实验篇——亚细胞定位
实验篇——亚细胞定位
文章目录
- 前言
- 一、亚细胞定位的在线网站
- 1. UniProt
- 2. WoLFPSORT
- 3. BUSCA
- 4. TargetP-2.0
- 二、代码实现
- 1. 基于UniProt(不会)
- 2. 基于WoLFPSORT
- 后续(已完善,有关代码放置于[python爬虫学习(一)](https://blog.csdn.net/2301_78630677/article/details/132241087)):
- 总结
前言
有关亚细胞定位的详细信息,请参考另一篇文章:
理化性质与亚细胞定位
一、亚细胞定位的在线网站
1. UniProt
网址:https://www.uniprot.org/
在这个网站中有一个关键的概念——ID映射(若AA序列文件不是在该官网中下载的,而是从外界导入的,那么要先将AA序列的ID转变为UniProt ID)
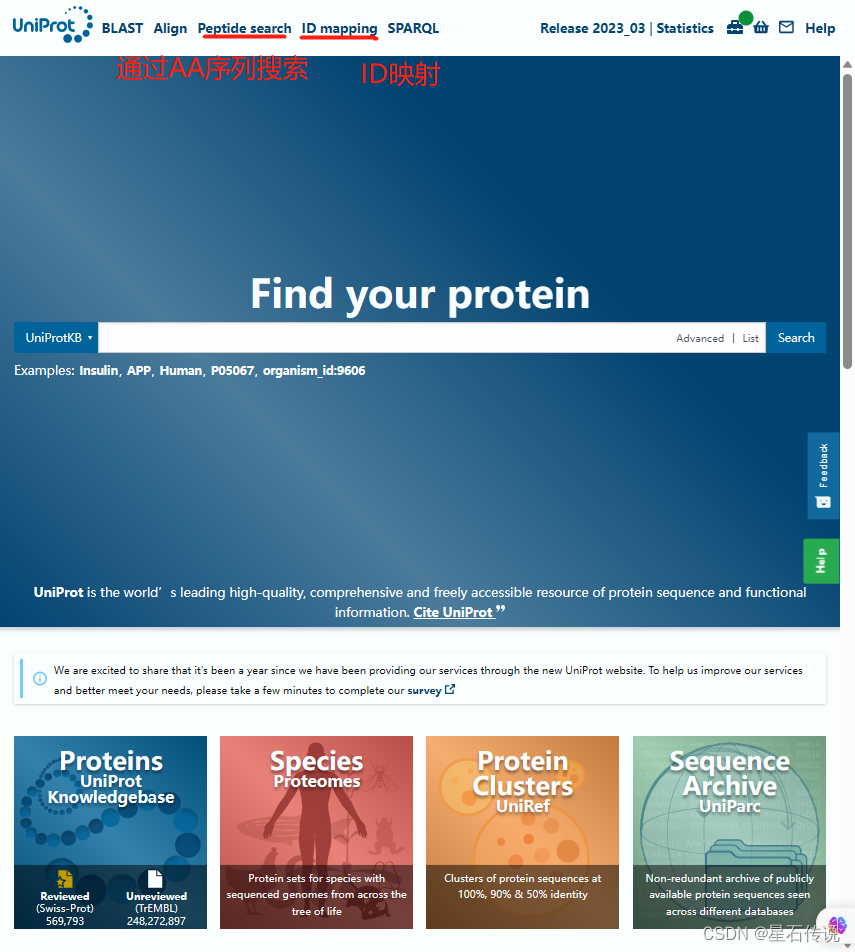
注意:首先要清楚待转换的AA序列的ID标识符来源于哪个数据库
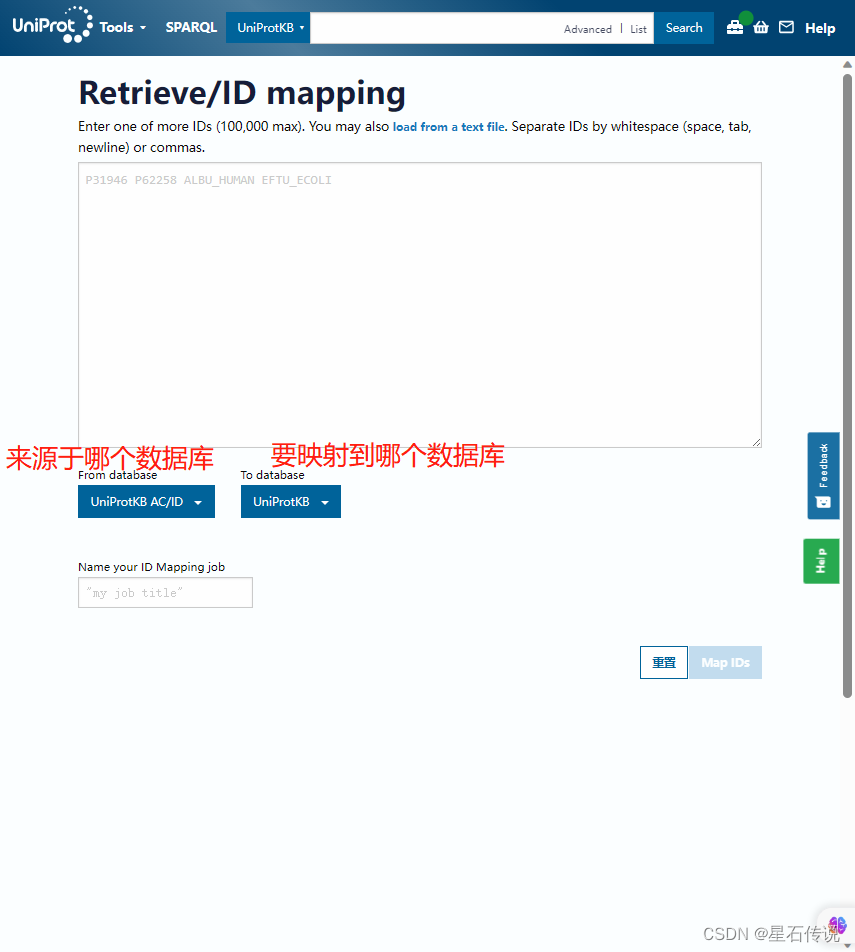
我输入了“sp|Q9FIK7.1|AACT1_ARATH”,这是某个AA序列的ID,得到如下结果,可知道它对应的UniProt ID 为 “Q8S4Y1”
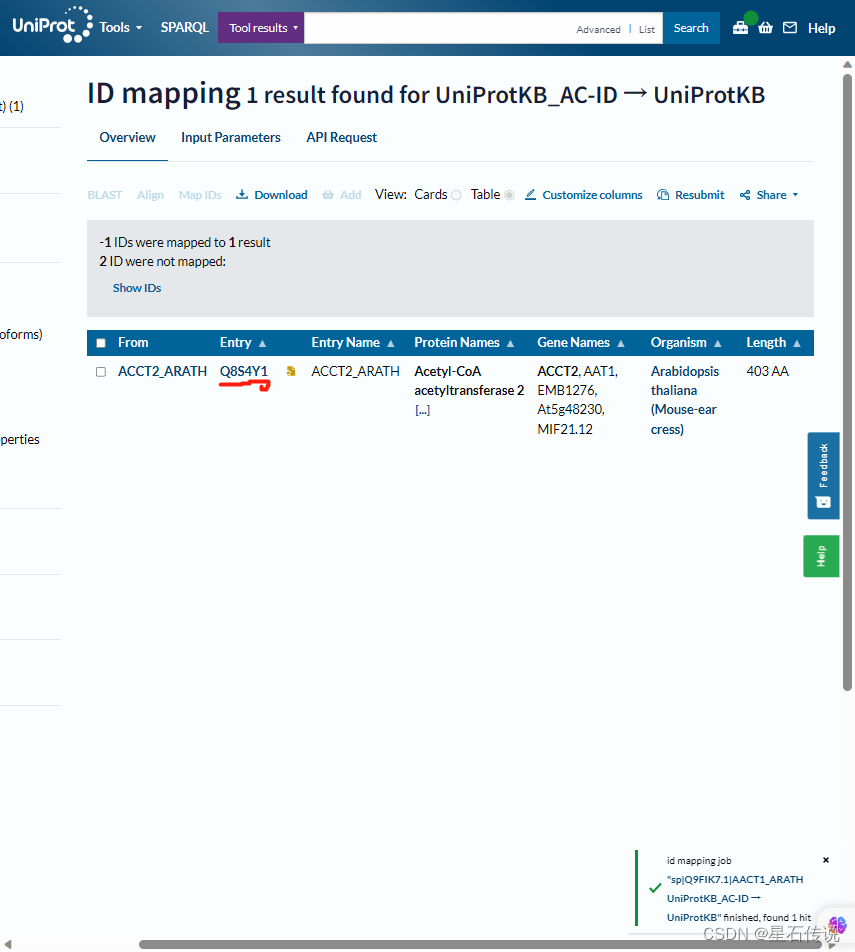
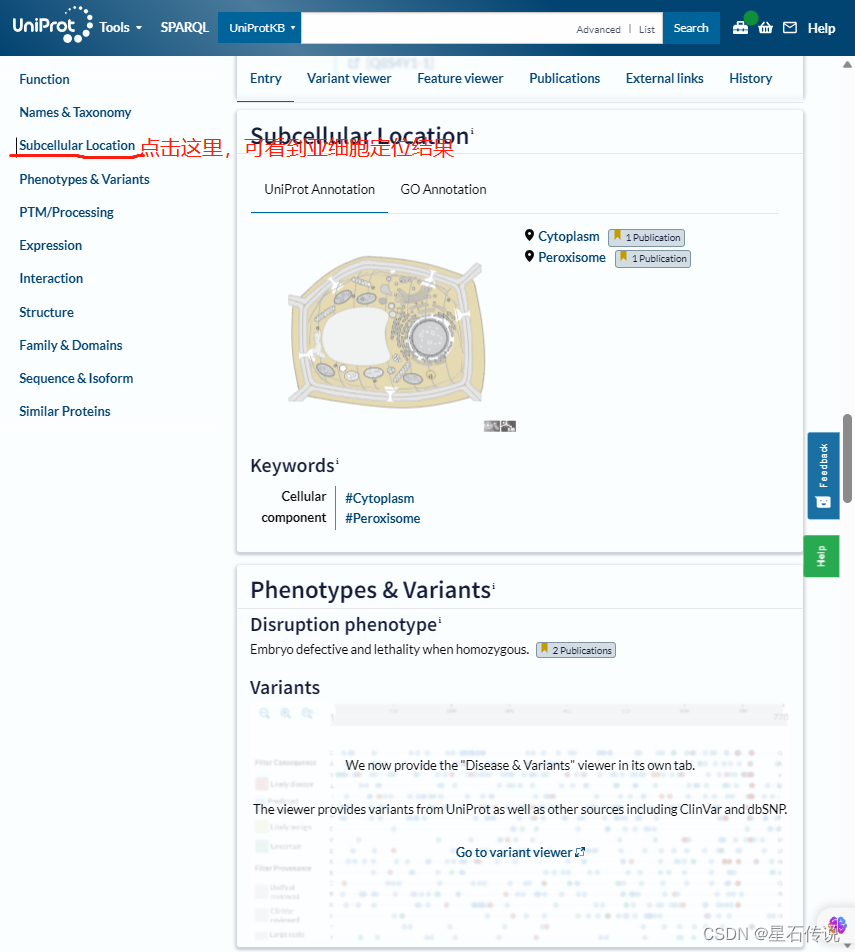
然后在搜索栏中输入该名称,得到
2. WoLFPSORT
网址:https://wolfpsort.hgc.jp/
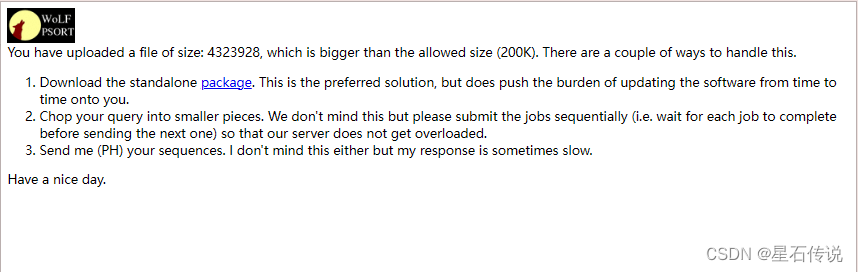
这个网站可以批量处理小量的AA序列,允许的大小(200K),根据实际情况,一般可以容纳几百到几千个氨基酸序列。
结果查看:

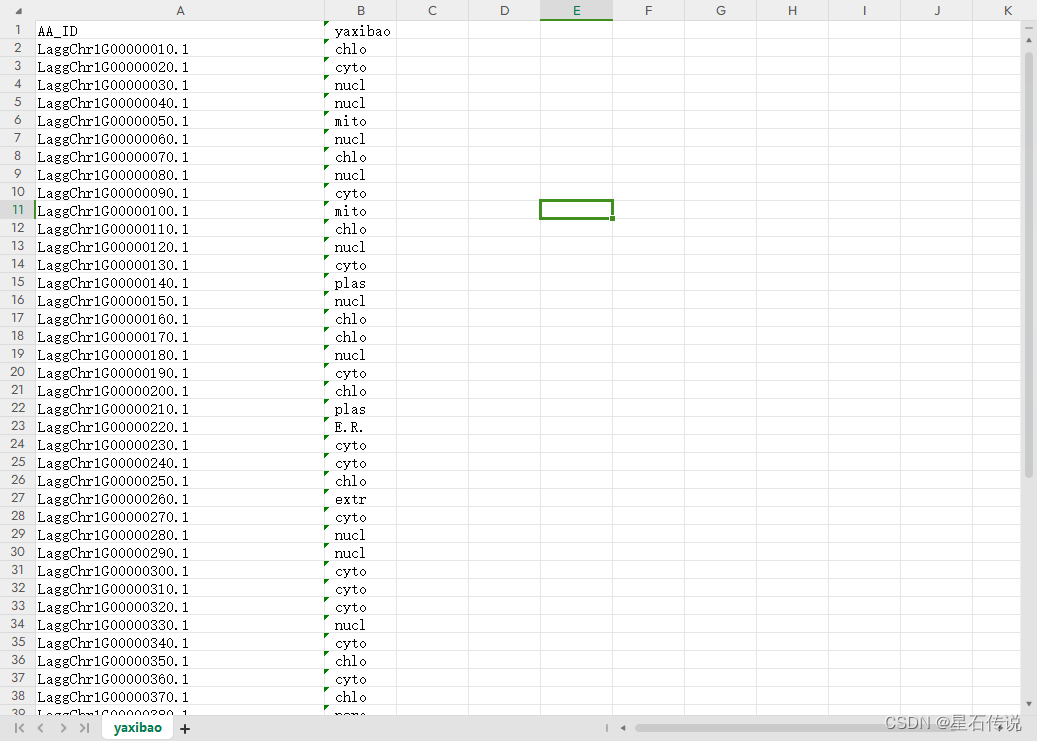
示例:
LaggChr1G00000010.1 details chlo: 5, nucl: 3.5, mito: 3, cyto_nucl: 3, cyto: 1.5, cysk: 1
LaggChr1G00000010.1这个蛋白质的亚细胞定位信息如下:
叶绿体(chlo)得分:5
细胞核(nucl)得分:3.5
线粒体(mito)得分:3
细胞质-细胞核(cyto-nucl)得分:3
细胞质(cyto)得分:1.5
细胞骨架(cysk)得分:1
这些得分表示蛋白质在各个亚细胞定位的可能性,较高的得分表示较高的概率。
他们是按得分排列的,故取第一个就行。
3. BUSCA
url: http://busca.biocomp.unibo.it/
最多可以输入500个序列
可以下载结果表格(还挺方便)
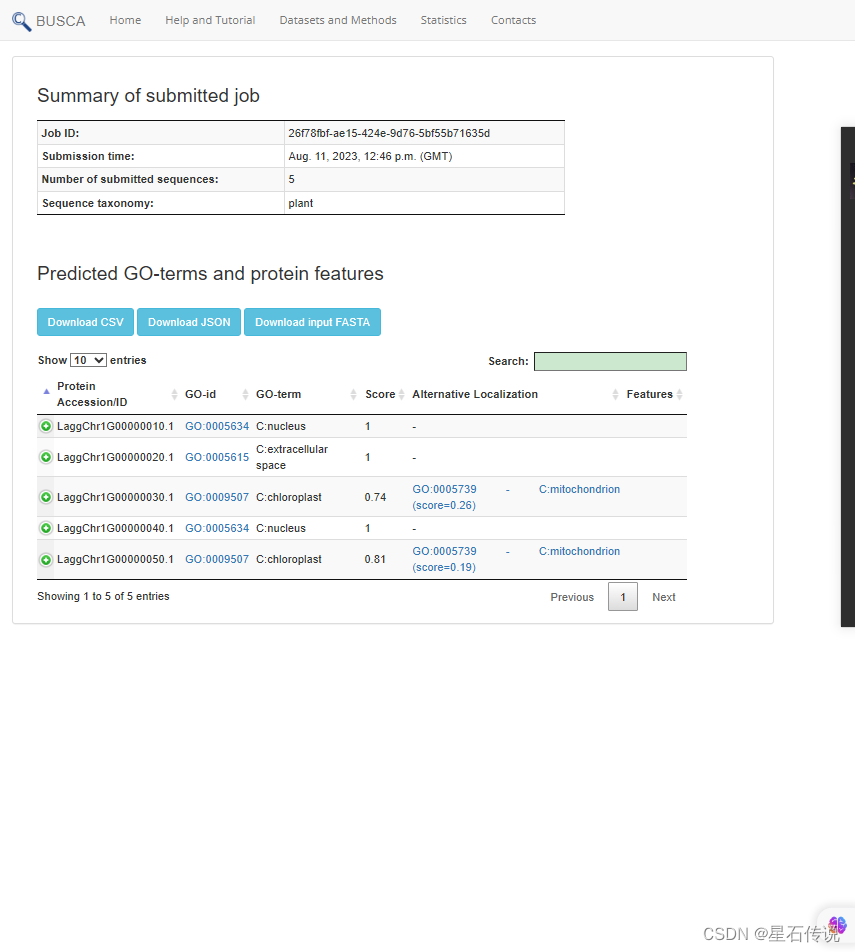
结果查看:
4. TargetP-2.0
TargetP-2.0
url = http://www.cbs.dtu.dk/services/TargetP/
我看了一下,它介绍中说能处理5000个AA序列,但是要得到结果文件是要下载这个软件,在网页上看不到结果(我没下载,因为下载它好像要填一些信息什么的)
二、代码实现
1. 基于UniProt(不会)
推荐:这是一篇有关于用R语言实现“根据uniprot ID 批量检测基因的亚细胞定位“
这篇文章是在已知道Uniprot ID的情况下实现的爬取
我最开始也是看的这篇文章,所以想要基于uniProt官网来通过爬虫爬取。但是我弄了好久才有点搞懂这个网站(它的功能太多了,太繁杂)。最主要是那个ID映射(我完全卡在这第一步了),因为我并不知道我的AA序列的ID来自哪个数据库 ,而且全是英文,就相当于我用之前还要了解好多数据库。我也看了许多关于这个官网介绍的教程,也是有点…
2. 基于WoLFPSORT
