使用vector<char>作为输入缓冲区
一、引言
当我们编写代码:实现网络接收、读取文件内容等功能时,我们往往要在内存中开辟一个输入缓冲区(又名:input buffer/读缓冲区)来存贮接收到的数据。在C++里面我们可以用如下方法开辟输入缓冲区。
①使用C语言中的数组:
char buf[100] = {0};②使用malloc/new动态分配内存:
char *pBuf = new char[100];③使用std::string
string sBuf;④使用vector<char> / vector<unsigned char>
vector<char> vecBuf(100);在这里面推荐使用方法④作为输入缓冲区。方法①在栈中开辟空间,对于大数组可能会有栈内存不够的问题。方法②在堆上分配内存,但是使用完需要程序员自行手动释放(delete pBuf),而且需要一个额外的变量记录申请空间的大小。方法③只能处理字符串,不能处理二进制数据。下面具体阐述使用vector<char>作为输入缓冲区的优势。
二、使用vector<char>作为输入缓冲区的优势
(一)跟方法①相比,vector<char>可以在程序运行时调整大小
例子1:
main.cpp
#include <iostream>
#include <fstream>
#include <vector>
#include <windows.h>// 通过stat结构体 获得文件大小,单位字节
size_t getFileSize1(const char* fileName) {if (fileName == NULL) {return 0;}// 这是一个存储文件(夹)信息的结构体,其中有文件大小和创建时间、访问时间、修改时间等struct stat statbuf;// 提供文件名字符串,获得文件属性结构体stat(fileName, &statbuf);// 获取文件大小size_t filesize = statbuf.st_size;return filesize;
}int main()
{const char *fileName = "test.txt";std::ifstream ifs(fileName);int nFileSize = getFileSize1(fileName);char buf[100] = { 0 };ifs.read(buf, sizeof(buf));printf("%s", buf);return 0;
}test.txt
hello world!运行效果:
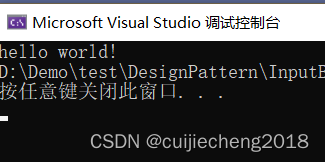
上述的例子中,定义一个大小为100字节的数组buf,一次性读取文件test.txt中的内存,并保存到buf里面,然后打印。该代码存在的问题是:假如文件test.txt中的内容非常多,超过数组的最大容量(100个字节),则超出数组容量外(超过100个字节之外)的数据会丢失。针对该问题我们可以尝试将上述代码优化为例子2。
例子2:
我们将例子1中的语句 char buf[100] = { 0 }; 修改为:char buf[nFileSize] = { 0 };
结果编译报错了:

在例子2中,我们尝试将数组buf的大小定义为要读取的文件的大小。很明显,这样是不行的,因为定义数组的时候,数组的大小必须确定,并且得是整型。我们继续优化代码。
例子3:
main.cpp
#include <iostream>
#include <fstream>
#include <vector>
#include <windows.h>// 通过stat结构体 获得文件大小,单位字节
size_t getFileSize1(const char* fileName) {if (fileName == NULL) {return 0;}// 这是一个存储文件(夹)信息的结构体,其中有文件大小和创建时间、访问时间、修改时间等struct stat statbuf;// 提供文件名字符串,获得文件属性结构体stat(fileName, &statbuf);// 获取文件大小size_t filesize = statbuf.st_size;return filesize;
}int main()
{const char *fileName = "test.txt";std::ifstream ifs(fileName);int nFileSize = getFileSize1(fileName);std::vector<char> vecBuf(nFileSize);ifs.read(&vecBuf[0], vecBuf.size());for (const auto& e : vecBuf){std::cout << e;}return 0;
}运行效果如下:

