分布式 - 消息队列Kafka:Kafka 消费者的消费位移
文章目录
- 01. Kafka 分区位移
- 02. Kafka 消费位移
- 03. kafka 消费位移的作用
- 04. Kafka 消费位移的提交
- 05. kafka 消费位移的存储位置
- 06. Kafka 消费位移与消费者提交的位移
- 07. kafka 消费位移的提交时机
- 08. Kafka 维护消费状态跟踪的方法
01. Kafka 分区位移
对于Kafka中的分区而言,它的每条消息都有唯一的offset,用来表示消息在分区中对应的位置。偏移量从0开始,每个新消息的偏移量比前一个消息的偏移量大1。
每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征。分区位移总是从 0 开始,假设一个生产者向一个空分区写入了 10 条消息,那么这 10 条消息的位移依次是 0、1、2、…、9。
02. Kafka 消费位移
对于kafka中的消费者而言,也有一个offset的概念,消费者使用 offset 来表示消费到分区中某个消息所在的位置。
消费位移(偏移量)是指消费者在消费分区中的消息时,记录的已经消费的消息的位移。消费者会定期地将已经消费的消息的位移提交到Kafka集群中,以便在下一次启动时从上次消费的位置继续消费。
每个消费者在消费消息的过程中必然需要有个字段记录它当前消费到了分区的哪个位置上,这个字段就是消费者位移(Consumer Offset)。注意,这和分区位移完全不是一个概念。“分区位移”表征的是分区内的消息位置,它是不变的,即一旦消息被成功写入到一个分区上,它的位移值就是固定的了。而消费者位移则不同,它可能是随时变化的,毕竟它是消费者消费进度的指示器嘛。另外每个消费者有着自己的消费者位移。
03. kafka 消费位移的作用
消费者位移(偏移量)是指消费者在消费分区中的消息时,记录的已经消费的消息的位移。它的作用主要有以下几个方面:
① 消费者可以通过记录偏移量来实现断点续传。当消费者下线或者重启时,它可以通过记录的偏移量来恢复之前的消费状态,从而避免重复消费已经处理过的消息。
② Kafka 通过偏移量来保证消息的顺序性。在同一个分区中,消息的顺序是有序的,消费者可以通过记录偏移量来保证消费的顺序性。
③ Kafka 还可以通过偏移量来实现消息的回溯。消费者可以通过指定偏移量来重新消费之前的消息,这在某些场景下非常有用,比如重新处理之前出现的错误。
总之,Kafka 消息偏移量是非常重要的一个概念,它可以帮助消费者实现断点续传、保证消息的顺序性以及实现消息的回溯等功能。
04. Kafka 消费位移的提交
消费者可以通过订阅一个或多个主题来拉取消息。当消费者调用 poll() 方法时,它会从 Kafka 集群中拉取一批消息,这些消息会被缓存在消费者的本地缓存中,等待消费者进一步处理。在消费者处理完这批消息后,它可以再次调用 poll() 方法来拉取下一批消息。如果消费者在处理消息时发生了错误,那么这批消息将会被重新拉取,直到消费者成功地处理它们为止。
因此每次调用poll()方法,它总是会返回还没有被消费者读取过的记录,这意味着我们可以追踪哪些记录是被群组里的哪个消费者读取过的。要做到这一点,就需要记录上一次消费时的消费位移。并且这个消费位移必须做持久化保存,而不是单单保存在内存中,否则消费者重启之后就无法知晓之前的消费位移。再考虑一种情况,当有新的消费者加入时,那么必然会有再均衡的动作,对于同一分区而言,它可能在再均衡动作之后分配给新的消费者,如果不持久化保存消费位移,那么这个新的消费者也无法知晓之前的消费位移。
在旧消费者客户端中,消费位移是存储在 ZooKeeper 中的。而在新消费者客户端中,消费位移存储在Kafka内部的主题 __consumer_offsets 中。这里把将消费位移存储起来(持久化)的动作称为“提交”,消费者在消费完消息之后需要执行消费位移的提交。
05. kafka 消费位移的存储位置
消费者默认将 offset 保存在Kafka一个内置的 topic 中,该 topic 为 __consumer_offsets。
[root@master01 kafka01]# bin/kafka-topics.sh --zookeeper localhost:2183 --list
__consumer_offsets
消费者会向一个叫作 __consumer_offset 的内置主题发送消息,消息里包含每个分区的偏移量。如果消费者一直处于运行状态,那么偏移量就没有什么实际作用。但是,如果消费者发生崩溃或有新的消费者加入群组,则会触发再均衡。再均衡完成之后,每个消费者可能会被分配新的分区,而不是之前读取的那个。为了能够继续之前的工作,消费者需要读取每个分区最后一次提交的偏移量,然后从偏移量指定的位置继续读取消息。
消费 offset 案例:
① __consumer_offsets 为 Kafka 中的 topic,那就可以通过消费者进行消费。但是需要在配置文件 config/consumer.properties 中添加配置 exclude.internal.topics=false,默认是 true,表示不能消费系统主题。为了查看该系统主题数据,所以该参数修改为 false。
② 创建主题 haha
[root@master01 kafka01]# bin/kafka-topics.sh --zookeeper localhost:2183 --create --partitions 3 --replication-factor 2 --topic haha
Created topic test1.
③ 启动生产者生产数据:
[root@master01 kafka01]# bin/kafka-console-producer.sh --broker-list 10.65.132.2:9093 --topic haha
>hello,haha!
>你好,haha!
>
④ 启动消费者消费数据:
[root@master01 kafka01]# bin/kafka-console-consumer.sh --bootstrap-server 10.65.132.2:9093 --topic haha --group group-haha --from-beginning
hello,haha!
你好,haha!
⑤ 查看消费者消费主题__consumer_offsets:
[root@master01 kafka01]# bin/kafka-console-consumer.sh --bootstrap-server 10.65.132.2:9093 --topic __consumer_offsets --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning# key是[消费者组,消费的主题,消费的分区],value中已经消费的消息在当前分区的offset+1
[group-haha,haha,2]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1692000487851, expireTimestamp=None)
[group-haha,haha,1]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1692000487851, expireTimestamp=None)
[group-haha,haha,0]::OffsetAndMetadata(offset=0, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1692000487851, expireTimestamp=None)
06. Kafka 消费位移与消费者提交的位移
如下图,x 表示某一次拉取操作中此分区消息的最大偏移量,假设当前消费者已经消费了 x 位置的消息,那么我们就可以说消费者的消费位移为 x,不过当前消费者需要提交的消费位移并不是 x,而是 x+1,它表示下一条需要拉取的消息的位置。

