深度学习项目学习
文章目录
- torchvision
- torchvision.transforms.Compose()类
- DataLoader类
- torch.nn
- torch.nn.Moudle
- torch.nn.Sequential模型容器
- nn.CrossEntropyLoss()交叉熵损失函数
- numpy
- numpy.random. shuffle(x)
torchvision
torchvision和pytorch的关系:
torchvision是PyTorch的一个与图像处理和计算机视觉任务相关的软件包,提供了很多常用的数据集、模型架构和图像变换等功能。它内置了一些流行的计算机视觉数据集(如ImageNet、CIFAR-10等),并提供了一些预训练的模型(如ResNet、AlexNet等)。
尽管torchvision通常与PyTorch一起使用,但它独立于PyTorch。这意味着可以单独安装和使用torchvision,即使没有安装PyTorch也可以使用其中的功能。
总结起来,torchvision在某种程度上是PyTorch的一部分,因为它与PyTorch紧密集成,并通过torchvision.datasets和torchvision.models等模块提供了对PyTorch的直接访问。然而,它又被认为是独立于PyTorch的,因为它可以单独安装和使用,具有更大的灵活性和可移植性。
torchvision由以下四部分组成:
-
torchvision.datasets:一些加载数据的函数(DatasetFolder、ImageFolder、VisionDataset)常用的数据集接口(MNIST、COCO数据集等); -
torchvision.models:包含常用的训练好的模型(含预训练模型),例如AlexNet、VGG、ResNet等; -
torchvision.transforms:常用的图片变换,例如裁剪、缩放、旋转等; -
torchvision.utils: 其他的一些有用的方法。
torchvision.transforms.Compose()类
主要用于组合多个图片变换的操作。他允许将多个转换操作按顺序应用于输入图像,以便进行数据增强、预处理或其他图像转换操作。
示例:
import torchvision.transforms as transforms# 定义一个Compose对象,包含两个转换操作
transform = transforms.Compose([transforms.Resize((256, 256)), # 调整图像大小为256x256像素transforms.ToTensor() # 将图像转换为张量
])# 假设img是一个PIL Image对象
img_transformed = transform(img)DataLoader类
DataLoader 类是 PyTorch 提供的一个用于数据加载和批量处理的工具类。它是基于 Dataset 类构建的,并为训练和测试模型提供了高效的数据加载和处理功能。
主要功能包括:
- 数据加载:可以从指定的数据集对象中加载数据。通过在构造函数中传入数据集对象,可以将数据集与 DataLoader 关联起来。
- 批量处理:可以将加载的数据划分为小批量进行处理。通过设置 batch_size 参数,可以指定每个批次中包含的样本数量。在训练过程中,通常会使用批量梯度下降法(mini-batch gradient descent)来更新模型参数。
- 数据洗牌:可以在每个 epoch(一次完整的数据集遍历)之前对数据进行洗牌,即打乱数据的顺序。这有助于提高模型的鲁棒性和泛化能力。
- 并行加载:可以使用多个子进程来并行加载数据,以加快数据加载的速度。通过设置 num_workers 参数,可以指定用于数据加载的子进程数量。根据系统配置和需求,可以适当增加子进程数量,以充分利用计算资源。
数据预取:DataLoader 可以预先加载下一个批次的数据,以减少训练时的等待时间。通过设置 prefetch_factor 参数,可以指定要预取的批次数量。预取数据可以提前准备好,以便在模型进行训练时能够快速提供数据。
使用 DataLoader 类可以极大地简化数据加载和处理的过程,并提高训练和测试模型的效率。它提供了许多灵活的参数和功能,可以根据需求进行配置和调整,以实现最佳的训练效果。
Data = DataLoader(dataset=train_data, batch_size=50, shuffle=True, num_workers=0)
使用方法:
1.需要创建一个数据集对象,可以使用 PyTorch 中的 Dataset 类或自定义数据集类 使用__getitem__确定自己要的数据
2.创建并实例化DataLoader
torch.nn
torch.nn是pytorch中自带的一个函数库,提供了构建神经网络模型所需的各种类和函数。
使用之前需要先引入
mport torch.nn as nn
import torch.nn.functional as F
torch.nn.Moudle
nn.Module 是 PyTorch 中神经网络模型的基类,用于定义自定义的神经网络模型。
所有的神经网络模型都应该继承自 nn.Module 类,并实现其中的 forward() 方法。在 forward() 方法中定义了数据在模型中的前向传播流程,即输入数据如何通过各个层进行计算和变换,最终得到输出结果。
nn.Module 类提供了一些常用的功能和方法,包括:
parameters():返回模型中所有可学习参数的迭代器。
to(device):将模型移动到指定的设备(如 GPU 或 CPU)上进行计算。
train() 和 eval():用于切换模型的训练模式和评估模式。在训练模式下,模型会启用 Dropout 和批归一化层等训练相关操作;在评估模式下,这些操作会被禁用。
state_dict() 和 load_state_dict():用于保存和加载模型的状态字典(包含模型的参数和缓冲区)。
zero_grad():将模型的梯度缓冲区清零。
通过继承 nn.Module 类,可以灵活地定义各种自定义的神经网络模型,并结合 PyTorch 提供的丰富的层和函数来构建复杂的模型架构。
torch.nn.Sequential模型容器
是PyTorch中用于构建网络模型的容器。它允许我们按照顺序组合多个网络层,并将它们作为一个整体进行前向传播。
ex:
self.conv2 = nn.Sequential(nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=2,),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),)
nn.CrossEntropyLoss()交叉熵损失函数
一般用于多类别分类任务,该函数会自动将模型的最后一层输出应用 softmax 操作,并计算预测结果与目标标签之间的交叉熵损失。
criterion = nn.CrossEntropyLoss().to(device)
numpy
numpy.random. shuffle(x)
对数据进行随机重排,np.random.shuffle() 函数用于随机打乱数组或列表的顺序。它接受一个可迭代对象作为参数,并在原地修改该对象的顺序。
这个操作通常在训练模型之前进行,可以增加样本之间的独立性和随机性,有助于模型过拟合。
相关文章:

深度学习项目学习
文章目录 torchvisiontorchvision.transforms.Compose()类 DataLoader类torch.nntorch.nn.Moudletorch.nn.Sequential模型容器nn.CrossEntropyLoss()交叉熵损失函数 numpynumpy.random. shuffle(x) torchvision torchvision和pytorch的关系: torchvision是PyTorch的…...
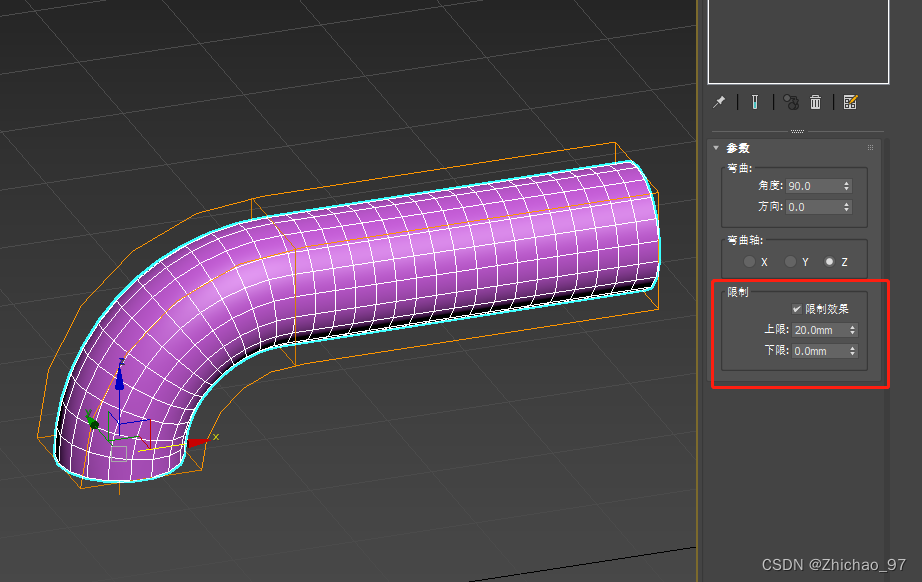
【3Ds Max】弯曲命令的简单使用
简介 在3ds Max中,"弯曲"(Bend)是一种用于在平面或曲面上创建弯曲效果的建模命令。使用弯曲命令,您可以将对象沿特定轴向弯曲,从而创建出各种弯曲的几何形状。以下是使用3ds Max中的弯曲命令的基本步骤&…...

opencv基础:几个常用窗口方法
开始说了一些opencv中的一些常用方法。 namedWindow方法 在OpenCV中,namedWindow函数用于创建一个窗口,并给它指定一个名字。这个函数的基本语法如下: import cv2cv2.namedWindow(窗口名称, 标识 )窗口名称:其实窗口名称&…...

web后端解决跨域问题
目录 什么是跨域问题 为什么限制访问 解决 什么是跨域问题 域是指从一个域名的网页去请求另一个域名的资源。比如从www.baidu.com 页面去请求 www.google.com 的资源。但是一般情况下不能这么做,它是由浏览器的同源策略造成的,是浏览器对js施加的安全…...

