自然语言处理: 第七章GPT的搭建
自然语言处理: 第七章GPT的搭建
理论基础
在以transformer架构为框架的大模型遍地开花后,大模型的方向基本分成了三类分别是:
- decoder-only架构 , 其中以GPT系列为代表
- encoder-only架构,其中以BERT系列为代表
- encoder-decoder架构,标准的transformer架构以BART和T5为代表
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0HeorgFi-1692024387908)(image/GPT/1691331765617.png)]](https://img-blog.csdnimg.cn/d328bba11d084c3184676d89b548a93b.png)
大模型的使用方法如下: 分解成pre-train 和fine-tuning ,其中pre-train是收集大量的高质量的文本(或者其他多模态的输入)去让模型拥有文本理解的泛化能力,而fine-tuing则是对应各自的下游任务将pre-train好的model在下游任务中作微调,从而适应不同的任务头。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i9UGSWHc-1692024387910)(image/GPT/1691337425884.png)]](https://img-blog.csdnimg.cn/24ed2c34b73f4f348e7d525eb316e2cd.png)
那么为什么基于transformer的架构为什么需要可以分成上面的三个分支呢?除了最基本的encoder-decoder架构,这种能普遍处理好各种任务外,那么decoder-only 和 encoder-only的区别在哪?下面以BERT和GPT为代表来分别解释这两种架构的代表,而其中最主要的区别就是二者的预训练目标的区别: 我们由之前Seq2Seq的模型知道,
- BERT全称是Bidirectional Encoder Representation from Transformers,可以看到它是一个双向的模型,而编码器的作用主要是将输入的全部文本信息压缩至一个定长的向量,然后再给下游任务作fine_tuning,所以BERT这种Encoder-only的架构的预训练任务更像是一个填空题,以下图的例子为例,BERT的任务就是给一个完整的文本, 一(二)三四五,上山(打)老虎,需要去预测括号里的内容,而且BERT本身是一个双向的网络,所以在预测括号里的内容时候,他是已经看过全文的,所以这种encoder-only的架构它更具有推理和理解上下文的能力,所以用来做文本分类,关系抽取与命名实体识别的任务有更好的效果,这种预训练的模式叫做MLM(masked language model)。
- 而GPT作为decoder-only,它拥有更好的文本生成能力,它的预训练任务就更加贴合我们传统理解的NLP任务,同样如下图的例子,GPT的预训练过程是老虎没打到,(抓到小松鼠),通过上文去预测下文,所以它是一个单向的,也就是更像一个问答题,所以它具有更好的文本生成能力所以就更适合用来作聊天机器人。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-riPOD8AQ-1692024387910)(image/GPT/1691336373171.png)]](https://img-blog.csdnimg.cn/60bb09f60b1c46c99e893c2a40b2192c.png)
因此,GPT的生成式预训练如,内容如下: 输入是上文,输出是下文,并且是单向的decoder结构,所以相比于传统的transformer结构,GPT结构更加的轻量了。除此之外还需要注意的是,在训练阶段由于保证运行效率,直接就由文本在前端加一个 <sos>, 但是在inference阶段需要没生成一个字,连同之前的上文一起再输入给下一次作为输入。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zpCejAxc-1692024387911)(image/GPT/1691337602259.png)]](https://img-blog.csdnimg.cn/d697e4b4edd9461bafaa8c4b4d89f509.png)
因此这种decorder-only的结构,除了去除了encoder结构之外,自身的decoder基本跟transfor的decoder结构一致,但是去掉了encoder-decoder的self-attention这部分,transformer基本的结构可以参考上文第六章Transformer- 现代大模型的基石: 分解的结构如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B45U7CTL-1692024387911)(image/GPT/1691339029807.png)]](https://img-blog.csdnimg.cn/a494eb74666c4297b80e802f4d3dc353.png)
还有一种解释是是从对模型的期望来解释BERT 和GPT的区别,根据前文我们可以知道BERT的预训练的模式是作填空题,所以它本身并不具备生成文字内容的能力,但是它具有更好的理解上下文的能力,所以对应不同的任务,只需要BERT + Head(任务头) 就可以针对不同的任务,所以这就导致了BERT更适合成为专才。而GPT由于预训练是做的问答题,而其实所有的NLP任务都可以看成是问答的任务,比如说机器翻译,你只要给GPT下一个prompt 请帮我将下列句子翻译成英文这样GPT就可以翻译成英文了。对于其他任务也是一样的,只需要下对应的prompt,所以GPT是更像一个通才,无需加单独的任务头,便可以完成不同的任务。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-InmH5a07-1692024387911)(image/07_GPT/1692005331398.png)]](https://img-blog.csdnimg.cn/c1ff5d37dcd94c2ea3395e6cd8d824f2.png)
代码实现
1. 多头注意力
class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__() def forward(self, Q, K, V, attn_mask): # Q K V [batch_size, n_heads, len_q/k/v, dim_q=k/v] (dim_q=dim_k)# 计算注意力分数(原始权重)[batch_size,n_heads,len_q,len_k]scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # 使用注意力掩码,将attn_mask中值为1的位置的权重替换为极小值# attn_mask [batch_size,n_heads,len_q,len_k],形状和scores相同scores.masked_fill_(attn_mask.to(torch.bool), -1e9) # 对注意力分数进行softmaxweights = nn.Softmax(dim=-1)(scores)# 计算上下文向量(也就是注意力的输出), 是上下文信息的紧凑表示context = torch.matmul(weights, V)return context, weights # 返回上下文向量和注意力分数# 定义多头注意力类
d_embedding = 512 # Embedding Size
n_heads = 8 # number of heads in Multi-Head Attention
batch_size = 3 # 每一批数据量
