深度学习优化器
1、什么是优化器
优化器用来寻找模型的最优解。

2、常见优化器
2.1. 批量梯度下降法BGD(Batch Gradient Descent)
2.1.1、BGD表示
BGD 采用整个训练集的数据来计算 cost function 对参数的梯度:
-
假设要学习训练的模型参数为W,代价函数为J(W),则代价函数关于模型参数的偏导数即相关梯度为ΔJ(W),学习率为ηt,则使用梯度下降法更新参数为:
Wt+1=Wt−ηtΔJ(Wt)
其中,Wt表示tt时刻的模型参数。 - 从表达式来看,模型参数的更新调整,与代价函数关于模型参数的梯度有关,即沿着梯度的方向不断减小模型参数,从而最小化代价函数。
- 基本策略可以理解为”在有限视距内寻找最快路径下山“,因此每走一步,参考当前位置最陡的方向(即梯度)进而迈出下一步。
2.1.2、BGD优缺点
-
训练速度慢:每走一步都要要计算调整下一步的方向,下山的速度变慢。在应用于大型数据集中,每输入一个样本都要更新一次参数,且每次迭代都要遍历所有的样本。会使得训练过程及其缓慢,需要花费很长时间才能得到收敛解。
-
容易陷入局部最优解:由于是在有限视距内寻找下山的反向。当陷入平坦的洼地,会误以为到达了山地的最低点,从而不会继续往下走。所谓的局部最优解就是鞍点。落入鞍点,梯度为0,使得模型参数不在继续更新。
2.2、随机梯度下降(SGD)
2.2.1、SGD表示
和 BGD 的一次用所有数据计算梯度相比,SGD 每次更新时对每个样本进行梯度更新,对于很大的数据集来说,可能会有相似的样本,这样 BGD 在计算梯度时会出现冗余,而 SGD 一次只进行一次更新,就没有冗余,而且比较快,并且可以新增样本。

随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况,那么可能只用其中部分的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。缺点是SGD的噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。所以虽然训练速度快,但是准确度下降,并不是全局最优。虽然包含一定的随机性,但是从期望上来看,它是等于正确的导数的。
2.2.2、SGD优缺点
优点:
-
引入噪声,增加模型的鲁棒性。虽然SGD需要走很多步的样子,但是对梯度的要求很低(计算梯度快)。而对于引入噪声,大量的理论和实践工作证明,只要噪声不是特别大,SGD都能很好地收敛。
- 应用大型数据集时,训练速度很快。比如每次从百万数据样本中,取几百个数据点,算一个SGD梯度,更新一下模型参数。相比于标准梯度下降法的遍历全部样本,每输入一个样本更新一次参数,要快得多。
缺点:
- SGD在随机选择梯度的同时会引入噪声,使得权值更新的方向不一定正确。
- 此外,SGD也没能单独克服局部最优解的问题。
- SGD 因为更新比较频繁,会造成 cost function 有严重的震荡。
- BGD 可以收敛到局部极小值,当然 SGD 的震荡可能会跳到更好的局部极小值处。
- 当我们稍微减小 learning rate,SGD 和 BGD 的收敛性是一样的。
2.3、批量梯度下降MBGD(Mini-Batch Gradient Descent)
2.3.1、MBGD梯度下降表示
梯度更新规则:
MBGD 每一次利用一小批样本,即 n(50-256) 个样本进行计算,这样它可以降低参数更新时的方差,收敛更稳定,另一方面可以充分地利用深度学习库中高度优化的矩阵操作来进行更有效的梯度计算。

