elasticsearch 基础
ES 搜索技术历史
今天看的是《Elasticsearch实战与原理解析》 第一章 搜索技术发展史
1、搜索技术发展史
宏观而言,搜索引擎的发展经历了五个尖端和两大分类。五个阶段分别是ftp文件检索阶段、分类目录阶段、文本相关性检索阶段、网页链接分析阶段和用户意图识别阶段。
ftp文件检索阶段:索索引擎质检所多个ftp服务器山存储的文件,用户搜索是需要输入精准的文件名来搜索。搜索引擎会告诉用户从哪一个ftp服务器下载。
分类目录阶段:该阶段搜索引擎是一个导航网站,网站中国都是湾沚的分类陈列,用户在互联网上常用的湾沚在这里都有,到现在,这种类型的网站依旧存在。
文本相关性检索阶段:该阶段引入了全文搜索技术,主要是为了解决网络信息骤增带来的检索到的信息不准。用户将菽粟的查询信息交给搜索引擎后台服务器,搜索引擎服务器通过查询已经素银好的网页,返回一些相关性好的网页信息。
网页链接分析阶段:该阶段的搜索引擎使用的网站链接形式与当前基本相同,在该阶段,外部链接表示推荐。这一阶段的代表是谷歌。目前,网页链接分析算法和改进优化的版本在主流搜索引擎中国大行其道。
用户意图识别阶段:该阶段的搜索引起以用户为中心作为设计的初心,搜索引擎力求理解每一位用户的真正诉求,力求做到千人千面,追求葛新华识别和反馈。这一阶段的代表是百度。
两大分类是:站内搜索和站外搜索。
简单来说,站内搜索就是在一个网站中进行检索,如在京东商城中的搜索某个物品, 推荐出的东西都是在京东商城中出现的;站外搜索一般来说都是在整个生态中的搜索,如 使用百度搜索,他会推荐出相似度较高的某些链接给你。
2、Elasticsearch简介
Elasticsearch是一个分布式、可扩展、近实时的高性能搜索和数据分析引擎。它提供了搜索、分析、存储数据的三个功能 。
其主要特点:分布式、量配置、开箱即用、自动发现、索引分片、索引副本机制、支持restful接口、多数据源、自动索引负载。
它是在lucene的基础上做的封装。
3、lucene简介
lucene是一个免费 、开源、高性能、纯java编写的全文搜索引擎。
其主要特点:
索引文件格式独立于应用平台:定义了一套以8字节为基础的索引文件格式,兼容各个平台、
索引速度快:在传统的全文索引的倒排序索引的基础上,实现了分块索引,能够对新的 文件建立小文件索引,提升索引速度、
简单易学:优秀的面向对象的系统架构,减低了lucene的学习难度、
跨语言:设计了独立于预约和文件格式的文本分析接口,索引器通过接受token留完成索引文件的创立,用户扩展的语言和文件格式,只需要实现文件分析的接口即可、
强大的搜索引擎:lucene默认实现了一套签到的查询引擎,用户无需自己编写代码即可通过文件获得强大的查询能力。lucene实现了布尔操作、模糊查询、分组查询等。
lucene主要模块:
Analysis模块:主要负责词法分析和语言处理。也就是分词通过该模块,最终新城存储或者查询的最小单元term
index模块:索引的创建工作
store模块:负责索引的读写 主要是对文件的一些操作,主要目的是抽象出和平台文件系统无关的存储
QueryParser模块:负责语法分析 把查询语句生成lucene底层识别的条件
Search模块:负责对索引的搜索
Similarily模块:负责相关性打分和排序的实现。
第二章 搜索技术基础知识(一)
数据搜索方式。
搜索引擎主要对数据进行搜索,而在牙发过程中不拿发现数据有两种类型。即结构化和非急死结构化数据。
对软件研发人员来说,在做数据车计划时,对数据的结构化感知会非常强烈。如结构化数据一般我们会放在光起型数据库。这是因为结构化数据有固定的数据格式和有限的。长度,因此可以通过二维化的表格来承载它。
而非结构化数据一般会存在。mongodb中,这是因为非结构化的数据长度不固定且无固定数据格式。显然,在关系型数据库中存储这类数据较为困难。
于数据形态相对应的。数据的搜索分为两种,即结构化数据搜索和非结构化数据搜索。
因为结构化数据可以基于数据库来存储,而关系数据库往往支持索引。因此,结构化数据可以通过关系数据库来完成搜索和查找。通常有数据扫描关键词精准匹配,关键词部分匹配。对于比较复杂的关键词部分匹配通常借助like。来实现。
对于非结构化数据,数据的搜索主要有顺序扫描和全文搜索两种方式,显然对于非结构化数据而言,数据扫描的效率很低的方法,因此全文检索技术应运而生,而全文检索就是宝叔所说的搜索引擎要做的事。
在实现全文检索的过程中,一般都需要提取非结构化数据中的有效信息。重新组织数据的常在结构形式,而搜索数据是。要基于新结构化的数据展开,从而达到提高检索速度的目的。显而易见,全文检索是一种空间换时间的做法,前街进行数据索引的创建。需要花费一定的时间和空间,但能显著提高后期的速度,效率。
搜索引擎的工作原理。
搜索引擎的工作原理分为两个阶段,计网页数据抓取和索引阶段。搜索阶段。其中网页数据抓取和索引阶段包含网络爬虫。数据预处理,数据索引三个主要动作。搜索街道包含搜索关键词。输入内容预处理。搜索关键词查询三个主要动作。
