论文浅尝 | CI4MRC:基于因果推断去除机器阅读理解中的名字偏差

笔记整理:朱珈徵,天津大学硕士,研究方向:问答
链接:https://aclanthology.org/2023.findings-acl.812/
动机
机器阅读理解(Machine Reading Comprehension,MRC)是根据给定的文章回答问题,基于预训练语言模型(Language Model,LM)已经取得了很大的成功。一个普遍的常识是,预训练模型越强则下游任务就越好,然而在MRC中不总是如此。本文研究了MRC模型对名字的鲁棒性。名字具有可互换性,即名字作为一个代号应具有可互换性,即对于篇章的某个名字,替换成任意名字,答案不会发生变化。基于LM的MRC模型可能会过度使用名字信息进行预测,从而导致名字表示的不可互换,称为名字偏差。在本文中,提出了一种新的MRC因果干预范式(Causal Interventional paradigm for MRC,CI4MRC)来减轻名字偏差。具体而言,首先基于结构因果模型(Structural Causal Model,SCM)分析了预训练知识、上下文表示和答案之间的因果关系,发现关于名字的预训练知识确实是一个混杂因素。其次,开发了有效的CI4MRC算法实现基于神经元感知和词元感知的调整来约束该混杂因素。实验表明,本文提出的CI4MRC有效地减轻了名字偏差,并在原始SQuAD上取得了竞争性能。此外,本文的方法对各种预训练LM具有通用性,并且对开源对抗的数据集同样具有鲁棒性。
亮点
CI4MRC的亮点主要包括:
(1) 构建一个结构因果模型,表明预训练知识本质上是一个混杂因素,导致名字的上下文表示和答案之间的虚假相关性,并且从理论上分析了因果干预MRC更好的根本原因;
(2) 设计基于神经元感知的后门调整,利用混合专家模型将前馈网络划分为多个专家模块,并将特定于名字激活的专家消除,以保证无实际意义的名字发生变化时不会对整体语义造成影响。
(3) 提出词元感知的后门调整将分类器作为额外的知识,针对前馈网络的干预对MRC任务的毒性,弥补名字表示的信息缺失,增强模型的性能。
概念及模型
CI4MRC主要由SCM的理论指导设计了有效的干预实现。基于神经元感知的后门调整,将预训练模型的前馈网络(Feed-Forward Networks,简记FFNs)参数分为多个专家,并将特定于名字的专家消除,促使MRC模型在训练阶段深入学习阅读理解能力。这一干预的实现成功地减轻了名字偏差,使模型的名字嵌入表示符合名字的可互换性,即名字的变化不会对整体语义产生影响。但是神经元感知的调整对整体上下文表示有一定损害,使名字在满足可互换性的情况下不可识别,即模型难以识别该处代表人名。因此,引入基于词元感知的后门调整将分类器作为额外的知识来弥补这一缺陷,从而保证模型的性能和鲁棒性。
(1)结构因果模型
图1是考虑了预训练模型因素的MRC结构因果模型,X表示为篇章和问题的上下文表示,K为预训练知识;
X ➡ M ⬅ K:M是一个中介变量,表示来自于文章、问题和K这三者的低维多源知识。根据调整方式的不同,M可以被理解为预训练模型的一系列特征或语义判别信息;
X ➡ Y ⬅ M:X总共以两种方式影响Y,直接路径X ➡ Y和中介路径X ➡ M ➡ Y。如果X可以完全由M表示,X ➡ Y可以忽略,但是这对于现有语言模型来说几乎是不可能的。

图1 (a) MRC因果图;(b)干预MRC,其中直接对 建模
进一步分析相关性概率和和根据后门调整及do演算得出干预后概率,并经过图2中实验的验证表明对x进行干预,阻止预训练中有关名字的知识影响x的表示,能避免名字偏差。

图2 对干预和不干预两者差异的案例研究
(2)基于神经元感知的调整模块
FFNs构成了近三分之二的模型参数,可被视为存储了大量的知识。基于 FFNs 的稀疏激活特性,首先对其中的神经元进行参数分割,将经常同时激活的神经元组合在一起,再将其参数分割构成各个专家。首先构造一个图,一个节点被表示为一个神经元,每一条边的值由共激活信息计算,然后通过图划分算法进行分割。对于FFN中的权重矩阵通过一个排列矩阵来实现。专家选择通过一个多层感知机为每组神经元打分,得到最终结果。应用归一化加权几何平均(Normalized Weighted Geometric Mean,NWGM)将由外部对概率求和转化为先由内部求和再计算概率。值得注意的是,因为稀疏激活现象被证明出现在Transformer架构的预训练模型的FFNs中,所以基于神经元感知的调整模块可以应用于大多数基于Transformer的预训练语言模型中。

