表cout << "虚函数表第一个函数的地址:" << (int *)*((int*)(&p)) << endl;cout << "析构函数的地址:" << (int* )*(int *)*((int*)(&p)) << endl;cout << "虚函数表中,第二个虚函数即print()的地址:" << ((int*)*(int*)(&p) + 1) << endl;//通过地址调用虚函数print()typedef void(*Fun)(void);Fun IsPrint=(Fun)* ((int*)*(int*)(&p) + 1);cout << endl;cout<<"调用了虚函数";IsPrint(); //若地址正确,则调用了Base类的虚函数print()cout << endl;//输入static函数的地址p.countI();//先调用函数以产生一个实例cout << "static函数countI()的地址:" << p.countI << endl;//验证nonstatic数据成员cout << "推测nonstatic数据成员baseI的地址:" << (int *)(&p) + 1 << endl;cout << "根据推测出的地址,输出该地址的值:" << *((int *)(&p) + 1) << endl;cout << "Base::getI():" << p.getI() << endl;}
Base b(1000); testBase(b);
结果分析:
- 通过 (int *)(&p)取得虚函数表的地址
- type_info信息的确存在于虚表的前一个位置。通过((int)(int*)(&p) – 1))取得type_infn信息,并成功获得类的名称的Base
- 虚函数表的第一个函数是析构函数。
- 虚函数表的第二个函数是虚函数print(),取得地址后通过地址调用它(而非通过对象),验证正确
- 虚表指针的下一个位置为nonstatic数据成员baseI。
- 可以看到,static成员函数的地址段位与虚表指针、baseI的地址段位不同。
好的,至此我们了解了非继承下类对象五种数据在内存上的布局,也知道了在每一个虚函数表前都有一个指针指向type_info,负责对RTTI的支持。而加入继承后类对象在内存中该如何表示呢?
5.继承下的C++对象模型
5.1.单继承
如果我们定义了派生类
class Derive : public Base
{
public:Derive(int d) :Base(1000), DeriveI(d){};//overwrite父类虚函数virtual void print(void){ cout << "Drive::Drive_print()" ; }// Derive声明的新的虚函数virtual void Drive_print(){ cout << "Drive::Drive_print()" ; }virtual ~Derive(){}
private:int DeriveI;
};
继承类图为:
一个派生类如何在机器层面上塑造其父类的实例呢?在简单对象模型中,可以在子类对象中为每个类子对象分配一个指针。如下图:
简单对象模型的缺点就是因间接性导致的空间存取时间上的额外负担,优点则是类的大小是固定的,基类的改动不会影响子类对象的大小。
在表格驱动对象模型中,我们可以为子类对象增加第三个指针:基类指针(bptr),基类指针指向指向一个基类表(base class table),同样的,由于间接性导致了空间和存取时间上的额外负担,优点则是无须改变子类对象本身就可以更改基类。表格驱动模型的图就不再贴出来了。
在C++对象模型中,对于一般继承(这个一般是相对于虚拟继承而言),若子类重写(overwrite)了父类的虚函数,则子类虚函数将覆盖虚表中对应的父类虚函数(注意子类与父类拥有各自的一个虚函数表);若子类并无overwrite父类虚函数,而是声明了自己新的虚函数,则该虚函数地址将扩充到虚函数表最后(在vs中无法通过监视看到扩充的结果,不过我们通过取地址的方法可以做到,子类新的虚函数确实在父类子物体的虚函数表末端)。而对于虚继承,若子类overwrite父类虚函数,同样地将覆盖父类子物体中的虚函数表对应位置,而若子类声明了自己新的虚函数,则编译器将为子类增加一个新的虚表指针vptr,这与一般继承不同,在后面再讨论。
我们使用代码来验证以上模型
typedef void(*Fun)(void);int main()
{Derive d(2000);//[0]cout << "[0]Base::vptr";cout << "\t地址:" << (int *)(&d) << endl;//vprt[0]cout << " [0]";Fun fun1 = (Fun)*((int *)*((int *)(&d)));fun1();cout << "\t地址:\t" << *((int *)*((int *)(&d))) << endl;//vprt[1]析构函数无法通过地址调用,故手动输出cout << " [1]" << "Derive::~Derive" << endl;//vprt[2]cout << " [2]";Fun fun2 = (Fun)*((int *)*((int *)(&d)) + 2);fun2();cout << "\t地址:\t" << *((int *)*((int *)(&d)) + 2) << endl;//[1]cout << "[2]Base::baseI=" << *(int*)((int *)(&d) + 1);cout << "\t地址:" << (int *)(&d) + 1;cout << endl;//[2]cout << "[2]Derive::DeriveI=" << *(int*)((int *)(&d) + 2);cout << "\t地址:" << (int *)(&d) + 2;cout << endl;getchar();
}
运行结果:
这个结果与我们的对象模型符合。
5.2.多继承
5.2.1一般的多重继承(非菱形继承)
单继承中(一般继承),子类会扩展父类的虚函数表。在多继承中,子类含有多个父类的子对象,该往哪个父类的虚函数表扩展呢?当子类overwrite了父类的函数,需要覆盖多个父类的虚函数表吗?
- 子类的虚函数被放在声明的第一个基类的虚函数表中。
- overwrite时,所有基类的print()函数都被子类的print()函数覆盖。
- 内存布局中,父类按照其声明顺序排列。
其中第二点保证了父类指针指向子类对象时,总是能够调用到真正的函数。
为了方便查看,我们把代码都粘贴过来
class Base
{
public:Base(int i) :baseI(i){};virtual ~Base(){}int getI(){ return baseI; }static void countI(){};virtual void print(void){ cout << "Base::print()"; }private:int baseI;static int baseS;
};
class Base_2
{
public:Base_2(int i) :base2I(i){};virtual ~Base_2(){}int getI(){ return base2I; }static void countI(){};virtual void print(void){ cout << "Base_2::print()"; }private:int base2I;static int base2S;
};class Drive_multyBase :public Base, public Base_2
{
public:Drive_multyBase(int d) :Base(1000), Base_2(2000) ,Drive_multyBaseI(d){};virtual void print(void){ cout << "Drive_multyBase::print" ; }virtual void Drive_print(){ cout << "Drive_multyBase::Drive_print" ; }private:int Drive_multyBaseI;
};
继承类图为:
此时Drive_multyBase 的对象模型是这样的:
我们使用代码验证:
typedef void(*Fun)(void);int main()
{Drive_multyBase d(3000);//[0]cout << "[0]Base::vptr";cout << "\t地址:" << (int *)(&d) << endl;//vprt[0]析构函数无法通过地址调用,故手动输出cout << " [0]" << "Derive::~Derive" << endl;//vprt[1]cout << " [1]";Fun fun1 = (Fun)*((int *)*((int *)(&d))+1);fun1();cout << "\t地址:\t" << *((int *)*((int *)(&d))+1) << endl;//vprt[2]cout << " [2]";Fun fun2 = (Fun)*((int *)*((int *)(&d)) + 2);fun2();cout << "\t地址:\t" << *((int *)*((int *)(&d)) + 2) << endl;//[1]cout << "[1]Base::baseI=" << *(int*)((int *)(&d) + 1);cout << "\t地址:" << (int *)(&d) + 1;cout << endl;//[2]cout << "[2]Base_::vptr";cout << "\t地址:" << (int *)(&d)+2 << endl;//vprt[0]析构函数无法通过地址调用,故手动输出cout << " [0]" << "Drive_multyBase::~Derive" << endl;//vprt[1]cout << " [1]";Fun fun4 = (Fun)*((int *)*((int *)(&d))+1);fun4();cout << "\t地址:\t" << *((int *)*((int *)(&d))+1) << endl;//[3]cout << "[3]Base_2::base2I=" << *(int*)((int *)(&d) + 3);cout << "\t地址:" << (int *)(&d) + 3;cout << endl;//[4]cout << "[4]Drive_multyBase::Drive_multyBaseI=" << *(int*)((int *)(&d) + 4);cout << "\t地址:" << (int *)(&d) + 4;cout << endl;getchar();
