数据分析 | 随机森林如何确定参数空间的搜索范围
1. 随机森林超参数
极其重要的三个超参数是必须要调整的,一般再加上两到三个其他超参数进行优化即可。

2. 学习曲线确定n_estimators搜索范围
首先导入必要的库,使用sklearn自带的房价预测数据集:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_validate
import matplotlib.pyplot as plt
housing = fetch_california_housing()
# 特征数据
X = housing.data[:, [0, 1, 2, 3, 4, 5, 6, 7]]
# 目标变量(房价)
y = housing.target初始化以及5折交叉验证计算RMSE:
trainRMSE = np.array([])
testRMSE = np.array([])
trainSTD = np.array([])
testSTD = np.array([])Option = range(5,101,5)
for n_estimators in Option :reg_f = RandomForestRegressor(n_estimators=n_estimators, random_state=1412)# 交叉验证输出结果cv = KFold(n_splits=5,shuffle=True,random_state=1412)result_f = cross_validate(reg_f,X,y,cv=cv,scoring="neg_mean_squared_error",return_train_score=True,n_jobs=-1)# 根据输出的MSE进行RMSE计算train = abs(result_f["train_score"])**0.5test = abs(result_f["test_score"])**0.5trainRMSE = np.append(trainRMSE,train.mean())testRMSE = np.append(testRMSE,test.mean())trainSTD = np.append(trainSTD,train.std())testSTD = np.append(testSTD,test.std())定义绘图函数:
def plotCVresult(Option,trainRMSE,testRMSE,trainSTD,testSTD) :xaxis = Option# RMSEplt.plot(xaxis, trainRMSE,color='k',label='RandomForestTrain')plt.plot(xaxis, testRMSE, color='red', label='RandomForestTest')# 将标准差围绕在RMSE旁边,区间越大表示模型越不稳定plt.plot(xaxis, trainRMSE + trainSTD, color='k', linestyle='dotted')plt.plot(xaxis, trainRMSE - trainSTD, color='k', linestyle='dotted')plt.plot(xaxis, testRMSE + testSTD, color='red', linestyle='dotted')plt.plot(xaxis, testRMSE - testSTD, color='red', linestyle='dotted')plt.xticks([*xaxis])plt.legend(loc=1)plt.xlabel('n_estimators')plt.ylabel('RMSE')plt.title('Learning Curve')plt.show()plotCVresult(Option,trainRMSE,testRMSE,trainSTD,testSTD)输出结果如下:

3. 使用Tree模块判断max_depth搜索范围
只需在输出的最小值和最大值之间进行搜索即可。
reg_f = RandomForestRegressor(n_estimators=100,random_state=1412)
reg_f = reg_f.fit(X,y)
d = pd.Series([],dtype="int64")
for idx,t in enumerate(reg_f.estimators_) :d[idx] = t.tree_.max_depth
print('决策树的最大深度的最小值为:',d.min())
print('决策树的最大深度的最大值为:',d.max())输出结果为:

4. 使用Tree模块判断min_weight_fraction_leaf搜索范围
reg_f = RandomForestRegressor(n_estimators=100,random_state=1412)
reg_f = reg_f.fit(X,y)
n = pd.Series([],dtype="int64")
for idx,t in enumerate(reg_f.estimators_) :n[idx] = t.tree_.weighted_n_node_samples
meann = np.zeros(20)
for i in range(0,20) :meann[i] = n[i].mean()
print('决策树分枝所需最小样本权重的最小值为:',meann.min())
print('决策树分枝所需最小样本权重的最大值为:',meann.max())
print('决策树分枝所需最小样本权重的平均值为:',meann.mean())输出结果为:

5. 使用Tree模块判断min_sample_split搜索范围
reg_f = RandomForestRegressor(n_estimators=20,random_state=1412)
reg_f = reg_f.fit(X,y)
s = pd.Series([],dtype="int64")
for idx,t in enumerate(reg_f.estimators_) :s[idx] = t.tree_.n_node_samples
meann = np.zeros(20)
for i in range(0,20) :meann[i] = s[i].mean()
print('决策树需要最小样本的最小值为:',meann.min())
print('决策树需要最小样本的最大值为:',meann.max())
print('决策树需要最小样本的平均值为:',meann.mean())输出结果为:

相关文章:
数据分析 | 随机森林如何确定参数空间的搜索范围
1. 随机森林超参数 极其重要的三个超参数是必须要调整的,一般再加上两到三个其他超参数进行优化即可。 2. 学习曲线确定n_estimators搜索范围 首先导入必要的库,使用sklearn自带的房价预测数据集: import numpy as np import pandas as pd f…...