如果使用自动提交或不指定提交的偏移量,那么将默认提交poll()返回的最后一个位置之后的偏移量,即提交比客户端从poll()返回的最后一个位置大1的偏移量。在进行手动提交或需要提交特定的偏移量时,一定要记住这一点。
07. kafka 消费位移的提交时机
当前一次 poll() 操作所拉取的消息集为[x+2,x+7],x+2代表上一次提交的消费位移,说明已经完成了x+1之前(包括x+1在内)的所有消息的消费,x+5表示当前正在处理的位置。

① 如果最后一次提交的偏移量大于客户端处理的最后一条消息的偏移量,那么处于两个偏移量之间的消息就会丢失:
如图,如果拉取到消息之后就进行了位移提交,即提交了x+8,那么当前消费x+5的时候遇到了异常,在故障恢复之后,我们重新拉取的消息是从x+8开始的。也就是说,x+5至x+7之间的消息并未能被消费,如此便发生了消息丢失的现象。
② 如果最后一次提交的偏移量小于客户端处理的最后一条消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理:
如图,如果消费完所有拉取到的消息之后才进行位移提交,那么当消费x+5的时候遇到了异常,在故障恢复之后,我们重新拉取的消息是从x+2开始的。也就是说,x+2至x+4之间的消息又重新消费了一遍,故而又发生了重复消费的现象。
08. Kafka 维护消费状态跟踪的方法
在Kafka中,消费者组可以通过消费者偏移量(consumer offset)来跟踪它们在分区中消费的消息。消费者偏移量是一个整数,表示消费者已经成功读取的消息的位置。当消费者读取消息时,它会将偏移量保存在内存中,以便在下一次读取消息时能够从正确的位置开始读取。
相关文章:
分布式 - 消息队列Kafka:Kafka 消费者的消费位移
文章目录 01. Kafka 分区位移02. Kafka 消费位移03. kafka 消费位移的作用04. Kafka 消费位移的提交05. kafka 消费位移的存储位置06. Kafka 消费位移与消费者提交的位移07. kafka 消费位移的提交时机08. Kafka 维护消费状态跟踪的方法 01. Kafka 分区位移 对于Kafka中的分区而…...
H3C QoS打标签和限速配置案例
EF:快速转发 AF:确保转发 CS:给各种协议用的 BE:默认标记(尽力而为) VSR-88-2 出口路由配置: [H3C]dis current-configuration version 7.1.075, ESS 8305 vlan 1 traffic classifier vlan10 operator and if-match a…...

