Observability:识别生成式 AI 搜索体验中的慢速查询
作者:Philipp Kahr

Elasticsearch Service 用户的重要注意事项:目前,本文中描述的 Kibana 设置更改仅限于 Cloud 控制台,如果没有我们支持团队的手动干预,则无法进行配置。 我们的工程团队正在努力消除对这些设置的限制,以便我们的所有用户都可以启用内部 APM。 本地部署不受此问题的影响。
不久前,我们在 Elasticsearch® 中引入了检测,让你能够识别它在幕后所做的事情。 通过在 Elasticsearch 中进行追踪,我们获得了前所未有的见解。
当我们想要利用 Elastic 的学习稀疏编码器模型进行语义搜索时,本博客将引导你了解各种 API 和 transaction。 该博客本身可以应用于 Elasticsearch 内运行的任何机器学习模型- 你只需相应地更改命令和搜索即可。 本指南中的说明使用我们的稀疏编码器模型(请参阅文档)。
对于以下测试,我们的数据语料库是 OpenWebText,它提供大约 40GB 的纯文本和大约 800 万个单独的文档。 此设置在具有 32GB RAM 的 M1 Max Macbook 上本地运行。 以下任何交易持续时间、查询时间和其他参数仅适用于本博文。 不应对生产用途或你的安装进行任何推断。
让我们动手吧!
在 Elasticsearch 中激活跟踪是通过静态设置(在 elasticsearch.yml 中配置)和动态设置来完成的,动态设置可以在运行时使用 PUT _cluster/settings 命令进行切换(动态设置之一是采样率)。 某些设置可以在 runtime 时切换,例如采样率。 在elasticsearch.yml中,我们要设置以下内容:
tracing.apm.enabled: true
tracing.apm.agent.server_url: "url of the APM server"秘密令牌(或 API 密钥)必须位于 Elasticsearch 密钥库中。 使用以下命令 elasticsearch-keystore add Tracing.apm.secret_token 或 tracing.apm.api_key ,密钥库工具应该可以在 <你的 elasticsearch 安装目录>/bin/elasticsearch-keystore 中使用。 之后,你需要重新启动 Elasticsearch。 有关跟踪的更多信息可以在我们的跟踪文档中找到。
激活后,我们可以在 APM 视图中看到 Elasticsearch 自动捕获各种 API 端点。 GET、POST、PUT、DELETE 调用。 整理好之后,让我们创建索引:
PUT openwebtext-analyzed
{"settings": {"number_of_replicas": 0,"number_of_shards": 1,"index": {"default_pipeline": "openwebtext"}},"mappings": {"properties": {"ml.tokens": {"type": "rank_features"},"text": {"type": "text","analyzer": "english"}}}
}这应该给我们一个名为 PUT /{index} 的单个 transaction。 正如我们所看到的,当我们创建索引时发生了很多事情。 我们有创建调用,我们需要将其发布到集群状态并启动分片。

我们需要做的下一件事是创建一个摄取管道 —— 我们称之为 openwebtext。 管道名称必须在上面的索引创建调用中引用,因为我们将其设置为默认管道。 这可确保如果请求中未指定其他管道,则针对索引发送的每个文档都将自动通过此管道运行。
PUT _ingest/pipeline/openwebtext
{"description": "Elser","processors": [{"inference": {"model_id": ".elser_model_1","target_field": "ml","field_map": {"text": "text_field"},"inference_config": {"text_expansion": {"results_field": "tokens"}}}}]
}我们得到一个 PUT /_ingest/pipeline/{id} transaction。 我们看到集群状态更新和一些内部调用。 至此,所有准备工作都已完成,我们可以开始使用 openwebtext 数据集运行批量索引。

在开始批量摄入之前,我们需要启动 ELSER 模型。 转到 “Maching Learning(机器学习)”、“Trained Models(训练模型)”,然后单击 “Play(播放)”。 你可以在此处选择分配和线程的数量。
模型启动被捕获为 POST /_ml/trained_models/{model_id}/deployment/_start。 它包含一些内部调用,可能不如其他事务那么有趣。

