Spring Data Elasticsearch 的简单使用
目录
一、简介
二、配置
三、映射
四、 常用方法
五、操作(重点)
1、对索引表的操作
2、对文档的操作(重点)
(1)、添加文档
(2)、删除文档
(3)、查询文档(重点)
查询全部文档 (两种方式)
matchQuery根据关键字拆分进行全局搜索
matchPhraseQuery短语搜索--完整搜索
rangeQuery范围搜索
termQuery精确搜索
boolQuery()复合查询
withPageable分页查询
withSorts对结果进行排序
高亮查询
一、简介
springData 操作ES类似于Mybatis-plus操作Mysql,都是简单易用
本博客基于springboot2最新方式操作 Elasticsearch7.12.1
二、配置
采用gradle构建 (maven构建一直失败)
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'
最新的yml配置
spring:elasticsearch:uris: http://101.201.209.14:9200三、映射
映射pojo
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName ="people_index") // 索引名字
public class People {@Id private String id; // Keyword类型不被分词索引 类型 分词器@Field(type = FieldType.Text,analyzer = "ik_max_word")private String name; @Field(type = FieldType.Text,analyzer = "ik_max_word")private String address; // index = false 不建立分词索引 @Field(type = FieldType.Long,index = true)private int age;
}
根据pojo创建索引
@SpringBootTestclass
EsDemo1ApplicationTests {// 直接注入使用@Autowired ElasticsearchRestTemplate elasticsearchTemplate; @Testvoid esTest(){// 创建索引 IndexOperations indexOperations = elasticsearchTemplate.indexOps(People.class); if(!indexOperations.exists()) { // 当前索引不存在boolean result1 =indexOperations.create();// 只是创建索引 。mappings没有映射boolean result2 = indexOperations.putMapping();// 映射属性 System.out.println("创建结果:" + ",映射结果:" + result2);}else {System.out.println("文档已存在");}
}验证索引表是否创建成功
GET people_index/_mapping
四、 常用方法
ElasticsearchRestTemplate 常用方法
1、save :保存或者更新文档
elasticsearchRestTemplate.save(object);2、index: 保存或更新文档数据到指定索引和类型中
IndexQuery indexQuery = new IndexQueryBuilder().withObject(object).build();
elasticsearchRestTemplate.index(indexQuery, IndexCoordinates.of(indexName));3、get: 根据文档 ID 获取文档数据。
elasticsearchRestTemplate.get(id, DocumentClass.class);4、update: 更新指定文档的数据。
UpdateQuery updateQuery = new UpdateQueryBuilder().withId(id).withObject(updatedObject).build();
elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of(indexName));5、delete: 删除指定文档。
elasticsearchRestTemplate.delete(id, IndexCoordinates.of(indexName));6、exists: 判断指定文档是否存在。
elasticsearchRestTemplate.exists(id, IndexCoordinates.of(indexName));7、search: 执行搜索操作,使用 Query 条件进行搜索。
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("field", "value")).build();
List<DocumentClass> resultList = elasticsearchRestTemplate.search(searchQuery, DocumentClass.class, IndexCoordinates.of(indexName));8、count: 计算满足指定条件的文档数量。
NativeSearchQuery countQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("field", "value")).build();
long count = elasticsearchRestTemplate.count(countQuery, IndexCoordinates.of(indexName));IndexOperations 常用方法
1、create():创建索引。如果索引已存在,则会抛出异常。2、delete():删除索引。如果索引不存在,则会抛出异常。3、exists():检查索引是否存在。4、putMapping():为索引设置映射。MappingContext 是 Spring Data Elasticsearch 提供的用于获取实体类映射信息的接口。5、refresh():刷新索引,使之可搜索最新添加的文档。在索引文档后,需要调用 refresh() 方法才能保证文档可以被搜索到。6、getIndexSettings():获取索引的配置信息。7、getAliases():获取索引的别名信息。8、addAlias(AliasQuery aliasQuery):添加别名。9、removeAlias(AliasQuery aliasQuery):移除别名。10、getSettings():获取索引的详细配置信息。11、updateSettings(UpdateSettingsRequest request):更新索引的配置信息。其实真正常用的也就是
保存/修改文档
elasticsearchRestTemplate.save()
查询文档
elasticsearchRestTemplate.search()
以及NativeSearchQuery 搜索对象
五、操作(重点)
1、对索引表的操作
对索引表的操作常用的也就是,创建/修改、删除
创建就是上面提到的映射
删除索引表:
@Test
void esTest2(){IndexOperations indexOperations = elasticsearchTemplate.indexOps(People.class); boolean delete = indexOperations.delete(); // 删除索引 System.out.println("删除索引:"+delete);}2、对文档的操作(重点)
对于ES来说,索引就是表,文档就是数据
(1)、添加文档
添加一条
// 添加文档
@Test
void esTest3(){People people=new People(); people.setId("1232"); people.setName("张三"); people.setAge(32); // 保存文档--save 根据文档id修改或者创建文档 People save = elasticsearchTemplate.save(people); }批量添加
// 批量添加
@Test
void esTest4(){List<People> list= Arrays.asList(new People("1","李四","长沙",23), new People("2","李四","长沙",23), new People("3","李四","长沙",23), new People("4","李四","长沙",23)); Iterable<People> save1 = elasticsearchTemplate.save(list); System.out.println("数据"+save1);}检查是否添加完成
GET people_index/_search
(2)、删除文档
// 删除操作
@Test
void esTest5(){// id // 对应索引库
String delete = elasticsearchTemplate.delete("1", People.class);
}除了根据id删除文档外,还可以根据条件删除文档,请类比下面的查询操作
(3)、查询文档(重点)
matchQuery按关键字查询(关键字也会被拆分),示例
@Test
void query(){// 创建查询 字段--索引 NativeSearchQuery searchQuery=new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("address", "太阳")).build(); // // 查询 SearchHits<People> search1 = elasticsearchTemplate.search(searchQuery, People.class); search1.forEach(System.out::println);
}查询全部文档 (两种方式)
// 第一种 ,不加查询条件
@Test
void query(){ // 查询--全部文档SearchHits<People> search1 = elasticsearchTemplate.search(new NativeSearchQueryBuilder().build(), People.class); search1.forEach(System.out::println);}// 第二种
// 查询全部
//matchAllQuery
@Test