带curl的docker镜像image
带curl的docker镜像,便于k8s中查找问题,确认容器内部是否可用。 用于测试网络的工具,带有curl nslookup等命令 镜像名docker.io/appropriate/curl 测试命令docker run --rm -it docker.io/appropriate/curl /bin/sh 已测试可用 用于测试网…...

Hadoop数据迁移distcp
Hadoop数据迁移distcp 准备工作 确认源集群(a),目标集群(b)确认a集群的主节点和b集群的主节点确认两个集群的网络相通确认迁移模式(全量迁移还是增量迁移),这里选择全量迁移 迁移文件 迁移t…...
QT-Mysql数据库图形化接口
QT sql mysqloper.h qsqlrelationaltablemodelview.h /************************************************************************* 接口描述:Mysql数据库图形化接口 拟制: 接口版本:V1.0 时间:20230727 说明:支…...
LeetCode150道面试经典题-- 合并两个有序链表(简单)
1.题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 2.示例 示例 1: 输入:l1 [1,2,4], l2 [1,3,4] 输出:[1,1,2,3,4,4] 示例 2: 输入:l1 [], l2 [] 输…...
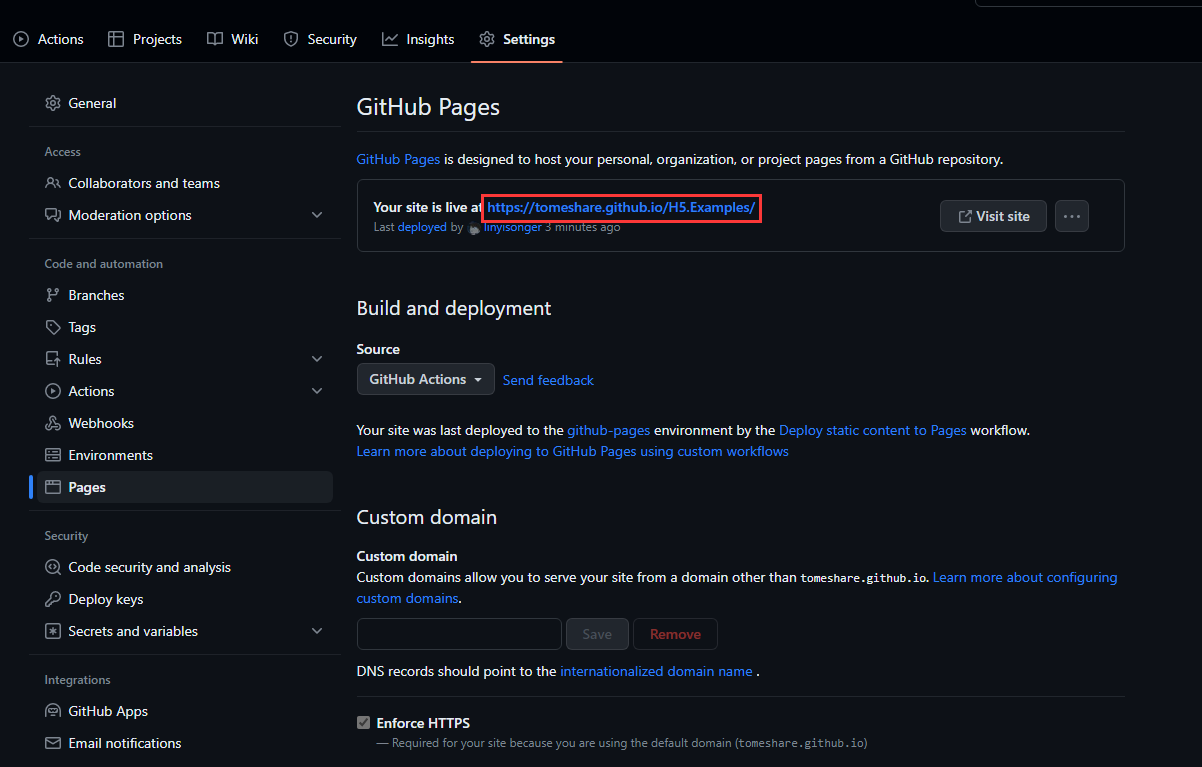
GitHub 如何部署写好的H5静态页面
感谢粉皮zu的私信,又有素材写笔记了。(●’◡’●) 刚好记录一下我示例代码的GitHub部署配置,以便于后期追加仓库。 效果 环境 gitwin 步骤 第一步 新建仓库 第二步 拉取代码 将仓库clone到本地 git clone 地址第三步 部署文件 新建.github\workflo…...
SharkTeam:Worldcoin运营数据及业务安全分析
Worldcoin的白皮书中声明,Worldcoin旨在构建一个连接全球人类的新型数字经济系统,由OpenAI创始人Sam Altman于2020年发起。通过区块链技术在Web3世界中实现更加公平、开放和包容的经济体系,并将所有权赋予每个人。并且希望让全世界每一个人都…...

