R语言ggplot2 | R语言绘制物种组成面积图(三)
📋文章目录
- 面积图简介
- 准备数据集
- 加载数据集
- 数据处理
- 数据可视化
利用R语言绘制物种组成图。本文以堆叠面积图的方式与大家分享。
面积图简介
面积图又叫区域图。它是在折线图的基础之上形成的, 它将折线图中折线与自变量坐标轴之间的区域使用颜色或者纹理填充,这样一个填充区域我们叫面积。颜色的填充可以更好地突出趋势信息(比如时间上的差异,分类上的差异),需要注意的是颜色要带有一定的透明度,透明度可以很好地帮助使用者观察不同序列之间的重叠关系,没有透明度的面积会导致不同序列之间相互遮盖减少可以被观察到的信息。
与折线图相似,面积图可用于强调数量随时间或分类而变化的程度,也可用于引起人们对总值趋势的注意。他们最常用于表现趋势和关系,而不是传达特定的值。
- 所有的数据都从相同的零轴开始。
- 标准面积图适用于展示或者比较随着时间连续变化的定量。
- 在需要绘制大量数据系列的情况下,折线图通常是更清晰的可视化表达方式。

准备数据集


加载数据集
otudf <- read.csv("otudf.csv", header = T, row.names = 1)
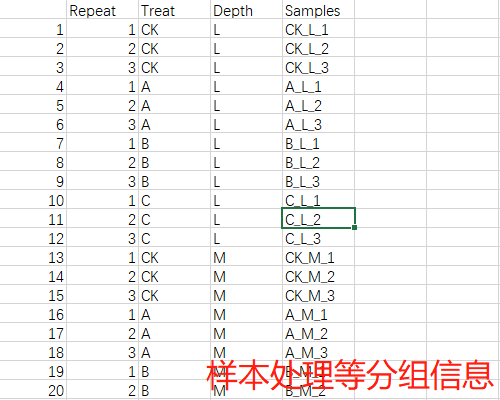
group_infor <- read.csv("group_infor.csv", header = T, row.names = 1)head(otudf[1:6, 1:6])
# CK_L_1 CK_L_2 CK_L_3 A_L_1 A_L_2 A_L_3
# otu_1 414 1371 113 1190 427 1327
# otu_2 462 1028 937 394 1266 547
# otu_3 178 193 722 1421 705 579
# otu_4 525 56 822 885 690 944
# otu_5 194 1353 365 680 1218 677
# otu_6 937 1140 1499 1098 1460 494
head(group_infor)
# Repeat Treat Depth Samples
# 1 1 CK L CK_L_1
# 2 2 CK L CK_L_2
# 3 3 CK L CK_L_3
# 4 1 A L A_L_1
# 5 2 A L A_L_2
# 6 3 A L A_L_3
数据处理
## 提取物种丰度和物种注释信息
species <- otudf[c(1:36)]
taxa <- otudf[-c(1:36)]## 确定数据正确与否
head(species)
# CK_L_1 CK_L_2 CK_L_3 A_L_1 A_L_2 A_L_3 B_L_1 B_L_2 B_L_3 C_L_1 C_L_2 C_L_3 CK_M_1 CK_M_2 CK_M_3 A_M_1 A_M_2 A_M_3
# otu_1 414 1371 113 1190 427 1327 631 207 1473 1322 1370 1476 28 1271 125 978 945 0
# otu_2 462 1028 937 394 1266 547 1144 851 365 1418 651 1329 1061 1124 332 919 1483 600
# otu_3 178 193 722 1421 705 579 1103 1398 241 1328 1286 452 263 1446 893 1098 868 661
# otu_4 525 56 822 885 690 944 86 720 1135 37 1323 792 362 696 806 1398 11 37
# otu_5 194 1353 365 680 1218 677 1129 547 829 1038 103 276 1166 630 539 1298 277 663
# otu_6 937 1140 1499 1098 1460 494 988 709 1137 251 356 130 344 727 1332 516 1154 454
# B_M_1 B_M_2 B_M_3 C_M_1 C_M_2 C_M_3 CK_H_1 CK_H_2 CK_H_3 A_H_1 A_H_2 A_H_3 B_H_1 B_H_2 B_H_3 C_H_1 C_H_2 C_H_3
# otu_1 1394 213 1449 1431 786 697 627 463 935 58 118 967 864 226 1053 834 551 961
# otu_2 985 247 1135 943 584 264 1286 838 37 1057 320 982 1351 621 1058 667 696 780
# otu_3 1117 566 508 142 1016 924 244 1426 1093 994 1166 962 632 628 163 1455 756 878
# otu_4 244 787 1261 533 1025 583 201 533 1051 651 1294 20 206 1151 369 1499 358 1083
# otu_5 716 736 1219 1411 1295 3 434 1023 406 1215 1074 994 1220 1220 528 1349 1138 906
# otu_6 1053 163 295 412 473 317 1065 981 1036 1113 435 19 1396 1151 1048 134 1199 383
head(taxa)
