Solr的入门使用
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化,被很多需要搜索的网站中广泛使用。
Solr基于Lucene的Java搜索引擎服务器,其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。
Solr安装
目前使用环境:
- Java 1.8
- Solr 8.2.0版本
- Windows7
下载
我们可在官网下载Solr对应的版本。下载到相应位置并解压,可看到不同的文件目录。
- bin:solr的运行脚本
- contrib:solr的一些扩展jar包,用于增强solr的功能
- dist:该目录包含build过程中产生的jar文件,以及相关的依赖文件
- example:solr工程的例子目录
- licenses:solr相关的一些许可信息
启动
进入到bin目录,打开cmd窗口,运行solr start即可启动。Solr默认端口为8983,启动成功后可在浏览器访问localhost:8983/solr,如若启动成功,可看到Solr管理界面。
solr的操作
启动 solr start
停止 solr stop
重启 solr restart
状态 solr status
配置中文分词器
Solr默认没有中文分词器,作为国人需要自己安装中文分词器,我使用的是IK-Analyzer-Solr8分词器。可在如下地址下载Jar包。
将下载的Jar包放入到~\solr-8.2.0\server\solr-webapp\webapp\WEB-INF\lib目录下,并配置~\solr-8.2.0\server\solr\configsets\_default\conf\managed-schema文件,加入以下配置代码。
<dynamicField name="*_txt_ik" type="text_ik" indexed="true" stored="true"/>
<fieldType name="text_ik" class="solr.TextField"><analyzer type="index"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer>
</fieldType>
创建Core
在Solr中,每一个Core代表一个索引库,里面包含索引数据及其配置信息。Solr中可以拥有多个Core,也就是同进管理多个索引库、就像MySQL中可以有多个数据库一样。
Solr的bin目录下打开cmd窗口,运行solr create -c test_solr,test_solr是core名,可以自定义修改。创建成功后,会在~\solr-8.2.0\server\solr中出现相应的文件夹,里面需要注意managed-schema、solrconfig.xml两个配置文件。managed-schema定义了索引库的数据类型,同时指明某个类型的字段是不是要进行索引,是不是要进行保存到索引库里等等。solrconfig.xml则是包含了很多solr自身配置相关的参数。
这样我们就可以在Solr界面进行插入Field、插入数据、查询数据等等操作了。
Java操作Solr
引入Jar包
<dependency><groupId>org.apache.solr</groupId><artifactId>solr-solrj</artifactId><version>8.2.0</version>
</dependency>
定义对象
import org.apache.solr.client.solrj.beans.Field;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@AllArgsConstructor
@NoArgsConstructor
public class Worker{@Field("workid")private String workid;@Field("position")private String position;@Field("salary")private double salary;
}
Java连接Solr服务器
private final static String SOLR_URL = "http://localhost:8983/solr/test_solr2";HttpSolrClient solr = null;@Before
public void createSolrServer() {solr = new HttpSolrClient.Builder(SOLR_URL).withConnectionTimeout(10000).withSocketTimeout(60000).build();
}
增删改查
1、新增\修改数据
@Test
public void addDoc() throws SolrServerException, IOException {SolrInputDocument document = new SolrInputDocument();document.addField("workid", "20190730A82");document.addField("position", "前端工程师");document.addField("salary", 8000);solr.add(document);solr.commit();solr.close();System.out.println("添加成功");
}
2、删除数据
@Test
public void deleteDocById() throws SolrServerException, IOException {//server.deleteById("39b070b4-c1f6-4f2b-899c-b9f8916ebecc");solr.deleteByQuery("id:*");solr.commit();solr.close();
}
3、查询数据
@Test
public void querySolr() throws Exception {SolrQuery query = new SolrQuery();//下面设置solr查询参数//query.set("q", "*:*");// 参数q 查询所有 //query.set("q", "position:*工程*");//模糊查询//参数fq, 给query增加过滤查询条件 //query.addFacetQuery("salary:[6000 TO 9000]");//query.addFilterQuery("position:数据库*"); ////参数df,给query设置默认搜索域,从哪个字段上查找query.set("df", "position"); //参数sort,设置返回结果的排序规则query.setSort("salary",SolrQuery.ORDER.desc);//设置分页参数query.setStart(0);query.setRows(10);//设置高亮显示以及结果的样式query.setHighlight(true);query.addHighlightField("salary"); query.setHighlightSimplePre("<font color='red'>"); query.setHighlightSimplePost("</font>"); //执行查询QueryResponse response = solr.query(query);//获取实体对象形式List<Worker> worker = response.getBeans(Worker.class);worker.stream().forEach(System.out::println);//获取返回结果SolrDocumentList resultList = response.getResults();System.out.println(FastJsonUtils.toJSONString(resultList));
}
基本查询方式
q 查询的关键字,例如,q=id:1,默认为q=*:*,
fl 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort
start 返回结果的第几条记录开始,一般分页用,默认0开始
rows 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页
sort 排序方式,例如id desc 表示按照 "id" 降序
wt(writer type) 指定输出格式,有 xml, json, php等
fq(filter query) 过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的。
df 默认的查询字段,一般默认指定。
qt(query type) 指定那个类型来处理查询请求,一般不用指定,默认是standard。
indent 返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
version 查询语法的版本,建议不使用它,由服务器指定默认值。
检索运算符
: 指定字段查指定值,如返回所有值*:*
? 表示单个任意字符的通配
* 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号)
~ 表示模糊检索,如检索拼写类似于”roam”的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录。
AND、||、OR、&& 布尔操作符
NOT、!、- 排除操作符不能单独与项使用构成查询
+ 存在操作符,要求符号”+”后的项必须在文档相应的域中存在
( ) 用于构成子查询
[] 包含范围检索,如检索某时间段记录,包含头尾,date:[201507 TO 201510]
{} 不包含范围检索,如检索某时间段记录,不包含头尾date:{201507 TO 201510}
注意点
在进行数据插入之前,一定要提前在managed-schema中定义索引字段、索引字段类型等等参数,不然使用默认类型的时候会出现不是自己想要的类型,然后出现不可预料的问题,建议自己提前定义好再进行数据插入。如果要进行分词搜索,可把相应字段定义text_ik分词类型(根据中英文或者自定义的分词名)。
相关文章:

Solr的入门使用
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化,被很多需要搜索的网站中广泛使用。…...

css鼠标样式 cursor: pointer
cursor: none; cursor:not-allowed; 禁止选择 user-select: none; pointer-events:none;禁止触发事件, 该样式会阻止默认事件的发生,但鼠标样式会变成箭头...
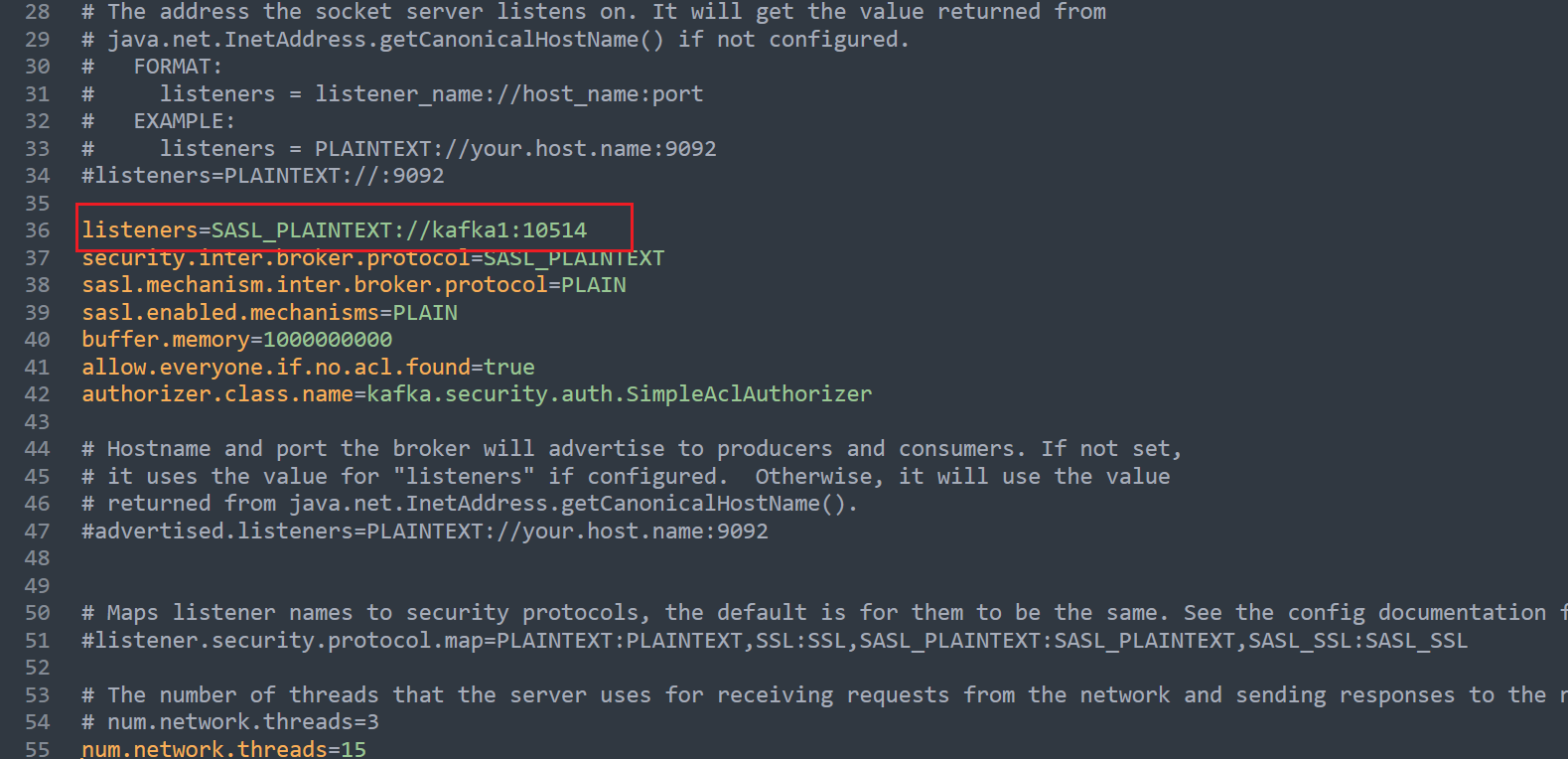
【解决】Kafka Exception thrown when sending a message with key=‘null‘ 异常
问题原因: 如下图,kafka 中配置的是监听域名的方式,但程序里使用的是 ip:port 的连接方式。 解决办法: kafka 中配置的是域名的方式,程序里也相应配置成 域名:port 的方式(注意:本地h…...