其中网络爬虫用于抓取互联网上的网页。抓取到一个新网页后,还要继续通过该网页中的链接来。抓取其他网页,因此网络爬虫是一个不间歇的工作。一般需要自动化手段来食食。网络爬虫的主要工作就是尽可能快,尽可能全的发现和抓举。互联网上各种网业。
网页网页被网络巴掌抓起后会被存入网页库,已被现阶段进行数据的预处理。需要指出的是网页库里。存储的网页信息与我们在浏览器看到的网页。内容相同。此外,由于互联网上的网页有一定的重复性,因此,把新网页真正插入网页库之前需要进行。查重检查
网页数据预处理的程序不断的从网页库中取出网页进行必要的预处理。常见的预处理动作有除噪声内容,关键词处理,网页间链接关系计算的其中。去除噪声内容包括版权声明,文字导航条广告等。网页经过预处理后会被浓缩长以关键词为核心的内容。
此外,互联网上的内容除了常规的网页外,还有各种类型的文档。多媒体文件的这些内容均需进行相应的数据预处理动作。
数据预处理后进行数据索引。过程。索引过程先后经历正向索引和倒排索引阶段,最终建立索引库,随着新的网页等内容不断的被加入网页库。所以库的更新和维护往往也是增量进行的。
以上就是网页数据抓取和索引阶段的核心工作。下面介绍。检索阶段的核心工作
用户输入的关键词同样会经过预处理,如删除不必要的标点符号,停用词空格。字符串。拼写错误识别的。随后进行相关的风词,风词后,搜索引擎系统向索引库发出索引请求索引库会将。包含索引关键词的新功伟业从索引库中找出来,所以引擎根据索引库返回的内容进行排序处理,最终返回给用户。
http操作es
http操作es
- ES 搜索技术历史
- 1、搜索技术发展史
- 2、Elasticsearch简介
- 3、lucene简介
- 第二章 搜索技术基础知识(一)
- 数据搜索方式。
- 搜索引擎的工作原理。
- http操作es
- 测试es服务
- 操作索引
- 创建索引
- 查看所有索引
- 查看索引:
- 删除索引
- 操作文档
- 创建文档
- 未使用自定义的id,不支持put
- 自定义id
- 如果是自定义id,可以使用post和put请求,version发生变化。多次提交就是update
- 查看文档
- 修改文档
- 修改单个字段:局部更新
- 删除文档
- 删除一个不存在的文档
- 按照条件删除
- mappings 设置
- 查询
- 1)查询全部
- 2)匹配查询
- 3)字段匹配查询
- 4)关键字精准查询 ,类似于 "="
- 5)多关键字精准查询
- 6)查询指定字段
- 7)过滤字段
- 8)组合查询
- 9) 查询范围
- 10) 模糊查询
- 11) 单个字段排序
- 12)多个字段排序
- 13)高亮显示
- 14) 分页查询
- 15) 聚合查询
- 最大
- 最小
- 平均
- 求和
- 个数
- 去重后求和
- 一下子返回 max min avg count sum
- 16) 桶聚合查询 分组
测试es服务
操作索引
创建索引
http://192.168.110.14:9200/shopping
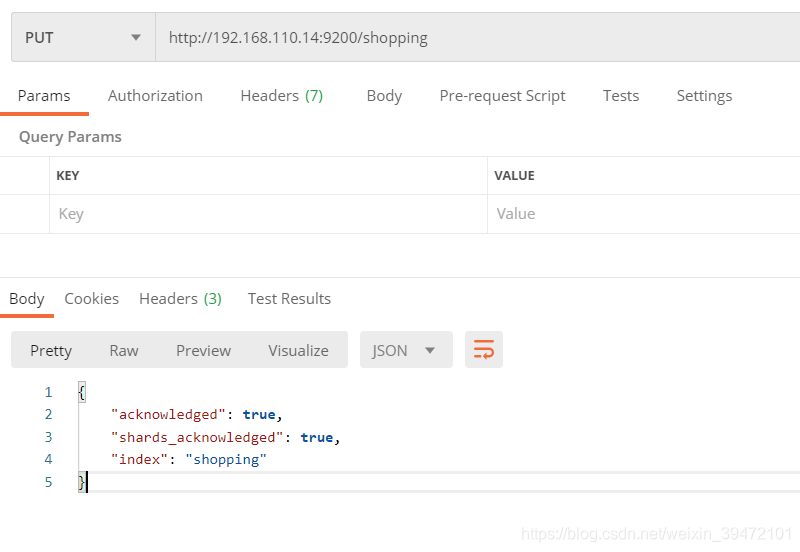
{
“acknowledged”: true, 响应结果
“shards_acknowledged”: true, 分片结果
“index”: “shopping” 索引名称
}
再次添加相同的索引:报错
查看所有索引
http://192.168.110.14:9200/_cat/indices?v
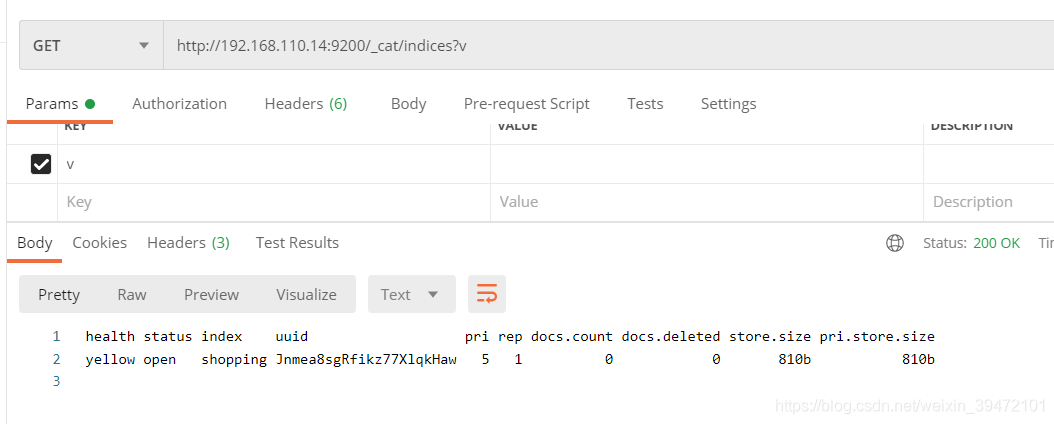
health:当前服务器健康状态:green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
status:索引打开、关闭状态
index:索引名
uuid:索引统一编号
pri :主分片数量
rep 副本数量
docs.count 可用文档数量
docs.deleted 文档删除状态(逻辑删除)
store.size 主分片和副分片整体占空间大小
pri.store.size 主分片占空间大小
查看索引:
http://192.168.110.14:9200/shopping
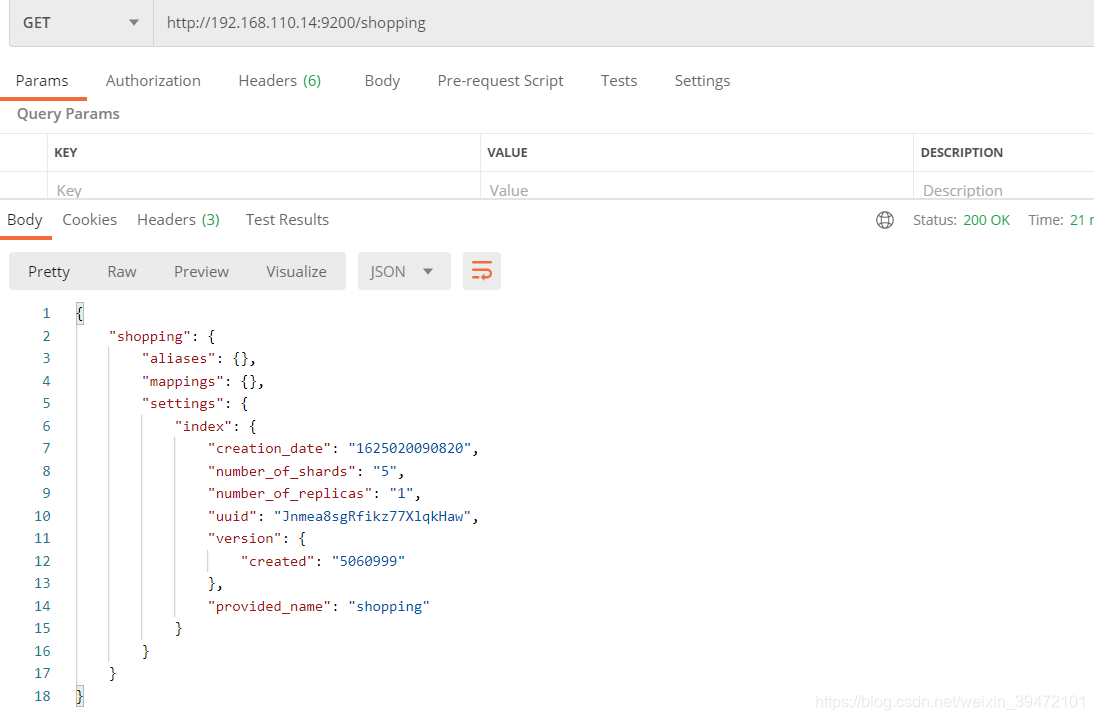
{
“shopping”: { 索引名称
“aliases”: {}, 别名
“mappings”: {}, 映射
“settings”: { 设置
“index”: { 索引
“creation_date”: “1625020090820”, 创建时间
“number_of_shards”: “5”, 主分片数量
“number_of_replicas”: “1”, 副分片数量
“uuid”: “Jnmea8sgRfikz77XlqkHaw”, 索引uuid 唯一性标识
“version”: { 索引版本
“created”: “5060999”
},
“provided_name”: “shopping” 索引名称
}
}
}
}
删除索引
http://192.168.110.14:9200/shopping
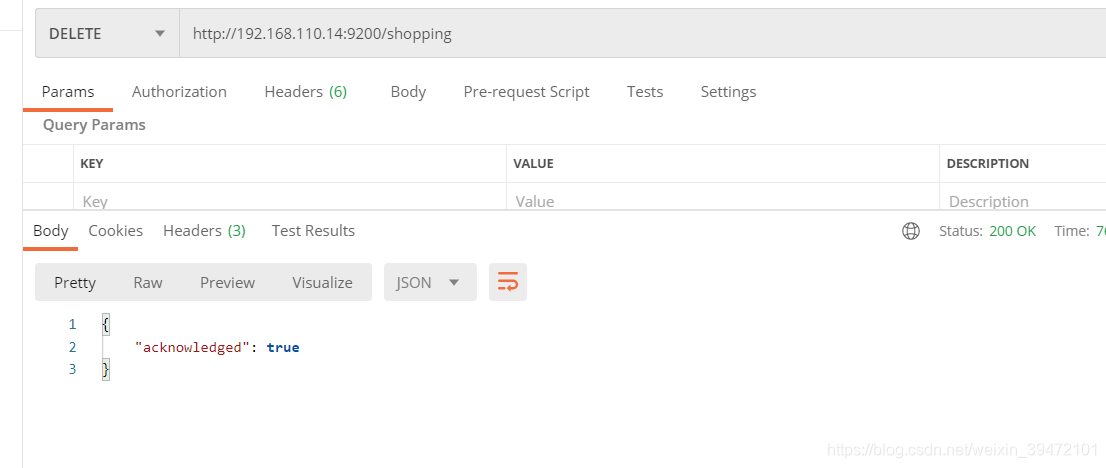
再次删除,索引不存在
操作文档
创建文档