}
运行结果:
5.2.2 菱形继承
菱形继承也称为钻石型继承或重复继承,它指的是基类被某个派生类简单重复继承了多次。这样,派生类对象中拥有多份基类实例(这会带来一些问题)。为了方便叙述,我们不使用上面的代码了,而重新写一个重复继承的继承层次:
class B{public:int ib;public:B(int i=1) :ib(i){}virtual void f() { cout << "B::f()" << endl; }virtual void Bf() { cout << "B::Bf()" << endl; }};class B1 : public B{public:int ib1;public:B1(int i = 100 ) :ib1(i) {}virtual void f() { cout << "B1::f()" << endl; }virtual void f1() { cout << "B1::f1()" << endl; }virtual void Bf1() { cout << "B1::Bf1()" << endl; }};class B2 : public B{public:int ib2;public:B2(int i = 1000) :ib2(i) {}virtual void f() { cout << "B2::f()" << endl; }virtual void f2() { cout << "B2::f2()" << endl; }virtual void Bf2() { cout << "B2::Bf2()" << endl; }};class D : public B1, public B2{public:int id;public:D(int i= 10000) :id(i){}virtual void f() { cout << "D::f()" << endl; }virtual void f1() { cout << "D::f1()" << endl; }virtual void f2() { cout << "D::f2()" << endl; }virtual void Df() { cout << "D::Df()" << endl; }};
这时,根据单继承,我们可以分析出B1,B2类继承于B类时的内存布局。又根据一般多继承,我们可以分析出D类的内存布局。我们可以得出D类子对象的内存布局如下图:
D类对象内存布局中,图中青色表示b1类子对象实例,黄色表示b2类子对象实例,灰色表示D类子对象实例。从图中可以看到,由于D类间接继承了B类两次,导致D类对象中含有两个B类的数据成员ib,一个属于来源B1类,一个来源B2类。这样不仅增大了空间,更重要的是引起了程序歧义:
D d;d.ib =1 ; //二义性错误,调用的是B1的ib还是B2的ib?d.B1::ib = 1; //正确d.B2::ib = 1; //正确
尽管我们可以通过明确指明调用路径以消除二义性,但二义性的潜在性还没有消除,我们可以通过虚继承来使D类只拥有一个ib实体。
6.虚继承
虚继承解决了菱形继承中最派生类拥有多个间接父类实例的情况。虚继承的派生类的内存布局与普通继承很多不同,主要体现在:
- 虚继承的子类,如果本身定义了新的虚函数,则编译器为其生成一个虚函数指针(vptr)以及一张虚函数表。该vptr位于对象内存最前面。
- vs非虚继承:直接扩展父类虚函数表。
- 虚继承的子类也单独保留了父类的vprt与虚函数表。这部分内容接与子类内容以一个四字节的0来分界。
- 虚继承的子类对象中,含有四字节的虚表指针偏移值。
为了分析最后的菱形继承,我们还是先从单虚继承继承开始。
6.1.虚基类表解析
在C++对象模型中,虚继承而来的子类会生成一个隐藏的虚基类指针(vbptr),在Microsoft Visual C++中,虚基类表指针总是在虚函数表指针之后,因而,对某个类实例来说,如果它有虚基类指针,那么虚基类指针可能在实例的0字节偏移处(该类没有vptr时,vbptr就处于类实例内存布局的最前面,否则vptr处于类实例内存布局的最前面),也可能在类实例的4字节偏移处。
一个类的虚基类指针指向的虚基类表,与虚函数表一样,虚基类表也由多个条目组成,条目中存放的是偏移值。第一个条目存放虚基类表指针(vbptr)所在地址到该类内存首地址的偏移值,由第一段的分析我们知道,这个偏移值为0(类没有vptr)或者-4(类有虚函数,此时有vptr)。我们通过一张图来更好地理解。
虚基类表的第二、第三…个条目依次为该类的最左虚继承父类、次左虚继承父类…的内存地址相对于虚基类表指针的偏移值,这点我们在下面会验证。
6.2.简单虚继承
如果我们的B1类虚继承于B类:
//类的内容与前面相同
class B{...}
class B1 : virtual public B
根据我们前面对虚继承的派生类的内存布局的分析,B1类的对象模型应该是这样的:
我们通过指针访问B1类对象的内存,以验证上面的C++对象模型:
int main()
{
B1 a;cout <<"B1对象内存大小为:"<< sizeof(a) << endl;//取得B1的虚函数表cout << "[0]B1::vptr";cout << "\t地址:" << (int *)(&a)<< endl;//输出虚表B1::vptr中的函数for (int i = 0; i<2;++ i){cout << " [" << i << "]";Fun fun1 = (Fun)*((int *)*(int *)(&a) + i);fun1();cout << "\t地址:\t" << *((int *)*(int *)(&a) + i) << endl;}//[1]cout << "[1]vbptr " ;cout<<"\t地址:" << (int *)(&a) + 1<<endl; //虚表指针的地址//输出虚基类指针条目所指的内容for (int i = 0; i < 2; i++){cout << " [" << i << "]";cout << *(int *)((int *)*((int *)(&a) + 1) + i);cout << endl;}//[2]cout << "[2]B1::ib1=" << *(int*)((int *)(&a) + 2);cout << "\t地址:" << (int *)(&a) + 2;cout << endl;//[3]cout << "[3]值=" << *(int*)((int *)(&a) + 3);cout << "\t\t地址:" << (int *)(&a) + 3;cout << endl;//[4]cout << "[4]B::vptr";cout << "\t地址:" << (int *)(&a) +3<< endl;//输出B::vptr中的虚函数for (int i = 0; i<2; ++i){cout << " [" << i << "]";Fun fun1 = (Fun)*((int *)*((int *)(&a) + 4) + i);fun1();cout << "\t地址:\t" << *((int *)*((int *)(&a) + 4) + i) << endl;}//[5]cout << "[5]B::ib=" << *(int*)((int *)(&a) + 5);cout << "\t地址: " << (int *)(&a) + 5;cout << endl;
运行结果:
这个结果与我们的C++对象模型图完全符合。这时我们可以来分析一下虚表指针的第二个条目值12的具体来源了,回忆上文讲到的:
第二、第三…个条目依次为该类的最左虚继承父类、次左虚继承父类…的内存地址相对于虚基类表指针的偏移值。
在我们的例子中,也就是B类实例内存地址相对于vbptr的偏移值,也即是:[4]-[1]的偏移值,结果即为12,从地址上也可以计算出来:007CFDFC-007CFDF4结果的十进制数正是12。现在,我们对虚基类表的构成应该有了一个更好的理解。
6.3.虚拟菱形继承
如果我们有如下继承层次:
class B{...}
class B1: virtual public B{...}
class B2: virtual public B{...}
class D : public B1,public B2{...}
类图如下所示:
菱形虚拟继承下,最派生类D类的对象模型又有不同的构成了。在D类对象的内存构成上,有以下几点:
- 在D类对象内存中,基类出现的顺序是:先是B1(最左父类),然后是B2(次左父类),最后是B(虚祖父类)
- D类对象的数据成员id放在B类前面,两部分数据依旧以0来分隔。
- 编译器没有为D类生成一个它自己的vptr,而是覆盖并扩展了最左父类的虚基类表,与简单继承的对象模型相同。
- 超类B的内容放到了D类对象内存布局的最后。
菱形虚拟继承下的C++对象模型为:
