哈希unordered系列介绍(上)
一.Unordered_map,Unordered_set介绍
在之前我们已经介绍过set,map,multiset等等关联式容器,它们的底层是红黑树进行模拟实现的,在查询时效率可达到 l o g 2 N log_2 N log2N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好的查询是,进行很少的比较次数就能够将元素找到
因此,在C++11中又引入了unordered系列的关联式容器,它们的用法和map,set非常类似,不过底层实现上有所不同,后者是用红黑树模拟实现的,而前者则是用一种名叫哈希的数据结构
二.简单性能对比
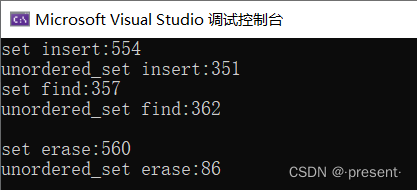
我们分别创建set对象,和unordered_set对象,然后生成一大堆随机数进行插入,通过时间上实现find,erase,insert等操作进行对比,来简单对比两者性能上的差别
#include <unordered_map>
#include <unordered_set>
#include <time.h>
#include <set>
#include <map>using namespace std;
int main()
{const size_t N = 200000;unordered_set<int> s1;set<int> s2;vector<int> v1;v1.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v1.push_back(rand());v1.push_back(rand()+i);//v1.push_back(i);}//插入时间对比size_t begin1 = clock();for (auto e : v1){s2.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();for (auto e : v1){s1.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;//寻找时间对比size_t begin3 = clock();for (auto e : v1){s2.find(e);}size_t end3 = clock();cout << "set find:" << end3 - begin3 << endl;size_t begin4 = clock();for (auto e : v1){s2.find(e);}size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl << endl;//删除时间对比size_t begin5 = clock();for (auto e : v1){s2.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v1){s1.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;return 0;
}
可以看到,在insert,erase等操作上,哈希实现的unordered系列具有一定的显著优势
在cplusplus网站对unordered系列的介绍也直接指出来它的优势所在,以及两者的不同,这里只简单列举unordered_map为例
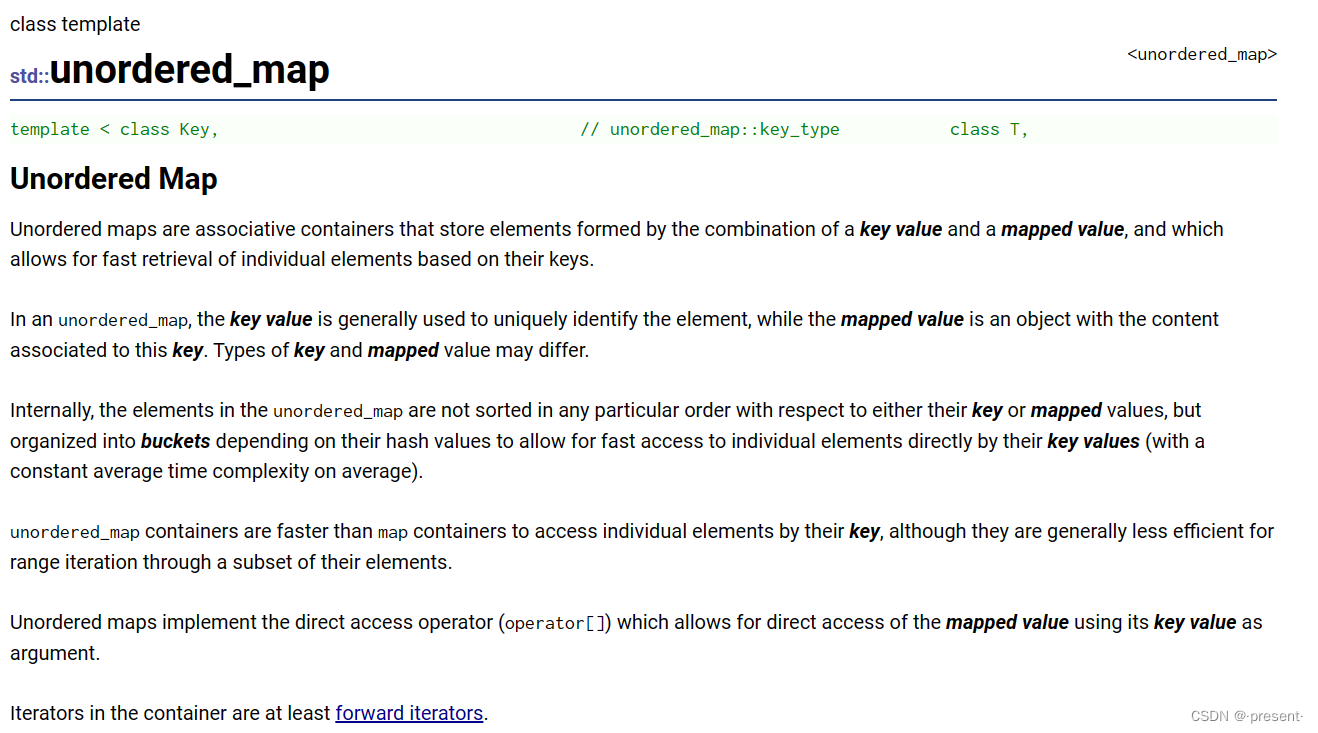
前两段指出了unordered_map也是关联式容器(associative containers),支持键值对,key和mapped value的类型可以不同
第三段指出,它与map系列的不同,它的底层实现是一种叫哈希桶(buckets)的数据结构
第四,五段也指出了该系列的优势和区别,unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭
代方面效率较低,同时map我们知道它是支持双向迭代器,而unordered_map只支持单向迭代器(forward iterators)
三.哈希概念介绍
2.1哈希概念
对于平衡树来说,元素关键字与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。
查找的效率即为平衡树中树的高度,即O( l o g 2 N log_2 N log2N),搜索的效率取决于搜索过程中元素的比较次数
那我们是否能建立一种这样的结构,将元素的关键字和其存储位置之间建立映射关系,从而大大提高查找的效率?
就像我们的宿舍号,在开学前,每位学生都会按照一定的规则(比如说按照学号进行分宿舍,按成绩进行分宿舍)分到相应的宿舍