# phylum class order family genus species
# otu_1 Spirochaetes Gemmatimonadetes BRC1 Firmicutes Planctomycetes Nitrospirae
# otu_2 WPS_1 Euryarchaeota Cyanobacteria Armatimonadetes Spirochaetes Chloroflexi
# otu_3 Gemmatimonadetes Gemmatimonadetes Armatimonadetes Cyanobacteria WPS_2 WPS_1
# otu_4 WPS_1 Chloroflexi Acidobacteria Firmicutes Acidobacteria WPS_2
# otu_5 Acidobacteria Cyanobacteria BRC1 Chloroflexi Bacteroidetes Spirochaetes
# otu_6 Planctomycetes Gemmatimonadetes WPS_1 Chloroflexi Chloroflexi Armatimonadetes# 计算不同处理下的门水平均值
library(tidyverse)
Phylum <- species %>%group_by(taxa$phylum) %>% # 使用taxa中的门水平进行分类summarise_all(sum) %>% # 计算总的otu数量rename(Phylum = `taxa$phylum`) %>% # 修改名称gather(key = "Samples", value = "Abundance", -Phylum) %>% # 数据形式转换 宽-长left_join(group_infor, by = c("Samples" = "Samples")) %>%select(Phylum, Treat, Depth, Abundance) %>%group_by(Phylum, Treat, Depth) %>% # 求均值summarise_all(mean) %>%arrange(Phylum, Treat, Depth, desc(Abundance))
Phylum
# # A tibble: 204 × 4
# # Groups: Phylum, Treat [68]
# Phylum Treat Depth Abundance
# <chr> <chr> <chr> <dbl>
# 1 Acidobacteria A H 462665.
# 2 Acidobacteria A L 459384.
# 3 Acidobacteria A M 454049.
# 4 Acidobacteria B H 454310
# 5 Acidobacteria B L 455244.
# 6 Acidobacteria B M 448743.
# 7 Acidobacteria C H 449425
# 8 Acidobacteria C L 455059.
# 9 Acidobacteria C M 454707.
# 10 Acidobacteria CK H 456931
# # … with 194 more rows
# # ℹ Use `print(n = ...)` to see more rows## 选择top9 及 合并剩余物种作为Other
phy_select <- unique(Phylum$Phylum)[1:9]top9 <- Phylum[Phylum$Phylum %in% phy_select, ]
other <- Phylum[!Phylum$Phylum %in% phy_select, ]
other <- other %>% group_by(Treat, Depth) %>% summarise(Abundance = mean(Abundance)) %>% cbind(Phylum = "Other") %>%select(Phylum, Treat, Depth, Abundance, everything())top10 <- rbind(top9, other)
