【Bert101】最先进的 NLP 模型解释【01/4】

0 什么是伯特?
BERT是来自【Bidirectional Encoder Representations from Transformers】变压器的双向编码器表示的缩写,是用于自然语言处理的机器学习(ML)模型。它由Google AI Language的研究人员于2018年开发,可作为瑞士军刀解决方案,用于11 +最常见的语言任务,例如情感分析和命名实体识别。
从历史上看,语言对计算机来说很难“理解”。当然,计算机可以收集、存储和读取文本输入,但它们缺乏基本的语言上下文。
因此,自然语言处理(NLP)随之而来:人工智能领域,旨在让计算机阅读,分析,解释并从文本和口语中获取含义。这种做法结合了语言学、统计学和机器学习,以帮助计算机“理解”人类语言。
传统上,单个NLP任务由为每个特定任务创建的单个模型来解决。也就是说,直到——伯特!
BERT通过解决11 +最常见的NLP任务(并且比以前的模型更好)彻底改变了NLP空间,使其成为所有NLP交易的杰克。在本指南中,您将了解BERT是什么,为什么它不同,以及如何开始使用BERT:
- 伯特的用途是什么?
- 伯特是如何工作的?
- BERT模型大小和架构
- BERT在公共语言任务上的表现
- 深度学习对环境的影响
- BERT的开源力量
- 如何开始使用伯特
- 伯特常见问题
- 结论
让我们开始吧!🚀
1. 伯特的用途是什么?
BERT可用于各种语言任务:
- 可以确定电影评论的正面或负面程度。(情绪分析)
- Helps chatbots answer your questions. (Question answering)
- Predicts your text when writing an email (Gmail). (Text prediction)
- 只需几句话就可以写一篇关于任何主题的文章。(文本生成)
- 可以快速总结长期法律合同。(摘要)
- 可以根据周围的文本区分具有多种含义的单词(如“银行”)。(多义性分辨率)
还有更多的语言/NLP任务+每个任务背后的更多细节。
有趣的事实:您几乎每天都与NLP(可能还有BERT)互动!
NLP是谷歌翻译,语音助手(Alexa,Siri等),聊天机器人,谷歌搜索,语音操作GPS等的背后。
1.1 BERT的例子
自 2020 年 <> 月以来,BERT 帮助 Google 更好地显示几乎所有搜索的(英语)结果。
以下是BERT如何帮助Google更好地了解特定搜索的示例,例如:
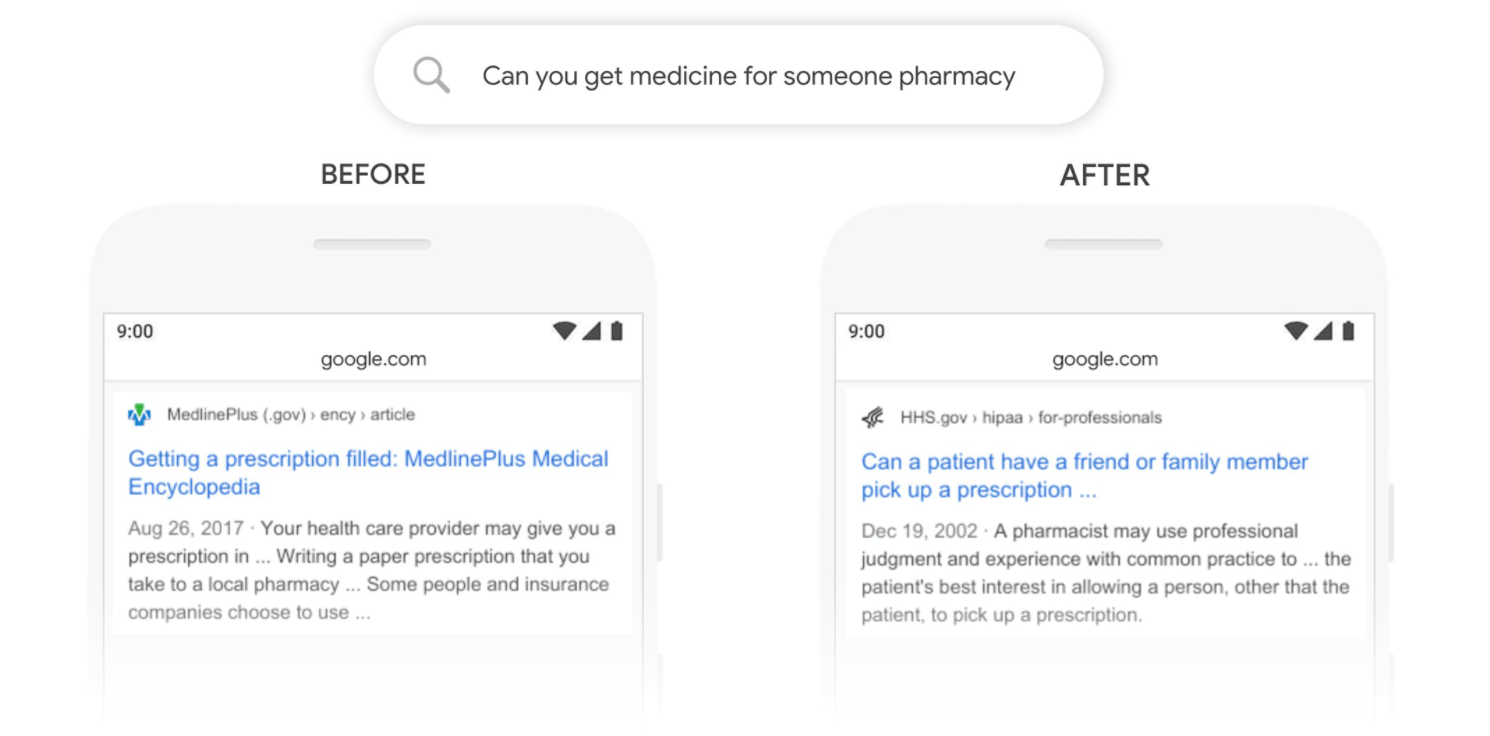
在BERT之前,谷歌浮出水面,提供有关填写处方的信息。
后伯特谷歌明白“为某人”与为其他人开处方有关,搜索结果现在有助于回答这个问题。
2. 伯特如何工作?
BERT通过利用以下内容来工作:
2.1 大量的训练数据
3亿字的庞大数据集为BERT的持续成功做出了贡献。
BERT在维基百科(~2.5B字)和谷歌的BooksCorpus(~800M字)上进行了专门训练。这些大型信息数据集不仅有助于BERT对英语的深入了解,而且有助于深入了解我们的世界!🚀
在这么大的数据集上进行训练需要很长时间。由于新颖的变压器架构,BERT的培训成为可能,并通过使用TPU(张量处理单元 - Google专门为大型ML模型构建的定制电路)来加速。—64 名 TPU 在 4 天内训练了 BERT。
注意:为了在较小的计算环境(如手机和个人计算机)中使用BERT,对较小的BERT模型的需求正在增加。23 年 2020 月发布了 60 款较小的 BERT 车型。DistilBERT提供了BERT的较轻版本;运行速度提高 95%,同时保持 BERT 性能的 <>% 以上。
2.2 什么是屏蔽语言模型?
MLM通过屏蔽(隐藏)句子中的单词并迫使BERT双向使用覆盖单词两侧的单词来预测被屏蔽的单词,从而实现/强制从文本中进行双向学习。这是以前从未做过的!
有趣的事实:作为人类,我们自然会这样做!
屏蔽语言模型示例:
想象一下,你的朋友在冰川国家公园露营时打电话给你,他们的服务开始中断。在呼叫断开之前,您听到的最后一件事是:
朋友:“叮!我出去钓鱼了,一条巨大的鳟鱼只是[空白]我的线!
你能猜出你朋友说了什么吗?
您自然能够通过将缺失单词前后的单词双向视为上下文线索来预测缺失的单词(除了您对钓鱼工作原理的历史知识)。你猜到你的朋友说,“破产”了吗?这也是我们预测的,但即使是我们人类也容易出错。
注意:这就是为什么您经常会看到“人类绩效”与语言模型的性能分数进行比较的原因。是的,像BERT这样的新模型可以比人类更准确!🤯
您为填写上面的[空白]单词所做的双向方法类似于BERT获得最先进准确性的方式。在训练过程中随机隐藏了15%的标记化单词,BERT的工作是正确预测隐藏的单词。因此,直接向模型教授有关英语(以及我们使用的单词)的知识。这不是很整洁吗?
玩弄BERT的掩蔽预测:
[MASK] 有趣的事实:掩蔽已经存在了很长时间 - 1953年关于完形填空程序(或“掩蔽”)的论文。
2.3 什么是下一句预测?
NSP(下一句预测)用于通过预测给定句子是否遵循前一个句子来帮助BERT了解句子之间的关系。