2.3.2、MBGD优缺点
优点:
- 批量梯度下降法比标准梯度下降法训练时间短,且每次下降的方向都很正确。
- 可以降低参数更新时的方差,收敛更稳定。
- 可以充分地利用深度学习库中高度优化的矩阵操作来进行更有效的梯度计算。
缺点:
- 不能保证很好的收敛。不过 Mini-batch gradient descent 不能保证很好的收敛性,learning rate 如果选择的太小,收敛速度会很慢,如果太大,loss function 就会在极小值处不停地震荡甚至偏离。(有一种措施是先设定大一点的学习率,当两次迭代之间的变化低于某个阈值后,就减小 learning rate,不过这个阈值的设定需要提前写好,这样的话就不能够适应数据集的特点。)
- 可能陷入鞍点或局部最小点。对于非凸函数,还要避免陷于局部极小值处,或者鞍点处,因为鞍点周围的error是一样的,所有维度的梯度都接近于0,SGD 很容易被困在这里。(会在鞍点或者局部最小点震荡跳动,因为在此点处,如果是训练集全集带入即BGD,则优化会停止不动,如果是mini-batch或者SGD,每次找到的梯度都是不同的,就会发生震荡,来回跳动。)
- 应用同样的 learning rate,不能适应所有的参数。如果我们的数据是稀疏的,我们更希望对出现频率低的特征进行大一点的更新。LR会随着更新的次数逐渐变小。
2.4、动量(冲量)梯度下降法Momentum(Batch Gradient Descent Momentum)
2.4.1、Momentum描述
SGD的梯度下降过程,类似于一个小球从山坡上滚下,它的前进方向由当前山坡的最大倾斜方向与之前的下降方向共同决定,小球具有初速度(动量),不只被梯度制约。SGDM克服了之前SGD易震荡的缺点。使用动量(Momentum)的随机梯度下降法(SGD),主要思想是引入一个积攒历史梯度信息动量来加速SGD。

2.4.2、Momentum优缺点
优点:
1、引入积攒的历史梯度信息动量加速参数更新
2、一定程度解决了SGD易震荡的问题
缺点:
1、全过程使用了相同的学习率
2、在Momentun中小球会盲目地跟从下坡的梯度,容易发生错误。
2.5、牛顿加速梯度NAG(Nesterov accelerated gradient)
2.5.1、NAG描述
NAG是Momentum动量算法的变种。更新模型参数表达式如下:

- Nesterov动量梯度的计算在模型参数施加当前速度之后,因此可以理解为往标准动量中添加了一个校正因子。
- 理解策略:在Momentun中小球会盲目地跟从下坡的梯度,容易发生错误。所以需要一个更聪明的小球,能提前知道它要去哪里,还要知道走到坡底的时候速度慢下来而不是又冲上另一个坡。计算Wt−αvt−1可以表示小球下一个位置大概在哪里。从而可以提前知道下一个位置的梯度,然后使用到当前位置来更新参数。
2.5.2、NAG优缺点
优点
在momentun SGD基础上添加了一个校正因子,避免盲目跟从梯度下降方向
缺点
固定学习率
2.6、AdaGrad
自适应学习率优化算法针对于机器学习模型的学习率,传统的优化算法要么将学习率设置为常数要么根据训练次数调节学习率。极大忽视了学习率其他变化的可能性。然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。目前的自适应学习率优化算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法。这类算法可以对低频的参数做较大的更新,对高频的做较小的更新,也因此,对于稀疏的数据它的表现很好,很好地提高了 SGD 的鲁棒性。
AdaGrad算法,独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平均值总和的平方根。具有代价函数最大梯度的参数相应地有个快速下降的学习率,而具有小梯度的参数在学习率上有相对较小的下降。
梯度更新规则:

- 从表达式可以看出,对出现比较频繁的特征,Adagrad给予越来越小的学习率,而对于比较少的特征,会给予较大的学习率。因此Adagrad适用于数据稀疏或者分布不平衡的数据集。
2.6.2、Adagrad优缺点
优点:
Adagrad适用于数据稀疏或者分布不平衡的数据集
Adagrad 的主要优势在于不需要人为的调节学习率,它可以自动调节;
缺点:
随着迭代次数增多,学习率会越来越小,最终会趋近于0。
2.7、RMSProp
2.7.1、RMSProp描述
RMSProp是对Adagrad的一个改进,它解决了Adagrad优化过程中学习率 η 单调减少问题。Adadelta不再对过去的梯度平方进行累加,而是改用加权平均

