【量化课程】07_量化回测
文章目录
- 7.1 pandas计算策略评估指标
- 数据准备
- 净值曲线
- 年化收益率
- 波动率
- 最大回撤
- Alpha系数和Beta系数
- 夏普比率
- 信息比率
- 7.2 聚宽平台量化回测实践
- 平台介绍
- 策略实现
- 7.3 Backtrader平台量化回测实践
- Backtrader简介
- Backtrader量化回测框架实践
- 7.4 BigQuant量化框架实战
- BigQuant简介
- 策略实现
- 7.5 手写回测代码 - 手把手实现一个傻瓜式量化回测框架
- 为什么?
- 为什么要开发?
- 为什么叫傻瓜式?
- 解决什么痛点?
- 怎么用?
- 引入StupidHead.py
- 编写策略
- 回测策略
- 参数优化
- 框架原理和细节
- more
7.1 pandas计算策略评估指标
本章节介绍关于金融量化分析的一些基本概念,如年华收益率、基准年化收益率、最大回撤等。在严格的量化策略回测中,这些概念都是需要掌握并熟练使用的,这样能够全面的评估量化策略。市面上,很多策略回测笼统地使用所谓的“胜率”来确定策略的好坏,这是一种非常业余而且不可靠的分析方法。在衡量基金业绩好坏的时候,大部分人也只是看基金的年化收益,忽略了基金的风险情况(波动率)。市场中充斥着大量类似的业余的分析方法,这些方法导致很多所谓的回测看起来很美好,其实在统计上根本站不住脚,即所谓的“统计骗局”。
因此在量化回测过程中,需要从收益、稳定性、胜率、风险四个方面来综合评估策略好坏。熟练掌握评估指标,还能够帮助大家识别一些经典“骗局”,如
- 只展示基金的年化收益,而不提基金的波动率或者最大回撤
- 使用周收益率来计算夏普比率,而不是使用日收益率来计算
数据准备
为了帮助大家深入了解指标计算逻辑和实现方式,本章节采用指标讲解和代码实现相结合的方式进行讲解。再具体计算过程中,选择的目标标的是贵州茅台(600519.SH)、工商银行(601398.SH)、中国平安(601318.SH),策略基准是沪深300指数(000300.XSHG),策略采用最简单的方式:买入持有。持有周期为20180101 - 20221231,共1826个自然日。数据获取如下所示
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tushare as ts
%matplotlib inline # 无视warning
import warnings
warnings.filterwarnings("ignore")# 正常显示画图时出现的中文和负号
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False#起始和结束日期可以自行输入,否则使用默认
def get_data(code, start_date, end_date):# 配置 tushare tokenmy_token = 'XXXXX' pro = ts.pro_api(my_token)df = pro.daily(ts_code=code, start_date=start_date, end_date=end_date)df.index = pd.to_datetime(df.trade_date)return df.close#以上证综指、贵州茅台、工商银行、中国平安为例
stocks={'600519.SH':'贵州茅台','601398.SH':'工商银行','601318.SH':'中国平安'
}df = pd.DataFrame()
for code,name in stocks.items():df[name] = get_data(code, '20180101', '20221231')# 按照日期正序
df = df.sort_index()# 本地读入沪深300合并
df_base = pd.read_csv('000300.XSHG_2018_2022.csv')
df_base.index = pd.to_datetime(df_base.trade_date)
df['沪深300'] = df_base['close']
净值曲线
净值曲线是一组时间序列的曲线,其含义表示为股票或基金在不同时间的价值相对于期初的价值的倍数。 再具体分析中,我们可以将期初价格定位1,那么如果你在当前时间点手里的净值是1.4,就意味着当前时间的资产价值是期初的1.4倍。
# 以第一交易日2018年1月1日收盘价为基点,计算净值并绘制净值曲线
df_worth = df / df.iloc[0]
df_worth.plot(figsize=(15,6))
plt.title('股价净值走势', fontsize=10)
plt.xticks(pd.date_range('20180101','20221231',freq='Y'),fontsize=10)
plt.show()

年化收益率
累计收益率:
R t = P T − P t P t R_t = \frac{P_T - P_{t}} {P_{t}} Rt=PtPT−Pt
P T P_T PT 表示在期末资产的价格
P t P_{t} Pt 表示期初资产价格。
年化收益率:
R p = ( 1 + R ) m n − 1 R_p = (1 + R)^\frac{m}{n} - 1 Rp=(1+R)nm−1
R R R 表示期间总收益率,m是与n(可以是天数、周数、月数)相对应的计算周期,根据计算惯例,m=252、52、12分别指代日、周、月向年化的转换;n为期间自然日天数。
年化收益的一个直观的理解是,假设按照某种盈利能力,换算成一年的收益大概能有多少。这个概念常常会存在误导性,比如,这个月股票赚了5%,在随机波动的市场中,这是很正常的现象。如果据此号称年化收益为5%×12个月=60%,这就显得不太可信了,实际上每个月的收益不可能都这么稳定。所以在听到有人说年化收益的时候,需要特别留意一下具体的情况,否则很容易被误导。
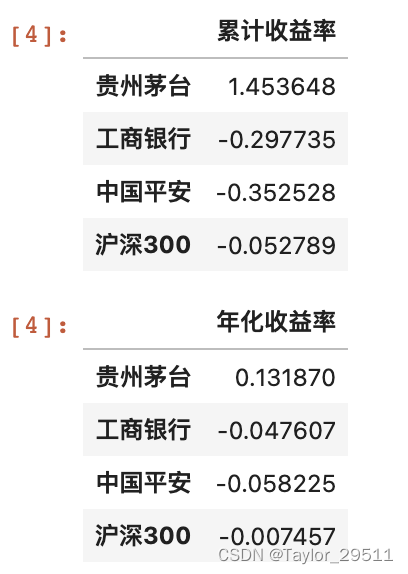
# 区间累计收益率(绝对收益率)
total_return = df_worth.iloc[-1]-1
total_return = pd.DataFrame(total_return.values,columns=['累计收益率'],index=total_return.index)
total_return# 年化收益率
annual_return = pd.DataFrame((1 + total_return.values) ** (252 / 1826) - 1,columns=['年化收益率'],index=total_return.index)
annual_return
波动率
波动率是对收益变动的一种衡量,本质也是风险,波动率和风险,都是用来衡量收益率的不确定性的。我们用方差来表示,年波动率等于策略收益和无风险收益的标准差除以其均值,再除以交易日倒数的平方根,通常交易日取252天。
V o l a t i l i t y = 252 n − 1 ∑ i = 1 n ( r p − r p ^ ) 2 Volatility = \sqrt{\frac{252}{n-1} \sum\limits_{i=1}^n (r_p - \hat{r_p})^2} Volatility=n−1252i=1∑n(rp−rp^)2
r p r_p rp表示策略每日收益率
r p ^ \hat{r_p} rp^表示策略每日收益率的平均值
n n n表示策略执行天数
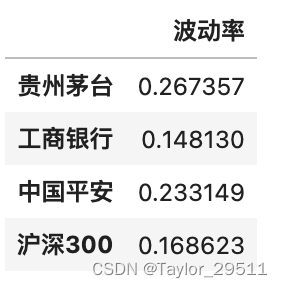
df_return = df / df.shift(1) - 1
