ubuntu 部署 ChatGLM-6B 完整流程 模型量化 Nvidia
ubuntu 部署 ChatGLM-6B 完整流程 模型量化 Nvidia
- 初
- 环境与设备
- 环境准备
- 克隆模型
- 代码部署 ChatGLM-6B
- 完整代码
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答
本篇文章将介绍ubuntu 部署 ChatGLM-6B 完整流程 模型量化 Nvidia GUP
初
希望能写一些简单的教程和案例分享给需要的人
环境与设备
系统:Ubuntu 22.04.2 LTS (ubuntu 就行)
设备:Nvidia GeForce RTX 4090 (英伟达 就行)
以下是一些推荐的消费级显卡:
-
Nvidia GeForce RTX 3080: RTX 3080 是一款性能出色的显卡,适用于高质量游戏和深度学习任务。它提供了强大的图形性能和 CUDA 核心,能够满足许多高性能计算需求。
-
AMD Radeon RX 6800 XT: 如果你对 AMD 的显卡感兴趣,RX 6800 XT 是一款强大的选择。它具有出色的游戏性能和计算能力,适用于多种应用场景。
-
Nvidia GeForce RTX 3070: RTX 3070 是一款性价比较高的显卡,它在性能和价格之间找到了很好的平衡。它适用于游戏、图形设计和一些中等规模的深度学习任务。
环境准备
在开始之前,确保 Ubuntu 系统已经安装了Python和必要的依赖项。
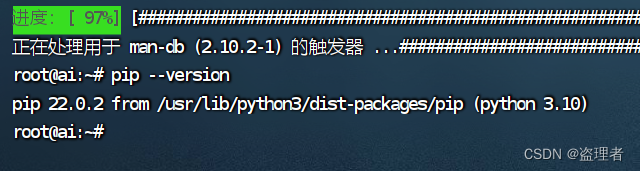
输入下面命令:判断PIP是否安装
pip --version

如果没安装,就安装 python3-pip
sudo apt update
sudo apt install python3-pip
安装完成后如下图:
克隆模型
全部都完成后,我们就可以去下载模型了
去下面这个网站,下载模型
https://huggingface.co/THUDM/chatglm2-6b-32k
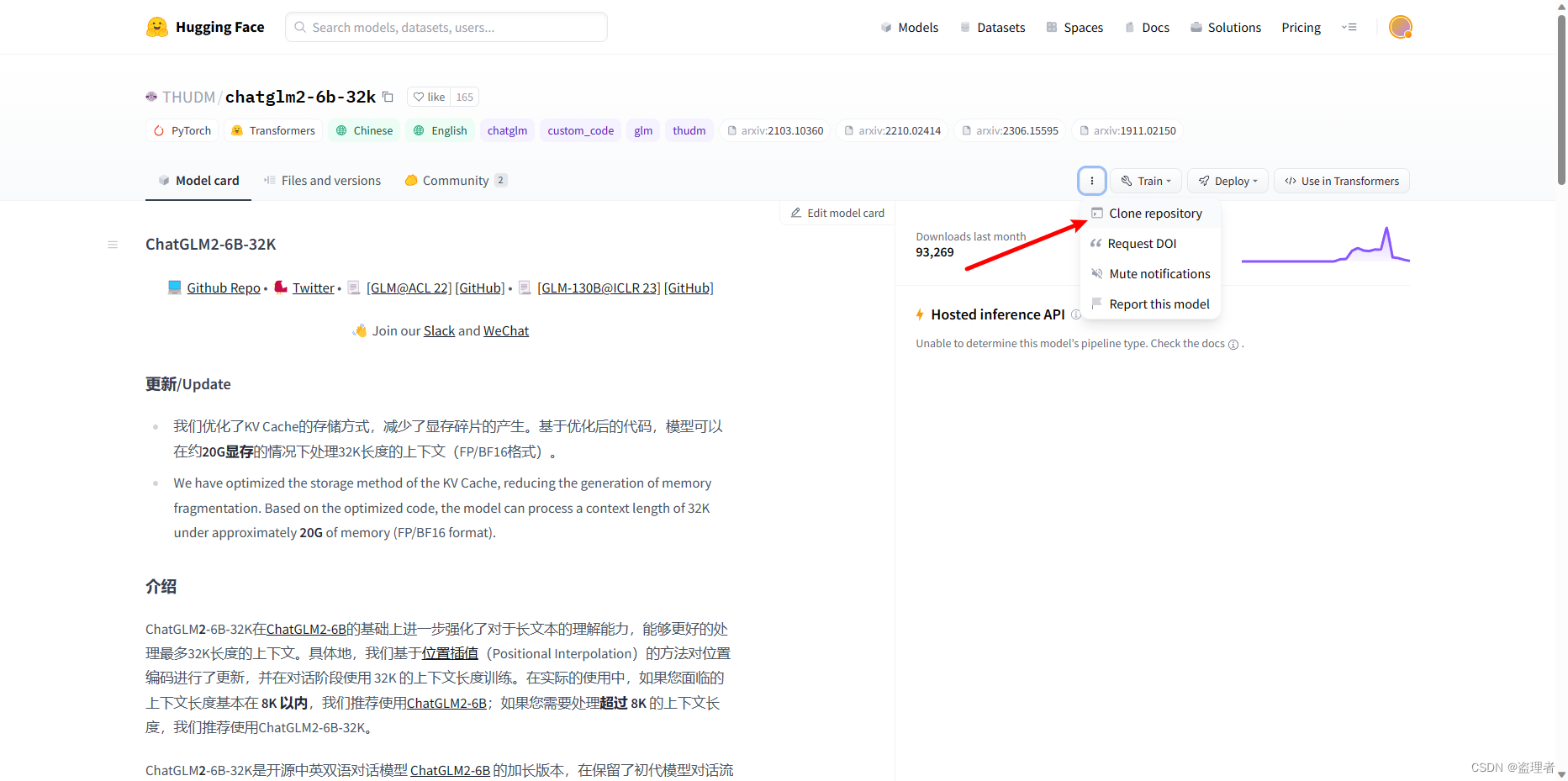
点击克隆后,我们需要使用命令:
git lfs install
git clone https://huggingface.co/THUDM/chatglm2-6b-32k
这个时候,可能会遇到报错:需要安装 git ,还有 git-lfs
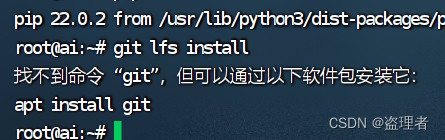
sudo apt install gitsudo apt install git-lfs这两个都安装完成后,我们再克隆,我这边会到指定的路径克隆,大家自行选择。
克隆成功后,如下图:
代码部署 ChatGLM-6B
git clone https://github.com/THUDM/ChatGLM-6B.git