(3)知识图谱嵌入模型适用性
为了弥补掩码造成的信息损失并进一步提高MRC模型的性能,本小节提出了词元感知的调整模块以提供额外的知识。在MRC任务中,大多数主流的预训练模型使用一个分类器进行预测,因此分类器可以看作是经过提炼的知识,其整体调整为:

将神经元感知的调整模块和词元感知的调整模块结合起来作为整体去偏方法,在词元感知的调整之后再应用神经元感知的调整,使名字表示在满足可互换性的同时具备可识别性。因此,总体的调整为:

实验
本节在两个偏差基准上进行了实验来评估本文的去偏见方法,分别是SQuAD及其变体和用于个人名字偏差的模板测试。实验也在公开的SQuAD对抗数据集上对各个模型进行了测试以进一步验证模型的鲁棒性,分别为Adversarial SQuAD数据集和Textflint数据集。
评价指标包括两类,分别为准确率指标,即EM分数和F1分数,以及偏差程度指标,即刻板印象分数(StereoType Score,ST分数)和名字敏感度(Name Fragility,NF),其中偏差程度指标越接近0表明模型受偏差影响更小。



图3 实验结果
实验结果如图3所示,CI4MRC在各个基线上的性能都得到了持续的提高,与其他去偏方法相比取得了最好的成绩。和之间的巨大差距反映出他们的预测高度偏向于名字。特别是在XLNet的情况下,的EM得分为80.10%,而的EM得分为40.74%,下降了几乎一半。与XLNet相比,BERT受名字偏差的影响较小,从78.29%下降到44.26%。CI4MRC和R-LACE都显著提高了模型的性能。然而,R-LACE倾向于从模型表示中删除所有名字信息,这是一种消除名字偏差的激进方法。深入观察Template的结果,BERT的性能低于XLNet,说明模型本身的阅读理解能力也很关键。其他基于BERT的去偏差方法的性能不如XLNet,这表明BERT可能很难减轻名字偏差。虽然CI4MRC在这一点上与它们相似,但性能提升更大。ST分数进一步证明BERT中的名字偏差是顽固的。值得注意的是,BERT和XLNet之间的NF和NF top-5差异较大(分别为36.00%和24.28%),说明XLNet比BERT更健壮。
进一步,使用模板示例进行案例研究。本文对EM平均得分之间的差距进行了排名,并列出了排名前六的名字。XLNet 的差距非常大,说明该模型在预训练LM中存在名字先验。CI4MRC将差距缩小到很小的程度,表明本文的模型确实减轻了名字偏差。

进行消融研究来验证神经元调整和词元调整的效果。结果如表所示。w/o表示去除对应模块。词元调整的去偏效果比神经元调整的去偏效果弱得多。然而,词元调整可以恢复神经元调整对MRC任务造成的损害,提高了模型的准确性,而单独的神经元感知调整在原始测试集上的性能降低。

总结
本文提出了一个新的因果干预范式CI4MRC来解决MRC中的名字偏差。关于名字的预训练知识是限制鲁棒性表现的混杂因素。具体来说,本文基于MRC系统中因果关系的结构因果模型,从理论上分析了预训练模型中有关名字的知识是导致模型产生名字偏差并影响模型鲁棒性的混杂因素。设计了基于神经元感知和词元感知的后门调整,对模型进行因果干预,在不损害模型原本上下文表示性能的前提下,去除名字偏差的不良影响。
实验表明,CI4MRC在各种名称偏差数据集上实现了所有基线的最佳去偏性能。
分析表明,两种调整相结合,既能有效缓解名字偏差,又能提高模型的准确率。本文认为CI4MRC提供了一种替代方案,可以在许多下游任务(例如,问答)中提高模型的鲁棒性。本文的工作仅限于最常见的名字名单,这些名字在美国具有很高的代表性。在未来的工作中,本文将考虑将实验扩展到更广泛的名称,并寻求因果干预的其他实现以获得更好的性能。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
相关文章:
论文浅尝 | CI4MRC:基于因果推断去除机器阅读理解中的名字偏差
笔记整理:朱珈徵,天津大学硕士,研究方向:问答 链接:https://aclanthology.org/2023.findings-acl.812/ 动机 机器阅读理解(Machine Reading Comprehension,MRC)是根据给定的文章回答…...

【校招VIP】测试计划之黑盒测试白盒测试
考点介绍: 黑盒测试&白盒测试是大厂和三四线公司校招的必考点。黑盒是以结果说话,白盒往往需要理解实现逻辑。现在商业项目的接口测试往往以白盒为主,也就是需要测试同学自己观察和修改数据库的值进行用例的测试。 但是无论采用哪种测试方…...