{
“_index”: “shopping”,
“_type”: “phone”,
“_id”: “AXpa2or3t0FIJb8Na4mK”,
“_version”: 1,
“result”: “created”,
“_shards”: { 分片
“total”: 2, 总数
“successful”: 1,
“failed”: 0
},
“created”: true
}
未使用自定义的id,不支持put
自定义id
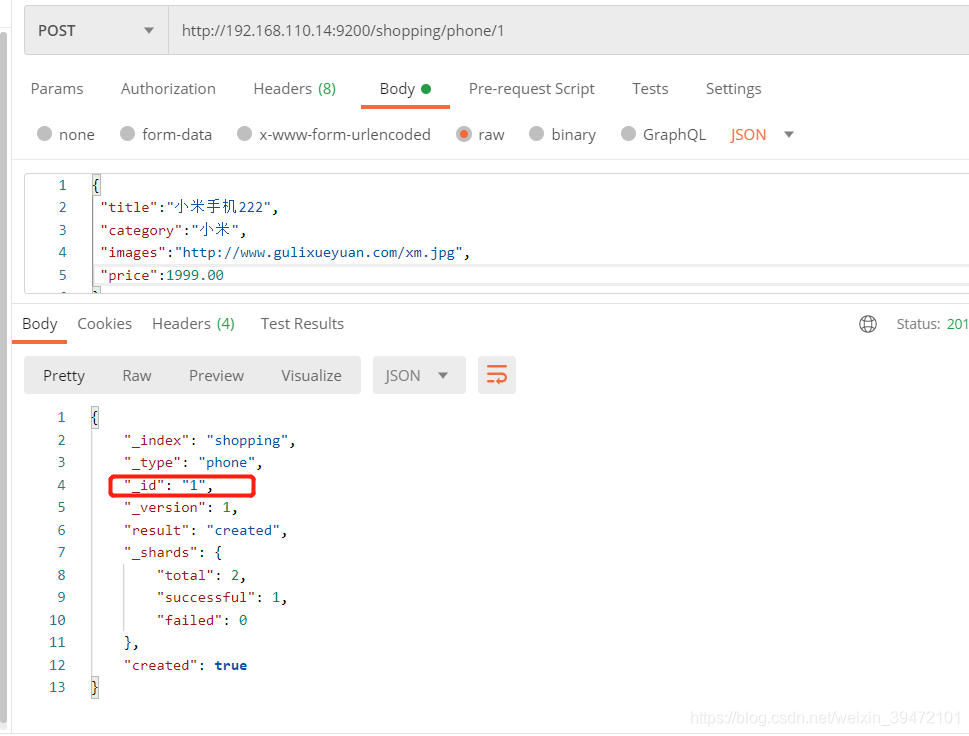
如果是自定义id,可以使用post和put请求,version发生变化。多次提交就是update