代码克隆下来后,就安装环境 pytorch
PyTorch 是一个开源的机器学习框架,它提供了丰富的工具和库,用于构建和训练各种深度学习模型。它由 Facebook 的人工智能研究院(Facebook AI Research,缩写为FAIR)开发并维护,旨在为研究人员和开发者提供一个灵活、动态的平台来实现各种机器学习任务。
PyTorch 提供了一种动态计算图的机制,这意味着您可以在运行时构建、修改和调整计算图,使其更加灵活和直观。这使得 PyTorch 在实验和原型开发阶段非常有用,因为它能够快速适应不同的数据和模型结构。此外,PyTorch 还具有广泛的神经网络库、优化算法以及用于数据加载和预处理的工具。它也支持 GPU 加速,可以在 NVIDIA CUDA 上利用 GPU 进行高效的计算,加速模型训练过程。总之,PyTorch 是一个受欢迎的机器学习框架,广泛用于深度学习研究、开发和应用。它以其动态计算图、灵活性和易用性而闻名。
直接进入下面网址
https://pytorch.org/
进入页面后,翻到下一页,我这里是ubuntu 所以我这边用预览版最新的 CUDA 12.1
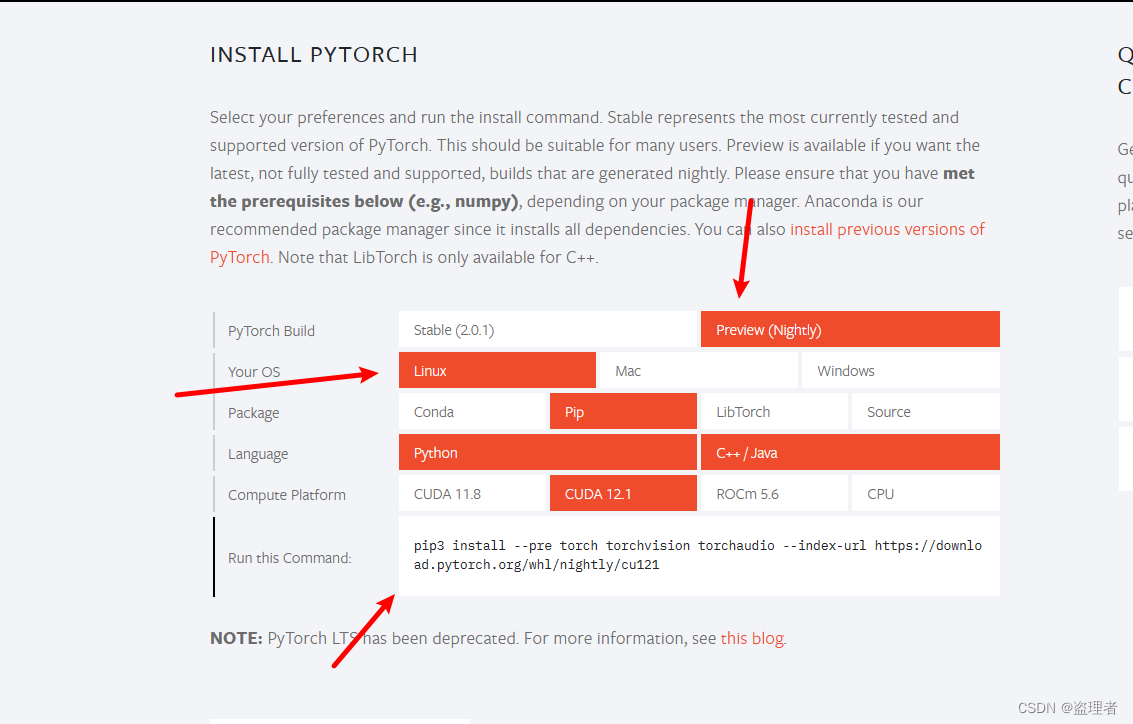
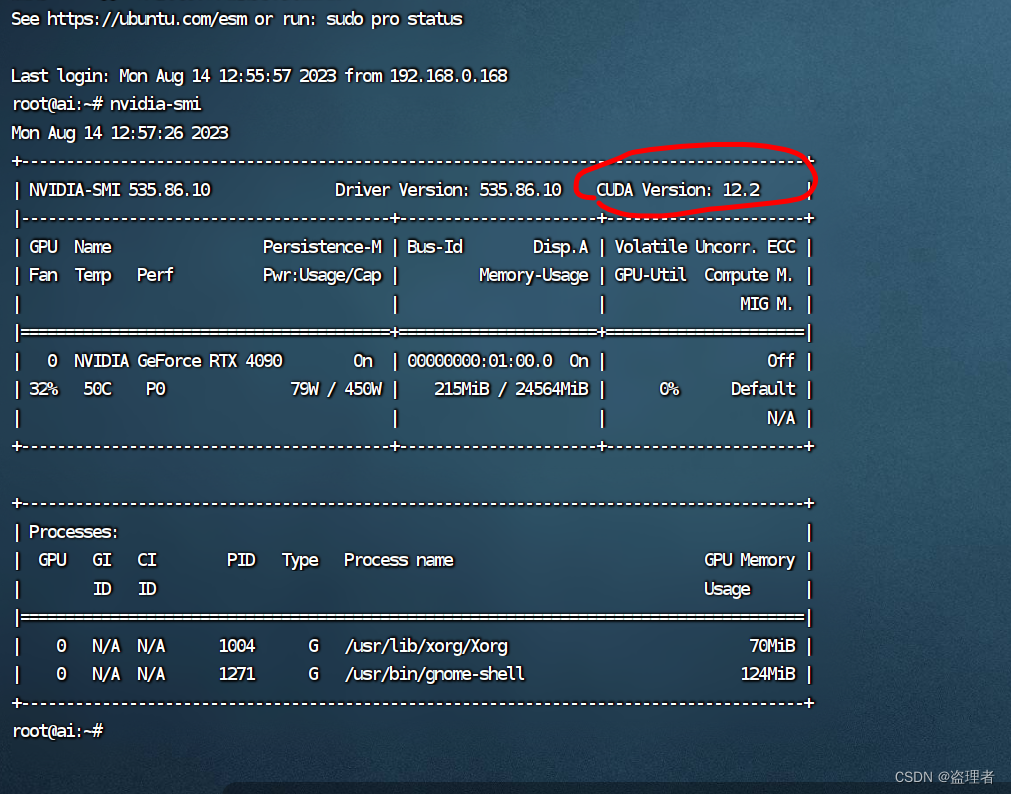
关于CUDA的支持可以通过命令 nvidia-smi 来查看
我们执行命令

pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu121
等待安装结束
都按照完成后,进入项目,我这里项目路径是这个 /home/ai/dev/code
cd /home/ai/dev/code
cd /home/ai/dev/code/ChatGLM-6B
然后安装 环境
pip install -r requirements.txt
等待这些都安装完成后,
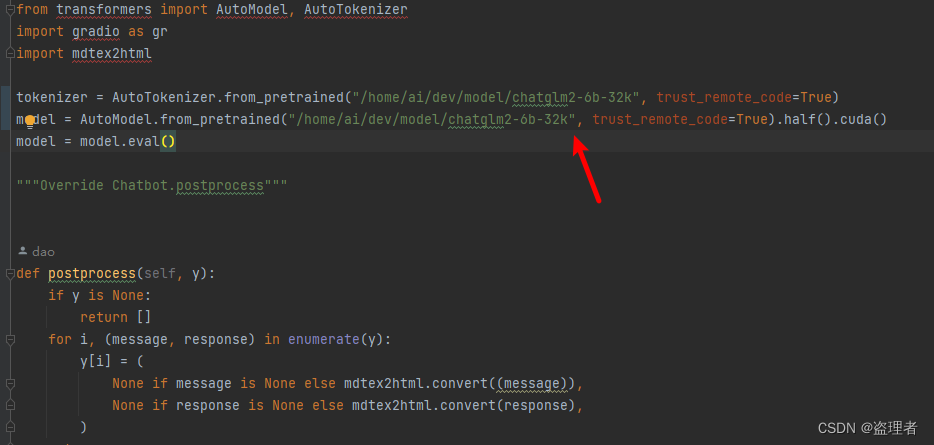
api.py 文件中的路径:
将原本的:THUDM/chatglm-6b
更换成:/home/ai/dev/model/chatglm2-6b-32k
/home/ai/dev/model/chatglm2-6b-32k

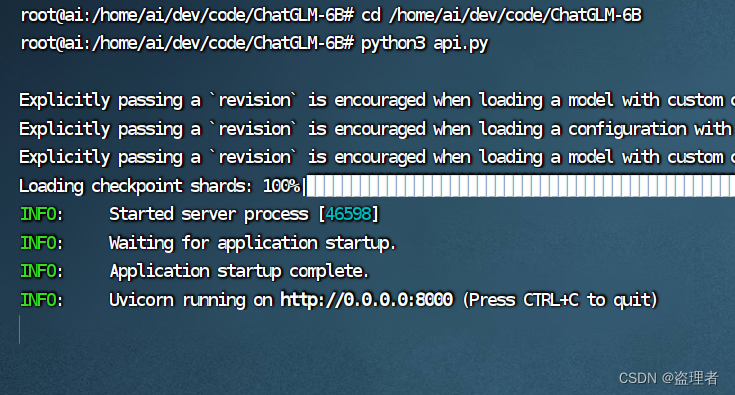
执行下面命令:
python3 api.py
测试一下:
curl -X POST "http://127.0.0.1:8000" \-H 'Content-Type: application/json' \-d '{"prompt": "你好", "history": []}'

