Python学习笔记_基础篇(八)_正则表达式
1. 正则表达式基础
1.1. 简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程:
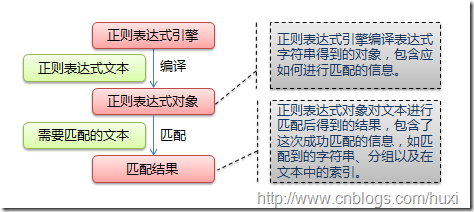
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法:
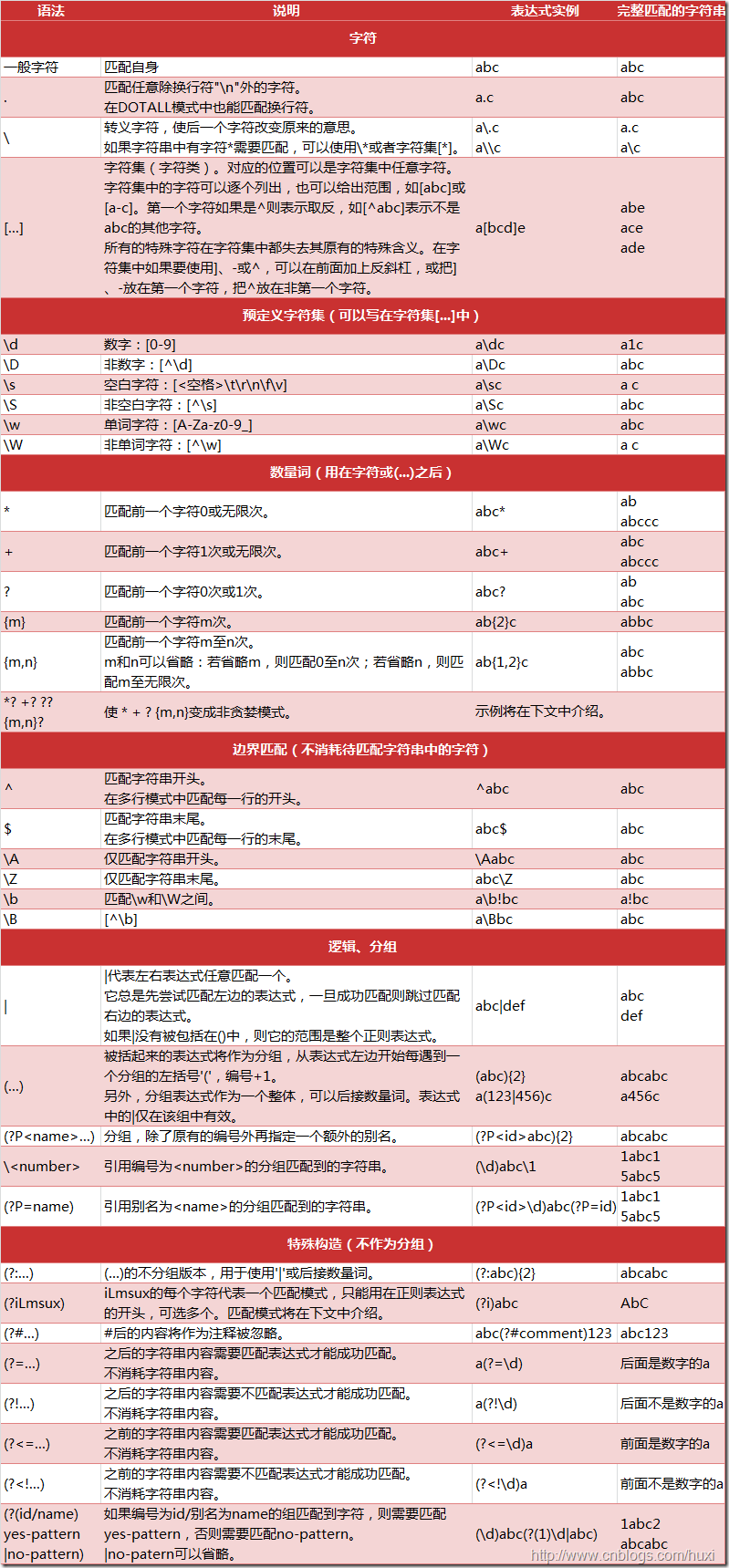
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*“如果用于查找"abbbc”,将找到"abbb"。而如果使用非贪婪的数量词"ab*?“,将找到"a”。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"“作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”“,那么使用编程语言表示的正则表达式里将需要4个反斜杠”\\\“:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r”\“表示。同样,匹配一个数字的”\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
# encoding: UTF-8
import re# 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello')# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match('hello world!')if match:# 使用Match获得分组信息print match.group()### 输出 ###
# hello
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符’|‘表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile(‘pattern’, re.I | re.M)与re.compile(’(?im)pattern’)是等价的。
可选值有:
* re. **I** (re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
* **M** (MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
* **S** (DOTALL): 点任意匹配模式,改变'.'的行为
* **L** (LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
* **U** (UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
* **X** (VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
- string : 匹配时使用的文本。
- re : 匹配时使用的Pattern对象。
- pos : 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos : 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex : 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup : 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
1. **group([group1, …]):**
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
2. groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
3. **groupdict([default]):
** 返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
4. start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
5. **end([group]):
** 返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
6. **span([group]):
** 返回(start(group), end(group))。
# match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回Nonematch(pattern, string, flags=0)# pattern: 正则模型# string : 要匹配的字符串# falgs : 匹配模式X VERBOSE Ignore whitespace and comments for nicer looking RE's.I IGNORECASE Perform case-insensitive matching.M MULTILINE "^" matches the beginning of lines (after a newline)as well as the string."$" matches the end of lines (before a newline) as wellas the end of the string.S DOTALL "." matches any character at all, including the newline.A ASCII For string patterns, make \w, \W, \b, \B, \d, \Dmatch the corresponding ASCII character categories(rather than the whole Unicode categories, which is thedefault).For bytes patterns, this flag is the only availablebehaviour and needn't be specified.L LOCALE Make \w, \W, \b, \B, dependent on the current locale.U UNICODE For compatibility only. Ignored for string patterns (itis the default), and forbidden for bytes patterns.