head(top10)
# # A tibble: 6 × 4
# # Groups: Phylum, Treat [2]
# Phylum Treat Depth Abundance
# <chr> <chr> <chr> <dbl>
# 1 Acidobacteria A H 462665.
# 2 Acidobacteria A L 459384.
# 3 Acidobacteria A M 454049.
# 4 Acidobacteria B H 454310
# 5 Acidobacteria B L 455244.
# 6 Acidobacteria B M 448743.
数据可视化
# 物种组成堆叠面积图
library(ggplot2)
library(ggalluvial)
ggplot(data = top10,aes(x = Depth, y = Abundance, fill = reorder(Phylum, -Abundance),colour = reorder(Phylum, -Abundance),stratum = reorder(Phylum, -Abundance) ,alluvium = reorder(Phylum, -Abundance))) +geom_alluvium(aes(fill = reorder(Phylum, -Abundance)), alpha = 0.7, decreasing = FALSE) +geom_stratum(aes(fill = reorder(Phylum, Abundance)), width = 0.3, size = 0.1, color = "black") +scale_y_continuous(expand = c(0, 0)) +theme_bw() +facet_grid(. ~ Treat, scales = "fixed") +scale_fill_manual(values = c("#EB7369", "#CF8B0B", "#9D9F20", "#2BB077", "#2BB077","#1BB3B7", "#29A4DE", "#8989C1", "#B174AD","#DE66A1"), name = "Phylum") +scale_color_manual(values = c("#EB7369", "#CF8B0B", "#9D9F20", "#2BB077", "#2BB077","#1BB3B7", "#29A4DE", "#8989C1", "#B174AD","#DE66A1")) +guides(color = "none")+theme(panel.grid=element_blank(),panel.spacing.x = unit(0, units = "cm"),strip.background = element_rect(color = "white", fill = "white", linetype = "solid", size = 1),strip.placement = "outside",axis.line.y.left = element_line(color = "black", size = 0.7),axis.line.x.bottom = element_line(color = "black", size = 0.7),strip.text.x = element_text(size = 14, face = "bold"),axis.text = element_text(face = "bold", size = 12, color = "black"),axis.title = element_text(face = "bold", size = 14, colour = "black"),legend.title = element_text(face = "bold", size = 12, color = "black"),legend.text = element_text(face = "bold", size = 12, color = "black"),axis.ticks.x = element_line(size = 1),axis.ticks.y = element_line(size = 1),)+labs(x = "Depth",y= "Relative Abundance of Phylum (%)")
相关文章:
R语言ggplot2 | R语言绘制物种组成面积图(三)
📋文章目录 面积图简介准备数据集加载数据集数据处理数据可视化 利用R语言绘制物种组成图。本文以堆叠面积图的方式与大家分享。 面积图简介 面积图又叫区域图。它是在折线图的基础之上形成的, 它将折线图中折线与自变量坐标轴之间的区域使用颜色或者纹理填充&…...