下面使用代码加以验证:
int main()
{D d;cout << "D对象内存大小为:" << sizeof(d) << endl;//取得B1的虚函数表cout << "[0]B1::vptr";cout << "\t地址:" << (int *)(&d) << endl;//输出虚表B1::vptr中的函数for (int i = 0; i<3; ++i){cout << " [" << i << "]";Fun fun1 = (Fun)*((int *)*(int *)(&d) + i);fun1();cout << "\t地址:\t" << *((int *)*(int *)(&d) + i) << endl;}//[1]cout << "[1]B1::vbptr ";cout << "\t地址:" << (int *)(&d) + 1 << endl; //虚表指针的地址//输出虚基类指针条目所指的内容for (int i = 0; i < 2; i++){cout << " [" << i << "]";cout << *(int *)((int *)*((int *)(&d) + 1) + i);cout << endl;}//[2]cout << "[2]B1::ib1=" << *(int*)((int *)(&d) + 2);cout << "\t地址:" << (int *)(&d) + 2;cout << endl;//[3]cout << "[3]B2::vptr";cout << "\t地址:" << (int *)(&d) + 3 << endl;//输出B2::vptr中的虚函数for (int i = 0; i<2; ++i){cout << " [" << i << "]";Fun fun1 = (Fun)*((int *)*((int *)(&d) + 3) + i);fun1();cout << "\t地址:\t" << *((int *)*((int *)(&d) + 3) + i) << endl;}//[4]cout << "[4]B2::vbptr ";cout << "\t地址:" << (int *)(&d) + 4 << endl; //虚表指针的地址//输出虚基类指针条目所指的内容for (int i = 0; i < 2; i++){cout << " [" << i << "]";cout << *(int *)((int *)*((int *)(&d) + 4) + i);cout << endl;}//[5]cout << "[5]B2::ib2=" << *(int*)((int *)(&d) + 5);cout << "\t地址: " << (int *)(&d) + 5;cout << endl;//[6]cout << "[6]D::id=" << *(int*)((int *)(&d) + 6);cout << "\t地址: " << (int *)(&d) + 6;cout << endl;//[7]cout << "[7]值=" << *(int*)((int *)(&d) + 7);cout << "\t\t地址:" << (int *)(&d) + 7;cout << endl;//间接父类//[8]cout << "[8]B::vptr";cout << "\t地址:" << (int *)(&d) + 8 << endl;//输出B::vptr中的虚函数for (int i = 0; i<2; ++i){cout << " [" << i << "]";Fun fun1 = (Fun)*((int *)*((int *)(&d) + 8) + i);fun1();cout << "\t地址:\t" << *((int *)*((int *)(&d) + 8) + i) << endl;}//[9]cout << "[9]B::id=" << *(int*)((int *)(&d) + 9);cout << "\t地址: " << (int *)(&d) +9;cout << endl;getchar();
}
查看运行结果:
7.一些问题解答
7.1.C++封装带来的布局成本是多大?
在C语言中,“数据”和“处理数据的操作(函数)”是分开来声明的,也就是说,语言本身并没有支持“数据和函数”之间的关联性。
在C++中,我们通过类来将属性与操作绑定在一起,称为ADT,抽象数据结构。
C语言中使用struct(结构体)来封装数据,使用函数来处理数据。举个例子,如果我们定义了一个struct Point3如下:
typedef struct Point3
{float x;float y;float z;
} Point3;
为了打印这个Point3d,我们可以定义一个函数:
void Point3d_print(const Point3d *pd)
{printf("(%f,%f,%f)",pd->x,pd->y,pd_z);
}
而在C++中,我们更倾向于定义一个Point3d类,以ADT来实现上面的操作:
class Point3d
{public:point3d (float x = 0.0,float y = 0.0,float z = 0.0): _x(x), _y(y), _z(z){}float x() const {return _x;}float y() const {return _y;}float z() const {return _z;}private:float _x;float _y;float _z;
};inline ostream&operator<<(ostream &os, const Point3d &pt){os<<"("<<pr.x()<<","<<pt.y()<<","<<pt.z()<<")";}
看到这段代码,很多人第一个疑问可能是:加上了封装,布局成本增加了多少?答案是class Point3d并没有增加成本。学过了C++对象模型,我们知道,Point3d类对象的内存中,只有三个数据成员。
上面的类声明中,三个数据成员直接内含在每一个Point3d对象中,而成员函数虽然在类中声明,却不出现在类对象(object)之中,这些函数(non-inline)属于类而不属于类对象,只会为类产生唯一的函数实例。
所以,Point3d的封装并没有带来任何空间或执行期的效率影响。而在下面这种情况下,C++的封装额外成本才会显示出来:
- 虚函数机制(virtual function) , 用以支持执行期绑定,实现多态。
- 虚基类 (virtual base class) ,虚继承关系产生虚基类,用于在多重继承下保证基类在子类中拥有唯一实例。
不仅如此,Point3d类数据成员的内存布局与c语言的结构体Point3d成员内存布局是相同的。C++中处在同一个访问标识符(指public、private、protected)下的声明的数据成员,在内存中必定保证以其声明顺序出现。而处于不同访问标识符声明下的成员则无此规定。对于Point3类来说,它的三个数据成员都处于private下,在内存中一起声明顺序出现。我们可以做下实验:
void TestPoint3Member(const Point3d& p)
{cout << "推测_x的地址是:" << (float *) (&p) << endl;cout << "推测_y的地址是:" << (float *) (&p) + 1 << endl;cout << "推测_z的地址是:" << (float *) (&p) + 2 << endl;cout << "根据推测出的地址输出_x的值:" << *((float *)(&p)) << endl;cout << "根据推测出的地址输出_y的值:" << *((float *)(&p)+1) << endl;cout << "根据推测出的地址输出_z的值:" << *((float *)(&p)+2) << endl;}
//测试代码Point3d a(1,2,3);TestPoint3Member(a);
运行结果:
从结果可以看到,_x,_y,_z三个数据成员在内存中紧挨着。
总结一下:
不考虑虚函数与虚继承,当数据都在同一个访问标识符下,C++的类与C语言的结构体在对象大小和内存布局上是一致的,C++的封装并没有带来空间时间上的影响。
7.2.下面这个空类构成的继承层次中,每个类的大小是多少?
今有类如下:
class B{};
class B1 :public virtual B{};
class B2 :public virtual B{};
class D : public B1, public B2{};int main()
{B b;B1 b1;B2 b2;D d;cout << "sizeof(b)=" << sizeof(b)<<endl;cout << "sizeof(b1)=" << sizeof(b1) << endl;cout << "sizeof(b2)=" << sizeof(b2) << endl;cout << "sizeof(d)=" << sizeof(d) << endl;getchar();
}
输出结果是:
解析:
- 编译器为空类安插1字节的char,以使该类对象在内存得以配置一个地址。
- b1虚继承于b,编译器为其安插一个4字节的虚基类表指针(32为机器),此时b1已不为空,编译器不再为其安插1字节的char(优化)。
- b2同理。
- d含有来自b1与b2两个父类的两个虚基类表指针。大小为8字节。
相关文章:
c++中超级详细的一些知识,新手快来
目录 2.文章内容简介 3.理解虚函数表 3.1.多态与虚表 3.2.使用指针访问虚表 4.对象模型概述 4.1.简单对象模型 4.2.表格驱动模型 4.3.非继承下的C对象模型 5.继承下的C对象模型 5.1.单继承 5.2.多继承 5.2.1一般的多重继承(非菱形继承) 5.2…...