class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()self.W_Q = nn.Linear(d_embedding, d_k * n_heads) # Q的线性变换层self.W_K = nn.Linear(d_embedding, d_k * n_heads) # K的线性变换层self.W_V = nn.Linear(d_embedding, d_v * n_heads) # V的线性变换层self.linear = nn.Linear(n_heads * d_v, d_embedding)self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, Q, K, V, attn_mask): # Q K V [batch_size,len_q/k/v,embedding_dim] residual, batch_size = Q, Q.size(0) # 保留残差连接# 将输入进行线性变换和重塑,以便后续处理# q_s k_s v_s: [batch_size,n_heads.,len_q/k/v,d_q=k/v]q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2)v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2)# 将注意力掩码复制到多头 [batch_size,n_heads,len_q,len_k]attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)# 使用缩放点积注意力计算上下文和注意力权重context, weights = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)# 重塑上下文向量并进行线性变换,[batch_size,len_q,n_heads * dim_v]context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) output = self.linear(context)# 与输入(Q)进行残差链接,并进行层归一化后输出[batch_size, len_q, embedding_dim]output = self.layer_norm(output + residual)return output, weights # 返回层归一化的输出和注意力权重
2. 逐位置前馈网络
# 定义逐位置前向传播网络类
class PoswiseFeedForwardNet(nn.Module):def __init__(self):super(PoswiseFeedForwardNet, self).__init__()# 定义一维卷积层1,用于将输入映射到更高维度self.conv1 = nn.Conv1d(in_channels=d_embedding, out_channels=2048, kernel_size=1)# 定义一维卷积层2,用于将输入映射回原始维度self.conv2 = nn.Conv1d(in_channels=2048, out_channels=d_embedding, kernel_size=1)# 定义层归一化self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, inputs): # inputs: [batch_size, len_q, embedding_dim] residual = inputs # 保留残差连接# 在卷积层1后使用ReLU激活函数output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))# 使用卷积层2进行降维output = self.conv2(output).transpose(1, 2)# 与输入进行残差链接,并进行层归一化,[batch_size, len_q, embedding_dim]output = self.layer_norm(output + residual)return output # 返回层归一化后的输出加上残差连接的结果
3. 正弦位置编码表
def get_sin_enc_table(n_position, embedding_dim):# 根据位置和维度信息,初始化正弦位置编码表sinusoid_table = np.zeros((n_position, embedding_dim)) # 遍历所有位置和维度,计算角度值for pos_i in range(n_position):for hid_j in range(embedding_dim):angle = pos_i / np.power(10000, 2 * (hid_j // 2) / embedding_dim)sinusoid_table[pos_i, hid_j] = angle # 计算正弦和余弦值sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i 偶数维sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 奇数维 return torch.FloatTensor(sinusoid_table)
4. 填充位置掩码
# 生成填充注意力掩码的函数,用于在多头自注意力计算中忽略填充部分
def get_attn_pad_mask(seq_q, seq_k):batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# 生成布尔类型张量[batch_size,1,len_k(=len_q)]pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) #<PAD> Token的编码值为0 # 变形为何注意力分数相同形状的张量 [batch_size,len_q,len_k]pad_attn_mask = pad_attn_mask.expand(batch_size, len_q, len_k) return pad_attn_mask # 形状[batch_size,len_q,len_k]
5. 后续位置掩码
# 生成后续注意力掩码的函数,用于在多头自注意力计算中忽略未来信息
def get_attn_subsequent_mask(seq):# 获取输入序列的形状 [batch_size, seq_len(len_q), seq_len(len_k)]attn_shape = [seq.size(0), seq.size(1), seq.size(1)]# 使用numpy创建一个上三角矩阵(triu = triangle upper)subsequent_mask = np.triu(np.ones(attn_shape), k=1)# 将numpy数组转换为PyTorch张量,并将数据类型设置为byte(布尔值)subsequent_mask = torch.from_numpy(subsequent_mask).byte()return subsequent_mask # [batch_size, seq_len(len_q), seq_len(len_k)]
6. 解码器
