Spring Data JPA 详解
目录
- 一、概述
- 1.1 JPA简介
- 1.2 Spring Data JPA简介
- 二、配置及应用
- 2.1 环境配置
- 2.2 依赖添加
- 2.3 实体类创建
- 2.4 Repository接口创建
- 2.5 示例程序运行
- 三、实体映射
- 3.1 注解
- 3.2 关系映射
- 四、Repository接口
- 4.1 基本增删改查
- 4.2 自定义查询方法
- 4.3 使用 Sort 和 Pageable 进行排序和分页
- 4.4 使用 @Modifying 注解进行修改
- 4.5 使用 Native SQL 查询
- 五、数据库操作
- 5.1 数据库初始化和升级
- 5.2 多数据源配置
- 5.3 审计日志和版本控制
- 六、总结
- 6.1 Spring Data JPA的优点和缺点
- 6.2 与其他 ORM 框架的比较
- 6.3 适合使用 Spring Data JPA 的项目类型
一、概述
Java持久化技术是Java开发中的重要组成部分,它主要用于将对象数据持久化到数据库中,以及从数据库中查询和恢复对象数据。在Java持久化技术领域,Java Persistence API (JPA) 和 Spring Data JPA 是两个非常流行的框架。

1.1 JPA简介
Java Persistence API (JPA) 是一种基于 ORM (Object-Relational Mapping) 技术的 Java EE 规范。它主要用于将 Java 对象映射到关系型数据库中,以便于对数据进行持久化操作。
JPA 主要由三个部分组成,分别是 Entity、EntityManager 和 Query。其中 Entity 用于描述 Java 对象和数据库表之间的映射关系;EntityManager 用于管理实体对象的生命周期和完成实体对象与数据库之间的操作;Query 用于查询数据。
JPA 支持多种底层实现,如 Hibernate、EclipseLink 等。在使用时,只需要引入相应的实现框架即可。 总结如下:
- JPA(Java Persistence API)是为Java EE平台设计的一种ORM解决方案。
- JPA提供了一些标准的API以及关系映射的元数据,使得Java开发人员可以在没有具体SQL编程经验的情况下,通过简单的注解配置实现对数据的访问和操作。
- JPA提供了对事务的支持,允许Java开发人员进行基于POJO的开发,在运行时将这些POJO映射成关系数据库表和列,最大限度地减少了Java开发者与数据库的交互。
1.2 Spring Data JPA简介
Spring Data JPA 是 Spring 框架下的一个模块,是基于 JPA 规范的上层封装,旨在简化 JPA 的使用。
Spring Data JPA 提供了一些常用的接口,如 JpaRepository、JpaSpecificationExecutor 等,这些接口包含了很多常用的 CRUD 操作方法,可直接继承使用。同时,Spring Data JPA 还提供了基于方法命名规范的查询方式,可以根据方法名自动生成相应的 SQL 语句,并执行查询操作。这种方式可以大大减少编写 SQL 语句的工作量。
除了基础的 CRUD 操作外,Spring Data JPA 还提供了一些高级功能,如分页、排序、动态查询等。同时,它也支持多种数据库,如 MySQL、PostgreSQL、Oracle 等。 总结如下:
- Spring Data JPA 是 Spring Data 项目家族中的一员,它为基于Spring框架应用程序提供了更加便捷和强大的数据操作方式。
- Spring Data JPA 支持多种数据存储技术,包括关系型数据库和非关系型数据库。
- Spring Data JPA 提供了简单、一致且易于使用的API来访问和操作数据存储,其中包括基本的CRUD操作、自定义查询方法、动态查询等功能。
- Spring Data JPA 也支持QueryDSL、Jinq、Kotlin Query等其他查询框架。
二、配置及应用
2.1 环境配置
- 使用 Spring Data JPA 需要在项目中配置相关依赖项和数据源。
- Spring Data JPA 支持的数据库类型包括 MySQL、PostgreSQL、Oracle、MongoDB 等。
2.2 依赖添加
- 在项目的 pom.xml 文件中添加如下 Spring Data JPA 相关依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId> </dependency> - 如果使用其他数据库类型,可以替换 mysql-connector-java 依赖,并相应地调整数据源配置。
2.3 实体类创建
在项目中创建实体类,用于映射数据库表和列。实体类需要使用@Entity注解进行标记,并且需要指定主键和自动生成策略,例如:
@Entity
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;// ...// 省略 getter 和 setter 方法
}
2.4 Repository接口创建
在项目中创建 Repository 接口,用于定义数据访问方法。Repository 接口需要继承自java JpaRepository接口,并且需要使用java @Repository注解进行标记,例如:
@Repository
public interface UserRepository extends JpaRepository<User, Long> {User findByName(String name);
}
在示例中,我们定义了一个名为 UserRepository 的接口,它继承自 JpaRepository 接口,泛型参数分别为实体类型和主键类型,并且新增了一个自定义查询方法 findByName。
2.5 示例程序运行
编写示例代码并运行应用程序,以验证 Spring Data JPA 的功能和使用方法。示例代码可以是简单的控制台程序,也可以是 Web 应用程序。下面是一个基于 Spring Boot 的 Web 应用程序的示例代码:
@SpringBootApplication
public class Application implements CommandLineRunner {@Autowiredprivate UserRepository userRepository;public static void main(String[] args) {SpringApplication.run(Application.class, args);}@Overridepublic void run(String... args) throws Exception {User user = new User();user.setName("Alice");user.setEmail("alice@example.com");userRepository.save(user);User savedUser = userRepository.findByName("Alice");System.out.println(savedUser);}
}
在示例代码中,我们使用 @SpringBootApplication 注解标记了应用程序入口类,并且在 main 方法中启动了应用程序。CommandLineRunner 接口的 run 方法用于定义初始化逻辑,在示例中我们创建了一个名为 Alice 的用户,并将其保存到数据库中,随后使用 findByName 方法查询并输出该用户信息。
三、实体映射
3.1 注解
-
Entity 注解
@Entity 注解用于标记实体类,表示该类会被映射到数据库中的一个表。示例代码:@Entity public class User {// 省略属性和方法 } -
Table 注解
@Table 注解用于标注实体类与数据库表之间的映射关系,并可以指定表的名称、唯一约束等信息。示例代码:@Entity @Table(name = "user") public class User {// 省略属性和方法 } -
Column 注解
@Column 注解用于标注实体类属性与数据表字段之间的映射关系,并可以指定字段名称、长度、精度等信息。示例代码:@Entity @Table(name = "user") public class User {@Idprivate Long id;@Column(name = "user_name", length = 20, nullable = false)private String userName;// 省略其他属性和方法 } -
Id 注解
@Id 注解用于标注实体类属性作为主键,通常与 @GeneratedValue 注解一起使用指定主键生成策略。示例代码:@Entity @Table(name = "user") public class User {@Id@GeneratedValue(strategy = GenerationType.AUTO)private Long id;// 省略其他属性和方法 } -
