Spark(39):Streaming DataFrame 和 Streaming DataSet 输出
目录
0. 相关文章链接
1. 输出的选项
2. 输出模式(output mode)
2.1. Append 模式(默认)
2.2. Complete 模式
2.3. Update 模式
2.4. 输出模式总结
3. 输出接收器(output sink)
3.1. file sink
3.2. kafka sink
3.2.1. 以 Streaming 方式输出数据
3.2.2. 以 batch 方式输出数据
3.3. console sink
3.4. memory sink
3.5. foreach sink
3.6. ForeachBatch Sink
0. 相关文章链接
Spark文章汇总
1. 输出的选项
一旦定义了最终结果DataFrame / Dataset,剩下的就是开始流式计算。为此,必须使用返回的 DataStreamWriter Dataset.writeStream()。
需要指定一下选项:
- 输出接收器的详细信息:数据格式,位置等。
- 输出模式:指定写入输出接收器的内容。
- 查询名称:可选,指定查询的唯一名称以进行标识。
- 触发间隔:可选择指定触发间隔。如果未指定,则系统将在前一处理完成后立即检查新数据的可用性。如果由于先前的处理尚未完成而错过了触发时间,则系统将立即触发处理。
- 检查点位置:对于可以保证端到端容错的某些输出接收器,请指定系统写入所有检查点信息的位置。这应该是与HDFS兼容的容错文件系统中的目录。
2. 输出模式(output mode)
2.1. Append 模式(默认)
默认输出模式, 仅仅添加到结果表的新行才会输出。采用这种输出模式, 可以保证每行数据仅输出一次。在查询过程中, 如果没有使用 watermask 机制, 则不能使用聚合操作。 如果使用了 watermask 机制, 则只能使用基于 event-time 的聚合操作。watermask 用于高速 append 模式如何输出不会再发生变动的数据。 即只有过期的聚合结果才会在 Append 模式中被“有且仅有一次”的输出。
2.2. Complete 模式
每次触发, 整个结果表的数据都会被输出。 仅仅聚合操作才支持。同时该模式使用 watermask 无效。
2.3. Update 模式
该模式在 从 spark 2.1.1 可用. 在处理完数据之后, 该模式只输出相比上个批次变动的内容(新增或修改)。如果没有聚合操作, 则该模式与 append 模式一样。如果有聚合操作, 则可以基于 watermast 清理过期的状态。
2.4. 输出模式总结
不同的查询支持不同的输出模式
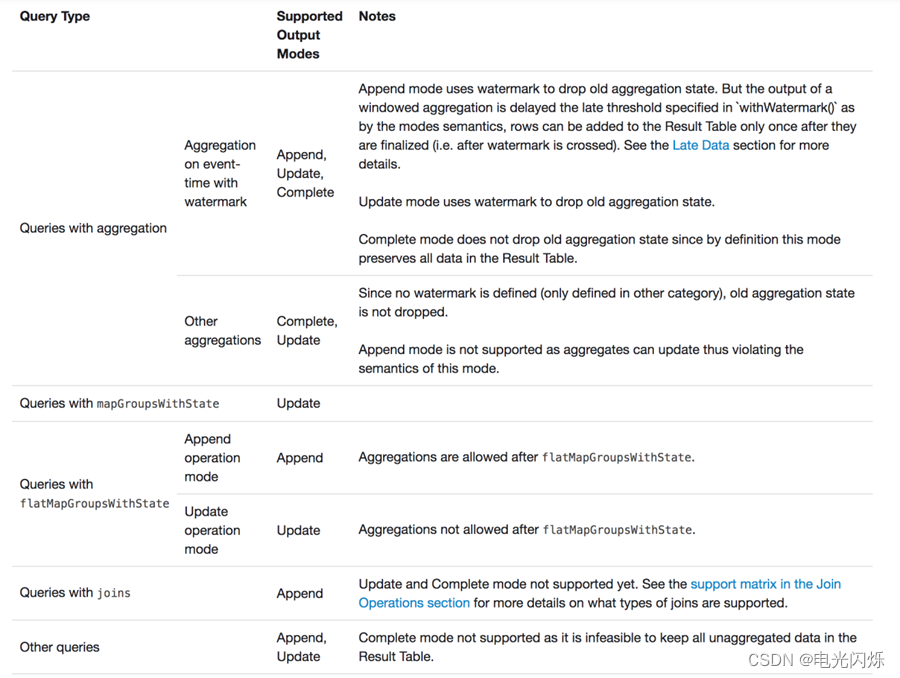
3. 输出接收器(output sink)
spark 提供了几个内置的 output-sink,不同 output sink 所适用的 output mode 不尽相同:
| Sink | Supported Output Modes | Options | Fault-tolerant | Notes |
| File Sink | Append | path: path to the output directory, must be specified. For file-format-specific options, see the related methods in DataFrameWriter (Scala/Java/Python/R). E.g. for “parquet” format options see DataFrameWriter.parquet() | Yes (exactly-once) | Supports writes to partitioned tables. Partitioning by time may be useful. |
| Kafka Sink | Append, Update, Complete | See the Kafka Integration Guide | Yes (at-least-once) | More details in the Kafka Integration Guide |
| Foreach Sink | Append, Update, Complete | None | Depends on ForeachWriter implementation | More details in the next section |
| ForeachBatch Sink | Append, Update, Complete | None | Depends on the implementation | More details in the next section |
| Console Sink | Append, Update, Complete | numRows: Number of rows to print every trigger (default: 20) truncate: Whether to truncate the output if too long (default: true) | No | |
| Memory Sink | Append, Complete | None | No. But in Complete Mode, restarted query will recreate the full table. | Table name is the query name. |
3.1. file sink
存储输出到目录中 仅仅支持 append 模式
需求: 把单词和单词的反转组成 json 格式写入到目录中。
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.sql.Timestampobject StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 设置数据源,并接收数据val lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load// 数据计算val words: DataFrame = lines.as[String].flatMap((line: String) => {line.split("\\W+").map((word: String) => {(word, word.reverse)})}).toDF("原单词", "反转单词")// 结果输出words.writeStream.outputMode("append").format("json") // 支持 "orc", "json", "csv".option("path", "./filesink") // 输出目录.option("checkpointLocation", "./ck1") // 必须指定 checkpoint 目录.start.awaitTermination()// 关闭执行环境spark.stop()}