void query3(){// 创建查询 字段--索引 NativeSearchQuery searchQuery=new NativeSearchQueryBuilder()// 根据关键字进行全局模糊搜索 .withQuery(QueryBuilders.matchAllQuery()) .build(); // 查询 SearchHits<People> search1 = elasticsearchTemplate.search(searchQuery,People.class); search1.forEach(System.out::println);}matchQuery根据关键字拆分进行全局搜索
@Test
void query1(){// 创建查询 字段--索引 NativeSearchQuery searchQuery=new NativeSearchQueryBuilder()// 根据关键字进行全局模糊搜索 .withQuery(QueryBuilders.matchQuery("李四")) // "李四"会被拆分成关键字进行搜索 .build(); // 查询 SearchHits<People> search1 = elasticsearchTemplate.search(searchQuery,People.class); search1.forEach(System.out::println);
}matchPhraseQuery短语搜索--完整搜索
不会对关键字的拆分搜索
// 短语搜索
@Test
void query4(){// 创建查询 字段--索引 NativeSearchQuery searchQuery=new NativeSearchQueryBuilder()// 根据关键字进行全局模糊搜索 .withQuery(QueryBuilders.matchPhraseQuery("address","长沙市")) // “长沙市” 不会进行拆分.build(); // 查询 SearchHits<People> search1 = elasticsearchTemplate.search(searchQuery,People.class); search1.forEach(System.out::println);}// 解释下什么是短语搜索比如查询 "小明爱吃葡萄"普通关键字查找(matchQuery),这句查找关键字会被拆分成 "小明","爱吃","葡萄" 等,查出的结果满足一个关键字即可,即查出来的结果可能会出现 "小明爱吃香蕉"短语搜索出来的结果 就是以"小明爱吃葡萄"为关键字去搜索,不会对关键字再进行拆分rangeQuery范围搜索
适用于数值类型
// 范围搜索
@Test
void query5(){// 创建查询 字段--索引 NativeSearchQuery searchQuery=new NativeSearchQueryBuilder()// 根据关键字进行全局模糊搜索 lte <= gte >= .withQuery(QueryBuilders.rangeQuery("age").gte(10).lte(20)) .build(); // 查询 SearchHits<People> search1 = elasticsearchTemplate.search(searchQuery,People.class); search1.forEach(System.out::println);
}termQuery精确搜索
注意: 对于text类型且使用的ik分词的字段而言, termQuery的作用和matchPhraseQuery 类似,所以termQuery 适用于keyword类型的字段和数值类型的字段
// 精确搜索
@Test
void query6(){// 创建查询 字段--索引 NativeSearchQuery searchQuery=new NativeSearchQueryBuilder()// 根据关键字进行全局模糊搜索 lte <= gte >= .withQuery(QueryBuilders.termQuery("age",15)).build(); // 查询 SearchHits<People> search1 = elasticsearchTemplate.search(searchQuery,People.class); search1.forEach(System.out::println);}boolQuery()复合查询
对于优先级别问题 使用多个must 来处理
// 复合查询
@Test
void query7(){// 创建查询 字段--索引 NativeSearchQuery searchQuery=new NativeSearchQueryBuilder()// boolQuery 符合查询,must必须 should 或者 // name=李四 ||age>=30 // QueryBuilders.boolQuery().should(QueryBuilders.termQuery("name","李四")).should(QueryBuilders.rangeQuery("age").gte(30)) // name=李四 && age>=30 // QueryBuilders.boolQuery().must(QueryBuilders.termQuery("name","李四")).must(QueryBuilders.rangeQuery("age").gte(30)) // (name=李四 || age>=25) && age <=30 使用must 处理优先级问题 .withQuery(QueryBuilders.boolQuery().must(QueryBuilders.boolQuery().should(QueryBuilders.termQuery("name","李四")).should(QueryBuilders.rangeQuery("age").gte(25))).must(QueryBuilders.rangeQuery("age").lte(30))).build(); // 查询 SearchHits<People> search1 = elasticsearchTemplate.search(searchQuery,People.class); search1.forEach(System.out::println);}withPageable分页查询
需要对查询结果进行封装
@Test
void query8() throws JsonProcessingException {// 创建查询 字段--索引 NativeSearchQuery searchQuery=new NativeSearchQueryBuilder() // 页码(从0开始) 每页条数 .withPageable(PageRequest.of(0,2)).build(); // 查询 SearchHits<People> search = elasticsearchTemplate.search(searchQuery, People.class); // 对查询结果进行封装--Page SearchPage<People> searchHits = SearchHitSupport.searchPageFor(search, searchQuery.getPageable()); System.out.println("当前页码(从0开始):getNumber:"+searchHits.getNumber()); System.out.println("总页数:getTotalPages :"+searchHits.getTotalPages()); System.out.println("每页的最大数据条数:getSize: "+searchHits.getSize()); System.out.println("是否有下一页数据:hasNext: "+searchHits.hasNext()); System.out.println("是否有上一页数据:hasPrevious: "+searchHits.hasPrevious()); System.out.println("当前页数据:getContent: "+searchHits.getContent()); String s = objectMapper.writeValueAsString(searchHits); System.out.println("json:"+s);
}withSorts对结果进行排序
@Test
void query8() throws JsonProcessingException {// 创建查询 字段--索引 NativeSearchQuery searchQuery=new NativeSearchQueryBuilder()// 查询全部 .withQuery(QueryBuilders.matchAllQuery())// 根据 age 字段进行从大到小排序 // 字段 排序规则.withSorts(SortBuilders.fieldSort("age").order(SortOrder.DESC)).build(); // 查询 SearchHits<People> search = elasticsearchTemplate.search(searchQuery, People.class); search.forEach(System.out::println);}高亮查询
把查询结果的关键字进行高亮处理
// 高亮查询
@Test
void query9() throws JsonProcessingException {// 创建查询 字段--索引 // 创建高亮设置 HighlightBuilder highlightBuilder=new HighlightBuilder(); // 设置高亮的结果字段 结果前面添加内容 后续添加内容 highlightBuilder.field("address").preTags("<span style=\"color:red\">").postTags("</span>"); highlightBuilder.field("name").preTags("<span style=\"color:red\">").postTags("</span>"); NativeSearchQuery searchQuery=new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("address","长沙"))// 处理高亮 .withHighlightBuilder(highlightBuilder).build(); // 查询 SearchHits<People> search = elasticsearchTemplate.search(searchQuery, People.class); // 查询结果为SearchHits --SearchHit为封装的单个数据,高亮数据在highlightFields 中 List<SearchHit<People>> searchHits = search.getSearchHits(); searchHits.forEach(System.out::println);
}相关文章:

Spring Data Elasticsearch 的简单使用
目录 一、简介 二、配置 三、映射 四、 常用方法 五、操作(重点) 1、对索引表的操作 2、对文档的操作(重点) (1)、添加文档 (2)、删除文档 (3)、查询…...

2024」预备研究生mem-角平分线定理中线定理垂线定理、射影定理
一、角平分线定理 二、中线定理 三、垂线定理、射影定理 垂线定理 射影定理: 四、课后题...

nginx部署时http接口正常,ws接口404
可以这么配置 map $http_upgrade $connection_upgrade {default upgrade; close; }upstream wsbackend{server ip1:port1;server ip2:port2;keepalive 1000; }server {listen 20038;location /{ proxy_http_version 1.1;proxy_pass http://wsbackend;proxy_redirect off;proxy…...
数学建模的概念和学习方法(什么是数学建模)
一、初步认识数学建模 数学建模是将数学方法和技巧应用于实际问题的过程。它涉及使用数学模型来描述和分析现实世界中的现象、系统或过程,并通过数学分析和计算来预测、优化或解决问题。数学建模可以应用于各种领域,包括自然科学、工程、经济学、环境科学…...

ChatGPT在智能安全监测和入侵检测中的应用如何?
ChatGPT在智能安全监测和入侵检测领域具有潜在的应用价值。虽然ChatGPT主要是一个基于自然语言处理的模型,但结合其他技术和领域专业知识,它可以用于生成和分析文本数据,提供实时安全警报、威胁情报等,从而在安全监测和入侵检测方…...
智能数据建模软件DTEmpower 2023R2新版本功能介绍
DTEmpower是由天洑软件自主研发的一款通用的智能数据建模软件,致力于帮助工程师及工科专业学生,利用工业领域中的仿真、试验、测量等各类数据进行挖掘分析,建立高质量的数据模型,实现快速设计评估、实时仿真预测、系统参数预警、设…...

BDA初级分析——认识SQL,认识基础语法
一、认识SQL SQL作为实用技能,热度高、应用广泛 在对数据分析人员的调查中SQL长期作为热度排名第-一的编程语言超过Python和R SQL:易学易用,高效强大的语言 SQL:Structured Query Language 结构化查询语言 SQL:易学…...
Qt应用开发(基础篇)——MDI窗口 QMdiArea QMdiSubWindow
一、前言 QMdiArea类继承于QAbstractScrollArea,QAbstractScrollArea继承于QFrame,是Qt用来显示MDI窗口的部件。 滚屏区域基类 QAbstractScrollAreahttps://blog.csdn.net/u014491932/article/details/132245486 框架类 QFramehttps://blog.csdn.net/u01…...
图片转换成pdf格式?这几种转换格式方法了解一下
图片转换成pdf格式?将图片转换成PDF格式的好处有很多。首先,PDF格式具有通用性,可以在几乎任何设备上查看。其次,PDF格式可以更好地保护文件,防止被篡改或者复制。此外,PDF格式还可以更好地压缩文件大小&am…...

thingsboard编译安装踩坑记录
thingsboard编译安装踩坑记录 一、编译:二、运行 朋友的thingsboard没人维护,要装新的服务器,啥文档也没有,就让参考官网的文档,版本也比较老3.2.2的,拿过来试了试记录下踩坑的地方。 一、编译:…...