[答疑]经营困难时期谈建模和伪创新-长点心和长点良心
leonll 2022-11-26 9:53 我们今年真是太难了……(此处删除若干字)……去年底就想着邀请您来给我们讲课,现在也没有实行。我想再和我们老大提,您觉得怎么说个关键理由,这样的形势合适引进UML开发流程? UML…...

计算机基础知识
计算机网络的拓扑结构 一、OSI 7层网络模型是指什么? 7层分别是什么?每层的作用是什么? OSI7层模型是 国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系。 每层功能:(自底向上) 物理层:建立、…...
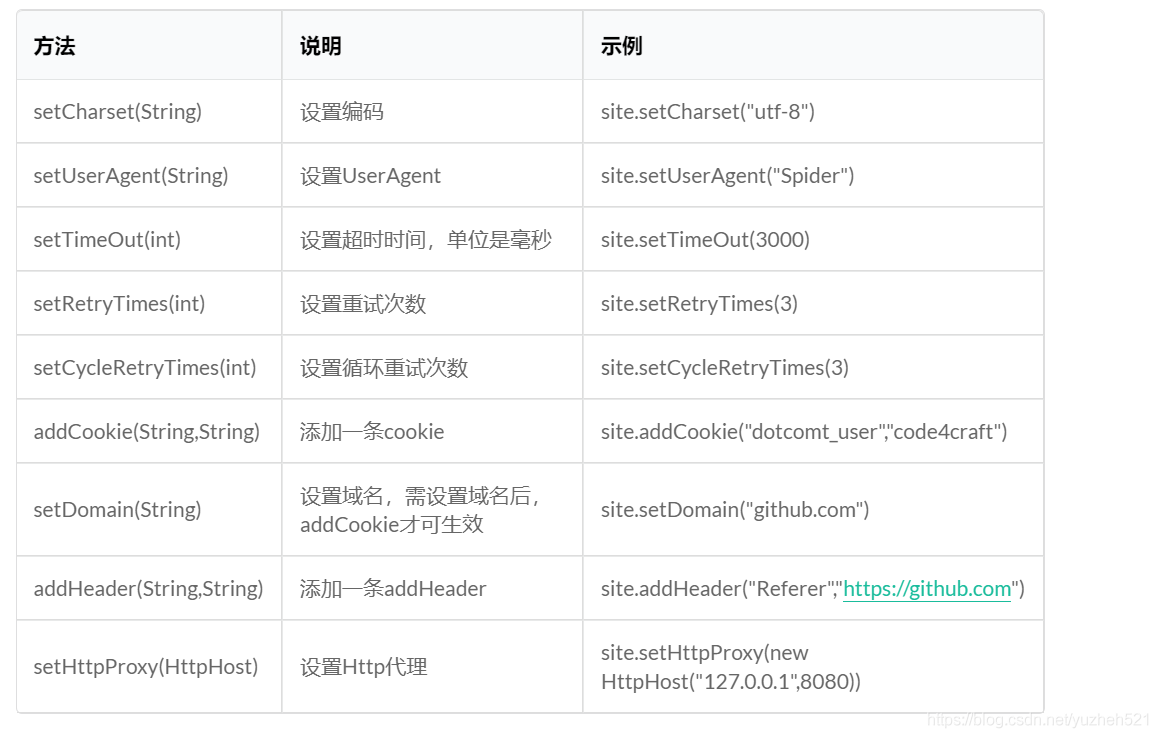
Java爬虫—WebMagic
一,WebMagic介绍WebMagic企业开发,比HttpClient和JSoup更方便一),WebMagic架构介绍WebMagic有DownLoad,PageProcessor,Schedule,Pipeline四大组件,并有Spider将他们组织起来…...