2.7.2、RMSProp优缺点
优点
不再对过去的梯度平方进行累加,通过指数衰减平均值,解决了Adagrad学习率单调递减问题
缺点
需指定全局学习率
2.8、AdaDelta算法
2.8.1、AdaDelta描述
思想:AdaGrad算法和RMSProp算法都需要指定全局学习率,AdaDelta算法结合两种算法每次参数的更新步长

2.8.2、AdaDelta优缺点
优点
结合adgrad和rmsprob算法,通过前t-1累加梯度指定学习率,无需指定全局学习率
缺点
在优化前期和中期效果较好,后期在局部最小点震荡。
2.9、Adam
这个算法是另一种计算每个参数的自适应学习率的方法。相当于 RMSprop + Momentum,除了像 Adadelta 和 RMSprop 一样存储了过去梯度的平方 vt 的指数衰减平均值 ,也像 momentum 一样保持了过去梯度 mt 的
相关文章:
深度学习优化器
1、什么是优化器 优化器用来寻找模型的最优解。 2、常见优化器 2.1. 批量梯度下降法BGD(Batch Gradient Descent) 2.1.1、BGD表示 BGD 采用整个训练集的数据来计算 cost function 对参数的梯度: 假设要学习训练的模型参数为W,代价函数为J(W),…...

由浅入深C系列五:使用libcurl进行基于http get/post模式的C语言交互应用开发
使用libcurl进行基于http get/post模式的C语言交互应用开发 简介环境准备在线资源示例代码测试调用运行结果 简介 大多数在linux下的开发者,都会用到curl这个命令行工具。对于进行restful api的测试等,非常方便。其实,这个工具还提供了一个C…...
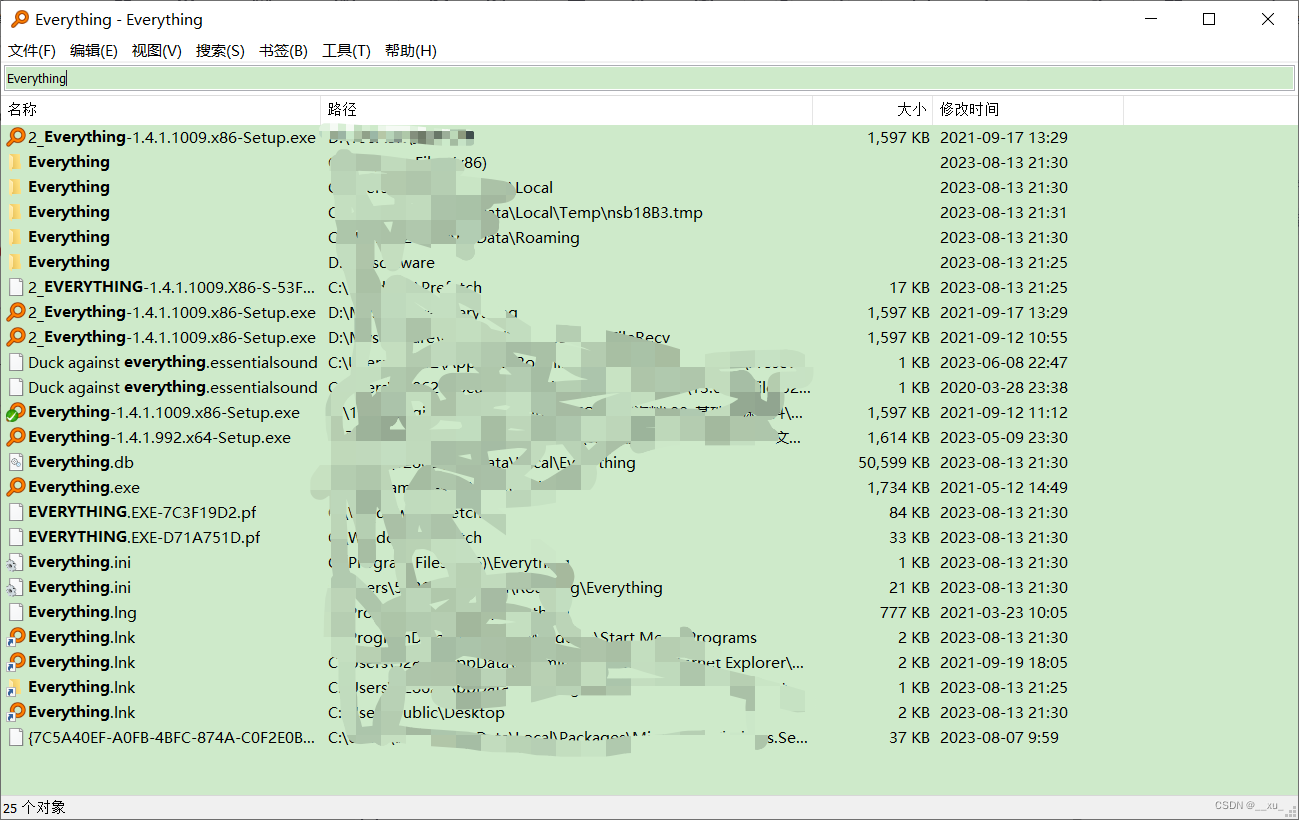
高效实用小工具之Everything
一,简介 有时候我们电脑文件较多时,想快速找到某个文件不是一件容易的事情,实用windows自带的搜素太耗时,效率不高。今天推荐一个用来搜索电脑文件的小工具——Everything,本文将介绍如何安装以及使用everything&…...