}输出的数据:
{"原单词":"abc","反转单词":"cba"}
3.2. kafka sink
将 wordcount 结果写入到 kafka
写入到 kafka 的时候应该包含如下列:
| Column | Type |
| key (optional) | string or binary |
| value (required) | string or binary |
| topic (optional) | string |
注意:
- 如果没有添加 topic option 则 topic 列必须有.
- kafka sink 三种输出模式都支持
3.2.1. 以 Streaming 方式输出数据
这种方式使用流的方式源源不断的向 kafka 写入数据:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.sql.Timestampobject StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 设置数据源,并接收数据val lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load// 数据计算val words = lines.as[String].flatMap((_: String).split("\\W+")).groupBy("value").count().map((row: Row) => row.getString(0) + "," + row.getLong(1)).toDF("value") // 写入数据时候, 必须有一列 "value"words.writeStream.outputMode("update").format("kafka").trigger(Trigger.ProcessingTime(0)).option("kafka.bootstrap.servers", "bigdata1:9092,bigdata2:9092,bigdata3:9092") // kafka 配置.option("topic", "update") // kafka 主题.option("checkpointLocation", "./ck1") // 必须指定 checkpoint 目录.start.awaitTermination()// 关闭执行环境spark.stop()}
}3.2.2. 以 batch 方式输出数据
这种方式输出离线处理的结果, 将已存在的数据分为若干批次进行处理. 处理完毕后程序退出:
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.sql.Timestampobject StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._val wordCount: DataFrame = spark.sparkContext.parallelize(Array("hello hello abc", "abc, hello")).toDF("word").groupBy("word").count().map(row => row.getString(0) + "," + row.getLong(1)).toDF("value") // 写入数据时候, 必须有一列 "value"wordCount.write // batch 方式.format("kafka").option("kafka.bootstrap.servers", "bigdata1:9092,bigdata2:9092,bigdata3:9092") // kafka 配置.option("topic", "update") // kafka 主题.save()// 关闭执行环境spark.stop()}
}
3.3. console sink
主要用于测试数据输出
3.4. memory sink
该 sink 也是用于测试, 将其统计结果全部输入内中指定的表中, 然后可以通过 sql 与从表中查询数据。
如果数据量非常大, 可能会发送内存溢出:
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.sql.Timestamp
import java.util.{Timer, TimerTask}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 设置数据源,并接收数据val lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).loadval words: DataFrame = lines.as[String].flatMap((_: String).split("\\W+")).groupBy("value").count()val query: StreamingQuery = words.writeStream.outputMode("complete").format("memory") // memory sink.queryName("word_count") // 内存临时表名.start// 测试使用定时器执行查询表val timer: Timer = new Timer(true)val task: TimerTask = new TimerTask {override def run(): Unit = spark.sql("select * from word_count").show}timer.scheduleAtFixedRate(task, 0, 2000)query.awaitTermination()// 关闭执行环境spark.stop()}
}3.5. foreach sink
foreach sink 会遍历表中的每一行, 允许将流查询结果按开发者指定的逻辑输出;把 wordcount 数据写入到 mysql。
注意(需要在依赖中添加MySQL的驱动依赖):
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.27</version>
</dependency>
建表语句如下所示:
create database ss;
use ss;
