06-hadoop集群搭建(root用户)
搭建Hadoop集群流程
环境准备
1、基础环境的搭建(内网封火墙关闭、主机名、规划好静态ip、hosts映射、时间同步ntp、jdk、ssh免密等)
2、Hadoop源码编译(为了适应不同操作系统间适配本地库、本地环境等)
3、Hadoop配置文件的修改(shell文件、4个xml文件、workers文件)
4、配置文件集群同步(scp进行分发)
具体流程如下:
常用命令(这部分看情况而定)
vim /etc/sysconfig/network-scripts/ifcfg-ens33# 做出如下修改
BOOTPROTO=static # 改为静态
# 末尾添加如下内容
IPADDR=192.168.188.128
GATEWAY=192.168.188.2
NETMASK=255.255.255.0
DNS1=114.114.114.114# 重启网卡
systemctl restart network.service# 修改主机名
vim /etc/hostname
# 配置hosts映射
vim /etc/hosts
192.168.188.128 kk01
192.168.188.129 kk02
192.168.188.130 kk03# 修改window的主机映射文件(hosts)
# 进入C:\Windows\System32\drivers\etc
# 添加如下内容
192.168.188.128 kk01
192.168.188.129 kk02
192.168.188.130 kk03
# 查看防火墙状态
firewall-cmd --state
# 或
systemctl status firewalld.service systemctl stop firewalld.service # 关闭当前防火墙
systemctl disable firewalld.service # 关闭防火墙开机自启动
创建普通用户,并让其具有root权限(如果使用root用户可以忽略该步骤)
# 创建用户 (如果安装Linux时已经创建了,这一步骤可以忽略)
useradd nhk
passwd 123456# 配置普通用户(nhk)具有root权限,方便后期加sudo执行root权限的命令
vim /etc/sudoers# 在%wheel这行下面添加一行 (大概是在100行左右位置)## Allow root to run any commands anywhere
root ALL=(ALL) ALL ## Allows members of the 'sys' group to run networking, software,
## service management apps and more.
# %sys ALL = NETWORKING, SOFTWARE, SERVICES, STORAGE, DELEGATING, PROCESSES, LOCATE, DRIVERS## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL ## Same thing without a password
# %wheel ALL=(ALL) NOPASSWD: ALL
nhk ALL=(ALL) NOPASSWD: ALL
注意:
nhk ALL=(ALL) NOPASSWD: ALL 这行内容要放在%wheel下面,千万不能放在root下面
创建统一工作目录
(后续在集群的多台机器之间都需要创建)
# 个人习惯
mkdir -p /opt/software/ # 软件安装目录、安装包存放目录
mkdir -p /opt/data/ # 数据存储路径# 修改文件夹所有者和所属组 (如果是使用root用户搭建集群可以忽略)
chown nhk:nhk /opt/software
chown nhk:nhk /opt/data# 黑马推荐
mkdir -p /export/server/ # 软件安装目录
mkdir -p /export/data/ # 数据存储路径
mkdir -p /export/software/ # 安装包存放目录SSH免密登录
# 只需配置(kk01 --> kk01 kk02 kk03 即可 )
ssh-keygen # kk01生成公钥、私钥# 配置免密 kk01 --> kk01 kk02 kk03
ssh-copy-id kk01
ssh-copy-id kk02
ssh-copy-id kk03
集群时间同步
# 在集群的每台集群
yum -y install ntpdate ntpdate ntp4.aliyun.com
# 或
ntpdate ntp5.aliyum.com# 查看时间
date
卸载Linux自带的jdk
(如果Linux这没有自带open jdk,则忽略此步骤)
# 查看jdk命令
rpm -qa | grep -i java # -i 忽略大小写
# 删除
rpm -e –nodeps 待删除的jdk # 也可以使用以下命令删除
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
# 其中 xargs -n1表示每次只传递一个参数
# -e --nodeps表强制卸载软件# 删除完后,使用以下命令查看jdk是否还在
java -version
配置JDK环境变量
注意:在安装jdk之前,一定要确保Linux自带的jdk已经被卸载
# 上传jdk压缩包(使用rz命令或者ftp工具)# 解压jdk
tar -zxvf jdk-8u152-linux-x64.tar.gz -C /opt/software/# 配置JDK环境(如果是普通用户进入需要加sudo)
sudo vim /etc/profileexport JAVA_HOME=/opt/software/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar# 重新加载环境变量文件
source /etc/profile
Hadoop安装
解压Hadoop压缩包
# 上传Hadoop压缩包
cd /opt/software/
rz# 解压
tar -xvzf hadoop-3.2.2.tar.gz
# 在每个节点中创建用于存放数据的data目录
配置文件描述
第一类1个:hadoop-env.sh
第二类4个:xxxx-site.xml,site表示是用户自定义的配置,会默认覆盖default默认配置
core-site.xml 核心模块配置
hdfs-site.xml hdfs文件系统模块配置
mapred-site.xml mapreduce模块配置
yarn-site.xml yarn模块配置
第三类1个:workers
所有的配置文件目录文件:/opt/software/haoop-3.2.2/etc/hadoop
配置NameNode(core-site.xml)
cd /opt/software/hadoop-3.2.2/etc/hadoop
vim core-site.xml # 添加如下内容
<!-- 数组默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统-->
<property><name>fs.defaultFS</name><value>hdfs://kk01:8020</value><description>指定NameNode的URL</description>
</property><!-- 设置hadoop本地保存数据路径-->
<property><name>hadoop.tmp.dir</name><!--可以配置在/opt/data/hadoop-3.2.2,但是我们建议配置在${HADOOP_HOME}/data下面--><value>/opt/data/hadoop-3.2.2</value>
</property>
<!-- 设置HDFS web UI用户身份为 root,如果使用的是普通用户,配置成普通用户即可-->
<property><name>hadoop.http.staticuser.user</name><value>root</value>
</property><!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property><name>io.file.buffer.size</name><value>4096</value>
</property>配置HDFS路径(hdfs-site.xml)
vim hdfs-site.xml# 添加如下内容
<!-- 设置SNN进程运行时机器位置的信息-->
<!--2nn web端访问地址 -->
<property><name>dfs.namenode.secondary.http-address</name><value>kk02:9868</value>
</property><!-- nn web端访问地址-->
<!--hadoop3默认该端口为9870,不配也行-->
<property><name>dfs.namenode.http-address</name><value>kk01:9870</value>
</property>
配置YARN(yarn-site.xml)
vim yarn-site.xml# 添加如下内容<!-- 设置yarn集群主角色rm运行机器位置-->
<property><name>yarn.resourcemanager.hostname</name><value>kk01</value>
</property>
<!--nodemanager上运行的附属程序。需配置成mapreduce_shuffle,才可运行mr程序-->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 生产中可产生改配置-->
