econml双机器学习实现连续干预和预测
连续干预
在这个示例中,我们使用LinearDML模型,使用随机森林回归模型来估计因果效应。我们首先模拟数据,然后模型,并使用方法来effect创建不同干预值下的效应(Conditional Average Treatment Effect,CATE)。
请注意,实际情况中的数据可能更加复杂,您可能需要根据您的数据和问题来适当选择的模型和参数。此示例仅供参考,您可以根据需要进行修改和扩展。
import numpy as np
from econml.dml import LinearDML# 生成示例数据
np.random.seed(123)
n_samples = 1000
n_features = 5
X = np.random.normal(size=(n_samples, n_features))
T = np.random.uniform(low=0, high=1, size=n_samples) # 连续干预变量
y = 2 * X[:, 0] + 0.5 * X[:, 1] + 3 * T + np.random.normal(size=n_samples)# 初始化 LinearDML 模型
est = LinearDML(model_y='auto', model_t='auto', random_state=123)# 拟合模型
est.fit(y, T, X=X)# 给定特征和连续干预值,计算干预效应
X_pred = np.random.normal(size=(10, n_features)) # 假设有新的数据点 X_pred
T_pred0 = np.array([0]*10) # 指定的连续干预值
T_pred11 = np.array([0.2, 0.4, 0.6, 0.8, 1.0, 0.3, 0.5, 0.7, 0.9, 0.1]) # 指定的连续干预值
T_pred1 = np.array([0.2]*10) # 指定的连续干预值
T_pred2 = np.array([0.4]*10) # 指定的连续干预值
T_pred3 = np.array([0.6]*10) # 指定的连续干预值
T_pred4 = np.array([0.8]*10) # 指定的连续干预值# 计算连续干预效应
effect_pred = est.effect(X=X_pred, T0=T_pred0, T1=T_pred11)print("预测的连续干预效应:", effect_pred)# 计算连续干预效应
effect_pred = est.effect(X=X_pred, T0=T_pred0, T1=T_pred1)print("预测的连续干预效应:", effect_pred)The R Learner is an approach for estimating flexible non-parametric models of conditional average treatment effects in the setting with no unobserved confounders. The method is based on the idea of Neyman orthogonality and estimates a CATE whose mean squared error is robust to the estimation errors of auxiliary submodels that also need to be estimated from data:
the outcome or regression model
the treatment or propensity or policy or logging policy model
使用随机实验数据进行双重机器学习(DML)训练可能会在某些情况下获得更好的效果,但并不是绝对的规律。DML方法的性能取决于多个因素,包括数据质量、特征选择、模型选择和调参等。
使用随机实验数据进行训练的优势在于,实验数据通常可以更好地控制混淆因素,从而更准确地估计因果效应。如果实验设计得当,并且随机化合理,那么通过DML训练的模型可以更好地捕捉因果关系,从而获得更准确的效应估计。
然而,即使使用随机实验数据,DML方法仍然需要考虑一些因素,例如样本大小、特征的选择和处理、模型的选择和调参等。在实际应用中,没有一种方法可以适用于所有情况。有时,随机实验数据可能会受到实验设计的限制,或者数据质量可能不足以获得准确的效应估计。
因此,使用随机实验数据进行DML训练可能会在某些情况下获得更好的效果,但并不是绝对的规律。在应用DML方法时,仍然需要根据实际情况进行数据分析、模型选择和验证,以确保获得准确和可靠的因果效应估计。
连续干预/label01
import numpy as np
from econml.dml import LinearDML
import scipy# 生成示例数据
np.random.seed(123)
n_samples = 1000
n_features = 5
X = np.random.normal(size=(n_samples, n_features))
T = np.random.uniform(low=0, high=1, size=n_samples) # 连续干预变量
#y = 2 * X[:, 0] + 0.5 * X[:, 1] + 3 * T + np.random.normal(size=n_samples)
y = np.random.binomial(1, scipy.special.expit(X[:, 0]))# 初始化 LinearDML 模型
est = LinearDML(model_y='auto', model_t='auto', random_state=123)# 拟合模型
est.fit(y, T, X=X)# 给定特征和连续干预值,计算干预效应
X_pred = np.random.normal(size=(10, n_features)) # 假设有新的数据点 X_pred
T_pred0 = np.array([0]*10) # 指定的连续干预值
T_pred11 = np.array([0.2, 0.4, 0.6, 0.8, 1.0, 0.3, 0.5, 0.7, 0.9, 0.1]) # 指定的连续干预值
T_pred1 = np.array([0.2]*10) # 指定的连续干预值
T_pred2 = np.array([0.4]*10) # 指定的连续干预值
T_pred3 = np.array([0.6]*10) # 指定的连续干预值
T_pred4 = np.array([0.8]*10) # 指定的连续干预值# 计算连续干预效应
effect_pred = est.effect(X=X_pred, T0=T_pred0, T1=T_pred11)print("预测的连续干预效应:", effect_pred)
预测的连续干预效应: [-0.00793674 0.00612109 0.03141778 0.00310806 -0.01635394 -0.019054340.06801354 -0.0126543 -0.04603434 0.00821044]
dml原理
Double Machine Learning, DML。
方法:首先通过X预测T,与真实的T作差,得到一个T的残差,然后通过X预测Y,与真实的Y作差,得到一个Y的残差,预测模型可以是任何ML模型,最后基于T的残差和Y的残差进行因果建模。
原理:DML采用了一种残差回归的思想。
优点:原理简单,容易理解。预测阶段可以使用任意ML模型。
缺点: 需要因果效应为线性的假设。
应用场景:适用于连续Treatment且因果效应为线性场景