汇编语言例子集合
本人早酷爱汇编语言,曾经以自己能直接执行和操作机器码而自豪不已。下面列出一些电脑隐藏角落里的汇编语言例子程序。后续发现整理后会进一步添加完善。 汇编语言在windows上的bmp文件浏览器。 使用win32汇编编写。 下载地址:https://download.csdn.net/…...

强化学习:用Python训练一个简单的机器人
一、介绍 强化学习(RL)是一个令人兴奋的研究领域,它使机器能够通过与环境的交互来学习。在这篇博客中,我们将深入到RL的世界,并探索如何使用Python训练一个简单的机器人。在本文结束时,您将对 RL 概念有基本…...
【Docker】Docker使用之容器技术发展史
🎬 博客主页:博主链接 🎥 本文由 M malloc 原创,首发于 CSDN🙉 🎄 学习专栏推荐:LeetCode刷题集 🏅 欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正࿰…...
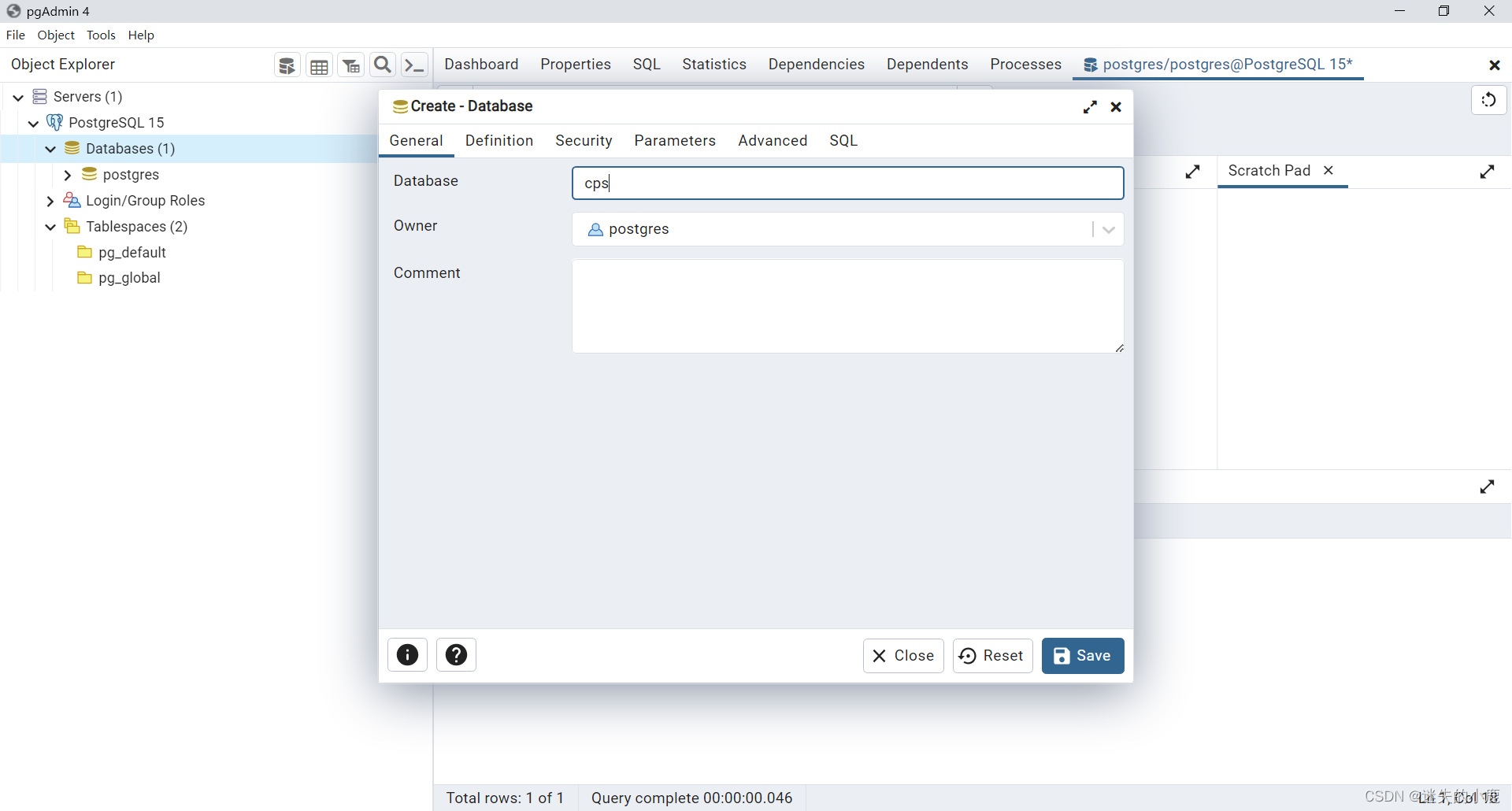
postgresql的在windows下的安装