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制 生产中可产生改配置-->
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property><!--日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试-->
<!-- 开启日志聚集-->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置yarn历史服务器地址-->
<property><name>yarn.log.server.url</name><value>http://kk01:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天-->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
配置MapReduce(mapred-site.xml)
vim mapred-site.xml# 添加如下内容<!-- 设置MR程序默认运行方式:yarn集群模式 local本地模式--><property><name>mapreduce.framework.name</name><value>yarn</value></property><!--为了查看程序的历史运行情况,需要配置一下历史服务器--><!-- MR程序历史服务地址--><property><name>mapreduce.jobhistory.address</name><value>kk01:10020</value></property><!-- MR程序历史服务器web端地址--><property><name>mapreduce.jobhistory.webapp.address</name><value>kk01:19888</value></property><!-- mr app master环境变量--><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><!-- mr maptask环境变量--><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><!-- mr reducetask环境变量--><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>workers文件(该文件是为了群起集群)
vim /opt/software/hadoop-3.2.2/etc/hadoop/workers# 将文件内容替换为如下
kk01
kk02
kk03# 注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
修改hadoop-env环境变量
如果是使用root用户搭建Hadoop则需要配置,否则忽略
vim /opt/software/hadoop-3.2.2/etc/hadoop/hadoop-env.sh # 添加如下内容
export JAVA_HOME=/opt/software/jdk1.8.0_152
# 如果是root用户,需要指明,如下所示
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root配置环境变量
# 如果使用的是普通用户需要加sudo,root用户,则不需要,后续不再赘述
sudo vi /etc/profile# Hadoop environment variables
export HADOOP_HOME=/opt/software/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin# 重新加载配置文件
source /etc/profile
分发配置好的Hadoop安装包
(这里我们演示的是采用root用户搭建的集群,普通用户稍稍修改即可)
# 使用$PWD时,记得先切换进相应目录(/opt/software/)
scp -r /opt/software/hadoop-3.2.2 root@kk02:$PWD
scp -r /opt/software/hadoop-3.2.2 root@kk03:$PWD# 如果其他节点没有jdk记得也要分发
scp -r /opt/software/jdk1.8.0_152 root@kk02:$PWD
scp -r /opt/software/jdk1.8.0_152 root@kk03:$PWD#分发配置文件
scp /etc/profile root@kk02:/etc/profile
scp /etc/profile root@kk03:/etc/profile# 在被分发节点上执行
source /etc/profile
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
基本语法
rsyns -av 待拷贝文件路径/名称 目的主机用户@主机名:目的地路径/名称# 参数说明
# -a 归档拷贝
# -v 显示拷贝过程
下面演示使用普通用户分到普通用户
rsync -av /opt/software/hadoop-3.2.2 nhk@kk02:/opt/software/
rsync -av /opt/software/hadoop-3.2.2 nhk@kk03:/opt/software/rsync -av /opt/software/jdk1.8.0_152 nhk@kk02:/opt/software/
rsync -av /opt/software/jdk1.8.0_152 nhk@kk03:/opt/software/# 为了方便分发,我们可以编写脚本 (可选)
vim xsync
#!/bin/bash#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi
#2. 遍历集群所有机器
for host in kk01 kk02 kk03
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done# 让脚本具有可执行权限
chmod +x xsync
# 将脚本复制到/bin,以便全局调用
sudo cp xsync /bin/ # 普通用户需sudo
# 同步环境变量
[nhk@kk01 ~]$ sudo ./bin/xsync # 普通用户情况下 # 注意:如果用了sudo,那么xsync一定要给它的路径补全。# 让环境变量生效
source /etc/profile# 使用自定义脚本分发
xsync /opt/software/hadoop-3.2.2/
HDFS格式化
首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。
cd /opt/software/hadoop-3.1.4
bin/hdfs namenode -format # 因为我们配置了环境变量,其实格式化操作也可以简化为如下操作:
hdfs namenode -format# 若出现 successfully formatted 字样则说明格式化成功
集群启动
# HDFS集群启动
start-dfs.sh# YARN集群启动
start-yarn.sh
web端查看HDFS的NameNode
http://kk01:9870
Web端查看YARN的ResourceManager
http://kk01:8088
编写hadoop集群常用脚本
Hadoop集群启停脚本
vim hdp.sh#!/bin/bashif [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
ficase $1 in
"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh kk01 "/opt/software/hadoop-3.2.2/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh kk01 "/opt/software/hadoop-3.2.2/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh kk01 "/opt/software/hadoop-3.2.2/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh kk01 "/opt/software/hadoop-3.2.2/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh kk01 "/opt/software/hadoop-3.2.2/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh kk01 "/opt/software/hadoop-3.2.2/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac# 赋予脚本执行权限
chmod +x hdp.sh
查看三台服务器Java进程脚本:jpsall
vim jpsall#!/bin/bash
for host in kk01 kk02 kk03
doecho "=========$host========="ssh $host "source /etc/profile; jps"
done# 赋予脚本执行权限
chmod +x jpsall分发自定义脚本,让三台服务器都能正常使用脚本
xsync 脚本放置的目录