中心极限定理 简明教程
中心极限定理是概率论中的一组定理,它们描述了一些独立随机变量的和或平均值的分布在一定条件下趋近于正态分布的现象。中心极限定理有多种形式,其中最常见的是独立同分布的中心极限定理,它可以用数学公式表示为: 前提条件&#x…...
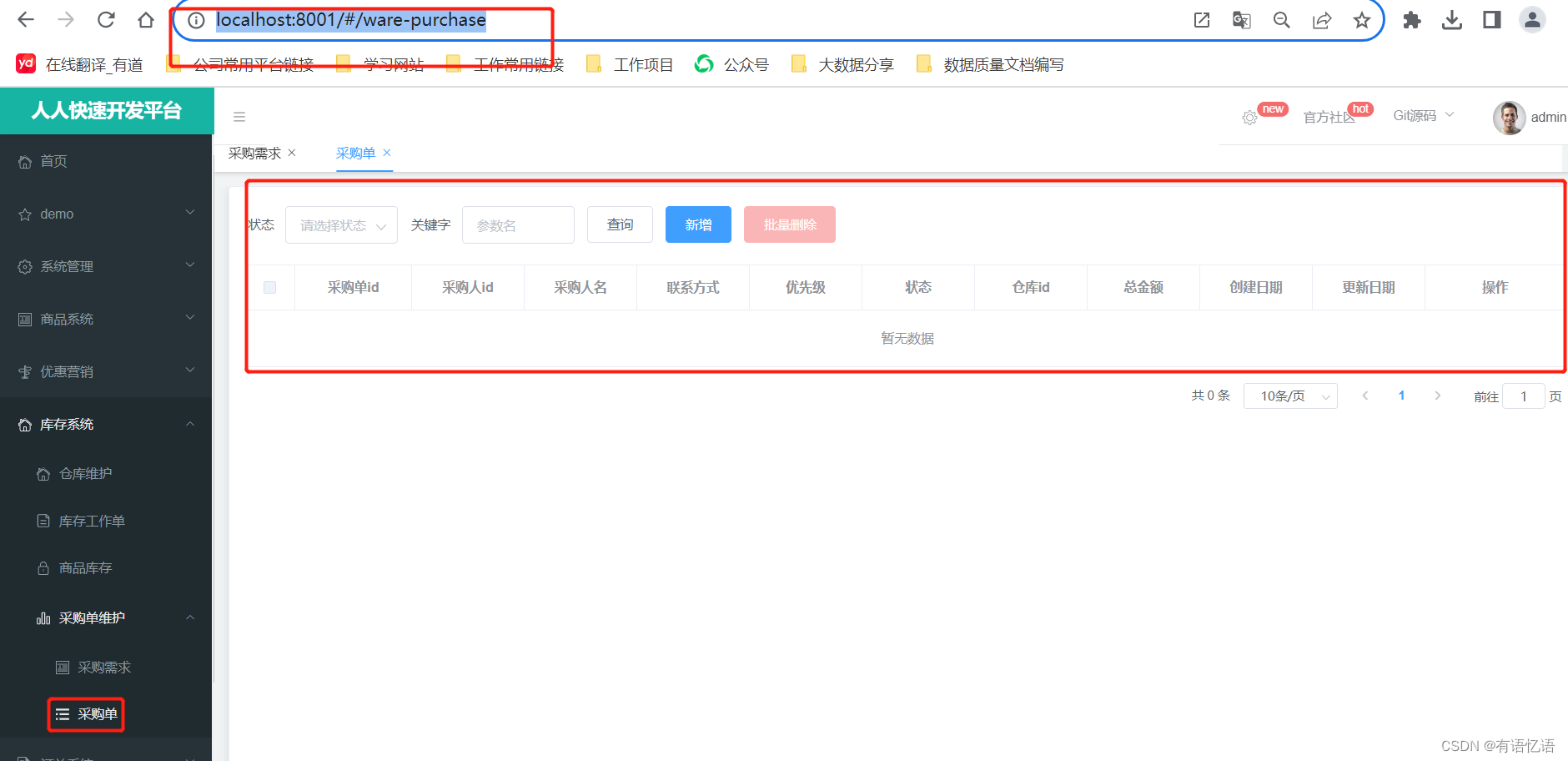
商城-学习整理-基础-库存系统(八)
一、整合ware服务 1、配置注册中心 2、配置配置中心 3、配置网关,重启网关 二、仓库维护 http://localhost:8001/#/ware-wareinfo 在前端项目module中创建ware文件夹保存仓库系统的代码。 将生成的wareinfo.vue文件拷贝到项目中。 根据功能,修改后台接…...
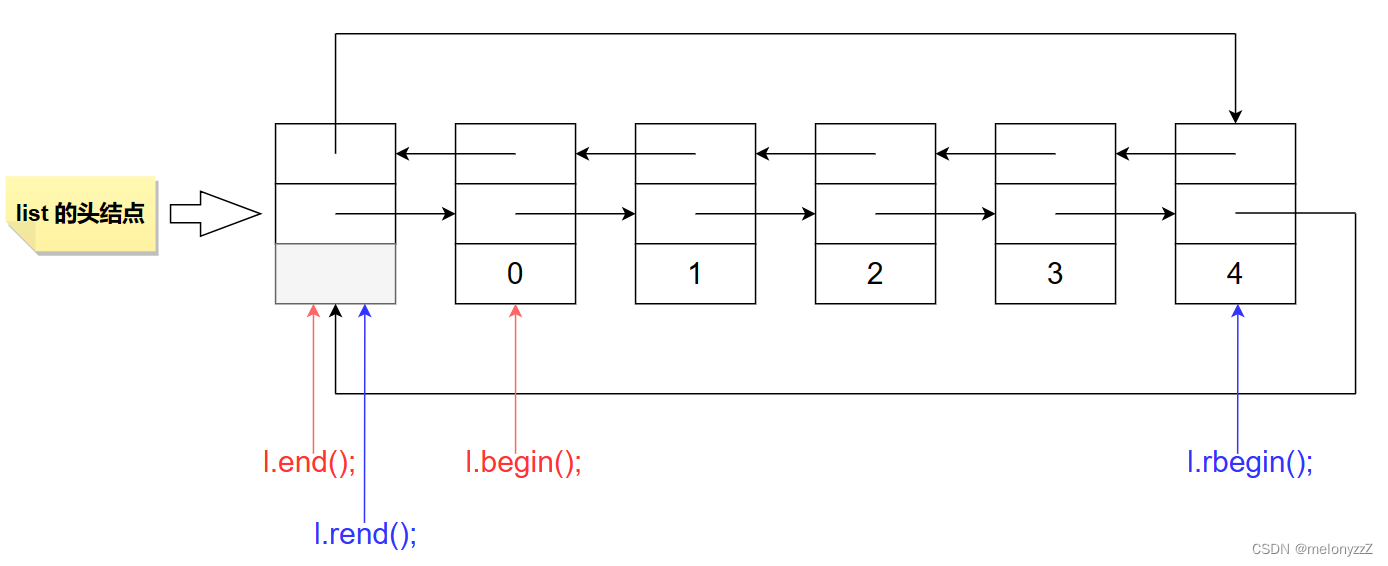
【C++ 学习 ⑬】- 详解 list 容器
目录 一、list 容器的基本介绍 二、list 容器的成员函数 2.1 - 迭代器 2.2 - 修改操作 三、list 的模拟实现 3.1 - list.h 3.2 - 详解 list 容器的迭代器 3.2 - test.cpp 一、list 容器的基本介绍 list 容器以类模板 list<T>(T 为存储元素的类型&…...
)
设计模式十五:命令模式(Command Pattern)
命令模式(Command Pattern)是一种行为型设计模式,它旨在将请求或操作封装成一个对象,从而允许你将不同的请求参数化,并且能够在不同的时间点执行或者队列化这些请求。这种模式使得请求发送者与接收者之间解耦ÿ…...
FPGA GTP全网最细讲解,aurora 8b/10b协议,HDMI视频传输,提供4套工程源码和技术支持
目录 1、前言免责声明 2、我这里已有的 GT 高速接口解决方案3、GTP 全网最细解读GTP 基本结构GTP 发送和接收处理流程GTP 的参考时钟GTP 发送接口GTP 接收接口GTP IP核调用和使用 4、设计思路框架HDMI输入视频配置及采集视频数据组包GTP aurora 8b/10b数据对齐视频数据解包图像…...