5G+AI数字化智能工厂建设解决方案PPT
导读:原文《5GAI数字化智能工厂建设解决方案》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。数字化智能工厂定义 智能基础架构协同框架 - 端、边、云、网…...

Windows配置编译ffmpeg +音视频地址
Windows配置MinGW及MinGW-make使用实例 https://blog.csdn.net/Henoiiy/article/details/122550618 ffmpeg安装遇错:nasm/yasm not found or too old. Use --disable-x86asm for a crippled build. https://blog.csdn.net/sayyy/article/details/124337834https://…...
)
C语言 常用工具型API --------system()
函数名: system() 用 法: int system(char *command); 原理: 加载一个子进程去执行指定的程序,而想Linux命令基本都是一个单独的进程实现的,所以你所掌握的Linux命令越多,该函数功…...
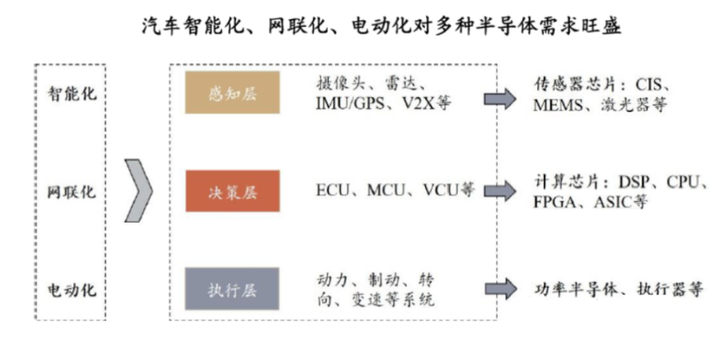
车规级半导体分类(汽车芯片介绍)
车规级半导体,也被称为“汽车芯片”,主要应用于车辆控制装置、车载监控系统和车载电子控制装置等领域。这些半导体器件主要分布在车体控制模块上,以及车载信息娱乐系统方面,包括动力传动综合控制系统、主动安全系统和高级辅助驾驶…...

opencv图像轮廓检测
效果展示: 代码部分: import cv2 import numpy as np img cv2.imread(C:/Users/ibe/Desktop/picture.PNG,cv2.IMREAD_UNCHANGED) # 类型转换 img cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 结构元 kernel cv2.getStructuringElement(cv2.MORPH_REC…...

诚迈科技荣膺小米“最佳供应商奖”
近日,诚迈科技受邀参加小米战略合作伙伴HBR总结会。诚迈科技以尽职尽责的合作态度、精益求精的交付质量荣膺小米公司颁发的最佳供应商奖,其性能测试团队荣获优秀团队奖。 诚迈科技与小米在手机终端方向一直保持着密切的合作关系,涉及系统框架…...