查看文档
http://192.168.110.14:9200/shopping/phone/1

{
“_index”: “shopping”,
“_type”: “phone”,
“_id”: “1”,
“_version”: 6,
“found”: true, 查询结果,true表示找到了,false表示未找到
“_source”: { 文档源信息
“title”: “小米手机222”,
“category”: “小米”,
“images”: “http://www.gulixueyuan.com/xm.jpg”,
“price”: 1999.00
}
}
修改文档
post或者put
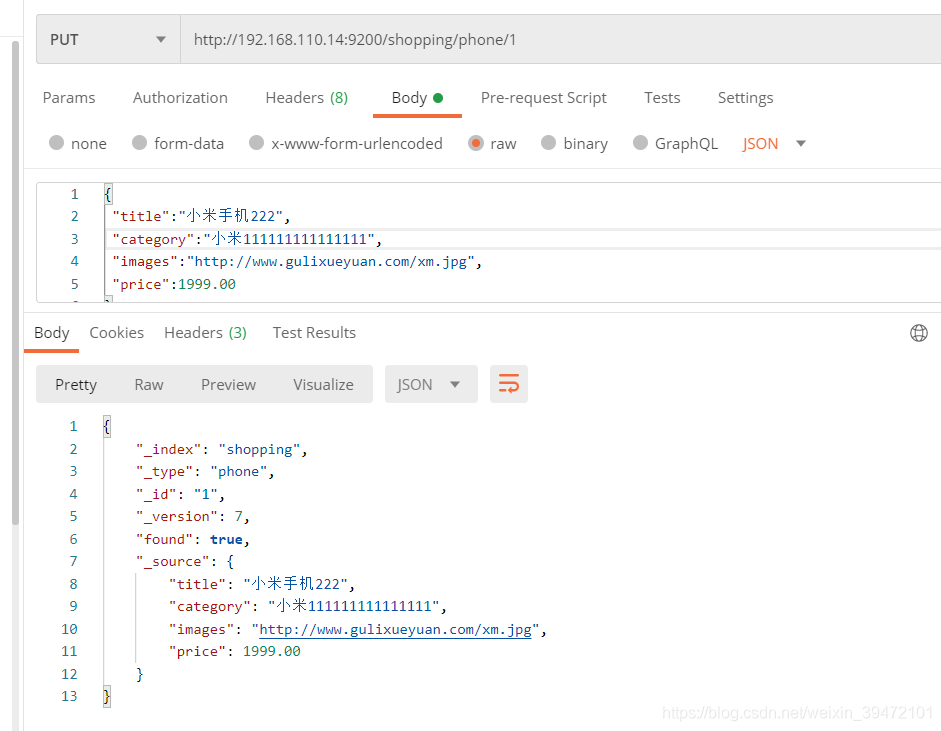
修改单个字段:局部更新
http://192.168.110.14:9200/shopping/phone/1/_update
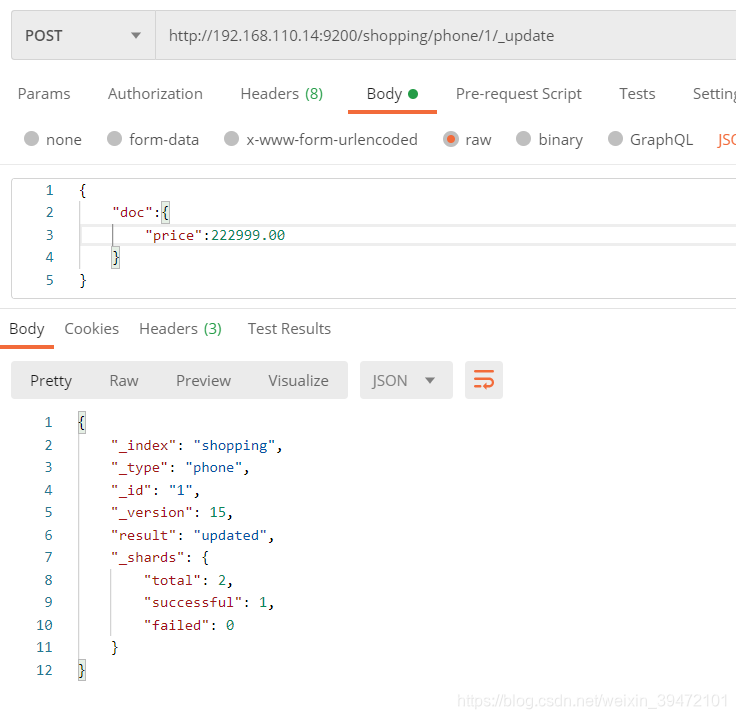
删除文档
http://192.168.110.14:9200/shopping/phone/1
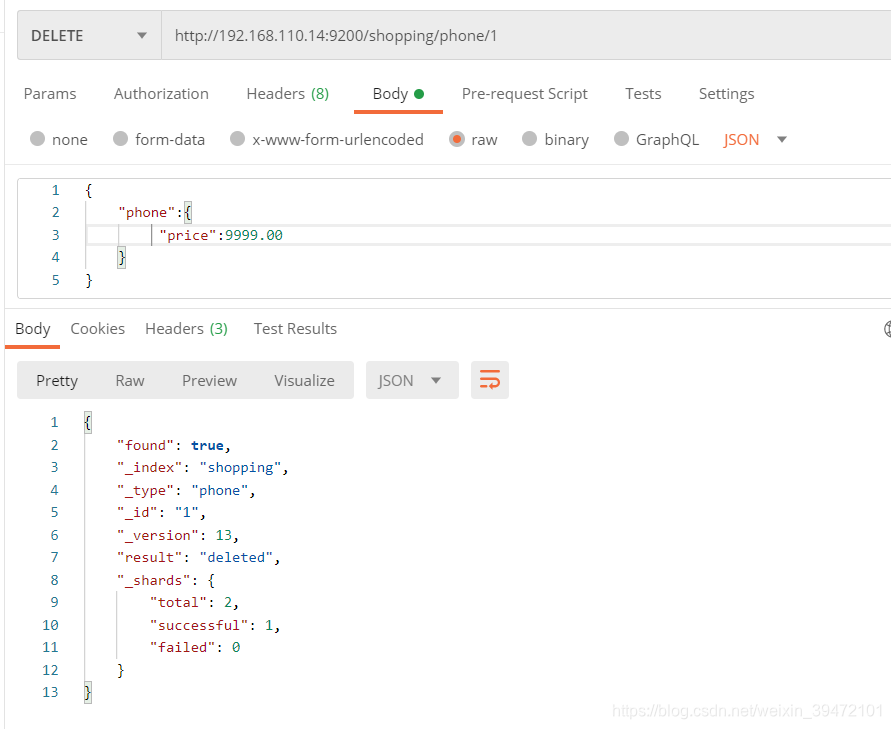
删除一个不存在的文档
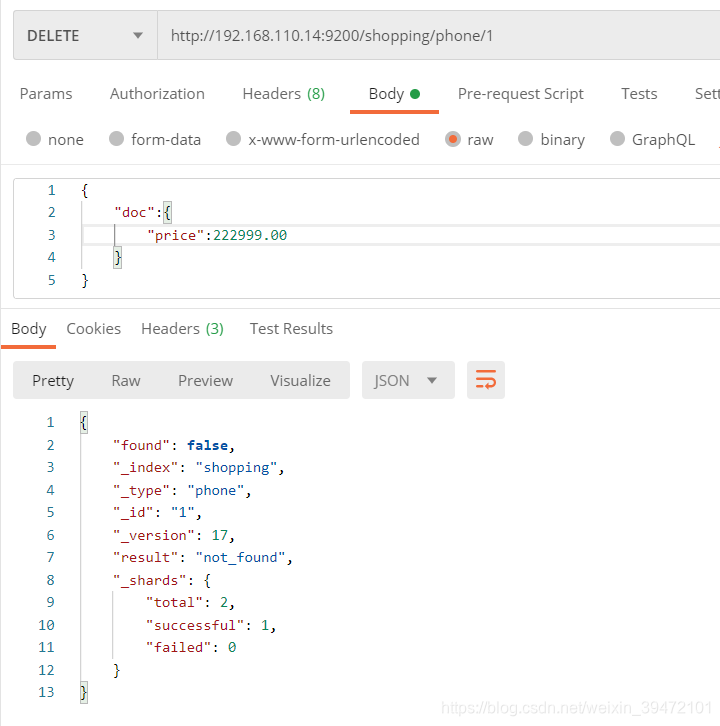
按照条件删除
post
http://192.168.110.14:9200/shopping/_delete_by_query
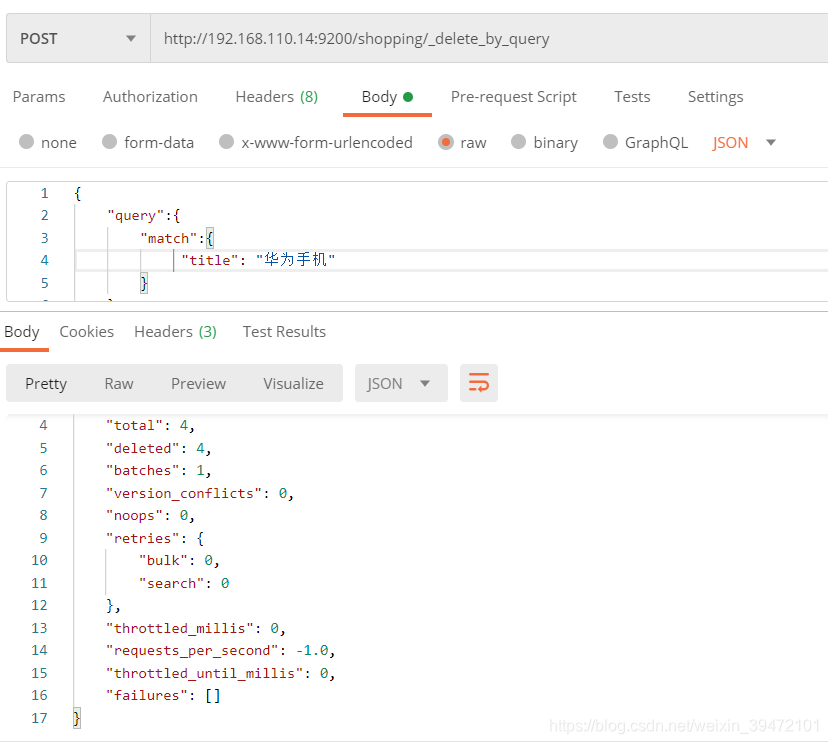
{
“took”: 118, 耗时
“timed_out”: false, 是否超时
“total”: 4, 总数
“deleted”: 4, 删除数量
“batches”: 1,
“version_conflicts”: 0,
“noops”: 0,
“retries”: {
“bulk”: 0,
“search”: 0
},
“throttled_millis”: 0,
“requests_per_second”: -1.0,
“throttled_until_millis”: 0,
“failures”: []
}
mappings 设置
使用put请求创建映射
http://192.168.110.14:9200/student/_mapping
{
“properties”:{
“name”:{ – 字段名称
“type”:“text”, – 字段类型
“index”:true
},
“sex”:{
“type”:“text”,
“index”:false
},
“age”:{
“type”:“long”,
“index”:false
}
}
}
1)字段类型 有哪些?
String 字符串类型
text: 可分词
keyword: 关键字 不可分词
Numerical 数值类型
基本类型:byte short int long double float
浮点数的高进度类型:scaled_float
Date 日期类型
Array 数组类型
Object 对象类型
2)定义中的index?
index 表示是否索引。默认是true,该字段会被索引到,能够进行搜索;false 表示不能被搜索到
3)store 是否将数据进行独立存储,默认是false
原始的文本会存储到_source,默认情况下 ,其他提取出来的字段都不是独立存储的,是从_source里面
提取出来的.当然你也可以独立的存储某个字段,只要设置"store":true即可,获取独立存储的字段
要比从_source中解析出来快得多,但是也会占用更多的空间,所以要更具业务需要来设置
4)analyzer: 分词器,这里的ik_max_word 及使用ik分词器
查询
get http://192.168.110.14:9200/shopping/_search
1)查询全部
{"query":{"mach_all":{}}
}
2)匹配查询
{"query":{"mach":{"name":"张三"}}
}
3)字段匹配查询
在多个字段上进行查询
{"query":{"multi_mach":{"name":"张三","fields":["name","nickname"]}}