【Unity每日一记】关于物体(敌方)检测—(向量点乘相关)
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:uni…...

Elasticsearch-查询
一、查询和过滤 1.1 相关性分数 :_score 默认情况下,Elasticsearch 按相关性得分对匹配的搜索结果进行排序,相关性得分衡量每个文档与查询的匹配程度。 相关性分数是一个正浮点数,在搜索的数据字段中返回。_score越高࿰…...
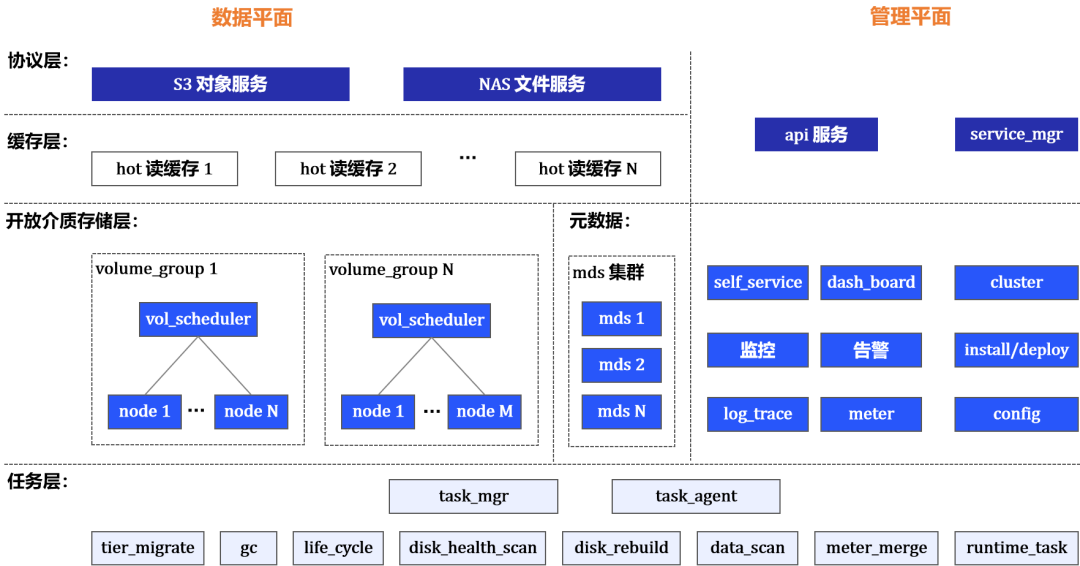
首发 | FOSS分布式全闪对象存储系统白皮书
一、 产品概述 1. 当前存储的挑战 随着云计算、物联网、5G、大数据、人工智能等新技术的飞速发展,数据呈现爆发式增长,预计到2025年中国数据量将增长到48.6ZB,超过80%为非结构化数据。 同时,数字经济正在成为我国经济发展的新…...

