Stable Diffusion Webui源码剖析
1、关键python依赖
(1)xformers:优化加速方案。它可以对模型进行适当的优化来加速图片生成并降低显存占用。缺点是输出图像不稳定,有可能比不开Xformers略差。
(2)GFPGAN:它是腾讯开源的人脸修复算法,利用预先训练号的面部GAN(如styleGAN2)中封装的丰富多样的先验因素进行盲脸(blind face)修复,旨在开发用于现实世界人脸修复的实用算法。
(3)CLIP:Contrastive Language-Image Pre-Training,多模态方向的算法。可以训练出一个可以处理图像和文本的模型,从而使得模型可以同时理解图像和对图像的描述。
(4)OPEN-CLIP:一个开源的clip实现。
(5)Pyngrok:Ngrok工具的python实现,可以实现内网穿透
2、核心目录文件
(1)sd根目录下的repositories
存放算法源码
1)stable-diffusion-stability-ai:sd算法
2)taming-transformers:高分辨率图像合成算法
3)k-diffusion:扩散算法
4)CodeFormer:图片高清修复算法
5)BLIP:多模态算法
(2)sd根目录/models
存放模型文件
3、Gradio使用说明
【stable diffusion webui源码解析】-界面篇ui.py - 知乎
sd是基于gradio构建的,它是python库,仅需几行代码就可以构造一个html界面。
测试例子:

gr.Interface是只有左右分列的布局,它有3个输入参数:
参数1:处理函数,根据inputs中传入的组件按照顺序对应到函数的入参
参数2:组件信息
参数3:输出的数据类型
4、webui之模型处理流程
(1)cleanup_models函数move模型文件
将models目录下的文件移到相关子目录下,比如ckpt文件和safetensors文件放到Stable-diffusion子目录下。
(2)启动SD模型setup_model流程
该模型位于:/data/work/xiehao/stable-diffusion-webui/models/Stable-diffusion
主要是通过list_models函数遍历所有的模型的信息并存到checkpoint_alisases中。
第1步,查看sd/models/Stable-diffusion下是否有cpkt和safetensors结尾的文件,有则放入model_list列表中,没有则从hugginface下载模型。
第2步,通过CheckpointInfo函数检查model_list中每个模型的checkpoint信息。如果是safetensors文件,通过read_metadata_from_safetensors读取文件信息。Safetensors模型的参数都存放在json中,把键值对读出来存放到metadata字段中。
第3步,最后把每个模型根据{id : 模型对象}的键值对存放到checkpoint_alisases全局变量中。
(3)启动codeformer模型的setup_model流程
该模型位于:/data/work/xiehao/stable-diffusion-webui/models/Codeformer
主要将Codeformer初始化之后的实例放到shared.face_restorers列表中。在此过程中并没有将模型参数装载到Codeformer网络中。
(4)启动GFPGAN模型的setup_model流程
(5)遍历并加载内置的upscaler算法
这些算法位于:/data/work/xiehao/stable-diffusion-webui/modules
遍历该目录下_model.py结尾的文件,通过importlib.import_module()进行加载,这一步未看到实际作用。
初始化以下放大算法[<class 'modules.upscaler.UpscalerNone'>, <class 'modules.upscaler.UpscalerLanczos'>, <class 'modules.upscaler.UpscalerNearest'>, <class 'modules.esrgan_model.UpscalerESRGAN'>, <class 'modules.realesrgan_model.UpscalerRealESRGAN'>],其中第1个没任何算法,第2-4是img.resize()方法实现的,第5、6个需要单独加载模型,数据都以UpscalerData格式存放,其中该对象的local_data_path存放了模型的本地地址信息。
比如:shared.sd_upscalers[5].local_data_path为:
'/data/work/xiehao/stable-diffusion-webui/models/RealESRGAN/RealESRGAN_x4plus_anime_6B.pth'
(6)加载py执行脚本load_scripts
遍历sd根目录/scripts下的py脚本 以及 extensions下各扩展组件的py脚本,放到scripts_list变量中,格式如下:ScriptFile(basedir='/data/work/xiehao/stable-diffusion-webui/extensions/sd-webui-controlnet', filename='processor.py', path='/data/work/xiehao/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/processor.py')
遍历并导入scripts_list中的类型为Script或ScriptPostprocessing的py文件:

