numpy 中常用的数据保存、fmt多个参数
在经常性读取大量的数值文件时(比如深度学习训练数据),可以考虑现将数据存储为Numpy格式,然后直接使用Numpy去读取,速度相比为转化前快很多
一、保存为二进制文件(.npy/.npz)
(1)numpy.save(file, arr, allow_pickle=True, fix_imports=True)
file:文件名/文件路径
arr:要存储的数组
allow_pickle:布尔值,允许使用Python pickles保存对象数组(可选参数,默认即可)
fix_imports:为了方便Pyhton2中读取Python3保存的数据(可选参数,默认即可)
保存格式是.npy
示例:
- #生成数据
- >>> x=np.arange(10)
- >>> x =array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- #数据保存
- >>> np.save('save_x',x)
- #读取保存的数据
- >>> np.load('save_x.npy')
- array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
(2)numpy.savez(file, *args, **kwds)
file:文件名/文件路径
*args:要存储的数组,可以写多个,如果没有给数组指定Key,Numpy将默认从'arr_0','arr_1'的方式命名
kwds:(可选参数,默认即可)
这个同样是保存数组到一个二进制的文件中,但是厉害的是,它可以保存多个数组到同一个文件中,保存格式是.npz,它其实就是多个前面np.save的保存的npy,再通过打包(未压缩)的方式把这些文件归到一个文件上
#生成数据
>>> x=np.arange(10)
>>> x =array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> y=np.sin(x)
>>> y=array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 , -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849]) #数据保存
>>> np.save('save_xy',x,y)
#读取保存的数据
>>> npzfile=np.load('save_xy.npz')
>>> npzfile #是一个对象,无法读取
<numpy.lib.npyio.NpzFile object at 0x7f63ce4c8860> #按照组数默认的key进行访问
>>> npzfile['arr_0']
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> npzfile['arr_1']
array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 , -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849]) 可以不适用Numpy默认给数组的Key,而是自己给数组有意义的Key,这样就可以不用去猜测自己加载数据是否是自己需要的.#数据保存
>>> np.savez('newsave_xy',x=x,y=y) #读取保存的数据
>>> npzfile=np.load('newsave_xy.npz') #按照保存时设定组数key进行访问
>>> npzfile['x']
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> npzfile['y']
array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 , -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849]) 二、保存到文本文件
xuexi:Numpy中数据的常用的保存与读取方法 - 好奇不止,探索不息 - 博客园 (cnblogs.com)
保存数组到文本文件上,可以直接打开查看文件里面的内容.
(1)numpy.savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)
fname:文件名/文件路径,如果文件后缀是.gz,文件将被自动保存为.gzip格式,np.loadtxt可以识别该格式
X:要存储的1D或2D数组
fmt:控制数据存储的格式
delimiter:数据列之间的分隔符
newline:数据行之间的分隔符
header:文件头步写入的字符串
footer:文件底部写入的字符串
comments:文件头部或者尾部字符串的开头字符,默认是'#'
encoding:使用默认参数
fmt参数:控制数据格式
如:
x = [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
np.savetxt(r'test.txt', x)
参数都使用默认值,存数结果如下所示:
文件中的数据小数点后保留太多位,使得数据看起来很凌乱,可以使用格式控制参数‘fmt’进行控制,比如小数点后保留3位:
fmt='%.3e'
以浮点数存储,fmt=’%.3f’
也可以整数格式存储,fmt=’%d’