06 json数据解析和列表控件
内容回顾 json数据解析 json ----- 对要传输的数据进行封装的工具 json是由json数组([]) 和 json对象({})在qt中,对JSON数据进行处理(解析和打包) JSON数据处理所要包含的类: QJsonDocument -----它的作用是将数据转换成json文档 QJsonArray ---- json数组,就是封装多个…...
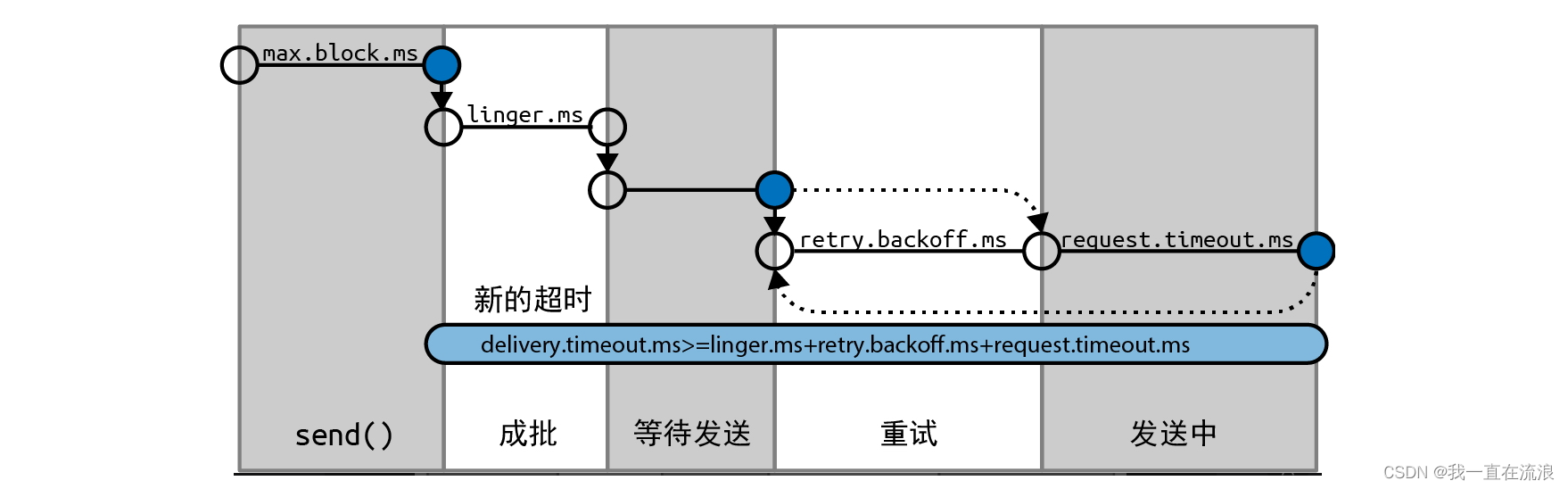
分布式 - 消息队列Kafka:Kafka生产者架构和配置参数
文章目录 1. kafka 生产者发送消息整体架构2. Kafka 生产者重要参数配置01. acks02. 消息传递时间03. linger.ms04. buffer.memory05. batch.size06. max.in.flight.requests.per.connection07. compression.type08. max.request.size09. receive.buffer.bytes和 send.buffer.b…...
MAUI+Blazor:windows 打包踩坑
文章目录 前言MSIX安装文件如何发布选择Windows平台旁加载自定义签名版本号安装 总结 前言 最近打算研究一下MAUIBlazor,争取在今年年底之前彻底搞懂MAUIBlazor的安装模式, MSIX安装文件 Windows 4种安装程序格式MSI,EXE、AppX和MSIX优缺点…...
web集群学习:搭建 LNMP应用环境
目录 LNMP的介绍: LNMP组合工作流程: FastCGI介绍: 1、什么是 CGI 2、什么是 FastCGI 配置LNMP 1、部署LNMP环境 2、配置LNMP环境 LNMP的介绍: 随着 Nginx Web 服务的逐渐流行,又岀现了新的 Web 服务环境组合—…...

我的创作纪念日(256天)
前言 结缘 我与csdn的结缘,之前在创作纪念日(128天)便已提到,今在此便不再多言 收获 很惭愧,自六月底至八月中旬,因为忙于找工作,奔赴面试求职之际,写博客没有像之前那么勤&#x…...