分布式 - 消息队列Kafka:Kafka 消费者的消费位移
文章目录 01. Kafka 分区位移02. Kafka 消费位移03. kafka 消费位移的作用04. Kafka 消费位移的提交05. kafka 消费位移的存储位置06. Kafka 消费位移与消费者提交的位移07. kafka 消费位移的提交时机08. Kafka 维护消费状态跟踪的方法 01. Kafka 分区位移 对于Kafka中的分区而…...
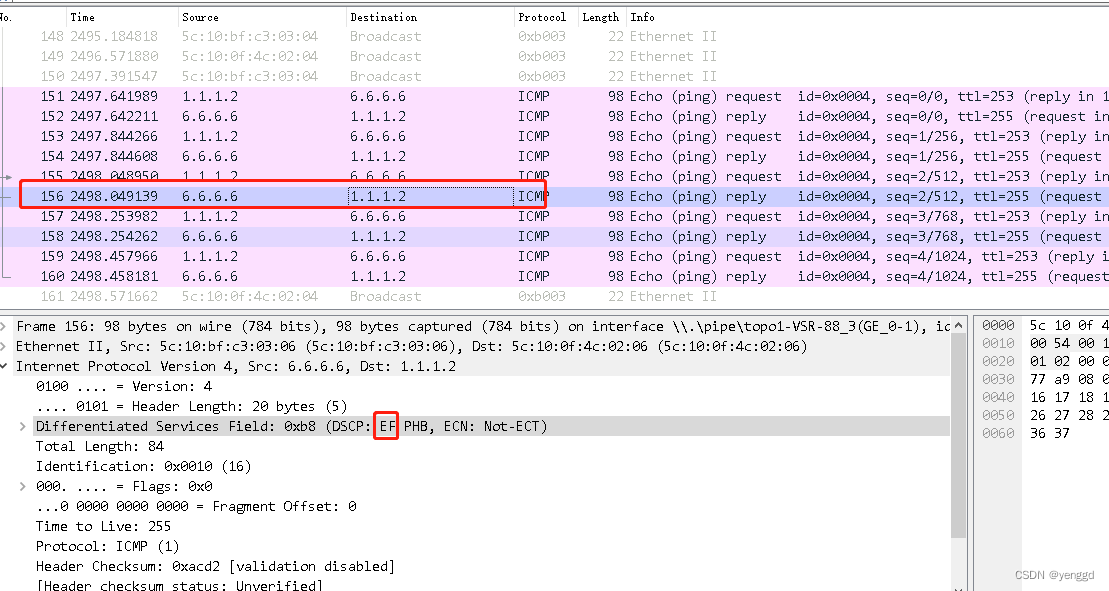
H3C QoS打标签和限速配置案例
EF:快速转发 AF:确保转发 CS:给各种协议用的 BE:默认标记(尽力而为) VSR-88-2 出口路由配置: [H3C]dis current-configuration version 7.1.075, ESS 8305 vlan 1 traffic classifier vlan10 operator and if-match a…...

带curl的docker镜像image
带curl的docker镜像,便于k8s中查找问题,确认容器内部是否可用。 用于测试网络的工具,带有curl nslookup等命令 镜像名docker.io/appropriate/curl 测试命令docker run --rm -it docker.io/appropriate/curl /bin/sh 已测试可用 用于测试网…...