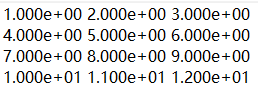
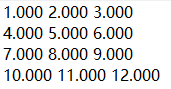
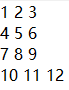
格式控制–数据对齐问题
可以看到上图中第4行的11和12与上一行的8和9发生错位,不够美观,通过设置数据长度进行调整。
np.savetxt(r'test.txt', x, fmt='%5d')
示例:
np.savetxt(r'test.txt', x, fmt='%5d', delimiter='|')
np.savetxt(r'test.txt', x, fmt='%05d', delimiter='|')



delimiter参数:每列数据之间的分割符号,默认为空格
newline参数:每行数据之间的分割符,默认换行
np.savetxt(r'test.txt', x, fmt='%d', newline='-|-')
fmt 其他写法:
学习:python - 在 numpy.savetxt 中设置 fmt 选项 - IT工具网 (coder.work)
- 当
fmt是单个格式化字符串时,它适用于 数组(一维或二维输入数组) - 当
fmt是一个格式化字符串序列时,它适用于二维输入数组的每一列 -
(1)添加字符以右对齐。
带空格:
np.savetxt('tmp.txt', a, fmt='% 4d')11 12 13 1421 22 23 2431 32 33 34带零:
np.savetxt('tmp.txt', a, fmt='%04d')0011 0012 0013 0014 0021 0022 0023 0024 0031 0032 0033 0034(3)向左对齐添加字符(使用“
-”)。带空格:
np.savetxt('tmp.txt', a, fmt='%-4d')11 12 13 14 21 22 23 24 31 32 33 34
当fmt为格式化字符串序列时,二维输入数组的每一行都按照fmt进行处理:
fmt 作为单个格式化字符串中的序列
fmt = '%1.1f + %1.1f / (%1.1f * %1.1f)'
np.savetxt('tmp.txt', a, fmt=fmt)11.0 + 12.0 / (13.0 * 14.0)
21.0 + 22.0 / (23.0 * 24.0)
31.0 + 32.0 / (33.0 * 34.0)
fmt 作为格式化字符串的迭代器:【fmt设置多个参数】
fmt = '%d', '%1.1f', '%1.9f', '%1.9f'
np.savetxt('tmp.txt', a, fmt=fmt)11 12.0 13.000000000 14.000000000
21 22.0 23.000000000 24.000000000
31 32.0 33.000000000 34.000000000(2)numpy.loadtxt(fname, dtype=<class 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes')
fname:文件名/文件路径,如果文件后缀是.gz或.bz2,文件将被解压,然后再载入
dtype:要读取的数据类型
comments:文件头部或者尾部字符串的开头字符,用于识别头部,尾部字符串
delimiter:划分读取上来值的字符串
converters:数据行之间的分隔符
参考学习:
Numpy中数据的常用的保存与读取方法 - 好奇不止,探索不息 - 博客园 (cnblogs.com)
遇到相关问题再补充哦!
相关文章:

numpy 中常用的数据保存、fmt多个参数
在经常性读取大量的数值文件时(比如深度学习训练数据),可以考虑现将数据存储为Numpy格式,然后直接使用Numpy去读取,速度相比为转化前快很多 一、保存为二进制文件(.npy/.npz) (1)numpy.save(file, arr, allow_pickleTrue, fix_importsTrue) file:文件名…...

从0到1一步一步玩转openEuler--19 openEuler 管理服务-特性说明
文章目录19 管理服务-特性说明19.1 更快的启动速度19.2 提供按需启动能力19.3 采用cgroup特性跟踪和管理进程的生命周期19.4 启动挂载点和自动挂载的管理19.5 实现事务性依赖关系管理19.6 与SysV初始化脚本兼容19.7 能够对系统进行快照和恢复19 管理服务-特性说明 19.1 更快的…...
完整思路Python代码)
23美赛E题:光污染(ICM)完整思路Python代码
问题E(综合评价与仿真题):光污染(ICM) 背景 光污染用于描述过度或不良使用人造光。我们称之为光污染的一些现象包括光侵入、过度照明和光杂波。在大城市,太阳落山后,这些现象最容易在天空中看到;然而,它们也可能发生在更偏远的地区。 光污染会改变我们对夜空的看法,…...

快速排序的描述以及两种实现方案
一、快速排序描述 每一轮排序选择一个基准点(pivot)进行分区 1.1. 让小于基准点的元素的进入一个分区,大于基准点的元素的进入另一个分区 1.2. 当分区完成时,基准点元素的位置就是其最终位置在子分区内重复以上过程,直…...