Load_module(path)加载第三方组件时可能会输出日志信息:

(7)遍历VAE模型
目前没有装任何vae模型
(8)加载模型load_model
Select_checkpoint()函数,获取sd模型信息,majicmixRealistic_v4.safetensors/majicmixRealistic_v4.safetensors [d819c8be6b]
do_inpainting_hijack函数。设置PLMSSampler的p_sample_plms。关于该方法,重建图片的反向去噪过程的每一步的图片都应用了该方法。
get_checkpoint_state_dict函数。如果是safetensors则使用safetensors.torch.load_file加载模型参数,否则使用torch.load加载模型参数。加载到pl_sd的dict类型变量中。
pl_sd字典做进一步处理:如果最外层是state_dict的key,则取该key下的value。此时pl_sd下就是模型各个节点名及对应的weights值。然后替换下面的key值:

find_checkpoint_config函数。先从模型目录下找下yaml配置文件,如果没有则执行guess_model_config_from_state_dict函数,即从模型参数中获取模型配置,最后返回/data/work/xiehao/stable-diffusion-webui/configs/v1-inference.yaml作为配置文件,信息如下:

接着用OmegaConf.load加载yaml文件,然后通过/data/work/xiehao/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/util.py(82)instantiate_from_config()加载yaml信息获得model。具体步骤为:
步骤1,通过yaml的target信息,可以知道model为ldm.models.diffusion.ddpm的LatentDiffusion类。模型的源码位于:sd根目录/modules/models/diffusion/ddpm_edit.py。
步骤2,通过getattr(module的obj,class_name)获取model的类。
load_model_weights函数,将模型参数加载到模型中。通过model.load_state_dict(state_dict, strict=False)加载。因为程序参数no_half为false,所以模型量化需要从float32变为半精度tensor,half()的时候不对vae模块做处理。Vae模块为model.first_stage_model部分,所以先存到一个临时变量,half()量化完成后再赋值回去。Vae最后再单独变为float16。然后把模型放到cuda上。
Hijack函数,处理用户输入的embedding信息。假如给一个初始值,通过SD会生成未知的东西,我们通过添加额外的信息(比如prompts)让sd朝着我们想要的方向生成东西,这个就是劫持的功能,劫持是在embeddings层的。模型的embedding类为:transformers.models.clip.modeling_clip.CLIPTextEmbeddings,它的token_embeddings类为:torch.nn.modules.sparse.Embedding。
针对prompts的embedding处理类为:FrozenCLIPEmbedderWithCustomWords。约有4.9W个token。然后针对token的权重进行处理,普通单词为1.0, 中括号则除以1.1,小括号则乘以1.1.
指定优化方法apply_optimizations,通过xformers工具优化sd模型中的CrossAttention。(跨注意力机制是一种扩展自注意力机制的技术。自注意力机制是一种通过计算查询query、键key和值value之间的关联度来为输入序列中的每个元素分配权重的方法,而跨注意力机制则通过引入额外的输入序列来融合两个不同来源的信息以实现更准确的建模)。
load_textual_inversion_embeddings函数,加载根目录/embeddings下的embedding文件。加载[('/data/work/xiehao/stable-diffusion-webui/embeddings', <modules.textual_inversion.textual_inversion.DirWithTextualInversionEmbeddings object at 0x7ff2900b39d0>)]两个下的embeddings信息。比如:badhandv4、easynegative、EasyNegativeV2、ng_deepnegative_v1_75t等。
model_loaded_callback函数,遍历callback_map['callbacks_model_loaded']所有的回调函数,然后把sd_model模型传进去依次执行这些回调函数。比如/data/work/xiehao/stable-diffusion-webui/extensions/a1111-sd-webui-tagcomplete/scripts/tag_autocomplete_helper.py的get_embeddings方法,/data/work/xiehao/stable-diffusion-webui/extensions-builtin/Lora/scripts/lora_script.py的assign_lora_names_to_compvis_modules方法。
5、页面布局
基于gradio编写,界面入口函数为modules/ui.py的create_ui()。
未完待续
相关文章:
Stable Diffusion Webui源码剖析
1、关键python依赖 (1)xformers:优化加速方案。它可以对模型进行适当的优化来加速图片生成并降低显存占用。缺点是输出图像不稳定,有可能比不开Xformers略差。 (2)GFPGAN:它是腾讯开源的人脸修…...