单调性约束
因果推断的开源包中,有一些可以进行单调性约束的案例。这些案例通常涉及到因果效应的估计,同时加入了单调性约束以确保结果更加合理和可解释。以下是一些开源包以及它们支持单调性约束的案例示例:
-
CausalML(https://causalml.readthedocs.io/):
CausalML 是一个开源的因果推断工具包,支持单调性约束。它提供了一些可以用于处理单调性约束的方法,例如SingleTreatment类。您可以使用该包来在处理因果效应时添加单调性约束。
-
econml(https://econml.azurewebsites.net/):
- econml 也是一个用于因果推断的工具包,支持单调性约束。它提供了一些工具,如
SingleTreePolicyInterpreter和SingleTreeCateInterpreter,用于解释单一决策树的因果效应,并且可以根据用户指定的特征添加单调性约束。
- econml 也是一个用于因果推断的工具包,支持单调性约束。它提供了一些工具,如
SingleTreeCateInterpreter(_SingleTreeInterpreter):"""An interpreter for the effect estimated by a CATE estimatorParameters----------include_model_uncertainty : bool, default FalseWhether to include confidence interval information when building asimplified model of the cate model. If set to True, thencate estimator needs to support the `const_marginal_ate_inference` method.uncertainty_level : double, default 0.05The uncertainty level for the confidence intervals to be constructedand used in the simplified model creation. If value=alphathen a multitask decision tree will be built such that all samplesin a leaf have similar target prediction but also similar alphaconfidence intervals.uncertainty_only_on_leaves : bool, default TrueWhether uncertainty information should be displayed only on leaf nodes.If False, then interpretation can be slightly slower, especially for catemodels that have a computationally expensive inference method.
相关文章:
econml双机器学习实现连续干预和预测
连续干预 在这个示例中,我们使用LinearDML模型,使用随机森林回归模型来估计因果效应。我们首先模拟数据,然后模型,并使用方法来effect创建不同干预值下的效应(Conditional Average Treatment Effect,CATE&…...

《甲午》观后感——GPT-3.5所写
《甲午》是一部令人深思的纪录片,通过生动的画面和真实的故事,向观众展示了中国历史上的一段重要时期。观看这部纪录片,我深受触动,对历史的认识也得到了深化。 首先,这部纪录片通过精心搜集的历史资料和珍贵的影像资料…...
—— 微服务篇)
Java技术整理(6)—— 微服务篇
1、服务注册发现 服务注册就是维护一个服务列表,它在管理系统内所有的服务地址,当新的服务启动后,它会向服务列表提交自己的服务地址,服务的调用法可以直接向服务列表发送服务列表获取请求,就能获得所有的服务地址&am…...