算力引领 数“聚”韶关——第二届中国韶关大数据创新创业大赛圆满收官
为进一步促进数字经济领域创新创业发展,推动国家数据中心集群建设,构建大数据领域资源专业平台,促进大湾区大数据科技成果和创新创业人才转化落地,为韶关大数据领域创新型产业集群的打造、大数据科技成果和创新创业人才的转化落地…...
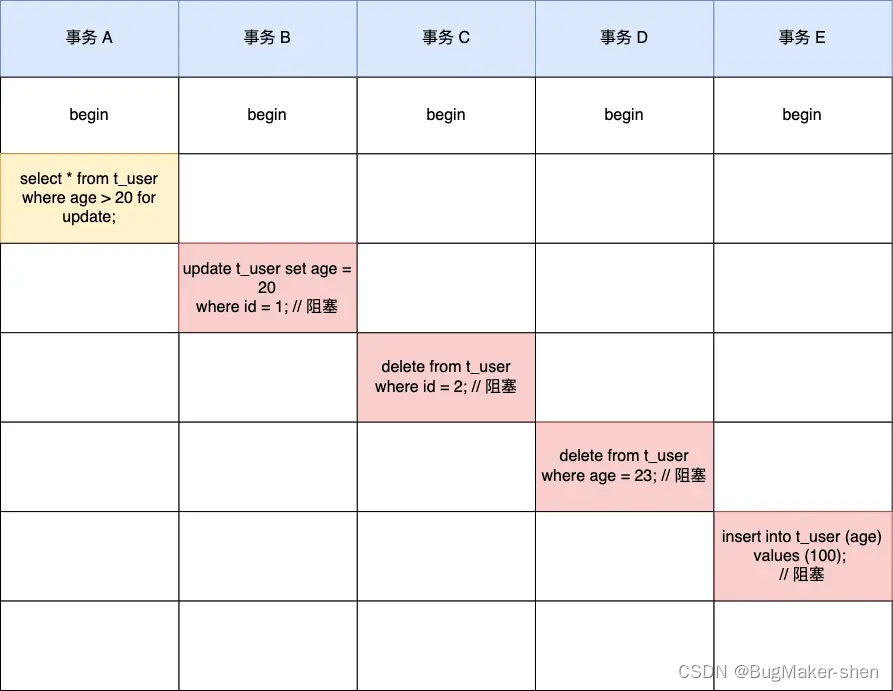
MySQL 记录锁+间隙锁可以防止删除操作而导致的幻读吗?
文章目录什么是幻读?实验验证加锁分析总结什么是幻读? 首先来看看 MySQL 文档是怎么定义幻读(Phantom Read)的: The so-called phantom problem occurs within a transaction when the same query produces different sets of r…...