GeneratedValue注解
@GeneratedValue 注解用于指定主键生成策略,通常与 @Id 注解一起使用。示例代码:@Entity @Table(name = "user") public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;// 省略其他属性和方法 }
3.2 关系映射
关系映射通常包括一对一、一对多和多对多等关系。在 Spring Data JPA 中,可以使用 @OneToOne、@OneToMany 和 @ManyToMany 注解来标注关系映射。这些注解通常与 @JoinColumn 注解一起使用,用于指定关联的外键列。
示例代码:
@Entity
@Table(name = "user")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;@OneToMany(mappedBy = "user", cascade = CascadeType.ALL)private List<Address> addresses;// 省略其他属性和方法
}@Entity
@Table(name = "address")
public class Address {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;@ManyToOne@JoinColumn(name = "user_id")private User user;// 省略其他属性和方法
}
在上例中,User 和 Address 之间是一对多的关系,所以在 User 实体类中使用了 @OneToMany 注解,在 Address 实体类中使用了 @ManyToOne 注解。mappedBy 属性用于指定关联的属性名称,这里是 user,表示 Address 实体类中的 user 属性与 User 实体类中的 addresses 属性相对应。cascade 属性表示级联操作,这里使用 CascadeType.ALL 表示在删除 User 实体时同时删除其关联的所有 Address 实体。@JoinColumn 注解用于指定外键名称,这里是 user_id,表示 Address 表中的 user_id 列与 User 表中的主键相对应。
四、Repository接口
Repository 接口是 Spring Data JPA 的核心接口之一,它提供了基本的增删改查方法和自定义查询方法,以及分页和排序等功能。在使用时需要继承 Repository 接口并指定对应的实体类和主键类型。示例代码:
public interface UserRepository extends Repository<User, Long> {// 省略基本增删改查方法和自定义查询方法
}
4.1 基本增删改查
在继承 Repository 接口后,会默认提供基本的增删改查方法,无需额外的代码实现即可使用。常用的方法如下:
| 方法名 | 描述 |
|---|---|
| T save(T entity) | 保存实体对象 |
| Iterable saveAll(Iterable entities) | 批量保存实体对象 |
| Optional findById(ID id) | 根据主键获取实体对象 |
| boolean existsById(ID id) | 判断是否存在特定主键的实体对象 |
| Iterable findAll() | 获取所有实体对象 |
| Iterable findAllById(Iterable ids) | 根据主键批量获取实体对象 |
| long count() | 获取实体对象的数量 |
| void deleteById(ID id) | 根据主键删除实体对象 |
| void delete(T entity) | 删除实体对象 |
| void deleteAll(Iterable<? extends T> entities) | 批量删除实体对象 |
示例代码:
public interface UserRepository extends Repository<User, Long> {// 保存用户User save(User user);// 根据主键获取用户Optional<User> findById(Long id);// 获取所有用户Iterable<User> findAll();// 根据主键删除用户void deleteById(Long id);
}
4.2 自定义查询方法
在 Repository 接口中可以定义自定义查询方法,实现按照指定规则查询数据。Spring Data JPA 支持三种方式定义自定义查询方法:方法名称查询、参数设置查询、使用 @Query 注解查询。
-
方法名称查询
方法名称查询是 Spring Data JPA 中最简单的一种自定义查询方法,并且不需要额外的注解或 XML 配置。它通过方法名来推断出查询的条件,例如以 findBy 开头的方法表示按照某些条件查询,以 deleteBy 开头的方法表示按照某些条件删除数据。示例代码:public interface UserRepository extends Repository<User, Long> {// 根据用户名查询用户User findByUserName(String userName);// 根据年龄查询用户列表List<User> findByAge(Integer age);// 根据用户名和密码查询用户User findByUserNameAndPassword(String userName, String password);// 根据主键和用户名删除用户void deleteByIdAndUserName(Long id, String userName); } -
查询参数设置
除了方法名称查询外,还可以使用参数设置方式进行自定义查询。它通过在方法上使用 @Query 注解来指定查询语句,然后使用 @Param 注解来指定方法参数与查询语句中的参数对应关系。示例代码:public interface UserRepository extends Repository<User, Long> {// 根据用户名查询用户@Query("SELECT u FROM User u WHERE u.userName = :userName")User findByUserName(@Param("userName") String userName);// 根据用户名和密码查询用户@Query("SELECT u FROM User u WHERE u.userName = :userName AND u.password = :password")User findByUserNameAndPassword(@Param("userName") String userName, @Param("password") String password); } -
使用@Query注解
在自定义查询方法时,还可以使用 @Query 注解直接指定查询语句。@Query 注解的 value 属性表示查询语句,可以使用占位符 ?1、?2 等表示方法参数。示例代码:public interface UserRepository extends Repository<User, Long> {// 根据用户名查询用户@Query(value = "SELECT * FROM user WHERE user_name = ?1", nativeQuery = true)User findByUserName(String userName);// 根据用户名和密码查询用户@Query(value = "SELECT * FROM user WHERE user_name = ?1 AND password = ?2", nativeQuery = true)User findByUserNameAndPassword(String userName, String password); }
4.3 使用 Sort 和 Pageable 进行排序和分页
在查询数据时,经常需要对结果进行排序和分页操作。Spring Data JPA 提供了 Sort 和 Pageable 两个类来实现排序和分页功能。
-
Sort 类表示排序规则,可以使用 Sort.by() 静态方法创建实例,并指定排序属性和排序方向。常用方法如下:
方法名 描述 static Sort by(Sort.Order… orders) 根据排序规则创建 Sort 实例 static Sort.Order by(String property) 根据属性升序排序 static Sort.Order by(String property, Sort.Direction direction) 根据属性排序 示例代码:
public interface UserRepository extends Repository<User, Long> {// 根据年龄升序查询用户列表List<User> findByOrderByAgeAsc();// 根据年龄降序分页查询用户列表Page<User> findBy(Pageable pageable); } -