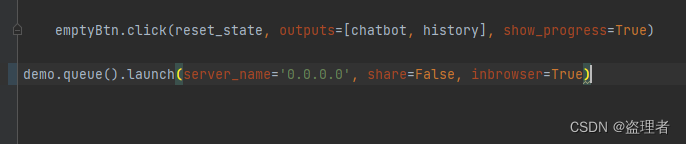
上面是 API 的效果。如果选需要 ui 版本 web_demo.py 这个文件 修改模型路径后,执行:
python3 web_demo.py
修改截图如下:
方便外网请求的修改地方如下:
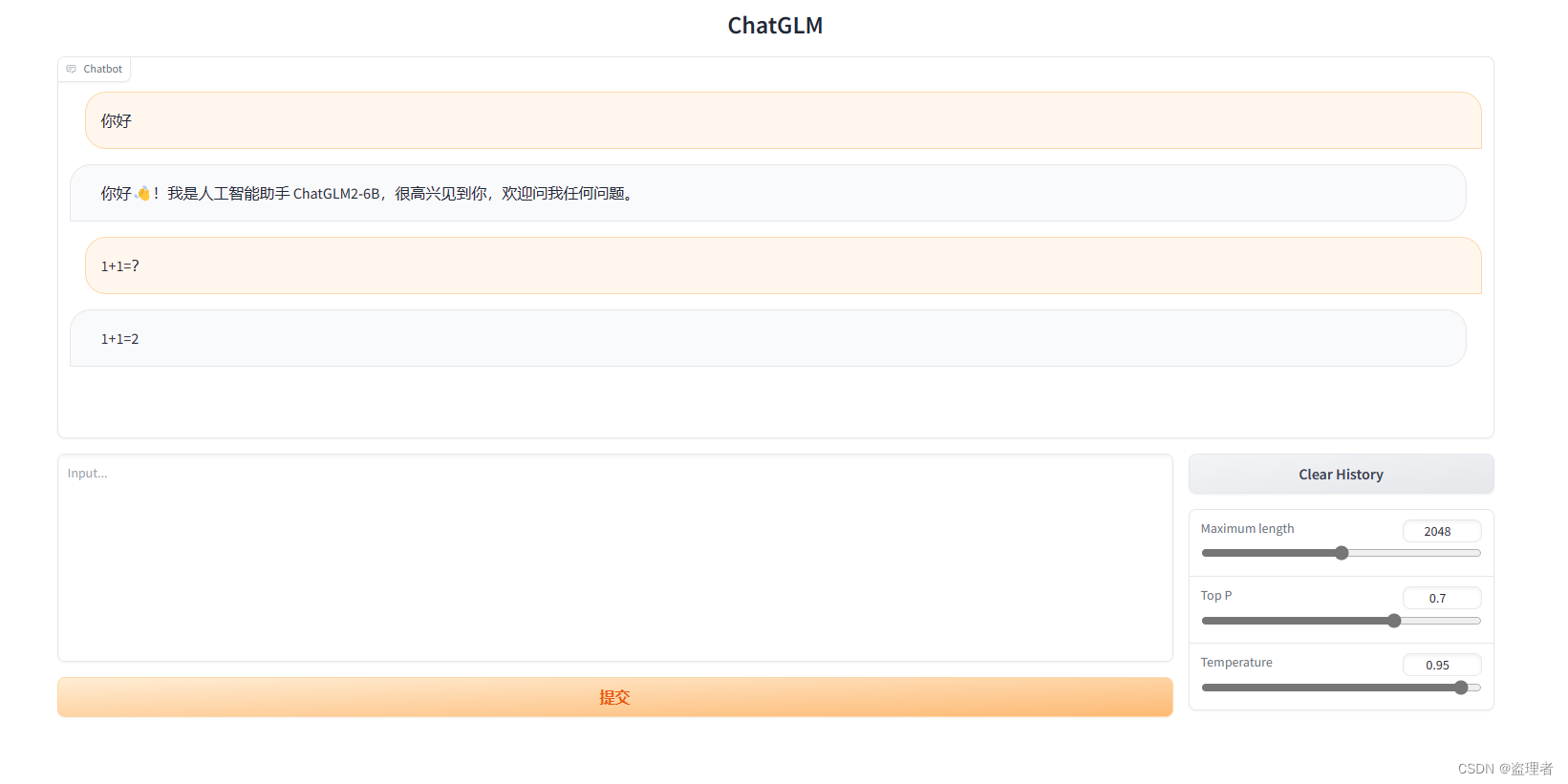
执行结果如下:
完整代码
api.py
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torchDEVICE = "cuda"
DEVICE_ID = "0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICEdef torch_gc():if torch.cuda.is_available():with torch.cuda.device(CUDA_DEVICE):torch.cuda.empty_cache()torch.cuda.ipc_collect()app = FastAPI()@app.post("/")
async def create_item(request: Request):global model, tokenizerjson_post_raw = await request.json()json_post = json.dumps(json_post_raw)json_post_list = json.loads(json_post)prompt = json_post_list.get('prompt')history = json_post_list.get('history')max_length = json_post_list.get('max_length')top_p = json_post_list.get('top_p')temperature = json_post_list.get('temperature')response, history = model.chat(tokenizer,prompt,history=history,max_length=max_length if max_length else 2048,top_p=top_p if top_p else 0.7,temperature=temperature if temperature else 0.95)now = datetime.datetime.now()time = now.strftime("%Y-%m-%d %H:%M:%S")answer = {"response": response,"history": history,"status": 200,"time": time}log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'print(log)torch_gc()return answerif __name__ == '__main__':tokenizer = AutoTokenizer.from_pretrained("/home/ai/dev/model/chatglm2-6b-32k", trust_remote_code=True)model = AutoModel.from_pretrained("/home/ai/dev/model/chatglm2-6b-32k", trust_remote_code=True).half().cuda()model.eval()uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
web_demo.py
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2htmltokenizer = AutoTokenizer.from_pretrained("/home/ai/dev/model/chatglm2-6b-32k", trust_remote_code=True)
model = AutoModel.from_pretrained("/home/ai/dev/model/chatglm2-6b-32k", trust_remote_code=True).half().cuda()
model = model.eval()"""Override Chatbot.postprocess"""def postprocess(self, y):if y is None:return []for i, (message, response) in enumerate(y):y[i] = (None if message is None else mdtex2html.convert((message)),None if response is None else mdtex2html.convert(response),)return ygr.Chatbot.postprocess = postprocessdef parse_text(text):"""copy from