假如班级管理委员要找某位同学,他并不会按照顺序,一间间宿舍往下找,假如一层有十多个宿舍,那效率实在太慢了,正确的做法,就是根据分配的规则,比如说按照学号进行分宿舍,然后根据学号直接找宿舍名单中对应宿舍即可.
将上述过程中的关键字抽离出来
一定的规则,我们称之为哈希函数
宿舍名单,我们称之为哈希表(HashTable)
从上述例子也可以看出,哈希函数并不是唯一的
比如说,数据集合{1,7,6,4,5,9};
我们将哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小.
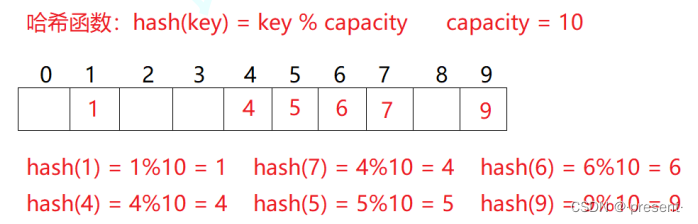
我们找4,只需要直接去哈希表中的4寻找即可,直接一步到位,它的关键思想和数组下标映射有点类似.
2.2哈希冲突
虽然理论上我们已经基本建立所谓的哈希表,但是实际运用上还有一些问题需要解决
假如我们对上面的例子中的表,再插入一个14呢?它应该放置在哪个位置?
我们把不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞
数学上解释:
对于两个数据元素的关键字 k i k_i ki和 k j k_j kj(i != j),有 k i k_i ki != k j k_j kj,但有:Hash( k i k_i ki) == Hash( k j k_j kj),我们称之为发生了哈希冲突
2.3哈希函数
引起哈希冲突的其中一个原因:可能是哈希函数设计的不够合理
因此,哈希函数虽然有很多种类型,但是也需要符合一定的设计原则
哈希函数设计原则:
1.哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
2.哈希函数计算出来的地址能均匀分布在整个空间中
3.哈希函数应该比较简单
常见的哈希函数如下:
1.直接定址法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
2.除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,
按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
3.平方取中法–(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址
平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
2.4哈希冲突解决
既然出现相应的问题,我们就要找相应的办法解决
解决哈希冲突两种常见的方法是:闭散列和开散列
2.4.1闭散列
闭散列也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去.
那如何理解闭散列中闭的含义呢?
因为哈希表的原始空间是固定大小的,比如说我们上述所举的例子,对应的哈希表本质是一个vector,大小是10个字节,后面即便再插入新元素,需要打到某种条件才会改变哈希表的大小
那闭散列如何解决哈希冲突的问题?
抓住闭散列的定义,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去.
因此,假如插入新元素14,和4发生冲突,就从哈希表中找一个新的位置,比如下标为8,下标为0的位置等等,这些位置都没有元素放置,可以用来放置14,从而解决哈希冲突的问题
但是怎么找空位置也是有讲究的
常用的探测方式主要是线性探测和二次探测
线性探测:
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止.
用大白话讲,就是一个一个从前往后找空位置
比如插入14,4发生冲突,往后找,看下标为5的位置有没有放置新元素,有;于是继续往后找,直到到下标为8的位置,发现为空,所以,放置对应的新元素14
二次探测:
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为:
H i H_i Hi = ( H 0 H_0 H0 + i 2 i^2 i2 )% m, 或者: H i H_i Hi = ( H 0 H_0 H0 - i 2 i^2 i2 )% m。其中:i = 1,2,3…, H 0 H_0 H0是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小
大白话来说,就是跳着找,第一次找下标为冲突下标+1的位置,如果冲突,找冲突下标+2的位置,以此类推
当然,还有很多探测方式,比如左右交替找等等,这里不再过多介绍
2.4.2 负载因子
前面我们提到过,哈希表在一定条件下需要扩容,那这个一定条件是什么呢?
有人会说,哈希表全部已经装满了,就可以考虑扩容
这固然是一种实现方法,但在现实中往往采取的是另一种策略