Pageable 类表示分页信息,可以使用 PageRequest.of() 静态方法创建实例,并指定页码、每页数据量和排序规则。常用方法如下:
方法名 描述 static PageRequest of(int page, int size, Sort sort) 创建分页信息实例 static PageRequest of(int page, int size, Sort.Direction direction, String… properties) 创建分页信息实例 示例代码:
public interface UserRepository extends Repository<User, Long> {// 根据年龄降序分页查询用户列表Page<User> findBy(Pageable pageable); }// 使用 Pageable pageable = PageRequest.of(0, 10, Sort.by("age").descending()); Page<User> page = userRepository.findBy(pageable); List<User> userList = page.getContent();
4.4 使用 @Modifying 注解进行修改
在 Spring Data JPA 中,使用 update 和 delete 语句需要使用 @Modifying 注解标注,并且需要添加 @Transactional 注解开启事务。需要注意的是,@Modifying 注解只支持 DML 语句。
示例代码:
public interface UserRepository extends Repository<User, Long> {// 更新用户密码@Modifying@Transactional@Query("UPDATE User u SET u.password = :password WHERE u.id = :id")void updatePasswordById(@Param("id") Long id, @Param("password") String password);// 删除年龄大于等于 age 的用户@Modifying@Transactional@Query("DELETE FROM User u WHERE u.age >= :age")void deleteByAgeGreaterThanEqual(@Param("age") Integer age);
}
4.5 使用 Native SQL 查询
在某些情况下,需要执行原生的 SQL 查询语句。Spring Data JPA 提供了 @Query 注解来支持使用原生 SQL 查询数据。在 @Query 注解中设置 nativeQuery=true 即可执行原生 SQL 语句。
以下示例代码演示了如何使用原生 SQL 查询 age 大于等于 18 的用户。
public interface UserRepository extends JpaRepository<User, Long> {@Query(value = "SELECT * FROM user WHERE age >= ?1", nativeQuery = true)List<User> findByAgeGreaterThanEqual(Integer age);
}// 使用
userRepository.findByAgeGreaterThanEqual(18);
五、数据库操作
5.1 数据库初始化和升级
-
数据库初始化
在使用 Spring Data JPA 进行开发时,使用 @Entity 标注实体类,当应用程序启动时,JPA 会自动检测实体类上的注解,并在数据库中创建对应的表。以下示例代码演示了如何在 Spring Boot 应用程序中使用 JPA 创建表。
@Entity @Table(name = "user") public class User {@Id@GeneratedValue(strategy = GenerationType.AUTO)private Long id;@Columnprivate String name;@Columnprivate Integer age;// 省略 getter 和 setter 方法 }@Repository public interface UserRepository extends JpaRepository<User, Long> { }@Service public class UserService {@Autowiredprivate UserRepository userRepository;// 添加用户public User addUser(User user) {return userRepository.save(user);} }在上述示例代码中,使用 @Entity 标注实体类,并在 @Table 注解中指定表名。当应用程序启动时,JPA 会自动创建名为 user 的表。使用 JpaRepository 提供的方法进行增删改查等操作。
-
数据库升级
当数据库表结构需要修改时,可以使用 Flyway、Liquibase 等工具进行数据库升级。其中,Flyway 是一款轻量级的数据库迁移工具,它可以很好地与 Spring Boot 集成。以下示例代码演示了如何在 Spring Boot 应用程序中使用 Flyway 进行数据库升级:
- 在 pom.xml 文件中添加依赖
<dependency><groupId>org.flywaydb</groupId><artifactId>flyway-core</artifactId><version>7.6.3</version> </dependency> - 在 application.properties 文件中配置 Flyway 数据库连接信息
spring.datasource.url=jdbc:mysql://localhost:3306/test spring.datasource.username=root spring.datasource.password=123456 # Flyway 数据库升级相关配置 spring.flyway.locations=classpath:/db/migration spring.flyway.baselineOnMigrate=true - 在 src/main/resources/db/migration 目录下创建 SQL 升级脚本,如 V1__create_user_table.sql 和 V2__add_address_column_to_user_table.sql
-- V1__create_user_table.sql CREATE TABLE `user` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,`age` int(11) DEFAULT NULL,PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;-- V2__add_address_column_to_user_table.sql ALTER TABLE `user` ADD `address` VARCHAR(255) NULL AFTER `age`; - 在 Spring Boot 应用程序启动时,Flyway 会自动执行 SQL 升级脚本,更新数据库表结构
@SpringBootTest class ApplicationTests {@Testvoid contextLoads() {} }
- 在 pom.xml 文件中添加依赖
5.2 多数据源配置
在实际应用中,有时需要使用多个数据源。Spring Boot 提供了 @ConfigurationProperties、@Primary、@Qualifier 等注解来支持多数据源配置。以下示例代码演示了如何在 Spring Boot 应用程序中配置多数据源。
-
在 application.properties 文件中配置两个数据源的连接信息
# 数据源一 spring.datasource.one.url=jdbc:mysql://localhost:3306/test1 spring.datasource.one.username=root spring.datasource.one.password=123456 # 数据源二 spring.datasource.two.url=jdbc:mysql://localhost:3306/test2 spring.datasource.two.username=root spring.datasource.two.password=123456 -
创建两个数据源的配置类