https://github.com/GaiZhenbiao/ChuanhuChatGPT/"""lines = text.split("\n")lines = [line for line in lines if line != ""]count = 0for i, line in enumerate(lines):if "```" in line:count += 1items = line.split('`')if count % 2 == 1:lines[i] = f'<pre><code class="language-{items[-1]}">'else:lines[i] = f'<br></code></pre>'else:if i > 0:if count % 2 == 1:line = line.replace("`", "\`")line = line.replace("<", "<")line = line.replace(">", ">")line = line.replace(" ", " ")line = line.replace("*", "*")line = line.replace("_", "_")line = line.replace("-", "-")line = line.replace(".", ".")line = line.replace("!", "!")line = line.replace("(", "(")line = line.replace(")", ")")line = line.replace("$", "$")lines[i] = "<br>"+linetext = "".join(lines)return textdef predict(input, chatbot, max_length, top_p, temperature, history):chatbot.append((parse_text(input), ""))for response, history in model.stream_chat(tokenizer, input, history, max_length=max_length, top_p=top_p,temperature=temperature):chatbot[-1] = (parse_text(input), parse_text(response)) yield chatbot, historydef reset_user_input():return gr.update(value='')def reset_state():return [], []with gr.Blocks() as demo:gr.HTML("""<h1 align="center">ChatGLM</h1>""")chatbot = gr.Chatbot()with gr.Row():with gr.Column(scale=4):with gr.Column(scale=12):user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(container=False)with gr.Column(min_width=32, scale=1):submitBtn = gr.Button("Submit", variant="primary")with gr.Column(scale=1):emptyBtn = gr.Button("Clear History")max_length = gr.Slider(0, 4096, value=2048, step=1.0, label="Maximum length", interactive=True)top_p = gr.Slider(0, 1, value=0.7, step=0.01, label="Top P", interactive=True)temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True)history = gr.State([])submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history], [chatbot, history],show_progress=True)submitBtn.click(reset_user_input, [], [user_input])emptyBtn.click(reset_state, outputs=[chatbot, history], show_progress=True)demo.queue().launch(server_name='0.0.0.0', share=False, inbrowser=True)
相关文章:
ubuntu 部署 ChatGLM-6B 完整流程 模型量化 Nvidia
ubuntu 部署 ChatGLM-6B 完整流程 模型量化 Nvidia 初环境与设备环境准备克隆模型代码部署 ChatGLM-6B完整代码 ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术&#x…...