C语言编程练习
考点:【字符串】【数组】 题目1. 打印X 题目描述 输入一个正整数N, 你需要按样例的方式返回一个字符串列表。 1≤N≤15。 样例 1: 输入:1 输出:[“X”] X样例 2: 输入:2 [“XX”, “XX”] …...
)
vue入门(增查改!)
<template><div><!-- 搜索栏 --><el-card id"search"><el-row><el-col :span"20"><el-input v-model"searchModel.name" placeholder"根据名字查询"></el-input><el-input v-mode…...
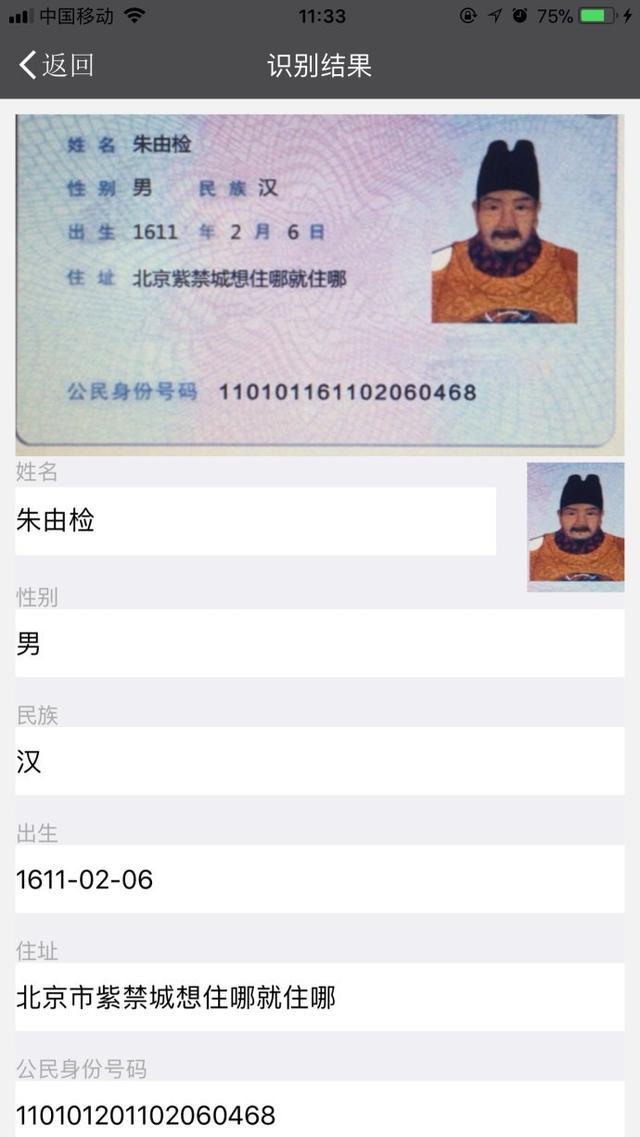
移动端身份证识别技术的应用,告别手动录入证件信息
随着移动互联网的的发展,越来越多的公司都推出了自己的移动APP,这些APP多数都涉及到个人身份证信息的输入认证(即实名认证),如果手动去输入身份证号码和姓名,速度非常慢,且用户体验非常差。为了…...