用dcker极简打包java.jar镜像并启动
用dcker极简打包java.jar镜像并启动 一、本地打包好jar包 二、新建文件夹,将步骤1中的jar包拷贝到文件夹下 三、同目录下新建Dockerfile ## 基础镜像,这里用的是openjdk:8 FROM openjdk:8## 将步骤一打包好的jar包 拷贝到镜像的 跟目录下[目录可以自定义…...

设计模式——创建型
1.单例模式 单例模式主要用于某个类有且只能用一个对象的场景,单例模式下不能外部实例化对象,由类内部自行私有化实例对象并提供一个可以获得该对象的方法。单例模式主要有饿汉模式(安全,但在编译时就会自动创建对象,…...
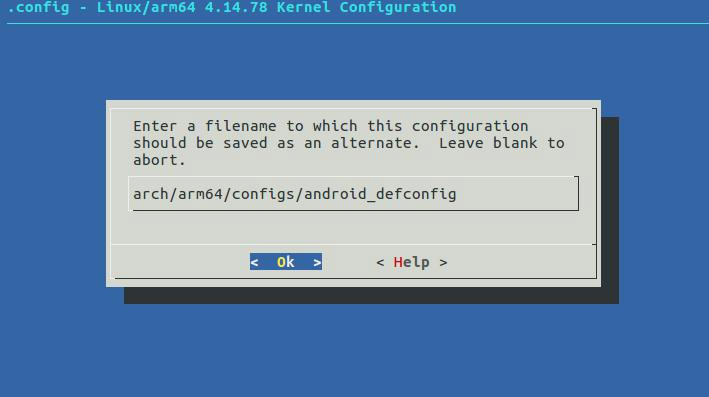
iTOP-i.MX8M开发板添加USB网络设备驱动
选中支持 USB 网络设备驱动,如下图所示: [*] Device Drivers→ *- Network device support → USB Network Adapters→ {*} Multi-purpose USB Networking Framework 将光标移动到 save 保存,如下图所示: 保存到 arch/arm64/c…...
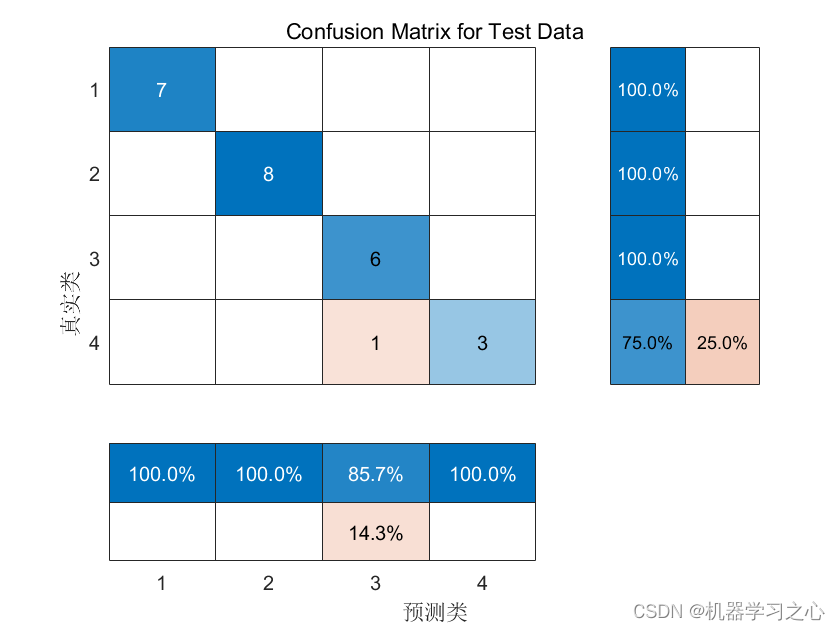
分类预测 | MATLAB实现GAPSO-LSSVM多输入分类预测
分类预测 | MATLAB实现GAPSO-LSSVM多输入分类预测 目录 分类预测 | MATLAB实现GAPSO-LSSVM多输入分类预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.分类预测 | MATLAB实现GAPSO-LSSVM多输入分类预测 2.代码说明:要求于Matlab 2021版及以上版本。 程序…...