# 构建解码器层
class DecoderLayer(nn.Module):def __init__(self):super(DecoderLayer, self).__init__()self.self_attn = MultiHeadAttention() # 多头自注意力层self.feed_forward = PoswiseFeedForwardNet() # 位置前馈神经网络层self.norm1 = nn.LayerNorm(d_embedding) # 第一个层归一化self.norm2 = nn.LayerNorm(d_embedding) # 第二个层归一化def forward(self, dec_inputs, attn_mask=None):# 使用多头自注意力处理输入attn_output, _ = self.self_attn(dec_inputs, dec_inputs, dec_inputs, attn_mask)# 将注意力输出与输入相加并进行第一个层归一化norm1_outputs = self.norm1(dec_inputs + attn_output)# 将归一化后的输出输入到位置前馈神经网络ff_outputs = self.feed_forward(norm1_outputs)# 将前馈神经网络输出与第一次归一化后的输出相加并进行第二个层归一化dec_outputs = self.norm2(norm1_outputs + ff_outputs)return dec_outputs# 构建解码器
n_layers = 6 # 设置Encoder/Decoder的层数
class Decoder(nn.Module):def __init__(self, corpus):super(Decoder, self).__init__()self.src_emb = nn.Embedding(corpus.vocab_size, d_embedding) # 词嵌入层(参数为词典维度)self.pos_emb = nn.Embedding(corpus.seq_len, d_embedding) # 位置编码层(参数为序列长度) self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) # 初始化N个解码器层def forward(self, dec_inputs): positions = torch.arange(len(dec_inputs), device=dec_inputs.device).unsqueeze(-1) # 位置信息 inputs_embedding = self.src_emb(dec_inputs) + self.pos_emb(positions) # 词嵌入与位置编码相加 attn_mask = get_attn_subsequent_mask(inputs_embedding).to(dec_inputs.device) # 生成自注意力掩码dec_outputs = inputs_embedding # 初始化解码器输入,这是第一层解码器层的输入 for layer in self.layers:# 每个解码器层接收前一层的输出作为输入,并生成新的输出# 对于第一层解码器层,其输入是dec_outputs,即词嵌入和位置编码的和# 对于后续的解码器层,其输入是前一层解码器层的输出 dec_outputs = layer(dec_outputs, attn_mask) # 将输入数据传递给解码器层return dec_outputs # 返回最后一个解码器层的输出,作为整个解码器的输出
7. GPT
class GPT(nn.Module):def __init__(self, corpus):super(GPT, self).__init__()self.corpus = corpusself.decoder = Decoder(corpus) # 解码器,用于学习文本生成能力self.projection = nn.Linear(d_embedding, corpus.vocab_size) # 全连接层,输出预测结果def forward(self, dec_inputs): dec_outputs = self.decoder(dec_inputs) # 将输入数据传递给解码器logits = self.projection(dec_outputs) # 传递给全连接层以生成预测return logits #返回预测结果def decode(self, input_str, strategy='greedy', **kwargs):if strategy == 'greedy': # 贪心解码函数return generate_text_greedy_search(self, input_str, **kwargs)elif strategy == 'beam_search': # 集束解码函数return generate_text_beam_search(self, input_str, **kwargs)else:raise ValueError(f"Unknown decoding strategy: {strategy}")
8. Greedy_search & Beam_search
def generate_text_beam_search(model, input_str, max_len=5, beam_width=5, repetition_penalty=1.2):# 将模型设置为评估(测试)模式,关闭dropout和batch normalization等训练相关的层model.eval()# 让NLTK工具帮忙分一下词input_str = word_tokenize(input_str)# 将输入字符串中的每个token转换为其在词汇表中的索引, 如果输入的词不再词表里面,就忽略这个词input_tokens = [model.corpus.vocab[token] for token in input_str if token in model.corpus.vocab]# 检查输入的有意义的词汇长度是否为0if len(input_tokens) == 0:return # 创建一个列表,用于存储候选序列,初始候选序列只包含输入tokenscandidates = [(input_tokens, 0.0)] # 创建一个列表,用于存储所有生成的序列及其得分final_results = []# 禁用梯度计算,以节省内存并加速测试过程with torch.no_grad():# 生成最多max_len个tokensfor _ in range(max_len):# 创建一个新的候选列表,用于存储当前时间步生成的候选序列new_candidates = [] # 遍历当前候选序列for candidate, candidate_score in candidates:# 将当前候选序列转换为torch张量并将其传递给模型device = "cuda" if torch.cuda.is_available() else "cpu"inputs = torch.LongTensor(candidate).unsqueeze(0).to(device)outputs = model(inputs) # 只关心最后一个时间步(即最新生成的token)的logitslogits = outputs[:, -1, :]# 应用重复惩罚:为已经生成的词汇应用惩罚,降低它们再次被选择的概率for token in set(candidate):logits[0, token] /= repetition_penalty# 将<pad>标记的得分设置为一个很大的负数,以避免选择它logits[0, model.corpus.vocab["<pad>"]] = -1e9 # 找到具有最高分数的前beam_width个tokensscores, next_tokens = torch.topk(logits, beam_width, dim=-1)# 遍历生成的tokens及其得分for score, next_token in zip(scores.squeeze(), next_tokens.squeeze()):# 将生成的token添加到当前候选序列new_candidate = candidate + [next_token.item()] # 更新候选序列得分new_score = candidate_score - score.item() # 