网络通信原理TCP字段解析(第四十七课)
字段含义Source Port(源端口号)源端口,标识哪...
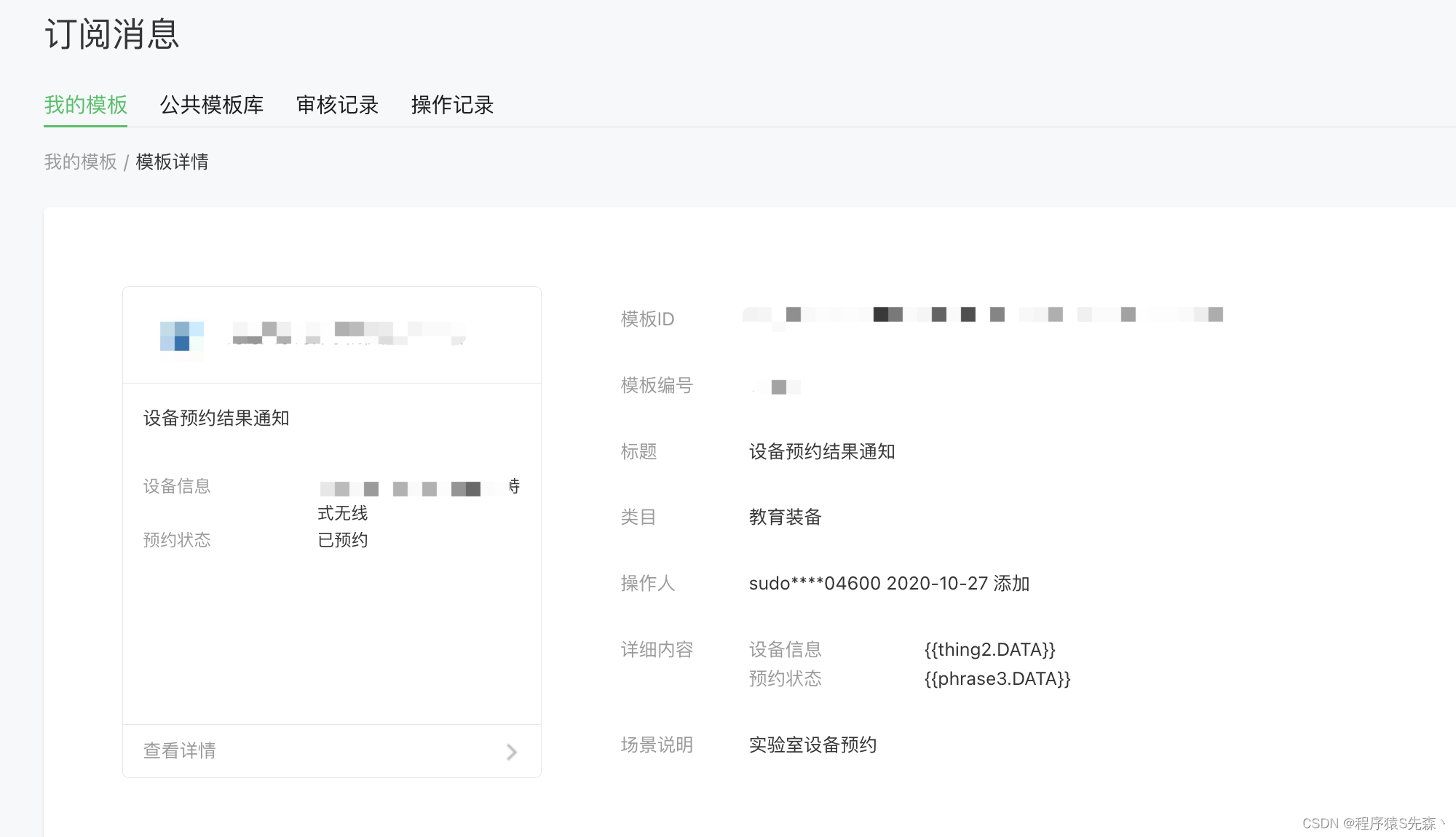
uniapp微信小程序消息订阅快速上手
一、微信公众平台小程序开通消息订阅并设置模板 这边的模板id和详细内容后续前后端需要使用 二、uniapp前端 需要是一个button触发 js: wx.getSetting({success(res){console.log(res)if(res.authSetting[scope.subscribeMessage]){// 业务逻辑}else{uni.request…...
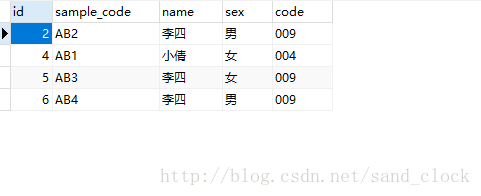
MySQL 根据多字段查询重复数据
MySQL 根据多字段查询重复数据 在实际的数据库应用中,我们经常需要根据多个字段来查询重复的数据。MySQL 提供了一些方法来实现这个功能,让我们能够快速准确地找到和处理重复数据。本文将介绍如何使用 MySQL 来根据多字段查询重复数据,并提供…...
Markdown编辑器 Mac版Typora功能介绍
Typora mac是一款跨平台的Markdown编辑器,支持Windows、MacOS和Linux操作系统。它具有实时预览功能,能够自动将Markdown文本转换为漂亮的排版效果,让用户专注于写作内容而不必关心格式调整。 Typora Mac版除了支持常见的Markdown语法外&#…...