【数据分享】2001-2022年我国省市县镇四级的逐月最高气温数据(无需转发/Shp/Excel格式)
气象数据是在各项研究中都非常常用的数据!之前我们分享过来自于国家青藏高原科学数据中心的1901-2022年1km分辨率的逐月平均气温栅格数据,以及基于该栅格数据处理的Shp和Excel格式的2001-2022年我国省市县镇四级的逐月平均气温数据(可查看之前…...
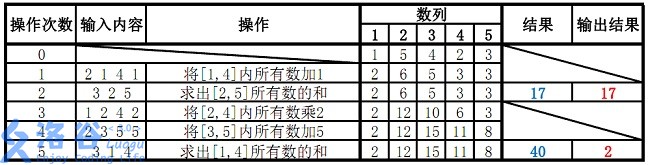
线段树-模板-区间查询-区间修改
【模板】线段树 2 传送门:https://www.luogu.com.cn/problem/P3373 题单:https://www.luogu.com.cn/training/16376#problems 题目描述 如题,已知一个数列,你需要进行下面三种操作: 将某区间每一个数乘上 x x x&a…...

微服务架构和分布式架构的区别
微服务架构和分布式架构的区别 有:1、含义不同;2、概念层面不同;3、解决问题不同;4、部署方式不同;5、耦合度不同。其中,含义不同指微服务架构是一种将一个单一应用程序开发为一组小型服务的方法ÿ…...
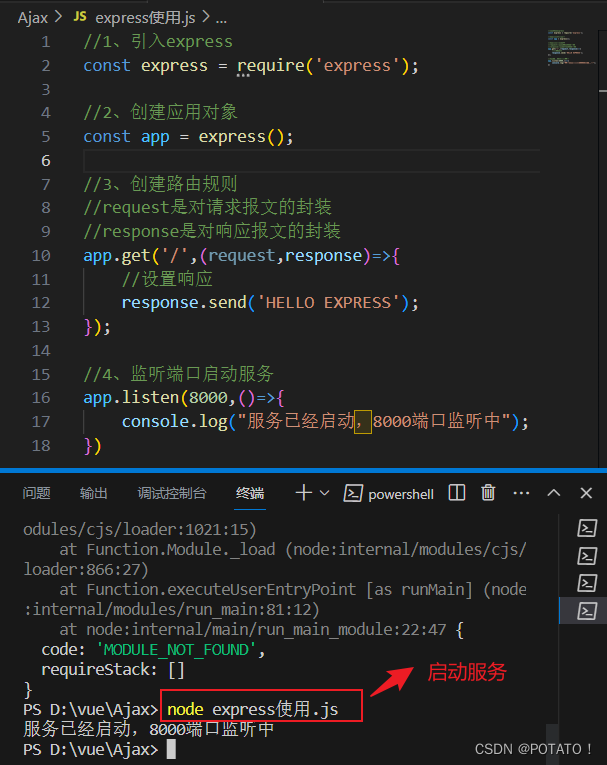
Ajax-概念、Http协议、Ajax请求及其常见问题
Ajax Ajax概念Ajax优缺点HTTP协议请求报文响应报文 Ajax案例准备工作express基本使用创建一个服务器 发送AJAX请求GET请求POST请求JSON响应 Ajax请求出现的问题IE缓存问题Ajax请求超时与网络异常处理Ajax手动取消请求Ajax重复发送请求问题 Ajax概念 AJAX 全称为Asynchronous J…...
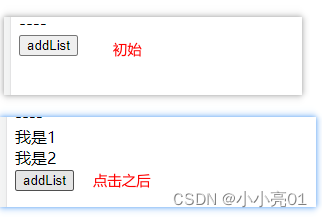
react 09之状态管理工具1 redux+ react-thunk的使用实现跨组件状态管理与异步操作
目录 react 09之状态管理工具1 redux react-thunk的使用实现跨组件状态管理与异步操作store / index.js store的入口文件index.js 在项目入口文件 引入store / actionType.js 定义action的唯一标识store / reducers / index.jsstore / actions / form.jsstore / reducers / for…...
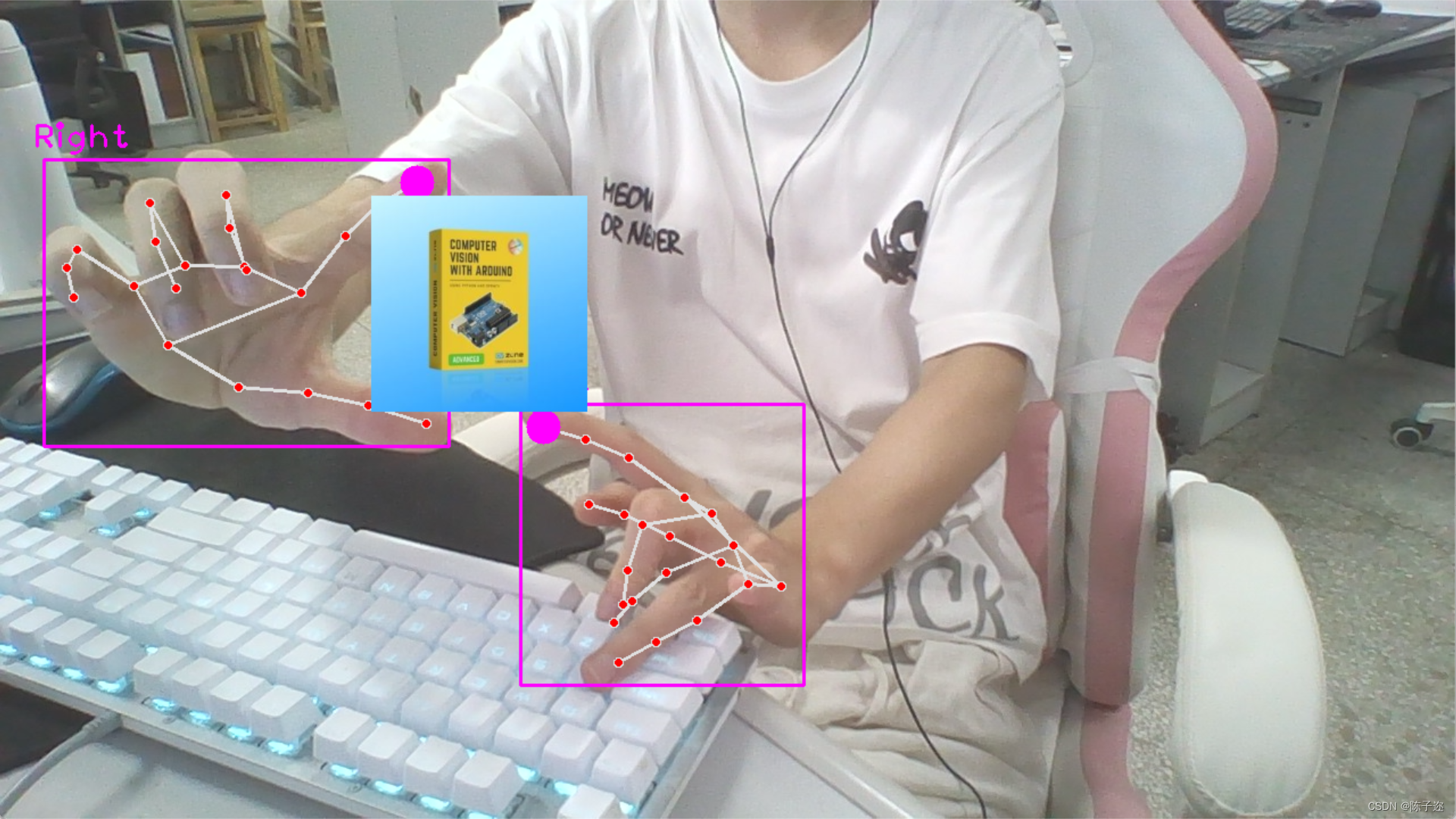
opencv实战项目 手势识别-实现尺寸缩放效果
手势识别系列文章目录 手势识别是一种人机交互技术,通过识别人的手势动作,从而实现对计算机、智能手机、智能电视等设备的操作和控制。 1. opencv实现手部追踪(定位手部关键点) 2.opencv实战项目 实现手势跟踪并返回位置信息&…...

Netty对HPACK头部压缩的支持
前言 HTTP2终于支持对头部进行压缩传输了,Netty很早就支持HTTP2了,看下Netty对HPACK的实现源码,可以对HPACK理解的更深一下。 HpackDecoder Netty内置的编解码器Http2FrameCodec专门用来对HTTP2的各种Frame进行编解码,其中就包…...

C++:替换string中的字符
1.按照位置进行替换 string的成员函数replace可以满足这种需求,其变体有很多种,请参考官方文档,以下列举常用的两种: #include <iostream> #include <string> using namespace std;int main() {string s = "hello world";s.replace(s.begin(), s.b…...