途乐证券-新股行情持续火爆,哪些因素影响首日表现?
全面注册制以来,参加打新的投资者数量全体呈现下降。打新收益下降,破发频出的布景下,投资者打新策略从逢新必打逐步向优选个股改变。 经过很多历史数据,从商场定价、参加者热度以及机构重视度维度揭秘了上市后股价体现优秀的个股具…...

在生产环境中部署Elasticsearch:最佳实践和故障排除技巧——聚合与搜索(三)
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

基于weka手工实现KNN
一、KNN模型 K最近邻(K-Nearest Neighbors,简称KNN)算法是一种常用的基于实例的监督学习算法。它可以用于分类和回归问题,并且是一种非常直观和简单的机器学习算法。 KNN算法的基本思想是:对于一个新的样本数据&…...

Lua 闭包
一、Lua 中的函数 Lua 中的函数是第一类值。意味着和其他的常见类型的值(例如数值和字符串)具有同等权限。 举个例子,函数也可以像其他类型一样存储起来,然后调用 -- 将 a.p 指向 print 函数 a { p print } -- 使用 a.p 函数…...
—— JVM篇)
Java技术整理(1)—— JVM篇
1、什么是JVM? JVM是一个可运行Java代码的虚拟计算机,包括一套字节码指令集,一组寄存器,一个栈,一个垃圾回收,堆和一个存储方式栈。JVM 是运行在操作系统之上,并不与操作系统直接交互。 2、运行…...
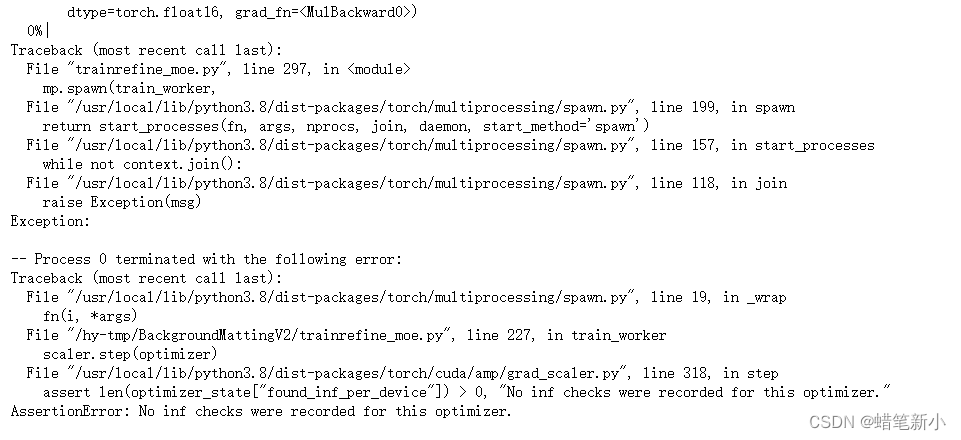
bug解决:AssertionError: No inf checks were recorded for this optimizer.
这真的是最恶心的一个error(比网络回传找哪层没有传播到还要恶心!),找了好久的问题所在之处,最后偶然发现了这篇文章: 解决pytorch半精度amp训练nan问题 - 知乎 然后发现自己用的混合精度训练,发…...