数据统计与可视化的Dash应用程序
在数据分析和可视化领域,Dash是一个强大的工具,它结合了Python中的数据处理库(如pandas)和交互式可视化库(如Plotly)以及Web应用程序开发框架。本文将介绍如何使用Dash创建一个简单的数据统计和可视化应用程…...

解决并发冲突:Java实现MySQL数据锁定策略
在并发环境下,多个线程同时对MySQL数据库进行读写操作可能会导致数据冲突和不一致的问题。为了解决这些并发冲突,我们可以采用数据锁定策略来保证数据的一致性和完整性。下面将介绍如何使用Java实现MySQL数据锁定策略,以及相关的注意事项和最…...

C++——函数重载及底层原理
函数重载的定义 函数重载: 是函数的一种特殊情况,C允许在同一作用域重声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数或者类型,类型的顺序)不同,常用来处理实现功能类似数据结构…...
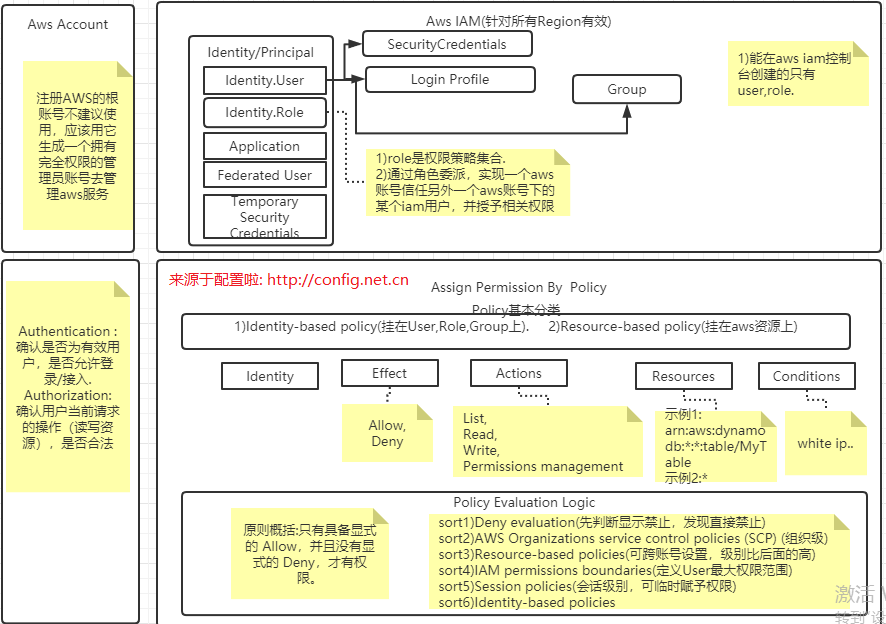
Ceph入门到精通-Aws Iam(user,role,group,policy,resource)架构图和快速入门
-- Aws Iam(identity,user,role,group,policy,resource,)架构图和快速入门. 【官网】:Cloud Computing Services - Amazon Web Services (AWS) 应用场景 aws 云服务运维,devops过程中经常涉及各项服务,权限,角色的处理。 为了更好的使用各项…...
【kubernetes】k8s高可用集群搭建(三主三从)
目录 【kubernetes】k8s高可用集群搭建(三主三从) 一、服务器设置 二、环境配置 1、关闭防火墙 2、关闭selinux 3、关闭swap 4、修改主机名(根据主机角色不同,做相应修改) 5、主机名映射 6、将桥接的IPv4流量…...
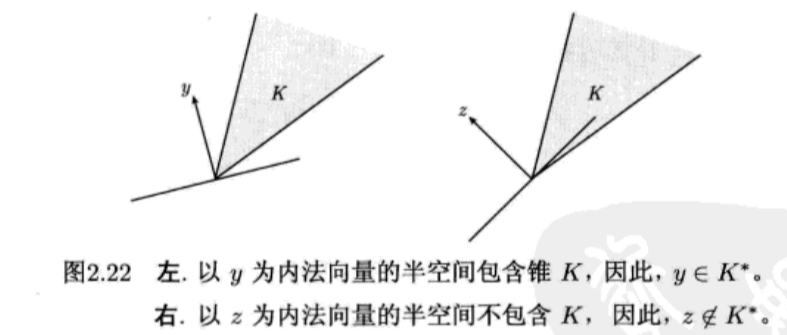
凸优化基础学习——凸集
凸优化基础学习——凸集 文章内容全部来自对Stephen Boyd and Lieven vandenberghe的Convex Optimization的总结归纳。 电子书资源: 链接:https://pan.baidu.com/s/1dP5zI6h3BEyGRzSaJHSodg?pwd0000 提取码:0000 基本概念 仿射集合 **…...

oracle 19c环境常见问题汇总
1、rman备份时会消耗这么多临时表空间 参考MOS: RMAN-08132: Warning: Cannot Update Recovery Area ORA-01652: unable to extend temp segment by 64 in tablespace TEMP (Doc ID 2658437.1) Known RMAN Performance Problems (Doc ID 247611.1) 处理办法&…...