例子3使用了vector<char>,所以可以在程序运行过程中调整大小(可以用resize()调整vector大小)。从而解决例子2中的问题。可能有些朋友会说用方法②“使用malloc/new动态分配内存”,不一样可以吗?确实是可以。但是vector<char>相当于对malloc/new进行了一层封装,使用起来更方便。而且不用手动调用delete函数释放内存,避免内存泄漏。
(二)跟方法②相比,vector<char>提供了各种方法
使用vector::reserve预分配内存
使用vector::size的记录缓冲区位置
使用vector::resize增长/清除缓冲区
使用&your_vector[0]转换为C缓冲区
使用vector::swap转换缓冲区所有权
例子4:
int bufsize = 4096;
char *pBuf = new char[bufsize];
int recv = read(sock, pbuf, bufsize)例子4是一个网络接收的小demo。可以看到使用new的方式,需要额外增加一个变量bufsize来存贮缓冲区的大小。我们可以用vector<char>优化如下:
例子5:
std::vector<char> buf(4096); // create buffer with preallocated size
int recv = read( sock, &buf[0], buf.size() );可以看到vector已经提供了size()方法来记录缓冲区的大小,不需要再额外增加变量了。所以使用vector<char>更方便,而且离开作用域自动释放内存,不需要手动delete,更安全。
(三)跟方法③相比,vector<char>可以存贮二进制数据
例子6:
main.cpp
#include <iostream>
#include <vector>
#include <string>using namespace std;int main()
{string strBuf = "abc\0ef";cout << strBuf << endl;std::vector<char> vecBuf = { 'a', 'b', 'c', '\0', 'e', 'f'};for (const auto& e : vecBuf){std::cout << e;}return 0;
}运行效果如下:
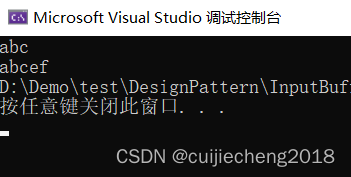
可以看到使用std::string丢失了'\0'之后的数据,但是vector<char>不会。所以std::string只能存贮字符串,不能存贮二进制数据。二进制数据中可能会包含0x00(即:'\0'),刚好是字符串结束标志,使用std::string会有截断问题。所以对于二进制数据的保存(比如保存图片,网络接收)我们得要用vector<char>,不要用string。
三、总结
综上所述。我们首选vector<char>作为输入缓冲区。
参考:
What is the advantage of using vector<char> as input buffer over char array?
How do I use vector as input buffer for socket in C++
A more elegant way to use recv() and vector<unsigned char>
What are differences between std::string and std::vector<char>?
相关文章:
使用vector<char>作为输入缓冲区
一、引言 当我们编写代码:实现网络接收、读取文件内容等功能时,我们往往要在内存中开辟一个输入缓冲区(又名:input buffer/读缓冲区)来存贮接收到的数据。在C里面我们可以用如下方法开辟输入缓冲区。 ①使用C语言中的数组&#x…...

自己在网站搭建用到的一些网站
背景 以后可能很少做网站类的项目了,所以做个简单总结,把自己的一些经历和一些小工具做个记录 域名和主机 https://www.godaddy.com/zh-sg, 我之前的基本都是国际会议型的网站,所以就在gadaddy上买了主机和域名。目标群体在国内可以考虑腾…...

XLSReadWriteII5 Color 颜色l的调用和使用
XLSReadWriteII5 Color 颜色l的调用和使用 一、色彩三原色 自然界,颜色是由红、绿、蓝三色组成,人眼的可见的颜色,可以通过红、绿、蓝三色按照不同的比例合成产生。 任意一种颜色由这三种原色按照一定的比例混合出来。 二、Windows系…...
RT-Thread SP使用教程
RT-Thread SPI 使用教程 实验环境使用的是正点原子的潘多拉开发板。 SPI从机设备使用的是BMP280温湿度大气压传感器。 使用RT-Thread Studio搭建基础功能。 1. 创建工程 使用RT-Thread Studio IDE创建芯片级的工程。创建完成后,可以直接编译下载进行测试。 2.…...

LeetCode 2363. 合并相似的物品
给你两个二维整数数组 items1 和 items2 ,表示两个物品集合。每个数组 items 有以下特质: items[i] [valuei, weighti] 其中 valuei 表示第 i 件物品的 价值 ,weighti 表示第 i 件物品的 重量 。 items 中每件物品的价值都是 唯一的 。 请你…...

numpy 中常用的数据保存、fmt多个参数
在经常性读取大量的数值文件时(比如深度学习训练数据),可以考虑现将数据存储为Numpy格式,然后直接使用Numpy去读取,速度相比为转化前快很多 一、保存为二进制文件(.npy/.npz) (1)numpy.save(file, arr, allow_pickleTrue, fix_importsTrue) file:文件名…...

从0到1一步一步玩转openEuler--19 openEuler 管理服务-特性说明
文章目录19 管理服务-特性说明19.1 更快的启动速度19.2 提供按需启动能力19.3 采用cgroup特性跟踪和管理进程的生命周期19.4 启动挂载点和自动挂载的管理19.5 实现事务性依赖关系管理19.6 与SysV初始化脚本兼容19.7 能够对系统进行快照和恢复19 管理服务-特性说明 19.1 更快的…...
完整思路Python代码)
23美赛E题:光污染(ICM)完整思路Python代码
问题E(综合评价与仿真题):光污染(ICM) 背景 光污染用于描述过度或不良使用人造光。我们称之为光污染的一些现象包括光侵入、过度照明和光杂波。在大城市,太阳落山后,这些现象最容易在天空中看到;然而,它们也可能发生在更偏远的地区。 光污染会改变我们对夜空的看法,…...