@Configuration @ConfigurationProperties(prefix = "spring.datasource.one") public class DataSourceOneConfig {private String url;private String username;private String password;// 省略 getter 和 setter 方法@Beanpublic DataSource dataSourceOne() {return DataSourceBuilder.create().url(url).username(username).password(password).build();} }@Configuration @ConfigurationProperties(prefix = "spring.datasource.two") public class DataSourceTwoConfig {private String url;private String username;private String password;// 省略 getter 和 setter 方法@Beanpublic DataSource dataSourceTwo() {return DataSourceBuilder.create().url(url).username(username).password(password).build();} } -
在 Service 或 Repository 中指定要使用的数据源
@Service public class UserService {@Autowired@Qualifier("dataSourceOne")private DataSource dataSourceOne;@Autowired@Qualifier("dataSourceTwo")private DataSource dataSourceTwo;public void addUser(User user) {try (Connection connection = dataSourceOne.getConnection();PreparedStatement statement = connection.prepareStatement("INSERT INTO user (name, age) VALUES (?, ?)")) {statement.setString(1, user.getName());statement.setInt(2, user.getAge());statement.executeUpdate();} catch (SQLException e) {e.printStackTrace();throw new RuntimeException(e);}} }
在上述示例代码中,使用 @ConfigurationProperties 注解将数据源的连接信息和配置类绑定。使用 @Qualifier 和 @Autowired 注解指定要使用的数据源。在 Service 或 Repository 中通过 DataSource.getConnection() 获取连接,手动执行 SQL 语句。
5.3 审计日志和版本控制
审计日志和版本控制是企业级应用程序常见的需求,Spring Data JPA 提供了 @CreatedBy、@CreatedDate、@LastModifiedBy、@LastModifiedDate 和 @Version 等注解来支持审计日志和版本控制功能。以下示例代码演示了如何在实体类中使用 Spring Data JPA 提供的注解实现审计日志和版本控制。
@Entity
@Table(name = "user")
@EntityListeners(AuditingEntityListener.class)
public class User {@Id@GeneratedValue(strategy = GenerationType.AUTO)private Long id;@Columnprivate String name;@Columnprivate Integer age;@CreatedDate@Column(name = "create_time", nullable = false, updatable = false)private LocalDateTime createTime;@CreatedBy@Column(name = "create_by", nullable = false, updatable = false)private String createBy;@LastModifiedDate@Column(name = "update_time", nullable = false)private LocalDateTime updateTime;@LastModifiedBy@Column(name = "update_by", nullable = false)private String updateBy;@Version@Column(name = "version")private Long version;// 省略 getter 和 setter 方法
}
在上述示例代码中,使用 @CreatedDate 和 @CreatedBy 注解标注创建时间和创建人属性,并设置 nullable=false 和 updatable=false 属性不允许为空和更新。使用 @LastModifiedDate 和 @LastModifiedBy 注解标注修改时间和修改人属性,并设置 nullable=false 属性不允许为空。使用 @Version 注解标注版本号属性。
在配置类中启用审计功能:
@Configuration
@EnableJpaAuditing
public class JpaConfig {
}
这样就可以在增删改查操作中自动记录审计日志和版本信息。
六、总结
6.1 Spring Data JPA的优点和缺点
- 优点
- 简单易用:Spring Data JPA 简化了数据访问层的开发,大大减少了代码量。
- 减少重复工作:通过继承 JpaRepository 接口,可以自动获得增删改查等基本操作,减少了开发人员的重复工作。
- 更好的可读性:通过使用 Spring Data JPA 提供的方法命名规范,可以使代码更具可读性,提高了代码的可维护性。
- 集成方便:Spring Data JPA 可以很方便地与其他 Spring 框架集成,如 Spring Boot、Spring Cloud 等。
- 规范化:Spring Data JPA 实现了 JPA 规范,支持多种数据库,并且提供了很多扩展接口,可以方便地进行定制。
- 缺点
- 性能问题:在大数据量、高并发情况下,性能可能不如原生的 SQL 查询,需要进行调优。
- 学习成本:学习 JPA 规范以及 Spring Data JPA 的相关知识需要一定的时间和精力。
- 灵活性差:由于 Spring Data JPA 主要是为了简化 CRUD 操作的开发,因此对于复杂查询等场景可能不太适合。
6.2 与其他 ORM 框架的比较
- 与 MyBatis 比较
- Spring Data JPA:优点是代码简单、易于维护,集成 Spring 框架更方便;缺点是灵活性不如 MyBatis,性能也可能不如 MyBatis。
- MyBatis:优点是灵活性强,可以执行复杂的 SQL 语句;缺点是需要手动编写 SQL 语句,难以维护。
- 与 Hibernate 比较
- Spring Data JPA:基于 JPA 标准,规范化强,使用简单,支持多种数据库;缺点是性能可能不如原生 SQL,不太适合复杂查询场景。
- Hibernate:性能好,支持丰富的 ORM 功能,适合复杂查询场景;缺点是学习成本高,文档相对较少,适用范围相对狭窄。
6.3 适合使用 Spring Data JPA 的项目类型
Spring Data JPA 适用于需求较为简单的 CRUD 操作的项目,特别是对于初学者来说,使用 Spring Data JPA 可以很快速的上手。对于一些需要进行关联操作的复杂查询场景,或者需要特定的 SQL 语句实现的场景,可以考虑使用 MyBatis 或者直接使用 Hibernate。但对于大多数项目而言,使用 Spring Data JPA 已经能够很好地满足需求。
相关文章:
Spring Data JPA 详解
目录 一、概述1.1 JPA简介1.2 Spring Data JPA简介 二、配置及应用2.1 环境配置2.2 依赖添加2.3 实体类创建2.4 Repository接口创建2.5 示例程序运行 三、实体映射3.1 注解3.2 关系映射 四、Repository接口4.1 基本增删改查4.2 自定义查询方法4.3 使用 Sort 和 Pageable 进行排…...
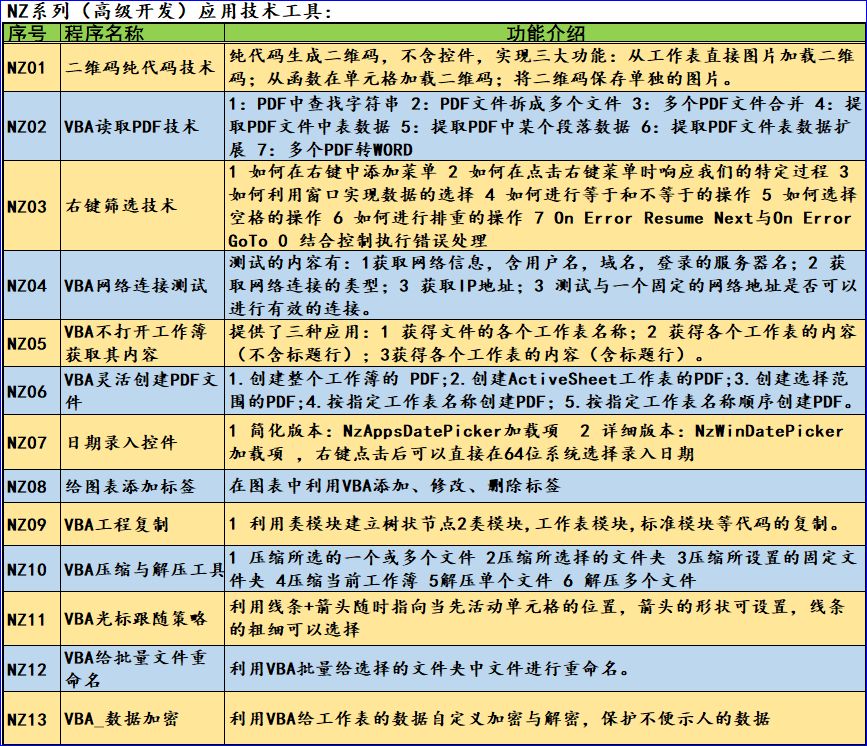
NZ系列工具NZ02:VBA读取PDF使用说明
【分享成果,随喜正能量】时光绽放并蒂莲,更是一份殷殷嘱托,更是一份诚挚祝福,是一份时光馈赠,又是一份时光陪伴。。 我的教程一共九套及VBA汉英手册一部,分为初级、中级、高级三大部分。是对VBA的系统讲解…...