搭建集群注意事项常见问题
如果使用root用户操作的话,需要在hadoop-env.sh文件下加入以下配置
在hadoop-env.sh文件下添加一下信息
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
使用root操作,需要再core-site.xml文件,修改以下配置
<!-- Web UI访问HDFS的用户名-->
<!-- 配置HDFS登录使用的静态用户为root -->
<property><name>hadoop.http.staticuser.user</name><value>root</value>
</property>
防火墙未关闭、或者没有启动YARN
INFO client.RMProxy:Connecting to ResourceManager at kk01/192.168.188.128:8032
解决:
在/etc/hosts文件中添加192.168.188.128 kk01
主机名称配置错误
解决:
更改主机名,主机名称不要起hadoop hadoop000等特殊名称
不识别主机名称
java.net.UnknownHostException: kk01: kk01at java.net.InetAddress.getLocalHost(InetAddress.java:1475)at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146)at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)
解决:
在/etc/hosts文件中添加192.168.188.128 kk01
主机名称不要起hadoop hadoop000等特殊名称
DataNode和NameNode进程同时只能工作一个
解决:
在格式化之前,先删除DataNode里面的信息(默认在/tmp目录,如果配置了该目录,那就去配置的目录下删除数据)
jps发现进程已经没有,但是重新启动集群,提示进程已经开启
解决:
原因是在Linux的根目录下/tmp目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。
jps不生效
解决:
原因:全局变量hadoop java没有生效。解决办法:需要source /etc/profile文件。
8088端口连接不上
解决:
cat /etc/hosts
# 注释掉如下信息
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 kk01Hadoop集群总结
-
format操作只在hadoop集群初次启动时执行一次
-
format多次会造成我们数据的丢失,还可能会造成Hadoop集群主从角色之间相互不识别(解决方法:将所以节点的hadoop.tmp.dir目录删除,删除所有机器的data和logs目录删除,后重新格式化)
Hadoop集群启动关闭
每台机器手动逐个开启/关闭进程
优点:利于精准的控制每一个进程的开启和关闭
HDFS集群
hdfs --daemon start namenode|datanode|secondarynamenodehdfs --daemon stop namenode|datanode|secondarynamenode
YARN集群
yarn --daemon start resourcemanager|nodemanageryarn --daemon stop resourcemanager|nodemanager
shell脚本一键启停
使用Hadoop自带的shell脚本一键启动
前提:配置好机器之间的ssh免密登录和workers文件
HDFS集群
start-dfs.sh
stop-dfs.sh
YARN集群
start-yarn.sh
stop-yarn.sh
Hadoop集群
start-all.sh
stop-all.sh
Hadoop集群启动日志
启动完成后,可以使用jps命令查看进程是否启动
若发现某些进程无法正常启动或者是启动后又闪退,可以查看logs目录下的日志文件(.log)查看
hadoop启动日志:日志路径:在Hadoop安装目录下的logs目录下
HDFS基准测试
实际生产环境当中,hadoop的环境搭建完成之后,第一件事情就是进行压力测试,测试Hadoop集群的读取和写入速度,测试网络带宽是否足够等一些基准测试。
测试写入速度
向HDFS文件系统中写入数据,10个文件,每个文件10MB,文件存放到/benchmarks/TestDFSIO中
# 启动Hadoop集群
start-all.sh# 在确保HDFS集群和YARN集群成功启动情况下,执行下面命令
hadoop jar /opt/software/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.2.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB# 说明:向HDFS文件系统中写入数据,10个文件,每个文件10MB,文件存放到/benchmarks/TestDFSIO中Throughput:吞吐量、Average IO rate:平均IO率、IO rate std deviation:IO率标准偏差2023-04-01 11:12:56,880 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
2023-04-01 11:12:56,880 INFO fs.TestDFSIO: Date & time: Sat Apr 01 11:12:56 EDT 2023
2023-04-01 11:12:56,880 INFO fs.TestDFSIO: Number of files: 10
2023-04-01 11:12:56,880 INFO fs.TestDFSIO: Total MBytes processed: 100
2023-04-01 11:12:56,880 INFO fs.TestDFSIO: Throughput mb/sec: 4.81
2023-04-01 11:12:56,880 INFO fs.TestDFSIO: Average IO rate mb/sec: 7.58
2023-04-01 11:12:56,880 INFO fs.TestDFSIO: IO rate std deviation: 7.26
2023-04-01 11:12:56,880 INFO fs.TestDFSIO: Test exec time sec: 34.81
2023-04-01 11:12:56,880 INFO fs.TestDFSIO: 我们看到目前在虚拟机上的IO吞吐量约为:4.81MB/s
测试读取速度
测试hdfs的读取文件性能,在HDFS文件系统中读入10个文件,每个文件10M
hadoop jar /opt/software/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.2.2-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB# 说明:在HDFS文件系统中读入10个文件,每个文件10MThroughput:吞吐量、Average IO rate:平均IO率、IO rate std deviation:IO率标准偏差2023-04-01 11:16:44,479 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2023-04-01 11:16:44,479 INFO fs.TestDFSIO: Date & time: Sat Apr 01 11:16:44 EDT 2023
2023-04-01 11:16:44,479 INFO fs.TestDFSIO: Number of files: 10
2023-04-01 11:16:44,479 INFO fs.TestDFSIO: Total MBytes processed: 100
2023-04-01 11:16:44,479 INFO fs.TestDFSIO: Throughput mb/sec: 33.8
2023-04-01 11:16:44,479 INFO fs.TestDFSIO: Average IO rate mb/sec: 93.92
2023-04-01 11:16:44,479 INFO fs.TestDFSIO: IO rate std deviation: 115.03
2023-04-01 11:16:44,479 INFO fs.TestDFSIO: Test exec time sec: 25.72
2023-04-01 11:16:44,479 INFO fs.TestDFSIO: 可以看到读取的吞吐量为:33.8Mb/s
清除测试数据
测试期间,会在HDFS集群上创建 /benchmarks目录,测试完毕后,我们可以清理该目录。
# 查看hdfs dfs -ls -R /benchmarks# 执行清理
hadoop jar /opt/software/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.2.2-tests.jar TestDFSIO -clean# 说明 删除命令会将 /benchmarks目录中内容删除相关文章:
)
06-hadoop集群搭建(root用户)
搭建Hadoop集群流程 环境准备 1、基础环境的搭建(内网封火墙关闭、主机名、规划好静态ip、hosts映射、时间同步ntp、jdk、ssh免密等) 2、Hadoop源码编译(为了适应不同操作系统间适配本地库、本地环境等) 3、Hadoop配置文件的修…...