df_return = ((df_return.iloc[1:] - df_return.mean()) ** 2)volatility = pd.DataFrame(np.sqrt(df_return.sum() * 252 / (1826-1)),columns=['波动率'],index=total_return.index)
volatility
最大回撤
选定周期内任一历史时点往后推,于最低点时的收益率回撤幅度的最大值。最大回撤用来描述可能出现的最糟糕的情况。最大回撤是一个重要的风险指标,对于量化策略交易,该指标比波动率还重要。
P为某一天的净值,i为某一天,j为i后的某一天,Pi为第i天的产品净值,Pj则是Pi后面某一天的净值
则该资产的最大回撤计算如下:
M a x D r a w d o w n = m a x ( P i − P j ) P i MaxDrawdown = \frac{max(P_i - P_j)} {P_{i}} MaxDrawdown=Pimax(Pi−Pj)
def max_drawdown_cal(df):md = ((df.cummax() - df)/df.cummax()).max()return round(md, 4)max_drawdown = {}stocks={'600519.SH':'贵州茅台','601398.SH':'工商银行','601318.SH':'中国平安','000300.XSHG': '沪深300'
}for code,name in stocks.items():max_drawdown[name]=max_drawdown_cal(df[name])max_drawdown = pd.DataFrame(max_drawdown,index=['最大回撤']).T
max_drawdown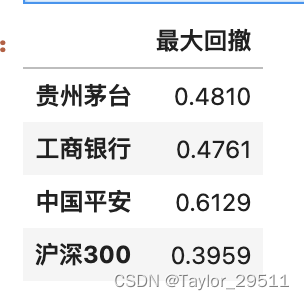
Alpha系数和Beta系数
关于Alpha系数和Beta系数有很多详尽的解释,这里就用最简单的一句话来帮助大家简单理解。Beta系数代表投资中的系统风险,而在投资中除了系统风险外还面临着市场波动无关的非系统性风险。 Alpha系数就代表投资中的非系统性风险,是投资者获得与市场波动无关的回报。
可以使用资本资产定价模型(CAPM)来估计策略的beta和alpha值,CAPM模型为:
E ( r i ) = r f + β ( E ( r m ) − r f ) E(r_i) = r_f + \beta(E(r_m) - r_f) E(ri)=rf+β(E(rm)−rf)
E ( r i ) E(r_i) E(ri)表示投资组合的预期收益率
r f r_f rf表示无风险利率
r m r_m rm表示市场指数收益率
β \beta β表示股市波动风险与投资机会中的结构性与系统性风险。
因此CAPM的计量模型可以表示为
r i = α + β r m + ϵ α r_i = \alpha + \beta r_m + \epsilon_\alpha ri=α+βrm+ϵα
ϵ α \epsilon_\alpha ϵα表示随机扰动,可以理解为个体风险
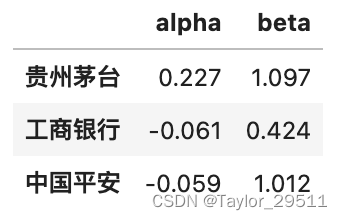
from scipy import stats#计算每日收益率 收盘价缺失值(停牌),使用前值代替
rets=(df.iloc[:,:4].fillna(method='pad')).apply(lambda x:x/x.shift(1)-1)[1:]#市场指数为x,个股收益率为y
x = rets.iloc[:,3].values
y = rets.iloc[:,:3].values
capm = pd.DataFrame()
alpha = []
beta = []
for i in range(3):b, a, r_value, p_value, std_err=stats.linregress(x,y[:,i])#alpha转化为年化alpha.append(round(a*250,3))beta.append(round(b,3))capm['alpha']=alpha
capm['beta']=beta
capm.index=rets.columns[:3]
#输出结果:
capm
夏普比率
夏普比率(sharpe ratio)表示每承受一单位总风险,会产生多少的超额报酬,该比率越高。夏普比率是在资本资产定价模型进一步发展得来的。
S h a r p e R a t i o = R p − R f σ p SharpeRatio = \frac{R_p - R_f} {\sigma_p} SharpeRatio=σpRp−Rf
R p R_p Rp表示策略年化收益率
R F R_F RF表示无风险收益率
σ p \sigma_p σp表示年化标准差
# 超额收益率以无风险收益率为基准 假设无风险收益率为年化3%
ex_return=rets - 0.03/250# 计算夏普比率
sharpe_ratio=np.sqrt(len(ex_return))*ex_return.mean()/ex_return.std()
sharpe_ratio=pd.DataFrame(sharpe_ratio,columns=['夏普比率'])
sharpe_ratio
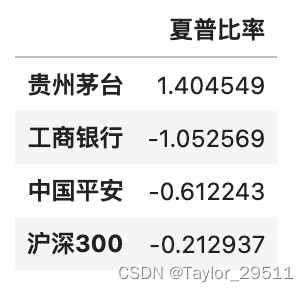
信息比率
信息比率含义与夏普比率类似,只不过其参照基准不是无风险收益率,而是策略的市场基准收益率。
I n f o r m a t i o n R a t i o = R p − R f σ t InformationRatio = \frac{R_p - R_f} {\sigma_t} InformationRatio=σtRp−Rf
R p R_p Rp表示策略年化收益率
R F R_F RF表示无风险收益率
σ t \sigma_t σt表示策略与基准每日收益率差值的年化标准差
###信息比率
ex_return = pd.DataFrame()
ex_return['贵州茅台']=rets.iloc[:,0]-rets.iloc[:,3]
ex_return['工商银行']=rets.iloc[:,1]-rets.iloc[:,3]
ex_return['中国平安']=rets.iloc[:,2]-rets.iloc[:,3]#计算信息比率
information_ratio = np.sqrt(len(ex_return))*ex_return.mean()/ex_return.std()
#信息比率的输出结果
information_ratio = pd.DataFrame(information_ratio,columns=['信息比率'])
information_ratio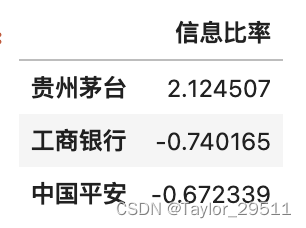
7.2 聚宽平台量化回测实践
平台介绍
聚宽(https://www.joinquant.com/) 成立于2015年5月,是一家量化交易平台,为投资者提供做量化交易的工具与服务,帮助投资者更好地做量化交易。
整体来看,聚宽具有以下几点优势
- 聚宽让做量化交易的成本极大降低
- 提供多种优质的便于取用的数据
- 提供投资研究功能,便于自由地统计、研究、学习等
- 提供多种的策略评价指标与评价维度
- 支持多种策略的编写、回测、模拟、实盘
- 具备丰富且活跃的量化社区,可以发帖、学习、比赛等。
策略实现
本部分将介绍如何在聚宽平台实现一个双均线策略(具体参照ch05择时策略),并且在聚宽平台上进行回测,
来测试整体收益率。
策略代码如下,核心点有:
- 选择标的为:002594.XSHE 比亚迪