现在,我们想通过运行以下命令来验证一切是否正常。 Kibana 开发工具有一个很酷的小技巧,你可以在文本的开头和结尾使用三引号(如”””),告诉 Kibana® 将其视为字符串并在必要时转义。 不再需要手动转义 JSON 或处理换行符。 只需输入你的文字即可。 这应该返回一个文本和一个显示所有令牌的 ml.tokens 字段。
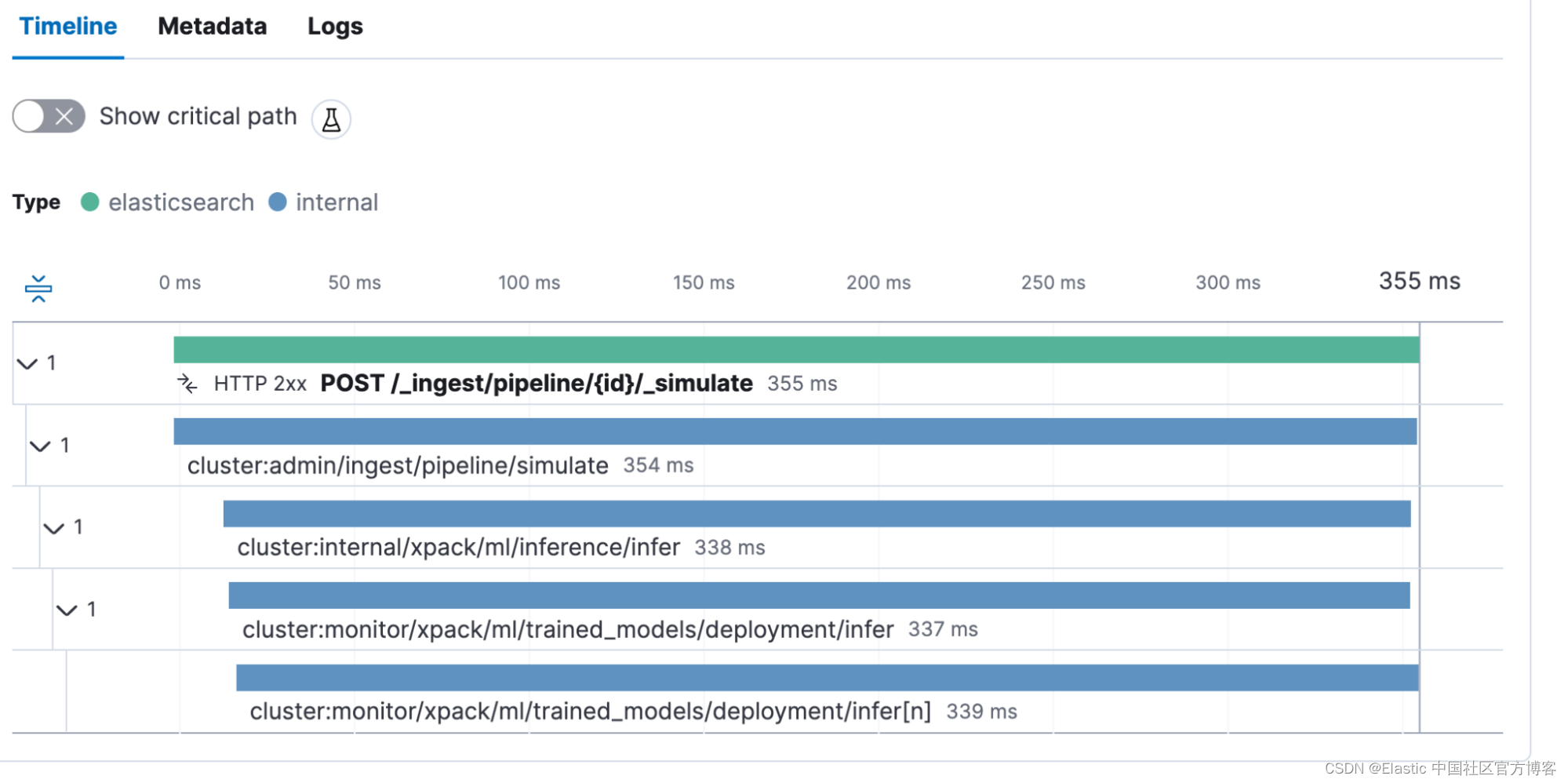
POST _ingest/pipeline/openwebtext/_simulate
{"docs": [{"_source": {"text": """This is a sample text"""}}]
}此调用也被捕获为 transaction POST _ingest/pipeline/{id}/_simulate。 有趣的是,我们看到推理调用花费了 338 毫秒。 这是模型创建向量所需的时间。
Bulk 摄入
openwebtext 数据集有一个文本文件,代表 Elasticsearch 中的单个文档。 这个相当 hack 的 Python 代码读取所有文件并使用简单的批量助手将它们发送到 Elasticsearch。 请注意,你不想在生产中使用它,因为它以序列化方式运行,因此速度相对较慢。 我们有并行批量帮助程序,允许你一次运行多个批量请求。
import os
from elasticsearch import Elasticsearch, helpers# Elasticsearch connection settings
ES_HOST = 'https://localhost:9200' # Replace with your Elasticsearch host
ES_INDEX = 'openwebtext-analyzed' # Replace with the desired Elasticsearch index name# Path to the folder containing your text files
TEXT_FILES_FOLDER = 'openwebtext'# Elasticsearch client
es = Elasticsearch(hosts=ES_HOST, basic_auth=('elastic', 'password'))def read_text_files(folder_path):for root, _, files in os.walk(folder_path):for filename in files:if filename.endswith('.txt'):file_path = os.path.join(root, filename)with open(file_path, 'r', encoding='utf-8') as file:content = file.read()yield {'_index': ES_INDEX,'_source': {'text': content,}}def index_to_elasticsearch():try:helpers.bulk(es, read_text_files(TEXT_FILES_FOLDER), chunk_size=25)print("Indexing to Elasticsearch completed successfully.")except Exception as e:print(f"Error occurred while indexing to Elasticsearch: {e}")if __name__ == "__main__":index_to_elasticsearch()我们看到这 25 个文档需要 11 秒才能被索引。 每次摄取管道调用推理处理器(进而调用机器学习模型)时,我们都会看到该特定处理器需要多长时间。 在本例中,大约需要 500 毫秒 — 25 个文档,每个文档约 500 毫秒,总共需约 12.5 秒来完成处理。 一般来说,这是一个有趣的观点,因为较长的文件可能会花费更多的时间,因为与较短的文件相比,需要分析的内容更多。 总体而言,整个批量请求持续时间还包括返回给 Python 代理的答案以及 “确定” 索引。 现在,我们可以创建一个仪表板并计算平均批量请求持续时间。 我们将在 Lens 中使用一些小技巧来计算每个文档的平均时间。 我会告诉你如何做。
首先,在事务中捕获了一个有趣的元数据 - 该字段称为 labels.http_request_headers_content_length。 该字段可能被映射为关键字,因此不允许我们运行求和、求平均值和除法等数学运算。 但由于运行时字段,我们不介意这一点。 我们可以将其转换为 Double。 在 Kibana 中,转到包含 traces-apm 数据流的数据视图,并执行以下操作作为值:
emit(Double.parseDouble($('labels.http_request_headers_content_length','0.0')))如果该字段不存在和/或丢失,则将现有值作为 Double 发出(emit),并将报告为 0.0。 此外,将格式设置为 Bytes。 这将使它自动美化! 它应该看起来像这样:

创建一个新的仪表板,并从新的可视化开始。 我们想要选择指标可视化并使用此 KQL 过滤器:data_stream.type: "traces" AND service.name: "elasticsearch" AND transaction.name: "PUT /_bulk"。 在数据视图中,选择包含 traces-apm 的那个,与我们在上面添加字段的位置基本相同。 单击 Prmary metric 和 fomula:
sum(labels.http_request_headers_content_length_double)/(count()*25)由于我们知道每个批量请求包含 25 个文档,因此我们只需将记录数(transaction 数)乘以 25,然后除以字节总和即可确定单个文档有多大。 但有一些注意事项 - 首先,批量请求会产生开销。 批量看起来像这样:
{ "index": { "_index": "openwebtext" }
{ "_source": { "text": "this is a sample" } }对于要索引的每个文档,你都会获得 JSON 中的第二行,该行会影响总体大小。 更重要的是,第二个警告是压缩。 当使用任何压缩时,我们只能说 “这批文档的大小为 x”,因为压缩的工作方式会根据批量内容而有所不同。 当使用高压缩值时,我们发送 500 个文档时可能会得到与现在发送 25 个文档相同的大小。 尽管如此,这是一个有趣的指标。

我们可以使用 transaction.duration.us 提示! 将 Kibana 数据视图中的格式更改为 Duration 并选择 microseconds,确保其渲染良好。 很快,我们可以看到,批量请求的平均大小约为 125kb,每个文档约为 5kb,耗时 9.6 秒,其中 95% 的批量请求在 11.8 秒内完成。