}
4)关键字精准查询 ,类似于 “=”
{"query":{"trrm":{"name":"张三"}}
}
5)多关键字精准查询
{"query":{"trrms":{"name":["张三","lisi"]}}
}
6)查询指定字段
{"_source":["name","age"]"query":{"trrm":{"name":"张三"}}
}
7)过滤字段
includes 包含
excludes 不包含
{"_source":{"includes":["name","age"],"excludes":["sex"]}"query":{"trrm":{"name":"张三"}}
}
8)组合查询
bool must must_not should
{"query":{"bool":{"must":{"sex":"男"},"must_not":{"age":"40"},"should":{"name":"张"}}}
}
9) 查询范围
gt 大于>
gte 大于等于>=
lt 小于<
lte 小于等于<=
{"query":{"range":{"age":{"gt":10,"lt":50}}}
}
10) 模糊查询
fuzzy 类似于 like
fuzziness 指定距离
{"query":{"fuzzy":{"name":"si","fuzziness":2},}
}
11) 单个字段排序
{"query":{"mach":{"name":"张三"}},"sort":["age":{"order":desc}]
}
12)多个字段排序
{"query":{"mach_all":{}},"sort":["age":{"order":desc},"_source":{"order":desc}]
}
13)高亮显示
{"query":{"mach_all":{}},"highlight":{"pre_tags": "<font color='red'>","post_tags":"</font>""fields":{"name":{}}}
}
14) 分页查询
{"query":{"mach_all":{}},"sort":["age":{"order":desc}],"from":0"size":5
}
15) 聚合查询
最大
{"aggs":{"max_age":{"max":{"fields":"age"}}},"size":0
}
最小
{"aggs":{"min_age":{"min":{"fields":"age"}}},"size":0
}
平均
{"aggs":{"avg_age":{"avg":{"fields":"age"}}},"size":0
}
求和
{"aggs":{"sum_age":{"sum":{"fields":"age"}}},"size":0
}
个数
{"aggs":{"sum_age":{"sum":{"fields":"age"}}},"size":0
}
去重后求和
{"aggs":{"distinct_age":{"cardinality":{"fields":"age"}}},"size":0
}
一下子返回 max min avg count sum
{"aggs":{"seats_age":{"seats":{"fields":"age"}}},"size":0
}
16) 桶聚合查询 分组
{"aggs":{"age_groupby":{"terms":{"fields":"age"}}},"size":0
}
相关文章:
elasticsearch 基础
ES 搜索技术历史 今天看的是《Elasticsearch实战与原理解析》 第一章 搜索技术发展史 1、搜索技术发展史 宏观而言,搜索引擎的发展经历了五个尖端和两大分类。五个阶段分别是ftp文件检索阶段、分类目录阶段、文本相关性检索阶段、网页链接分析阶段和用户意图识别…...
【BUG】docker安装nacos,浏览器却无法访问到页面
个人主页:金鳞踏雨 个人简介:大家好,我是金鳞,一个初出茅庐的Java小白 目前状况:22届普通本科毕业生,几经波折了,现在任职于一家国内大型知名日化公司,从事Java开发工作 我的博客&am…...