如果生成的token是EOS(结束符),将其添加到最终结果中if next_token.item() == model.corpus.vocab["<eos>"]:final_results.append((new_candidate, new_score))else:# 将新生成的候选序列添加到新候选列表中new_candidates.append((new_candidate, new_score))# 从新候选列表中选择得分最高的beam_width个序列candidates = sorted(new_candidates, key=lambda x: x[1], reverse=True)[:beam_width]# 选择得分最高的候选序列,如果final_results为空,选择当前得分最高的候选序列if final_results:best_candidate, _ = sorted(final_results, key=lambda x: x[1])[0]else:best_candidate, _ = sorted(candidates, key=lambda x: x[1])[0]# 将输出 token 转换回文本字符串output_str = " ".join([model.corpus.idx2word[token] for token in best_candidate])return output_strdef generate_text_greedy_search(model, input_str, max_len=5):# 将模型设置为评估(测试)模式,关闭dropout和batch normalization等训练相关的层model.eval()# 使用NLTK工具进行词汇切分input_str = word_tokenize(input_str)# 将输入字符串中的每个token转换为其在词汇表中的索引, 如果输入的词不在词表里面,就忽略这个词input_tokens = [model.corpus.vocab[token] for token in input_str if token in model.corpus.vocab]# 检查输入的有意义的词汇长度是否为0if len(input_tokens) == 0:return # 创建一个列表,用于存储生成的词汇output_tokens = input_tokens# 禁用梯度计算,以节省内存并加速测试过程with torch.no_grad():# 生成最多max_len个tokensfor _ in range(max_len):# 将当前生成的tokens转换为torch张量并将其传递给模型device = "cuda" if torch.cuda.is_available() else "cpu"inputs = torch.LongTensor(output_tokens).unsqueeze(0).to(device)outputs = model(inputs) # 只关心最后一个时间步(即最新生成的token)的logitslogits = outputs[:, -1, :]# 找到具有最高分数的token_, next_token = torch.topk(logits, 1, dim=-1)# 如果生成的token是EOS(结束符),则停止生成if next_token.item() == model.corpus.vocab["<eos>"]:break# 否则,将生成的token添加到生成的词汇列表中output_tokens.append(next_token.item())# 将输出 tokens 转换回文本字符串output_str = " ".join([model.corpus.idx2word[token] for token in output_tokens])return output_str结果
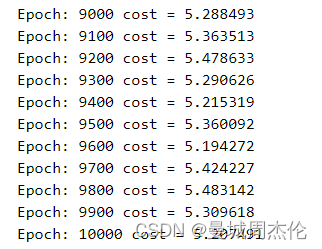
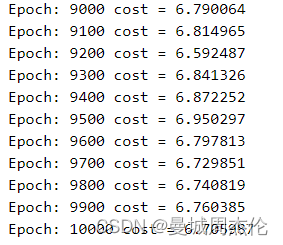
本次实验设置了三个对照组,分别是baseline(N_head = 8 , n_layer = 6), N_head = 32 , n_layer = 18,可以看到训练10000个step之后得loss分别如下图:
从收敛程度上来看,18层layer得transformer 完全没有收敛,这个可能是因为深度神经网络的梯度消失,所以我们设置的网络如果没有残差链接的话,尽量不要太深。然后再看多头,可以看到头的数量好像也不是越多越好,但是其实二者都收敛了,具体结果我们可以结合一下inference的结果看看。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OrbLynmi-1692024387912)(image/GPT/1691457265515.png)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f13C96uI-1692024387912)(image/GPT/1691457362491.png)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sgAzQFd1-1692024387912)(image/GPT/1691457508644.png)]](https://img-blog.csdnimg.cn/b7760759aeb544d489cd245d5b7115dd.png)
可以看到两种解码得方式,greedy_search在大部分时候由于设置了惩罚项所以现在大部分时候是两个单词无限循环,相比之下beam_search得结果就好得多,更像一句话。
其次对比一下三个对照组得结果,正如loss的结果一样,深层次GPT架构无论是beam_search还是greedy_search翻译的结果都非常的差,出现了很多标点,这应该就是没有收敛的结果。然后对比下不同的head数量,这里看上去也是n_head越少的效果越好。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IGo8HqTZ-1692024387913)(image/GPT/1691456509885.png)]](https://img-blog.csdnimg.cn/fbaaa1416a70496fb3d5a8603ff1c2bb.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RlxRHHwJ-1692024387913)(image/GPT/1691456528323.png)]](https://img-blog.csdnimg.cn/3090f33f02cb4600962523ec13c7693e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VzW91uqg-1692024387913)(image/GPT/1691456544126.png)]](https://img-blog.csdnimg.cn/c1282bb963d844a799cfd29add14ea05.png)
相关文章:
自然语言处理: 第七章GPT的搭建
自然语言处理: 第七章GPT的搭建 理论基础 在以transformer架构为框架的大模型遍地开花后,大模型的方向基本分成了三类分别是: decoder-only架构 , 其中以GPT系列为代表encoder-only架构,其中以BERT系列为代表encoder-decoder架构,标准的tr…...
【奶奶看了都会】2分钟学会制作最近特火的ikun幻术图
1.效果展示 最近ikun幻术图特别火啊,在网上能找到各种各样的ikun姿势图片,这些图片都是AI绘制的,能和风景完美融合在一起,今天小卷就来教大家怎么做这种图片 先看看图片效果 视频链接: 仿佛见到一位故人,…...