查询时间!
现在,我们已经对许多文档建立了索引,终于准备好对其进行查询了。 让我们执行以下查询:
GET /openwebtext/_search
{"query":{"text_expansion":{"ml.tokens":{"model_id":".elser_model_1","model_text":"How can I give my cat medication?"}}}
}我正在向 openwebtext 数据集询问有关给我的猫喂药的文章。 我的 REST 客户端告诉我,整个搜索(从开始到解析响应)花费了:94.4 毫秒。 响应中的语句为 91 毫秒,这意味着在 Elasticsearch 上的搜索花费了 91 毫秒(不包括一些内容)。 现在让我们看看 GET /{index}/_search transaction。
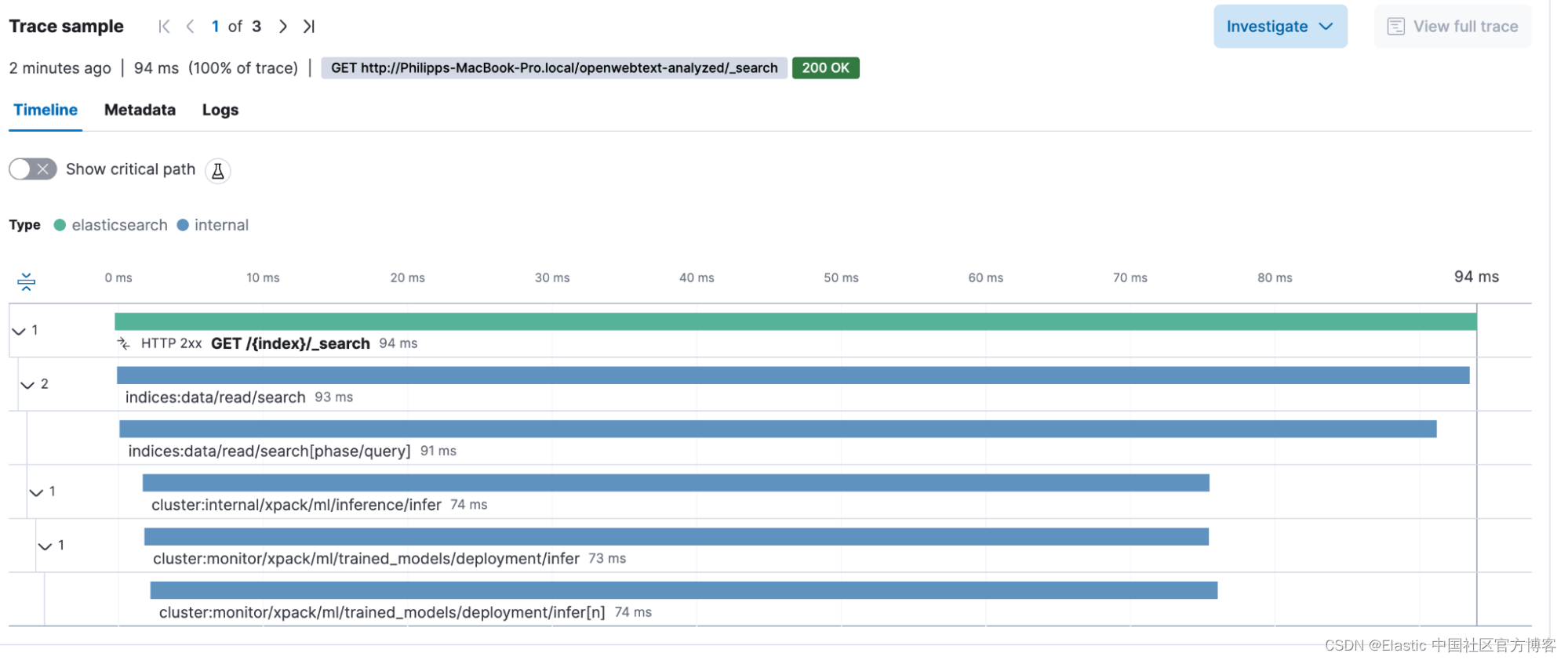
我们可以发现,机器学习(基本上是动态创建令牌)的影响占总请求的 74 毫秒。 是的,这大约占整个交易持续时间的 3/4。 有了这些信息,我们就可以就如何扩展机器学习节点以缩短查询时间做出明智的决策。
结论
这篇博文向你展示了将 Elasticsearch 作为仪表化应用程序并更轻松地识别瓶颈是多么重要。 此外,你还可以使用事务持续时间作为异常检测的指标,为你的应用程序进行 A/B 测试,并且再也不用怀疑 Elasticsearch 现在是否感觉更快了。 你有数据支持这一点。 此外,这广泛地关注了机器学习方面的问题。 查看一般慢日志查询调查博客文章以获取更多想法。
仪表板和数据视图可以从我的 Github 存储库导入。
原文:Identify slow queries in generative AI search experiences | Elastic Blog
相关文章:
Observability:识别生成式 AI 搜索体验中的慢速查询
作者:Philipp Kahr Elasticsearch Service 用户的重要注意事项:目前,本文中描述的 Kibana 设置更改仅限于 Cloud 控制台,如果没有我们支持团队的手动干预,则无法进行配置。 我们的工程团队正在努力消除对这些设置的限制…...

接口测试及接口抓包常用的测试工具
接口 接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。 接口测试的重要性 是节省时间前后端不…...
CH342/CH343/CH344/CH347/CH9101/CH9102/CH9103/CH9104 Linux串口驱动使用教程
CH343 Linux串口驱动 ch343ser_linux 支持USB转串口芯片 ch342/ch343/ch344/ch347/ch9101/ch9102/ch9103/ch9104等 ,同时该驱动配合ch343_lib库还提供了芯片GPIO接口的读写功能,内部EEPROM的信息配置和读取功能等。 芯片型号串口数量GPIO数量CH342F/K2C…...