Autocasting和GradScaler
Autocasting和GradScaler是什么 torch.autocast 是一个上下文管理器,它可以将数据类型从 float32 自动转换为 float16。这可以提高性能,因为 float16 比 float32 更小,因此可以更快地处理。torch.cuda.amp.GradScaler 是一个类,它…...
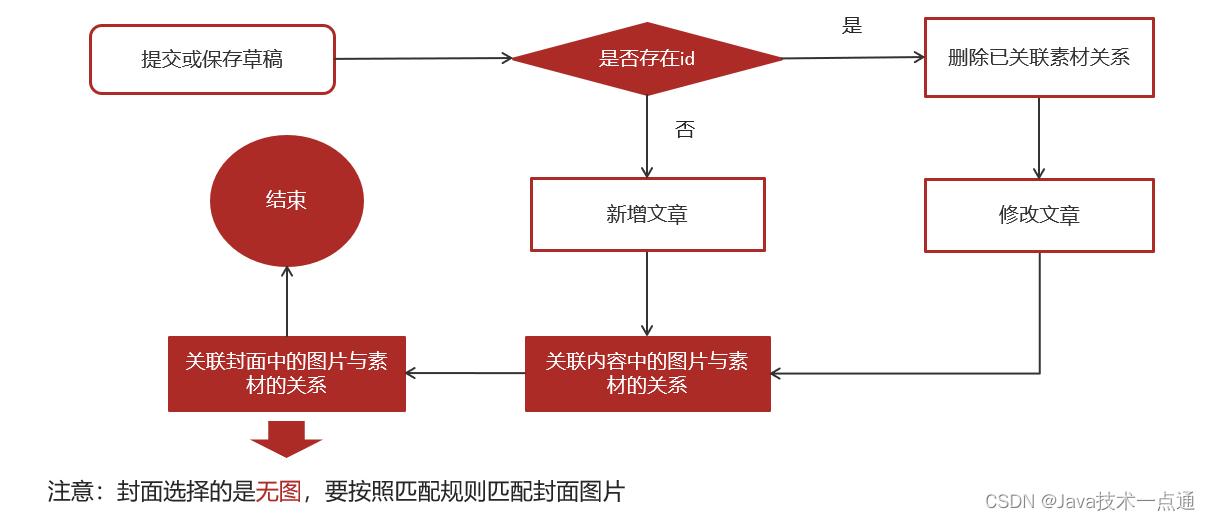
头条移动端项目Day03 —— 自媒体素材管理、自媒体文章管理、自媒体文章发布
❤ 作者主页:欢迎来到我的技术博客😎 ❀ 个人介绍:大家好,本人热衷于Java后端开发,欢迎来交流学习哦!( ̄▽ ̄)~* 🍊 如果文章对您有帮助,记得关注、点赞、收藏、…...
的详细介绍】)
【ARM 嵌入式 编译系列 9-- GCC 编译符号表(Symbol Table)的详细介绍】
文章目录 什么是符号表符号表的作用是什么如何生成符号表符号表中的数据类型有哪些?符号表与map文件什么关系? 上篇文章:ARM 嵌入式 番外篇 编译系列 8 – RT-Thread 编译命令 Scons 详细讲解 什么是符号表 在 ARM GCC 中,符号表…...