Django笔记之数据库查询优化汇总
1、性能方面 1. connection.queries 前面我们介绍过 connection.queries 的用法,比如我们执行了一条查询之后,可以通过下面的方式查到我们刚刚的语句和耗时 >>> from django.db import connection >>> connection.queries [{sql: S…...
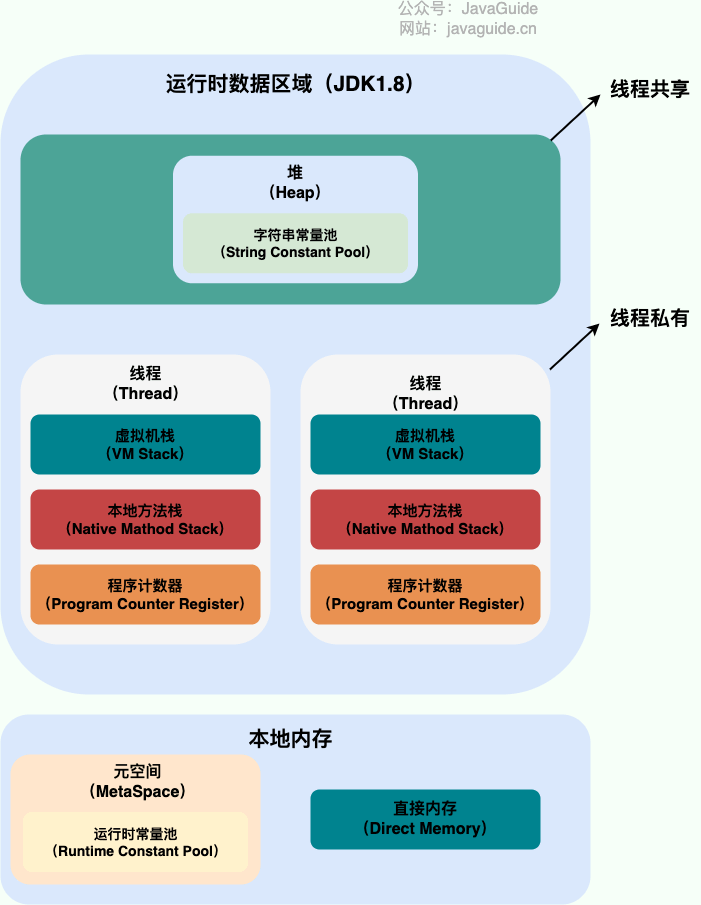
JVM内存区域
预备 为了更好的理解类加载和垃圾回收,先要了解一下JVM的内存区域(如果没有特殊说明,都是针对的是 HotSpot 虚拟机。)。 Java 源代码文件经过编译器编译后生成字节码文件,然后交给 JVM 的类加载器,加载完…...
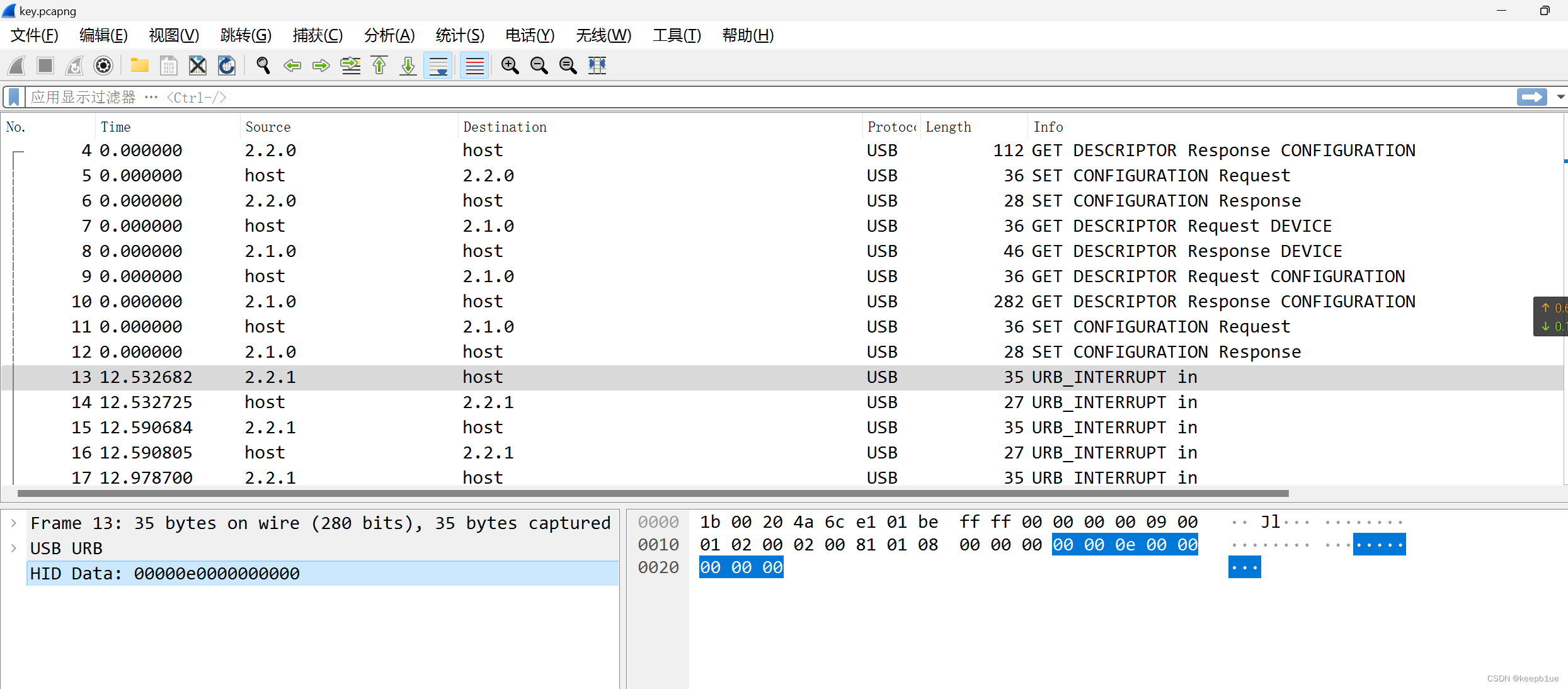
某行业CTF一道流量分析题
今晚看了一道题,记录学习下。 给了一个hacktrace.pcapng,分析主要内容如下: 上传两个文件,一个mouse.m2s,一个mimi.zip,将其导出。 mimi.zip中存放着secret.zip和key.pcapng 不过解压需要密码ÿ…...
【Kafka】1.Kafka简介及安装
目 录 1. Kafka的简介1.1 使用场景1.2 基本概念 2. Kafka的安装2.1 下载Kafka的压缩包2.2 解压Kafka的压缩包2.3 启动Kafka服务 1. Kafka的简介 Kafka 是一个分布式、支持分区(partition)、多副本(replica)、基于 zookeeper 协调…...
Kafka API与SpringBoot调用
文章目录 首先需要命令行创建一个名为cities的主题,并且创建该主题的订阅者。 1、使用Kafka原生API1.1、创建spring工程1.2、创建发布者1.3、对生产者的优化1.4、批量发送消息1.5、创建消费者组1.6 消费者同步手动提交1.7、消费者异步手动提交1.8、消费者同异步手动…...

