SQL 语句解析过程详解
SQL 语句解析过程详解:
1.输入SQL语句
2.词法分析------flex
使用词法分析器(由Flex生成)将 SQL 语句分解为一个个单词,这些单词被称为“标记“。标记包括关键字、标识符、运算符、分隔符等。
2.1 flex 原理
1、使用 flex 工具定义正则表达式规则来匹配不同类型的词法单元;例如,可以定义以下规则:
- 匹配关键字:SELECT、FROM、WHERE、HAVING等。
- 匹配标识符:由字母或下划线开头,后跟字母、数字或下划线组成。
- 匹配运算符:比如=、<、>、+、等。
- 匹配常量:包括整数、浮点数、字符串等。
2、生成词法分析器代码:根据定义的词法规则,使用Flex工具生成对应的词法分析器代码;
3、输入查询字符串:将要解析的查询字符串作为输入提供给同法分析器;
4、扫描和匹配:词法分析器从输入字符串中逐个读取字符,并尝试将其与定义的词法规则进行匹配;
5、生成词法单元:当词法分析器匹配到一个词法规则时,它会生成相应的词法单元并返回给语法分析器。每个词法单元通常包含两部分信息:
- 词法单元类型(token type):表示该词法单元的种类,比如关键字、标识符、运算符等;
- 词法单元值(tokenvalue):表示该词法单元具体的取值;
6、继续扫描:词法分析器会持续从输入字符串中读取字符,并重复步骤4和步骤5,直到整个查询字符串被完全解析为一系列词法单元;
7、返回词法单元序列:当整个查询字符串都被解析后,词法分析器将返回一个包含所有词法单元的序列给语法分析器,供后续的语法分析处理;
2.2 flex 文件代码结构
2.2.1 flex 文件介绍
1、flex文件代码
%option noyywrap
%{
definition
%}%%
rules
%%
Code
(1)%option 指定 flex 扫描时的一些特性。yywrap 通常在多文件扫描时定义使用。常用的一些选项有:
- Noyywrap:告诉flex不使用yywrap函数;
- yylineno:会告诉flex生成一个名为yylineno的整型变量来保存当前的行号;
- case-insensitive 正则表达式规则大小写无关;
(2)definitio部分为定义部分,包括引入头文件,变量声明,函数声明,注释等,这部分会被原样拷贝到输出的.c文件中。
(3)rules部分定义词法规则,使用正则表达式定义词法,后面{}内则是扫描到对应词法时的动作代码;“|”是一个特殊符号,表示下一个模式应用相同的动作;正则表达式后面不指定动作,则相应的模式会被忽略。
(4)code部分为C语言的代码。yylex为flex的函数,使用yylex开始扫描。
2.2.2 flex 文件常用变量
(1)yytext:词法分析程序当前识别到的一些词素,与转换规则部分中的某个模式相匹配;
(2)yylength:词法分析程序当前识别到的词素的长度;
(3)yylval:yylval是在bison中定义的联合类型变量(union),因为Flex生成的词法分析程序yylex()需要向bison生成的语法分析器返回识别到的词法单元,所以需要使用yylval来保存词法单元的属性值;
2.2.3 正则表达式
. 匹配除换行符”\n”以外的任何单个字符;* 匹配前面表达式的零个或多个拷贝;[] 匹配括号中任意字符的字符类,如果第一个字符是 “^”,则匹配除括号中的字符以外的任意字符;“-” 指示一个字符范围,例如“[0-9]”和“[0123456789]”含义相同;除了以 “\” 开始的转义序列,元字符在括号内没有任何含义;^ 作为正则表达式的行首匹配行的开头,也用于方括号中的否定;$ 作为正则表达式的行尾匹配行的结尾;\ 用于转义元字符,也作为常用的C转义序列的一部分,例如”\n”表示换行,“\*” 表示非元字符的星号;+ 匹配前面的正则表达式一次或多次出现;? 匹配前面的正则表达式零次或一次出现;| 匹配前面的正则表达式或随后的正则表达式;“…” 引号中的每个字符解释为字面意义,除C转义序列外元字符会失去其特殊含义;() 将一系列正则表达式组成一个新的正则表达式,例如(01),表示字符序列 01;{} 当括号中包含一个或两个数字时,指示前面的模式允许被匹配多少次,例如{1,3}表示匹配字母一次到三次;2.2.4 flex 文件具体案例
1、创建一个名为 lexer.l 的文件,其中包含词法规则;
%{
#include <stdio.h>
%}%%
SELECT { printf("Keyword: SELECT\n"); }
FROM { printf("Keyword: FROM\n"); }
WHERE { printf("Keyword: WHERE\n"); }
AND { printf("Keyword: AND\n"); }
OR { printf("Keyword: OR\n"); }[0-9]+ { printf("Number: %s\n", yytext); }[A-Za-z_][A-Za-z0-9_]* { printf("Identifier: %s\n", yytext); }
[=><]+ { printf("Operator: %s\n", yytext); }
[ \t\n] ; // Skip whitespace. { printf("Unknown: %s\n",yytext); }%%int main() { yylex(); return 0;
}
2、使用 flex 命令编译 lexer.l 文件,生成词法分析器代码
(1)执行下列语句生成词法分析器代码
flex lexer.l(2)词法分析器生成结果
lex.yy.c(3)编译生成的词法分析器代码,生成可执行文件
gcc -o lexer lex.yy.c -lfl(4)运行可执行文件并输入一些算术表达式进行测试
./lexer输入:SELECT * FROM table;(5)执行结果如下