Java反射获取所有Controller和RestController类的方法
Java反射获取所有Controller和RestController类的方法 引入三方反射工具Reflections <dependency><groupId>org.reflections</groupId><artifactId>reflections</artifactId><version>0.10.2</version> </dependency>利用反…...

设计模式--策略模式
目录 一.场景 1.1场景 2.2 何时使用 2.3个人理解 二. 业务场景练习 2.1业务: 2.2具体实现 2.3思路 三.总结 3.1策略模式的特点: 3.2策略模式优点 3.3策略模式缺点 一.场景 1.1场景 许多相关的类仅仅是行为有异,也就是说业务代码需要根据场景不…...
VSCode使用SSH无密码连接Ubuntu
VSCode使用SSH无密码连接Ubuntu 前提条件: 1. 能够正常使用vscode的Remote-ssh连接Ubuntu 2. Ubuntu配置静态ip(否则经常需要修改Remote-ssh的配置文件里的IP) 1. windows下 打开Win下的PowerShell,生成公钥和私钥 ssh-keygen…...
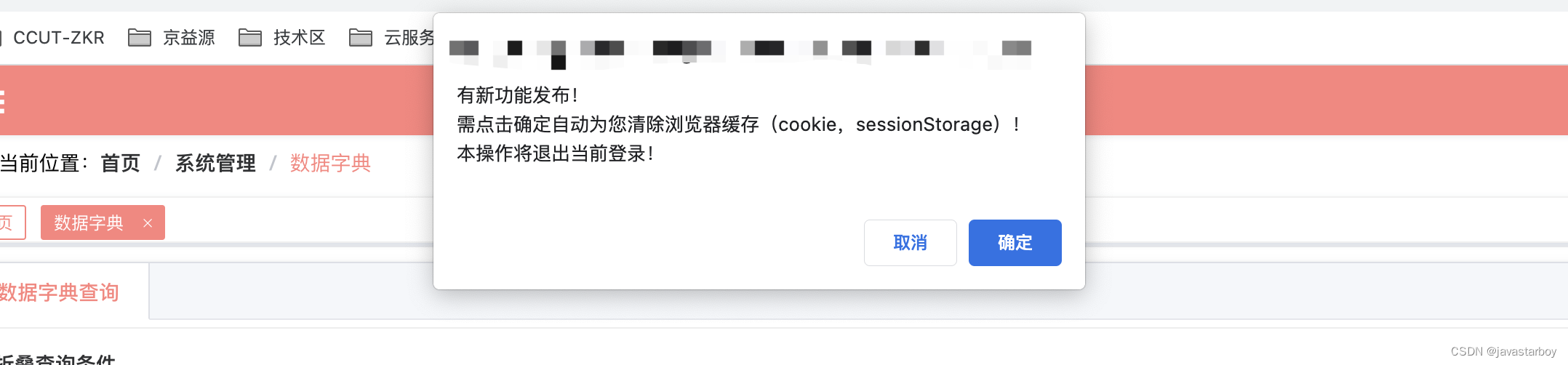
通过版本号控制强制刷新浏览器或清空浏览器缓存
背景介绍 在我们做 web 项目时,经常会遇到一个问题就是,需要 通知业务人员(系统用户)刷新浏览器或者清空浏览器 cookie 缓存的情况。 而对于用户而言,很多人一方面不懂如何操作,另一方面由于执行力问题&am…...
Redis系列(二):深入解读Redis的两种持久化方式
博客地址:blog.zysicyj.top Redis为什么要引入持久化机制 Redis引入持久化机制是为了解决内存数据库的数据安全性和可靠性问题。虽然内存数据库具有高速读写的优势,但由于数据存储在内存中,一旦服务器停止或崩溃,所有数据将会丢失…...
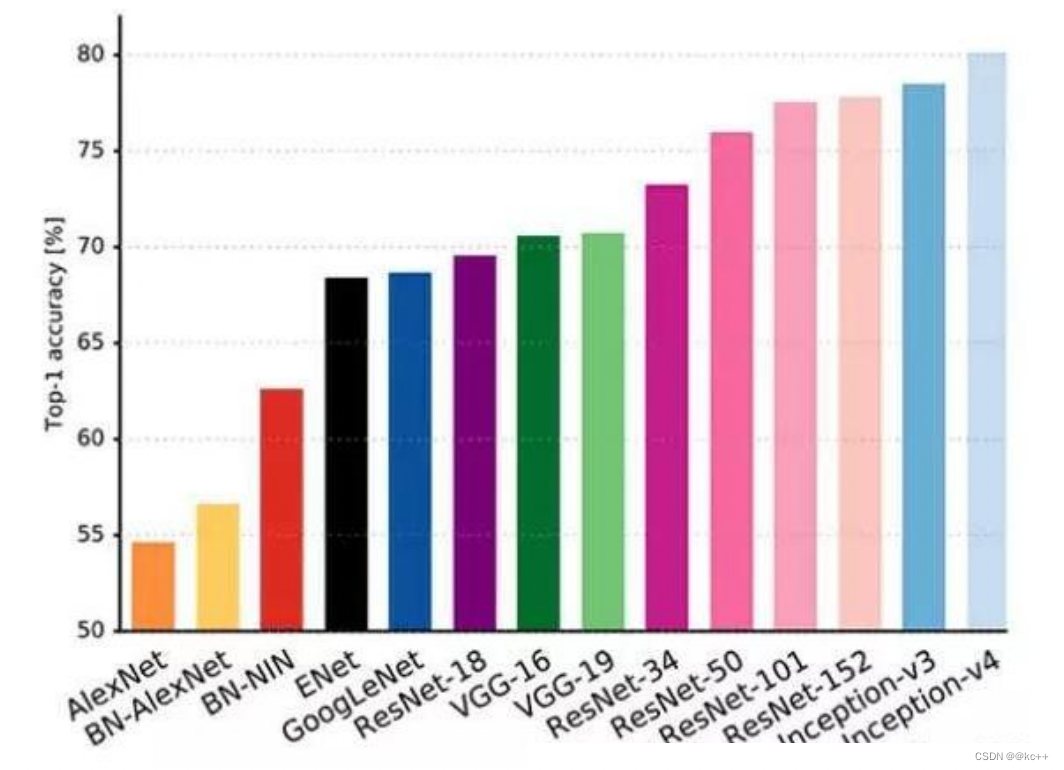
CNN之图像识别
文章目录 1. 图像识别1.1 模式识别1.2 图像识别的过程1.3 图像识别的应用 2. 深度学习发展2.1 深度学习为何崛起2.2 分类与检测2.3 常见的卷积神经网络 3. VGG3.1 VGG163.2 VGG16的结构:3.3 使用卷积层代替全连接3.4 1*1卷积的作用3.5 VGG16代码示例 4. 残差模型-Re…...