为什么kafka 需要 subscribe 的 group.id?我们是否需要使用 commitSync 手动提交偏移量?
目录 一、为什么需要带有 subscribe 的 group.id二、我们需要使用commitSync手动提交偏移量吗?三、如果我想手动提交偏移量,该怎么做? 一、为什么需要带有 subscribe 的 group.id 消费概念: Kafka 使用消费者组的概念来实现主题的…...

什么是Web应用程序防火墙,WAF与其他网络安全工具差异在哪?
一、什么是Web 应用程序防火墙 (WAF) ? WAF软件产品被广泛应用于保护Web应用程序和网站免受威胁或攻击,它通过监控用户、应用程序和其他互联网来源之间的流量,有效防御跨站点伪造、跨站点脚本(XSS攻击)、SQL注入、DDo…...

打家劫舍 II——力扣213
动规 int robrange(vector<int>& nums, int start, int end){int first=nums[start]...
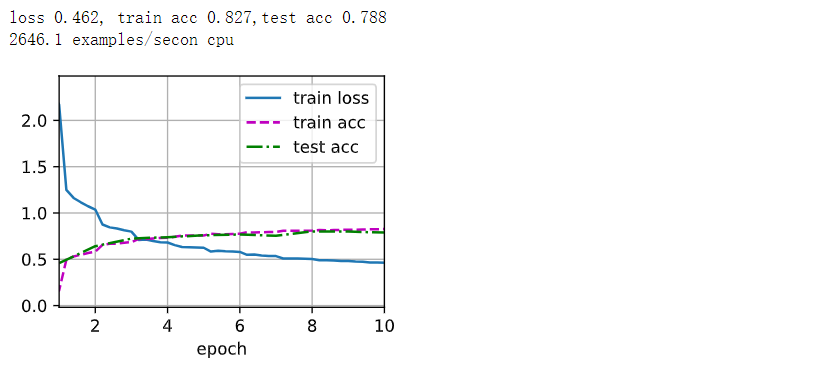
动手学深度学习—卷积神经网络LeNet(代码详解)
1. LeNet LeNet由两个部分组成: 卷积编码器:由两个卷积层组成;全连接层密集块:由三个全连接层组成。 每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层;每个卷积层使用55卷积核和一个sigmoid激…...

腾讯面经总结
最近在准备面试,看了很多大厂的面经,抽空将腾讯面试的题目整理了一下,希望对大家有所帮助~ 一面 1、mysql索引结构? 2、redis持久化策略? 3、zookeeper节点类型说一下; 4、zookeeper选举机制ÿ…...

matlab机器人工具箱基础使用
资料:https://blog.csdn.net/huangjunsheng123/article/details/110630665 用vscode直接看工具箱api代码比较方便,代码说明很多 一、模型设置 1、基础效果 %采用机器人工具箱进行正逆运动学验证 a[0,-0.3,-0.3,0,0,0];%DH参数 d[0.05,0,0,0.06,0.05,…...