说明:
- -ll: 这是旧版本的Flex生成器(例如Flex 2.5.4)的链接选项。它指示链接器将使用名为 libl.a 或 libl.so 的库文件。在以前的版本中,Flex生成的词法分析器的默认名称是 lex.yy.c,而库文件的名称以 "l" 开头,因此使用 -ll 是一种传统的方式。
- -lg: 这是新版本的Flex生成器(例如Flex 2.5.35)的链接选项。类似于旧版本的 -ll,它指示链接器使用名为 libg.a 或 libg.so 的库文件。这种新方式是为了避免与其他工具和库发生命名冲突。
- -lfl: 这是一个与Flex生成的词法分析器库相关的选项。-lfl 表示链接器将使用名为 libfl.a 或 libfl.so 的库文件。这个库包含了Flex所需的运行时支持函数。
注意:
如果 flex 词法分析器对 .l 进行编译时报错:
/opt/h/devtoolset-11/root/usr/ibexec/gcex86.64-redhat-linux/11/ld: cannot find -lfn
解决方案:
该错误表明链接器无法找到名为 -if 的库文件。这通常是因为在您的系统上缺少libfl库,或者库文件的路径未正确配置。要解决这个问题,您可以尝试以下步骤:
1、确认库是否已安装:首先,请确保您的系统上已安装了libfl库。您可以尝试使用包管理器来安装它。在基于Red Hat的系统中,您可能需要执行类似于以下的命令:
yum install flex-devel2、检查库文件路径:如果库已安装,但链接器仍然找不到它,可能是因为库文件的路径未正确配置。您可以尝试手动指定库文件的路径。例如,假设libfl库文件位于/usr/lib64目录下,您可以使用以下方式链接:
gcc -o my program lex.yy.c -L/usr/lib64 -1f13、更新库文件缓存:如果您最近安装了libfl库,但链接器仍然找不到它,您可能需要更新库文件缓存。运行以下命令以更新库文件缓存:
sudo ldconfig3.语法分析------bison
使用语法分析器(由 Bison 生成)根据语法规则进行语法分析,生成抽象语法树。语法树是一种树形结构,它表示 SQL 语句的语法结构。语法分析器会检查语法树是否符合 SQL 语法规则,如果不符合,则会抛出语法错误。
3.1 bison原理
3.2 bison文件代码结构
1、bison文件代码
%{
// C 代码和头文件的声明
#include <stdio.h>
// 在这里可以定义全局变量和函数等
%}
// Bison 的选项部分
%option verbose // 控制 Bison 解析器的详细输出// Bison 的声明部分
%token NAME // 定义终结符或标记的名称
%token NUMBER%left ‘+’ ‘-‘ // 定义运算符的优先级和结合性
%left ‘*’ ‘/’%{
// 在这里可以编写更多的 C 代码
%}// Bison 的规则部分%%
// 语法规则的定义
expression : expression '+' expression | expression '-' expression | expression '*' expression | expression '/' expression | '(' expression ')' | NUMBER ;
// 更多的语法规则...
%%// C 代码部分(选项中的 %{ ... %} 和规则部分中的 %% 之间的部分)
// 在这里可以编写与语法规则相关的 C 代码
int main() { yyparse(); // 调用 Bison 生成的解析函数 return 0;
}
bison文件的书写格式与flex文件的书写格式基本一致,只是规则的定义语法不同。
3.3 规则语法介绍
(1)终结符(Terminals)
终结符是语法规则中的基本符号,通常是语言中的关键字、运算符、标识符等。可以使用%token来定义终结符。以下是一个示例:
%token NUMBER
%token PLUS MINUS TIMES DIVIDE
%token IDENTIFIER
%token SEMICOLON在这个示例中,我们定义了几个终结符,包括数字(NUMBER)、加号(PLUS)、减号(MINUS)、乘号(TIMES)、除号(DIVIDE)、标识符(IDENTIFIER)和分号(SEMICOLON)等。终结符是语法规则中的基本符号,代表语言中的最小单元或词汇元素。终结符在语法分析的过程中与输入字符串的实际内容进行匹配,帮助构建解析树或语法分析树。在 Bison 文件中,终结符通常以大写字母或使用引号括起来的字符串表示。
(2)非终结符(Non-terminals)
非终结符表示语法规则中的抽象结构,可以由其他非终结符和/或终结符组成。您可以使用 %type 来定义非终结符的类型。以下是一个示例:
%type <expr> expression%type <term> term%type <factor> factor在这个示例中,我们定义了三个非终结符 expression、term 和 factor,并指定了它们的类型。这些类型标记可以在产生式的操作部分使用,以便对解析树节点进行更复杂的操作。非终结符在语法分析树中代表了一些更高级的结构,可以用来执行语义操作、构建解析树,并帮助描述语言的抽象语法结构。在 Bison 文件中,非终结符通常以小写字母开头。
终结符和非终结符在 Bison 文件中共同定义了语法规则,帮助我们描述和分析特定编程语言或语言的一部分。终结符代表了实际的词法单元,而非终结符则代表了更高层次的语法结构。通过将终结符和非终结符组合起来,我们可以创建复杂的语法规则,用于生成和解析语言的有效字符串。
(3)“文法”
“文法”是一组规则,用于描述编程语言或语言的语法结构。这些规则定义了语言的句法(syntax),即哪些组合是有效的、合法的语句和表达式,以及它们如何组合在一起。文法规则使用产生式(productions)的形式来表示,其中包含终结符(terminals)和非终结符(non-terminals)的组合。
文法规则在 Bison 文件中是使用 BNF(巴科斯-诺尔范式)或 EBNF(扩展巴科斯-诺尔范式)的形式表示的。BNF 是一种形式化的表示方法,用于定义上下文无关文法(Context-Free Grammar),这些文法用于指定编程语言的语法规则。
expression : expression '+' term| expression '-' term| term;(4) %start
%start 指令用于指定文法的起始非终结符。起始非终结符是语法分析的入口点,也就是从哪个语法规则开始构建解析树或语法分析树。
%start program%%statements : statement| statements statement;statement : assignment| if_statement| while_statement| /* ... other statement types ... */ ;%start program 指定了起始非终结符为 program。这意味着语法分析将从 program 规则开始,逐步展开其他非终结符,最终构建解析树。在实际语法规则中,起始非终结符的选择取决于您想要分析的语言的语法结构。
(5)$
在语法规则中,$ 用于引用当前产生式的右侧的符号或值。例如,在产生式的右侧,$1 表示该产生式右侧的第一个元素(终结符或非终结符),$2表示第二个元素,依此类推。这些引用用于将产生式右侧的值传递给产生式左侧。注意:生产式的起始下标为1。
(6)$$
在语法规则中,$$ 用于引用当前产生式的结果。当 Bison 解析器完成一个产生式的分析并计算出其结果时,该结果会被赋值给 $$。这通常用于构建解析树的节点或为更高层次的语法规则提供结果。
(7)|
| 用于表示多个产生式之间的选择。它在上下文无关文法中用于定义非终结符的不同产生式形式。每个产生式通过竖线分隔,表示它们是该非终结符的可能形式之一。
3.4 bison文件具体案例
1、创建一个名为parser.l的文件,其中包含词法规则;
%{
#include <stdio.h>
#include <stdlib.h>
%}//定义终结符
%token SELECT INSERT UPDATE DELETE FROM WHERE
%token INTO VALUES SET
%token ID INT STRING%%//定义规则statement: SELECT columns FROM table WHERE condition ';'| INSERT INTO table '(' columns ')' VALUES '(' values ')' ';'| UPDATE table SET assignments WHERE condition ';'| DELETE FROM table WHERE condition ';';columns: ID| columns ',' ID;table: ID;assignments: ID '=' value| assignments ',' ID '=' value;values: value| values ',' value;value: INT| STRING;condition: ID '=' value;%%int main() {yyparse();return 0;
}int yyerror(const char *s) {printf("Error: %s\n", s);return 0;
}
2、使用 bison 命令编译 lexer.l 文件
bison -d parser.y这将生成 parser.tab.c 和 parser.tab.h 两个文件。接下来,你可以将这些文件与你的编译器项目一起编译,并链接到你的代码中。