Hadoop数据迁移distcp
Hadoop数据迁移distcp 准备工作 确认源集群(a),目标集群(b)确认a集群的主节点和b集群的主节点确认两个集群的网络相通确认迁移模式(全量迁移还是增量迁移),这里选择全量迁移 迁移文件 迁移t…...
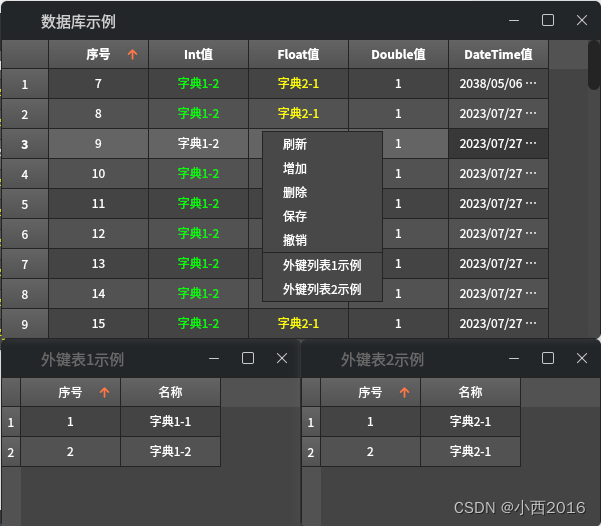
QT-Mysql数据库图形化接口
QT sql mysqloper.h qsqlrelationaltablemodelview.h /************************************************************************* 接口描述:Mysql数据库图形化接口 拟制: 接口版本:V1.0 时间:20230727 说明:支…...
LeetCode150道面试经典题-- 合并两个有序链表(简单)
1.题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 2.示例 示例 1: 输入:l1 [1,2,4], l2 [1,3,4] 输出:[1,1,2,3,4,4] 示例 2: 输入:l1 [], l2 [] 输…...
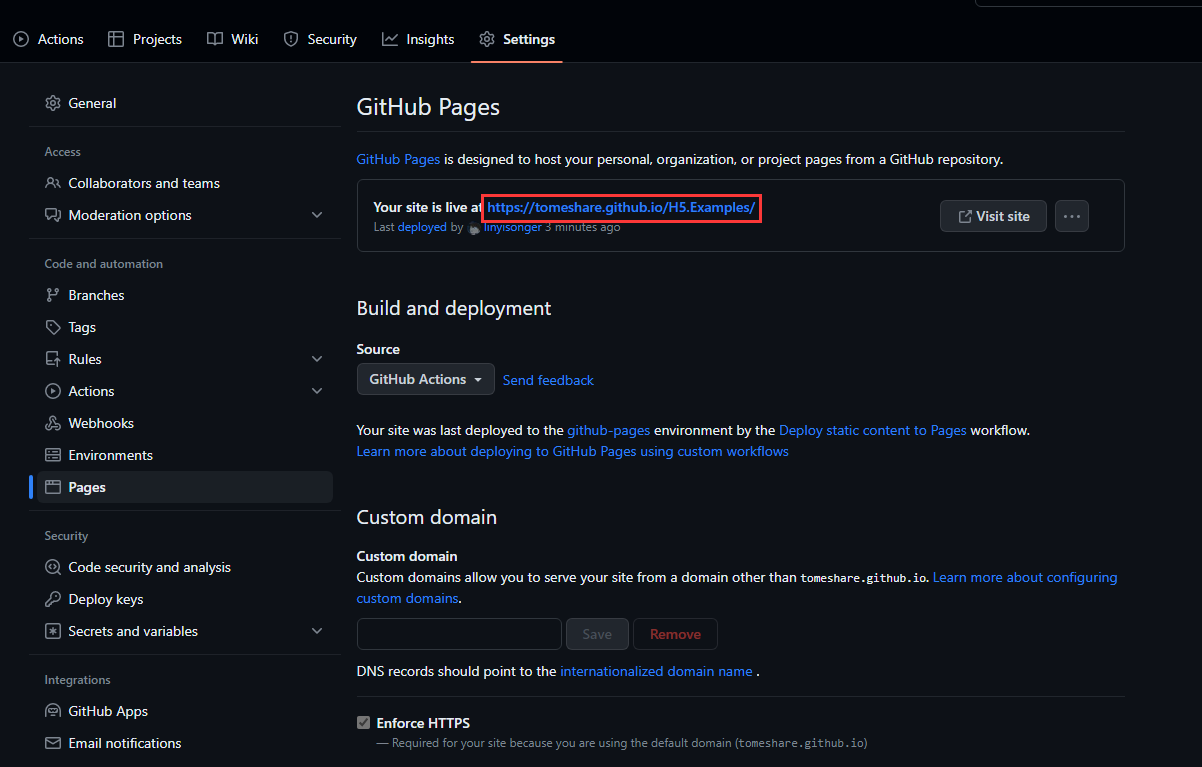
GitHub 如何部署写好的H5静态页面
感谢粉皮zu的私信,又有素材写笔记了。(●’◡’●) 刚好记录一下我示例代码的GitHub部署配置,以便于后期追加仓库。 效果 环境 gitwin 步骤 第一步 新建仓库 第二步 拉取代码 将仓库clone到本地 git clone 地址第三步 部署文件 新建.github\workflo…...
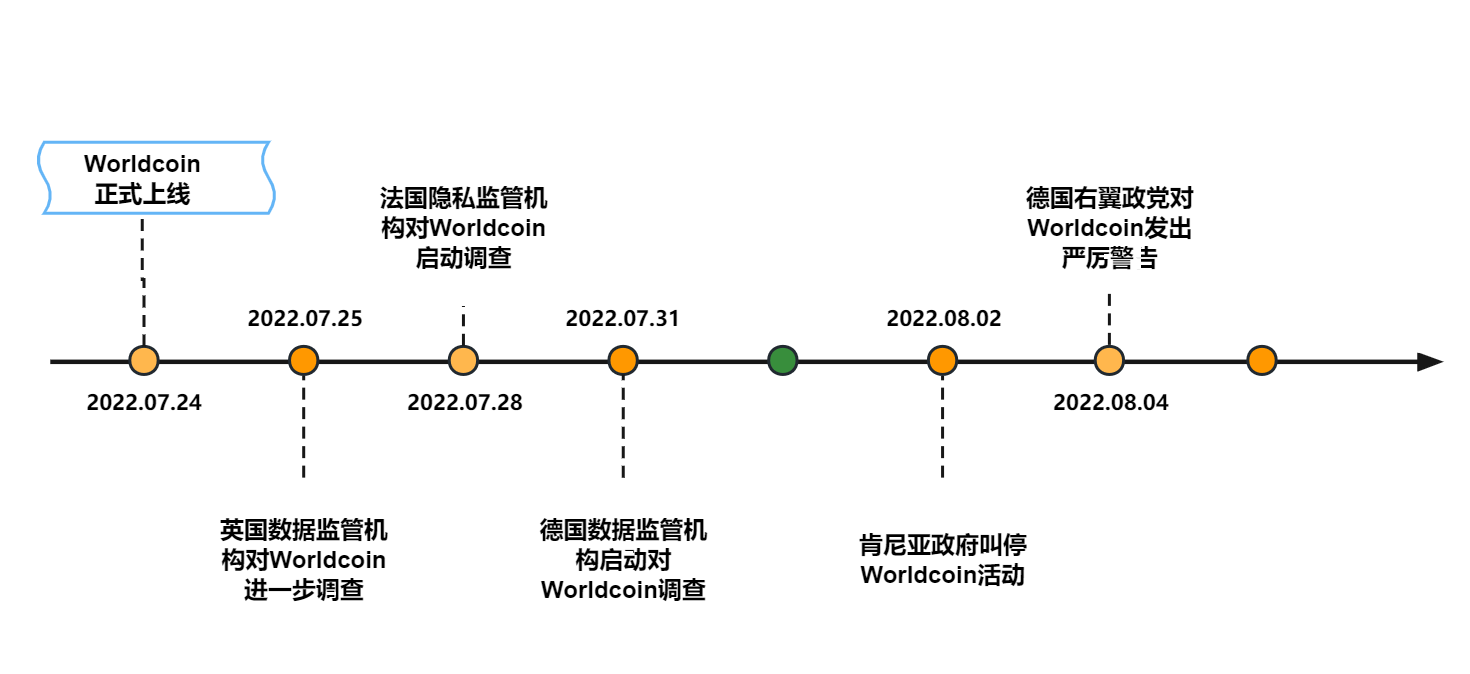
SharkTeam:Worldcoin运营数据及业务安全分析
Worldcoin的白皮书中声明,Worldcoin旨在构建一个连接全球人类的新型数字经济系统,由OpenAI创始人Sam Altman于2020年发起。通过区块链技术在Web3世界中实现更加公平、开放和包容的经济体系,并将所有权赋予每个人。并且希望让全世界每一个人都…...