postgresql的在windows下的安装 下载安装步骤超级用户设置密码本地化设置安装信息安装完成 查看postgresql服务pgAdmin的使用打开命令 行工具查询数据库版本 创建数据库 下载 官网地址 https://www.postgresql.org/ 下载页面 https://www.postgresql.org/download/ windows下…...
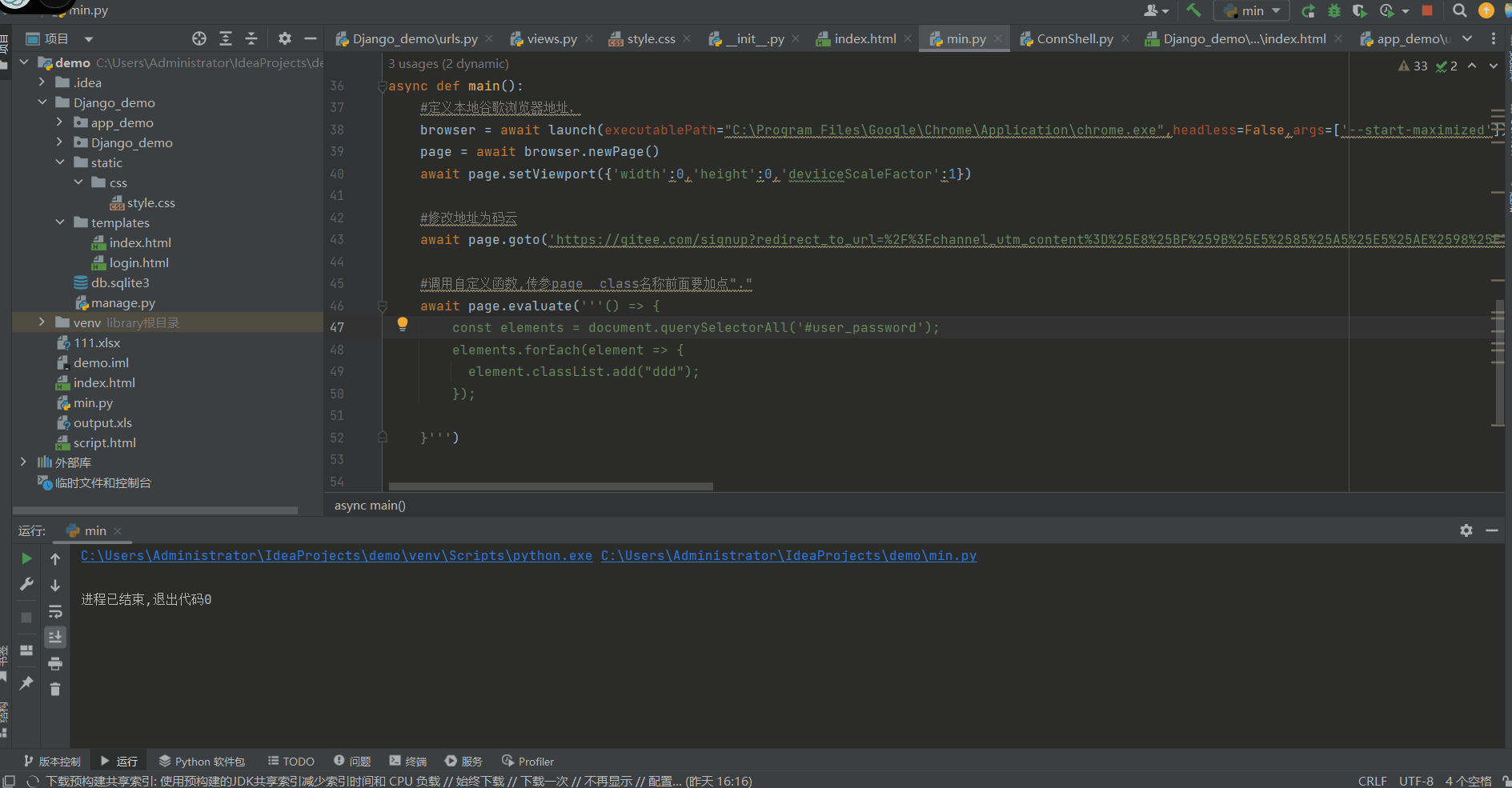