- 选择基准为:000300.XSHG 沪深300
- 策略为:当5日线金叉10日线,全仓买入;当5日线死叉10日线全仓卖出。
# 导入函数库
from jqdata import *# 初始化函数,设定基准等等
def initialize(context):# 设定沪深上证作为基准set_benchmark('000300.XSHG')# 开启动态复权模式(真实价格)set_option('use_real_price', True)# 输出内容到日志 log.info()log.info('初始函数开始运行且全局只运行一次')# 过滤掉order系列API产生的比error级别低的log# log.set_level('order', 'error')### 股票相关设定 #### 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type='stock')## 运行函数(reference_security为运行时间的参考标的;传入的标的只做种类区分,因此传入'000300.XSHG'或'510300.XSHG'是一样的)# 开盘前运行run_daily(before_market_open, time='before_open', reference_security='000300.XSHG')# 开盘时运行run_daily(market_open, time='open', reference_security='000300.XSHG')# 收盘后运行run_daily(after_market_close, time='after_close', reference_security='000300.XSHG')## 开盘前运行函数
def before_market_open(context):# 输出运行时间log.info('函数运行时间(before_market_open):'+str(context.current_dt.time()))# 给微信发送消息(添加模拟交易,并绑定微信生效)# send_message('美好的一天~')# 要操作的股票:比亚迪(g.为全局变量)g.security = '002594.XSHE'## 开盘时运行函数
def market_open(context):log.info('函数运行时间(market_open):'+str(context.current_dt.time()))security = g.security# 获取股票的收盘价close_data5 = get_bars(security, count=5, unit='1d', fields=['close'])close_data10 = get_bars(security, count=10, unit='1d', fields=['close'])# close_data20 = get_bars(security, count=20, unit='1d', fields=['close'])# 取得过去五天,十天的平均价格MA5 = close_data5['close'].mean()MA10 = close_data10['close'].mean()# 取得上一时间点价格#current_price = close_data['close'][-1]# 取得当前的现金cash = context.portfolio.available_cash# 五日均线上穿十日均线if (MA5 > MA10) and (cash > 0):# 记录这次买入log.info("5日线金叉10日线,买入 %s" % (security))# 用所有 cash 买入股票order_value(security, cash)# 五日均线跌破十日均线elif (MA5 < MA10) and context.portfolio.positions[security].closeable_amount > 0:# 记录这次卖出log.info("5日线死叉10日线, 卖出 %s" % (security))# 卖出所有股票,使这只股票的最终持有量为0for security in context.portfolio.positions.keys():order_target(security, 0)## 收盘后运行函数
def after_market_close(context):log.info(str('函数运行时间(after_market_close):'+str(context.current_dt.time())))#得到当天所有成交记录trades = get_trades()for _trade in trades.values():log.info('成交记录:'+str(_trade))log.info('一天结束')log.info('##############################################################')
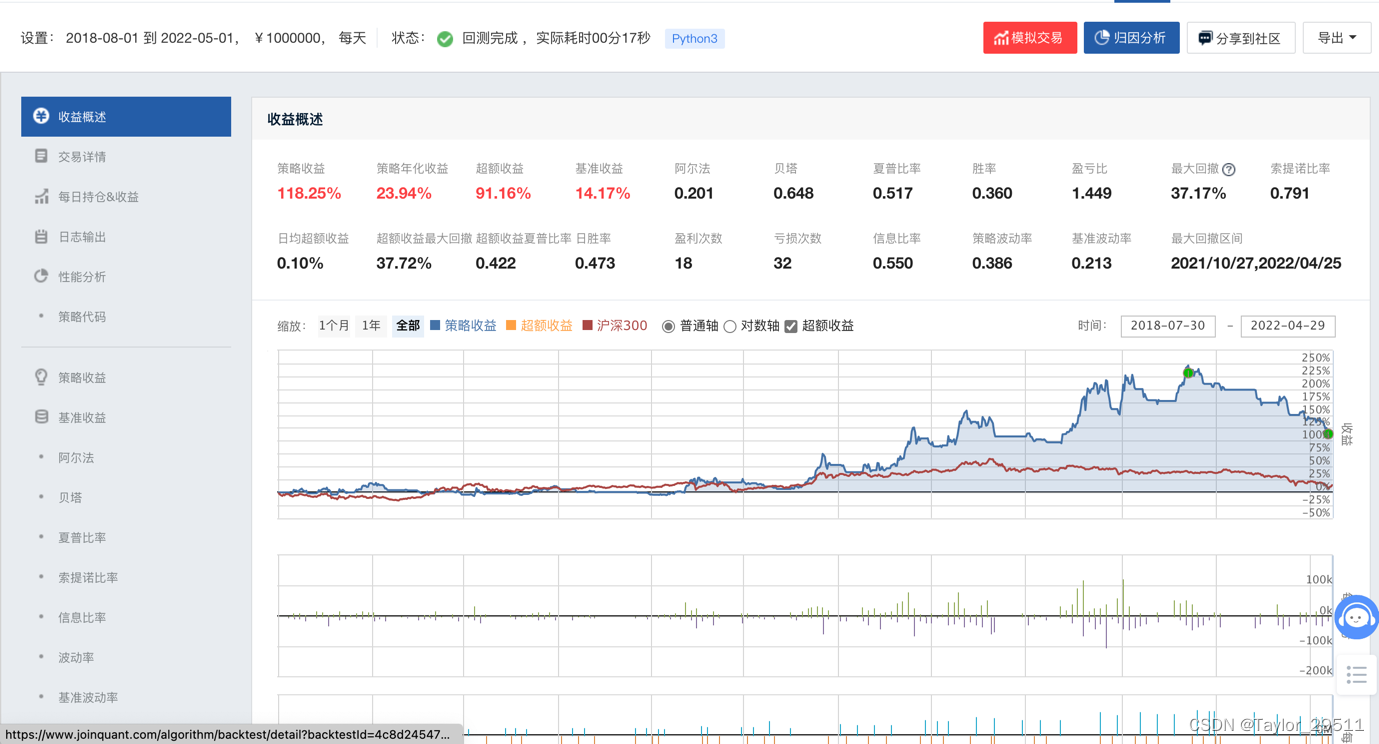
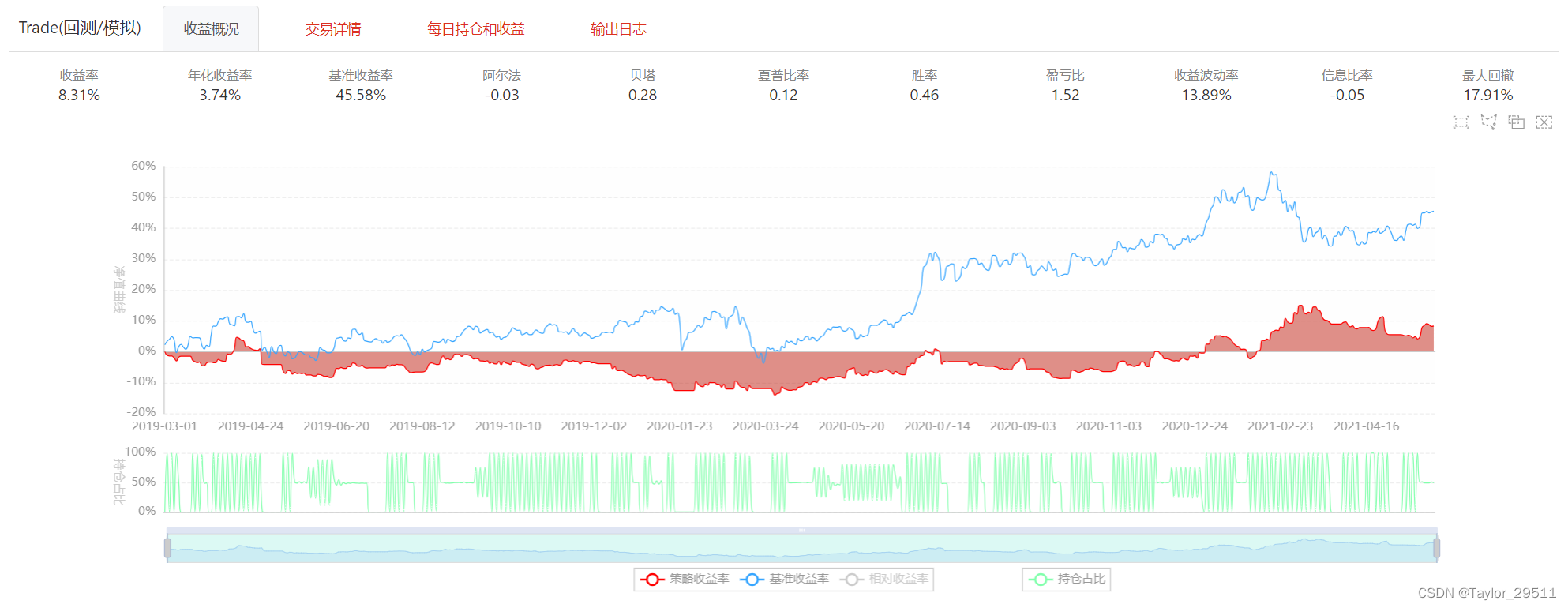
在聚宽上回测策略结果如下,虽然策略整体具备较好的收益,但需要提示的是该策略并不稳定。
- 该策略带入了后验知识。因为我们大致知道2018-2020年左右比亚迪处于上涨周期,该周期内基本上五日线在10日线以上。
- 该策略会有很强的回撤。例如回测的后半段,该策略已经开始较大幅度回撤,因此需要结合其他策略来进行止盈止损。
- 该策略回测周期不够长。本策略仅回测了两年,并且处于较强周期内,因此不具备较强的回测意义。
7.3 Backtrader平台量化回测实践
Backtrader简介
Backtrader是一款基于Python的开源的量化回测框架,功能完善,安装简单。
Backtrader官方文档(英文) https://www.backtrader.com/docu/
Backtrader非官方文档(中文) https://www.heywhale.com/mw/project/63857587d0329ee911dcd7f2
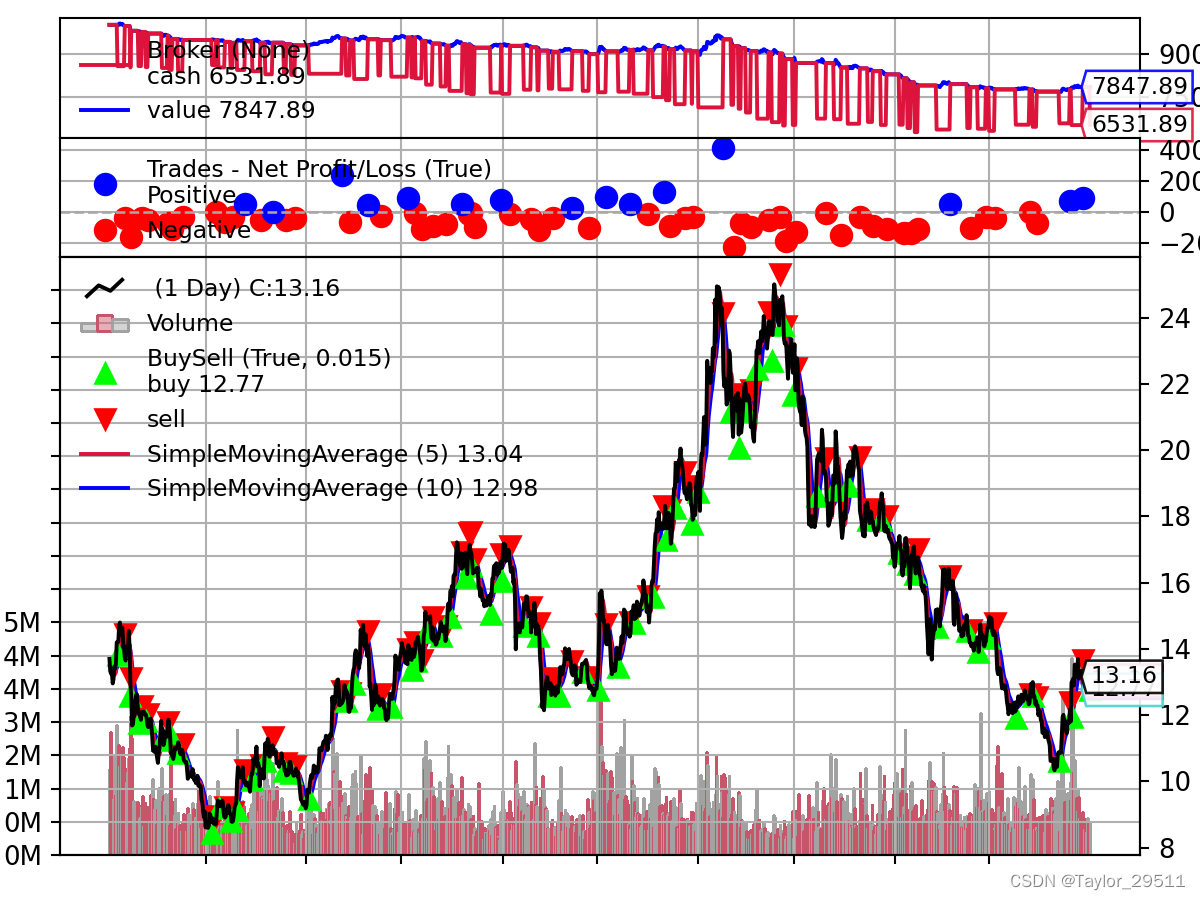
Backtrader量化回测框架实践
本部分将介绍如何在Backtrader实现一个双均线策略(具体参照ch05择时策略),并且在该平台上进行回测,
来测试整体收益率。
策略代码如下,核心点有:
- 选择标的为:002594.XSHE 比亚迪
- 选择基准为:000300.XSHG 沪深300
- 策略为:当5日线金叉10日线,全仓买入;当5日线死叉10日线全仓卖出。
# 导入函数库
from __future__ import (absolute_import, division, print_function, unicode_literals)
import datetime
import pymysql
import pandas as pd
import backtrader as bt
import tushare as ts
import numpy as np# 数据获取(从Tushare中获取数据)
"""
数据获取一般都是通过连接数据库从数据库中读取,对于不了解数据库来源的新手可以从Tushare中直接获取数据
"""