C语言编程练习
考点:【字符串】【数组】 题目1. 打印X 题目描述 输入一个正整数N, 你需要按样例的方式返回一个字符串列表。 1≤N≤15。 样例 1: 输入:1 输出:[“X”] X样例 2: 输入:2 [“XX”, “XX”] …...
)
vue入门(增查改!)
<template><div><!-- 搜索栏 --><el-card id"search"><el-row><el-col :span"20"><el-input v-model"searchModel.name" placeholder"根据名字查询"></el-input><el-input v-mode…...
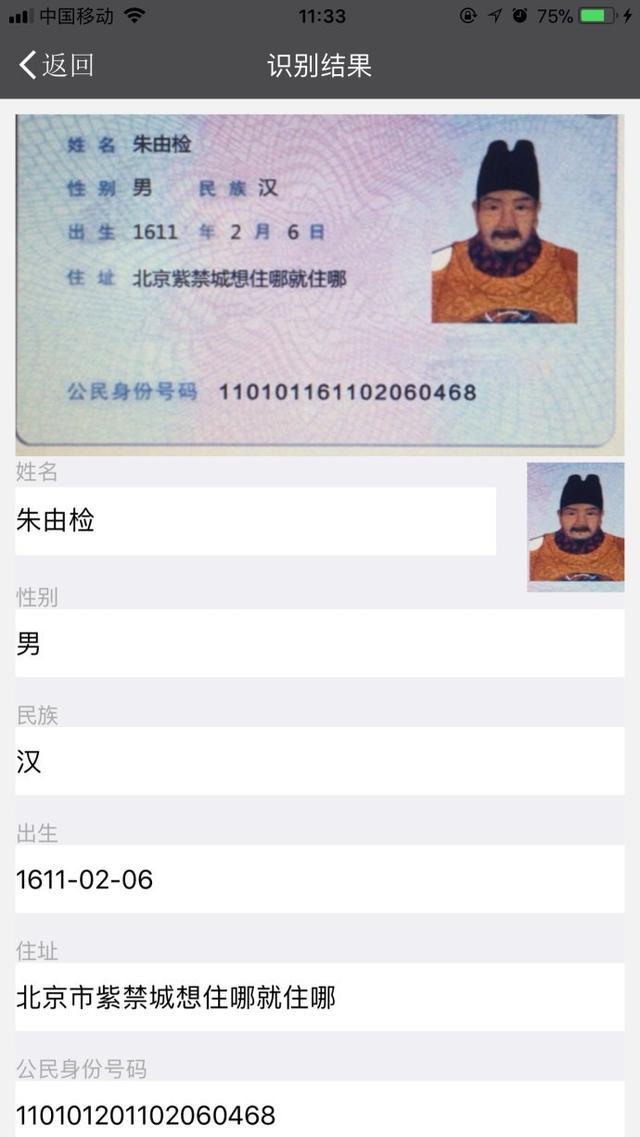
移动端身份证识别技术的应用,告别手动录入证件信息
随着移动互联网的的发展,越来越多的公司都推出了自己的移动APP,这些APP多数都涉及到个人身份证信息的输入认证(即实名认证),如果手动去输入身份证号码和姓名,速度非常慢,且用户体验非常差。为了…...