JMeter 的并发设置教程
JMeter 是一个功能强大的性能测试工具,可以模拟许多用户同时访问应用程序的情况。在使用 JMeter 进行性能测试时,设置并发是非常重要的。本文将介绍如何在 JMeter 中设置并发和查看报告。 设置并发 并发是在线程组下的线程属性中设置的。 线程数&#…...

数据治理有哪些产品
数据治理是现代企业管理中至关重要的一个环节。随着企业的数据量不断增长,如何有效地管理和利用数据成为了一个亟待解决的问题。幸运的是,市场上已经涌现出了许多优秀的数据治理产品,下面就来介绍一些常见的数据治理产品。 首先,我…...
windows安装go,以及配置工作区,配置vscode开发环境
下载安装go 我安装在D:\go路径下配置环境变量 添加GOROOT value为D:\go修改path 添加%GOROOT%\bin添加GOPATH value为%USERPROFILE%\go 其中GOPATH 是我们自己开发的工作区,其中包含三个folder bin,pkg,以及src,其中src为我们编写代码的位置 配置vscod…...

第五章nginx负载均衡
负载均衡:反向代理来实现 nginx的七层代理: 七层是最常用的反向代理方式,只能配置在nginx配置文件的hppt模块中。而且配置方法名称:upstream模块,不能写在server中,也不能在location中,在http…...
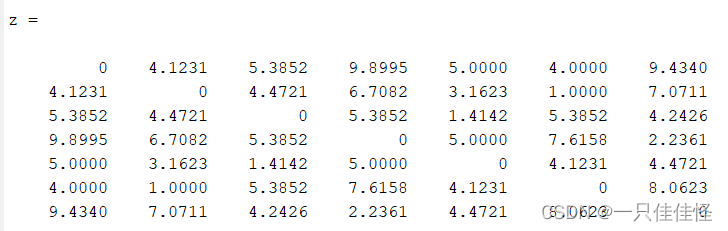
MATLAB计算一组坐标点的相互距离(pdist、squareform、pdist2函数)
如果有一组坐标P(X,Y),包含多个点的X和Y坐标,计算其坐标点之间的相互距离 一、坐标点 P[1 1;5 2;3 6;8 8;4 5;5 1; 6 9];二、pdist函数 输出的结果是一维数组,获得任意两个坐标之间的距离,但没有对应关系 Dpdist(P)三、square…...