def get_data(stock_code):"""stock_code:股票代码,类型: strreturn: 股票日线数据,类型: DataFrame"""token = 'Tushare token' # 可通过进入个人主页-接口TOKEN获得ts.set_token(token)pro = ts.pro_api(token)data_daily = pro.daily(ts_code = stock_code, start_date='20180101', end_date='20230101')data_daily['trade_date'] = pd.to_datetime(data_daily['trade_date'])data_daily = data_daily.rename(columns={'vol': 'volume'})data_daily.set_index('trade_date', inplace=True) data_daily = data_daily.sort_index(ascending=True)dataframe = data_dailydata_daily['openinterest'] = 0dataframe['openinterest'] = 0data = bt.feeds.PandasData(dataname=dataframe,fromdate=datetime.datetime(2018, 1, 1),todate=datetime.datetime(2023, 1, 1))return data# 双均线策略实现
class DoubleAverages(bt.Strategy):# 设置均线周期params = (('period_data5', 5),('period_data10', 10))# 日志输出def log(self, txt, dt=None):dt = dt or self.datas[0].datetime.date(0)print('%s, %s' % (dt.isoformat(), txt))def __init__(self):# 初始化数据参数self.dataclose = self.datas[0].close # 定义变量dataclose,保存收盘价self.order = None # 定义变量order,用于保存订单self.buycomm = None # 定义变量buycomm,记录订单佣金self.buyprice = None # 定义变量buyprice,记录订单价格self.sma5 = bt.indicators.SimpleMovingAverage(self.datas[0], period=self.params.period_data5) # 计算5日均线self.sma10 = bt.indicators.SimpleMovingAverage(self.datas[0], period=self.params.period_data10) # 计算10日均线def notify_order(self, order):if order.status in [order.Submitted, order.Accepted]: # 若订单提交或者已经接受则返回returnif order.status in [order.Completed]:if order.isbuy():self.log('Buy Executed, Price: %.2f, Cost: %.2f, Comm: %.2f' %(order.executed.price, order.executed.value, order.executed.comm))self.buyprice = order.executed.priceself.buycomm = order.executed.commelse:self.log('Sell Executed, Price: %.2f, Cost: %.2f, Comm: %.2f' %(order.executed.price, order.executed.value, order.executed.comm))self.bar_executed = len(self)elif order.status in [order.Canceled, order.Margin, order.Rejected]:self.log('Order Canceled/Margin/Rejected')self.order = Nonedef notify_trade(self, trade):if not trade.isclosed: # 若交易未关闭则返回returnself.log('Operation Profit, Total_Profit %.2f, Net_Profit: %.2f' %(trade.pnl, trade.pnlcomm)) # pnl表示盈利, pnlcomm表示手续费def next(self): # 双均线策略逻辑实现self.log('Close: %.2f' % self.dataclose[0]) # 打印收盘价格if self.order: # 检查是否有订单发送returnif not self.position: # 检查是否有仓位if self.sma5[0] > self.sma10[0]:self.log('Buy: %.2f' % self.dataclose[0])self.order = self.buy()else:if self.sma5[0] < self.sma10[0]:self.log('Sell: %.2f' % self.dataclose[0])self.order = self.sell()if __name__ == '__main__':cerebro = bt.Cerebro() # 创建策略容器cerebro.addstrategy(DoubleAverages) # 添加双均线策略data = get_data('000001.SZ')cerebro.adddata(data) # 添加数据cerebro.broker.setcash(10000.0) # 设置资金cerebro.addsizer(bt.sizers.FixedSize, stake=100) # 设置每笔交易的股票数量cerebro.broker.setcommission(commission=0.01) # 设置手续费print('Starting Portfolio Value: %.2f' % cerebro.broker.getvalue()) # 打印初始资金cerebro.run() # 运行策略print('Final Portfolio Value: %.2f' % cerebro.broker.getvalue()) # 打印最终资金cerebro.plot()
7.4 BigQuant量化框架实战
BigQuant简介
BigQuant是一个人工智能量化投资平台。
BigQuant官网 https://bigquant.com/
策略实现
本部分将介绍如何在BigQuant实现一个双均线策略(具体参照ch05择时策略),并且在该平台上进行回测,
来测试整体收益率。
策略代码如下,核心点有:
- 选择标的为:600519.SHA 贵州茅台、601392.SHA 工商银行
- 选择基准为:000300.HIX 沪深300
- 策略为:当5日线金叉10日线,全仓买入;当5日线死叉10日线全仓卖出。
from bigdatasource.api import DataSource
from biglearning.api import M
from biglearning.api import tools as T
from biglearning.module2.common.data import Outputsimport pandas as pd
import numpy as np
import math
import warnings