学习笔记整理-JS-01-语法与变量
文章目录 一、语法与变量1. 初识JavaScript2. JavaScript的历史3. JavaScript与ECMAScript的关系4. JavaScript的体系5. JavaScript的语言风格和特性 二、语法1. JavaScript的书写位置2. 认识输出语句3. REPL环境,交互式解析器4. 变量是什么5. 重点内容 一、语法与变…...

PHP之PHPExcel
include PHPExcel.php; include PHPExcel/Writer/Excel2007.php; //或者include PHPExcel/Writer/Excel5.php; 用于输出.xls的 //创建一个excel $objPHPExcel new PHPExcel(); // 输出Excel表格到浏览器下载 header(Content-Type: application/vnd.ms-excel); header(Content-…...
Redis系列(一):深入了解Redis数据类型和底层数据结构
Redis有以下几种常用的数据类型: redis数据是如何组织的 为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。 Redis全局哈希表(Global Hash Table)是指在Redis数据库内部用于存储所有键值对的主要数据结构。…...

javaScript:如何获取html中的元素对象
目录 前言: 方法 1.通过id获取元素 2.通过标签名获取元素 3.通过类名class获取元素 获取body的方法 1.document.getElementsByTagName(body)[0] 2.document.body 相关代码 前言: 通过获取HTML中的元素对象,JavaScript可以对网页进行动…...

面试总结-webpack/git
说说你对webpack的理解 webpack 是一个静态模块打包器,整个打包过程就像是一条生产线,把资源从入口放进去,经过一系列的加工(loader),最终转换成我们想要的结果,整个加工过程还会有监控&#x…...

深入解析美颜SDK:算法、效果与实现
在当今数字化社会中,图像处理和美化技术已经成为了许多应用领域的重要组成部分,尤其在视频直播领域,美颜技术更是无处不在。直播美颜SDK作为一种集成的软件工具包,为开发者和应用提供了强大的美颜功能。 一、算法原理 磨皮算法…...

ChatGPT Plus和ChatGPT对比
模型规模更大,参数数量超过6万亿,比ChatGPT大很多训练数据更丰富,包括不同语言、领域和类型的数据语言理解和生成能力更强,能够更准确地理解和生成文本可解释性和可控性更好,支持更多的调参和控制参数,生成…...
计算机网络 运输层 TCP连接建立、释放
三报文而不是两报文...
npm run xxx 的时候发生了什么?(以npm run dev举例说明)
文章目录 一、去package.json寻找scripts对应的命令二、去node_modules寻找vue-cli-service三、从package-lock.json获取.bin的软链接1. bin目录下的那些软连接存在于项目最外层的package-lock.json文件中。2.vue-cli-service文件的作用3.npm install 的作用 总结 一、去packag…...
图解结构体大小和位域例子
struct A {short a; char b; int c : 1; char d : 4; short e : 7; }; 备注:蓝色:表示占一个符号位空间红色:表示补齐其他颜色:实际最大值所占空间 (1)图解例1 st…...

游戏行业实战案例 5 :玩家在线分布
【面试题】某游戏数据后台设有“登录日志”和“登出日志”两张表。 「登录日志」记录各玩家的登录时间和登录时的角色等级。 「登出日志」记录各玩家的登出时间和登出时的角色等级。 其中,「角色 id 」字段唯一识别玩家。 游戏开服前两天( 2022-08-13 至…...
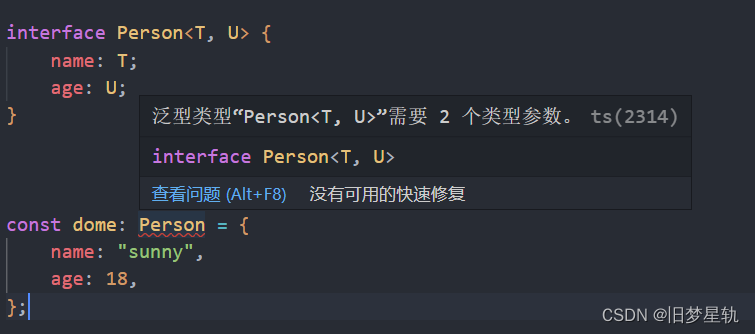
TypeScript 关于对【泛型】的定义使用解读
目录 概念导读泛型函数多个泛型参数泛型约束泛型别名泛型接口泛型类总结: 概念导读 泛型(Generics)是指在定义函数、接口或类的时候,不预先指定具体的类型,而在使用的时候再指定类型的一种特性。使用泛型 可以复用类型…...