Apache Doris 入门教程27:BITMAP精准去重和HLL近似去重
BITMAP 精准去重 背景 Doris原有的Bitmap聚合函数设计比较通用,但对亿级别以上bitmap大基数的交并集计算性能较差。排查后端be的bitmap聚合函数逻辑,发现主要有两个原因。一是当bitmap基数较大时,如bitmap大小超过1g,网络/磁盘…...

bug总结
bug总是意外的出现,对于语法问题导致的bug是容易排查的,对于逻辑的bug和环境的bug往往令人头疼。在这里,将这些收集起来。、 【1-8来自对博客认输了!这些Bug让我目瞪口呆!_电脑放青藏高原共振是真的?_Truda.的博客-C…...

DC电源模块的高转换率
BOSHIDA DC电源模块的高转换率 DC电源模块是将交流电转换为直流电供应设备使用的装置,是现代工业制造和电子产品中不可或缺的组件之一。高转换率是DC电源模块最重要的性能之一,它直接影响着电源的效率、功耗和发热等方面,因此也深受设计师的关…...

用于网页抓取的最佳 Python 库
探索一系列用于网页抓取的强大 Python 库,包括用于 HTTP 请求、解析 HTML/XML 和自动浏览的库。 网络抓取已成为当今数据驱动世界中不可或缺的工具。Python 是最流行的抓取语言之一,拥有一个由强大的库和框架组成的庞大生态系统。在本文中,我…...