C#引用Web Service 类型方法,添加搜索本地服务器Web Service 接口调用方法
首先保证现在网络能调用web service接口,右键项目添加服务引用 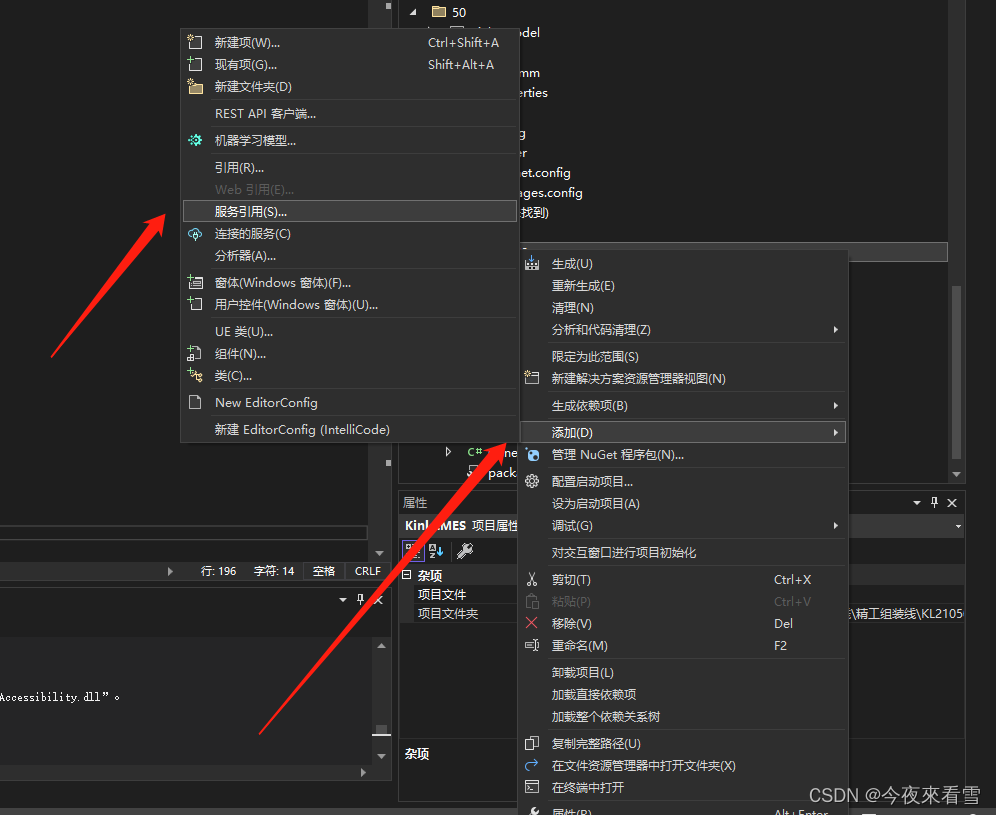 点击高级 添加web服务 输入搜索的服务器接口,选中你要添加调用的方法即可 添加完成调用方…...