快速排序的描述以及两种实现方案
一、快速排序描述 每一轮排序选择一个基准点(pivot)进行分区 1.1. 让小于基准点的元素的进入一个分区,大于基准点的元素的进入另一个分区 1.2. 当分区完成时,基准点元素的位置就是其最终位置在子分区内重复以上过程,直…...

算力引领 数“聚”韶关——第二届中国韶关大数据创新创业大赛圆满收官
为进一步促进数字经济领域创新创业发展,推动国家数据中心集群建设,构建大数据领域资源专业平台,促进大湾区大数据科技成果和创新创业人才转化落地,为韶关大数据领域创新型产业集群的打造、大数据科技成果和创新创业人才的转化落地…...
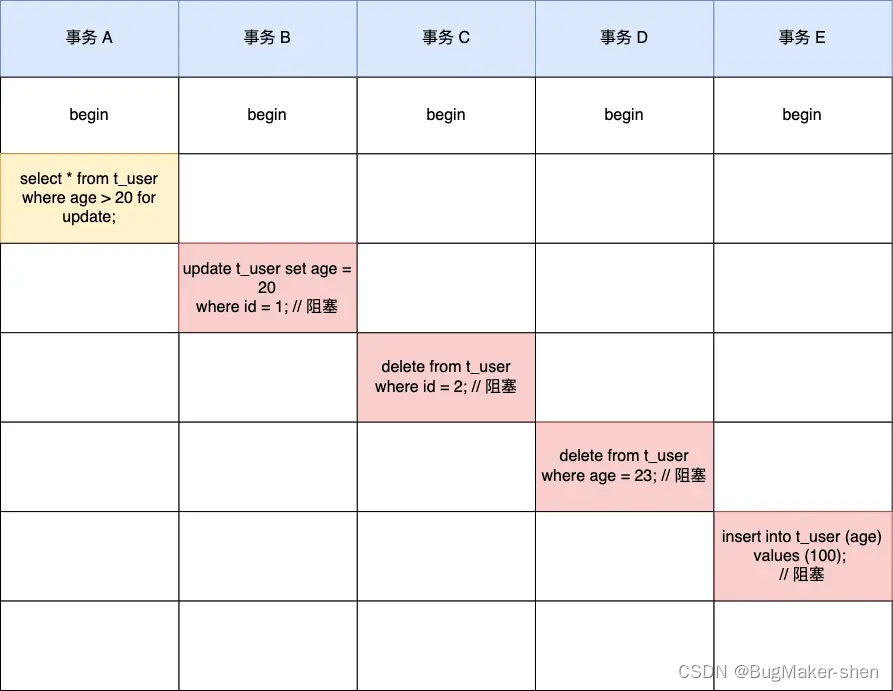
MySQL 记录锁+间隙锁可以防止删除操作而导致的幻读吗?
文章目录什么是幻读?实验验证加锁分析总结什么是幻读? 首先来看看 MySQL 文档是怎么定义幻读(Phantom Read)的: The so-called phantom problem occurs within a transaction when the same query produces different sets of r…...