[软件工程导论(第六版)]第2章 可行性研究(复习笔记)
文章目录2.1 可行性研究的任务2.2 可行性研究过程2.3 系统流程图2.4 数据流图概念2.5 数据字典2.6 成本/效益分析2.1 可行性研究的任务 可行性研究的目的 用最小的代价在尽可能短的时间内确定问题是否能够解决。 可行性研究的3个方面 (1)技术可行性&…...
Mac下安装Tomcat以及IDEA中的配置
安装brew 打开终端输入以下命令: /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" 搜索tomcat版本,输入以下命令: brew search tomcat 安装自己想要的版本,例…...
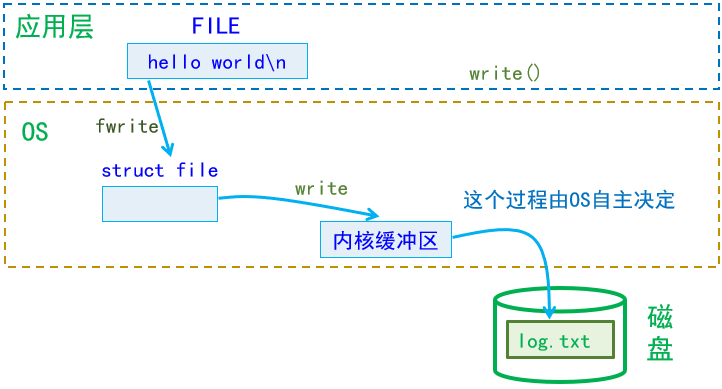
【Linux详解】——文件基础(I/O、文件描述符、重定向、缓冲区)
📖 前言:本期介绍文件基础I/O。 目录🕒 1. 文件回顾🕘 1.1 基本概念🕘 1.2 C语言文件操作🕤 1.2.1 概述🕤 1.2.2 实操🕤 1.2.3 OS接口open的使用(比特位标记)…...