el-form自定义校验规则
Vue 的 el-form 组件可以使用自定义校验规则进行表单验证。自定义校验规则可以通过传递一个函数来实现,该函数接受要校验的字段的值作为参数,并返回一个布尔值或一个 Promise 对象。 下面是一个示例,演示如何在 el-form 中使用自定义校验规则…...

xml对象与字符串互换
很多老系统,特别是C的系统,可能数据结构采用的xml。xml对java来说没有什么,但是C来说,可能还有个顺序问题,毕竟c没有那么多通用类库。 2 xstream 先说依赖,我本来不想升级,但是有个问题卡者就给…...

单例模式和多例模式和工厂模式
1单例设计模式 学习目标 能够使用单例设计模式设计代码 内容讲解 正常情况下一个类可以创建多个对象 public static void main(String[] args) {// 正常情况下一个类可以创建多个对象Person p1 new Person();Person p2 new Person();Person p3 new Person(); }如果说有…...
【网络架构】华为hw交换机网络高可用网络架构拓扑图以及配置
一、网络拓扑 1.网络架构 核心层:接入网络----路由器 汇聚层:vlan间通信 创建vlan ---什么是vlan:虚拟局域网,在大型平面网络中,为了实现广播控制引入了vlan,可以根据功能或者部门等创建vlan,再把相关的端口加入到vlan.为了实现不用交换机上的相同vlan通信,需要配置中继,为了…...