# 无分组r = re.match("h\w+", origin)print(r.group()) # 获取匹配到的所有结果print(r.groups()) # 获取模型中匹配到的分组结果print(r.groupdict()) # 获取模型中匹配到的分组结果# 有分组# 为何要有分组?提取匹配成功的指定内容(先匹配成功全部正则,再匹配成功的局部内容提取出来)r = re.match("h(\w+).*(?P<name>\d)$", origin)print(r.group()) # 获取匹配到的所有结果print(r.groups()) # 获取模型中匹配到的分组结果print(r.groupdict()) # 获取模型中匹配到的分组中所有执行了key的组
demo
**search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
** 这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
# search,浏览整个字符串去匹配第一个,未匹配成功返回None
# search(pattern, string, flags=0)

# 无分组r = re.search("a\w+", origin)print(r.group()) # 获取匹配到的所有结果print(r.groups()) # 获取模型中匹配到的分组结果print(r.groupdict()) # 获取模型中匹配到的分组结果# 有分组r = re.search("a(\w+).*(?P<name>\d)$", origin)print(r.group()) # 获取匹配到的所有结果print(r.groups()) # 获取模型中匹配到的分组结果print(r.groupdict()) # 获取模型中匹配到的分组中所有执行了key的组
demo
**split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
** 按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
# split,根据正则匹配分割字符串split(pattern, string, maxsplit=0, flags=0)
# pattern: 正则模型
# string : 要匹配的字符串
# maxsplit:指定分割个数
# flags : 匹配模式


# 无分组origin = "hello alex bcd alex lge alex acd 19"r = re.split("alex", origin, 1)print(r)# 有分组origin = "hello alex bcd alex lge alex acd 19"r1 = re.split("(alex)", origin, 1)print(r1)r2 = re.split("(al(ex))", origin, 1)print(r2)
demo
**findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
** 搜索string,以列表形式返回全部能匹配的子串。
# findall,获取非重复的匹配列表;如果有一个组则以列表形式返回,且每一个匹配均是字符串;如果模型中有多个组,则以列表形式返回,且每一个匹配均是元祖;
# 空的匹配也会包含在结果中
#findall(pattern, string, flags=0)


# 无分组r = re.findall("a\w+",origin)print(r)# 有分组origin = "hello alex bcd abcd lge acd 19"r = re.findall("a((\w*)c)(d)", origin)print(r)
demo
**sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
** 使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
# sub,替换匹配成功的指定位置字符串sub(pattern, repl, string, count=0, flags=0)
# pattern: 正则模型
# repl : 要替换的字符串或可执行对象
# string : 要匹配的字符串
# count : 指定匹配个数
# flags : 匹配模式