nvcc not found
检查cuda 安装成功 nvidia-smiCommand ‘nvcc’ not found, apt install nvidia-cuda-toolkitnvcc fatal : No input files specified; use option --help for more information # 注意是大写 V nvcc -V export PATH"/usr/local/cuda/bin:$PATH" expor…...
pdf怎么转换成jpg图片?这几个转换方法了解一下
pdf怎么转换成jpg图片?转换PDF文件为JPG图片格式在现代工作中是非常常见的需求,比如将PDF文件中的图表、表格或者图片转换为JPG格式后使用在PPT演示、网页设计等场景中。 【迅捷PDF转换器】是一款非常实用的工具,可以将PDF文件转换成多种不同…...
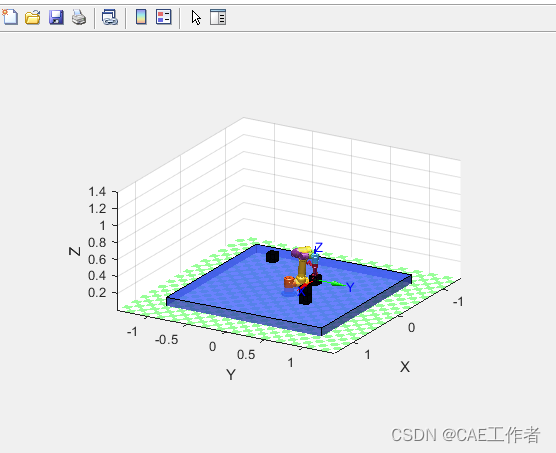
六轴机械臂码垛货物堆叠仿真
六轴机械臂码垛货物堆叠仿真 1、建立模型与仿真 clear,clc,close all addpath(genpath(.)) %建立模型参数如下: L(1) Link( d, 0.122, a , 0 , alpha, pi/2,offset,0); L(2) Link( d, 0.019 , a ,0.408 , alpha, 0,offset,pi/2); L(3) Link( d, …...