我国农机自动驾驶系统需求日益增长,北斗系统赋能精准农业
中国现代农业的发展,离不开智能化、自动化设备,迫切需要自动驾驶系统与农用机械的密切结合。自动驾驶农机不仅能够缓解劳动力短缺问题,提升劳作生产效率,同时还能对农业进行智慧化升级,成为解决当下农业痛点的有效手段…...

防雷检测行业应用完整解决方案
防雷检测是指对雷电防护装置的性能、质量和安全进行检测的活动,是保障人民生命财产和公共安全的重要措施。防雷检测的作用和意义主要有以下几点: 防止或减少雷电灾害事故的发生。雷电是一种自然现象,具有不可预测、不可控制和高能量等特点&a…...

16.4 【Linux】特殊文件与程序
16.4.1 具有 SUID/SGID 权限的指令执行状态 SUID 的权限其实与程序的相关性非常的大!为什么呢?先来看看 SUID 的程序是如何被一般使用者执行,且具有什么特色呢? SUID 权限仅对二进制程序(binary program)…...

5分钟学会LDDC:让每一首歌都有完美歌词的终极指南
5分钟学会LDDC:让每一首歌都有完美歌词的终极指南 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目地址: …...
)
Midjourney纹理失控?3步诊断+4类修复模板(附12组对比Prompt+SD交叉验证报告)
更多请点击: https://kaifayun.com 第一章:Midjourney纹理生成技巧 在 Midjourney 中生成高质量、可控的纹理,关键在于精准的提示词工程、参数协同与风格锚定。不同于通用图像生成,纹理需强调重复性、无缝性、材质物理属性&#…...

Ladybug天气数据分析工具:建筑环境设计的智能助手
Ladybug天气数据分析工具:建筑环境设计的智能助手 【免费下载链接】ladybug 🐞 Core ladybug library for weather data analysis and visualization 项目地址: https://gitcode.com/gh_mirrors/lad/ladybug Ladybug是一个功能强大的Python天气数…...

Win11Debloat:让你的Windows系统告别臃肿,重获极速体验的完整指南
Win11Debloat:让你的Windows系统告别臃肿,重获极速体验的完整指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other chang…...

多角色对话配音方案:顶伯 一键生成有声剧,支持角色区分
多角色对话配音方案:顶伯 一键生成有声剧,支持角色区分在制作有声剧、播客或短视频时,多角色对话配音往往是最耗时的一环。传统方法需要为每个角色分别录制、剪辑、混音,不仅效率低下,还容易因音色不统一而影响沉浸感。…...

用USRP B200mini和GNU Radio抓取大疆无人机位置:一个极客的无线安全实验手记
极客实验室:用USRP B200mini破解无人机通信协议实战指南 从零开始的SDR探险 去年夏天的一个傍晚,我在阳台上调试天线时,突然注意到头顶频繁掠过的无人机。这些飞行器究竟在传输什么数据?这个偶然的观察引发了我长达三个月的技术…...

Vue SSR实战:如何用Express + Webpack-dev-middleware实现开发环境热更新与内存编译?
Vue SSR开发环境优化:Express与Webpack-dev-middleware深度整合指南 1. 为什么需要开发环境热更新? 在传统Vue SSR项目开发中,每次代码修改后都需要手动重启服务并刷新浏览器,这种开发体验对于中型以上项目来说效率极低。想象一…...
)
Wireshark实战:从流量包里‘捞出’图片和压缩包的两种方法(附CTF解题步骤)
Wireshark实战:从流量包里‘捞出’图片和压缩包的两种方法(附CTF解题步骤) 在网络安全和数字取证领域,网络流量分析是一项基础但至关重要的技能。想象一下这样的场景:你正在调查一起数据泄露事件,或者参加…...

飞机在飞行中将电力传输至地面接收器
此次演示为太空太阳能新方案奠定了基础。在2025年11月一个狂风大作的日子,一架塞斯纳涡轮螺旋桨飞机在5000米的高度飞越宾夕法尼亚州上空时,遭遇了时速高达70节(约130公里/小时)的侧风,风速几乎与这架小型飞机的飞行速…...

SMUDebugTool:5个技巧掌握AMD Ryzen底层硬件调试的完整指南
SMUDebugTool:5个技巧掌握AMD Ryzen底层硬件调试的完整指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https…...