# 与分组无关origin = "hello alex bcd alex lge alex acd 19"r = re.sub("a\w+", "999", origin, 2)print(r)
demo
**subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
** 返回 (sub(repl, string[, count]), 替换次数)。
import rep = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'print p.subn(r'\2 \1', s)def func(m):return m.group(1).title() + ' ' + m.group(2).title()print p.subn(func, s)### output ###
# ('say i, world hello!', 2)
# ('I Say, Hello World!', 2)
相关文章:
Python学习笔记_基础篇(八)_正则表达式
1. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则…...
)
【洛谷 P5736】【深基7.例2】质数筛 题解(判断质数)
【深基7.例2】质数筛 题目描述 输入 n n n 个不大于 1 0 5 10^5 105 的正整数。要求全部储存在数组中,去除掉不是质数的数字,依次输出剩余的质数。 输入格式 第一行输入一个正整数 n n n,表示整数个数。 第二行输入 n n n 个正整数 …...
C语言好题解析(一)
目录 选择题1选择题2选择题3选择题4编程题一 选择题1 执行下面程序,正确的输出是( )int x 5, y 7; void swap() {int z;z x;x y;y z; } int main() {int x 3, y 8;swap();printf("%d,%d\n",x, y);return 0; }A: 5,7 B: …...
uniapp微信小程序区分正式版,开发版,体验版
小程序代码区分是正式版,开发版,还是体验版 通常正式和开发环境需要调用不同域名接口,发布时需要手动更换 或者有些东西不想在正式版显示,只在开发版体验版中显示,也需要去手动隐藏 官方没有明确给出判断环境的方法&a…...
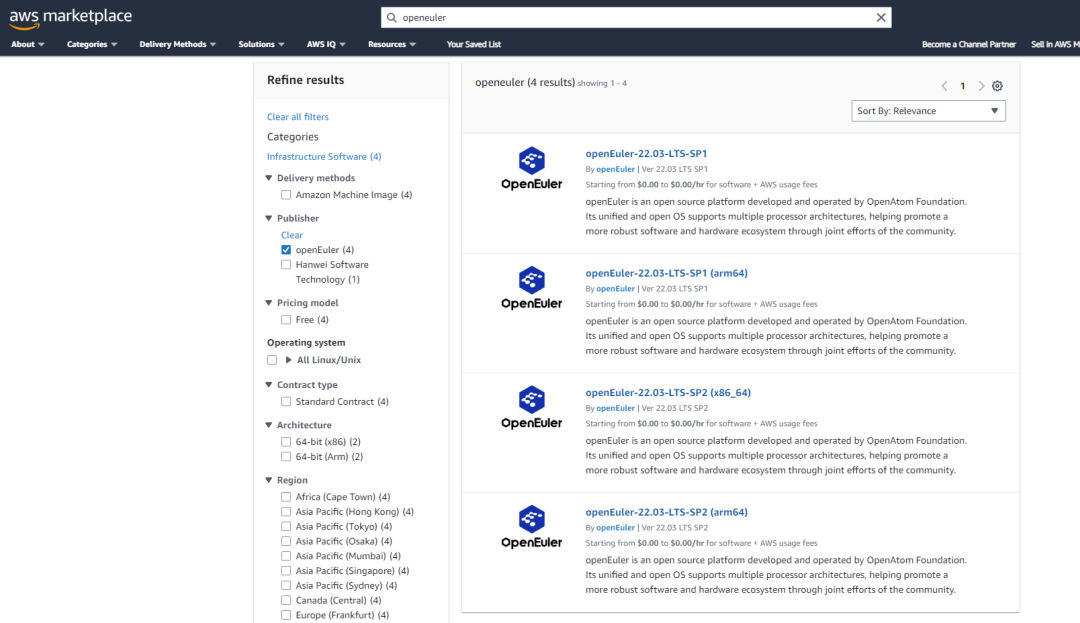
更多openEuler镜像加入AWS Marketplace!
自2023年7月openEuler 22.03 LTS SP1正式登陆AWS Marketplace后,openEuler社区一直持续于在AWS上提供更多版本。 目前,openEuler22.03 LTS SP1 ,SP2两个版本及 x86 arm64两种架构的四个镜像均可通过AWS对外提供,且在亚太及欧洲15个Region开放…...
)
【BASH】回顾与知识点梳理(二十四)
【BASH】回顾与知识点梳理 二十四 二十四. 权限规划和身份切换24.1 主机的细部权限规划:ACL 的使用什么是 ACL 与如何支持启动 ACL如何启动 ACL 24.2 ACL 的设定技巧: getfacl, setfaclsetfacl 指令用法介绍及最简单的『 u:账号:权限 』设定getfacl 指令…...
CSRF
CSRF CSRF,跨站域请求伪造,通常攻击者会伪造一个场景(例如一条链接),来诱使用户点击,用户一旦点击,黑客的攻击目的也就达到了,他可以盗用你的身份,以你的名义发送恶意请…...
pyscenic分析:视频教程
我们之前更新过pyscenic的教程:pySCENIC单细胞转录因子分析更新:数据库、软件更新。我们也说过,我们号是放弃R语言版的SCENIC的分析了,因为它比较耗费计算资源和时间,所以我们的单细胞转录因子分析教程都是基于pysceni…...
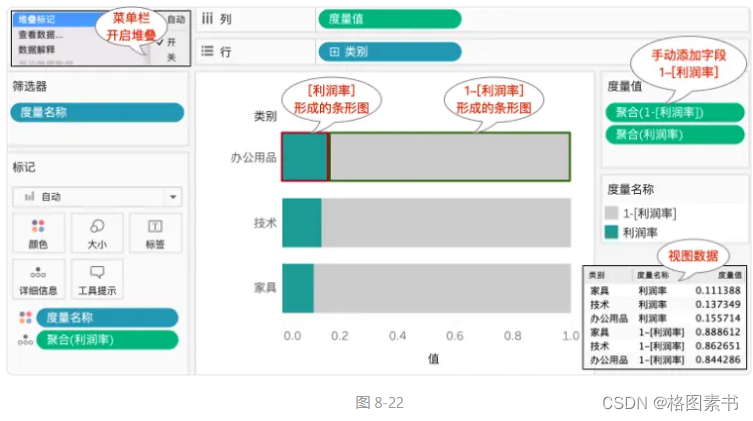
可视化绘图技巧100篇进阶篇(九)-三维百分比堆积条形图(3D Stacked Percentage Bar Chart)
目录 前言 适用场景 绘图工具及代码实现 帆软 实现思路 方案一:使用计算指标 上传数据 添加组件 生成图表 添加计算字段 生成分区柱形图 生成百分比堆积条形图 美化图表 设置标签 设置颜色 效果查看 PC 端 移动端 方案二:使用自助数…...