MySQL 窗口函数是什么,有这么好用
先看这段像天书一样的 SQL ,看着就头疼。 SELECTs1.name,s1.subject,s1.score,sub.avg_score AS average_score_per_subject,(SELECT COUNT(DISTINCT s2.score) 1 FROM scores s2 WHERE s2.score > s1.score) AS score_rank FROM scores s1 JOIN (SELECT subject, AVG(sco…...
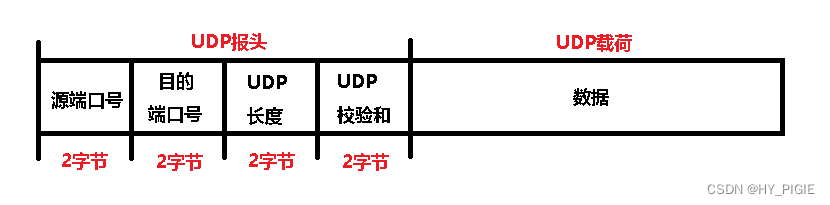
用户数据报协议UDP
UDP的格式 载荷存放的是:应用层完整的UDP数据报 报头结构: 源端口号:发出的信息的来源端口目的端口号:信息要到达的目的端口UDP长度:2个字节(16位),即UDP总长度为:2^16bit 2^10bit * 2^6bit 1KB * 64 64KB.所以一个UDP的最大长度为64KBUDP校验和:网络的传输并非稳定传输,…...