盛元广通食品药品检验检测实验室LIMS系统
随着食品与制药行业法规标准的日益提高和国家两化融合的不断推进,为保障检验工作的客观、公正及科学性,确保制药企业对于生产、实验室、物流、管理的信息化和智能化需求越来越明确,为确保新品可及时得到科学准确的检测检验结果,盛…...
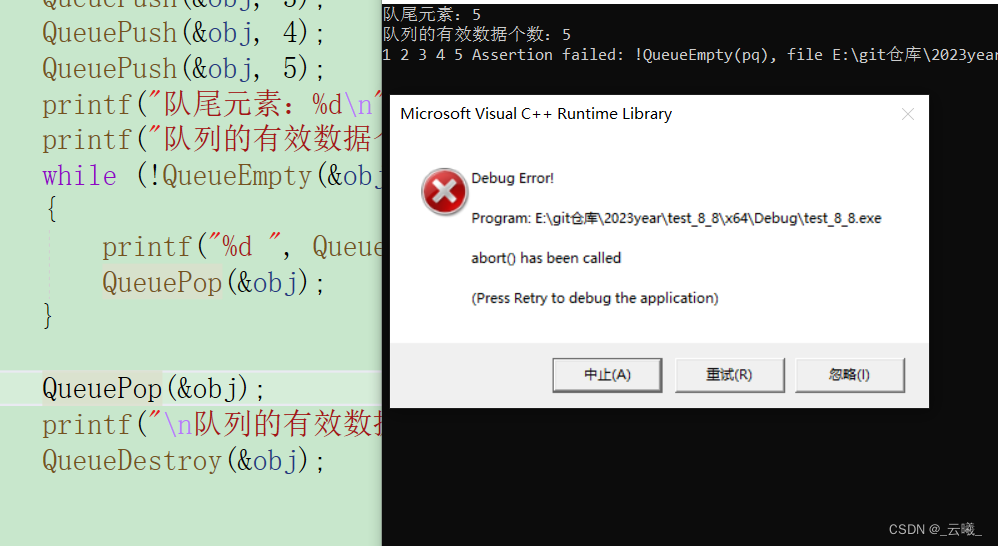
【数据结构】-- 栈和队列
🐇 🔥博客主页: 云曦 📋系列专栏:数据结构 💨吾生也有涯,而知也无涯 💛 感谢大家👍点赞 😋关注📝评论 文章目录 前言一、栈📙1.1 栈…...

使用SpringAop切面编程通过Spel表达式实现Controller权限控制
目录 参考一、概念SpEL表达式 二、开发引入包定义注解定义切面定义用户上下文 三、测试新建Service在方法上注解新建Service在类上注解运行 参考 SpringBoot:SpEL让复杂权限控制变得很简单 一、概念 对于在Springboot中,利用自定义注解切面来实现接口…...
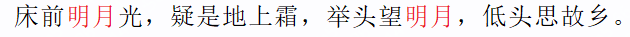
Flutter:简单搞一个内容高亮
内容高亮并不陌生,特别是在搜索内容页面,可以说四处可见,就拿掘金这个应用而言,针对某一个关键字,我们搜索之后,与关键字相同的内容,则会高亮展示,如下图所示: 如上的效果…...

2023/08/10
文章目录 一、计算属性传参二、小程序、h5跳转其他平台授权三、封装popup弹窗四、实现保存海报五、下载图片和复制分享链接 一、计算属性传参 计算属性的值往往通过一个回调函数返回,但是这个回调函数是无法传递参数的,要想实现计算属性传参可以通过闭包…...
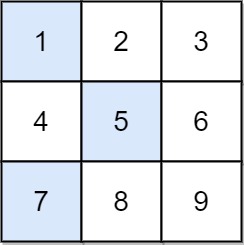
LeetCode 1289. 下降路径最小和 II:通俗易懂地讲解O(n^2) + O(1)的做法
【LetMeFly】1289.下降路径最小和 II:通俗易懂地讲解O(n^2) O(1)的做法 力扣题目链接:https://leetcode.cn/problems/minimum-falling-path-sum-ii/ 给你一个 n x n 整数矩阵 arr ,请你返回 非零偏移下降路径 数字和的最小值。 非零偏移下…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...

MaxEnt建模总失败?别急着换数据,先检查ArcGIS裁剪栅格这1个像素的坑
MaxEnt建模失败?ArcGIS栅格裁剪的1像素陷阱与精准修复指南当你花费数小时整理好WorldClim气候数据、本地DEM高程和物种分布数据,满心期待地点击MaxEnt的运行按钮时,屏幕上突然跳出"Error projecting, two layers have different geograp…...