【分库分表】企业级分库分表实战方案与详解(MySQL专栏启动)
📫作者简介:小明java问道之路,2022年度博客之星全国TOP3,专注于后端、中间件、计算机底层、架构设计演进与稳定性建设优化,文章内容兼具广度、深度、大厂技术方案,对待技术喜欢推理加验证,就职于…...
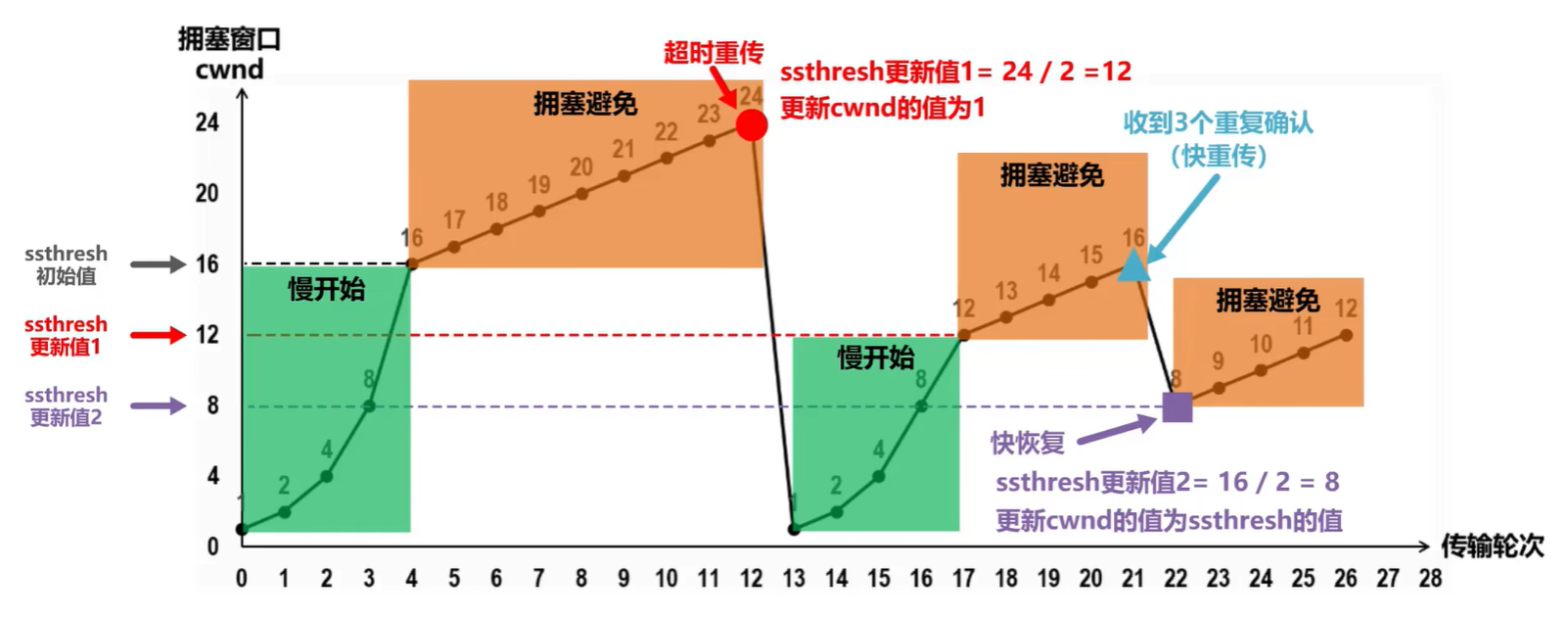
(考研湖科大教书匠计算机网络)第五章传输层-第五节:TCP拥塞控制
获取pdf:密码7281专栏目录首页:【专栏必读】考研湖科大教书匠计算机网络笔记导航 文章目录一:拥塞控制概述二:拥塞控制四大算法(1)慢开始和拥塞避免A:慢启动(slow start)…...

13.使用自动创建线程池的风险,要自己创建为好
自动创建线程池就是直接调用 Executors去new默认的那几个线程池,但是会出现一定的风险,线程池里面会用到队列,也会跟线程池自身有关,所以要从队列和线程池两个方面去解析。 1.了解线程池的队列 线程池的内部结构主要由四部分组成…...
【项目设计】—— 负载均衡式在线OJ平台
目录 一、项目的相关背景 二、所用技术栈和开发环境 三、项目的宏观结构 四、compile_server模块设计 1. 编译服务(compiler模块) 2. 运行服务(runner模块) 3. 编译并运行服务(compile_run模块) 4…...
Docker学习笔记
1:docker安装步骤Linux 2:docker安装步骤Windows 3:docker官方文档 4:docker官方远程仓库 docker常用命令 1: docker images----查看docker中安装的镜像 2: docker pull nginx------在docker中安装Nginx镜…...