反射和工厂设计模式---工厂设计模式
一、工厂设计模式概述 ■什么是工厂设计模式 工厂模式(Factory Pattern)是开发中比较常用的设计模式之一。 它属于创建型模式(单例模式就是创建型模式的一种),这种模式让我们在创建对象时不会直接暴露创建逻辑,而是通过使用一个共同的接口来完成对象的…...
【算法——双指针】LeetCode 283 移动零
题目描述: 思路: (双指针) O(n)O(n)O(n) 给定一个数组 nums,要求我们将所有的 0 移动到数组的末尾,同时保持非零元素的相对顺序。 如图所示,数组nums [0,1,0,3,12],移动完成后变成nums [1,3,12,0,0] &am…...
腾讯云轻量服务器和云服务器的CPU处理器有差别吗?
腾讯云轻量应用服务器和CVM云服务器的CPU处理器性能有差别吗?创建轻量应用服务器时不支持指定底层物理服务器的CPU型号,腾讯云将随机分配满足套餐规格的物理CPU型号,通常优先选择较新代次的CPU型号。而云服务器CVM的CPU处理器型号、主频都是有…...
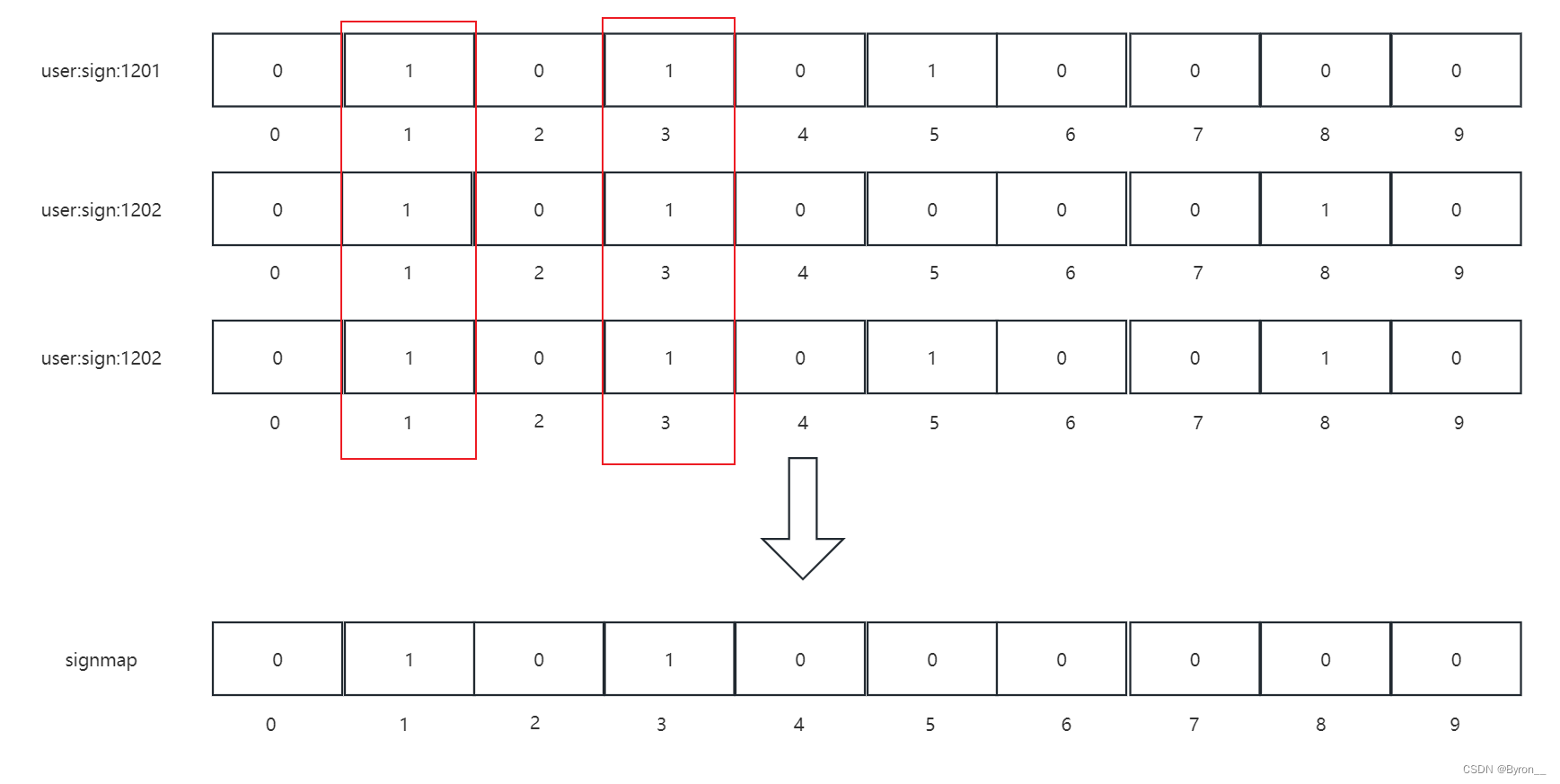
Redis_亿级访问量数据处理