下一句预测示例:
- 保罗去购物了。他买了一件新衬衫。(正确的句子对)
- 雷蒙娜煮咖啡。香草冰淇淋蛋筒出售。(不正确的句子对)
在训练中,50%的正确句子对与50%的随机句子对混合在一起,以帮助BERT提高下一个句子预测的准确性。
有趣的事实:BERT同时接受传销(50%)和NSP(50%)的培训。
2.4 变压器
转换器架构可以非常高效地并行化 ML 训练。因此,大规模并行化使得在相对较短的时间内在大量数据上训练BERT变得可行。
变形金刚使用注意力机制来观察单词之间的关系。最初在2017年流行的Attention Is All You Need论文中提出的一个概念引发了世界各地NLP模型中变形金刚的使用。
自 2017 年推出以来,变形金刚已迅速成为处理自然语言处理、语音识别和计算机视觉等许多领域任务的最先进方法。简而言之,如果你正在做深度学习,那么你需要变形金刚!
Lewis Tunstall,Hugging Face ML工程师,《变形金刚自然语言处理》作者
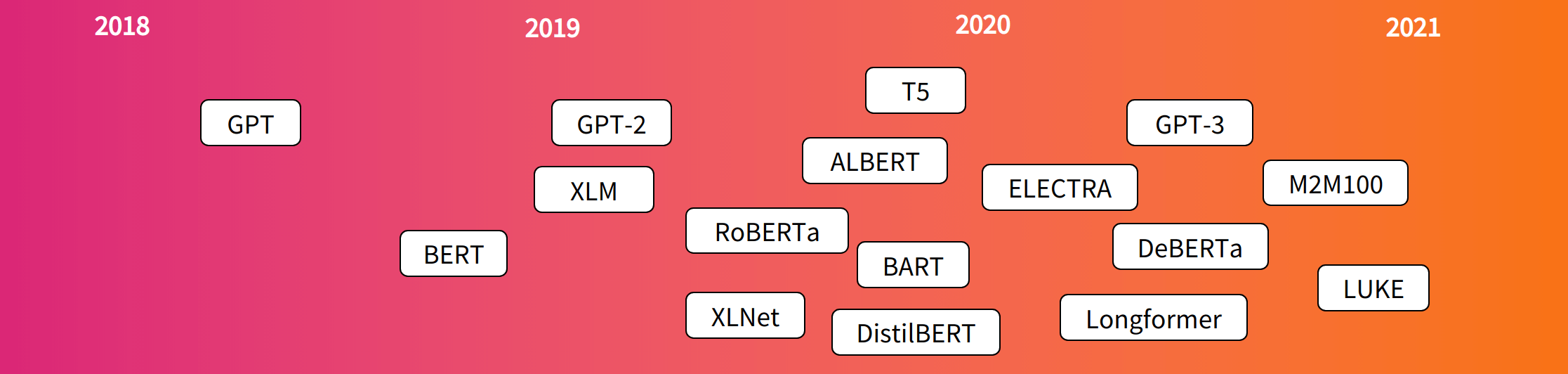
流行的变压器模型发布时间表:
2.4.1 变压器如何工作?
变形金刚通过利用注意力来工作,注意力是一种强大的深度学习算法,首次出现在计算机视觉模型中。
—与我们人类通过注意力处理信息的方式并没有太大区别。我们非常善于忘记/忽略平凡的日常输入,这些输入不会构成威胁或需要我们做出回应。例如,你还记得上周二回家时看到和听到的一切吗?当然不是!我们大脑的记忆是有限而有价值的。我们的回忆得益于我们忘记琐碎输入的能力。
同样,机器学习模型需要学习如何只关注重要的事情,而不是浪费计算资源来处理不相关的信息。变压器产生差分权重,指示句子中的哪些单词对进一步处理最关键。
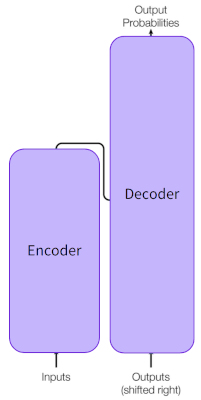
变压器通过变压器层堆栈(通常称为编码器)连续处理输入来实现这一点。如有必要,可以使用另一个变压器层堆栈 - 解码器 - 来预测目标输出。—但是,BERT不使用解码器。变压器特别适合无监督学习,因为它们可以有效地处理数百万个数据点。
有趣的事实:自 2011 年以来,Google 一直在使用您的 reCAPTCHA 选择来标记训练数据。整个 Google 图书档案和《纽约时报》目录中的 13 万篇文章已通过输入 reCAPTCHA 文本的人进行转录/数字化。现在,reCAPTCHA要求我们标记Google街景图像,车辆,红绿灯,飞机等。如果谷歌让我们意识到我们参与了这项工作(因为训练数据可能具有未来的商业意图),那就太好了,但我跑题了。