3.5 抽象语法树(AST)
AST构建步骤:
1、从前缀表达式构建函数关系表里获取当前Token的构建函数,调用该函数构建出一个前缀表达式;
2、查看下一个Token的优先级,如果下一个Token的优先级比当前Token的优先级更高,则说明这可能是一个中缀表达式,或后缀表达式;
3、如果是中缀表达式,则从中缀表达式构建函数关系表里获取下一个Token的构建函数,调用该函数构建出一个中缀表达式;
4、如果是后缀表达式,则从后缀表达式构建函数关系表里获取下一个Token的构建函数,调用该函数构建出一个后缀表达式;
5、通过递归方式,将这些表达式建立起父子关系,最终形成一个抽象语法树。
4.语义分析
在语法分析的基础上,对生成的抽象语法树进行语义分析。语义分析器会检查SQL语句是否符合数据库的语义规则,例如表是否存在、列是否存在、数据类型是否匹配等。如果不符合,则会抛出语义错误。
5.优化器
在语义分析的基础上,进行优化。优化器会对SQL语句进行优化,以提高查询效率。优化器会选择最优的执行计划,包括选择最优的索引、选择最优的连接方式等。
6.执行计划生成器
在优化器的基础上,生成执行计划。执行计划是一组计算机指令,用于执行SQL语句。执行计划包括访问表、过滤数据、排序数据等操作。
7.执行计划执行器
执行计划执行器会按照执行计划执行SQL语句。执行计划执行器会访问表、过滤数据、排序数据等操作,最终返回查询结果。
8.结果集返回
执行计划执行器会将查询结果返回给客户端。查询结果可以是一张表、一组记录或一个标量值。
9.清理
在查询结束后,数据库管理系统会清理执行计划、释放资源等。
未完,writing……
相关文章:
SQL 语句解析过程详解
SQL 语句解析过程详解: 1.输入SQL语句 2.词法分析------flex 使用词法分析器(由Flex生成)将 SQL 语句分解为一个个单词,这些单词被称为“标记“。标记包括关键字、标识符、运算符、分隔符等。 2.1 flex 原…...