STM32F429IGT6使用CubeMX配置外部中断按键
1、硬件电路 2、设置RCC,选择高速外部时钟HSE,时钟设置为180MHz 3、配置GPIO引脚 4、NVIC配置 PC13相同 5、生成工程配置 6、部分代码 中断回调函数 /* USER CODE BEGIN 0 */void HAL_GPIO_EXTI_Callback(uint16_t GPIO_Pin) {if(GPIO_Pin GPIO_PIN_0){HAL_GPIO…...
时序预测 | Python实现LSTM长短期记忆网络时间序列预测(电力负荷预测)
时序预测 | Python实现LSTM长短期记忆网络时间序列预测(电力负荷预测) 目录 时序预测 | Python实现LSTM长短期记忆网络时间序列预测(电力负荷预测)效果一览基本描述模型结构程序设计参考资料效果一览...

[开发|前端] 路由守卫笔记
描述 vue-router提供的导航跳转或取消的api。 router.beforeEach 切换路由前调用 router.beforeResolve 组件内路由守卫解析之后调用,和beforeEach用法类似 router.afterEach 切换后调用 全局路由守卫有上面3个,调用时机不同 路由守卫都有3个参数 …...

网络基础——网络的由来与发展史
作者:Insist-- 个人主页:insist--个人主页 作者会持续更新网络知识和python基础知识,期待你的关注 目录 一、网络的由来 二、计算机网络的发展史 1、第一阶段 2、第二阶段 3、第三阶段 前言 每天都是使用网络,那么你知道网络…...
)
八数码(bfs)
思路: (1)用string来存储状态,用d<string,int>来记录状态变换次数; (2)在bfs过程中,先初始化(q,d);每次拿出队头状态,得到x的相对位置&am…...