import datetimefrom zipline.finance.commission import PerOrder
from zipline.api import get_open_orders
from zipline.api import symbolfrom bigtrader.sdk import *
from bigtrader.utils.my_collections import NumPyDeque
from bigtrader.constant import OrderType
from bigtrader.constant import Directiondef m3_initialize_bigquant_run(context):context.set_commission(PerOrder(buy_cost=0.0003, sell_cost=0.0013, min_cost=5))def m3_handle_data_bigquant_run(context, data):today = data.current_dt.strftime('%Y-%m-%d') stock_hold_now = {e.symbol: p.amount * p.last_sale_pricefor e, p in context.perf_tracker.position_tracker.positions.items()}cash_for_buy = context.portfolio.cash try:buy_stock = context.daily_stock_buy[today] except:buy_stock=[] try:sell_stock = context.daily_stock_sell[today] except:sell_stock=[] stock_to_sell = [ i for i in stock_hold_now if i in sell_stock ]stock_to_buy = [ i for i in buy_stock if i not in stock_hold_now ] stock_to_adjust=[ i for i in stock_hold_now if i not in sell_stock ]if len(stock_to_sell)>0:for instrument in stock_to_sell:sid = context.symbol(instrument) cur_position = context.portfolio.positions[sid].amount if cur_position > 0 and data.can_trade(sid):context.order_target_percent(sid, 0) cash_for_buy += stock_hold_now[instrument]if len(stock_to_buy)+len(stock_to_adjust)>0:weight = 1/(len(stock_to_buy)+len(stock_to_adjust)) for instrument in stock_to_buy+stock_to_adjust:sid = context.symbol(instrument) if data.can_trade(sid):context.order_target_value(sid, weight*cash_for_buy) def m3_prepare_bigquant_run(context):df = context.options['data'].read_df()def open_pos_con(df):return list(df[df['buy_condition']>0].instrument)def close_pos_con(df):return list(df[df['sell_condition']>0].instrument)context.daily_stock_buy= df.groupby('date').apply(open_pos_con)context.daily_stock_sell= df.groupby('date').apply(close_pos_con)m1 = M.input_features.v1(features="""# #号开始的表示注释
# 多个特征,每行一个,可以包含基础特征和衍生特征
buy_condition=where(mean(close_0,5)>mean(close_0,10),1,0)
sell_condition=where(mean(close_0,5)<mean(close_0,10),1,0)""",m_cached=False
)m2 = M.instruments.v2(start_date=T.live_run_param('trading_date', '2019-03-01'),end_date=T.live_run_param('trading_date', '2021-06-01'),market='CN_STOCK_A',instrument_list="""600519.SHA
601392.SHA""",max_count=0
)m7 = M.general_feature_extractor.v7(instruments=m2.data,features=m1.data,start_date='',end_date='',before_start_days=60
)m8 = M.derived_feature_extractor.v3(input_data=m7.data,features=m1.data,date_col='date',instrument_col='instrument',drop_na=False,remove_extra_columns=False
)m4 = M.dropnan.v2(input_data=m8.data
)m3 = M.trade.v4(instruments=m2.data,options_data=m4.data,start_date='',end_date='',initialize=m3_initialize_bigquant_run,handle_data=m3_handle_data_bigquant_run,prepare=m3_prepare_bigquant_run,volume_limit=0.025,order_price_field_buy='open',order_price_field_sell='open',capital_base=1000000,auto_cancel_non_tradable_orders=True,data_frequency='daily',price_type='后复权',product_type='股票',plot_charts=True,backtest_only=False,benchmark='000300.HIX'
)
7.5 手写回测代码 - 手把手实现一个傻瓜式量化回测框架
为什么?
为什么要开发?
- 为了避免重复造轮子,简化策略的回测,开发该框架
- VNPY等框架
- 过于复杂,继承嵌套太多,不易理解
- 回测需填入合约名称、保证金比率、手续费等详细参数,但对于一个策略的雏形验证,往往不需要这么精细
- 有时候回测标的是指数或估值,市场上并没有相关合约
为什么叫傻瓜式?
🔴 无需安装,只需引用一个StupidHead.py文件
🟢 架构简单,没有复杂的类继承及嵌套关系,纯函数模式
🟡 策略编写简单
解决什么痛点?
🔴 回测结果表现无需手写
🟢 封装常用技术指标
🔵 策略参数优化问题
🟣 可直接对接模拟盘、实盘
怎么用?