异步回调中axios,ajax,promise,cors详解区分
Ajax、Promise和Axios之间的关系是,它们都是用于在Web应用程序中发送异步HTTP请求的JavaScript库,但它们有不同的实现方式和用法。 Ajax是一种旧的技术,使用XMLHttpRequest对象来向服务器发送异步请求并获取响应。它通常需要手动编写回调函数…...
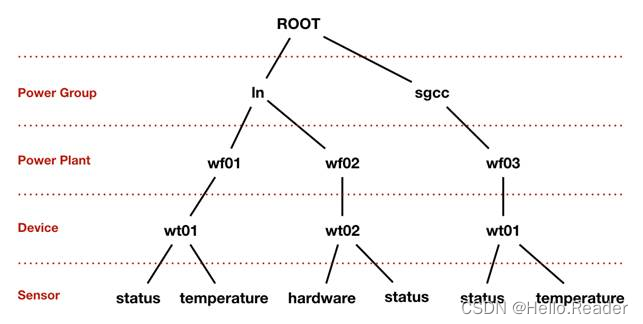
IoTDB原理剖析
一、介绍 IoTDB(物联网数据库)是一体化收集、存储、管理与分析物联网时序数据的软件系统。 Apache IoTDB采用轻量式架构,具有高性能和丰富的功能。 IoTDB从存储上对时间序列进行排序,索引和chunk块存储,大大的提升时序…...
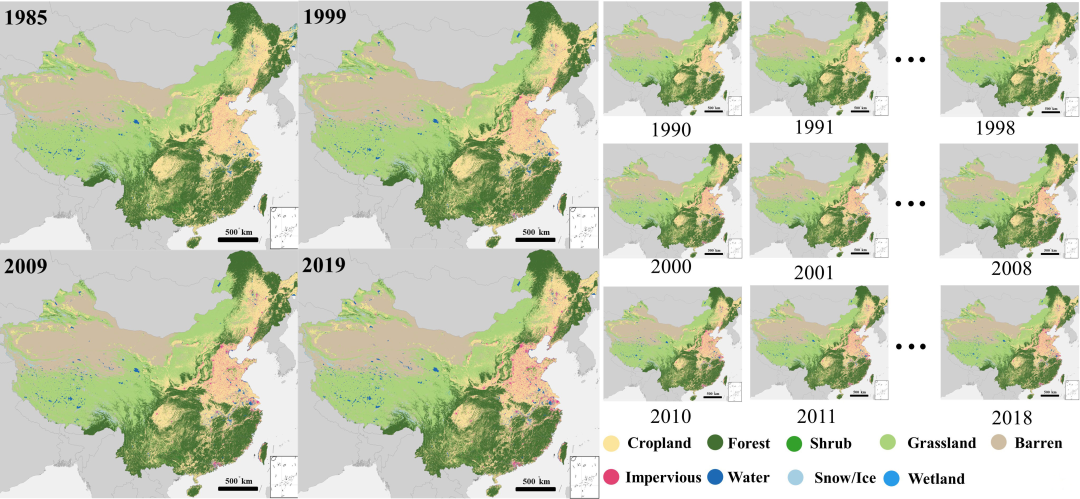
中国1990-2021连续30年土地利用数据CLCD介绍及下载
CLCD数据介绍 CLCD(China Land Cover Dataset)数据集由武汉大学黄昕老师公布,黄昕老师基于Google Earth Engine上335,709景Landsat数据,制作中国年度土地覆盖数据集(annual China Land Cover Dataset, CLCD),包含1985+1990—2020中国逐年土地覆盖信息。 为此,黄昕老师…...
Tubi 前端测试:迁移 Enzyme 到 React Testing Library
前端技术发展迅速,即便不说是日新月异,每年也都推出新框架和新技术。Tubi 的产品前端代码仓库始建于 2015 年,至今 8 年有余。可喜的是,多年来紧随 React 社区的发展,Tubi 绝大多数的基础框架选型都遵循了社区流行的最…...
Chrome
Chrome 简介下载 简介 Chrome 是由 Google 开发的一款流行的网络浏览器。它以其快速的性能、强大的功能和用户友好的界面而闻名,并且在全球范围内被广泛使用。Chrome 支持多种操作系统,包括 Windows、macOS、Linux 和移动平台。 Chrome官网: https://ww…...
零代码编程:用ChatGPT批量删除Excel文件中的行
文件夹中有上百个Excel文件,每个文件中都有如下所示的两行,要进行批量删除。 在ChatGPT中输入提示词: 你是一个Python编程专家,要完成一个处理Excel文件内容的任务,具体步骤如下: 打开F盘的文件夹&#x…...
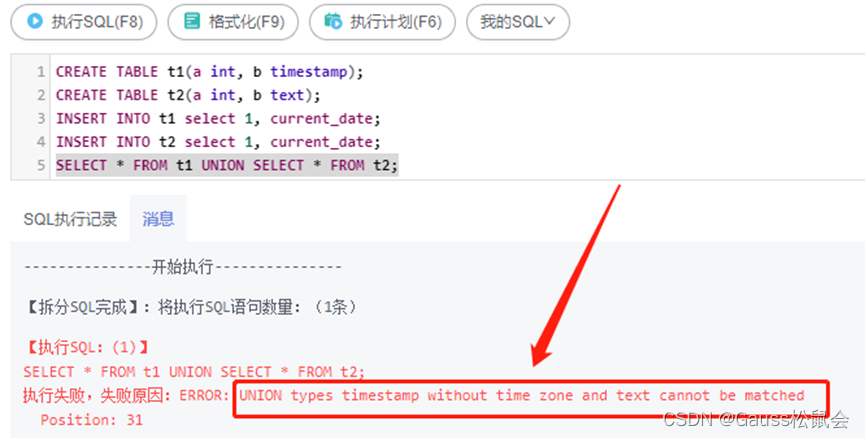
GaussDB数据库SQL系列-UNION UNION ALL
目录 一、前言 二、GaussDB UNION/UNION ALL 1、GaussDB UNION 操作符 2、语法定义 三、GaussDB实验示例 1、创建实验表 2、合并且除重(UNION) 3、合并不除重(UNION ALL) 4、合并带有WHERE子句SQL结果集(UNION ALL) 5、…...
Azure创建第一个虚拟机
首先,登录到 Azure 门户 (https://portal.azure.com/)。在 Azure 门户右上角,点击“虚拟机”按钮,并点击创建,创建Azure虚拟机。 在虚拟机创建页面中,选择所需的基本配置,包括虚拟机名称、操作系统类型和版…...

