SQL | 分组数据
10-分组数据
两个新的select子句:group by子句和having子句。
10.1-数据分组
上面我们学到了,使用SQL中的聚集函数可以汇总数据,这样,我们就能够对行进行计数,计算和,计算平均数。
目前为止,所有的计算都是在表的所有数据或者匹配特定的where子句的数据上进行的。
select count(*) as num_prods
from products
where vend_id = 'DLL01';如上述SQL语句,返回供应商为DLL01的所有产品数目。
但是,现在有一个功能,就是想要返回每个供应商的产品数目;或者返回只提供一种商品的供应商数目。
这个时候就需要用到这次要写的分组的内容了。
使用分组可以将数据分为多个逻辑组,对每个组进行聚集计算。
10.2-创建分组
分组是使用select语句和group by子句进行创建的。
select vend_id,count(*) as num_prods
from products
group by vend_id;
上述SQL语句执行后,会分别查出来供应商为BRS01的产品数目,供应商为DLL01的产品数目,供应商为FNG01的产品数目。
group by子句指示DBMS按照vend_id排序并分组数据。这么做就会对每个不同的vend_id进行分别查询。
因为使用了group by子句,就不必指定要计算和估值的每个组了,系统会自动完成。group by子句提示DBMS对数据按照vend_id进行分组,然后对每个组而不是整个结果集进行聚集。根据上述的SQL语句,DBMS按照我们的指示,分为三组,然后每组进行分别计算。
使用group by之前,需要知道下面内容:
-
gruop by子句可以包含任意数目的列,因而可以对分组进行嵌套,更细致地进行分组。
-
如果group by 子句中嵌套了分组,数据将在最后指定的分组上进行汇总。在建立分组时,所有列都一起计算,所以不能从个别列取数据。
-
group by 子句中累出的每一列都必须是检索列或者有效的表达式,但是不能为聚集函数。如果在select中使用表达式,则必须在gruop by子句中指定相同的表达式,不能使用别名。
-
大多数SQL实现不允许group by 列带有长度可变的数据类型(如文本字段,备注型字段)。
-
除聚集计算语句外,select语句中的每一列都必须在group by子句中给出。
-
如果分组列中包含具有NULL值的行,则NULL将作为一个分组返回。如果列中有多行NULL值,他们将分为一组。
-
group by子句必须出现在where子句之后,order by子句之前。
10.3-过滤分组
除了使用group by分组数据外,SQL还能过滤分组,可以规定包括哪些分组,排除哪些分组。例如,我们查找至少有两个订单的顾客;商品数量大于100的供应商等。必须基于完整的分组而不是个别的行进行过滤。
看到过滤,就想起了where子句,但是过滤分组这个功能可能不能使用where,因为where过滤的是某些不符合条件的行,而不是组。
SQL提供的另一个子句:having子句,是专门用来过滤分组的。having类似于where。
目前为止,所有where子句都可以使用having进行替换。只不过having用户过滤组,where用于过滤行。
having支持所有where操作符:where子句的条件,包括通配符条件和带多个操作符的子句,学过的这些有关where的所有技术和选项都使用having。句法是相同的,只是关键字不同而已。
select cust_id,count(*) as orders
from orders
group by cust_id
having count(*) >= 2;
上述SQL语句通过分组查询订单量大于等于2的顾客id和订单数量。可以看到,我们是通过having过滤组数据的。
having和where的差别:where在数据分组前进行过滤,having在数据分组后进行过滤。经过where过滤后的数据,就不包含在组中了。
select vend_id,count(*) as num_prods
from products
where prod_price >= 4
group by vend_id
having count(*) >= 2;
上述SQL语句用于查询产品列表中,某个供应商供应的产品数量大于等于2,并且产品价格大于等于4的供应商的数量。
第一行正常使用selec子句,使用聚集函数count(*)。第三行过滤产品价格大于等于4的行;第四行按照vend_id进行分组;然后第五行过滤计数大于等于2的组。
如果没有where子句,会怎么样呢?
select vend_id,count(*) as num_prods
from products
group by vend_id
having count(*) >= 2;
上述SQL语句除去了where子句,可以看到数据比上面多了一条。
关于使用where和having:如果没有group by子句,大多数DBMS会同等对待这两个子句。但是实际开发过程中应该知道,只用having时,后面要跟group by子句。
10.4-分组和排序
group by 和 order by
对于第一条区别,有时我们使用group by,大部分情况是按照分组顺序进行排序的,但并不是总是这样。如果想要指定输出的数据为某种指定的排序,那么还是要指定order by子句,即使它的效果等同于group by子句。
select order_num,count(*) as items
from orderitems
group by order_num
having count(*) >=3; 
但是,如果我们按照订购物品的数目进行排序输出。
select order_num,count(*) as items
from orderitems
group by order_num
having count(*) >= 3
order by items,order_num; 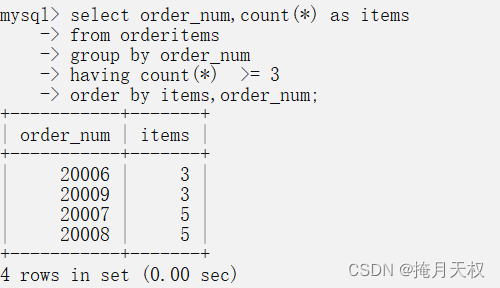
上述SQL语句按照order_num分组数据,查询符合大于等于3的数据,然后按照数量进行排序。
10.5-select子句顺序