我们定义
负载因子 α = 插入表中元素个数 散列表长度 \alpha = \frac{插入表中元素个数}{散列表长度} α=散列表长度插入表中元素个数
表中元素个数在哈希表中占据的相对比重越大,就越可能发生哈希冲突,因此负载因子在等于0.7至0.8的时候就要及时考虑哈希表的扩容问题,否则发生哈希冲突的概率将会急剧增大
2.4.3闭散列代码实现
哈希表的本质是一个自定义类型,里面包含两个成员变量,一个是vector,另一个是哈希表大小n(当然也可以采取函数指针的方式,不过c++本身就实现了vector,明显用vector更香)
插入的每一个HashData也不是简单的数字,同样也是一个自定义类型,里面包含的是pair键值对,和对应的元素状态
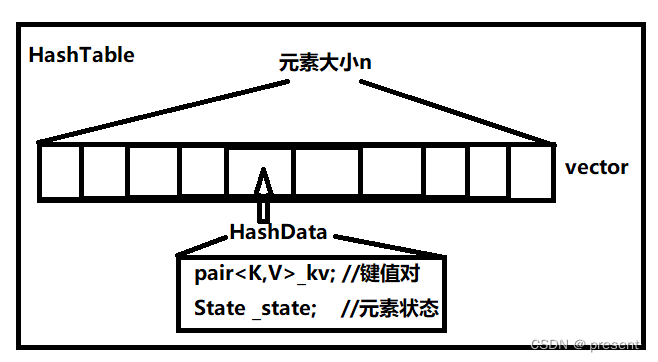
至于为什么HashData(哈希表中每个对应的元素)的成员变量要这样设计,其实背后也蕴含深意
1.插入哈希表中的元素类型并不固定,可能是内置类型int,或者是自定义类型string,再加上需要映射相应的位置,所以采取模板+pair的方式作为其中一个成员变量是合情合理的
2.那为什么要加入相应的元素状态呢?
这主要是为了实现删除和扩容的方便
删除对应的元素,只需要将对应的元素状态设为空即可,假如用一个不存在的值覆盖,反而还不方便
同样的,扩容需要重新创建一个新大小n的vector,并将旧的原有元素重新映射到新的vector中,如何快速判断对应位置是否存在元素呢?如果每个元素本身就有一个状态EXIST(存在)or Empty(空),那就能迅速判断是否要将该旧元素映射到新的哈希表中.
具体代码实现如下:
namespace OpenAddress {//设三个状态enum State{EMPTY,EXIST,DELETE};template <class K,class V>struct HashData {pair<K, V> _kv;//初始状态都设为空State _state = EMPTY;};template <class K,class V>class HashTable {public://insertbool insert(const pair<K, V>& kv){//如果哈希表中本身已经存在该元素,则直接返回falseif (Find(kv.first))return false;//考虑扩容问题,表长为0或负载因子超过0.7都要考虑扩容,并重新映射if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7){size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;HashTable<K,V> new_hash_table;//调整新哈希表size为newsizenew_hash_table._tables.resize(newsize);//重新映射for (auto& data : _tables){//假设元素状态为存在,则移动到新表if (data._state == EXIST){new_hash_table.insert(data._kv);}}_tables.swap(new_hash_table._tables);}//实际的插入代码size_t hashi = kv.first % _tables.size();size_t i = 1;size_t index = hashi;//找到对应插入的位置while (_tables[index]._state == EXIST){index = hashi + i;index %= _tables.size();++i;}_tables[index]._kv = kv;_tables[index]._state = EXIST;_n++;return true;}//FindHashData<K,V>* Find(const K& key){//假如哈希表本身大小就为0,则直接返回空即可if (_tables.size() == 0)return nullptr;//计算应该找的下标 = 键值%表长size_t hashi = key % _tables.size();//线性探测---从前往后找对应元素,直到遇到空size_t i = 1;size_t index = hashi;while (_tables[index]._state != EMPTY){//如果状态不为删除,为存在;且键值相等,表明相同,说明if (_tables[index]._state == EXIST&& _tables[index]._kv.first == key){return &_tables[index];}//当前位置没找到,调整下标位置index = hashi + i;//下标不能越界,及时调整回来index %= _tables.size();++i;//如果已经遍历了一圈,说明全都为空或者删除,则直接break即可if (index == hashi){break;}}return nullptr;}//Erasebool Erase(const K& key){HashData<K, V>* ret = Find(key);//找到对应的元素,状态设为删除即可if (ret){ret->_state = DELETE;//调整容量--_n;return true;}else{return false;}}private://哈希表本质是一个vector,里面存放的都是HashData自定义类型数据vector <HashData<K,V>> _tables;//存储的数据个数size_t _n = 0;//HashData* tables;//size_t _size;//size_t _capacity;};
}
2.4.4开散列
闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷
于是有人想到用开散列的方式来实现哈希表
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶(Bucket),各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中
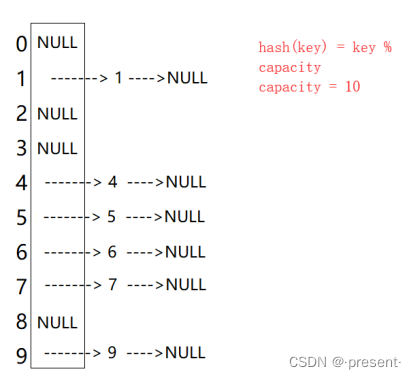
从上面的定义我们就可以看出来,开散列中的开是什么意思
虽然也需要考虑扩容问题,但是开散列有一个很显著的特征,它处理哈希冲突的方式简单又粗暴,直接挂到相应的桶即可,不需要再进行诸如线性探测,二次探测等等的操作
2.4.4.1 开散列增容
桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容
那该条件怎么确认呢?
开散列最好的情况是:每个哈希桶中刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可以给哈希表增容
2.4.4.2 映射方案
还有一些细节需要思考
第一个,就是映射元素的问题,在闭散列中,我们故意忽略了该问题,实际上,实现哈希表是无法躲开的
比如说下面的代码,假如是字符串,我们是无法挂到相应的桶的,需要人为将key转为整型(下面例子的key对应的就是string类型)
//哈希表不能映射字符串,只能映射整型void TestHashTable3(){//HashTable<string, string, HashStr> ht;HashTable<string, string> ht;ht.insert(make_pair("sort","排序"));ht.insert(make_pair("left", "左边"));ht.insert(make_pair("right", "右边"));ht.insert(make_pair("", "右边"));}
所以我们设计时,需要加入相应的模板,让用户自己传递相应的哈希函数实现,使得我们的哈希表能够适应不同类型的数据
具体如何将字符串映射为相应的整型,可以参照下面这篇文章
链接: 字符串Hash函数
在模拟实现开散列时,我们采取的是BKDR算法