django实现悲观锁乐观锁
前期准备 # 线上卖图书-图书表 图书名字,图书价格,库存字段-订单表: 订单id,订单名字# 表准备class Book(models.Model):name models.CharField(max_length32)price models.IntegerField() #count models.SmallIntegerField…...
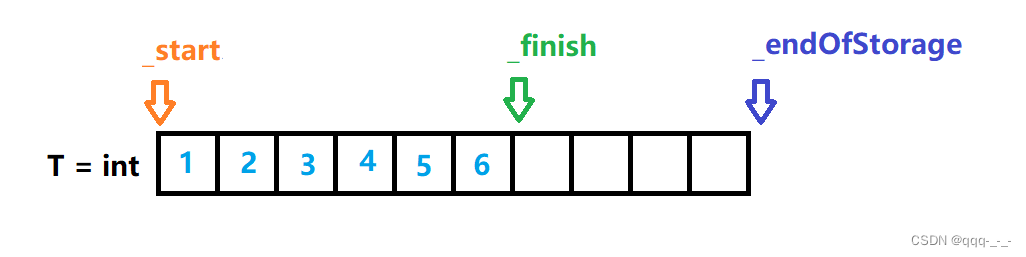
vector【2】模拟实现(超详解哦)
vector 引言(实现概述)接口实现详解默认成员函数构造函数析构函数赋值重载 迭代器容量size与capacityreserveresizeempty 元素访问数据修改inserterasepush_back与pop_backswap 模拟实现源码概览总结 引言(实现概述) 在前面&…...

金融助贷公司怎么获客——大数据获客
2023年已过去大半,整个贷款领域遭遇的现象仍然是拓客难、拓客贵、顾客精确度不高难题。从业者工作压力与日俱增,每日遭遇各种各样考评,因此大家并不是在开发客户便是在开发客户的路上。贷款市场销售艰难变成一个问题,很多贷款营销…...
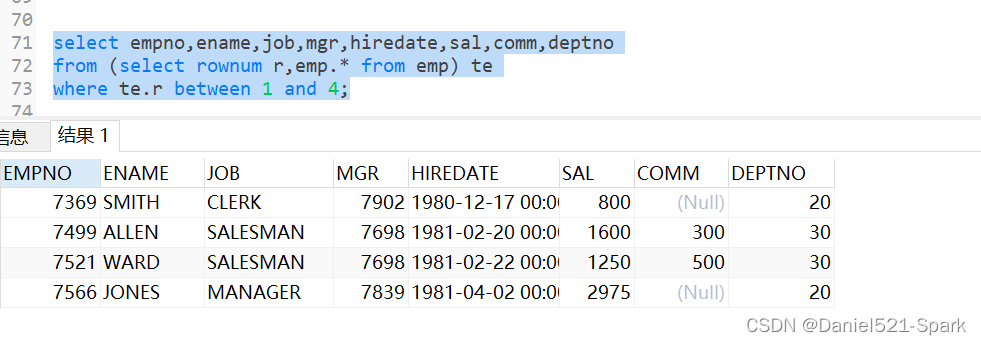
Java进阶-Oracle(二十一)(2)
🌻🌻 目录 一、Oracle 数据库的操作(DDL DML DQL DCL TPL)1.1 标识符、关键字、函数等1.1.1 数值类型:1.1.2 字符串类型:1.1.3 日期类型1.1.4 大的数据类型--适合保存更多的数据 1.2 运算符1.3 函数---预定义函数、自定义函数&…...