网络通信原理TCP字段解析(第四十七课)
字段含义Source Port(源端口号)源端口,标识哪...
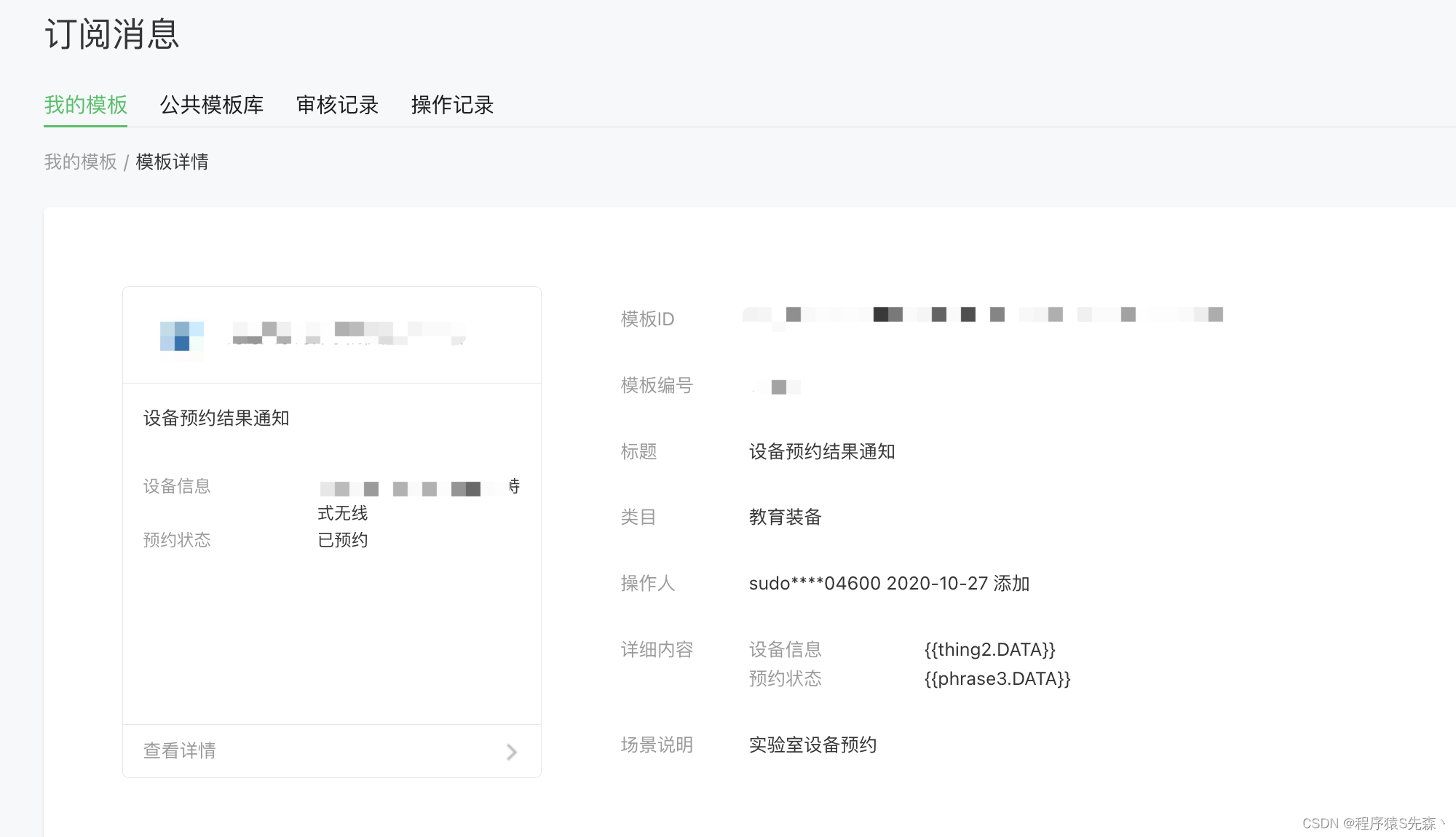
uniapp微信小程序消息订阅快速上手
一、微信公众平台小程序开通消息订阅并设置模板 这边的模板id和详细内容后续前后端需要使用 二、uniapp前端 需要是一个button触发 js: wx.getSetting({success(res){console.log(res)if(res.authSetting[scope.subscribeMessage]){// 业务逻辑}else{uni.request…...