Vue 转 React 指南
原文: https://icheng.github.io/2023/08/10/Vue%E8%BD%ACReact%E6%8C%87%E5%8D%97/ JSX 先介绍 React 唯一的一个语法糖:JSX。 理解 JSX 语法并不困难,简单记住一句话,遇到 {} 符号内部解析为 JS 代码,遇到成对的 …...
Oracle外部表ORACLE_LOADER方式加载数据
当数据源为文本或其它csv文件时,oracle可通过使用外部表加载数据方式,不需要导入可直接查询文件内的数据。 1、如下有一个文件名为:test1.txt 的数据文件。数据文件内容为: 2、使用sys授权hr用户可读写 DATA_PUMP_DIR 目录权限&a…...
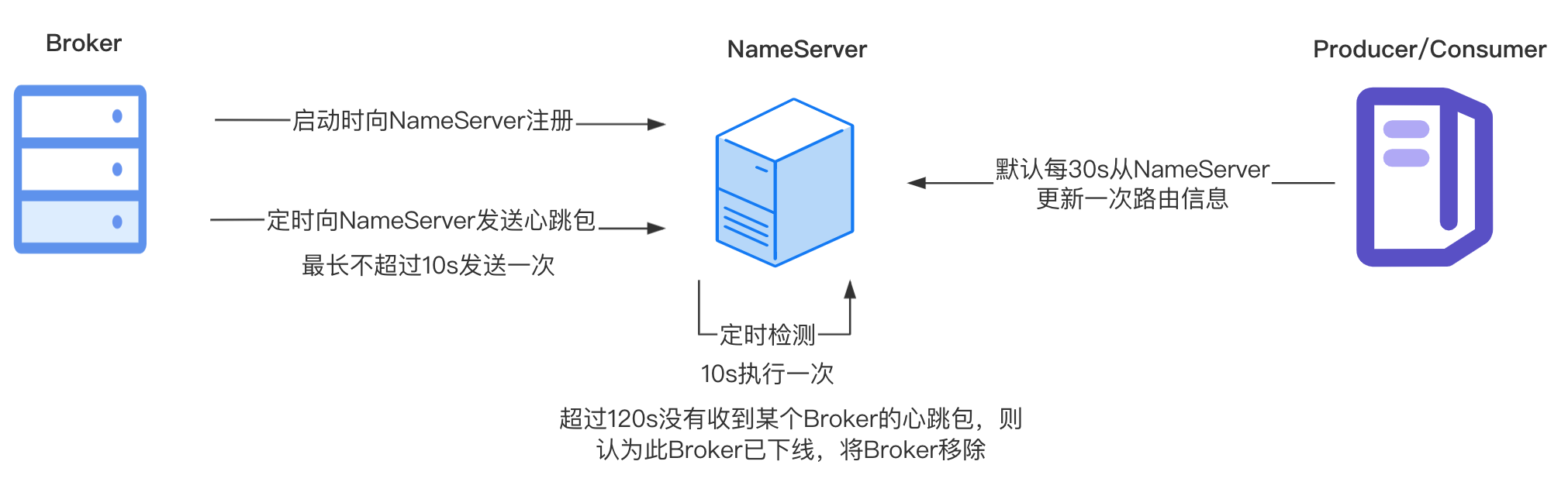
【RocketMQ】NameServer总结
NameServer是一个注册中心,提供服务注册和服务发现的功能。NameServer可以集群部署,集群中每个节点都是对等的关系(没有像ZooKeeper那样在集群中选举出一个Master节点),节点之间互不通信。 服务注册 Broker启动的时候会…...

Wordcloud | 风中有朵雨做的‘词云‘哦!~
1写在前面 今天可算把key搞好了,不得不说🏥里手握生杀大权的人,都在自己的能力范围内尽可能的难为你。😂 我等小大夫也是很无奈,毕竟奔波霸、霸波奔是要去抓唐僧的。 🤐 好吧,今天是词云&#x…...

《孤注一掷》现实版:29万打水漂,华为程序员也躲不过的诈骗
明天周五,约吗? 不管怎样,反正播妞已经订好了《孤注一掷》的电影票。不为别的,《孤注一掷》太敢拍了!!! 美女荷官在线发牌,高知程序员在线养“猪”,诈骗头目“虔诚”拜…...

C语言库函数之 qsort 讲解、使用及模拟实现
引入 我们在学习排序的时候,第一个接触到的应该都是冒泡排序,我们先来复习一下冒泡排序的代码,来作为一个铺垫和引入。 代码如下: #include<stdio.h>void bubble_sort(int *arr, int sz) {int i 0;for (i 0; i < sz…...