练习
-
OrderItems表包含每个订单的每个产品。编写SQL语句,返回每个订单号(order_num)各有多少行数(order_lines),并 按order_lines对结果进行排序。
select order_num,count(*) as order_lines from orderitems group by order_num order by order_lines;
-
编写SQL语句,返回名为cheapest_item的字段,该字段包含每个供应商成本最低的产品(使用Products表中的prod_price), 然后从最低成本到最高成本对结果进行排序。
select vend_id,min(prod_price) as cheapest_item from products group by vend_id order by cheapest_item;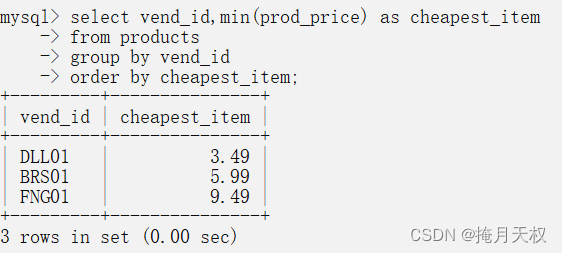
-
确定最佳顾客非常重要,请编写SQL语句,返回至少含100项的所有订单的订单号(OrderItems表中的order_num)。
select order_num,count(*) as orders from orderitems where quantity >= 100 group by order_num;
-
确定最佳顾客的另一种方式是看他们花了多少钱。编写SQL语句,返回总价至少为1000的所有订单的订单号(OrderItems表中的order_num)。提示:需要计算总和(item_price乘以quantity)。按订单号对结果进行排序。
select order_num from orderitems where (item_price * quantity) >= 1000 group by order_num;
-
下面的SQL语句有问题吗?(尝试在不运行的情况下指出。)
SELECT order_num, COUNT(*) AS items FROM OrderItems GROUP BY items HAVING COUNT(*) >= 3 ORDER BY items, order_num;
group by 子句应当时候表中的字段名,而不是别名,正确:
group by order_num;
相关文章:
SQL | 分组数据
10-分组数据 两个新的select子句:group by子句和having子句。 10.1-数据分组 上面我们学到了,使用SQL中的聚集函数可以汇总数据,这样,我们就能够对行进行计数,计算和,计算平均数。 目前为止,…...
)
软件测试技术之如何编写测试用例(6)
四、客户端兼容性测试 1、平台测试 市场上有很多不同的操作系统类型,最常见的有Windows、Unix、Macintosh、Linux等。Web应用系统的最终用户究竟使用哪一种操作系统,取决于用户系统的配置。这样,就可能会发生兼容性问题,同一个应…...