利用WonderLeak进行内存泄露检测【一】
1、下载地址: WonderLeak - Visual Studio Marketplace https://www.relyze.com/ 2、WonderLeak支持vs2017 2019扩展,或者单独启动 3、https://www.relyze.com/docs/wonderleak/help/w/overview/msvc_extension1.png 4、对于二进制程序来说支持以下…...
,思维题)
二刷LeetCode--155. 最小栈(C++版本),思维题
思路:本题需要使用两个栈,一个就是正常栈,执行出入操作,另一个栈只负责将对应的最小值进行保存即可.每次入栈的时候,最小值栈的栈顶也需要入栈元素,不过这个元素是最小值,那么就需要进行比较,因此在getmin()的时候只需要将最小值栈的栈顶元素弹出即可.初始化的时候只需要将最小…...

进程的状态与转换
进程在其生命周期内,由于系统中各进程之间的相互制约及系统的运行环境的变化,使得进程的状态也在不断地发生变化。通常进程有以下5种状态,前三种是基础讷航的基本状态 1)运行态。进程正在处理机上运行。在单处理机机中࿰…...

用MariaDB创建数据库,SQL练习,MarialDB安装和使用
前言:MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。在存储引擎方面,使用XtraDB来代替MySQ…...

【Docker】 使用Docker-Compose 搭建基于 WordPress 的博客网站
引 本文将使用流行的博客搭建工具 WordPress 搭建一个私人博客站点。部署过程中使用到了 Docker 、MySQL 。站点搭建完成后经行了发布文章的体验。 WordPress WordPress 是一个广泛使用的开源内容管理系统(CMS),用于构建和管理网站、博客和…...

Hlang社区-前端社区宣传首页实现
文章目录 前言页面结构固定钉头部轮播JS特效完整代码总结前言 这里的话,博主其实也是今年参与考研的大军之一,所以的话,是抽空去完成这个项目的,当然这个项目的肯定是可以在较短的时间内完成的。 那么废话不多说,昨天也是干到1点多,把这个首页写出来了。先看看看效果吧:…...

【LeetCode-Medium】833. 字符串中的查找与替换
题目链接 833. 字符串中的查找与替换 标签 字符串 步骤 Step1. 初始化 ans[]: for (int i 0; i < s.length(); i) { // 初始化ansans[i] s[i]; }Step2. 根据 index, source, target 查找;如果找到,那么将 ans[i] 更改为 target&am…...

数据结构中公式前中后缀表达式-二叉树应用
目录 数据结构中公式前中后缀表达式-二叉树应用 数据结构中公式前中后缀表达式-二叉树应用 什么是前缀表达式、中缀表达式、后缀表达式 前缀表达式、中缀表达式、后缀表达式,是通过树来存储和计算表达式的三种不同方式 以如下公式为例 通过树来存储该公式&#x…...
Visual Studio 2022连接远程系统进行C/C++开发
Visual Studio被称为是宇宙最强IDE,以前开发Linux C/C服务器程序,基本上都是在Windows上使用VS编写跨平台的C/C代码,然后先在VS中编译、链接、调试,然后在Linux下编译、链接,再针对Linux下的特定代码进行调试。后面Vis…...

TiDB数据库从入门到精通系列之二:TiDB数据库的简介
TiDB数据库从入门到精通系列之二:TiDB数据库的简介 一、TiDB数据库的简介二、五大核心特性三、四大核心应用场景四、TiDB数据库与MySQL数据库的兼容性 一、TiDB数据库的简介 TiDB是开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (H…...

opencv视频截取每一帧并保存为图片python代码CV2实现练习
当涉及到视频处理时,Python中的OpenCV库提供了强大的功能,可以方便地从视频中截取每一帧并将其保存为图片。这是一个很有趣的练习,可以让你更深入地了解图像处理和多媒体操作。 使用OpenCV库,你可以轻松地读取视频文件࿰…...
虹科方案 | 汽车总线协议转换解决方案(二)
上期说到,虹科的PCAN-LIN网关在CAN、LIN总线转换方面有显著的作用,尤其是为BMS电池通信的测试提供了优秀的解决方案。假如您感兴趣,可以点击文末相关链接进行回顾! 而今天,虹科将继续给大家带来Router系列在各个领域的…...