yolov8训练进阶:新增配置参数
续yolov8训练进阶:自定义训练脚本,从配置文件载入训练超参数_CodingInCV的博客-CSDN博客 尽管yolov8有很多参数可以设置,但难免我们训练过程中会需要增加自己的参数,如新的数据增强、自定义的一些条件。那么在yolov8中如何实现呢&…...
轻量级自动化测试框架WebZ
一、什么是WebZ WebZ是我用Python写的“关键字驱动”的自动化测试框架,基于WebDriver。 设计该框架的初衷是:用自动化测试让测试人员从一些简单却重复的测试中解放出来。之所以用“关键字驱动”模式是因为我觉得这样能让测试人员(测试执行人员…...
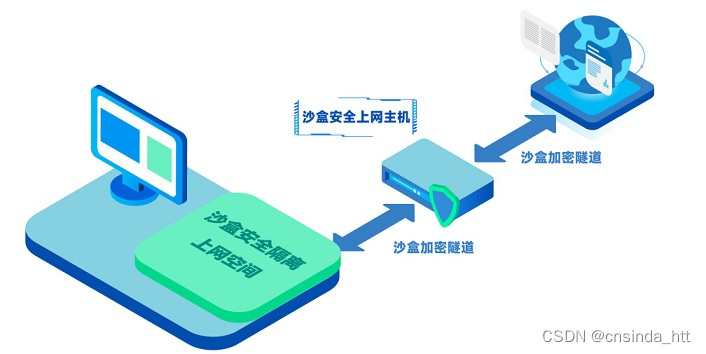
如何实现安全上网
l 场景描述 政府、军工、科研等涉密单位或企业往往要比其他组织更早接触高精尖的技术与产品,相对应的数据保密性要求更高。常规的内外网物理隔离手段,已经满足不了这些涉密单位的保密需求,发展到现在,需求已经演变成既要保证网络…...

Redis心跳检测
在命令传播阶段,从服务器默认会以每秒一次的频率,向主服务器发送命令: REPLCON FACK <rep1 ication_ offset>其中replication_offset是从服务器当前的复制偏移量。 发送REPLCONF ACK命令对于主从服务器有三个作用: 检测主…...
【数据库】Sql Server可视化工具SSMS条件和SQL窗格以及版本信息
2023年,第34周,第1篇文章。给自己一个目标,然后坚持总会有收货,不信你试试! SQL SERVER 官方本身就有数据库可视化管理工具SSMS,所以大部分都会使用SSMS。以前版本是直接捆绑, 安装完成就自带有…...

Python SFTP 详细使用
Python SFTP 详细使用 SFTP(SSH File Transfer Protocol)是一种基于SSH协议的安全文件传输协议。Python提供了paramiko库来实现SFTP功能。本文将详细介绍如何使用Python和paramiko库进行SFTP操作。 安装paramiko库 首先,我们需要安装param…...

MyBatis的XML映射文件
Mybatis的开发有两种方式: 注解 XML配置文件 通过XML配置文件的形式来配置SQL语句,这份儿XML配置文件在MyBatis当中也称为XML映射文件。 导学:在MyBatis当中如何来定义一份儿XML映射文件? 在MyBatis当中,定义XML…...
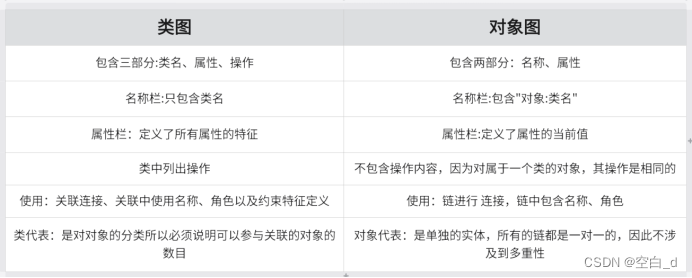
UML-类图和对象图
目录 类图概述: 1.类: 2.属性: 3.类的表示: 4.五种方法: 类图的关系: 1.关联 2.聚合 3.组合 4.依赖 5.泛化 6.实现 对象图概述: 1. 对象图包含元素: 2. 什么是对象 3.对象的状态可以改变: 4.对象的行为 5.对象标…...