template <class K>struct HashFunc {size_t operator()(const K& key){return key;}};//特化template <>struct HashFunc<string>{ //BKDRsize_t operator()(const string& s){size_t hashi = 0;for (auto ch : s){hashi = hashi * 131 + ch;}return hashi;}};
还有另外一个细节,我们扩容时采取的策略是扩2倍的方式,这当然没有问题,不过出于某种原因(效率上),现代大多采取开辟邻近相应的最大素数的方式
所以,我们下面的模拟实现开散列,也是直接仿照stl库中的方式,直接给出对应的素数大小空间,一旦超过元素和旧表大小相同,则开辟邻近最大素数大小的新表
size_t GetNextPrime(size_t prime){// SGIstatic const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};size_t i = 0;for (; i < __stl_num_primes; ++i){if (__stl_prime_list[i] > prime)return __stl_prime_list[i];}return __stl_prime_list[i];}
2.4.5 开散列代码实现
namespace HashBucket {template<class K,class V> //其实就类似于链表中的节点struct HashNode {HashNode<K, V>* _next;pair<K, V> _kv;//构造函数HashNode(const pair<K,V> & kv):_next(nullptr),_kv(kv){}};template <class K>struct HashFunc {size_t operator()(const K& key){return key;}};//特化,由于整型和字符串作为Key值最为常用,整型Hash函数直接作为//默认模板,而字符串Hash函数直接特化template <>struct HashFunc<string>{ //BKDRsize_t operator()(const string& s){size_t hashi = 0;for (auto ch : s){hashi = hashi * 131 + ch;}return hashi;}};template <class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public://析构函数~HashTable(){for (auto& cur : _tables){while (cur){Node* next = cur->_next;delete cur;cur = next;}cur = nullptr;}}//Find函数实现Node* Find(const K& key){//如果哈希表本身为空if (_tables.size() == 0){return nullptr;}Hash hash;//找到对应的数组下标size_t hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];//遍历链表while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;}//Erase函数实现bool Erase(const K& key){//如果哈希表本身为空if (_tables.size() == 0){return false;}//先确定对应的下标size_t hashi = key % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){ //假设找到对应要删除的元素if (cur->_kv.first == key){//假设就为头节点,直接调整头节点if (prev == nullptr){_tables[hashi] = cur->_next;}//不为头节点,让prev指向cur的下一个节点即可else{prev->_next = cur->_next;}//删除当前节点delete cur;return true;}//没有找到对应要删除的元素,cur和prev往后移动else{prev = cur;cur = cur->_next;}}return false;}//insert函数实现bool insert(const pair<K, V>& kv){//如果找到对应相同的元素,则直接返回falseif (Find(kv.first))return false;Hash hash;//哈希表长度为0或负载因子为1时扩容,尽量让每条链不超过三个节点if (_n == _tables.size()){//size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;size_t newsize = GetNextPrime(_tables.size());//与闭散列不同,哈希桶扩容释放旧哈希桶,不断析构,代价还是有点大的//所以我们采取直接将节点,挂到新哈希桶的方法vector <Node*> newtables(newsize, nullptr);for (auto& cur : _tables){//只要cur不为空,则将链表挂到新哈希桶上while (cur){Node* next = cur->_next;//找到需要挂的新位置size_t hashi = hash(cur->_kv.first) % newtables.size();//头插挂到新哈希桶cur->_next = newtables[hashi];newtables[hashi] = cur;//向后一个节点移动cur = next;}}_tables.swap(newtables);}//正式插入代码//找到需要挂的新位置size_t hashi = hash(kv.first) % _tables.size();//建新节点Node* newnode = new Node(kv);//头插newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}size_t GetNextPrime(size_t prime){// SGIstatic const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};size_t i = 0;for (; i < __stl_num_primes; ++i){if (__stl_prime_list[i] > prime)return __stl_prime_list[i];}return __stl_prime_list[i];}size_t MaxSizeBucket(){size_t max = 0;//遍历每一个哈希桶for (size_t i = 0;i < _tables.size();i++){auto cur = _tables[i];size_t size = 0;//一直到空指针为止while (cur){size++;cur = cur->_next;}printf("[%d] --> %d\n", i, size);//如果比最大值要大,则更新最大桶值if (size > max){max = size;}}return max;}private://自定义类型的指针数组vector<Node*> _tables;//数组大小(有效数据个数)size_t _n = 0;};}
相关文章:
哈希unordered系列介绍(上)
一.Unordered_map,Unordered_set介绍 在之前我们已经介绍过set,map,multiset等等关联式容器,它们的底层是红黑树进行模拟实现的,在查询时效率可达到 l o g 2 N log_2 N log2N,即最差情况下需要比较红黑树的高度次,当树中的节点…...