单源最短路径【学习算法】
单源最短路径【学习算法】 前言版权推荐单源最短路径Java算法实现代码结果 带限制的单源最短路径1928. 规定时间内到达终点的最小花费LCP 35. 电动车游城市 最后 前言 2023-8-14 18:21:41 以下内容源自《【学习算法】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此…...
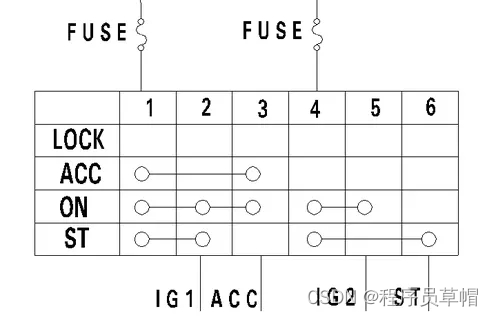
汽车上的电源模式详解
① 一般根据钥匙孔开关的位置来确定整车用电类别,汽车上电源可以分为常电,IG电,ACC电 1)常电。常电表示蓄电池和发电机输出直接供电,即使点火开关在OFF档时,也有电量供应。一般来讲模块的记忆电源及需要在车…...

【碎碎念随笔】1、回顾我的电脑和编程经历
✏️ 闲着无事,讲述一下我的计算机和代码故事 一、初识计算机 🖥️ 余家贫,耕植无钱买电脑。大约六年级暑假,我在姐姐哪儿第一次接触到了计算机(姐姐也是买的二手)。 🖥️ 计算机真有趣&#x…...
)
背上花里胡哨的书包准备面试之webpack篇(+一些常问的面试题)
目录 webpack理解? webpack构建流程? loader解决什么问题? plugin解决什么问题? 编写loader和plugin的思路? webpack热更新? 如何提高webpack的构建速度? 问git常用命令? ht…...