HomMat2d
1.affine_trans_region(区域的任意变换) 2.hom_mat2d_identity(创建二位变换矩阵) 3.hom_mat2d_translate(平移) 4.hom_mat2d_scale(缩放) 5.hom_mat2d_rotate(旋转 &…...
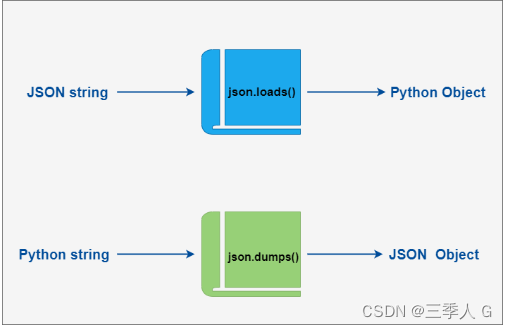
Python3 JSON 数据解析
Python3 JSON 数据解析 JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。 Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数: json.dumps(): 对数据进行编码。json.loads(): 对数据进行解码。 在 json 的编解码…...
Homebrew 安装遇到的问题
Homebrew 安装遇到的问题 例如:第一章 Python 机器学习入门之pandas的使用 文章目录Homebrew 安装遇到的问题前言一、安装二、遇到的问题1.提示 zsh: command not found: brew三、解决问题前言 使用 Homebrew 能够 安装 Apple(或您的 Linux 系统&#…...