【分库分表】企业级分库分表实战方案与详解(MySQL专栏启动)
📫作者简介:小明java问道之路,2022年度博客之星全国TOP3,专注于后端、中间件、计算机底层、架构设计演进与稳定性建设优化,文章内容兼具广度、深度、大厂技术方案,对待技术喜欢推理加验证,就职于…...
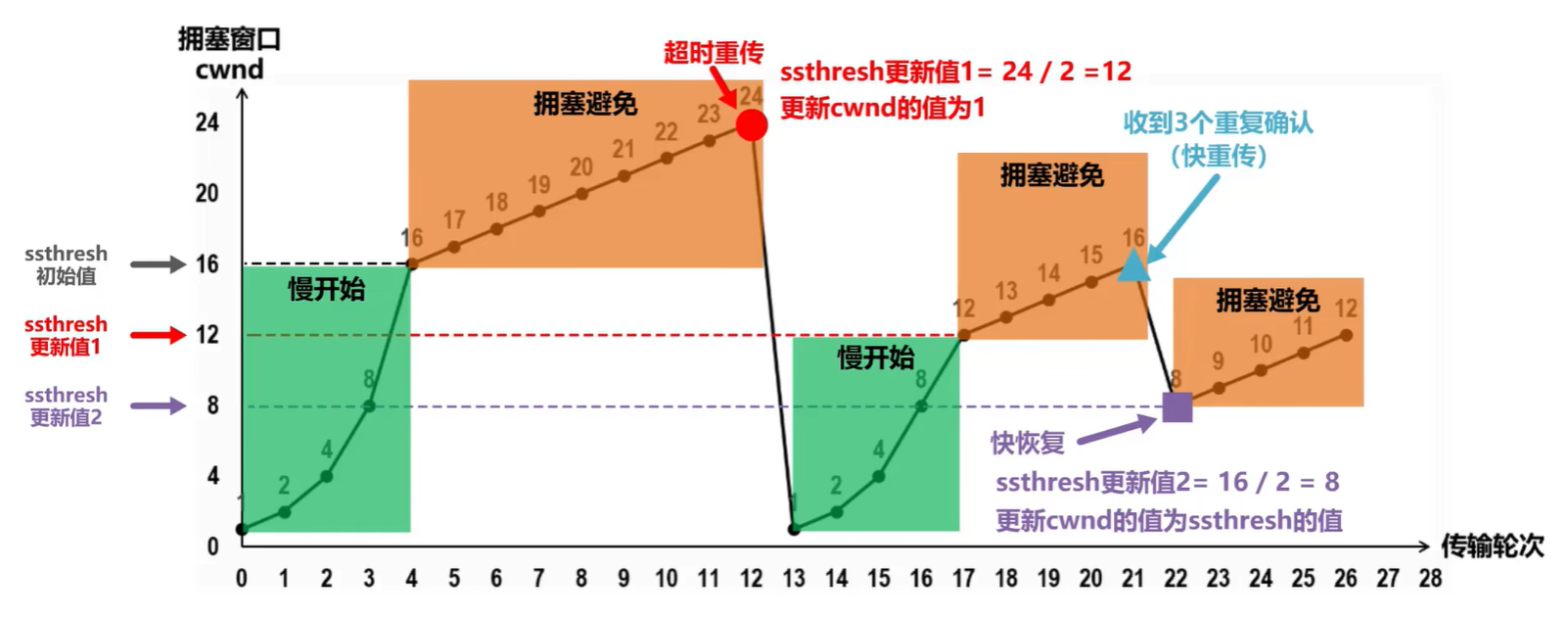
(考研湖科大教书匠计算机网络)第五章传输层-第五节:TCP拥塞控制
获取pdf:密码7281专栏目录首页:【专栏必读】考研湖科大教书匠计算机网络笔记导航 文章目录一:拥塞控制概述二:拥塞控制四大算法(1)慢开始和拥塞避免A:慢启动(slow start)…...