要了解有关变形金刚的更多信息,请查看我们的拥抱面变压器课程。
3. BERT模型大小和架构
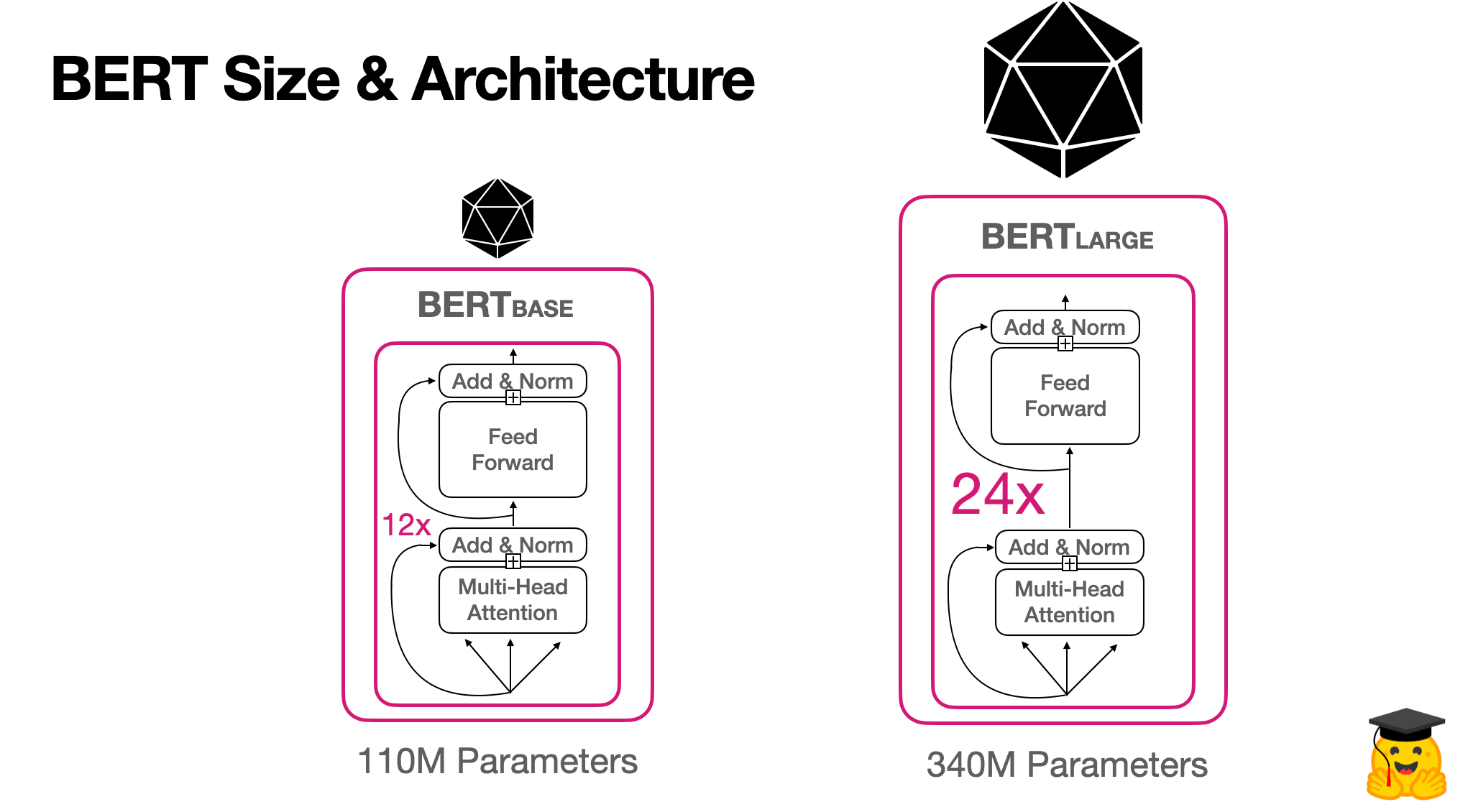
让我们分解一下两个原始BERT模型的架构:
ML 架构术语表:
| 机器学习架构部件 | 定义 |
|---|---|
| 参数: | 可用于模型的可学习变量/值的数量。 |
| 变压器层: | 变压器块的数量。转换器块将一系列单词表示转换为一系列上下文化单词(编号表示)。 |
| 隐藏大小: | 位于输入和输出之间的数学函数层,用于分配权重(单词)以产生所需的结果。 |
| 注意头: | 变压器块的大小。 |
| 加工: | 用于训练模型的处理单元的类型。 |
| 培训时间: | 训练模型所花费的时间。 |
以下是BERTbase和BERTlarge拥有的上述ML架构部分的数量:
| 变压器层 | 隐藏尺寸 | 注意头 | 参数 | 加工 | 培训时长 | |
|---|---|---|---|---|---|---|
| 伯特基地 | 12 | 768 | 12 | 110米 | 4 个热塑性聚氨酯 | 4天 |
| 伯特大 | 24 | 1024 | 16 | 340米 | 16 个热塑性聚氨酯 | 4天 |
让我们来看看BERTlarge的附加层,注意头和参数如何提高其在NLP任务中的性能。
4. BERT在公共语言任务上的表现
BERT 在 11 个常见的 NLP 任务上成功实现了最先进的准确性,优于以前的顶级 NLP 模型,并且是第一个超越人类的模型! 但是,如何衡量这些成就?
自然语言处理评估方法:
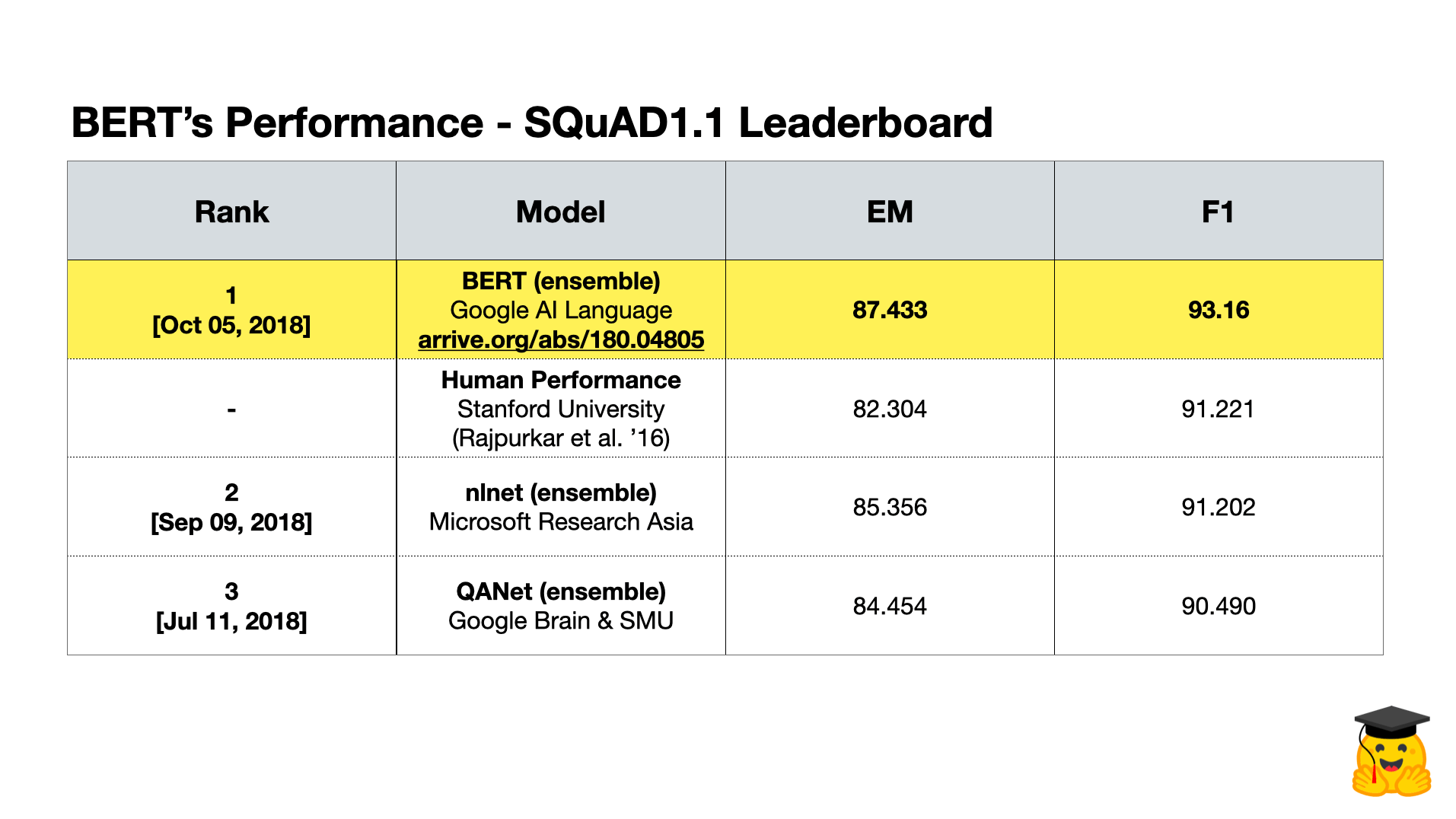
4.1 SQuAD v1.1 & v2.0
SQuAD(斯坦福问答数据集)是一个包含大约 108k 个问题的阅读理解数据集,可以通过维基百科文本的相应段落回答。BERT在这种评估方法上的表现是超越以前最先进的模型和人类水平表现的巨大成就:
4.2 SWAG 评估法
SWAG(Situations With Adversarial Generations)是一个有趣的评估,因为它检测模型推断常识的能力!它通过一个关于常识情况的 113k 多项选择题的大规模数据集来做到这一点。这些问题是从视频场景/情况中转录而来的,SWAG 在下一个场景中为模型提供了四种可能的结果。然后,该模型在预测正确答案方面做到最好。
BERT的表现优于以前的顶级模型,包括人类水平的表现:

4.3 格鲁基准
GLUE(通用语言理解评估)基准是一组资源,用于训练、测量和分析彼此比较的语言模型。这些资源由九个“困难”的任务组成,旨在测试NLP模型的理解。以下是其中每个任务的摘要:

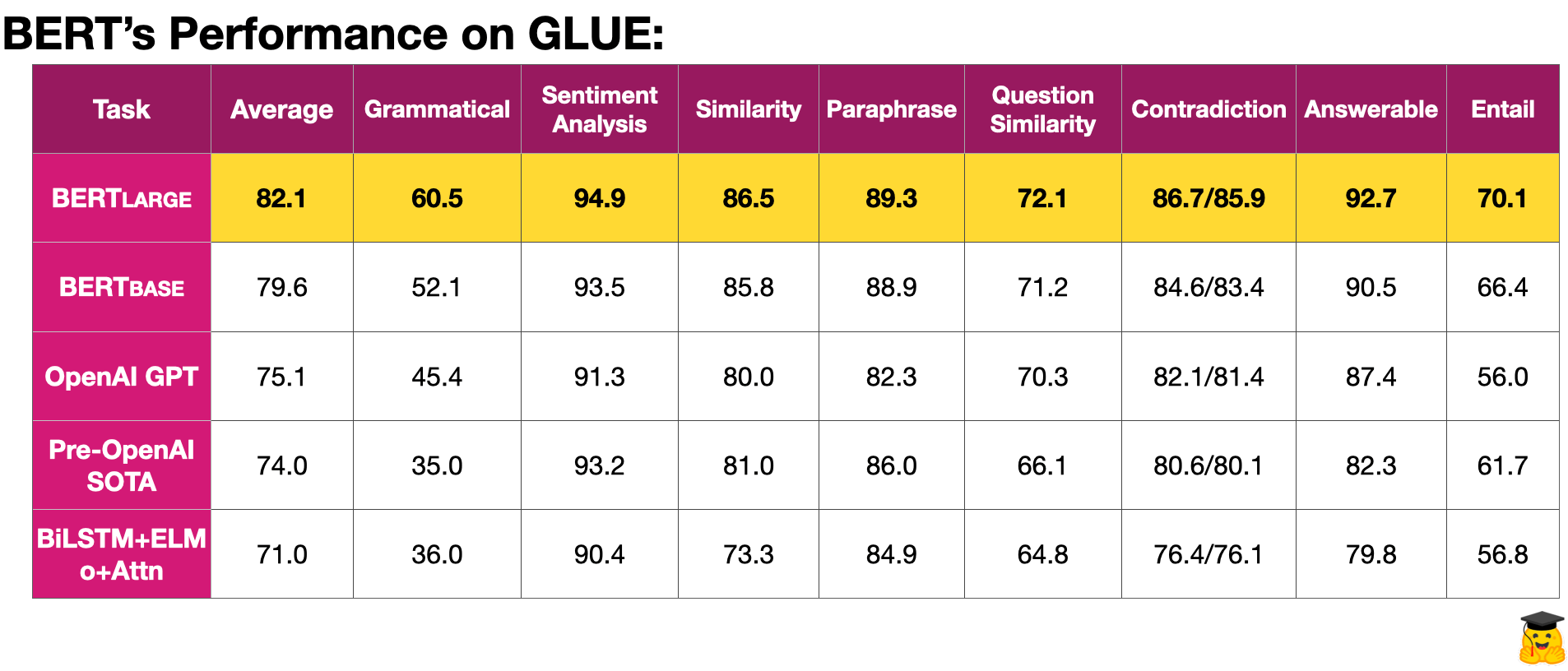
虽然其中一些任务可能看起来无关紧要和平庸,但重要的是要注意,这些评估方法在指示哪些模型最适合您的下一个 NLP 应用程序方面非常强大。
获得这种机芯的性能并非没有后果。接下来,让我们了解机器学习对环境的影响。
5. 深度学习对环境的影响
大型机器学习模型需要大量数据,这在时间和计算资源方面都很昂贵。
这些模型还对环境有影响:
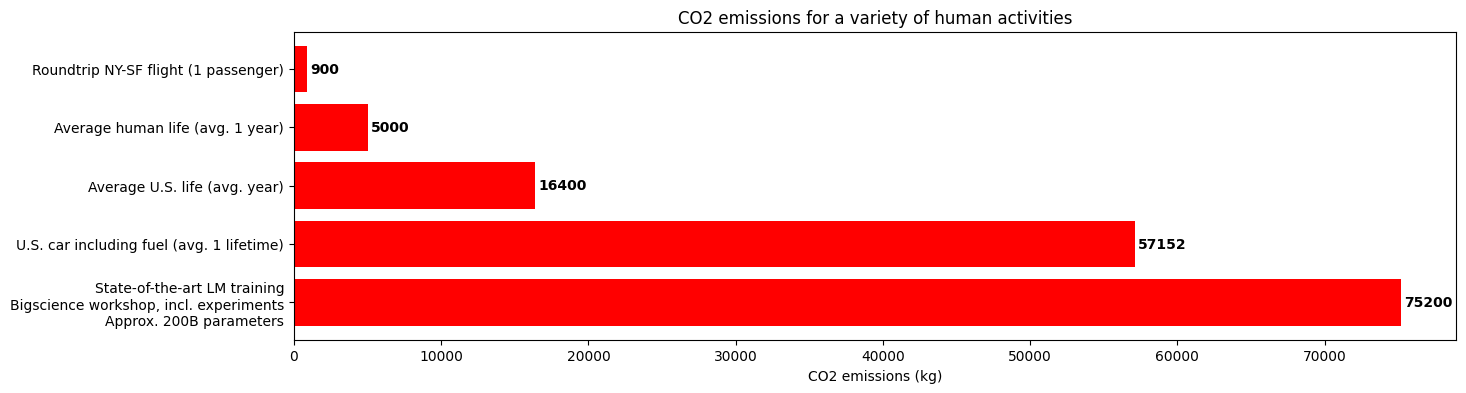
机器学习对环境的影响是我们相信通过开源使机器学习世界民主化的众多原因之一!共享大型预训练语言模型对于降低社区驱动工作的总体计算成本和碳足迹至关重要。
6. BERT的开源力量
与GPT-3等其他大型学习模型不同,BERT的源代码是可公开访问的(在Github上查看BERT的代码),从而使BERT在世界各地得到更广泛的使用。这是一个改变游戏规则的人!
开发人员现在能够快速启动并运行像BERT这样的最先进的模型,而无需花费大量时间和金钱。🤯
相反,开发人员可以将精力集中在微调BERT上,以根据其独特的任务自定义模型的性能。
重要的是要注意,如果您不想微调BERT,目前有数千个开源和免费的预训练BERT模型可用于特定用例。
针对特定任务预先训练的BERT模型:
- 推特情绪分析
- 日文文本分析
- 情绪分类器(英语 - 愤怒、恐惧、喜悦等)
- 临床笔记分析
- 语音到文本翻译
- 有害评论检测
您还可以在拥抱面部集线器上找到数百个预先训练的开源变压器模型。
7. 如何开始使用伯特
我们创建了这个笔记本,所以你可以通过谷歌Colab中的这个简单的教程来尝试BERT。打开笔记本或将以下代码添加到你自己的笔记本中。专业提示:使用 (Shift + 单击) 运行代码单元格。
注意:Hugging Face 的管道类使得只需一行代码即可非常轻松地引入像转换器这样的开源 ML 模型。
7.1 安装变压器
首先,让我们通过以下代码安装转换器:
!pip install transformers
7.2 试用Bert
随意将下面的句子换成您自己的句子。但是,将[MASK]留在某个地方,以便BERT预测丢失的单词
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("Artificial Intelligence [MASK] take over the world.")
当您运行上面的代码时,您应该看到如下所示的输出:
[{'score': 0.3182411789894104,'sequence': 'artificial intelligence can take over the world.','token': 2064,'token_str': 'can'},{'score': 0.18299679458141327,'sequence': 'artificial intelligence will take over the world.','token': 2097,'token_str': 'will'},{'score': 0.05600147321820259,'sequence': 'artificial intelligence to take over the world.','token': 2000,'token_str': 'to'},{'score': 0.04519503191113472,'sequence': 'artificial intelligences take over the world.','token': 2015,'token_str': '##s'},{'score': 0.045153118669986725,'sequence': 'artificial intelligence would take over the world.','token': 2052,'token_str': 'would'}]
有点吓人吧?🙃
7.3 注意模型偏差
让我们看看BERT为“男人”建议的工作:
unmasker("The man worked as a [MASK].")
运行上述代码时,您应该看到如下所示的输出:
[{'score': 0.09747546911239624,'sequence': 'the man worked as a carpenter.','token': 10533,'token_str': 'carpenter'},{'score': 0.052383411675691605,'sequence': 'the man worked as a waiter.','token': 15610,'token_str': 'waiter'},{'score': 0.04962698742747307,'sequence': 'the man worked as a barber.','token': 13362,'token_str': 'barber'},{'score': 0.037886083126068115,'sequence': 'the man worked as a mechanic.','token': 15893,'token_str': 'mechanic'},{'score': 0.037680838257074356,'sequence': 'the man worked as a salesman.','token': 18968,'token_str': 'salesman'}]
BERT预测该男子的工作是木匠,服务员,理发师,机械师或推销员
现在让我们看看伯特为“女人”提供哪些工作
unmasker("The woman worked as a [MASK].")
您应该会看到如下所示的输出:
[{'score': 0.21981535851955414,'sequence': 'the woman worked as a nurse.','token': 6821,'token_str': 'nurse'},{'score': 0.1597413569688797,'sequence': 'the woman worked as a waitress.','token': 13877,'token_str': 'waitress'},{'score': 0.11547300964593887,'sequence': 'the woman worked as a maid.','token': 10850,'token_str': 'maid'},{'score': 0.03796879202127457,'sequence': 'the woman worked as a prostitute.','token': 19215,'token_str': 'prostitute'},{'score': 0.030423851683735847,'sequence': 'the woman worked as a cook.','token': 5660,'token_str': 'cook'}]
BERT预测,该女性的工作是护士,女服务员,女佣,或厨师,在专业角色中表现出明显的性别偏见。
7.4 您可能喜欢的其他一些BERT笔记本:
BERT首次的可视化笔记本
训练您的分词器
+不要忘记查看拥抱面变压器课程以了解更多信息 🎉
8. Bert常见问题
BERT可以与PyTorch一起使用吗?
专业提示:Lewis Tunstall,Leandro von Werra和Thomas Wolf还写了一本书,帮助人们使用Hugging Face构建语言应用程序,名为“使用变形金刚进行自然语言处理”。
BERT可以与Tensorflow一起使用吗?
预训练BERT需要多长时间?
微调BERT需要多长时间?
是什么让伯特与众不同?
- BERT以无监督的方式对大量未标记的数据(无人工注释)进行了训练。
- 然后,从之前的预训练模型开始,对少量人工注释的数据对BERT进行训练,从而获得最先进的性能。
9. 结论
BERT是一种高度复杂和先进的语言模型,可以帮助人们自动理解语言。它实现最先进性能的能力得到了大量数据培训和利用变压器架构彻底改变NLP领域的支持。
由于BERT的开源库,以及令人难以置信的AI社区为继续改进和共享新的BERT模型所做的努力,未触及的NLP里程碑的未来看起来很光明。
相关文章:
【Bert101】最先进的 NLP 模型解释【01/4】
0 什么是伯特? BERT是来自【Bidirectional Encoder Representations from Transformers】变压器的双向编码器表示的缩写,是用于自然语言处理的机器学习(ML)模型。它由Google AI Language的研究人员于2018年开发,可作为…...
c语言经典例题讲解(输出菱形,喝汽水问题)
目录 一、输出菱形 二、喝汽水问题 方法1:一步一步来 方法二:直接套公式 一、输出菱形 输出类似于下图的菱形: 通过分析:1、先分为上下两部分输出 2.在输出前先输出空格 3.找规律进行输出 可知,可令上半部分lin…...