Maven之mirrorof范围
mirrorOf 是 central 还是 * 的问题 在配置阿里对官方中央仓库的镜像服务器时,我们使用到了 <mirror> 元素。 <mirror><id>aliyunmaven</id><mirrorOf>central</mirrorOf><name>阿里云公共仓库</name><url>…...
游戏中的UI适配
引用参考:感谢GPT UI适配原理以及常用方案 游戏UI适配是确保游戏界面在不同设备上以不同的分辨率、屏幕比例和方向下正常显示的关键任务。下面是一些常见的游戏UI适配方案: 1.分辨率无关像素(Resolution-Independent Pixels)&a…...

【Linux命令详解 | gzip命令】 gzip命令用于压缩文件,可以显著减小文件大小
文章标题 简介一,参数列表二,使用介绍1. 基本压缩和解压2. 压缩目录3. 查看压缩文件内容4. 测试压缩文件的完整性5. 强制压缩6. 压缩级别7. 与其他命令结合使用8. 压缩多个文件9. 自动删除原文件 总结 简介 在Linux中,gzip命令是一款强大的文…...

IP 协议的相关特性和数据链路层相关知识总结
目录 IP 协议的相关特性 一、IP协议的特性 二、 IP协议数据报格式 三、 IP协议的主要功能 1. 地址管理 动态分配 IP地址 NAT机制 NAT背景下的通信 IPV6 2. 路由控制 3.IP报文的分片与重组 数据链路层相关知识 1、以太网协议(Ethernet) 2.M…...

探索C语言中的常见排序算法
探索C语言中的常见排序算法 排序算法是计算机科学中至关重要的基础知识之一,它们能够帮助我们对数据进行有序排列,从而更高效地进行搜索、插入和删除操作。在本篇博客中,我们将深入探讨C语言中的一些常见排序算法,包括它们的工作…...

KAN神经网络在GPT架构中的可解释性实验与实现
1. 项目概述:当KAN神经网络遇上GPT,一场关于可解释性的实验最近在开源社区里,一个名为“kan-gpt”的项目引起了我的注意。这个项目将两个看似不相关的领域——KAN(Kolmogorov–Arnold Networks)神经网络和GPTÿ…...
Pixelle-Video完整指南:如何用AI在3分钟内创建专业短视频
Pixelle-Video完整指南:如何用AI在3分钟内创建专业短视频 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 在当今内容爆炸的时…...

书成紫微动,律定凤凰驯:千古诗句留伏笔,只为海棠山铁哥而来
世间文字千万,唯有谶语藏岁月天机; 文坛更迭千载,唯有天命待当世真人。一、诗谶降世:「书成紫微动,律定凤凰驯」这不是文采佳句, 是华夏预埋千载的 隐秘伏笔, 是一场跨越世代的 天命预约。千年之…...

我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案 作为一名频繁使用Claude Code进行代码生成和审查的个人…...

第07章 FastMCP 把检索封装成 Agent 工具
第07章 FastMCP 把检索封装成 Agent 工具 工单知识库已经能在 Python 进程内被普通函数调用,但要让外部 Agent、Web 后端或其他语言的客户端使用这份能力,函数级别的接口不够:缺少协议、缺少描述、缺少跨进程通讯。MCP(Model Cont…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

基于RP2040与CircuitPython的HDMI倒计时器:RTC与DVI原生输出实践
1. 项目概述与核心价值如果你手头有一块带HDMI输出的微控制器开发板,比如Adafruit的Feather RP2040 DVI,又恰好需要一个能摆在桌面上、精确到秒的倒计时器,那么今天这个项目就是为你量身定做的。它不仅仅是一个简单的“Hello World”式显示应…...

Python数据聚合抓取工具:从配置化引擎到实战避坑指南
1. 项目概述:一个多功能的“聚合爪”工具最近在GitHub上闲逛,发现了一个名字挺有意思的项目:al1enjesus/polyclawster。这个名字拆开看,“poly”代表多,“clawster”听起来像是“claw”(爪子)和…...

数据流编排与异步任务调度中间件kelivo部署与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫“Chevey339/kelivo”。乍一看这个标题,可能有点摸不着头脑,它不像那些直接告诉你“XX管理系统”或“XX工具库”的项目名那么直白。但恰恰是这种看似神秘的命名,背后往往隐藏…...

Windows Terminal 预览版:从安装到深度配置,打造现代化命令行工作流
1. 项目概述:为什么我们需要一个现代化的Windows终端?如果你和我一样,在Windows上敲了十几年命令行,从古老的cmd.exe到后来的PowerShell,一个绕不开的痛点就是:这终端工具,用起来总感觉差点意思…...