13.使用自动创建线程池的风险,要自己创建为好
自动创建线程池就是直接调用 Executors去new默认的那几个线程池,但是会出现一定的风险,线程池里面会用到队列,也会跟线程池自身有关,所以要从队列和线程池两个方面去解析。 1.了解线程池的队列 线程池的内部结构主要由四部分组成…...
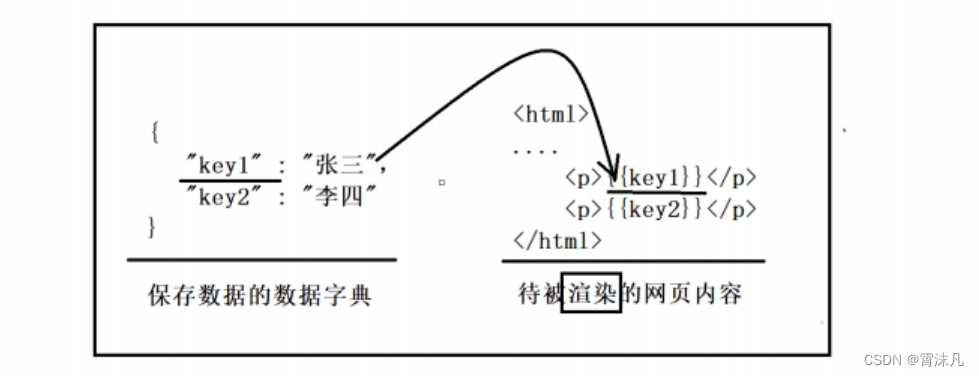
【项目设计】—— 负载均衡式在线OJ平台
目录 一、项目的相关背景 二、所用技术栈和开发环境 三、项目的宏观结构 四、compile_server模块设计 1. 编译服务(compiler模块) 2. 运行服务(runner模块) 3. 编译并运行服务(compile_run模块) 4…...
Docker学习笔记
1:docker安装步骤Linux 2:docker安装步骤Windows 3:docker官方文档 4:docker官方远程仓库 docker常用命令 1: docker images----查看docker中安装的镜像 2: docker pull nginx------在docker中安装Nginx镜…...

【爬虫理论实战】详解常见头部反爬技巧与验证方式 | 有 Python 代码实现
以下是常见头部反爬技巧与验证方式的大纲: User-Agent 字段的伪装方式,Referer 字段的伪装方式,Cookie 字段的伪装方式。 文章目录1. ⛳️ 头部反爬技巧1.1. User-Agent 字段&User-Agent 的作用1.2. 常见 User-Agent 的特征1.3. User-Age…...
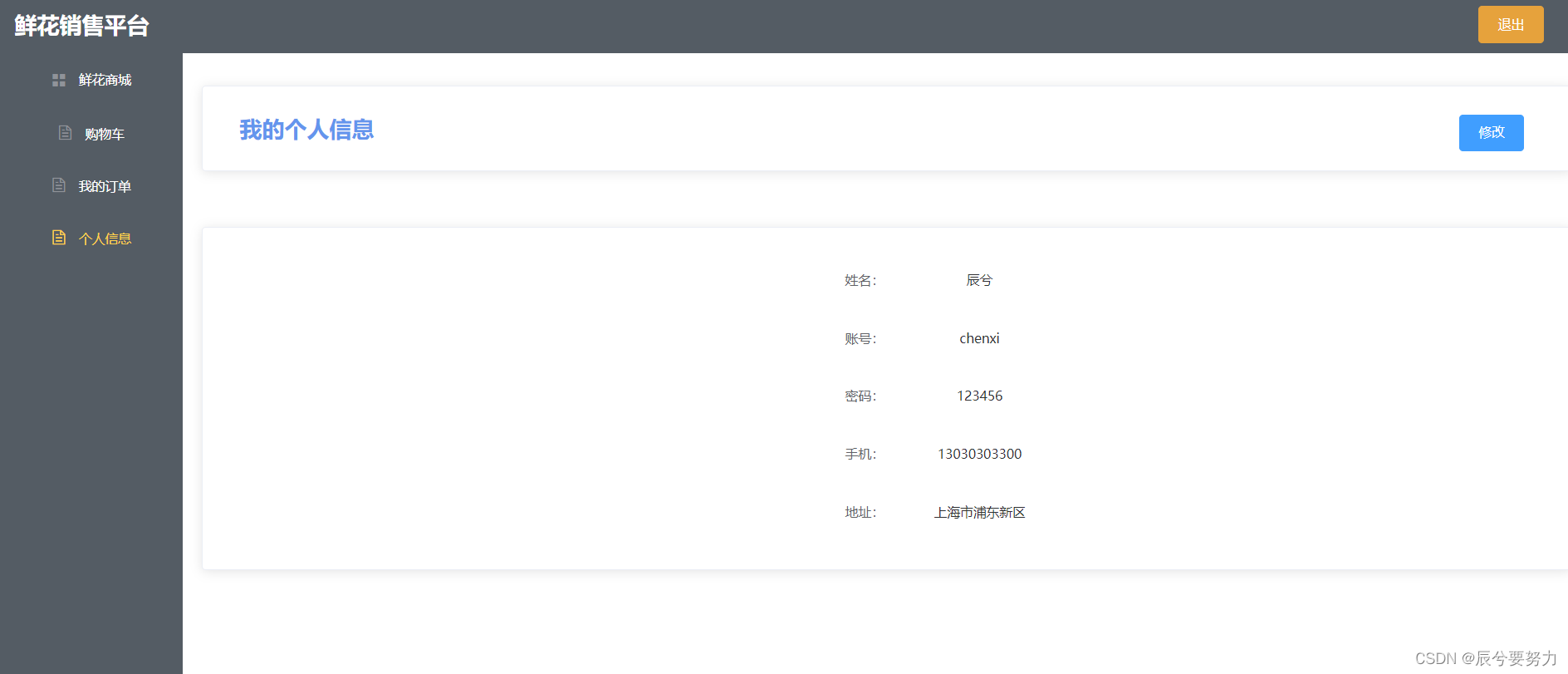
基于SpringBoot+Vue的鲜花商场管理系统
【辰兮要努力】:hello你好我是辰兮,很高兴你能来阅读,昵称是希望自己能不断精进,向着优秀程序员前行! 博客来源于项目以及编程中遇到的问题总结,偶尔会有读书分享,我会陆续更新Java前端、后台、…...
)
华为OD机试 - 静态扫描最优成本(JS)
静态扫描最优成本 题目 静态扫描快速识别源代码的缺陷,静态扫描的结果以扫描报告作为输出: 文件扫描的成本和文件大小相关,如果文件大小为 N ,则扫描成本为 N 个金币扫描报告的缓存成本和文件大小无关,每缓存一个报告需要 M 个金币扫描报告缓存后,后继再碰到该文件则不…...
多层感知机
多层感知机理论部分 本文系统的讲解多层感知机的pytorch复现,以及详细的代码解释。 部分文字和代码来自《动手学深度学习》!! 目录多层感知机理论部分隐藏层多层感知机数学逻辑激活函数1. ReLU函数2. sigmoid函数3. tanh函数多层感知机的从零…...