【爬虫理论实战】详解常见头部反爬技巧与验证方式 | 有 Python 代码实现
以下是常见头部反爬技巧与验证方式的大纲: User-Agent 字段的伪装方式,Referer 字段的伪装方式,Cookie 字段的伪装方式。 文章目录1. ⛳️ 头部反爬技巧1.1. User-Agent 字段&User-Agent 的作用1.2. 常见 User-Agent 的特征1.3. User-Age…...
基于SpringBoot+Vue的鲜花商场管理系统
【辰兮要努力】:hello你好我是辰兮,很高兴你能来阅读,昵称是希望自己能不断精进,向着优秀程序员前行! 博客来源于项目以及编程中遇到的问题总结,偶尔会有读书分享,我会陆续更新Java前端、后台、…...
)
华为OD机试 - 静态扫描最优成本(JS)
静态扫描最优成本 题目 静态扫描快速识别源代码的缺陷,静态扫描的结果以扫描报告作为输出: 文件扫描的成本和文件大小相关,如果文件大小为 N ,则扫描成本为 N 个金币扫描报告的缓存成本和文件大小无关,每缓存一个报告需要 M 个金币扫描报告缓存后,后继再碰到该文件则不…...
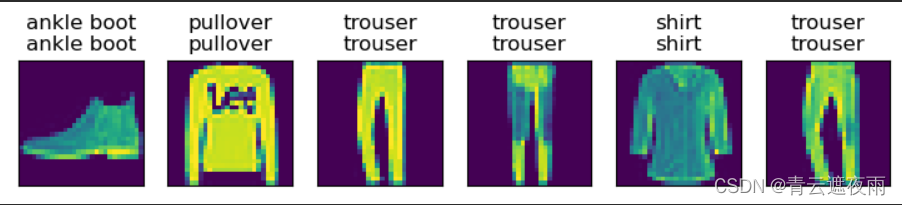
多层感知机
多层感知机理论部分 本文系统的讲解多层感知机的pytorch复现,以及详细的代码解释。 部分文字和代码来自《动手学深度学习》!! 目录多层感知机理论部分隐藏层多层感知机数学逻辑激活函数1. ReLU函数2. sigmoid函数3. tanh函数多层感知机的从零…...

基于Dify平台快速构建AI对话机器人:从部署到生产级实践
1. 项目概述与核心价值最近在折腾AI应用落地的过程中,我反复被一个问题困扰:如何把一个强大的大语言模型(LLM)能力,快速、低成本地封装成一个能实际解决业务问题的对话机器人?自己从零开始搭框架、写API、处…...

3PEAK思瑞浦 TP2274-TS2R TSSOP14 精密运放
特性 增益带宽积:7MHz 高斜率:20V/us 宽供电范围:3.1V至36V或2.25V至18V 低失调电压:0.5mV(最大值) 低输入偏置电流:30pA(典型值) 轨到轨输出电压范围 单位增益稳定 工作温度范围:-40C至125C...
)
STM32CubeMX实战:FSMC高效驱动ILI9488 LCD屏(基于STM32F407)
1. 环境准备与硬件连接 在开始配置FSMC驱动ILI9488 LCD屏之前,我们需要准备好开发环境和硬件设备。我使用的是STM32F407VET6核心板搭配3.5寸320x480分辨率的ILI9488控制器TFT LCD屏幕。这种组合在工业控制和消费电子领域非常常见,性价比高且性能稳定。 硬…...
深入剖析QWidget鼠标追踪失效:从setMouseTracking到事件拦截的完整解决方案
1. 为什么鼠标移动事件会突然失效? 最近在做一个Qt项目时,遇到了一个让人抓狂的问题:明明已经调用了setMouseTracking(true),但鼠标在某些区域移动时,mouseMoveEvent就是死活不触发。这让我百思不得其解,毕…...

TarsCpp协程实现原理:从用户态上下文切换看高性能RPC框架设计
1. 从线程到协程:为什么TarsCpp要拥抱协程?在分布式微服务架构里,我们每天都在和RPC、网络IO、并发处理打交道。传统的多线程模型,一个请求一个线程,逻辑清晰,但线程创建、上下文切换的开销,以及…...

AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册
AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

CentOS LVM实战:动态调整home与root分区空间,解决系统盘爆满难题
1. 当服务器根分区告急时,你该怎么办? 最近接手了一台运行了3年的CentOS服务器,刚登录就发现系统弹出了"磁盘空间不足"的警告。df -h一看,好家伙,根分区(/)已经用了98%,而…...

5分钟快速上手GSE:魔兽世界智能技能循环终极指南
5分钟快速上手GSE:魔兽世界智能技能循环终极指南 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. 项目地址: https://gitcode.com/gh_mirrors/gs/GSE-Advanced-Macro-Compiler …...

Windows外接显示器亮度控制终极指南:使用Twinkle Tray轻松解决Windows系统限制
Windows外接显示器亮度控制终极指南:使用Twinkle Tray轻松解决Windows系统限制 【免费下载链接】twinkle-tray Easily manage the brightness of your monitors in Windows from the system tray 项目地址: https://gitcode.com/gh_mirrors/tw/twinkle-tray …...

回流平台深耕闲置翡翠流通,以数字化服务激活珠宝产业新动能
据中国珠宝玉石首饰行业协会数据,我国珠宝玉石首饰产业市场规模持续扩大,翡翠玉石作为第二大珠宝消费品类,市场存量可观。与此同时,发达国家二手高端消费品交易占整个高端消费品市场的20%至30%,我国目前占比约5%&#…...