11. 亿级访问量数据处理 11.1 场景表述 手机APP用户登录信息,一天用户登录ID或设备ID电商或者美团平台,一个商品对应的评论文章对应的评论APP上有打卡信息网站上访问量统计统计新增用户第二天还留存商品评论的排序月活统计统计独立访客(Unique Vistito…...
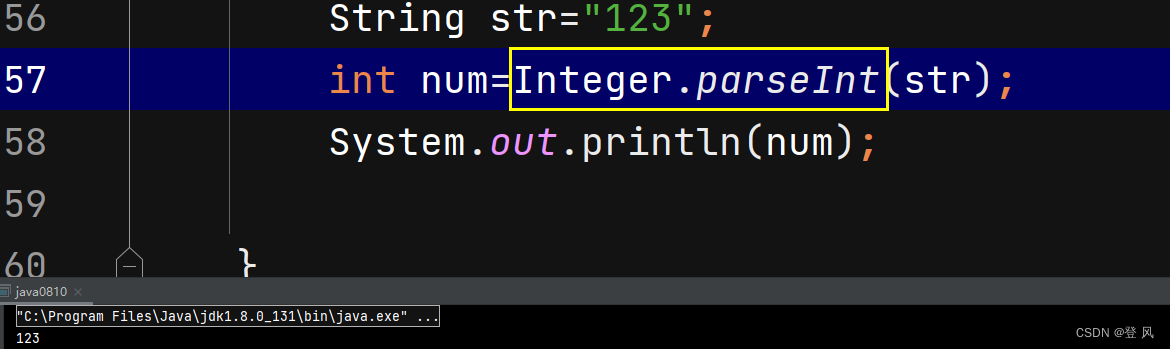
Java-类型和变量(基于C语言的补充)
一个简单的Java程序 args){ System.out.println("Hello,world"); } }通过上述代码,我们可以看到一个完整的Java程序的结构,Java程序的结构由如下三个部分组成: 1.源文件(扩展名为*.java):源文件带有类的定义…...
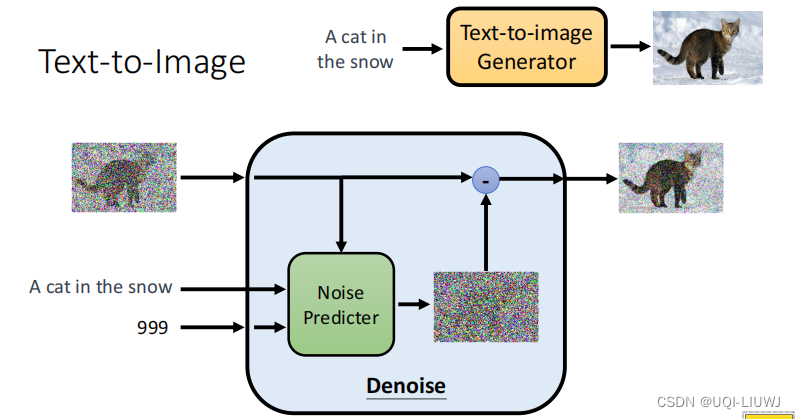
机器学习笔记:李宏毅diffusion model
1 概念原理 首先sample 一个都是噪声的vector然后经过denoise network 过滤一些杂质接着继续不断denoise,直到最后出来一张清晰图片 【类似于做雕塑,一开始只是一块石头(噪声很杂的雕塑),慢慢雕刻出想要的花纹】 同一个…...