【深度学习】【风格迁移】Zero-shot Image-to-Image Translation
论文:https://arxiv.org/abs/2302.03027 代码:https://github.com/pix2pixzero/pix2pix-zero/tree/main 文章目录 Abstract1. Introduction相关工作3. Method Abstract 大规模文本到图像生成模型展示了它们合成多样且高质量图像的显著能力。然而&#x…...
)
Day 30 C++ STL 常用算法(上)
文章目录 算法概述常用遍历算法for_each——实现遍历容器函数原型示例 transform——搬运容器到另一个容器中函数原型注意示例 常用查找算法find——查找指定元素函数原型示例 find_if—— 查找符合条件的元素函数原型示例 adjacent_find——查找相邻重复元素函数原型示例 bina…...

MES系统在机器人行业生产管理种的运用
机器人的智能水平也伴随技术的迭代不断攀升。 2021年的春晚舞台上,来自全球领先工业机器人企业abb的全球首款双臂协作机器人yumi,轻松自如地表演了一出写“福”字,赢得了全国观众的赞叹。 在汽车装配领域,一台机器人可以自主完成一…...
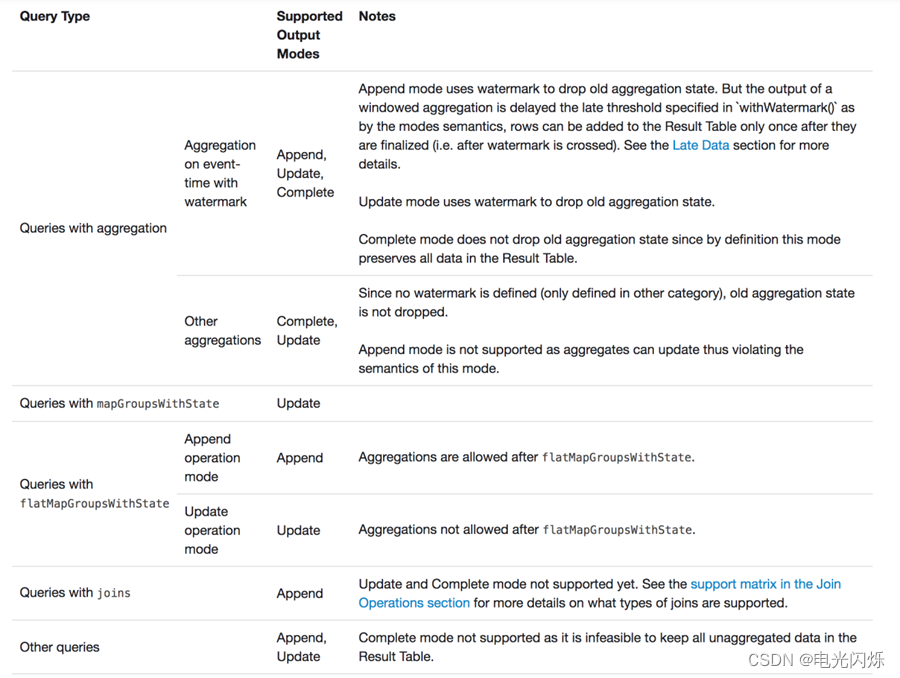
Spark(39):Streaming DataFrame 和 Streaming DataSet 输出
目录 0. 相关文章链接 1. 输出的选项 2. 输出模式(output mode) 2.1. Append 模式(默认) 2.2. Complete 模式 2.3. Update 模式 2.4. 输出模式总结 3. 输出接收器(output sink) 3.1. file sink 3.2. kafka sink 3.2.1. 以 Streaming 方式输出数据 3.2.2. 以 batch …...