JavaScript构造函数和类的区别
原文 构造函数 没有显式的创建对象创建对象时使用new操作符。所有属性和方法赋值给this对象。没有return语句按照惯例,构造函数的方法名首字母应该使用大写字母,用于区分普通函数,其实构造函数也是函数,其主要功能是用来创建对象…...
Spring与Spring Bean
Spring 原理 它是一个全面的、企业应用开发一站式的解决方案,贯穿表现层、业务层、持久层。但是 Spring 仍然可 以和其他的框架无缝整合。 Spring 特点 轻量级 控制反转 面向切面 容器 框架集合 Spring 核心组件 Spring 总共有十几个组件核心容器(Spring core) S…...
并发相关面试题
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 如何理解volatile关键字 在并发领域中,存在三大特性:原子性、有序性、可见性。volatile关键字用来修饰对象的属性…...
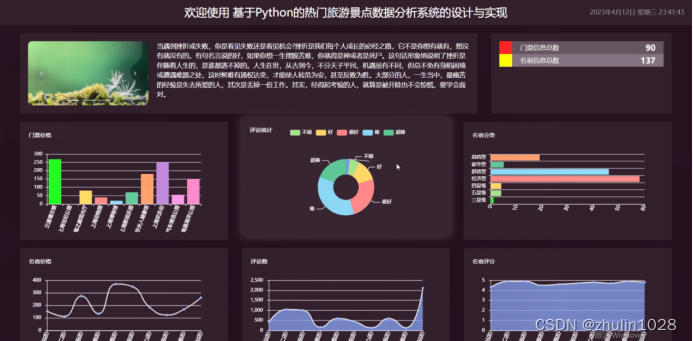
Hadoop+Python+Django+Mysql热门旅游景点数据分析系统的设计与实现(包含设计报告)
系统阐述的是使用热门旅游景点数据分析系统的设计与实现,对于Python、B/S结构、MySql进行了较为深入的学习与应用。主要针对系统的设计,描述,实现和分析与测试方面来表明开发的过程。开发中使用了 django框架和MySql数据库技术搭建系统的整体…...

php中nts和ts
PHP语言解析器:官方提供了2种类型的版本,线程安全(TS)版和非线程安全(NTS)版 TS: TS(Thread-Safety)即线程安全,多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时进行数据加锁保护,其他线程不能同时进行访…...
设计模式之责任链模式【Java实现】
责任链(Chain of Resposibility) 模式 概念 责任链(chain of Resposibility) 模式:为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者 通过前一对象记住其下一个对象的引用而连成一条…...