create table word_count
(word varchar(255) primary key not null,count bigint not null
);
代码示例如下:
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, ForeachWriter, Row, SparkSession}import java.sql.{Connection, DriverManager, PreparedStatement, Timestamp}
import java.util.{Timer, TimerTask}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 设置数据源,并接收数据val lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).loadval wordCount: DataFrame = lines.as[String].flatMap((_: String).split("\\W+")).groupBy("value").count()val query: StreamingQuery = wordCount.writeStream.outputMode("update")// 使用 foreach 的时候, 需要传递ForeachWriter实例, 三个抽象方法需要实现. 每个批次的所有分区都会创建 ForeeachWriter 实例.foreach(new ForeachWriter[Row] {var conn: Connection = _var ps: PreparedStatement = _var batchCount = 0// 一般用于 打开链接. 返回 false 表示跳过该分区的数据,override def open(partitionId: Long, epochId: Long): Boolean = {println("open ..." + partitionId + " " + epochId)Class.forName("com.mysql.jdbc.Driver")conn = DriverManager.getConnection("jdbc:mysql://hadoop201:3306/ss", "root", "aaa")// 插入数据, 当有重复的 key 的时候更新val sql = "insert into word_count values(?, ?) on duplicate key update word=?, count=?"ps = conn.prepareStatement(sql)conn != null && !conn.isClosed && ps != null}// 把数据写入到连接override def process(value: Row): Unit = {println("process ...." + value)val word: String = value.getString(0)val count: Long = value.getLong(1)ps.setString(1, word)ps.setLong(2, count)ps.setString(3, word)ps.setLong(4, count)ps.execute()}// 用户关闭连接override def close(errorOrNull: Throwable): Unit = {println("close...")ps.close()conn.close()}}).startquery.awaitTermination()// 关闭执行环境spark.stop()}
}3.6. ForeachBatch Sink
ForeachBatch Sink 是 spark 2.4 才新增的功能, 该功能只能用于输出批处理的数据。将统计结果同时输出到本地文件和 mysql 中。
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, ForeachWriter, Row, SparkSession}import java.sql.{Connection, DriverManager, PreparedStatement, Timestamp}
import java.util.{Properties, Timer, TimerTask}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 设置数据源,并接收数据val lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).loadval wordCount: DataFrame = lines.as[String].flatMap(_.split("\\W+")).groupBy("value").count()val props: Properties = new Properties()props.setProperty("user", "root")props.setProperty("password", "aaa")val query: StreamingQuery = wordCount.writeStream.outputMode("complete").foreachBatch((df: Dataset[Row], batchId: Long) => { // 当前分区id, 当前批次idif (df.count() != 0) {df.cache()df.write.json(s"./$batchId")df.write.mode("overwrite").jdbc("jdbc:mysql://hadoop201:3306/ss", "word_count", props)}}).start()query.awaitTermination()// 关闭执行环境spark.stop()}
}注:其他Spark相关系列文章链接由此进 -> Spark文章汇总
相关文章:
Spark(39):Streaming DataFrame 和 Streaming DataSet 输出
目录 0. 相关文章链接 1. 输出的选项 2. 输出模式(output mode) 2.1. Append 模式(默认) 2.2. Complete 模式 2.3. Update 模式 2.4. 输出模式总结 3. 输出接收器(output sink) 3.1. file sink 3.2. kafka sink 3.2.1. 以 Streaming 方式输出数据 3.2.2. 以 batch …...