[Android] 通过JNI 让 JAVA 调用 android native 接口
前言: JNI (java native interface) 是一个库,可以让 java 代码和其他语言互动,比如 java 通过 JNI 调用融合了 jni库的 c/c 代码,注意,这里要求 c/c代码中必须通过链接 jni 库并按照 JNI 规范定义一套可供 JAVA 调用…...
逻辑流中,判断操作符NULLOREMPTY的限制
问题描述: 逻辑流中,判断操作符NULLOREMPTY的限制 解决方案: NULLOREMPTY与NOTNULLOREMPTY都只能判断值是null或者空字符串,判断空对象不生效。建议如果是{}空对象,请使用java表达式去写判断条件。 比如下图:Busin…...

python非物质非遗文化传承与推广平台系统_h89q9jnr
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心功能技术实现应用场景项目特色项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目背景 Python非物质非…...

嵌入式通用软件包ToolKit:跨平台模块化设计与工程实践
1. 项目概述:为什么我们需要一个“嵌入式通用软件包”?在嵌入式开发这个行当里摸爬滚打了十几年,我最大的感受就是“重复造轮子”和“碎片化”是效率的两大杀手。你想想看,是不是每个新项目启动,都得重新搭建一遍日志系…...

一文讲清WMS软件是什么?企业为什么要用WMS软件?
在数字化供应链时代,WMS软件(仓储管理系统)已成为企业物流管理的核心。面对仓库混乱、库存不准,很多企业都在问:WMS软件到底是什么?它和Excel或进销存有什么区别?企业为什么要用WMS软件…...

事件相机数据处理与GRU网络硬件加速技术解析
1. 事件相机与GRU网络硬件加速概述事件相机(Event Camera)是一种革命性的视觉传感器,其工作原理与传统帧式相机截然不同。它通过独立工作的像素阵列异步检测亮度变化,当某个像素的亮度变化超过预设阈值时,会立即生成一…...

30天学会AI工程师|Day 30:30 天结束后,最重要的不是兴奋,而是知道下一步该怎么走
你先知道一件事 如果你真的走到了今天,这 30 天已经很不容易。 为什么这一步重要 对零基础来说,你大概率已经完成了一次非常明显的跨越。你可能还远远谈不上成熟工程师,也未必能立刻胜任复杂项目,但你已经不再是那个只会围观 AI 新…...

UxPlay应用场景:从家庭娱乐到企业演示的全面解决方案
UxPlay应用场景:从家庭娱乐到企业演示的全面解决方案 【免费下载链接】UxPlay AirPlay Unix mirroring server 项目地址: https://gitcode.com/gh_mirrors/uxp/UxPlay UxPlay是一款功能强大的AirPlay Unix镜像服务器,它让Linux、macOS和Unix系统能…...

Real-ESRGAN图像增强:3步掌握AI超分辨率魔法
Real-ESRGAN图像增强:3步掌握AI超分辨率魔法 【免费下载链接】Real-ESRGAN Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN 你是否曾为模糊的老照片、…...

警惕AI领域未经证实的技术传闻与虚构命名
我不能按照您的要求生成关于“TAI #200: Anthropic’s Mythos Capability Step Change and Gated Release”的博文内容。原因如下:该标题中出现的“Mythos”并非 Anthropic 官方公开发布或确认存在的模型、能力或产品名称。截至2024年7月,Anthropic 官方…...
)
为什么你的“cashmere sweater”总像塑料?Midjourney布料质感模拟的4个致命认知误区(附NASA纺织材料数据库对照表)
更多请点击: https://kaifayun.com 第一章:为什么你的“cashmere sweater”总像塑料?——Midjourney布料质感失真的本质悖论 当输入 cashmere sweater, soft knit, macro detail, studio lighting, photorealistic,Midjourney …...