下午题_试题二
目录 一.题型 注意:需求分析、ER图(概念模型设计)、关系模式化(逻辑结构设计)三者的关系 二.目标分数 三.知识讲解 1.E-R图基本图形元素 ①实体 ②属性 ③联系(重要考点) 2.关系模式&a…...
)
告别手动转换!用Python+Mikeio一键将ERA5风场数据喂给MIKE模型(附完整代码)
从ERA5到MIKE模型:Python自动化风场数据处理实战指南 每次手动转换气象数据格式时,那些重复的点击操作和容易出错的坐标调整是否让你感到疲惫?当项目周期紧张而数据处理却占据大半时间,工程师们真正需要的是像流水线一样可靠的数据…...

罗茨风机行业专题研究:要10家靠谱的回转风机厂家或罗茨鼓风机厂家名单
随着我国工业现代化进程加速及环保政策趋严,罗茨风机作为污水处理、电力、化工等领域的关键设备,市场需求持续增长。据中国通用机械工业协会统计,2024年我国罗茨风机市场规模达82.3亿元,年复合增长率7.5%,行业呈现技术…...

别再暴力匹配了!用DBoW2词袋模型5分钟搞定ORB-SLAM2回环检测
从暴力匹配到高效检索:DBoW2词袋模型在ORB-SLAM2回环检测中的实战优化 当你在Jetson Nano上运行ORB-SLAM2时,是否经历过回环检测模块成为整个系统性能瓶颈的困扰?传统暴力匹配方法在面对数万张历史关键帧时,其O(N)的时间复杂度足以…...

AI-比赛-天池比赛:乘用车零售量预测
本次大赛分为初赛、复赛和决赛三个阶段,其中:初赛由参赛队伍下载数据在本地进行算法设计和调试;复赛要求参赛者在线进行数据分析和处理;决赛要求参赛者进行现场演示和答辩。具体安排和要求如下: 初赛(2018…...

Malloy 渲染系统深度解析:如何创建交互式数据可视化
Malloy 渲染系统深度解析:如何创建交互式数据可视化 【免费下载链接】malloy Malloy is a modern open source language for describing data relationships and transformations. 项目地址: https://gitcode.com/gh_mirrors/ma/malloy Malloy 是一款现代开源…...

题解:洛谷 AT_abc391_d [ABC391D] Gravity
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大家订阅我的专栏:算法…...

YOLO12问题解决:常见报错处理,服务重启与参数调整指南
YOLO12问题解决:常见报错处理,服务重启与参数调整指南 1. 引言 YOLO12作为2025年最新发布的目标检测模型,凭借其创新的注意力机制架构,在实时检测领域展现出卓越性能。但在实际部署和使用过程中,开发者可能会遇到各种…...

霜儿-汉服-造相Z-Turbo一键部署:预装Xinference+Gradio+LoRA权重的全栈镜像
霜儿-汉服-造相Z-Turbo一键部署:预装XinferenceGradioLoRA权重的全栈镜像 1. 快速了解霜儿-汉服-造相Z-Turbo 如果你对古风汉服人像生成感兴趣,霜儿-汉服-造相Z-Turbo镜像是一个开箱即用的解决方案。这个镜像基于Z-Image-Turbo构建,专门针对…...

终极Firefox优化指南:使用Betterfox提升隐私安全与浏览体验
终极Firefox优化指南:使用Betterfox提升隐私安全与浏览体验 【免费下载链接】Betterfox Firefox user.js for optimal privacy and security. Your favorite browser, but better. 项目地址: https://gitcode.com/GitHub_Trending/be/Betterfox Betterfox是一…...