MySQL随心记第二篇
一、正则表达式篇: regular expression--> regexp 元字符: . : 单个的任意字符(默认不包含换行) \d:数字: 0-9 补集:\D \w:ascil:数字,大写字母,小写字母,以及下划线 unicode: 数字,大…...
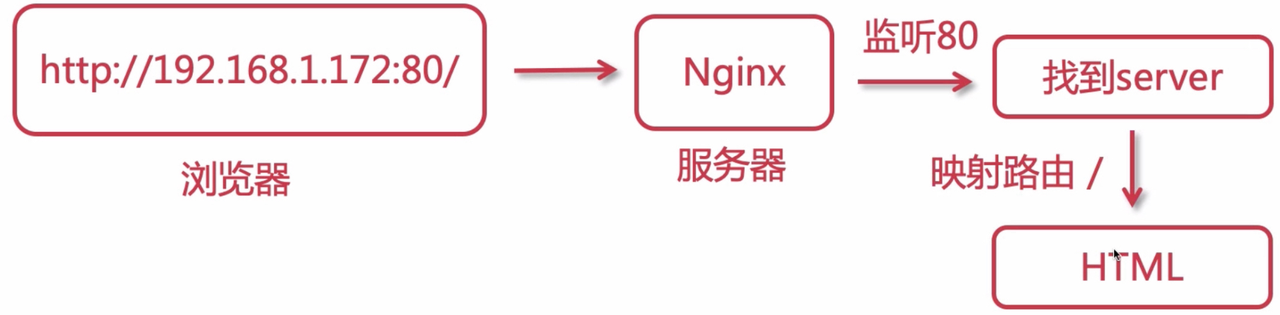
0001nginx简介、相关模型与原理
文章目录 一. 什么是Nginx二. ngnix的一些模型1、nginx的进程模型2、worker的抢占(锁)机制模型3. nginx事件处理模型 三. nginx加载静态资源的过程 一. 什么是Nginx Nginx是一个高性能HTTP反向代理服务器,以下是nginx的相关能力 反向代理&am…...
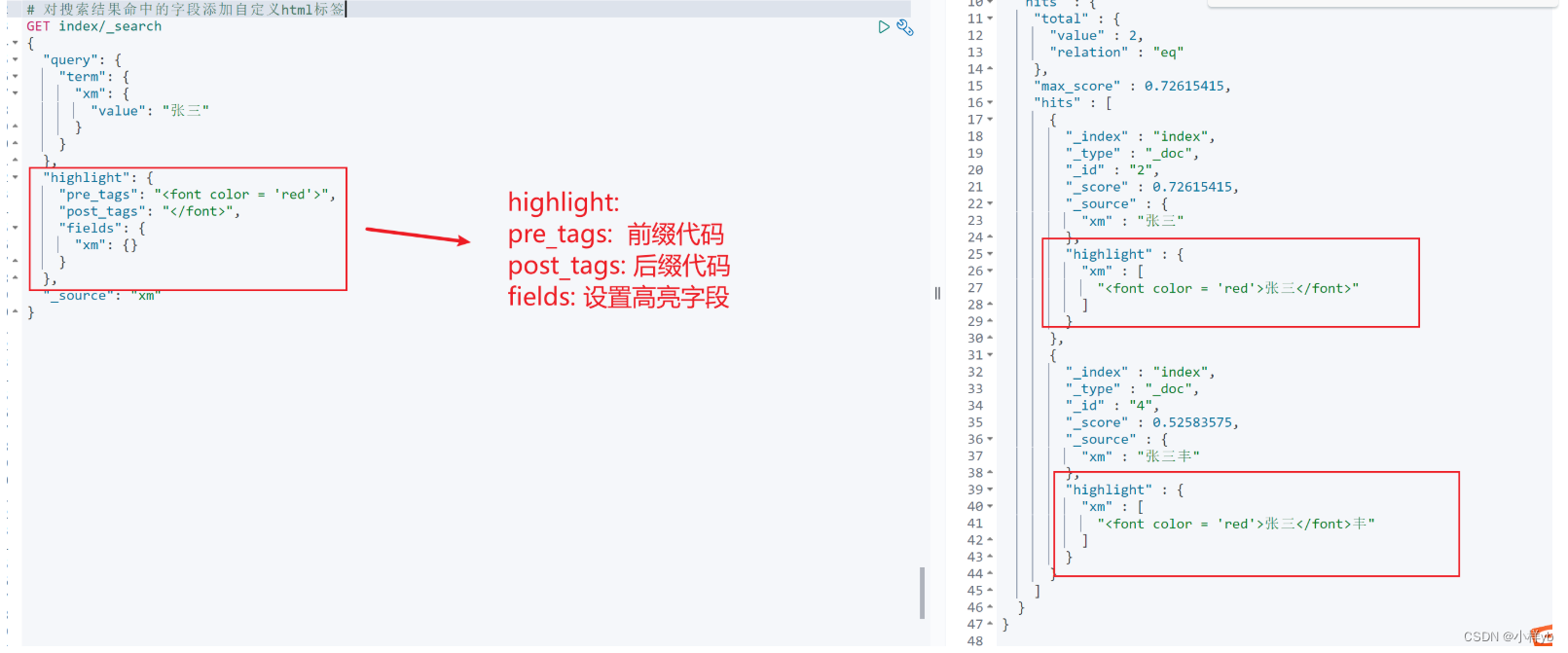
elasticsearch简单入门语法
基本操作 创建不同的分词器 ik_smart: 极简分词 ; ik_max_word: 最细力再度分词 基本的rest命令 methodurl地址描述PUTlocalhost:9200/索引名称/类型名称/文档id创建文档(指定文档id)POSTlocalhost:9200/索引名称/类型名称创建文…...