【云原生】Docker 详解(一):从虚拟机到容器
Docker 详解(一):从虚拟机到容器 1.虚拟化 要解释清楚 Docker,首先要解释清楚 容器(Container)的概念。要解释容器的话,就需要从操作系统说起。操作系统太底层,细说的话一两本书都说…...

代码随想录第48天 | 198. 打家劫舍、213. 打家劫舍II、337. 打家劫舍III
198. 打家劫舍 当前房屋偷与不偷取决于 前一个房屋和前两个房屋是否被偷了。 递归五部曲: dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]。决定dp[i]的因素就是第i房间偷还是不偷。 如果偷第i房间&…...
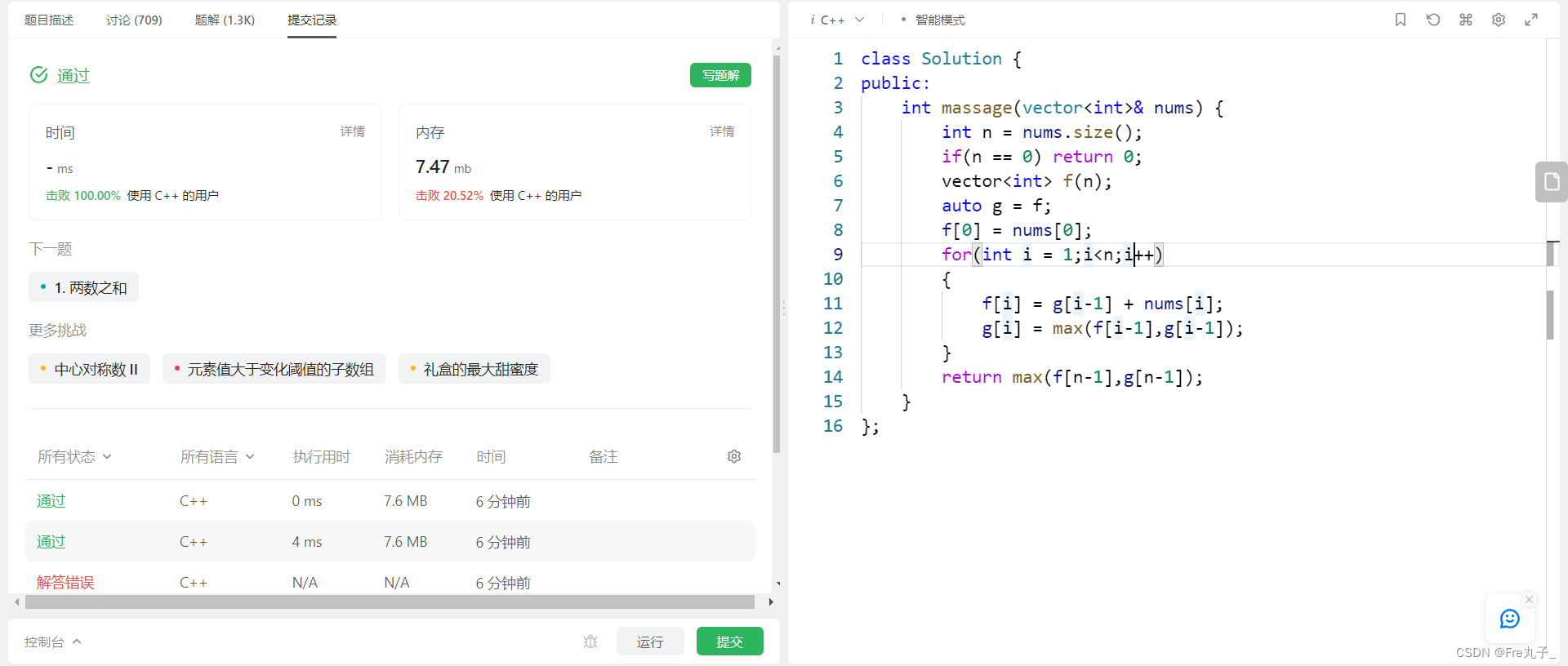
【LeetCode】按摩师
按摩师 题目描述算法分析编程代码 链接: 按摩师 题目描述 算法分析 编程代码 class Solution { public:int massage(vector<int>& nums) {int n nums.size();if(n 0) return 0;vector<int> f(n);auto g f;f[0] nums[0];for(int i 1;i<n;i){f[i] g[i…...