你知道什么是Curriculum Training模型吗
随着深度学习技术的飞速发展,研究人员在不断探索新的训练方法和策略,以提高模型的性能和泛化能力。其中,Curriculum Training(课程学习)模型作为一种前沿的训练方法,引起了广泛的关注和研究。本文将深入探讨…...

vue 大文件视频切片上传处理方法
前端上传大文件、视频的时候会出现超时、过大、很慢等情况,为了解决这一问题,跟后端配合做了一个切片的功能。 我这个切片功能是基于 minion 的,后端会把文件放在minion服务器上。具体看后端怎么做 1、在项目的 util(这个文件夹是自己创建的…...
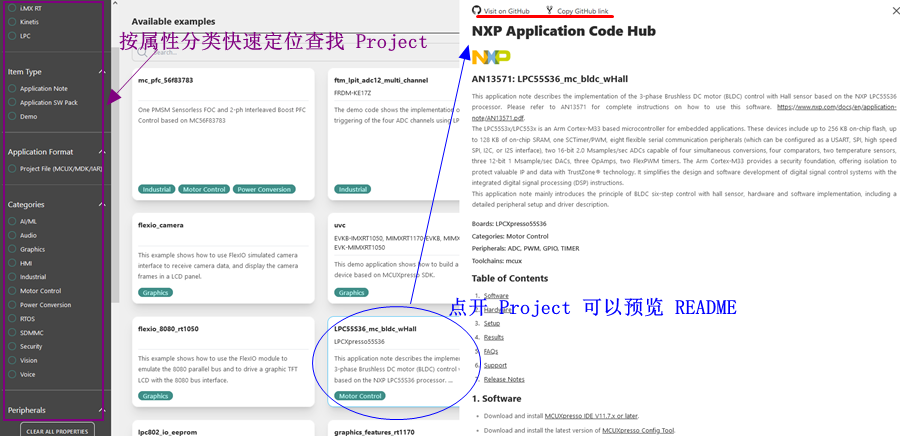
痞子衡嵌入式:AppCodeHub - 一站网罗恩智浦MCU应用程序
近日,恩智浦官方隆重上线了应用程序代码中心(Application Code Hub,简称 ACH),这是恩智浦 MCUXpresso 软件生态的一个重要组成部分。痞子衡之所以要如此激动地告诉大家这个好消息,是因为 ACH 并不是又一个恩智浦官方 github proje…...