【ChatGPT】自我救赎
ChatGPT辅助学习C之【在C中如果大数据类型转小数据类型会发生什么呢?】,今天问ChatGPT一个问题,让它解析下面这个C程序: #include <iostream> #include <cstdio> using namespace std; int main() {int a;long long b532165478…...
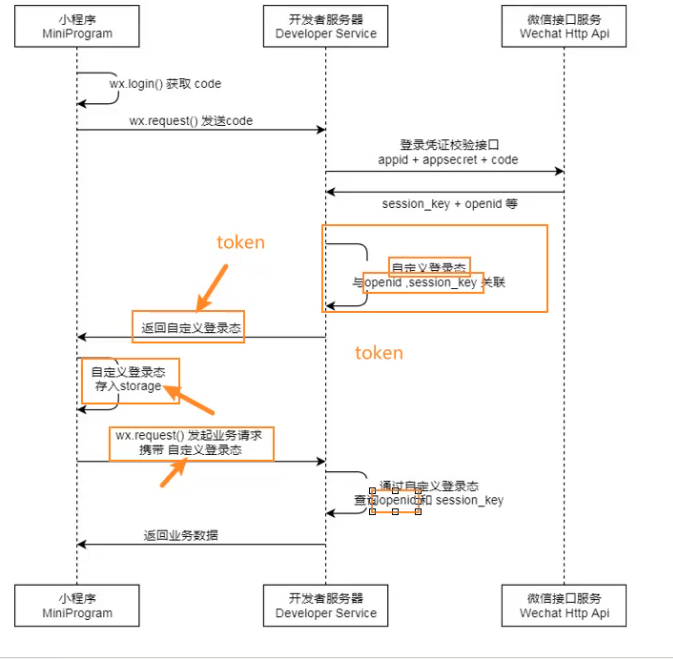
微信小程序(由浅到深)
文章目录 一. 项目基本配置1. 项目组成2. 常见的配置文件解析3. app.json全局的五大配置4.单个页面中的page配置5. App函数6.tabBar配置 二. 基本语法,事件,单位1. 语法2. 事件3. 单位 三. 数据响应式修改四 . 内置组件1. button2. image3. input4. 组件…...
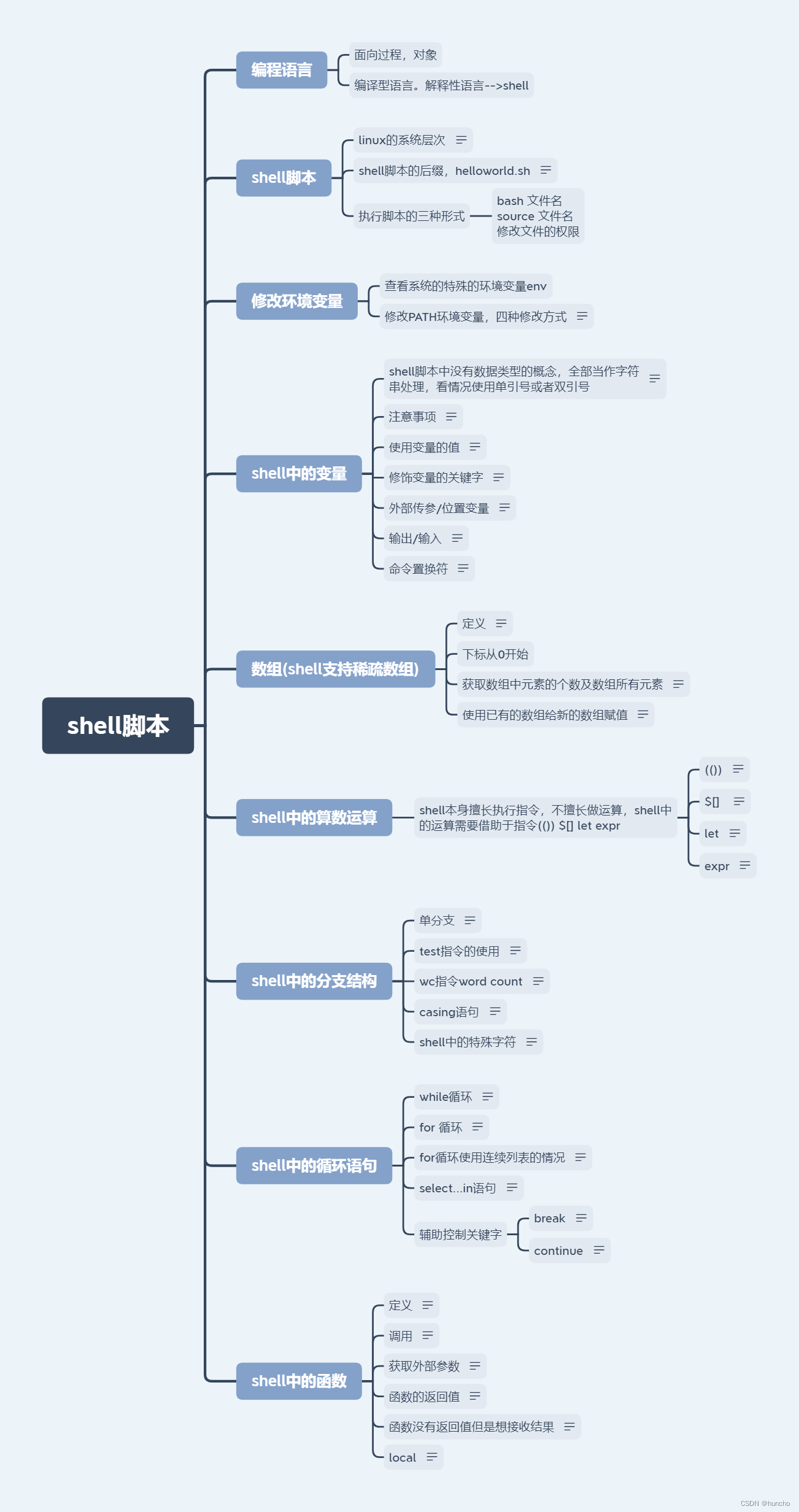
冒泡排序 简单选择排序 插入排序 快速排序
bubblesort 两个for循环,从最右端开始一个一个逐渐有序 #include <stdio.h> #include <string.h> #include <stdlib.h>void bubble(int *arr, int len); int main(int argc, char *argv[]) {int arr[] {1, 2, 3, 4, 5, 6, 7};int len sizeof(…...
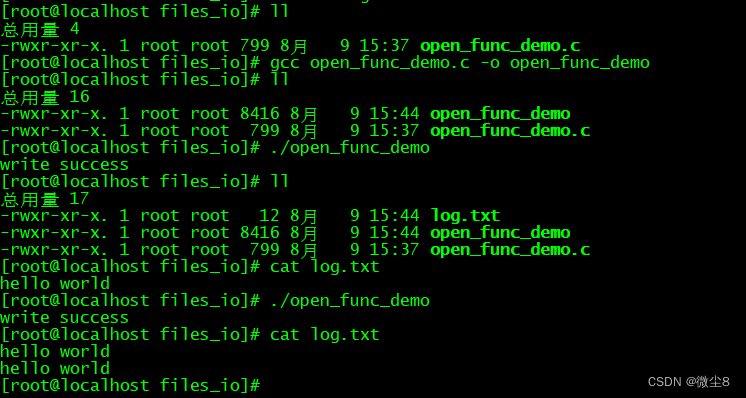
linux文件I/O之 open() 函数用法
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> typedef unsigned int mode_t ; int open(const char *pathname, int flags); int open(const char *pathname, int flags, mode_t mode); 函数功能 打开或创建一个文件 返回值 成功…...