信也科技一面凉经
1.在项目经历里挑一个详细介绍一下 项目的应用场景 2.项目里用到多线程是怎么用的?回答:线程池 用通过 ThreadPoolExecutor 构造函数的方式创建的线程池 3.线程池有哪些重要参数?回答:核心线程数、最大线程数、阻塞队列类型、…...

别让严谨变成AI味!实测5大主流降AI工具,这款能完美保留原格式
最近看了一些行业报告,AI工具在写作方面的普及率真的已经超乎想象了。 很多大学生在写论文时也都习惯用AI来辅助寻找灵感、提高效率。 与此同时,相关部门针对人工智能写作出台了一系列规定,各大学术检测平台也都在不断升级AIGC检测算法。 现…...

免费照片怎样去水印?2026年去水印app优缺点对比与4款工具推荐
在日常生活和内容创作中,我们经常会遇到需要去除照片水印的情况。无论是整理素材库、处理工作资料,还是保存喜欢的图片,一款好用的免费去水印软件可以大大提高效率。2026年市场上的去水印app选择众多,每款工具都有不同的特点和适用…...

告别日志脱敏烦恼:手把手教你用sensitive注解优雅保护用户隐私数据
优雅实现日志脱敏:基于注解的隐私数据保护实战指南 在金融、电商等强合规领域,用户隐私数据保护早已从"可选"变为"必选"。每次看到同事在代码中手动拼接"手机号:"user.getPhone().substring(0,3)"****&qu…...

SteamAutoCrack完整指南:一键移除游戏DRM保护
SteamAutoCrack完整指南:一键移除游戏DRM保护 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack SteamAutoCrack是一款专业的开源游戏DRM移除工具,能够自动解除Ste…...

Arduino | 从串口收发到双向对话:实战指令解析与数据交换
1. 串口通讯:Arduino与世界的对话桥梁 第一次接触Arduino时,很多人都会从经典的Blink示例开始——让板载LED灯规律闪烁。但当你想要动态调整LED亮度时,就会发现需要一种与Arduino"对话"的方式。这就是串口通讯的用武之地。想象一下…...

MCUXPresso for VS Code插件实战:从零构建NXP MCU的HelloWorld项目
1. 项目概述:为什么选择MCUXPresso for VS Code?如果你是一位嵌入式开发者,尤其是使用恩智浦(NXP)MCU的工程师,那么你大概率对MCUXpresso IDE不陌生。它是一个功能强大的集成开发环境,但有时我们…...

RK3566安卓11开发板千兆网卡RTL8211F移植避坑指南:从原理图到DTS配置全流程
RK3566安卓11平台RTL8211F千兆网卡移植实战:硬件原理到DTS配置的深度解析 当开发者需要在RK3566安卓11平台上实现千兆以太网功能时,RTL8211F PHY芯片的移植往往成为关键挑战。不同于简单的驱动加载,实际项目中常会遇到"软件配置看似正常…...

【Python自动化】PyAutoGUI构建游戏稳定性测试守护脚本
1. PyAutoGUI在游戏测试中的核心价值 游戏稳定性测试往往需要长时间运行,人工值守既低效又容易遗漏异常。PyAutoGUI作为Python的GUI自动化利器,能完美模拟鼠标键盘操作,配合进程监控和图像识别,构建724小时无人值守的测试环境。我…...
)
告别Qt默认英文!3分钟搞定QMessageBox按钮中文显示(附完整代码示例)
3分钟实现QMessageBox按钮中文显示的实战指南 刚接触Qt开发的程序员经常会遇到一个尴尬问题——精心设计的界面突然弹出英文按钮的对话框。这种"半中半英"的体验在交付给国内客户时尤为明显。今天我们就来解决这个看似简单却困扰很多开发者的问题,无需复杂…...

多VM同时启动卡爆?2种方法设置启动延迟,避免启动风暴
在虚拟化运维中,多台虚拟机(VM)同时启动时,很容易引发“启动风暴”——CPU、内存、存储IO瞬间被占满,导致所有虚拟机启动缓慢、卡顿,甚至部分VM启动失败,严重影响业务正常运行。其实解决方法很简…...