STM32--TIM定时器(2)
文章目录 输出比较PWM输出比较通道参数计算舵机简介直流电机简介TB6612 PWM基本结构PWM驱动呼吸灯PWM驱动舵机PWM控制电机 输出比较 输出比较,简称OC(Output Compare)。 输出比较的原理是,当定时器计数值与比较值相等或者满足某种…...

git Authentication failed
情况是这样的,之前看代码只是clone了一份,但随着分支越来越多,有时候切换分支时必须先把修改的代码 stash 一下,觉得很麻烦,于是又clone了一份代码。然后pull代码是正常的,当push 代码的时候,去…...
【软考】2023系统架构设计师考试
目录 1 软考资格设置 2 考试报名 3 考试准备 4 参加考试 5 考试感受 6 其他 1 软考资格设置 2 考试报名 报名网址:https://www.ruankao.org.cn/ 3 考试准备 4 参加考试 2023年下半年系统架构设计师考试时间为11月4、5日。 5 考试感受 6 其他 最近好像有地区…...
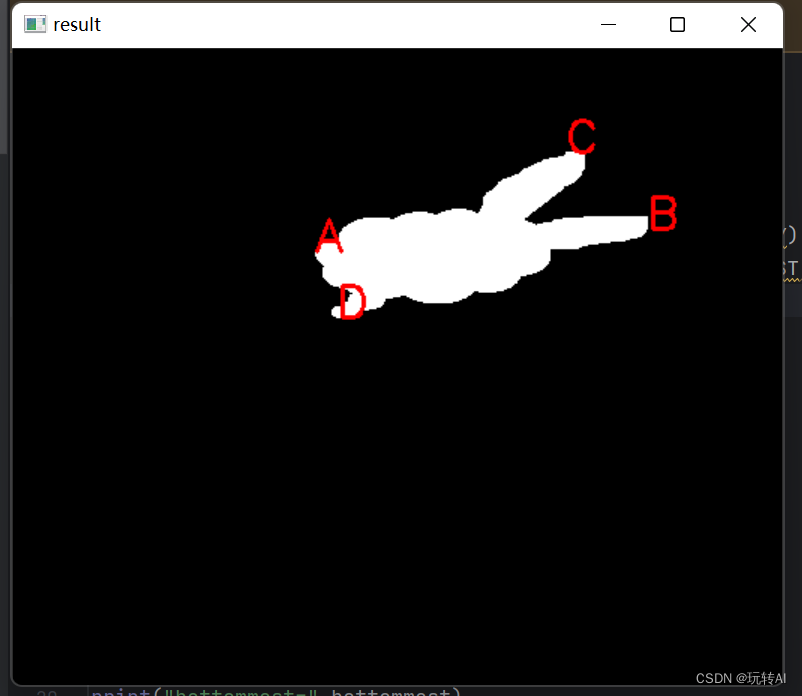
opencv基础55-获取轮廓的特征值及示例
轮廓自身的一些属性特征及轮廓所包围对象的特征对于描述图像具有重要意义。本节介绍几个轮廓自身的属性特征及轮廓所包围对象的特征。 宽高比 可以使用宽高比(AspectRation)来描述轮廓,例如矩形轮廓的宽高比为: 宽高比 宽度&am…...
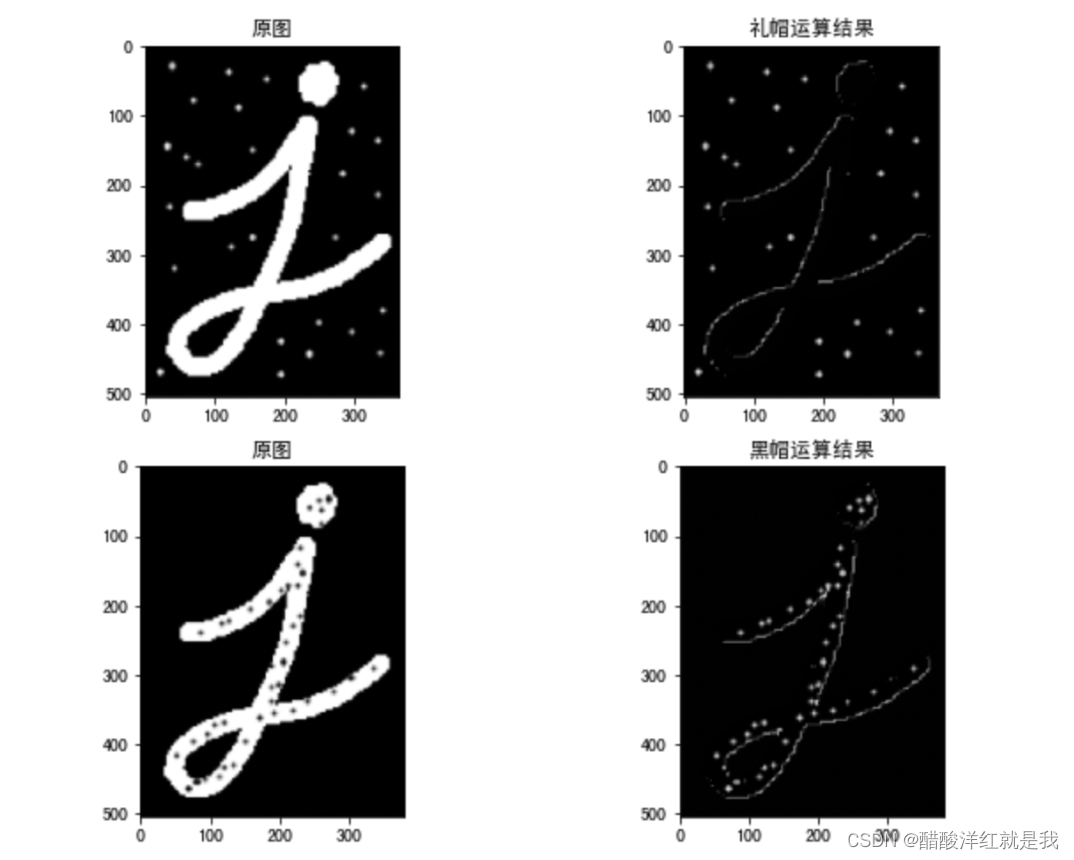
OpenCV图像处理——形态学操作
目录 连通性形态学操作腐蚀和膨胀开闭运算礼帽和黑帽 连通性 形态学操作 形态学转换是基于图像形状的一些简单操作。它通常在二进制图像上执行。腐蚀和膨胀时两个基本的形态学运算符。然后它的变体形式如开运算,闭运算,礼帽黑帽等 腐蚀和膨胀 cv.erode…...

修改VS Code终端的显示行数
文章目录 前言修改VS Code终端显示行数参考 前言 在我们使用VS Code运行代码的过程中,有时需要再终端中显示很多的运行过程信息或者结果。然而,VS Code的终端默认显示1000行的内容,随着显示内容的增多,之前的内容就丢失了。为了解…...

C++学习| MFC简单入门
前言:因为接手了CMFC的程序,所以需要对MFC编程方面有所了解。 C之MFC简单入门 MFC相关的概念MFCWIN32QT MFC项目基本操作MFC项目创建MFC项目文件解读界面和代码数据交互——加法器 MFC相关的概念 MFC MFC(Microsoft Foundation Classes微软…...