【云原生】Docker 详解(一):从虚拟机到容器
Docker 详解(一):从虚拟机到容器 1.虚拟化 要解释清楚 Docker,首先要解释清楚 容器(Container)的概念。要解释容器的话,就需要从操作系统说起。操作系统太底层,细说的话一两本书都说…...

代码随想录第48天 | 198. 打家劫舍、213. 打家劫舍II、337. 打家劫舍III
198. 打家劫舍 当前房屋偷与不偷取决于 前一个房屋和前两个房屋是否被偷了。 递归五部曲: dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]。决定dp[i]的因素就是第i房间偷还是不偷。 如果偷第i房间&…...
【LeetCode】按摩师
按摩师 题目描述算法分析编程代码 链接: 按摩师 题目描述 算法分析 编程代码 class Solution { public:int massage(vector<int>& nums) {int n nums.size();if(n 0) return 0;vector<int> f(n);auto g f;f[0] nums[0];for(int i 1;i<n;i){f[i] g[i…...

国际腾讯云账号云核算概述!!
云核算概述 维基百科界说:云核算是一种依据互联网的新型核算方法,经过互联网上异构、自治的服务为个人和企业供给按需即取的核算。 云核算描绘的一起特征:云是一种按需运用的服务,运用者只重视服务本身。 云核算作为IT服务形式&am…...

.NET 6.0 重启 IIS 进程池
在 .NET 6.0 中,你可以使用 Microsoft.Web.Administration 命名空间提供的 API 来管理 IIS 进程池并实现重启操作。以下是一个示例代码,展示如何使用 .NET 6.0 中的 Microsoft.Web.Administration 来重启 IIS 进程池: using Microsoft.Web.A…...

一位心理学教师对ChatGPT的看法,提到了正确地使用它的几个要点
在没有自主学习能力和有自主学习能力的两类学生中,ChatGPT的出现,会加大他们在知识学习及思维发展上的鸿沟。爱学习的人会因为AI变得更好…… 从2022年年底起,ChatGPT的技术突破使人类终于进入了一个AI被广泛应用在工作、学习、生活的时代。…...

认识Node.js及三个模块
文章目录 1.初识 Node.js1.1 什么是 Node.js1.2 Node.js 中的 JavaScript 运行环境1.3 Node.js 可以做什么1.4 Node.js 环境的安装1.4.1 区分 LTS 版本和 Current 版本的不同1.4.2 查看已安装的 Node.js 的版本号1.4.3 什么是终端1.4.4 终端中的快捷键 1.5 在 Node.js 环境中执…...

49 | 公司销售数据分析
公司销售数据分析报告 本数据是2012~2014年间一家生产体育类产品的全球销售订单数据,分别按时间、产品类别、销售国家统计产品销售情况,分析销售额和利润额统计各产品市场占有份额,为下一步生产计划提供有价值的建议。 数据大小:88475 行, 11 列 Retailer country销售国…...
Android 项目导入高德SDK初次上手
文章目录 一、前置知识:二、学习目标三、学习资料四、操作过程1、创建空项目2、高德 SDK 环境接入2.1 获取高德 key2.2下载 SDK 并导入2.2.1、下载SDK 文件2.2.2、SDK 导入项目2.2.3、清单文件配置2.2.4、隐私权限 3、显示地图 一、前置知识: 1、Java 基…...
)
生成树协议用来解决网络风暴的问题?(第三十二课)
生成树协议用来解决网络风暴的问题?(第三十二课) 一 STP RSTP MSTP 介绍 STP(Spanning Tree Protocol)、RSTP(Rapid Spanning Tree Protocol)和MSTP(Multiple Spanning Tree Protocol)都是用于网络中避免环路的协议。 STP是最初的协议,它通过将某些端口阻塞来防止…...

git分支操作
Git分支的操作 1.1 Git分支简介 Git分支是由指针管理起来的,所以创建、切换、合并、删除分支都非常快,非常适合大型项目的开发。 在分支上做开发,调试好了后再合并到主分支。那么每个人开发模块式都不会影响到别人。 分支使用策略…...