js实现将文本转PDF格式并下载到本地
html里面需要引入jspdf.umd.min.js和FileSaver.js jspdf.umd.min.js:https://www.npmjs.com/package/jspdf FileSaver.js:https://download.csdn.net/download/weixin_45791806/87272893?spm1001.2014.3001.5503 同时项目的根部目录也需要引入SimHei.tt…...

Servlet+JDBC实战开发书店项目讲解第四篇:登录实现
ServletJDBC 实战开发书店项目讲解第四篇:登录注册实现 在本篇博客中,我们将继续讲解 ServletJDBC 实战开发书店项目。这次我们将重点讲解如何实现登录和注册功能。 1. 创建数据库表 首先,我们需要在数据库中创建两个表,一个用…...

HarmonyOS NEXT新能力,一站式高效开发HarmonyOS应用
2023年8月6日华为开发者大会2023(HDC.Together)圆满收官,伴随着HarmonyOS 4的发布,华为向开发者发布了汇聚所有最新开发能力的HarmonyOS NEXT开发者预览版,并分享了围绕“一次开发,多端部署” “可分可合&a…...
【Java从0到1学习】09 正则表达式
1. 正则表达式概述 在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。 正则表达式,又称正规表示法、常规表示法ÿ…...
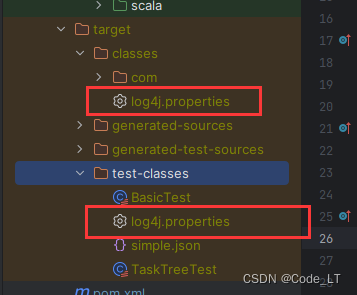
log4j:WARN No appenders could be found for logger问题
本文将idea场景下的使用。 IDEA中,将配置文件命名为log4j.properties(该命名才会被自动加载), 并放到某个目录下(通常放到resources目录),并在resources上右键,找到Mark Directory a…...

【Java】批量生成条形码-itextpdf
批量生成条形码 Controller ApiOperation("商品一览批量生成商品条形码")PostMapping("/batchGenerateProdBarCode")public void batchGenerateProdBarCode(RequestBody ProductListCondition productListCondition,HttpServletResponse response){import…...

SpringBoot登录、退出、获取用户信息的session处理
1、登录方法:login PostMapping("/user/login")public ResponseVo<User> login(Valid RequestBody UserLoginForm userLoginForm,HttpSession session) {ResponseVo<User> userResponseVo userService.login(userLoginForm.getUsername(), …...