“一日之际在于晨”,欢迎莅临WAVE SUMMIT上午场:Arm 虚拟硬件早餐交流会
8月16日,盛夏的北京将迎来第九届WAVE SUMMIT深度学习开发者大会。在峰会主论坛正式开启前,让我们先用一份精美的元气早餐,和一场“Arm虚拟硬件交流会”,唤醒各位开发小伙伴的开发魂! 8月16日,WAVE SUMMIT大…...

leetcode454. 四数相加 II
题目:leetcode454. 四数相加 II 描述: 给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < n nums1[i] nums2[j] nums3[k] num…...
PHP证券交易员学习网站mysql数据库web结构apache计算机软件工程网页wamp
一、源码特点 PHP证券交易员学习网站 是一套完善的web设计系统,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 下载地址https://download.csdn.net/download/qq_41221322/88205549 PHP证券交易员…...
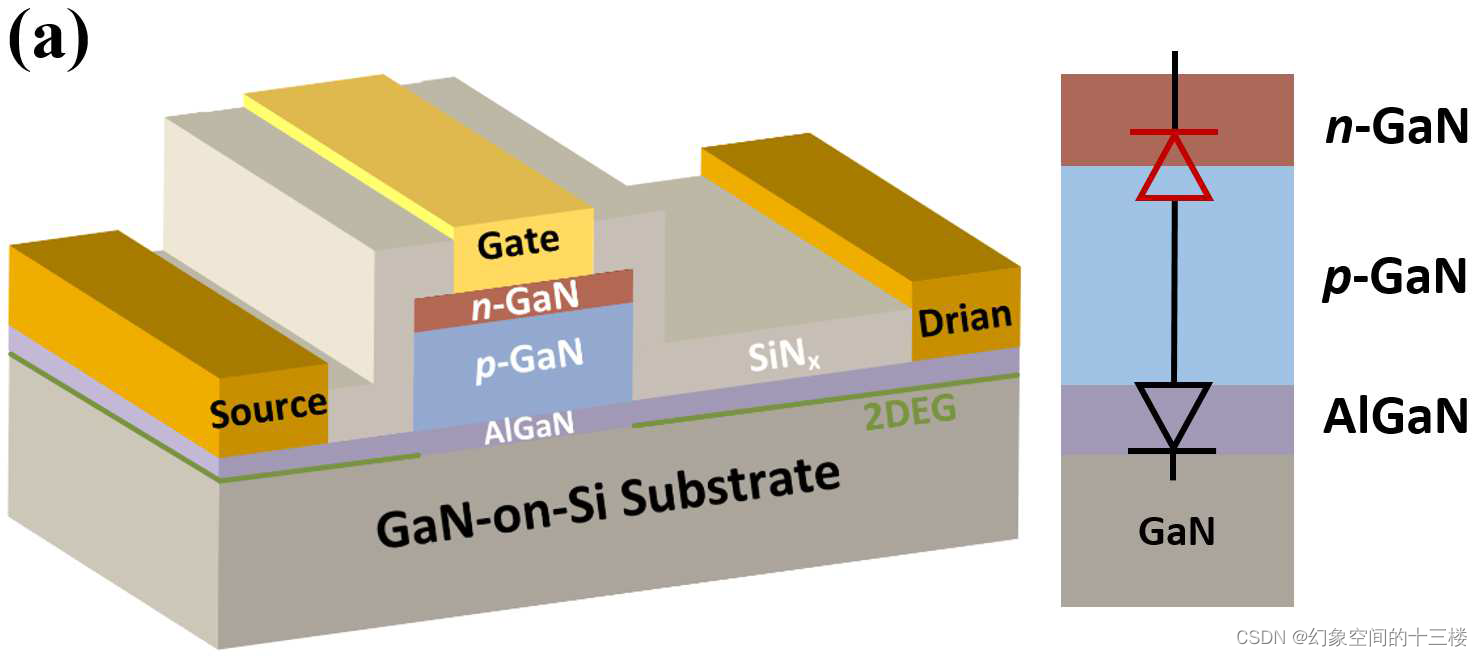
对p-n结/AlGaN/GaN HEMTs中n-GaN掺杂浓度对栅极可靠性的影响
目录 第35届功率半导体器件与集成电路国际研讨会论文集2023年5月28日至6月1日,中国香港南方科技大学电气电子工程系,深圳标题:Impacts of n-GaN Doping Concentration on Gate Reliability of p-n Junction/AlGaN/GaN HEMTs摘要信息解释研究了…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...

集成Taotoken为OpenClaw工作流提供持久化模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 集成Taotoken为OpenClaw工作流提供持久化模型支持 在构建基于OpenClaw的自动化Agent工作流时,一个稳定且可灵活切换的模…...

【2026实测】怎么提高论文原创度?盘点8款主流降AI工具,附结构级优化指南
写文章最怕碰到什么,是辛辛苦苦自己码出来的字,却被标了极高的AI值。目前很多文本审核机制对内容的原创度要求极高,纯手写的初稿也可能因为句式太工整被判定为机器生成的。 为了帮几个快被这事折腾疯了的学弟学妹找条出路,我花了…...