主要是对结果的整理
从前文可知,它返回的结果是一堆的,要想从中提取出来蛋白质的亚细胞定位,可以用代码实现
import requests
url = "https://wolfpsort.hgc.jp/results/pLAcbca22a5a0ccf7d913a9fc0fb140c3f4.html"
r = requests.get(url)
print(r.status_code)
# print(r.encoding)
text = r.text
# print(text)
lines = text.split("<BR>")
AA_ID_list = []
yaxibao_list =[]
for i in lines:if "details" in i:AA_ID = i.split("<A")[0].strip().split()[-1]yaxibao = i.split("details")[1].strip().split()[1][:-1]AA_ID_list.append(AA_ID)yaxibao_list.append(yaxibao)
with open("yaxibao.csv","w",encoding="utf-8") as f:f.write("AA_ID, yaxibao\n") # 写入列名for j in range(len(AA_ID_list)):f.write(f"{AA_ID_list[j]}, {yaxibao_list[j]}\n")
text:

yaxibao.csv:
后续(已完善,有关代码放置于python爬虫学习(一)):
因为在WoLF PSORT官网中一次提交的数据大小最多200kb,那 我可以试着将原来几万kb大小的AA序列的大文件分为小文件,(之前说错了,之前的那个划分文件的函数是根据文件的行数划分的,而不是AA序列的ID数。我要将大的AA序列文件划分为小的AA序列文件,是要根据AA序列的ID划分,不然就会导致AA的ID 与AA的序列不连贯这种情况。故我又重新修改了一下)。