Redis 之 缓存预热 缓存雪崩 缓存击穿 缓存穿透
目录 一、缓存预热 1.1 缓存预热是什么? 1.2 解决方案: 二、缓存雪崩 2.1 缓存雪崩是什么?怎么发生的? 2.2 怎么解决 三、缓存穿透 3.1 是什么?怎么产生的呢? 3.2 解决方案 3.2.1、采用回写增强&a…...
:收集样本数据和编译)
Golang 程序性能优化利器 PGO 详解(二):收集样本数据和编译
在软件开发过程中,性能优化是不可或缺的一部分。无论是在Web服务、数据处理系统还是实时通信中,良好的性能都是至关重要的。Golang 从1.20版版本开始引入的 Profile Guided Optimization(PGO)机制能够帮助更好地优化 Go 程序的性能…...
《格斗之王AI》使用指南
目录 一、说明 二、步骤 1. 下载 2.配置环境 3.替换 4.测试 5.训练 一、说明 该项目是 针对B站UP主 林亦LYi 的作品 格斗之王!AI写出来的AI竟然这么强!的使用指南,目的是在帮助更多小白轻松入门,一起感受AI的魅力。 林亦LYi…...

忍者像素绘卷微信小程序A/B测试:不同‘火之意志’视觉权重用户留存
忍者像素绘卷微信小程序A/B测试:不同火之意志视觉权重用户留存分析 1. 项目背景与测试目标 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工作站,将忍者文化与16-Bit复古游戏美学完美融合。其独特的"云端"视觉设计为用户提供了清爽…...

3步解决网盘下载烦恼:LinkSwift直链助手全解析
3步解决网盘下载烦恼:LinkSwift直链助手全解析 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / …...

MAA明日方舟助手:3个步骤告别重复性游戏操作,实现全自动智能管理
MAA明日方舟助手:3个步骤告别重复性游戏操作,实现全自动智能管理 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. …...

【限时解禁|SITS2026未公开演讲PPT】:大模型量化压缩的“最后一公里”——如何让KV Cache压缩不掉F1、Attention稀疏不降BLEU?
第一章:SITS2026分享:大模型量化压缩技术 2026奇点智能技术大会(https://ml-summit.org) 大模型量化压缩已成为部署百亿参数级语言模型至边缘设备与推理服务集群的关键路径。在SITS2026现场,来自Meta、DeepMind及国内头部AI基础设施团队的工…...
:从尖顶脉冲到高效输出的工程实践)
《高频电子线路》 —— 高频谐振功放(2):从尖顶脉冲到高效输出的工程实践
1. 高频谐振功放的工程实践挑战 作为一名射频工程师,在实际调试发射机末级功放时,最头疼的就是如何平衡输出功率和效率。记得我第一次独立负责项目时,对着频谱仪上扭曲的波形整整折腾了两周。高频谐振功放这个看似简单的电路,藏着…...

Qwen3-0.6B-FP8功能测评:思维模式切换,让对话更智能
Qwen3-0.6B-FP8功能测评:思维模式切换,让对话更智能 你是否遇到过这样的场景:想让AI帮你解决一个复杂的数学题,它却用闲聊的语气跟你兜圈子;或者只是想简单聊聊天,它却开始长篇大论地推理分析?…...

Qwen3-VL-2B图文理解系统备份方案:数据安全实战部署
Qwen3-VL-2B图文理解系统备份方案:数据安全实战部署 1. 引言 想象一下,你花了好几天时间,终于把一个能看懂图片、识别文字的AI服务部署上线了。它不仅能帮你分析商品图,还能从复杂的图表里提取数据,甚至辅导孩子做作…...
 超详细实现(C 语言 + 逐行精讲))
链栈(链式栈) 超详细实现(C 语言 + 逐行精讲)
前言栈(Stack) 是一种后进先出(LIFO)的线性数据结构。前面我们学习了顺序栈(数组实现),今天我们学习它的兄弟 ——链栈(链式栈)。链栈 用单链表实现的栈它完美解决了顺序…...
)
音视频AI工程化最后一公里(SITS2026原生框架实测报告:FFmpeg vs WebAssembly vs 原生Kernel Mode)
第一章:音视频AI工程化最后一公里的挑战与SITS2026原生框架定位 2026奇点智能技术大会(https://ml-summit.org) 在音视频AI大规模落地过程中,“最后一公里”并非指部署时长或物理距离,而是指模型能力与真实业务场景之间不可忽视的语义鸿沟—…...

EspMQTTClient:ESP32/ESP8266的Wi-Fi+MQTT一体化连接框架
1. EspMQTTClient 库深度解析:面向嵌入式工程师的 Wi-Fi 与 MQTT 一体化连接方案EspMQTTClient 是专为 ESP8266 和 ESP32 平台设计的轻量级、高鲁棒性网络通信库,其核心目标并非简单封装底层 SDK API,而是构建一套面向生产环境的连接生命周期…...