python在windows调用svn-pysvn
作为EBS开发人员,开发工具用的多,部署代码类型多,管理程序麻烦,操作繁琐,一直是我最讨厌的事情。部署一次程序要使用好几个工具,改来改去,上传下载,实在难受。 扣了一下python&#…...
office365 word 另存为 pdf 的注意事项和典型设置
0. 操作环境介绍 Office 版本:Office 365 版本 不同版本的操作可能有所不同 1. 基本操作 – 另存为 pdf 【文件】 --> 【另存为】,选择适当的文件路径、文件名保存类型选择【PDF】点击【保存】 1. 导出的pdf包含目录标签 word中,可使用…...
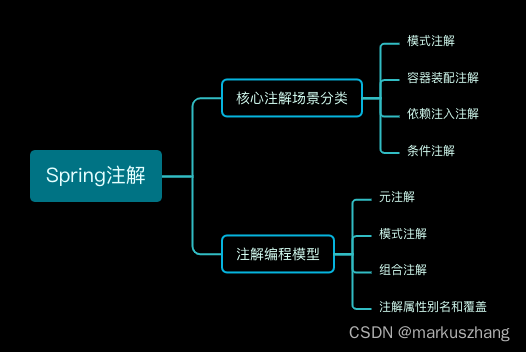
Spring IoC容器之常见常用注解以及注解编程模型简介
一、全文概览 本篇文章主要学习记录Spring中的核心注解,罗列常见常用的注解以及Spring中的注解编程模型介绍 二、核心注解 1、Spring模式注解 常用注解场景描述Spring起始支持版本Component通用组件模式注解,是所有组件类型注解的元注解Spring 2.5Repo…...
超详细讲解文件函数
超详细讲解文件函数!!!!字符输入/输出函数fgetcfputc文本行输入/输出函数fgetsfputs格式化输入/输出函数fscanffprintf二进制输入/输出函数freadfwrite打开/关闭文件函数fopenfclose字符输入/输出函数 fgetc fgetc函数可以从指定…...