所以根据估算,这个WoLF PSORT官网中一次提交的AA序列最多也是差不多500左右。与那个BUSCA网站的差不多。
若是一定要批量处理大量的AA序列,可以尝试运用爬虫:
(一个思路,其中结果页面的url无法获得)
import requests
import os
import pandas as pd
from bs4 import BeautifulSoupdef split_gene_file(source_file, output_folder, ids_per_file):os.makedirs(output_folder, exist_ok=True)current_file = Nonecount = 0with open(source_file, "r") as f:for line in f:if line.startswith(">"):count += 1if count % ids_per_file == 1:if current_file:current_file.close()output_file = f"{output_folder}/gene_file_{count // ids_per_file + 1}.csv"current_file = open(output_file, "w", encoding='utf-8')current_file.write(line)else:current_file.write(line)if current_file:current_file.close()split_gene_file("D:\yuceji\Lindera_aggregata.gene.pep", "gene1", 500)files = os.listdir("D:\python\PycharmProjects\pythonProject1\爬虫\gene1")base_url = "https://wolfpsort.hgc.jp/"
new_url = []
for i in range(len(files)):with open(f"D:\python\PycharmProjects\pythonProject1\爬虫\gene1\gene_file_{i + 1}.csv", "r") as f:aa_sequence = f.read()# 构建WoLFPSORT请求的数据data = {"seq": aa_sequence}# 发送POST请求到WoLFPSORT官网response = requests.post(base_url, data=data)print(response.status_code)print(response.text)# 检查请求是否成功if response.status_code == 200:# 解析结果页面的URLsoup = BeautifulSoup(response.content, "html.parser")result_links = soup.find_all("a", href=True)print(result_links)result_url = None# 遍历所有的链接for link in result_links:href = link.get("href", "")# 判断链接是否包含 "results"if "results" in href:result_url = base_url + hrefbreakif result_url:print(result_url)new_url.append(result_url)else:print("无法找到亚细胞定位结果页面的URL")for i in range(len(new_url)):# url = "https://wolfpsort.hgc.jp/results/pLAcbca22a5a0ccf7d913a9fc0fb140c3f4.html"r = requests.get(new_url[i])print(r.status_code)# print(r.encoding)text = r.text# print(text)lines = text.split("<BR>")AA_ID_list = []yaxibao_list = []for i in lines:if "details" in i:AA_ID = i.split("<A")[0].strip().split()[-1]yaxibao = i.split("details")[1].strip().split()[1][:-1]AA_ID_list.append(AA_ID)yaxibao_list.append(yaxibao)with open(f"yaxiba{i}o.csv", "w", encoding="utf-8") as f:f.write("AA_ID, yaxibao\n") # 写入列名for j in range(len(AA_ID_list)):f.write(f"{AA_ID_list[j]}, {yaxibao_list[j]}\n")这个爬虫代码中返回的url并不是我要的那种,例如:https://wolfpsort.hgc.jp/results/pLA2dbb41dafad4afb342b5000abcb263b1.html
而是:(如图所示)

我点进这个链接是这样的:

我也不知道为什么,只能等我再学学爬虫,希望之后能解决这个问题吧!(当然也希望有大佬能帮忙指教一下)
我还看了看结果页面的源代码(HTML语言):
怎么说呢,既然我不能爬取到结果页面的url,那我只能将结果页面url的获得的步骤放在官网中实现,而后面的结果整理则用代码实现。
总结
本章详细介绍了许多用于亚细胞定位的网站,其中,我还是比较推荐 WoLFPSORT这个网站的(简单易懂,十分好上手)。至于后续的代码实现我也是基于这个网站,但是因为爬虫学习还不到位(无法爬取到结果页面的url)。只能等以后在学习爬虫时,再修改。