【Flutter】【基础】CustomPaint 绘画功能(一)
功能:CustomPaint 相当于在一个画布上面画画,可以自己绘制不同的颜色形状等 在各种widget 或者是插件不能满足到需求的时候,可以自己定义一些形状 使用实例和代码: CustomPaint: 能使你绘制的东西显示在你的ui 上面&a…...

iOS 实现图片高斯模糊效果
效果图 用到了 UIVisualEffectView 实现代码 - (UIVisualEffectView *)bgEffectView{if(!_bgEffectView){UIBlurEffect *blur [UIBlurEffect effectWithStyle:UIBlurEffectStyleLight];_bgEffectView [[UIVisualEffectView alloc] initWithEffect:blur];}return _bgEffect…...

[保研/考研机试] KY7 质因数的个数 清华大学复试上机题 C++实现
描述 求正整数N(N>1)的质因数的个数。 相同的质因数需要重复计算。如1202*2*2*3*5,共有5个质因数。 输入描述: 可能有多组测试数据,每组测试数据的输入是一个正整数N,(1<N<10^9)。 输出描述: 对于每组数…...
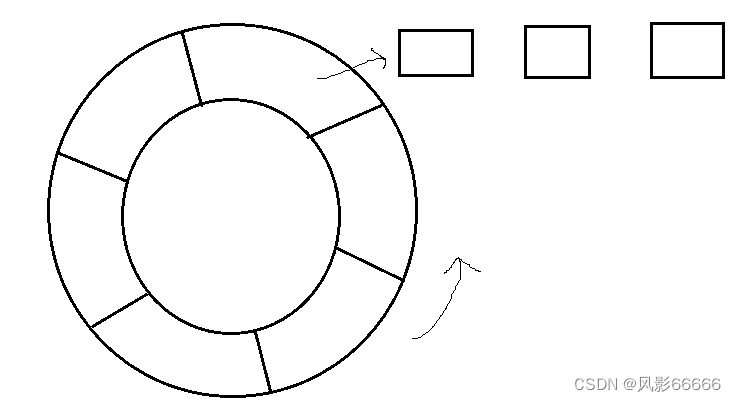
初识Redis
目录 认识Redis分布式系统Redis的特性Redis的应用场景Redis客户端Redis命令 认识Redis 上面一段话是官网给出的对Redis的介绍,in-memory data store表明Redis是在内存中存储数据的,这和我们接触的其他数据库就有很大的不同,比如MySQL…...
每天一道leetcode:115. 不同的子序列(动态规划困难)
今日份题目: 给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数。 题目数据保证答案符合 32 位带符号整数范围。 示例1 输入:s "rabbbit", t "rabbit" 输出:3 解释: 如下所…...

服务器数据恢复-RAID5多块磁盘离线导致崩溃的数据恢复案例
服务器数据恢复环境: DELL POWEREDGE某型号服务器中有一组由6块SCSI硬盘组建的RAID5阵列,LINUX REDHAT操作系统,EXT3文件系统,存放图片文件。 服务器故障&分析: 服务器raid5阵列中有一块硬盘离线,管理员…...

NO.2 MyBatis框架:创建Mapper接口和映射文件,实现基本增删改查
目录 1、Mapper接口和映射文件关系 2、Mapper接口和映射文件的命名规则 2.1 Mapper接口的命名规则 2.2 映射文件的命名规则 3、Mapper接口和映射文件的创建及增删改查的实现 3.1 Mapper接口和映射文件的创建 3.2 增删改查的实现 3.2.1表结构 3.2.2 创建表User对应的实…...

【JS】怎么提取object类的内容
需求:在网页端中通过getElementsByClassName获取到一个元素,想提取其中的数字内容做个if判断,奈何一直提取不了 开始获取元素时,以为默认就是字符类型;但使用操作字符的函数就失败,然后就考虑数据类型是不是…...
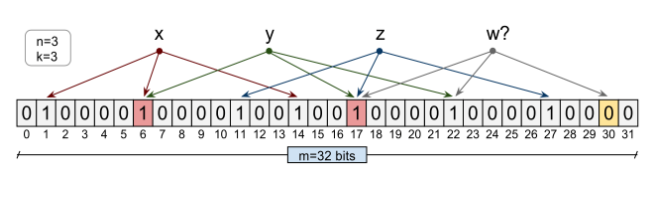
分布式系统的 38 个知识点
天天说分布式分布式,那么我们是否知道什么是分布式,分布式会遇到什么问题,有哪些理论支撑,有哪些经典的应对方案,业界是如何设计并保证分布式系统的高可用呢? 1. 架构设计 这一节将从一些经典的开源系统架…...
)
机器学习基础(二)
线性回归 误差是独立并且具有相同的分布通常认为服从均值为0方差为的高斯分布。 损失函数(loss Function)/代价函数(Cost Function) 其实两种叫法都可以,损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随…...