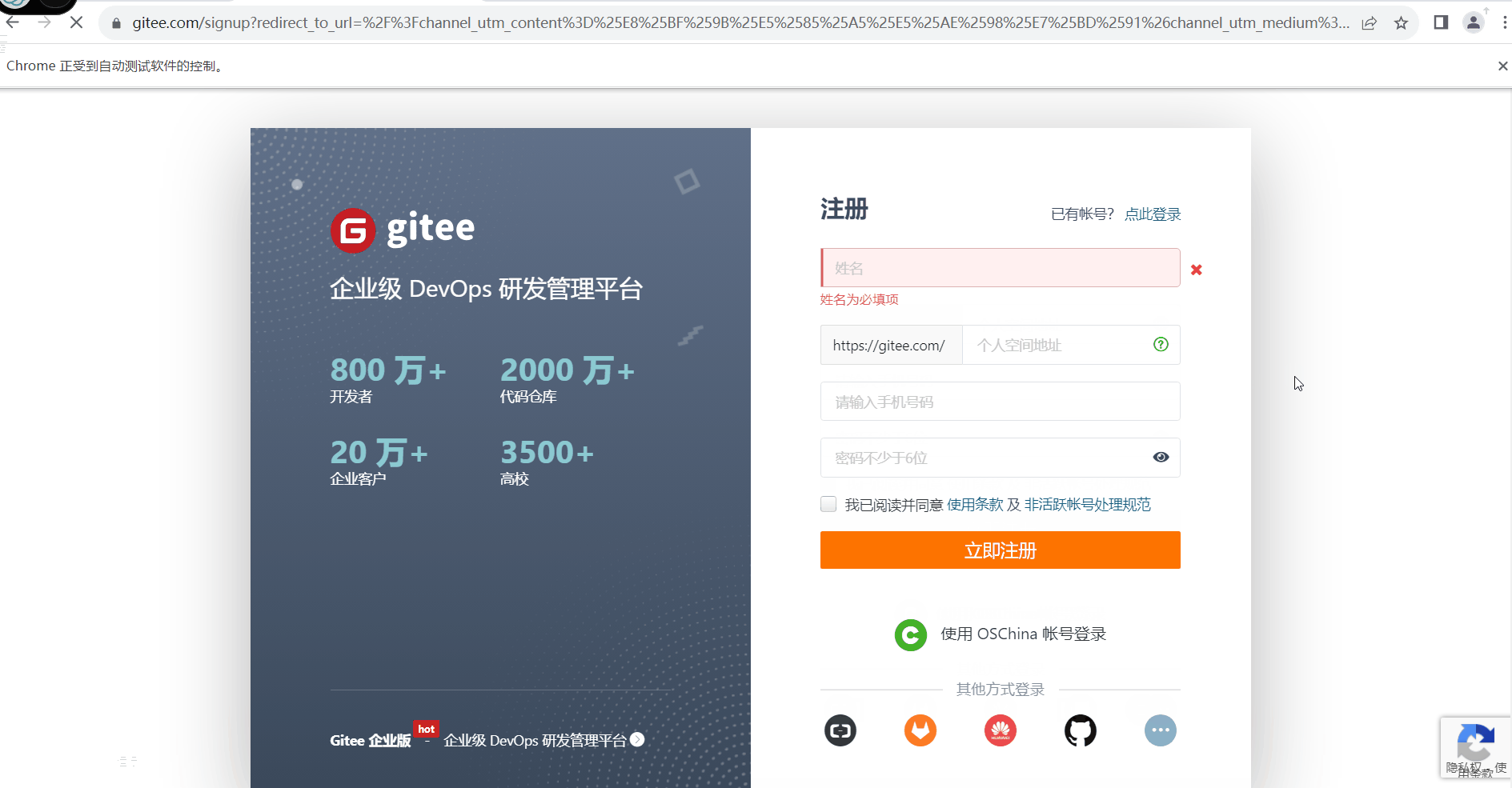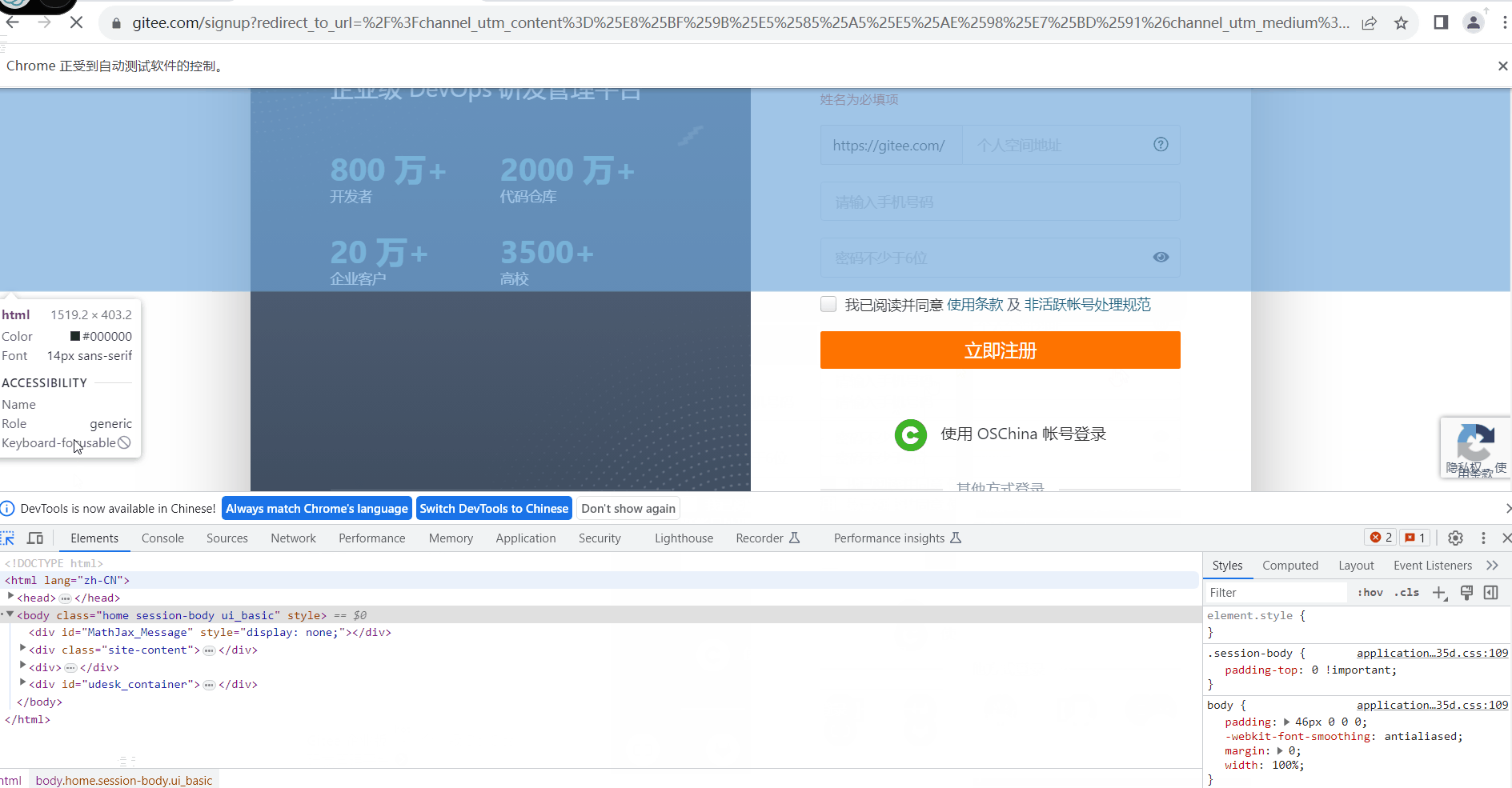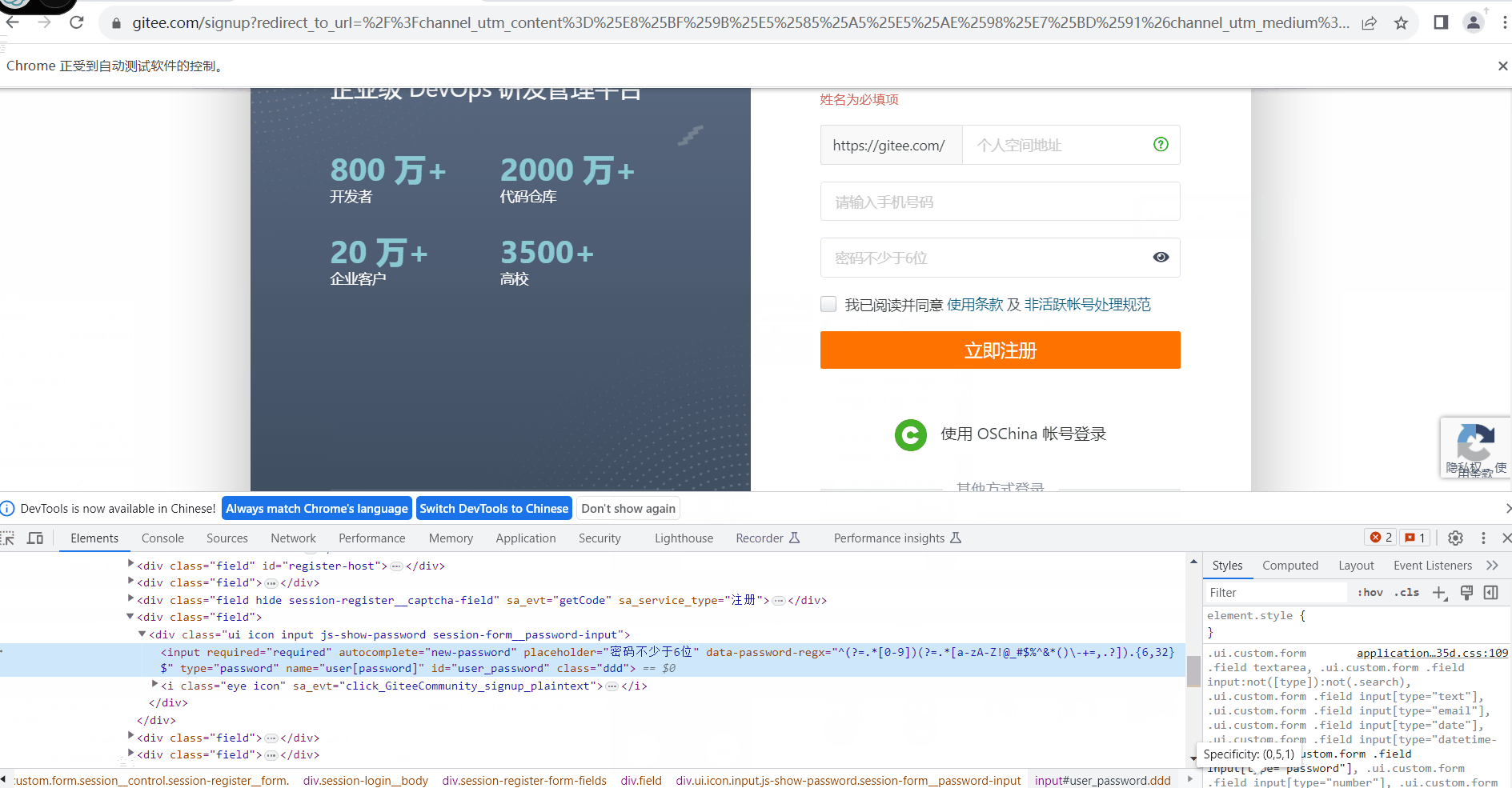
python 自动化学习(四) pyppeteer 浏览器操作自动化
背景 之前我在工作中涉及到了很多地方都是重复性的页面点点点工作,又因为安全保密原则不开放接口和数据库,只有一个页面来提供点击进行操作,就想着用前面学的自动化来实现,但发现前面学的模拟操作对浏览器来说并没有那么友好&…...