SpringCloud实用篇4——MQ RabbitMQ SpringAMQP
目录 1 初识MQ1.1 同步和异步通讯1.1.1 同步通讯1.1.2 异步通讯 1.2 技术对比 2.快速入门2.1 安装RabbitMQ2.1.1 单机部署2.1.2集群部署 2.2 RabbitMQ消息模型2.3.导入Demo工程2.4 入门案例2.4.1 publisher实现2.4.2 consumer实现 3 SpringAMQP3.1 Basic Queue 简单队列模型3.1…...
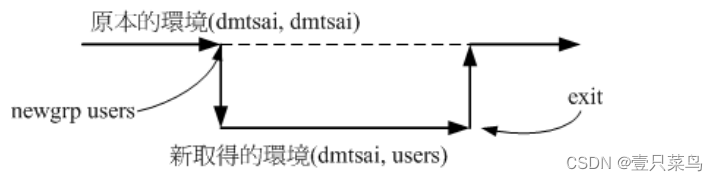
【BASH】回顾与知识点梳理(二十二)
【BASH】回顾与知识点梳理 二十二 二十二. Linux 账号管理22.1 Linux 的账号与群组使用者标识符: UID 与 GID使用者账号/etc/passwd 文件结构/etc/shadow 文件结构 关于群组: 有效与初始群组、groups, newgrp/etc/group 文件结构有效群组(effective grou…...
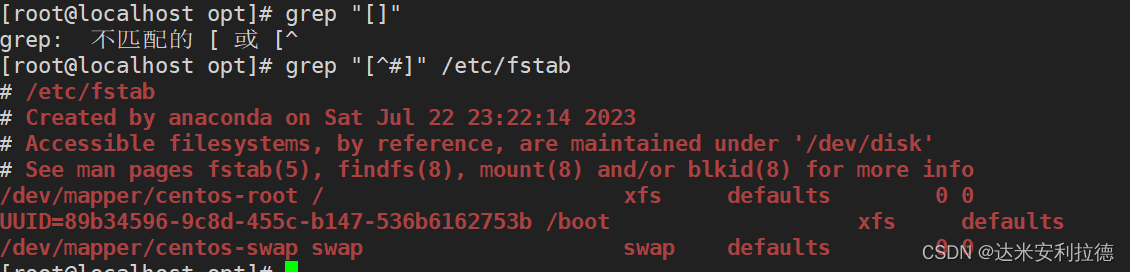
shell脚本之正则表达式
目录 一.常见的管道命令1.1sort命令1.2uniq命令1.3tr命令1.4cut命令1.5实例1.5.1统计当前主机连接状态1.5.2统计当前主机数 二.正则表达式2.1正则表达式的定义2.2常见元字符(支持的工具:find,grep,egrep,sed和awk&…...
将SM2根证书预置到chromium中
最近花了很多精力在做chromium的GmSSL适配,协议和算法都已经完成,这篇文章是关于将SM2根证书预置到chromium中 我的开发测试环境是macos12.4,从chromium的代码和文档中得知证书获取和校验都是通过操作系统以及native api接口完成,…...
linux安装mysql-8.0.33正确方式及常见问题
目录 获取mysql下载地址链接 解压安装包 复制文件到安装目录 添加用户和用户属组修改权限 创建存储数据的文件夹/usr/local/mysql 初始化安装 修改配置文件 创建日志文件并赋予对应权限 启动成功编辑 创建软链接 之前安装过mysql,时间比较长忘记安装步骤了今天…...
Vim的插件管理器之Vundle
1、安装Vundle插件管理器 Vim可以安装插件,但是需要手动安装比较麻烦,Vim本身没有提供插件管理器,所以会有很多的第三方的插件管理器,有一个vim的插件叫做 “vim-easymotion”,在它的github的安装说明里有列出对于不同…...
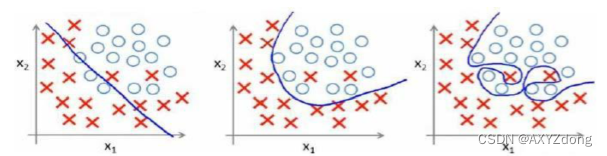
机器学习丨1. 机器学习概述
Author:AXYZdong 硕士在读 工科男 有一点思考,有一点想法,有一点理性! 定个小小目标,努力成为习惯!在最美的年华遇见更好的自己! CSDNAXYZdong,CSDN首发,AXYZdong原创 唯…...
清除pip安装库时的缓存
目录 1、命令清除缓存 2、路径手动清除 在使用pip安装Python库时,如果之前已经下载过该库,pip会默认使用缓存来安装库,而不是重新从网络上下载。缓存文件通常存储在用户目录下的缓存文件夹中,具体位置因操作系统和Python版本而异…...