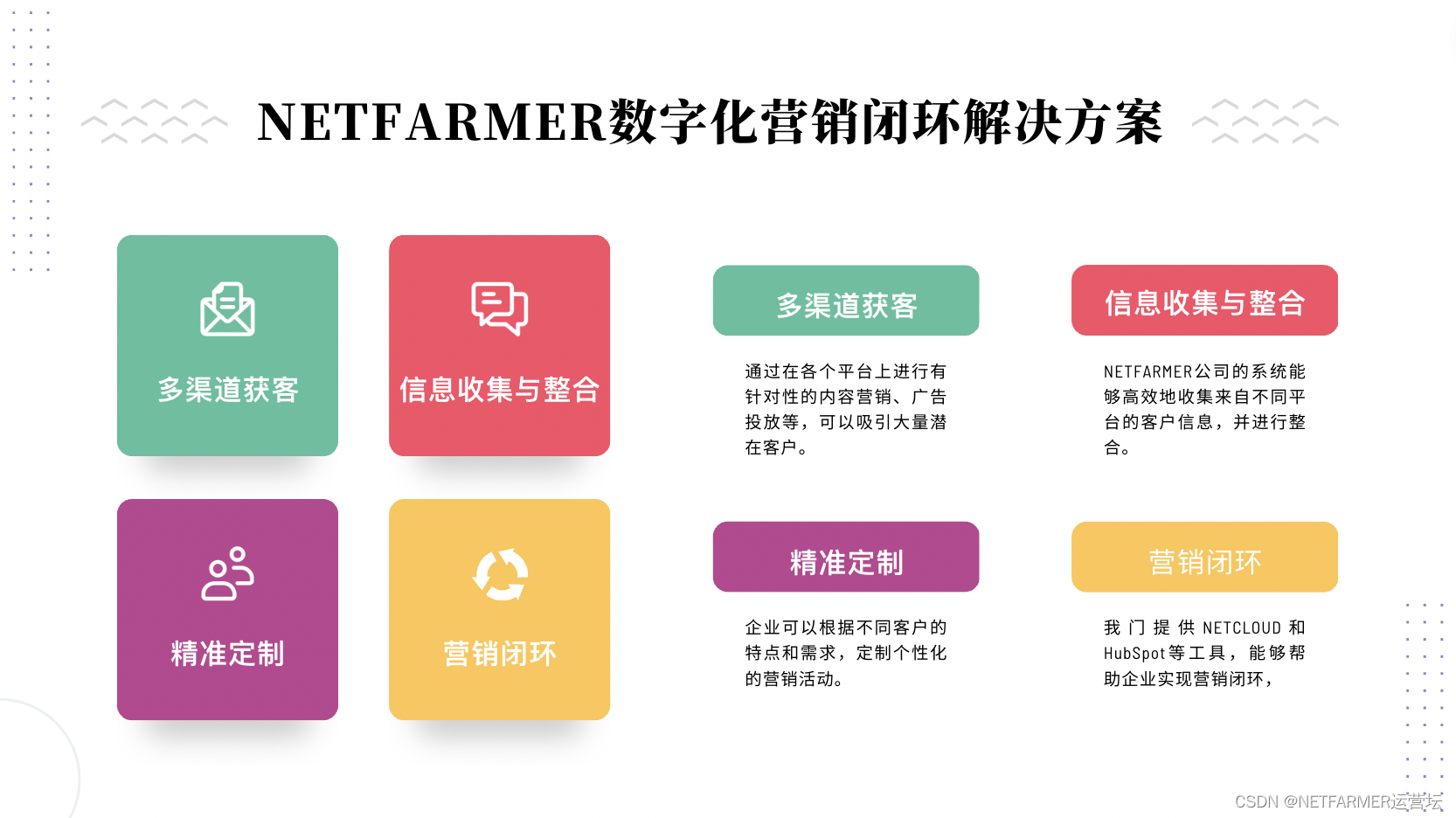
打造数字化营销闭环,破解精准获客难题
现阶段,企业需要进行数字化营销闭环,以实现更精确的客户获取。随着数字技术的迅猛发展,企业需要将在线广告、社交媒体营销和数据分析等工具相互结合,建立一个完整的数字化营销流程。通过使用客户细分、精准定位和个性化广告等手段…...
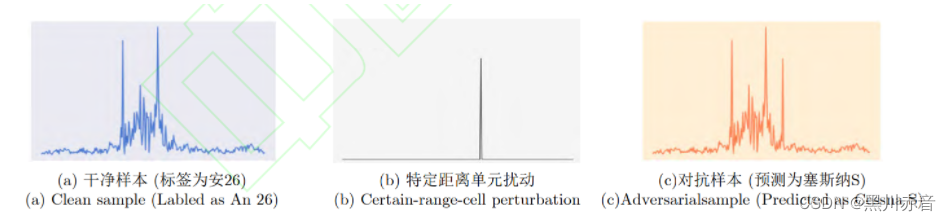
《雷达像智能识别对抗研究进展》阅读记录
(1)引言 神经网络通常存在鲁棒性缺陷,易受到对抗攻击的威胁。攻击者可以隐蔽的诱导雷达智能目标识别做出错误预测,如: a图是自行车,加上对抗扰动后神经网络就会将其识别为挖掘机。 (2&a…...
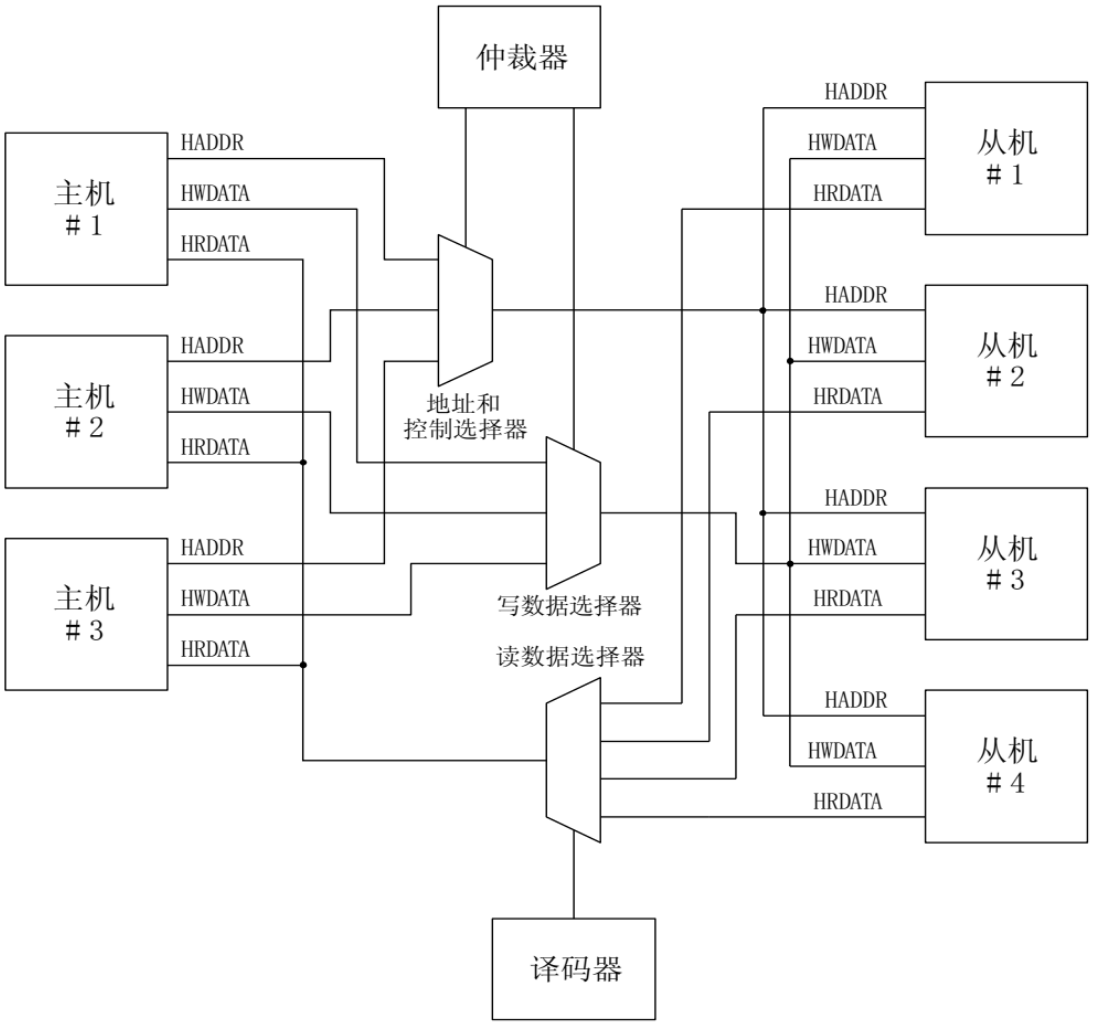
【AHB】初识 AHB 总线
AHB 与 APB、ASB同属于 AMBA 总线架构规范,该总线规范由 ARM 公司提出。 目录 一、AHB 总线 二、AHB 总线组成 三、AHB 主从通信过程 一、AHB 总线 AHB(Advanced High Performance Bus),意为高级高性能总线,能将微控制器&…...