Metasploit框架基础(二)
文章目录前言一、Meatsplooit的架构二、目录结构datadocumentationlibmodulesplugins三、Measploit模块四、Metasploit的使用前言 Metasploit是用ruby语言开发的,所以你打开软件目录,会发现很多.rb结尾的文件。ruby是一门OOP的语言。 一、Meatsplooit的…...

c++容器
1、vector容器 1.1性质 a)该容器的数据结构和数组相似,被称为单端数组。 b)在存储数据时不是在原有空间上往后拓展,而是找到一个新的空间,将原数据深拷贝到新空间,释放原空间。该过程被称为动态拓展。 vec…...

Vue.js如何实现对一千张图片进行分页加载?
目录 vue处理一千张图片进行分页加载 分页加载、懒加载---概念介绍: 思路: 开发过程中,如果后端一次性返回你1000多条图片或数据,那我们前端应该怎么用什么思路去更好的渲染呢? 第一种:我们可以使用分页…...
)
计算机网络复习(六)
考点:MIME及其编码(base64,quoted-printable)网络协议http是基于什么协议,应用层到网络层基于什么协议6-27.试将数据 11001100 10000001 00111000 进行 base64 编码,并得到最后传输的 ASCII 数据。答:先将 24 比特的二…...

Redis进阶:布隆过滤器(Bloom Filter)及误判率数学推导
1 缘起 有一次偶然间听到有同事在说某个项目中使用了布隆过滤器, 哎呦,我去,我竟然不知道啥是布隆过滤器, 这我哪能忍?其实,也可以忍,但是,可能有的面试官不能忍!&#…...
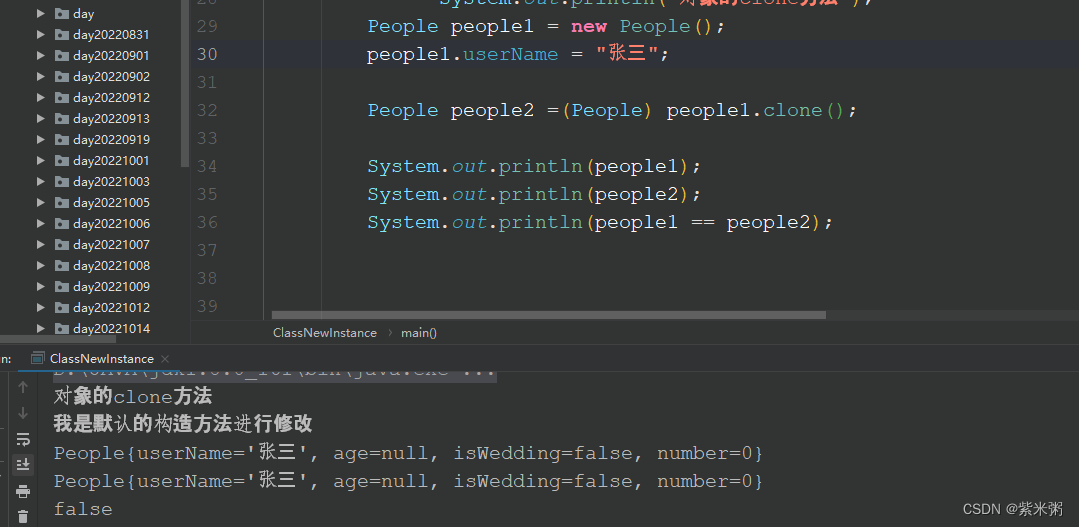
Java创建对象的方式
Java创建对象的五种方式: (1)使用new关键字 (2)使用Object类的clone方法 (3)使用Class类的newInstance方法 (4)使用Constructor类中的newInstance方法 (5&am…...

dom基本操作
1、style修改样式 基本语法: 元素.style.样式’值‘ 注意: 1.修改样式通过style属性引出 2.如果属性有-连接符,需要转换为小驼峰命名法 3.赋值的时候,需要的时候不要忘记加css单位 4.后面的值必须是字符串 <div></div> // 1、…...