【基础学习笔记 enum】TypeScript 中的 enum 枚举类型介绍
因为之前网上查好多博客都是只说最基础的,所以这里记录一下,最基础的放在最后面。 这里重点要记录的是枚举成员的值可以是字符串(字符串枚举,因为网上大部分只介绍常数枚举),需要注意的一点是,…...
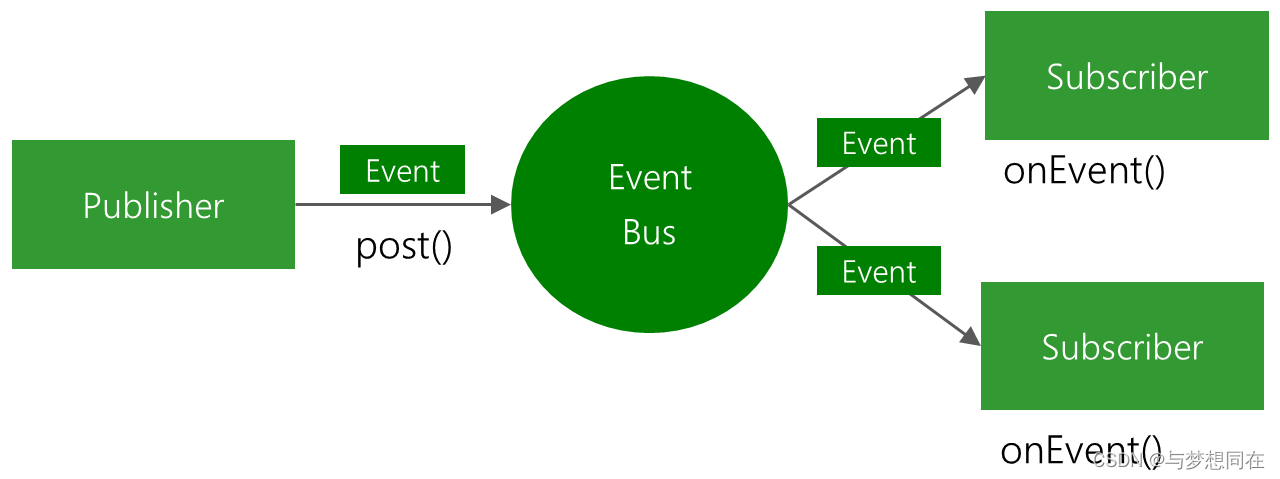
SpringBoot中间件使用之EventBus、Metric、CommandLineRunner
1、EventBus 使用EventBus 事件总线的方式可以实现消息的发布/订阅功能,EventBus是一个轻量级的消息服务组件,适用于Android和Java。 // 1.注册事件通过 EventBus.getDefault().register(); // 2.发布事件 EventBus.getDefault().post(“事件内容”); …...

ffmpeg命令行是如何打开vf_scale滤镜的
前言 在ffmpeg命令行中,ffmpeg -i test -pix_fmt rgb24 test.rgb,会自动打开ff_vf_scale滤镜,本章主要追踪这个流程。 通过gdb可以发现其基本调用栈如下: 可以看到,query_formats()中创建的v…...
【Vue3】自动引入插件-`unplugin-auto-import`
Vue3自动引入插件-unplugin-auto-import,不必再手动 import 。 自动导入 api 按需为 Vite, Webpack, Rspack, Rollup 和 esbuild 。支持TypeScript。由unplugin驱动。 插件安装:unplugin-auto-import 配置vite.config.ts(配置完后需要重启…...

每日温度(力扣)单调栈 JAVA
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 1: 输入: temperatur…...
博客项目(Spring Boot)
1.需求分析 注册功能(添加用户操纵)登录功能(查询操作)我的文章列表页(查询我的文章|文章修改|文章详情|文章删除)博客编辑页(添加文章操作)所有人博客列表(带分页功能)…...

修改Jenkins存储目录
注意:在Jenkins运行时是不能更改的. 请先将Jenkins停止运行。 1、windows环境下更改JENKINS的主目录 Windows环境中,Jenkins主目录默认在C:Documents and SettingsAAA.jenkins 。可以通过设置环境变量来修改,例如: JENKINS_HOME…...
数据结构【第4章】——栈与队列
队列是只允许在一端进行插入操作、而在另-端进行删除操作的线性表。 栈 栈与队列:栈是限定仅在表尾进行插入和删除操作的线性表。 我们把允许插入和删除的一端称为栈顶(top),另一端称为栈底(bottom)&…...

3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐
3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在使用功能单一的网易云音乐吗?想不想让你的播放器拥…...

DISMTools企业部署:在组织中大规模应用的最佳实践
DISMTools企业部署:在组织中大规模应用的最佳实践 【免费下载链接】DISMTools The connected place for Windows system administration 项目地址: https://gitcode.com/GitHub_Trending/di/DISMTools DISMTools是一款专为Windows系统管理设计的连接平台&…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

危急时刻的六条基本安全提示
人机协作,AI模型:Deepseek 仅供参考 危急时刻的六条基本安全提示 以下内容仅为通用性安全建议,供在紧急情况下保持冷静、保护自身安全时参考。所有建议均基于常理和公共安全常识,不包含任何具体操作细节或可能被不当使用的信息…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...