Linux服务使用宝塔面板搭建网站,通过内网穿透实现公网访问
文章目录 前言1. 环境安装2. 安装cpolar内网穿透3. 内网穿透4. 固定http地址5. 配置二级子域名6. 创建一个测试页面 前言 宝塔面板作为简单好用的服务器运维管理面板,它支持Linux/Windows系统,我们可用它来一键配置LAMP/LNMP环境、网站、数据库、FTP等&…...
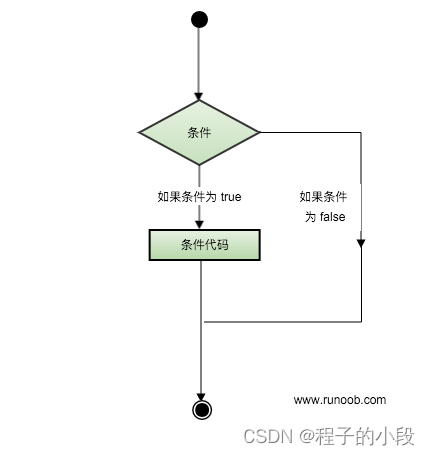
C++ 判断
判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需的)和条件为假时要执行的语句(可选的)。 下面是大多数编程语言中典型的判断结构的一般形式: 判断语句 C 编程语言…...

“解引用“空指针一定会导致段错误吗?
可能有些朋友看见这个标题第一反应是嵌入式的某些内存中,0地址也是可以被正常访问的,所以对0地址的解引用不会发生错误,但我要说的情况不是这个,而是指一个真正的空指针,不仅是c/c中的0,(void*)0,NULL,还有nullptr,一个真正的空指针. 在c语言中,想获得某结构体的成员变量相对偏…...