论文阅读——Adversarial Eigen Attack on Black-Box Models
Adversarial Eigen Attack on Black-Box Models 作者:Linjun Zhou, Linjun Zhou 攻击类别:黑盒(基于梯度信息),白盒模型的预训练模型可获得,但训练数据和微调预训练模型的数据不可得ÿ…...
-[自定义对话记忆与自定义记忆类])
自然语言处理从入门到应用——LangChain:记忆(Memory)-[自定义对话记忆与自定义记忆类]
分类目录:《自然语言处理从入门到应用》总目录 自定义对话记忆 本节介绍了几种自定义对话记忆的方法: from langchain.llms import OpenAI from langchain.chains import ConversationChain from langchain.memory import ConversationBufferMemoryllm…...

【C/C++】STL queue 非线程安全接口,危险!
STL 中的 queue 是非线程安全的,一个组合操作:front(); pop() 先读取队首元素然后删除队首元素,若是有多个线程执行这个组合操作的话,可能会发生执行序列交替执行,导致一些意想不到的行为。因此需要重新设计线程安全的…...
执行Lua脚本后一直查询不到Redis中的数据(附带问题详细排查过程,一波三折)
文章目录 执行Lua脚本后一直查询不到Redis中的数据(附带详细问题排查过程,一波三折)问题背景问题1:Lua脚本无法切库问题2:RedisTemlate切库报错问题3:序列化导致数据不一致问题4:Lua脚本中单引号…...
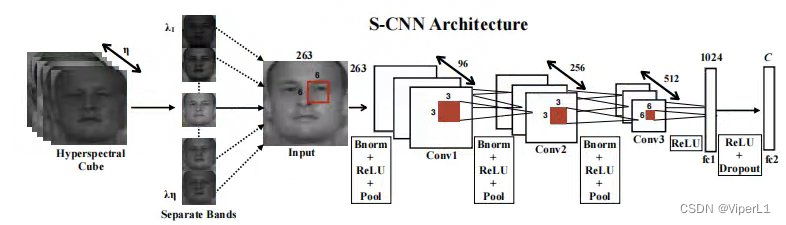
[高光谱]PyTorch使用CNN对高光谱图像进行分类