Python自动化测试用例:如何优雅的完成Json格式数据断言
目录 前言 直接使用 优化 封装 小结 进阶 总结 资料获取方法 前言 记录Json断言在工作中的应用进阶。 直接使用 很早以前写过一篇博客,记录当时获取一个多级json中指定key的数据: #! /usr/bin/python # coding:utf-8 """ aut…...

阿里云对象存储服务OSS
1、引依赖 <dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.15.1</version> </dependency> <dependency><groupId>javax.xml.bind</groupId><artifa…...
第三节:在WORD为应用主窗口下关闭EXCEL的操作(1)
【分享成果,随喜正能量】夏日里的遗憾,一定都会被秋风温柔化解。吃素不难,难于不肯捨贪口腹之心。若不贪口腹,有何吃素之不便乎。虽吃华素,不吃素日,亦须少吃。以一切物类,皆是贪生怕死…...

mybatis 缓存
很久没有弄mybatis了,以至于今天在使用时忘记了一个很重事情(缓存),导致始终读取不数据库更新之后的最新的数据,后来折腾了小半天才想起缓存,所有小记住一下关闭mybatis的缓存 mybatis.configuration.cach…...
分布式Redis详解
目录 前言安装redis的俩种方法Redis 与 MySQL的区别Redis可以实现那些功能Redis常用的数据类型有序列表的底层是如何实现的?什么是跳跃表 Redis在Spring中的使用Redis 中为什么单线程比多线程快Redis的分布式锁如何实现Redis 分布式锁可能出现的问题Redis保持数据不丢失的方式…...
揭秘程序员和技师的7大共同点,最后一点绷不住了
大家好,这里是程序员晚枫,周末朋友出去放松回来,给我分析了一下程序员和技师的7个相同点,尤其是最后一点让我彻底绷不住了! 我也分享给大家。 1、都有工号。98号技师,380号技师大家都很熟悉了,…...
SQL | 使用函数处理数据
8-使用函数处理数据 8.1-函数 SQL可以用函数来处理数据。函数一般是在数据上执行的,为数据的转换和处理提供了方便。 8.1.1 函数带来的问题 每种DBMS都有特定的函数,只有很少一部分函数,是被所有主要的DBMS等同的支持。 虽然所有的类型的…...
基于Dlib库+SVM+Tensorflow+PyQT5智能面相分析-机器学习算法应用(含全部工程源码)+训练及测试数据集
目录 前言总体设计系统整体结构图系统流程图模型流程 运行环境Python 环境TensorFlow环境界面编程环境 模块实现1. 数据预处理2. 模型构建1)定义模型结构2)交叉验证模型优化 3. 模型训练及保存4. 模型测试1)摄像头调用2)模型导入及…...