C++ `dynamic_cast
1. 基础 C类型转换概览为什么需要dynamic_cast 2. dynamic_cast 的使用 基本语法与其他类型转换(如 static_cast、reinterpret_cast 和 const_cast)的对比 3. RTTI (运行时类型信息) 什么是RTTI如何在C中启用和禁用RTTI 4. dynamic_cast 与多态 使用dyna…...

3分钟搞定:Windows免iTunes安装苹果驱动终极指南
3分钟搞定:Windows免iTunes安装苹果驱动终极指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mirrors/…...
)
用树莓派和LED灯带,我亲手搭了个能跑程序的‘图灵机’(附完整代码和接线图)
用树莓派和LED灯带打造实体图灵机:从理论到硬件的沉浸式实践 当计算机科学从抽象的数学公式变成指尖跳动的LED灯光,理论突然有了温度。去年冬天,我在车库工作台前完成了这个项目——用树莓派和LED灯带构建的实体图灵机。当第一个加法程序成功…...

从游戏地图切割到3D模型生成:凸多边形三角剖分在Unity/C++中的实战应用
从游戏地图切割到3D模型生成:凸多边形三角剖分在Unity/C中的实战应用 在游戏开发中,我们经常需要处理复杂的几何形状。无论是为开放世界游戏创建导航网格,还是为3D模型生成优化的三角面片,凸多边形的三角剖分都是核心技能之一。不…...

cp520靶场学习笔记
正文1、端口扫描2、web登录页面用户密码爆破3、文件上传漏洞利用4、nc 反弹5、Linux用户检索与特权分析6、图片隐写7、解密与格式转换8、cp命令横向获取用户密码9、diff命令进行文件比较正文 kali攻击机地址:192.168.1.4 靶场地址:192.168.1.15 1、端口…...

从零封装一个MCP4728的C语言驱动库:支持STM32/HAL库,含EEPROM读写状态处理
构建高可靠MCP4728驱动库:STM32 HAL库实战与EEPROM状态管理 在嵌入式开发中,DAC(数模转换器)是连接数字世界与模拟世界的关键桥梁。MCP4728作为Microchip公司推出的4通道12位I2C接口DAC芯片,凭借其内置EEPROM存储和灵活…...
)
OpenISP 模块拆解 · 第7讲:去马赛克 (CFA)
OpenISP 模块拆解 第7讲:去马赛克 (CFA) 模块作用 CFA 插值也叫 demosaic,是把单通道 Bayer RAW 转成三通道 RGB 的关键模块。每个传感器像素只采集 R/G/B 之一,CFA 要为每个位置估计缺失的两个颜色通道。 openISP 实现 源码类名为 CFA(img,…...

程序员的职场心态:如何应对代码bug和项目延期
在软件研发的全流程中,测试与开发如同孪生兄弟,紧密协作又时常因问题产生摩擦。作为软件测试从业者,我们既是bug的“捕手”,也是项目进度的“监督者”,更需要成为程序员职场心态的“理解者”与“协同者”。深入剖析程序…...

python学习笔记 | 11.2、面向对象高级编程-使用@property
一、先搞懂:我们为什么要用 property? 1. 原始问题 直接给对象赋值,没法检查数据是否合法: class Student:passs Student() s.score 9999 # 成绩不可能是9999,完全不合理!2. 笨办法解决(太麻…...

56、CAN总线RC低通滤波器截止频率计算与实战
CAN总线RC低通滤波器截止频率计算与实战 一、一个让我熬夜三天的CAN通信故障 去年做某车载ECU项目,CAN总线在电机启动瞬间频繁丢帧。示波器抓波形,CAN_H对地毛刺高达8V,持续时间约200ns。团队里有人提议“加磁珠”,有人喊“上共模扼流圈”。我翻出TI的AN-2298应用笔记,发…...