项目原地址: Hyperspectral-Classificationhttps://github.com/eecn/Hyperspectral-ClassificationDataLoader讲解: [高光谱]使用PyTorch的dataloader加载高光谱数据https://blog.csdn.net/weixin_37878740/article/details/130929358 一、模型加载 在…...
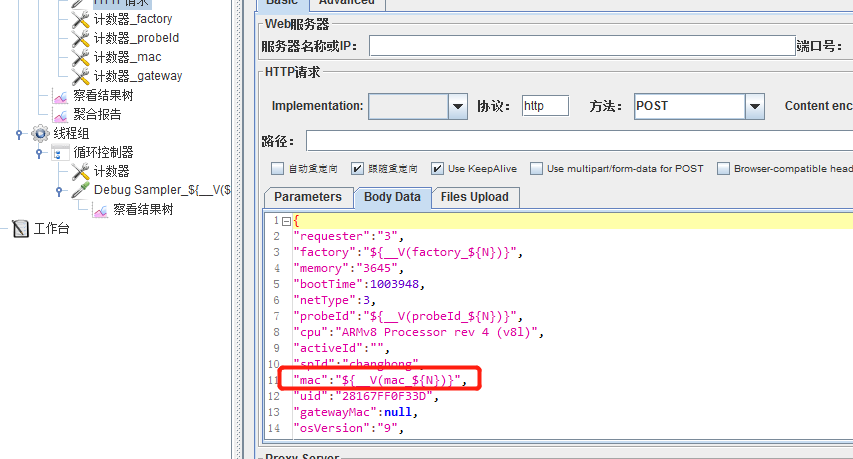
jmeter获取mysql数据
JDBC Connection Configuration Database URL: jdbc:mysql:// 数据库地址 /库名 JDBC Driver class:com.mysql.jdbc.Driver Username:账号 Password:密码 JDBC Request 字段含义 字段含义 Variable Name Bound to Pool 数据库连接池配置…...
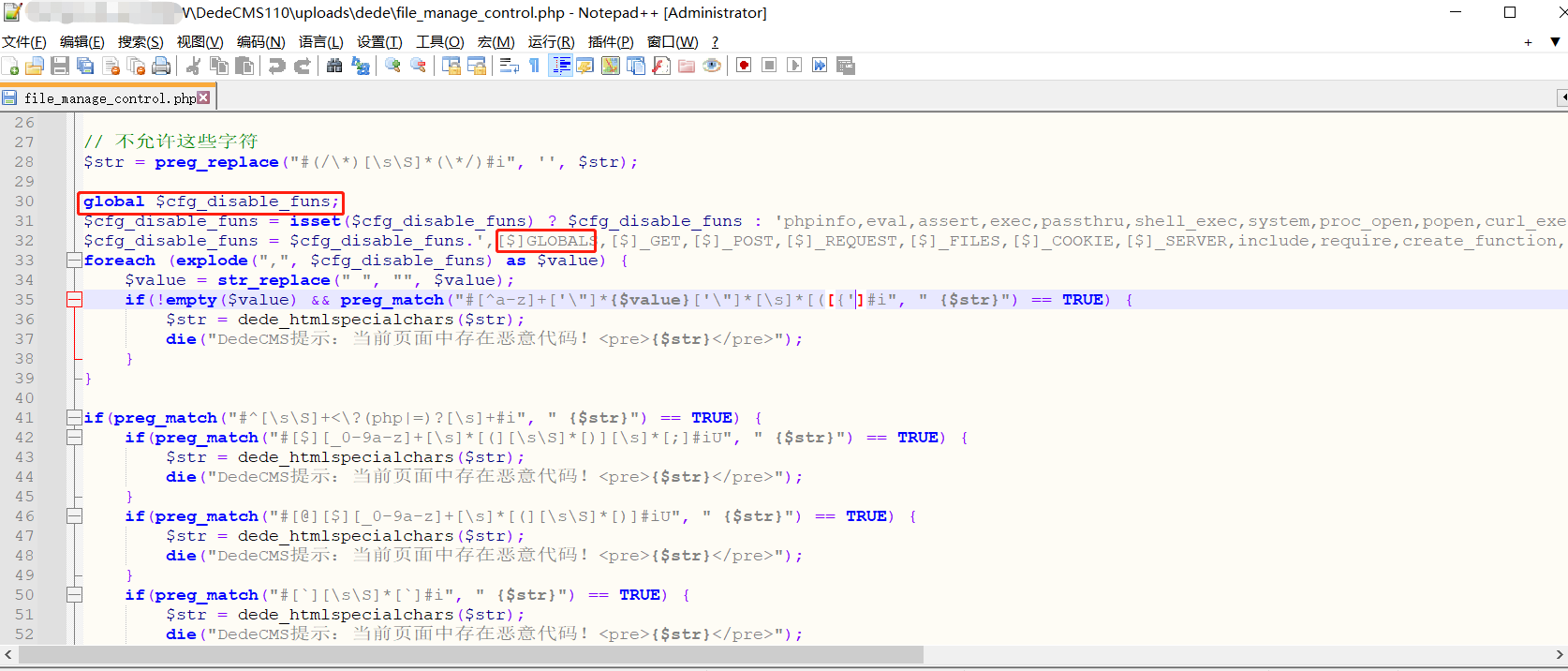
Dedecms V110最新版RCE---Tricks
前言 刚发现Dedecms更新了发布版本,顺便测试一下之前的day有没有修复,突然想到了新的tricks去实现RCE。 文章发布的时候估计比较晚了,一直没时间写了。 利用 /uploads/dede/article_string_mix.php /uploads/dede/article_template_rand.…...
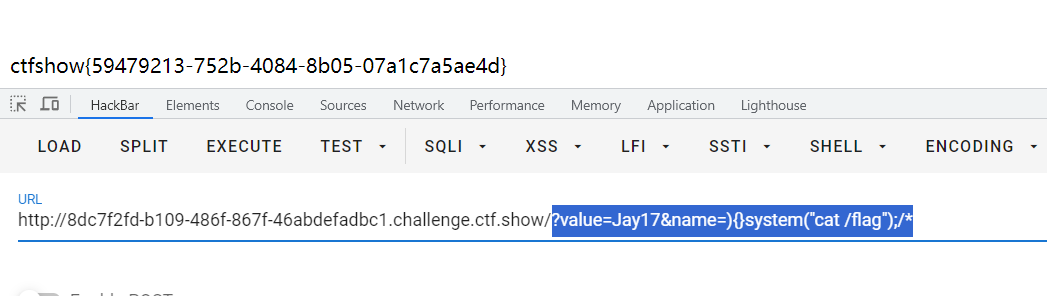
CTFshow 限时活动 红包挑战7、红包挑战8
CTFshow红包挑战7 写不出来一点,还是等了官方wp之后才复现。 直接给了源码 <?php highlight_file(__FILE__); error_reporting(2);extract($_GET); ini_set($name,$value);system("ls ".filter($_GET[1])."" );function filter($cmd){$cmd…...