P1009 阶乘之和
[NOIP1998 普及组] 阶乘之和 题目描述 用高精度计算出 S 1 ! 2 ! 3 ! ⋯ n ! S 1! 2! 3! \cdots n! S1!2!3!⋯n!( n ≤ 50 n \le 50 n≤50)。 其中 ! 表示阶乘,定义为 n ! n ( n − 1 ) ( n − 2 ) ⋯ 1 n!n\times (n-1)…...
)
Linux内核源码剖析之TCP保活机制(KeepAlive)
写在前面: 版本信息: Linux内核2.6.24(大部分centos、ubuntu应该都在3.1。但是2.6的版本比较稳定,后续版本本质变化也不是很大) ipv4 协议 https://blog.csdn.net/ComplexMaze/article/details/124201088 本文使用案例…...

后端 springboot 给 vue 提供参数
前端 /** 发起新增或修改的请求 */requestAddOrEdit(formData) {debuggerif(formData.id undefined) {formData.id }getAction(/material/getNameModelStandard, {standard: this.model.standard,name: this.model.name,model: this.model.model}).then((res) > {if (res …...

《vue3实战》运用radio单选按钮或Checkbox复选框实现单选多选的试卷制作
文章目录 目录 系列文章目录 1.《Vue3实战》使用axios获取文件数据以及走马灯Element plus的运用 2.《Vue3实战》用路由实现跳转登录、退出登录以及路由全局守护 3.《vue3实战》运用Checkbox复选框实现单选多选的试卷展现(本文) 文章目录 前言 radio是什…...

排序算法-冒泡排序(C语言实现)
简介😀 冒泡排序是一种简单但效率较低的排序算法。它重复地扫描待排序元素列表,比较相邻的两个元素,并将顺序错误的元素交换位置,直到整个列表排序完成。 实现🧐 以下内容为本人原创,经过自己整理得出&am…...

G-Helper:华硕笔记本轻量化控制工具完整指南
G-Helper:华硕笔记本轻量化控制工具完整指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertbook,…...

告别光流计算!用PyTorch复现MotionNet,5分钟搞定视频动作识别
5分钟实现视频动作识别:PyTorch版MotionNet实战指南 在咖啡还没凉透的间隙里,让AI看懂视频动作——这曾是计算机视觉领域最耗时的任务之一。传统双流网络需要预计算光流,像手工制作意大利面般繁琐;而2017年问世的MotionNet就像发…...

RT-Thread Smart用户态开发:基于xmake的嵌入式高性能应用构建实践
1. 项目概述与核心价值最近在嵌入式圈子里,和几位做工业网关和智能设备的朋友聊天,大家普遍有个痛点:项目从单片机往更高性能的处理器(比如Cortex-A系列)迁移时,开发体验有点“开倒车”。在资源受限的单片机…...

数据分析篇---U型关系与与阈值效应
在数据科学、经济学和医学研究中,“U型关系”和“阈值效应”是两种非常经典且重要的非线性模式。它们描述的是变量之间并非简单的“越多越好”的直线关系,而是存在转折点。可以把线性关系想象成匀速开车,而U型和阈值效应则像是开车时遇到的上…...
)
RWKV vs. LLaMA2:在论文审稿任务上,我为什么第一版选了它(以及为什么后来放弃了)
RWKV与LLaMA2在论文审稿任务中的技术选型反思 当面对一个需要处理长文档的AI审稿系统时,模型选型往往成为决定项目成败的关键因素。2023年第三季度,我们在构建论文审稿GPT第一版时,做出了一个在当时看来合理但事后证明值得商榷的决策——选择…...

FanControl风扇控制软件:5分钟快速上手指南,轻松解决电脑噪音与散热难题
FanControl风扇控制软件:5分钟快速上手指南,轻松解决电脑噪音与散热难题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gi…...
选购指南)
来姨妈不舒适有没有补充营养的经期产品推荐?ULOV(最美是你)选购指南
# 来姨妈不舒适有没有补充营养的经期产品推荐?ULOV(最美是你)选购指南来姨妈不舒适有没有补充营养的经期产品推荐?这是14-40岁女性高频搜索的真实困惑。传统红糖水、热饮或普通果汁难以兼顾舒缓不适与科学补养,而市面多…...

FPGA超声波测距项目优化:从50MHz到17kHz时钟分频,聊聊资源与精度的权衡
FPGA超声波测距的时钟优化艺术:从50MHz到17kHz的工程哲学 在资源受限的嵌入式系统中,每一个逻辑单元和存储位都显得弥足珍贵。当我们在Cyclone IV这类中低端FPGA上实现超声波测距功能时,时钟管理策略往往成为决定项目成败的关键因素之一。本文…...

明日方舟自动化助手MAA:3步解放双手,让游戏回归乐趣
明日方舟自动化助手MAA:3步解放双手,让游戏回归乐趣 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: ht…...

AI一键生成微信红包封面系统源码
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 AI微信红包封面生成器源码是一款开源的微信红包封面生成工具,由前腾讯微信后台开发工程师「idoubi」开发并开源。项目名为“AI Cover”,旨在利用人工智能技术为用…...