羌笛何须怨杨柳,春风不度玉门关。
–2023-8-12 实验篇
相关文章:
实验篇——亚细胞定位
实验篇——亚细胞定位 文章目录 前言一、亚细胞定位的在线网站1. UniProt2. WoLFPSORT3. BUSCA4. TargetP-2.0 二、代码实现1. 基于UniProt(不会)2. 基于WoLFPSORT后续(已完善,有关代码放置于[python爬虫学习(一&#…...
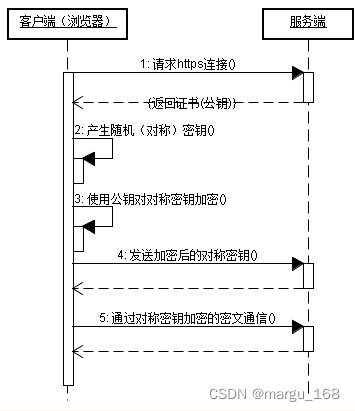
【日常积累】HTTP和HTTPS的区别
背景 在运维面试中,经常会遇到面试官提问http和https的区别,今天咱们先来简单了解一下。 超文本传输协议HTTP被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果…...

Qt creator之对齐参考线——新增可视化缩进功能
Qt creator随着官方越来越重视,更新频率也在不断加快,今天无意中发现qt creator新版有了对齐参考线,也称可视化缩进Visualize Indent,默认为启用状态。 下图为旧版Qt Creator显示设置栏: 下图为新版本Qt Creator显示设…...

Go语言之依赖管理
go module go module是Go1.11版本之后官方推出的版本管理工具,并且从Go1.13版本开始,go module将是Go语言默认的依赖管理工具。 GO111MODULE 要启用go module支持首先要设置环境变量GO111MODULE 通过它可以开启或关闭模块支持,它有三个可选…...

【定时任务处理中的分页问题】
最近要做一个定时任务处理的需求,在分页处理上。发现了大家容易遇到的一些"坑",特此分析记录一下。 场景 现在想象一下这个场景,你有一个定时处理任务,需要查询数据库任务表中的所有待处理任务,然后进行处理…...