Redis使用Lua脚本和Redisson来保证库存扣减中的原子性和一致性
文章目录 前言1.使用SpringBoot Redis 原生实现方式2.使用redisson方式实现3. 使用RedisLua脚本实现3.1 lua脚本代码逻辑 3.2 与SpringBoot集成 4. Lua脚本方式和Redisson的方式对比5. 源码地址6. Redis从入门到精通系列文章7. 参考文档 前言 背景:最近有社群技术交…...
【从零开始学Kaggle竞赛】泰坦尼克之灾
目录 0.准备1.问题分析挑战流程数据集介绍结果提交 2.代码实现2.1 加载数据2.1.1 加载训练数据2.1.2 加载测试数据 2.2 数据分析2.3 模型建立与预测 3.结果提交 0.准备 注册kaggle账号后,进入titanic竞赛界面 https://www.kaggle.com/competitions/titanic 进入后界…...

输出无重复的3位数和计算无人机飞行坐标
编程题总结 题目一:输出无重复的3位数 题目描述 从{1,2,3,4,5,6,7,8,9}中随机挑选不重复的5个数字作为输入数组‘selectedDigits’,能组成多少个互不相同且无重复数字的3位数?请编写程》序,从小到大顺序,以数组形式输出这些3位…...

muduo 29 异步日志
目录 Muduo双缓冲异步日志模型: 异步日志实现: 为什么要实现非阻塞的日志...

Qt 对象序列化/反序列化
阅读本文大概需要 3 分钟 背景 日常开发过程中,避免不了对象序列化和反序列化,如果你使用 Qt 进行开发,那么有一种方法实现起来非常简单和容易。 实现 我们知道 Qt 的元对象系统非常强大,基于此属性我们可以实现对象的序列化和…...
)
从零学算法(非官方题库)
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构) B是A的子结构, 即 A中有出现和B相同的结构和节点值。 例如: 给定的树 A:3/ \4 5/ \1 2给定的树 B:4 / 1返回 true,因为 B 与 A 的一个子树拥有相…...

Java # JVM内存管理
一、运行时数据区域 程序计数器、Java虚拟机栈、本地方法栈、Java堆、方法区、运行时常量池、直接内存 二、HotSpot虚拟机对象 对象创建: 引用检查类加载检查分配内存空间:指针碰撞、空闲列表分配空间初始化对象信息设置(对象头内࿰…...