【挣值分析】
名称解释 拼写解释PV计划费用,预估预算EV挣值,实际预估预算AC实际费用,实际花费CV成本偏差 (EV - AC)SV进度偏差(EV - PV)CPI成本绩效指数 (EV / AC)SPI进度绩效指数 &a…...

在Nodejs后端服务中集成Taotoken调用大模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken调用大模型API 对于Node.js后端开发者而言,将大模型能力集成到服务中已成为构建智能应…...

保姆级教程:用Intel官方工具搞定Realsense D435深度不准和黑点问题
深度视觉优化实战:Intel RealSense D435深度校准全流程解析 刚拆封的RealSense D435摄像头在深度模式下出现零星黑点?深度图某些区域数值明显失真?这些问题往往不是硬件缺陷,而是出厂校准参数与实际使用环境不匹配导致的。作为计算…...

Windows下Python包管理权限踩坑实录:从WinError 5到WinError 32的完整解决流程
Windows下Python包管理权限问题深度解析:从WinError 5到WinError 32的实战指南 作为一名长期在Windows平台进行Python开发的工程师,我深刻理解文件权限问题带来的困扰。特别是当你在紧急项目交付前夜,突然遭遇PermissionError: [WinError 5]或…...
)
CES效用函数保姆级解析:从公式推导到Python代码实现(附替代弹性计算)
CES效用函数实战指南:从数学本质到Python可视化 在经济学建模和金融工程领域,CES(Constant Elasticity of Substitution)效用函数就像一把瑞士军刀——它不仅能描述消费者偏好,还能通过调整参数δ来模拟完全替代、Cobb…...

终极指南:Visual C++运行库一键修复完整教程
终极指南:Visual C运行库一键修复完整教程 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突然弹出"无法启动此程序…...

Java开发者集成OpenAI API:社区SDK核心设计与生产实践
1. 项目概述:一个面向Java开发者的OpenAI API集成利器如果你是一名Java后端开发者,最近被ChatGPT、DALLE这些AI能力深深吸引,想在自家的Spring Boot应用里快速集成智能对话、文本生成或者图像创作功能,那你大概率已经搜过“OpenAI…...

小白程序员必看:收藏这份AI黑话指南,轻松入门大模型世界!
本文用大白话解释了AI领域几个核心概念:AI是总称,LLM是推理模型,Agent能独立执行任务,MCP是标准化接口,Skills是技能包。文章通过生活化比喻和实例,帮助读者理解这些概念如何协同工作,实现高效自…...

Unity3D游戏马赛克清除终极指南:7种高效技术深度解析
Unity3D游戏马赛克清除终极指南:7种高效技术深度解析 【免费下载链接】UniversalUnityDemosaics A collection of universal demosaic BepInEx plugins for games made in Unity3D engine 项目地址: https://gitcode.com/gh_mirrors/un/UniversalUnityDemosaics …...

TongWeb实战:GBase数据库连接池的配置与性能调优指南
1. 连接池基础与TongWeb集成 第一次在TongWeb里配置GBase数据库连接池时,我犯了个低级错误——直接把最大连接数设成了1000,结果系统刚上线就崩溃了。后来才明白,连接池不是越大越好,它本质上是个数据库连接的共享停车场。想象一…...

技术团队的“1对1沟通”:别等员工提离职了才聊真心话
在软件测试领域,我们习惯于用脚本验证系统的稳定性,用压测工具探测性能的边界,却常常忽略了对团队中最重要的“系统”——人——进行定期的健康检查。许多技术管理者,尤其是从资深测试工程师晋升上来的团队负责人,往往…...