国际腾讯云账号云核算概述!!
云核算概述 维基百科界说:云核算是一种依据互联网的新型核算方法,经过互联网上异构、自治的服务为个人和企业供给按需即取的核算。 云核算描绘的一起特征:云是一种按需运用的服务,运用者只重视服务本身。 云核算作为IT服务形式&am…...

.NET 6.0 重启 IIS 进程池
在 .NET 6.0 中,你可以使用 Microsoft.Web.Administration 命名空间提供的 API 来管理 IIS 进程池并实现重启操作。以下是一个示例代码,展示如何使用 .NET 6.0 中的 Microsoft.Web.Administration 来重启 IIS 进程池: using Microsoft.Web.A…...

一位心理学教师对ChatGPT的看法,提到了正确地使用它的几个要点
在没有自主学习能力和有自主学习能力的两类学生中,ChatGPT的出现,会加大他们在知识学习及思维发展上的鸿沟。爱学习的人会因为AI变得更好…… 从2022年年底起,ChatGPT的技术突破使人类终于进入了一个AI被广泛应用在工作、学习、生活的时代。…...

认识Node.js及三个模块
文章目录 1.初识 Node.js1.1 什么是 Node.js1.2 Node.js 中的 JavaScript 运行环境1.3 Node.js 可以做什么1.4 Node.js 环境的安装1.4.1 区分 LTS 版本和 Current 版本的不同1.4.2 查看已安装的 Node.js 的版本号1.4.3 什么是终端1.4.4 终端中的快捷键 1.5 在 Node.js 环境中执…...

49 | 公司销售数据分析
公司销售数据分析报告 本数据是2012~2014年间一家生产体育类产品的全球销售订单数据,分别按时间、产品类别、销售国家统计产品销售情况,分析销售额和利润额统计各产品市场占有份额,为下一步生产计划提供有价值的建议。 数据大小:88475 行, 11 列 Retailer country销售国…...
Android 项目导入高德SDK初次上手
文章目录 一、前置知识:二、学习目标三、学习资料四、操作过程1、创建空项目2、高德 SDK 环境接入2.1 获取高德 key2.2下载 SDK 并导入2.2.1、下载SDK 文件2.2.2、SDK 导入项目2.2.3、清单文件配置2.2.4、隐私权限 3、显示地图 一、前置知识: 1、Java 基…...
)
生成树协议用来解决网络风暴的问题?(第三十二课)
生成树协议用来解决网络风暴的问题?(第三十二课) 一 STP RSTP MSTP 介绍 STP(Spanning Tree Protocol)、RSTP(Rapid Spanning Tree Protocol)和MSTP(Multiple Spanning Tree Protocol)都是用于网络中避免环路的协议。 STP是最初的协议,它通过将某些端口阻塞来防止…...

git分支操作
Git分支的操作 1.1 Git分支简介 Git分支是由指针管理起来的,所以创建、切换、合并、删除分支都非常快,非常适合大型项目的开发。 在分支上做开发,调试好了后再合并到主分支。那么每个人开发模块式都不会影响到别人。 分支使用策略…...