大疆第二批笔试复盘
大疆笔试复盘(8-14) 笔试时候的状态和下来复盘的感觉完全不一样,笔试时脑子是懵的。 (1)输出无重复三位数 题目描述 从 { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } \left \{ 1,2,3,4,5,6,7,8,9 \right \...

【Linux】磁盘或内存 占用比较高要怎么排
当 Linux 磁盘空间满了时 请注意,在进行任何删除操作之前,请确保你知道哪些文件可以安全删除,并备份重要文件,以免意外丢失数据。当 Linux 磁盘空间满了时,可以按照以下步骤进行排查: 检查磁盘使用情况&…...
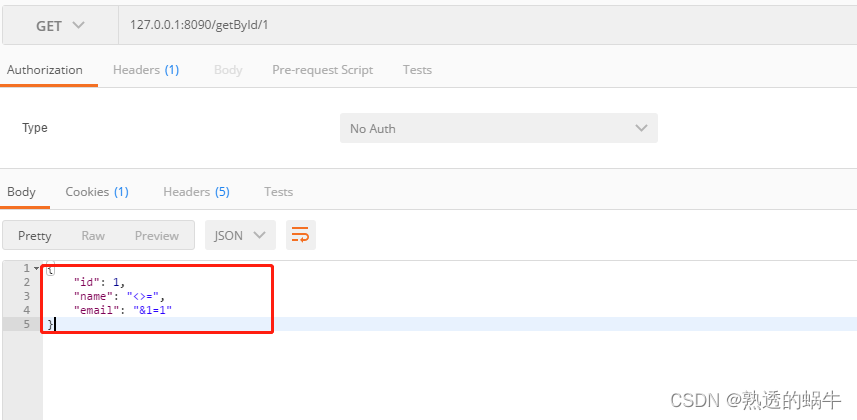
解决xss转义导致转码的问题
一、xss简介 人们经常将跨站脚本攻击(Cross Site Scripting)缩写为CSS,但这会与层叠样式表(Cascading Style Sheets,CSS)的缩写混淆。因此,有人将跨站脚本攻击缩写为XSS。跨站脚本攻击ÿ…...

AI智能体到底强在哪?为什么大家开始从“养龙虾”转向“养马”
那么AI智能体的核心能力是什么? 1、理解需求 它能分析你的真实意图,而不是只看表面的文字,比如让它整理这个月的消费情况,它明白之后,会读取账单,做分类统计,生成总结,最后输出图表。…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

PentestGPT实战部署指南:AI驱动的渗透测试工作流落地
1. 这不是另一个“AI安全”的概念玩具,而是一套能真正跑起来的渗透测试辅助工作流“PentestGPT”这个名字刚在GitHub上出现时,我第一反应是点开又关掉——过去三年里,我见过太多打着“AI渗透”旗号的项目:有的只是把ChatGPT API封…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...

【RT-DETR实战】070、模型分析工具:PyTorch Profiler性能分析
上周在部署RT-DETR到边缘设备时遇到一个诡异现象:模型推理时延波动极大,有时30ms,偶尔突然跳到200ms。 盯着代码看了半天没发现逻辑问题,数据流也正常。这种时候,靠猜是没用的,必须上性能分析工具——PyTorch Profiler。 今天我们就来聊聊怎么用它揪出那些藏在细节里的…...

ZYNQ中断避坑指南:PL端信号线如何正确‘连线’到PS端处理函数?
ZYNQ中断系统深度解析:从硬件信号到软件响应的全链路实践 在嵌入式系统开发中,中断处理是实时响应的核心机制。对于ZYNQ这种集成了ARM处理器(PS)和可编程逻辑(PL)的异构计算平台,其中断系统既有传统处理器的特性,又具备FPGA灵活定…...