用Java操作MySQL数据库
新建Maven项目 创建Maven项目 添加依赖 在pom.xml的标签里加上下面的内容 如果是MySQL 5.8那么的版本号是5.x.x, 例如5.1.49 如果是MySQL 8.0那么的版本号是8.x.x, 例如 8.0.28 <dependencies><!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java …...
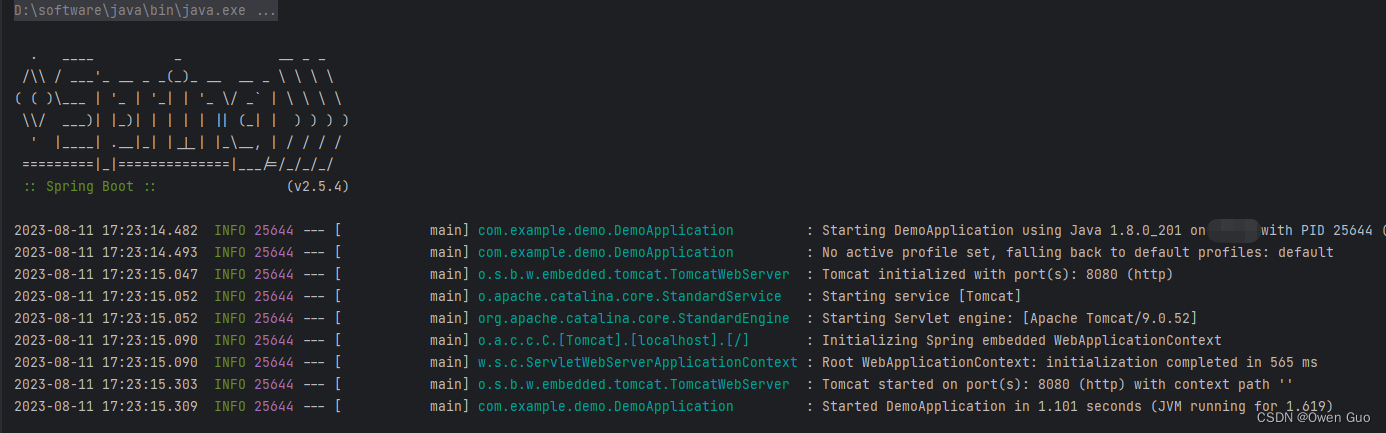
SpringBoot启动报错:java: 无法访问org.springframework.boot.SpringApplication
报错原因:jdk 1.8版本与SpringBoot 3.1.2版本不匹配 解决方案:将SpringBoot版本降到2系列版本(例如2.5.4)。如下图: 修改版本后切记刷新Meavn依赖 然后重新启动即可成功。如下图:...

Vue3 setup语法糖 解决富文本编辑器上传图片64位码过长问题 quill-image-extend-module
引言: 富文本编辑器传图片会解码成64位,非常长导致数据库会报错第一种方法:将数据库类型改成 mediumtext第二种办法:本文中的方法 说明,本周文所用语法糖为Vue3 setup语法,即<script setup> 思路 拦…...
、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换)
百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换
<!DOCTYPE html> <html><head><meta charset="UTF-8"><title></title></head><body><script>/*** * 百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换*///定义一些常量var x_PI = …...

论文浅尝 | CI4MRC:基于因果推断去除机器阅读理解中的名字偏差
笔记整理:朱珈徵,天津大学硕士,研究方向:问答 链接:https://aclanthology.org/2023.findings-acl.812/ 动机 机器阅读理解(Machine Reading Comprehension,MRC)是根据给定的文章回答…...

【校招VIP】测试计划之黑盒测试白盒测试
考点介绍: 黑盒测试&白盒测试是大厂和三四线公司校招的必考点。黑盒是以结果说话,白盒往往需要理解实现逻辑。现在商业项目的接口测试往往以白盒为主,也就是需要测试同学自己观察和修改数据库的值进行用例的测试。 但是无论采用哪种测试方…...

学习笔记整理-JS-01-语法与变量
文章目录 一、语法与变量1. 初识JavaScript2. JavaScript的历史3. JavaScript与ECMAScript的关系4. JavaScript的体系5. JavaScript的语言风格和特性 二、语法1. JavaScript的书写位置2. 认识输出语句3. REPL环境,交互式解析器4. 变量是什么5. 重点内容 一、语法与变…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...

深度解析:JetBrains IDE试用期重置机制的技术实现
深度解析:JetBrains IDE试用期重置机制的技术实现 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在软件开发工作流中,JetBrains IDE试用期管理是一个常见的技术挑战,尤其是在多…...

基于KS距离度量交通流分布偏移:提升DRL交通信号控制鲁棒性的工程实践
1. 项目概述与核心挑战在智能交通系统(ITS)领域,基于深度强化学习(DRL)的交通信号控制(Traffic Signal Control)正从研究走向实际部署。作为一名长期关注AI落地应用的从业者,我见过太…...

基于Arduino UNO的真随机数生成与数据持久化在Tambola游戏机中的应用
1. 项目概述:用Arduino UNO打造一台全自动Tambola游戏机如果你玩过或者听说过Tambola(在印度非常流行的游戏,在欧美也叫Bingo或Housie),就知道它的核心玩法是主持人从一个装有数字球的容器中随机抽取号码,玩…...

Java入门全记录
一、表达式 1. 概念 由变量、运算符、字面值组成的式子,运算后会产生一个结果。 两变量参与运算,结果类型规则 如果参与运算的变量有一个为 double 类型,结果就是 double 类型 如果没有 double ,有一个为 float 类型,结…...