【Flutter】【packages】simple_animations 简单的实现动画
package:simple_animations 导入包到项目中去 可以实现简单的动画, 快速实现,不需要自己过多的设置 有多种样式可以实现[ ] 功能: 简单的用例:具体需要详细可以去 pub 链接地址 1. PlayAnimationBuilder PlayAnima…...
python之matplotlib入门初体验:使用Matplotlib进行简单的图形绘制
目录 绘制简单的折线图1.1 修改标签文字和线条粗细1.2 校正图形1.3 使用内置样式1.4 使用scatter()绘制散点图并设置样式1.5 使用scatter()绘制一系列点1.6 python循环自动计算数据1.7 自定义颜色1.8 使用颜色映射1.9 自动保存图表练习题 绘制简单的折线图 绘制一个简单折线图…...

[Linux kernel] [ARM64] boot 流程梳理
一、启动汇编代码部分 0. 链接文件找代码段入口 – _text arch/arm64/kernel/vmlinux.lds.S ENTRY(_text). KIMAGE_VADDR;.head.text : {_text .;HEAD_TEXT}.text : ALIGN(SEGMENT_ALIGN) { /* Real text segment */_stext .; /* Text and read-only data */IRQENTRY_TE…...

重建二叉树
输入一棵二叉树前序遍历和中序遍历的结果,请重建该二叉树。 注意: 二叉树中每个节点的值都互不相同;输入的前序遍历和中序遍历一定合法; 数据范围 树中节点数量范围 [0,100] 。 样例 给定: 前序遍历是:[3, 9, 2…...

支付整体架构
5.4 支付的技术架构 架构即未来,只有建立在技术架构设计良好的体系上,支付机构才能有美好的未来。如果支付的技术体系在架构上存在问题,那么就没有办法实现高可用性、高安全性、高效率和水平可扩展性。 总结多年来在海内外支付机构主持和参与…...

百度智能云:千帆大模型平台接入Llama 2等33个大模型,上线103个Prompt模板
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的…...
烦人的幻灯片——拓扑排序
烦人的幻灯片 烦人的幻灯片问题描述输入输出格式输入格式输出格式 输入输出样例输入样例:输入样例一:输入样例二: 输出样例:输出样例一:输出样例二: 正确做法拓扑排序 代码 烦人的幻灯片 问题描述 李教授…...