如何将python训练的XGBoost模型部署在C++环境推理
当前环境:Ubuntu,xgboost1.7.4过程介绍:首先用python训练XGBoost模型,在训练完成后注意使用xgb_model.save_model(checkpoint.model)进行模型的保存。找到xgboost的动态链接库和头文件动态链接库:如果你在conda环境下面…...
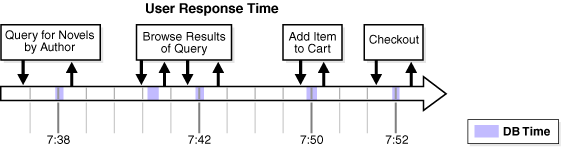
About Oracle Database Performance Method
bottleneck(瓶颈): a point where resource contention is highest throughput(吞吐量): the amount of work that can be completed in a specified time. response time (响应时间): the time to complete a spec…...
)
JavaScript 日期和时间的格式化大汇总(收集)
一、日期和时间的格式化 1、原生方法 1.1、使用 toLocaleString 方法 Date 对象有一个 toLocaleString 方法,该方法可以根据本地时间和地区设置格式化日期时间。例如: const date new Date(); console.log(date.toLocaleString(en-US, { timeZone: …...

基于HTML5 Canvas的轻量级图像标注库visual-annotator集成指南
1. 项目概述:一个为开发者打造的视觉标注利器如果你做过图像识别、目标检测或者任何需要处理大量图片标注的计算机视觉项目,那你一定对标注工具不陌生。从早期的LabelImg到后来的CVAT、Label Studio,工具的选择往往决定了你项目前期数据准备的…...

医院内外部人员管理系统
基于计算机视觉技术的医院人员综合管理解决方案,整合人脸识别考勤与行人流量监控两大核心能力,实现内部员工身份验证、自动打卡签到,以及公共区域人流量实时统计与可视化分析,提升医院管理效率与安全保障水平。 [📺 系…...

555定时器深度解析:从RC电路到三种工作模式的原理与应用
1. 项目概述在电子设计的工具箱里,有那么几颗芯片,你几乎可以在任何时代的电路板上找到它们的身影。它们可能不是性能最强的,但一定是应用最广、最经久不衰的。今天要聊的555定时器,就是这样一个“活化石”级别的存在。自上世纪70…...

基于Feather RP2040与CircuitPython的CNC旋钮宏键盘DIY指南
1. 项目概述:打造你的专属生产力旋钮如果你经常使用像Cura、Fusion 360或者Adobe系列这类专业软件,一定对频繁切换工具、调整参数时在键盘和鼠标间来回切换的繁琐深有体会。传统的键盘快捷键虽然快,但组合键太多容易忘记,而且缺乏…...

如何用Photoshop图层批量导出工具提升3倍工作效率 [特殊字符]
如何用Photoshop图层批量导出工具提升3倍工作效率 🚀 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Adobe. 项目地址: http…...
)
Win11任务栏小喇叭失踪?别慌!3个亲测有效的修复方法(含重启资源管理器与音频服务)
Win11任务栏音量图标消失?3种专业修复方案与深度解析 刚升级Win11的用户常会遇到一个令人抓狂的小问题——任务栏右下角的音量图标突然"离家出走"。这个看似微不足道的小喇叭,却是我们日常调节系统音量的主要入口。当它消失时,不仅…...

手持设备串口屏应用指南:从架构解析到实战开发
1. 项目概述:为什么手持设备需要一块“聪明”的屏幕?在手持设备这个领域摸爬滚打了十几年,从早期的黑白点阵屏到后来的TFT彩屏,再到如今各种智能交互界面,我深刻感受到一个趋势:设备越来越“聪明”…...

Linux 下用火焰图进行性能分析
软件的性能分析,往往需要查看 CPU 耗时,了解瓶颈在哪里。火焰图 (flame graph) 是性能分析的利器。 1. 火焰图简介 很多人感冒发烧的时候,往往会模仿神农氏尝百草的路子:先尝尝抗病毒的药,再试试抗细菌的药ÿ…...

Rust异步任务取消机制:从协作式取消到结构化并发实践
1. 项目概述:当异步任务“半途而废”时在Rust的异步编程世界里,我们常常专注于如何让任务“跑起来”——用async/await优雅地处理并发,用Future描述计算,用tokio或async-std这样的运行时来驱动一切。代码逻辑清晰,从A点…...

从0到1搭建AI心理健康预警系统:我是如何用BERT+BiLSTM捕捉情绪拐点的
一、 痛点:为什么通用大模型干不了这活?首先声明,我们不是大模型黑。但在心理预警这个场景下,直接用GPT-4或者文心一言的API,有三个致命伤:成本炸裂: 每天几万条的学生/员工咨询日志ÿ…...