引入StupidHead.py
-
talib安装
技术指标库,调用C++的talib库,安装有点麻烦,步骤如下:
🔴 先解压下面文件到
C:\ta-libta-lib-0.4.0-msvc.zip
🟢 安装C++编译包
vc_redist.x64.exe
🟡 安装talib
Ctrl+F 找到对应版本的的ta-lib包,下载到本地,pip安装
https://www.lfd.uci.edu/~gohlke/pythonlibs/
pip install TA_Lib-0.4.17-cp37-cp37m-win_amd64.whl
# %% 引入包
import pandas as pd
import math
import matplotlib.pyplot as plt
import talib # http://mrjbq7.github.io/ta-lib/doc_index.html
import numpy as np
from sqlalchemy import create_engine
from hyperopt import tpe, hp, fmin, STATUS_OK, Trials
from hyperopt.pyll.base import scope
import importlib
import warningswarnings.filterwarnings('ignore')plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False# %% 自定义函数def setpos(pos, *args):HQDf = args[1]idx = args[2]HQDf.loc[idx, 'pos'] = posdef CalculateResult(HQDf):def get_max_drawdown(array):array = pd.Series(array)cummax = array.cummax()return array / cummax - 1# HQDf = HQDf.fillna(method='ffill')HQDf = HQDf.fillna(0)HQDf['base_balance'] = HQDf.close / HQDf.close[0] # 基准净值HQDf['chg'] = HQDf.close.pct_change() # 单日涨跌幅# 计算策略净值HQDf['strategy_balance'] = 1.0for i in range(0, len(HQDf)):if i > 0:HQDf.loc[HQDf.index[i], 'strategy_balance'] = HQDf.iloc[i - 1]['strategy_balance'] * (1. + HQDf.iloc[i]['chg'] * HQDf.iloc[i - 1]['pos'])HQDf['drawdown'] = get_max_drawdown(HQDf['strategy_balance']) # 回撤StatDf = {}StatDf['MaxDrawDown'] = min(HQDf['drawdown']) # 最大回撤StatDf['return'] = HQDf['strategy_balance'][-1] - 1 # 区间收益# 计算年化收益years = (HQDf.index[-1] - HQDf.index[0]).days / 365if years <= 1:StatDf['yearReturn'] = StatDf['return'] / yearselse:StatDf['yearReturn'] = (HQDf['strategy_balance'][-1] / 1) ** (1 / years) - 1StatDf['return/maxdrawdown'] = -1 * StatDf['return'] / StatDf['MaxDrawDown']# 计算夏普比x = HQDf["strategy_balance"] / HQDf["strategy_balance"].shift(1)x[x <= 0] = np.nanHQDf["return"] = np.log(x).fillna(0)daily_return = HQDf["return"].mean() * 100return_std = HQDf["return"].std() * 100daily_risk_free = 0.015 / np.sqrt(240)StatDf['sharpe_ratio'] = (daily_return - daily_risk_free) / return_std * np.sqrt(240)# HQDf = HQDf.dropna()return HQDf, StatDfdef plotResult(HQDf):fig, axes = plt.subplots(4, 1, figsize=(16, 12))HQDf.loc[:, ['base_balance', 'strategy_balance']].plot(ax=axes[0], title='净值曲线')HQDf.loc[:, ['drawdown']].plot(ax=axes[1], title='回撤', kind='area')HQDf.loc[:, ['pos']].plot(ax=axes[2], title='仓位', kind='area', stacked=False)HQDf['empty'] = HQDf.close[HQDf.pos == 0]HQDf['long'] = HQDf.close[HQDf.pos > 0]HQDf['short'] = HQDf.close[HQDf.pos < 0]HQDf.loc[:, ['long', 'short', 'empty']].plot(ax=axes[3], title='开平仓点位', color=["r", "g", "grey"])plt.show()def CTA(HQDf, loadBars, func, **kwargs):HQDf['pos'] = np.nan# for idx, hq in tqdm(HQDf.iterrows()):for idx, hq in HQDf.iterrows():TradedHQDf = HQDf[:idx]idx_num = TradedHQDf.shape[0]if idx_num < loadBars:continuefunc(TradedHQDf, HQDf, idx, idx_num, **kwargs)HQDf[:idx].pos = HQDf[:idx].pos.fillna(method='ffill')HQDf, StatDf = CalculateResult(HQDf)# print(StatDf)return HQDf, StatDfdef hypeFun(space, target):"""贝叶斯超参数优化:param space: 参数空间:param target: 优化目标:return:"""def hyperparameter_tuning(params):HQDf, StatDf = CTA(**params)return {"loss": -StatDf[target], "status": STATUS_OK}trials = Trials()best = fmin(fn=hyperparameter_tuning,space=space,algo=tpe.suggest,max_evals=100,trials=trials)print("Best: {}".format(best))return trials, bestfrom StupidHead import *
编写策略
- 策略逻辑
TradedHQDf- 历史行情
DataFrame - 函数内第一行
TradedHQDf = args[0]
- 历史行情
- 开多、开空、空仓通过
setpos函数即可:- setpos(1, *args) ——满仓开多
- setpos(-1, *args) ——满仓开空
- setpos(0, *args) ——空仓
- setpos(0.5, *args) ——50%仓位开多
- setpos(-0.5, *args) ——50%仓位开空
def doubleMa(*args, **kwargs):TradedHQDf = args[0]fast_ma = talib.SMA(TradedHQDf.close, timeperiod=kwargs['fast'])fast_ma0 = fast_ma[-1]fast_ma1 = fast_ma[-2]slow_ma = talib.SMA(TradedHQDf.close, timeperiod=kwargs['slow'])slow_ma0 = slow_ma[-1]slow_ma1 = slow_ma[-2]cross_over = fast_ma0 > slow_ma0 and fast_ma1 < slow_ma1cross_below = fast_ma0 < slow_ma0 and fast_ma1 > slow_ma1if cross_over:setpos(1, *args)elif cross_below:setpos(-1, *args)
回测策略
T888_1d.csv
T888_15m.csv
from stupids.StupidHead import *def doubleMa(*args, **kwargs):TradedHQDf = args[0]fast_ma = talib.SMA(TradedHQDf.close, timeperiod=kwargs['fast'])fast_ma0 = fast_ma[-1]fast_ma1 = fast_ma[-2]slow_ma = talib.SMA(TradedHQDf.close, timeperiod=kwargs['slow'])slow_ma0 = slow_ma[-1]slow_ma1 = slow_ma[-2]cross_over = fast_ma0 > slow_ma0 and fast_ma1 < slow_ma1cross_below = fast_ma0 < slow_ma0 and fast_ma1 > slow_ma1if cross_over:setpos(1, *args)elif cross_below:setpos(-1, *args)if __name__ == '__main__':HQDf = pd.read_csv('data\T888_1d.csv', index_col='date')HQDf.index = pd.to_datetime(HQDf.index)ctaParas = {'fast': 5, 'slow': 10}ResultTSDf, StatDf = CTA(HQDf, 30, doubleMa, **ctaParas)plotResult(ResultTSDf)参数优化
📌采用机器学习中贝叶斯超参数优化方法,以极短的时间寻找出最优参数
# sapce 是参数空间,定义贝叶斯搜索的空间
# func 技术指标名称
# fast slow 为技术指标的参数范围
space = {"HQDf": HQDf,"loadBars": 40,"func": doubleMa,"fast": hp.quniform("fast", 3, 30, 1),"slow": hp.quniform("slow", 5, 40, 1),}# 调用贝叶斯搜索,第一个参数为参数空间,第二个为优化目标(求解优化目标极值)
trials, best = hypeFun(space, 'sharpe_ratio')BestResultTSDf, BestStatDf = CTA(HQDf, 30, doubleMa, **best)
plotResult(BestResultTSDf)框架原理和细节
more
- 修改
setpos(pos, *args)+行情订阅,可以直接变为实盘 - 可以添加组合回测功能
- 完善代码可读性
相关文章:
【量化课程】07_量化回测
文章目录 7.1 pandas计算策略评估指标数据准备净值曲线年化收益率波动率最大回撤Alpha系数和Beta系数夏普比率信息比率 7.2 聚宽平台量化回测实践平台介绍策略实现 7.3 Backtrader平台量化回测实践Backtrader简介Backtrader量化回测框架实践 7.4 BigQuant量化框架实战BigQuant简…...

竞赛项目 深度学习花卉识别 - python 机器视觉 opencv
文章目录 0 前言1 项目背景2 花卉识别的基本原理3 算法实现3.1 预处理3.2 特征提取和选择3.3 分类器设计和决策3.4 卷积神经网络基本原理 4 算法实现4.1 花卉图像数据4.2 模块组成 5 项目执行结果6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 &a…...