釉面陶瓷器皿SOR/2016-175标准上架亚马逊加拿大站
亲爱的釉面陶瓷器皿和玻璃器皿制造商和卖家,亚马逊加拿大站将执行SOR/2016-175法规。这是一份新的法规,规定了含有铅和镉的釉面陶瓷器和玻璃器皿需要满足的要求。让我们一起来看一看,为什么要实行SOR/2016-175法规?这是一个保护消…...

Redux - Redux在React函数式组件中的基本使用
文章目录 一,简介二,安装三,三大核心概念Store、Action、Reducer3.1 Store3.2 Reducer3.3 Action 四,开始函数式组件中使用4.1,引入store4.1,store.getState()方法4.3,store.dispatch()方法4.4&…...

rust学习-同时执行多Future
只用 .await 来执行future,会阻塞并发任务,直到特定的 Future 完成 join!:等待所有future完成 可事实上为什么都是res1完成后再执行res2? join! 不保证并发执行,难道只负责同步等待? 示例 [package] name = "rust_demo5" version = "0.1.0" edit…...

问道管理:旅游酒店板块逆市拉升,桂林旅游、华天酒店涨停
游览酒店板块14日盘中逆市拉升,到发稿,桂林游览、华天酒店涨停,张家界涨超8%,君亭酒店涨超5%,众信游览、云南游览涨逾4%。 音讯面上,8月10日,文旅部办公厅发布康复出境团队游览第三批名单&#…...

算法通关村第三关——数组白银
文章目录 一、删除元素1.1 原地移除所有值等于val的元素1.2 删除有序数组中的重复项 二、元素奇偶移动三、数组轮转 一、删除元素 1.1 原地移除所有值等于val的元素 LeetCode 27.移除元素 解法1:快慢指针 class Solution {public int removeElement(int[] nums, …...
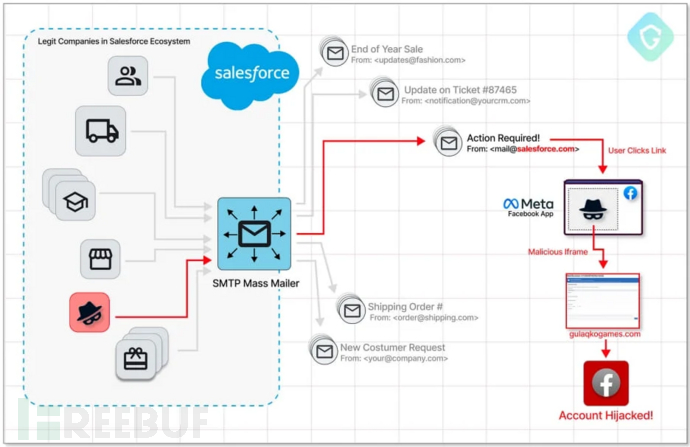
黑客利用 Facebook 漏洞,发起网络钓鱼攻击
Bleeping Computer 网站披露,网络攻击者利用 Salesforce 电子邮件服务和 SMTP 服务器中的漏洞,针对一些特定的 Facebook 账户发起复杂的网络钓鱼活动。 据悉,网络攻击者利用 Salesforce 等具有良好信誉的电子邮件网关分发网络钓鱼电子邮件&am…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...
)
内存申请和使用的场景分析(以AP->kernal->ISP为例)
在 ISP(Image Signal Processor)系统中,AP 与 ISP 之间的内存交互本质上是一个**“AP 申请可 DMA 访问的共享内存 → 内核建立映射 → 硬件寻址读写 → 同步与回收”**的过程。下面按数据流分层详细拆解。一、ISP 内存需求的特殊性 与普通应用…...
3步高效解决TranslucentTB任务栏透明化难题:完整配置指南
3步高效解决TranslucentTB任务栏透明化难题:完整配置指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否厌倦了Window…...

Python多智能体建模终极指南:用Mesa轻松构建复杂系统仿真
Python多智能体建模终极指南:用Mesa轻松构建复杂系统仿真 【免费下载链接】mesa Mesa is an open-source Python library for agent-based modeling, ideal for simulating complex systems and exploring emergent behaviors. 项目地址: https://gitcode.com/gh_…...

《关于 AI Agent 基础设施的一些奇思妙想》
目录 目录 目录 一、AI Agent 容器 问题背景 想法思路:API 中转站模式 多 Agent 切换 二、手机端操控 AI Agent(手机与电脑互联) 三、AI 开发依赖管理工具 总结 最近 AI Agent 越来越火,我作为一个重度使用者,…...