Java 实现Rtsp 转rtmp,hls,flv
服务支撑:FFmpeg srs(流媒体服务器) 整个流程是 FFmpeg 收流转码 推 rtmp 到流媒体服务 流媒体服务再 分发流到公网 搭建流媒体服务: 1. SRS (Simple Realtime Server) | SRS (本例子使用的是SrS 安装使用docker ) 2.GitHub - ZLMedi…...
)
机器学习基础(三)
逻辑回归 场景 垃圾邮件分类 预测肿瘤是良性还是恶性 预测某人的信用是否良好 正确率与召回率 正确率与召回率(Precision & Recall)是广泛应用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。 一般来说,正确率就是检索出来的条目有多少是正确的,召回率就…...
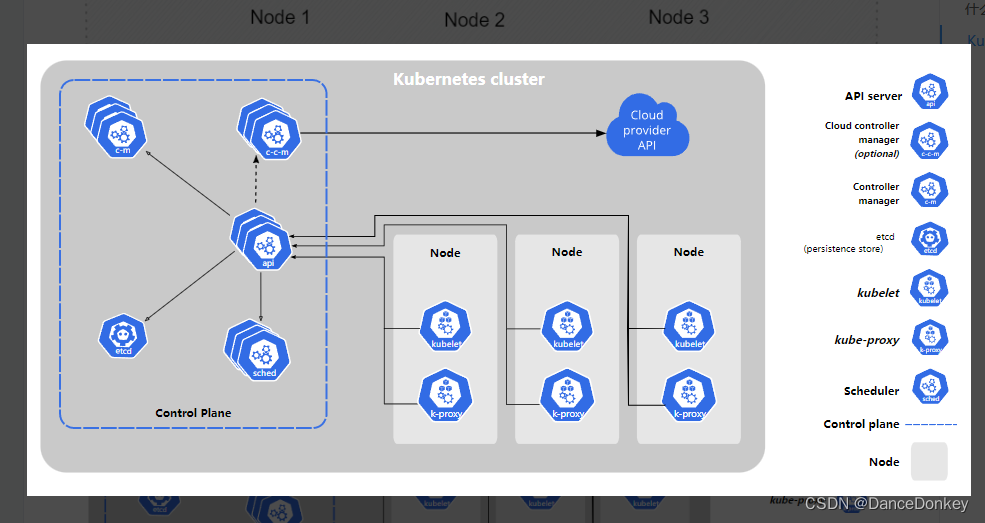
Kubeadm安装K8s集群
一、硬件环境 准备3台Linux服务器,此处用Vmware虚拟机。 主机名CPU内存k8smaster2核4Gk8snode12核4Gk8snode22核4G 二、系统前置准备 配置三台主机的hosts文件 cat << EOF > /etc/hosts 192.168.240.130 k8smaster 192.168.240.132 k8snode1 192.168.…...

【C++】开源:spdlog跨平台日志库配置使用
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍spdlog日志库配置使用。 无专精则不能成,无涉猎则不能通。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,下…...

[Azkaban] No active executors found
没有找到活动的executors,需在MySQL数据库里设置端口为12321的executors表的active为1: select * from executors;如果显示active0 则需要进行处理: update azkaban.executors set active1;当active0,更新为1时,用 n…...

无涯教程-Perl - recv函数
描述 This function receives a message on SOCKET attempting to read LENGTH bytes, placing the data read into variable SCALAR.The FLAGS argument takes the same values as the recvfrom( ) system function, on which the function is based. When communicating wit…...

算法练习-搜索 相关
文章目录 迷宫问题 迷宫问题 定义一个二维数组 m行 * n列 ,如 4 5 数组下所示: int arr[5][5] { 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, }; 它表示一个迷宫,1表示墙壁,0表示可以走的路,只…...

PyQt5控件布局管理
Qt Designer提供了四种窗口布局:Vertical Layout(垂直布局) ,Horizontal Layout(水平布局),Grid Layout(栅格布局),Form Layout(表单布局),以及一种隐藏的布局—绝对布局 一般进行布局有两种方式: 一是通…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

AI大模型应用开发全攻略:从入门到精通,掌握LLM、RAG、Agent核心技能!“
本文全面介绍了AI大模型应用开发的核心技术和实践。从大模型API交互基础,到关键参数Messages和Tools的作用,深入解析了RAG、ReAct、Agent等应用范式。文章还探讨了Fine-tuning微调和Prompt提示词工程的重要性,强调工程实践与业务需求相结合。…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...

JavaScript对象创建:告别繁琐,四种灵活写法一学就会
在JavaScript里,创建对象的这般方法常把刚开始学习的新手弄得困惑不已,好像无论走哪条道都行得通,可又不清楚该挑哪一条才好。我编写JavaScript都有十几年功夫了,对象创建这事差不多每天都会碰到可谓基础技能。它不像变量声明那般…...

Unity Spine换装系统:骨骼映射与Skin动态管理实战
1. 为什么Spine换装不能只靠“替换贴图”——一个被低估的骨骼绑定难题 在Unity里做Spine换装,很多人第一反应是:把新衣服的Atlas和SkeletonData拖进去,用 SkeletonRenderer 的 skeletonDataAsset 字段一换,完事。我去年接手一…...