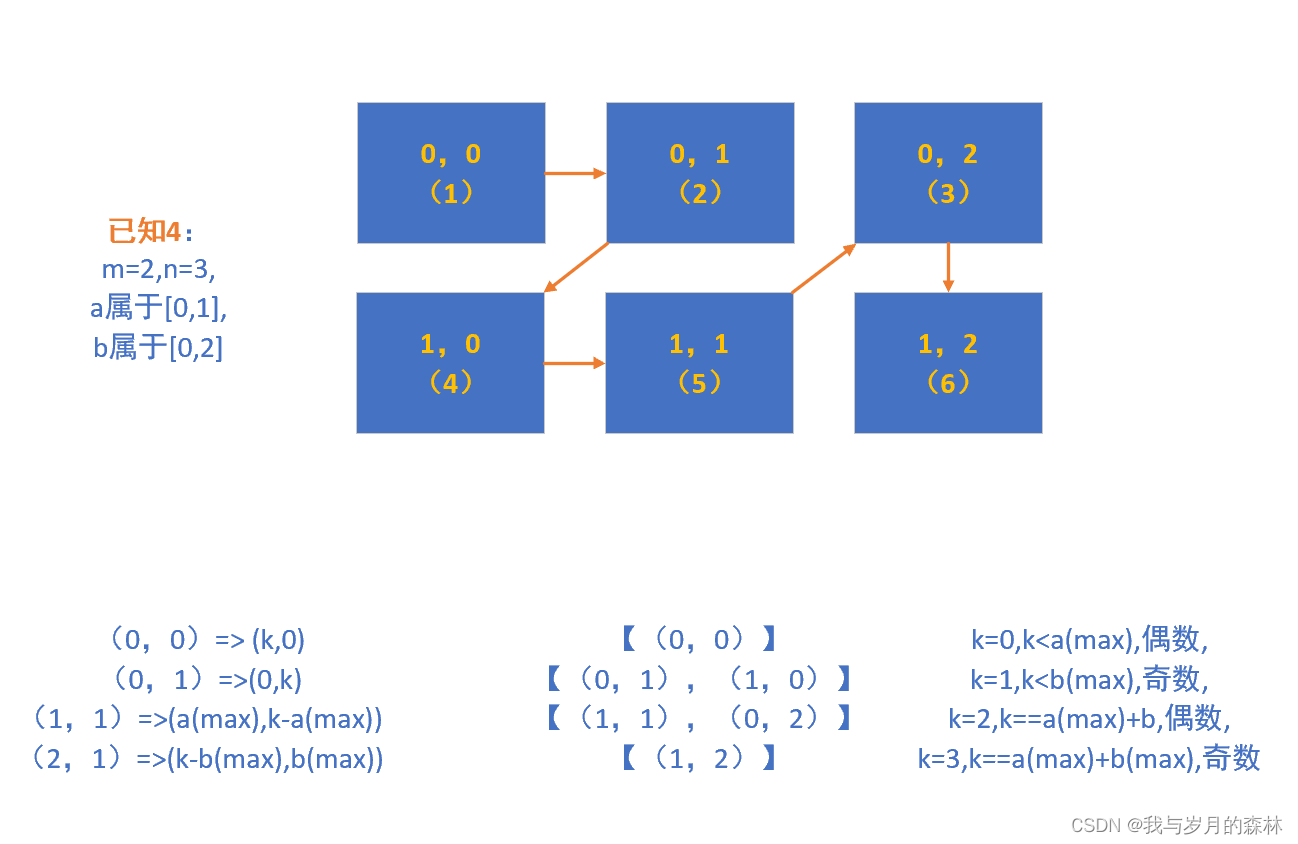
用对角线去遍历矩阵
声明 该系列文章仅仅展示个人的解题思路和分析过程,并非一定是优质题解,重要的是通过分析和解决问题能让我们逐渐熟练和成长,从新手到大佬离不开一个磨练的过程,加油! 原题链接 用对角线遍历矩阵https://leetcode.c…...
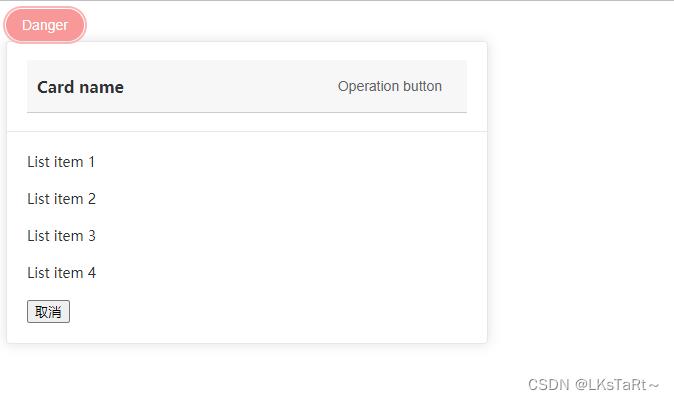
【vue】点击按钮弹出卡片,点击卡片中的取消按钮取消弹出的卡片(附代码)
实现思路: 在按钮上绑定一个点击事件,默认是true;在export default { }中注册变量给卡片标签用v-if判断是否要显示卡片,ture则显示;在卡片里面写好你想要展示的数据;给卡片添加一个取消按钮,绑…...

【K8S】pod 基础概念讲解
目录 Pod基础概念:在Kubrenetes集群中Pod有如下两种使用方式:pause容器使得Pod中的所有容器可以共享两种资源:网络和存储。总结:kubernetes中的pause容器主要为每个容器提供以下功能:Kubernetes设计这样的Pod概念和特殊…...
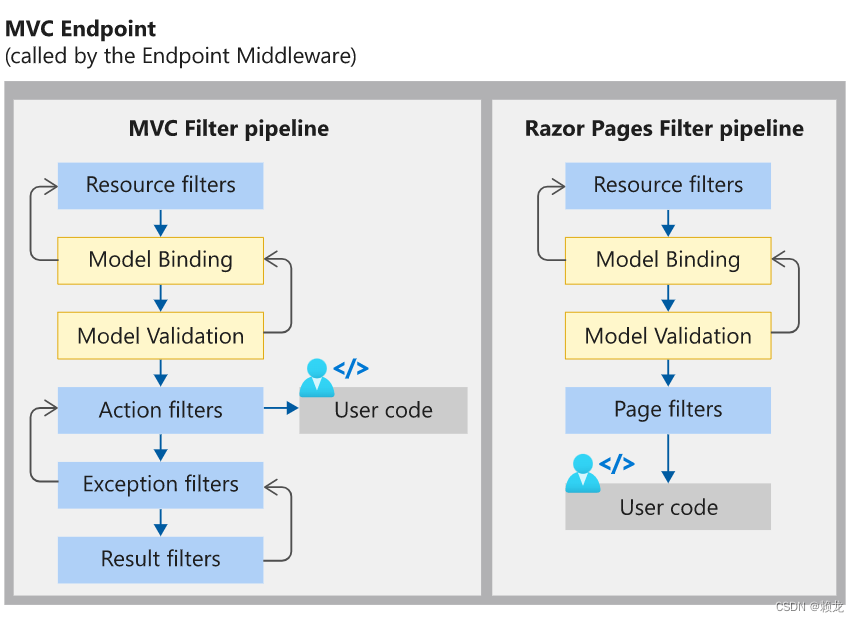
ASP.NET Core中间件记录管道图和内置中间件
管道记录 下图显示了 ASP.NET Core MVC 和 Razor Pages 应用程序的完整请求处理管道 中间件组件在文件中添加的顺序Program.cs定义了请求时调用中间件组件的顺序以及响应的相反顺序。该顺序对于安全性、性能和功能至关重要。 内置中间件记录 内置中间件原文翻译MiddlewareDe…...

[系统安全] 五十二.DataCon竞赛 (1)2020年Coremail钓鱼邮件识别及分类详解
您可能之前看到过我写的类似文章,为什么还要重复撰写呢?只是想更好地帮助初学者了解病毒逆向分析和系统安全,更加成体系且不破坏之前的系列。因此,我重新开设了这个专栏,准备系统整理和深入学习系统安全、逆向分析和恶意代码检测,“系统安全”系列文章会更加聚焦,更加系…...

Android学习之路(3) 布局
线性布局LinearLayout 前几个小节的例程中,XML文件用到了LinearLayout布局,它的学名为线性布局。顾名思义,线性布局 像是用一根线把它的内部视图串起来,故而内部视图之间的排列顺序是固定的,要么从左到右排列…...