升级指定版本Node.js或npm
一. 下载指定node.js版本Node.js 二. 升级node.js版本 打开电脑cmd 输入 npm install node18.17.1 -g 三. 升级npm版本 打开电脑cmd 输入 npm install npm8.1.2 -g...

UE4/5 GAS技能系统入门3 - GameplayEffect
阅读本文需要上一篇AttributeSet的基础知识: https://blog.csdn.net/grayrail/article/details/132148492 本文也并非教程性质文章,主要讲解学习记录为主。 这篇开始讲AttributeSet配置好后,GameplayEffect的使用。 1.将GE配置至Ability Co…...

Linux交叉编译opencv并移植ARM端
Linux交叉编译opencv并移植ARM端 - 知乎 一、安装交叉编译器 目标平台为arm7l,此为32位ARM架构,要安装合适的编译器 sudo apt install arm-linux-gnueabihf-gcc sudo apt install arm-linux-gnueabihf-g注意:64位ARM架构的编译器与32位ARM架…...
简介与安装)
TypeScript教程(一)简介与安装
一、简介 TypeScript 是 JavaScript 的一个超集,扩展了JavaScript的语法,因此现有的JavaScript可与TypeScript一起工作无需修改,支持 ECMAScript 6 标准(ES6 教程)。 语言特性: 1.类型批注和编译时类型检…...

做视频_Style
Video 1> 风格2> 技巧3> 借鉴 🔗 B站视频 1> 风格 记录分享生活,工作,学习方面的总结; 4个段位: 实用 -> 简洁 -> 清晰流畅 -> 生动有趣 2> 技巧 1> 大视频分段录制,最后合并…...
vue3使用pinia和pinia-plugin-persist做持久化存储
插件和版本 1、安装依赖 npm i pinia // 安装 pinia npm i pinia-plugin-persist // 安装持久化存储插件2、main.js引入 import App from ./App.vue const app createApp(App)//pinia import { createPinia } from pinia import piniaPersist from pinia-plugin-persist //持…...

数据结构入门指南:二叉树
目录 文章目录 前言 1. 树的概念及结构 1.1 树的概念 1.2 树的基础概念 1.3 树的表示 1.4 树的应用 2. 二叉树 2.1 二叉树的概念 2.2 二叉树的遍历 前言 在计算机科学中,数据结构是解决问题的关键。而二叉树作为最基本、最常用的数据结构之一,不仅在算法…...

大数据课程J2——Scala的基础语法和函数
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Scala的基础语法; ⚪ 掌握Scala的函数库; 一、Scala 基础语法一 1. 概述 语句 说明 示例 var 用来声明一个变量, 变量声明后…...
03-基础入门-搭建安全拓展
基础入门-搭建安全拓展 1、涉及的知识点2、常见的问题3、web权限的设置4、演示案例-环境搭建(1)PHPinfo(2)wordpress(3)win7虚拟机上使用iis搭建网站(4)Windows Server 2003配置WEB站…...

终极指南:如何用Continue实现AI驱动的代码检查与PR自动化审查
终极指南:如何用Continue实现AI驱动的代码检查与PR自动化审查 【免费下载链接】continue ⏩ Source-controlled AI checks, enforceable in CI. Powered by the open-source Continue CLI 项目地址: https://gitcode.com/GitHub_Trending/co/continue Contin…...

CANN/pypto PASS组件错误码说明
PASS 组件错误码说明文档 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 范围:F40000-F44002本文档说明 PASS 组件的错误码定义、场…...

CANN/pypto isfinite函数文档
pypto.isfinite 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品…...

都在喊难,它却狂赚!深度扒开长鑫科技底牌:什么才是决定生死的产业势?
2026年的商业世界,正在经历一场冰火两重天的考验。 一边,是无数传统企业在需求萎缩、价格内卷的泥潭里苦苦挣扎,老板们每天为了几毛钱的利润拼得头破血流;而另一边,一份堪称“核弹级”的财报,直接炸翻了整个…...

淘宝淘金币自动化脚本:3步解放你的双手,每天多赚30分钟自由时间
淘宝淘金币自动化脚本:3步解放你的双手,每天多赚30分钟自由时间 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/t…...

AI设计泳装,效率能翻几倍?
炎夏未至,泳装行业的备战硝烟却已弥漫。设计师灵感枯竭、打版反复修改、样衣成本高企……每一个痛点都像一座大山,压得品牌方喘不过气。面对Z世代瞬息万变的审美,“快”与“准”成了决胜关键。北京先智先行科技有限公司,正携旗下“…...

技术选型翻车实录:我们选的那个框架,两年后停止维护了
一、惊魂一刻:框架停更的暴击“紧急通知,我们一直使用的XX测试框架将于本月底停止维护!”当这条消息出现在团队工作群时,整个测试部瞬间陷入死寂。作为一家中型电商企业的测试负责人,我清楚地知道,这个框架…...

嵌入式工程师核心素养:从测试到系统构建的全链路能力模型
1. 从“明星评选”看嵌入式工程师的成长路径与价值塑造最近看到一篇关于某公司内部“品质与服务创建活动”的报道,评选了四位明星工程师。这让我感触颇深。在嵌入式这个行当里摸爬滚打了十几年,我见过太多技术扎实但默默无闻的同行,也见过一些…...
)
从零开始学AI Agent:软件工程视角下的企业数字化转型实践指南(收藏版)
本文从软件工程视角出发,探讨了AI Agent在企业数字化转型中的应用与构建。首先强调需求分析的重要性,指出应从业务问题出发判断Agent是否适用。接着,介绍了Agent的系统设计,包括任务编排、上下文管理、记忆存储和工具扩展四个核心…...

使用电脑快速测试 PROFINET 设备通讯
Anybus PROFINET主站仿真工具介绍日常对客户进行技术支持的时候,我们发现工厂自动化领域的不同部门不同职能的人员对于工业通讯设备都面临着一些使用的困难,例如设备研发人员,尤其是嵌入式研发部门,对于工厂自动化使用的工业通讯协…...