CCLINK IE FIELD BASIC转MODBUS-TCP网关cclink与以太网的区别
协议的不同,数据读取困难,这是很多生产管理系统的难题。但是现在,捷米JM-CCLKIE-TCP通讯网关,让这个问题变得非常简单。这款通讯网关可以将各种MODBUS-TCP设备接入到CCLINK IE FIELD BASIC网络中,连接到MODBUS-TCP总线…...
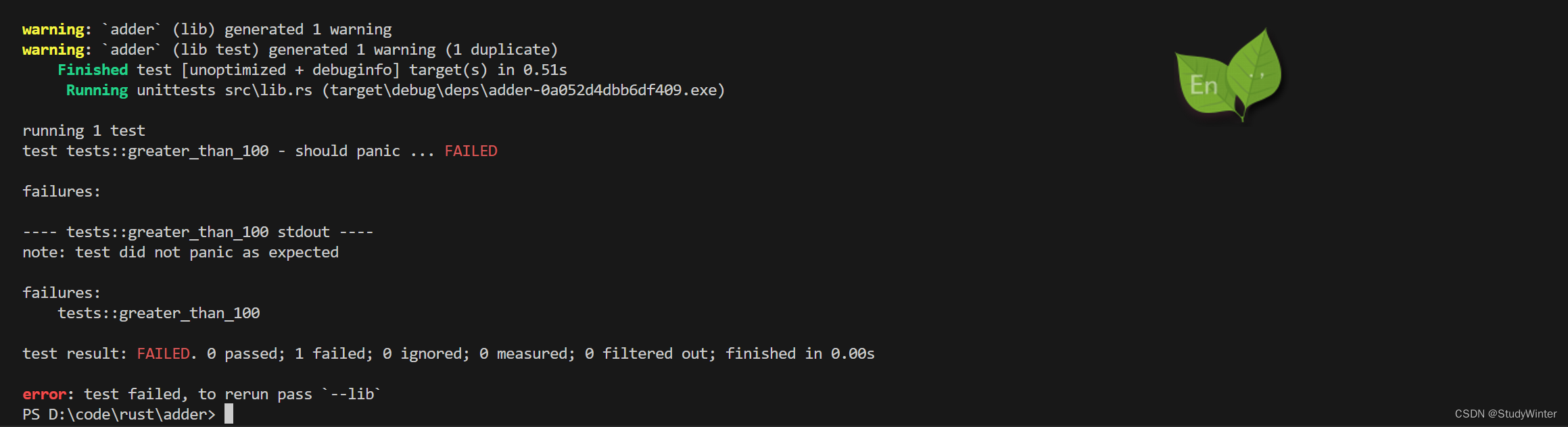
【Rust】Rust学习 第十一章编写自动化测试
Rust 是一个相当注重正确性的编程语言,不过正确性是一个难以证明的复杂主题。Rust 的类型系统在此问题上下了很大的功夫,不过它不可能捕获所有种类的错误。为此,Rust 也在语言本身包含了编写软件测试的支持。 编写一个叫做 add_two 的将传递…...