从FM收音机到5G基站:拆解DDS技术如何悄悄改变我们的通信设备
从FM收音机到5G基站:拆解DDS技术如何悄悄改变我们的通信设备 上世纪90年代,当人们第一次在车载收音机上按下"自动搜台"按钮时,很少有人意识到这个流畅体验背后隐藏着一项革命性技术——直接数字频率合成(DDS)…...

体验 Taotoken 官方价折扣活动对个人开发者月度支出的实际影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验 Taotoken 官方价折扣活动对个人开发者月度支出的实际影响 作为一名独立开发者,我日常需要调用多种大模型 API 来完…...

鼎讯 SZT-1000A:交通网络多合一智能测试仪
铁路、高速公路通信网络业务密集、链路复杂,集传输、监控、收费于一体,对测试设备的集成度、便携性、精准度要求极高。鼎讯 SZT-1000A 以太网测试仪,以 “一机多能、超轻便携” 的优势,成为交通领域网络安装、调试、运维的核心利器…...

Python实战:基于InsightFace构建实时人脸识别系统
1. 环境准备与InsightFace初探 第一次接触人脸识别系统开发时,我被各种算法和框架搞得晕头转向,直到发现了InsightFace这个宝藏库。它就像瑞士军刀一样集成了人脸检测、对齐、识别全套功能,而且对Python开发者特别友好。记得当时用OpenCVDlib…...

Claude Code 用户如何通过 Taotoken 配置稳定 API 连接避免封号困扰
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何通过 Taotoken 配置稳定 API 连接避免封号困扰 基础教程类,针对经常遇到 Claude Code 封号或 Tok…...

初次使用Taotoken从注册获取Key到完成第一次API调用的全流程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken从注册获取Key到完成第一次API调用的全流程指引 本文旨在为初次接触Taotoken平台的开发者提供一份清晰的入门指南…...

别再手动搭后台了!用vue-admin-template + SpringBoot 30分钟搞定讲师管理模块
别再手动搭后台了!用vue-admin-template SpringBoot 30分钟搞定讲师管理模块 在快节奏的互联网开发中,后台管理系统的高效搭建一直是开发者面临的痛点。传统方式从零开始构建,不仅需要处理路由配置、权限管理、UI组件等基础架构,…...

3步掌握抖音内容批量下载技巧:无水印视频保存终极指南
3步掌握抖音内容批量下载技巧:无水印视频保存终极指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppo…...

OpCore-Simplify:30分钟完成专业级黑苹果配置的终极指南
OpCore-Simplify:30分钟完成专业级黑苹果配置的终极指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的黑苹果配置而烦恼吗&…...

ESP32 Arduino核心开发终极指南:构建专业级物联网控制系统
ESP32 Arduino核心开发终极指南:构建专业级物联网控制系统 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 还在为物联网项目开发中的硬件兼容性、开发环境复杂…...