【基础学习笔记 enum】TypeScript 中的 enum 枚举类型介绍
因为之前网上查好多博客都是只说最基础的,所以这里记录一下,最基础的放在最后面。 这里重点要记录的是枚举成员的值可以是字符串(字符串枚举,因为网上大部分只介绍常数枚举),需要注意的一点是,…...
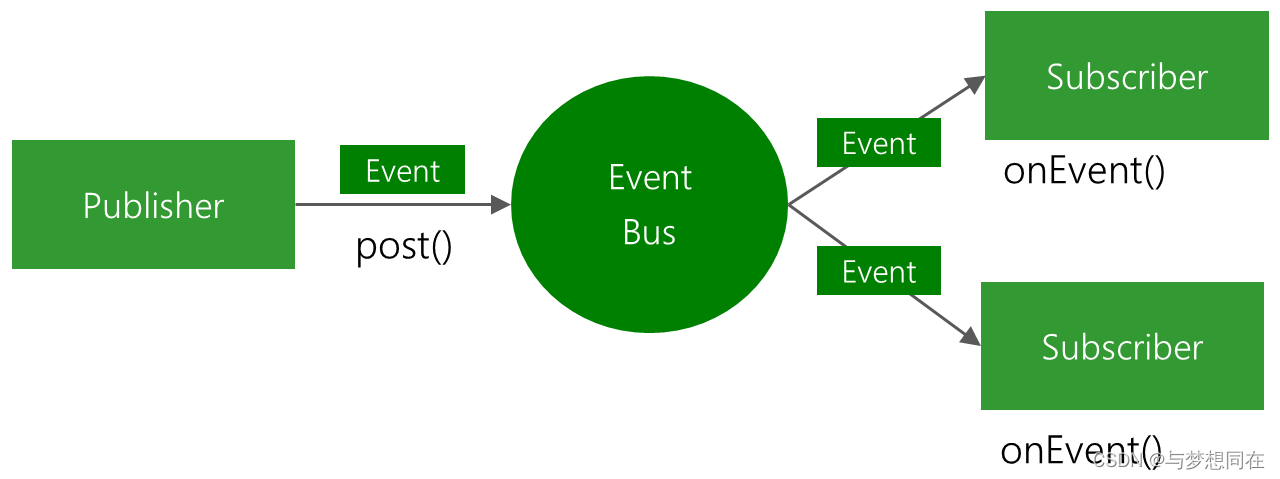
SpringBoot中间件使用之EventBus、Metric、CommandLineRunner
1、EventBus 使用EventBus 事件总线的方式可以实现消息的发布/订阅功能,EventBus是一个轻量级的消息服务组件,适用于Android和Java。 // 1.注册事件通过 EventBus.getDefault().register(); // 2.发布事件 EventBus.getDefault().post(“事件内容”); …...

ffmpeg命令行是如何打开vf_scale滤镜的
前言 在ffmpeg命令行中,ffmpeg -i test -pix_fmt rgb24 test.rgb,会自动打开ff_vf_scale滤镜,本章主要追踪这个流程。 通过gdb可以发现其基本调用栈如下: 可以看到,query_formats()中创建的v…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

内存占用3KB!极致瘦身释放MCU无限可能
极致小体积,给工业领域带来了无限的可能:更低硬件成本,更小芯片体积,更低功耗,更高可靠性,让每一颗小MCU都拥有大系统的完整能力。 https://www.bilibili.com/video/BV1eZLi6PEjc/?spm_id_from333.1387.ho…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

万星easy-vibe:描述需求即发布 零基础无需学语法
开源Easy-Vibe是一套开源AI编程学习方案,把学习顺序从先学语法再做项目翻转为直接做项目。文章拆解了项目驱动、提示词编写、AI编辑器和多Agent协作的完整流程,解释了为什么想法比语法更重要。 github上datawhalechina/easy-vibe:它在GitHub…...

基于PGA2311的树莓派Hi-Fi模拟音量控制器设计与实现
1. 项目概述:为树莓派DAC打造的高品质模拟音量控制器玩过树莓派音频播放器的朋友都知道,用上像PCM1794A这类高性能DAC芯片后,音质确实能上一个台阶,但有个不大不小的麻烦:这类芯片本身不带音量控制。软件调音量&#x…...

如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造
如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造 【免费下载链接】redux-dynamic-modules Modularize Redux by dynamically loading reducers and middlewares. 项目地址: https://gitcode.com/gh_mirrors/re/redux-dynamic-modules Redux Dyn…...