关于使用pycharm遇到只能使用unittest方式运行,无法直接选择Run
相信大家可能都遇到过这个问题,使用pycharm直接运行脚本的时候,只能选择unittest的方式,能愁死个人 经过几次各种尝试无果之后,博主就放弃死磕了,原谅博主是个菜鸟 后来遇到这样的问题,往往也就直接使用cm…...
Docker+rancher部署SkyWalking8.5并应用在springboot服务中
1.Skywalking介绍 Skywalking是一个国产的开源框架,2015年有吴晟个人开源,2017年加入Apache孵化器,国人开源的产品,主要开发人员来自于华为,2019年4月17日Apache董事会批准SkyWalking成为顶级项目,支持Jav…...

代码随想录第45天 | 322. 零钱兑换、279. 完全平方数
322. 零钱兑换 动规五部曲分析如下: 确定dp数组以及下标的含义 dp[j]:凑足总额为j所需钱币的最少个数为dp[j] 确定递推公式 凑足总额为j - coins[i]的最少个数为dp[j - coins[i]],那么只需要加上一个钱币coins[i]即dp[j - coins[i]] 1就是…...

怎么加入Microsoft Cloud Partner Program?
目录 前言 加入Microsoft Cloud Partner Program 1、注册成为微软合作伙伴 2、完成合作伙伴资格要求...
LNMP简易搭建
目录 前言 一、拓扑图 二、NGINX配置 三、配置MySQL 四、配置php环境 五、部署应用 总结 前言 LNMP平台指的是将Linux、Nginx、MySQL和PHP(或者其他的编程语言,如Python、Perl等)集成在一起的一种Web服务器环境。它是一种常用的开发和部署网…...
CClink IE转Modbus TCP网关连接三菱FX5U PLC
捷米JM-CCLKIE-TCP 是自主研发的一款 CCLINK IE FIELD BASIC 从站功能的通讯网关。该产品主要功能是将各种 MODBUS-TCP 设备接入到 CCLINK IE FIELD BASIC 网络中。 捷米JM-CCLKIE-TCP网关连接到 CCLINK IE FIELD BASIC 总线中做为从站使用,连接到 MODBUS-TCP 总线…...

PyTorch 微调终极指南:第 1 部分 — 预训练模型及其配置
一、说明 如今,在训练深度学习模型时,通过在自己的数据上微调预训练模型来迁移学习已成为首选方法。通过微调这些模型,我们可以利用他们的专业知识并使其适应我们的特定任务,从而节省宝贵的时间和计算资源。本文分为四个部分&…...
GO学习之 微框架(Gin)
GO系列 1、GO学习之Hello World 2、GO学习之入门语法 3、GO学习之切片操作 4、GO学习之 Map 操作 5、GO学习之 结构体 操作 6、GO学习之 通道(Channel) 7、GO学习之 多线程(goroutine) 8、GO学习之 函数(Function) 9、GO学习之 接口(Interface) 10、GO学习之 网络通信(Net/Htt…...
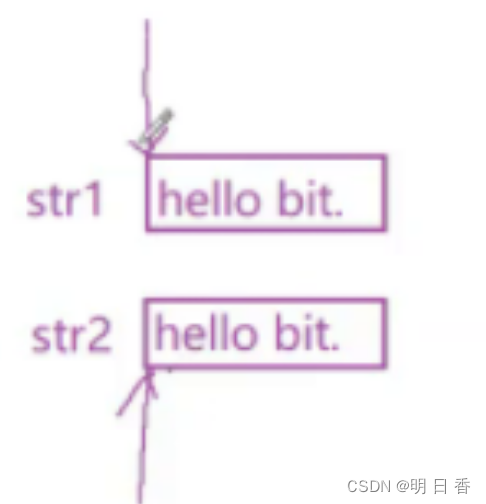
C语言 字符指针
1、介绍 概念: 字符指针,就是字符类型的指针,同整型指针,指针指向的元素表示整型一样,字符指针指向的元素表示的是字符。 假设: char ch a;char * pc &ch; pc 就是字符指针变量,字符指…...