无涯教程-Perl - ord函数
描述 此函数返回EXPR指定的字符的ASCII数值,如果省略则返回$_。例如,ord(A)返回值为65。 语法 以下是此函数的简单语法- ord EXPRord返回值 该函数返回整数。 例 以下是显示其基本用法的示例代码- #!/usr/bin/perl -wprint("ord() ", ord(G), "\n"…...

新手必学!PDF导出为矢量图不模糊,5种实用方法速会
在数字化办公的日常中,PDF文件的使用频率越来越高,但将其导出为矢量图却常常让人头疼。很多时候,要么PDF导出矢量图后放大模糊失真,要么面对众多工具不知如何选择,浪费了大量时间。其实PDF导出矢量图并不难,…...

如何利用Page Assist打造完全私密的AI浏览助手:本地化智能网页辅助完整指南
如何利用Page Assist打造完全私密的AI浏览助手:本地化智能网页辅助完整指南 【免费下载链接】page-assist Use your locally running AI models to assist you in your web browsing 项目地址: https://gitcode.com/GitHub_Trending/pa/page-assist Page Ass…...

AI Agent:从“科幻概念“到“生活必需品“的进化之路
想象一下,如果钢铁侠的贾维斯不再是电影里的幻想,而是每天早上帮你规划日程、处理邮件、甚至帮你写周报——这就是AI Agent正在做的事情。 一、先搞清楚:AI Agent到底是什么? 很多人把AI Agent和ChatGPT混为一谈,这就像把"瑞士军刀"和"瑞士军刀工厂"…...

RK3588 MPP解码实战:从mpi_dec_test源码剖析到自定义解码器开发
1. RK3588 MPP解码框架初探 第一次接触RK3588的MPP解码框架时,我完全被它强大的视频处理能力震撼到了。这块芯片内置的硬解模块能轻松应对4K60fps的视频解码,功耗却只有软件解码的十分之一。官方提供的mpi_dec_test demo就像一把钥匙,帮我打开…...
:性能压测数据+等保审计支持度+厂商服务SLA三维度权威评测)
Docker+Kubernetes国产化栈终极选型对比(龙蜥Anolis OS vs 欧拉openEuler vs 中标麒麟):性能压测数据+等保审计支持度+厂商服务SLA三维度权威评测
第一章:Docker国产化演进背景与政策合规全景图近年来,随着《网络安全法》《数据安全法》《关键信息基础设施安全保护条例》及信创产业“28N”体系的纵深推进,容器技术的自主可控成为政务、金融、能源等关键行业基础设施升级的核心关切。Docke…...

Mermaid Live Editor:5分钟学会的终极免费在线图表编辑器
Mermaid Live Editor:5分钟学会的终极免费在线图表编辑器 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-edi…...

JDK 17强封装性引发的‘血案’:ShardingSphere/MyBatis项目升级踩坑实录与一劳永逸的配置
JDK 17强封装性引发的技术适配困境:ShardingSphereMyBatis深度调优指南 当Java生态迈入模块化时代,JDK 17带来的强封装特性像一把双刃剑,在提升安全性的同时,也让许多依赖反射机制的传统框架陷入适配困境。最近在将ShardingSphere…...

保姆级教程:在RK3588 Android 12上配置硬件看门狗,解决系统卡死重启问题
RK3588 Android 12硬件看门狗深度配置指南:从内核到应用层的完整解决方案 在嵌入式系统开发中,系统稳定性是衡量产品质量的关键指标之一。RK3588作为Rockchip旗舰级处理器,广泛应用于智能终端、工业控制等领域,其硬件看门狗功能为…...

嵌入式C代码如何喂饱轻量级大模型?:揭秘ARM Cortex-M7上LLM推理延迟从2800ms压至197ms的7个关键编译器指令级优化
第一章:嵌入式C语言与轻量级大模型适配性能调优指南在资源受限的嵌入式设备(如 Cortex-M7、ESP32-S3 或 RISC-V MCU)上部署轻量级大模型(如 TinyLlama、Phi-3-mini、TinyBERT)时,C语言仍是底层推理引擎的核…...

如何利用分区进行并行DML_开启会话并行针对不同分区同时执行更新
Oracle分区表UPDATE需同时满足四个条件才启用并行DML:会话级启用ENABLE_PARALLEL_DML、SQL中显式添加PARALLEL提示、WHERE条件实现精准分区裁剪、避免绑定变量导致裁剪失效。Oracle 分区表更新时 ENABLE_PARALLEL_DML 不生效?并行 dml 默认是关闭的&…...