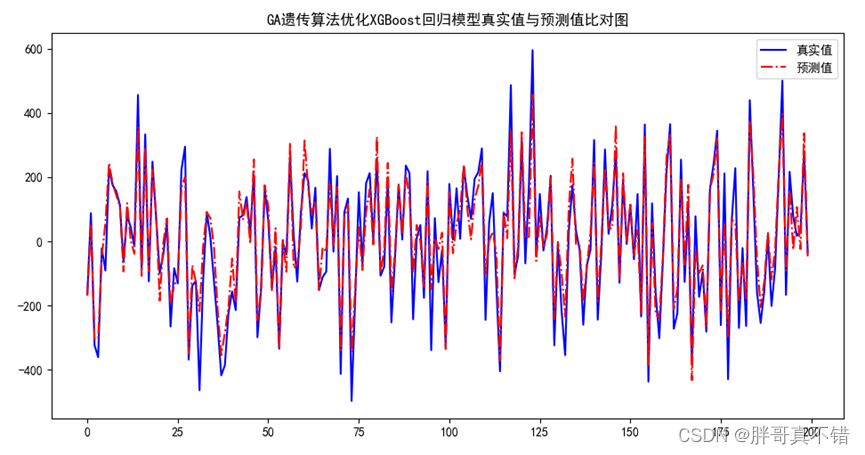
Python实现GA遗传算法优化XGBoost回归模型(XGBRegressor算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 遗传算法(Genetic Algorithm,GA)最早是由美国的 John holland于20世…...
C#软件外包开发流程
C# 是一种由微软开发的多范式编程语言,常用于开发各种类型的应用程序,从桌面应用程序到移动应用程序和Web应用程序。下面和大家分享 C# 编程学习流程,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司&#…...

队列的实现
1.队列的概念 队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out)。 入队列:进行插入操作的一端称为队尾 出队列:进行删除操作的一端称为队头 2.队列…...

Node + Express 后台开发 —— 起步
Node Express 后台开发 —— 起步 前面陆续学习了一下 node、npm、模块,也稍尝试 Express,感觉得换一个思路加快进行。 比如笔者对前端的开发已较熟悉,如果领导给一个内部小网站的需求,难道说你得给我配置一个后端?…...
Python学习笔记第五十七天(Pandas 数据清洗)
Python学习笔记第五十七天 Pandas 数据清洗Pandas 清洗空值isnull() Pandas替换单元格mean()median()mode() Pandas 清洗格式错误数据Pandas 清洗错误数据Pandas 清洗重复数据duplicated()drop_duplicates() 后记 Pandas 数据清洗 数据清洗是对一些没有用的数据进行处理的过程…...
Elasticsearch的一些基本概念
文章目录 基本概念:文档和索引JSON文档元数据索引REST API 节点和集群节点Master eligible节点和Master节点Data Node 和 Coordinating Node其它节点 分片(Primary Shard & Replica Shard)分片的设定操作命令 基本概念:文档和索引 Elasticsearch是面…...

Guitar Pro8专业版吉他学习、绘谱、创作软件
Guitar Pro 8 专业版更强大!更优雅!更完美!Guitar Pro 8.0 五年磨一剑!多达30项功能优化!Guitar Pro8 版本一共更新近30项功能,令吉他打谱更出色!Guitar Pro8 是自2017年4月发布7.0之后发布的最…...
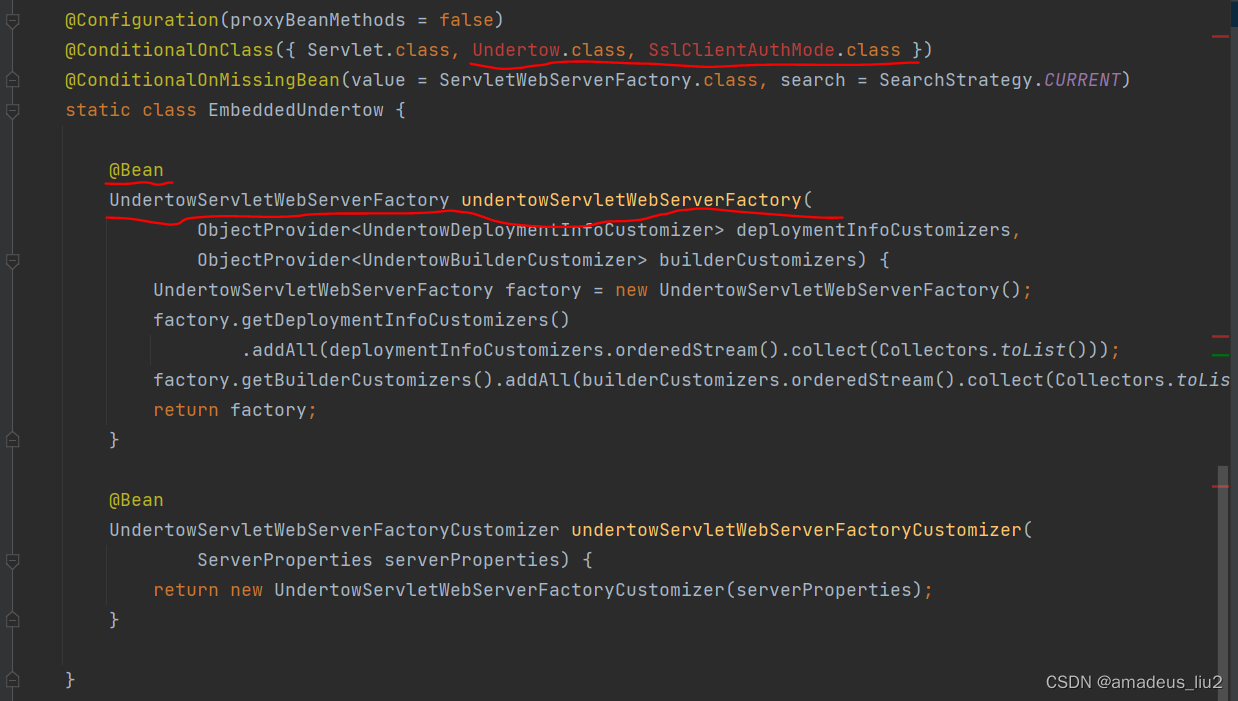
SpringBoot复习(39)Servlet容器的自动配置原理
Servlet容器自动配置类为ServletWebServerFactoryAutoConfiguration 可以看到通过Import注解导入了三个配置类: 通过这个这三个配置类可以看出,它们都使用了ConditionalOnClass注解,当类路径存在tomcat相关的类时,会配置一个T…...

【前端 | CSS】盒模型clientWidth、clientHeight、offsetWidht、offsetHeight
图 先看一个例子 html <div class"container"><div class"item">内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容</div> </…...

Django 高级指南:深入理解和使用类视图和中间件
Django 是一款强大的 Python Web 框架,它提供了一套完整的解决方案,让我们能够用 Python 语言快速开发和部署复杂的 Web 应用。在本文中,我们将会深入研究 Django 中的两个高级特性:类视图(Class-Based Viewsÿ…...

《C语言深度解剖》.pdf
🐇 🔥博客主页: 云曦 📋系列专栏:深入理解C语言 💨吾生也有涯,而知也无涯 💛 感谢大家👍点赞 😋关注📝评论 C语言深度解剖.pdf 提取码:yunx...
【小梦C嘎嘎——启航篇】string介绍以及日常使用的接口演示
【小梦C嘎嘎——启航篇】string 使用😎 前言🙌C语言中的字符串标准库中的string类string 比较常使用的接口对上述函数和其他函数的测试代码演示: 总结撒花💞 😎博客昵称:博客小梦 😊最喜欢的座右…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...