Springboot所有的依赖
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!-- 声明springboot的版本号 -->…...
)
从零到一:手把手教你用OpenVINS跑通INDEMIND双目VIO(附避坑指南)
从零到一:手把手教你用OpenVINS跑通INDEMIND双目VIO(附避坑指南) 最近在机器人定位领域,基于视觉惯性里程计(VIO)的方案越来越受到关注。作为一个在多个实际项目中部署过VIO系统的开发者,我发现…...

C++ string操作指南:从入门到精通
一、为什么要用 string?之前学的 char[] 缺点:必须手动处理 \0,容易乱码不能直接用 赋值、 拼接长度受限,容易越界函数少,操作麻烦string 优点:是 C 标准类,安全方便可以直接 、、 比较自动管理…...

免费音频编辑神器Audacity:从零基础到专业级的完整指南
免费音频编辑神器Audacity:从零基础到专业级的完整指南 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 在数字内容创作成为主流的今天,音频质量直接影响着作品的专业度和传播效果。然而&am…...

从词向量到大模型:NLP 技术是怎么一步步变强的
自然语言处理(Natural Language Processing,简称 NLP)是人工智能里一个特别重要的方向,它的发展过程其实就是人们想办法让机器从只会按规则做事,慢慢变成能真正理解人类说话意思的过程。这篇文章会带你简单看看&#x…...

12N65-ASEMI解锁功率电子新边界12N65
编辑:LL12N65-ASEMI解锁功率电子新边界12N65型号:12N65品牌:ASEMI沟道:NPN封装:TO-220F漏源电流:12A漏源电压:650VRDS(on):0.8Ω批号:最新引脚数量:3封装尺寸:…...

“一句话就能毁掉一个人?”AI 正在接管网络暴力识别,但真相更复杂
友友们好! 我是Echo_Wish,我的的新专栏《Python进阶》以及《Python!实战!》正式启动啦!这是专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会…...

SOCD Cleaner技术深度解析:内核级输入仲裁的架构设计与性能优化
SOCD Cleaner技术深度解析:内核级输入仲裁的架构设计与性能优化 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在竞技游戏和实时交互应用中,输入延迟和精度往往成为影响用户体验的关键因…...

虚拟机基础:JVM、V8 运行机制极简科普
文章目录 前言一、先搞懂:到底什么是“虚拟机”?二、JVM:Java世界的“铁饭碗管家”2.1 JVM的整体工作流程2.2 JVM的核心结构:五大区域三大子系统2.2.1 运行时数据区(JVM的“房间布局”)2.2.2 三大核心子系统…...

Stable Diffusion 3.5 FP8镜像实测:低显存也能流畅运行
Stable Diffusion 3.5 FP8镜像实测:低显存也能流畅运行 1. 引言:FP8量化的突破性价值 Stable Diffusion 3.5作为Stability AI最新发布的文本到图像生成模型,在图像质量、语义理解和文字渲染方面都有显著提升。然而,传统部署方式…...

A股量化交易系统的工程化实践:从策略建模到AI风控的选型思考
在 2026 年的市场环境下,个人交易者面临的竞争已从信息不对称转向了“决策一致性”与“执行响应比”的博弈。对于技术从业者而言,编写一套属于自己的交易脚本并非难事,但如何将零散的逻辑整合为一套具备防御性的投资系统,才是跨越…...