【软件测试】随笔系统测试报告
博主简介:想进大厂的打工人博主主页:xyk:所属专栏: 软件测试 随笔系统采用 SSM 框架前后端分离的方法实现,本文主要针对功能:登录,注册,注销,写随笔,删除随笔,随笔详情页…...

vue中使用html2canvas+jsPDF实现pdf的导出
导入依赖 html2canvas依赖 npm install html2canvasjspdf依赖 npm install jspdfpdf导出 以导出横向,A4大小的pdf为例 规律:1. html2canvas 中,在保持jsPDF中的宽高不变的情况下,设置html2canvas中的 width 和 height 值越小&a…...

Linux学习之firewallD
systemctl status firewalld.service查看一下firewalld服务的状态,发现状态是inactive (dead)。 systemctl start firewalld.service启动firewalld,systemctl status firewalld.service查看一下firewalld服务的状态,发现状态是active (runni…...

【JS学习】Object.assign 用法介绍
Object.assign 是ES6中的一个方法。该方法能够实现对象的浅复制以及对象合并。Object.assign 并不会修改目标对象本身,而是返回一个新的对象,其中包含了所有源对象的属性。 例1 2个对象合并 const target { a: 1, b: 2 }; const source { b: 3, c: 4…...

LangChain4j-examples:基于Java的AI智能体工作流编排深度解析与实践指南
LangChain4j-examples:基于Java的AI智能体工作流编排深度解析与实践指南 【免费下载链接】langchain4j-examples 项目地址: https://gitcode.com/GitHub_Trending/la/langchain4j-examples LangChain4j-examples是一个面向Java开发者的AI智能体工作流编排框…...

OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具
OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑…...

Nginx、Tengine、OpenRestry的http和tcp后端健康检查【20260520-003篇】
文章目录 一、Nginx 开源版(无第三方模块) 1. 被动健康检查(内置,默认) TCP 后端(stream 四层) HTTP 后端(http 七层) 2. Nginx + 第三方模块(主动检查) 编译 Nginx 加模块 HTTP 主动检查 TCP 主动检查 二、Tengine(原生带主动检查) HTTP 健康检查 TCP 健康检查 查…...

如何一键清理Windows冗余驱动:Driver Store Explorer完全指南
如何一键清理Windows冗余驱动:Driver Store Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否发现C盘空间不知不觉就满了?Windows系统在C:…...

从Verilog到GDS:用Calibre nmLVS-H模式搞定复杂芯片的层级化物理验证
从Verilog到GDS:用Calibre nmLVS-H模式搞定复杂芯片的层级化物理验证 在当今超大规模集成电路设计中,物理验证已成为确保芯片功能正确的最后一道防线。随着工艺节点不断微缩,设计复杂度呈指数级增长,传统的扁平化验证方法已难以应…...

歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程
歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬(LRC Maker)是…...
)
告别Visio!用WPF+MVVM打造属于你自己的业务流程设计器(附完整源码)
基于WPFMVVM构建企业级业务流程设计器的实战指南 在当今企业数字化转型浪潮中,业务流程管理系统(BPM)已成为提升运营效率的核心工具。传统Visio等绘图工具虽然功能强大,但往往难以与企业内部系统深度集成,且缺乏动态交互能力。本文将带你从零…...

使用Taotoken聚合端点一个月,我的API调用延迟与稳定性观察记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken聚合端点一个月,我的API调用延迟与稳定性观察记录 1. 项目背景与接入动机 我最近的一个个人项目需要持续…...

告别重影和误检:手把手教你为Apollo 7.0激光雷达数据做运动补偿
激光雷达运动补偿实战:解决Apollo 7.0中的点云畸变问题 当自动驾驶车辆以72km/h的速度行驶时,激光雷达每采集一帧点云的100毫秒内,车辆已经移动了2米。这个看似微小的位移,却会导致点云中出现车辆"分身"、建筑物扭曲等诡…...
:解锁摄像头与雷达融合的3D感知新范式)
跨域空间匹配(CDSM):解锁摄像头与雷达融合的3D感知新范式
1. 为什么自动驾驶需要跨域空间匹配技术 当你坐在一辆自动驾驶汽车里,最不希望看到的就是系统把前方停着的卡车误判成广告牌。这种错误在单一传感器系统中其实很常见——摄像头可能因为逆光看不清物体轮廓,雷达又难以识别物体的具体形状。这就是为什么我…...