text-decoration 使用
text-decoration text-decoration 用于设置文本上的装饰性线条的外观。 它是 text-decoration-line、text-decoration-style、text-decoration-color 和text-decoration-thickness的缩写。 text-decoration: underline wavy red;text-decoration-line 设置文本装饰类型 可以…...

linux shell快速入门
linux shell快速入门 0 、前置1、简单使用 0 、前置 一安装linux的虚拟环境 1、简单使用 1、新建/usr/shell目录 2、新建hello.sh 文件 3、编写脚本文件# !/bin/bashecho "hello world"查看是否具备执行权限 新增执行权限 chomd x hello.sh执行hello.sh文件 /b…...

【Spring源码】小白速通解析Spring源码,从0到1,持续更新!
Spring源码 参考资料 https://www.bilibili.com/video/BV1Tz4y1a7FM https://www.bilibili.com/video/BV1iz4y1b75q bean的生命周期 bean–>推断构造方法(默认是无参构造,或指定的构造方法)–>实例化成普通对象(相当于ne…...
Unity 鼠标实现对物体的移动、缩放、旋转
文章目录 1. 代码2. 测试场景 1. 代码 using UnityEngine;public class ObjectManipulation : MonoBehaviour {// 缩放比例限制public float MinScale 0.2f;public float MaxScale 3.0f;// 缩放速率private float scaleRate 1f;// 新尺寸private float newScale;// 射线pri…...

67Class 的基本语法
Class 的基本语法 类的由来[constructor() 方法](https://es6.ruanyifeng.com/#docs/class#constructor() 方法)类的实例实例属性的新写法取值函数(getter)和存值函数(setter)属性表达式[Class 表达式](https://es6.ruanyifeng.c…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...

深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 [特殊字符]
深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 🎮 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com…...

VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案
VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网…...

热电效应自发电自行车灯:利用体温实现免充电照明的工程实践
1. 项目概述:从人体体温到自行车灯光你有没有想过,骑自行车时身体散发出的热量,除了让你出汗,还能干点什么?这个项目就是把我们骑车时产生的“废热”,变成照亮前路的灯光。听起来有点像科幻情节,…...

监控摄像头小众场景爆发,融合类产品成新蓝海
随着户外运动热潮的持续和物联网技术的全面落地,打猎相机市场在2025年迎来了真正的爆发期,并在2026年继续向智能化、网联化深度演进。根据最新的行业监测数据,2025年全球消费类IPC(网络摄像机)出货量突破1.92亿台&…...

终极跨平台空洞骑士模组管理器:Lumafly如何让模组管理变得简单高效
终极跨平台空洞骑士模组管理器:Lumafly如何让模组管理变得简单高效 【免费下载链接】Lumafly A cross platform mod manager for Hollow Knight written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/lu/Lumafly 你是否曾经因为空洞骑士模组安装…...

LVGL事件处理实战:从按钮点击到复杂手势,手把手教你写响应式UI回调
LVGL事件处理实战:从按钮点击到复杂手势,手把手教你写响应式UI回调 在嵌入式系统开发中,用户界面的交互体验往往决定了产品的成败。LVGL作为轻量级通用图形库,其事件处理机制是构建动态交互的核心。不同于简单的回调函数绑定&…...
从主题到视频:Pixelle-Video如何用AI重构你的内容创作流程
从主题到视频:Pixelle-Video如何用AI重构你的内容创作流程 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 想象一下…...