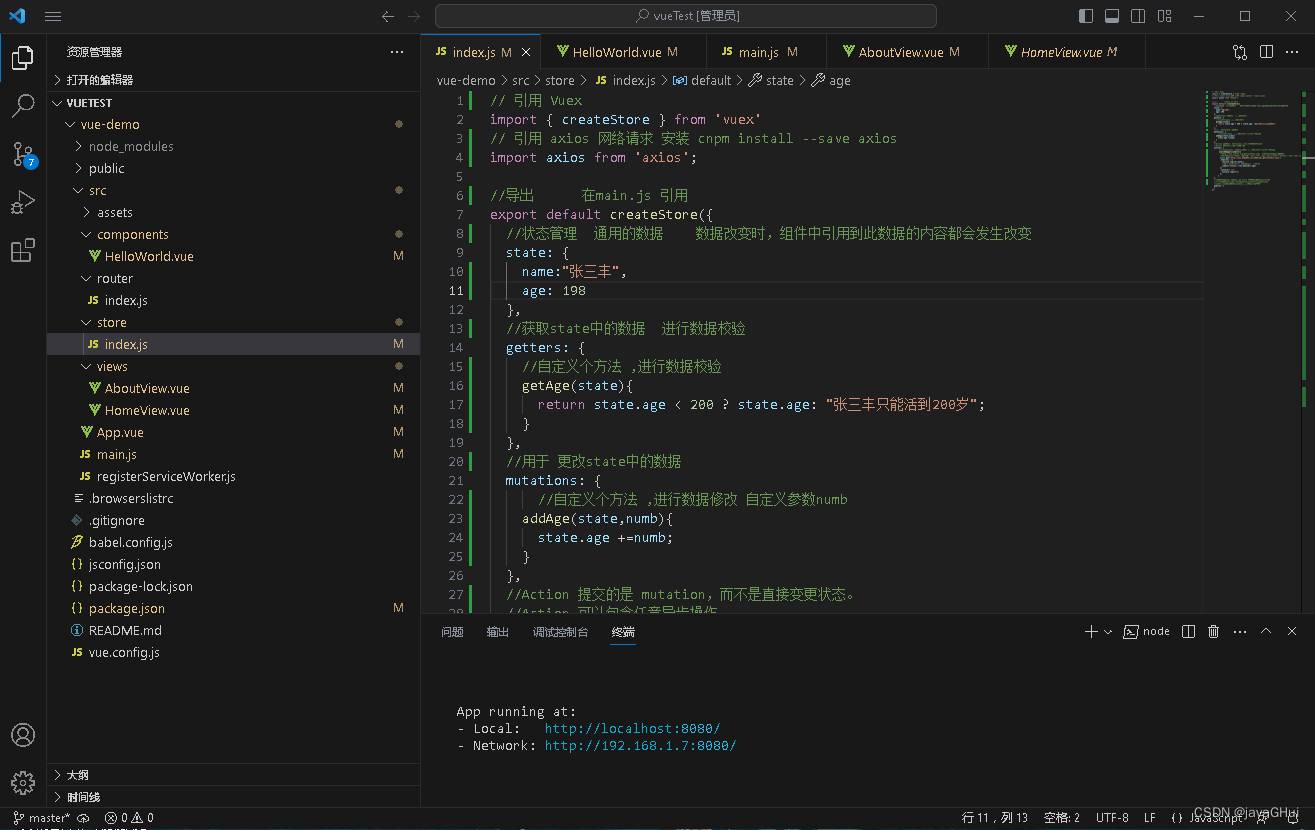
Vue3 Vuex状态管理多组件传递数据简单应用
去官网学习→安装 | Vuex cd 项目 安装 Vuex: npm install --save vuex 或着 创建项目时勾选Vuex vue create vue-demo ? Please pick a preset: Manually select features ? Check the features needed for your project: (Press <space> to se…...
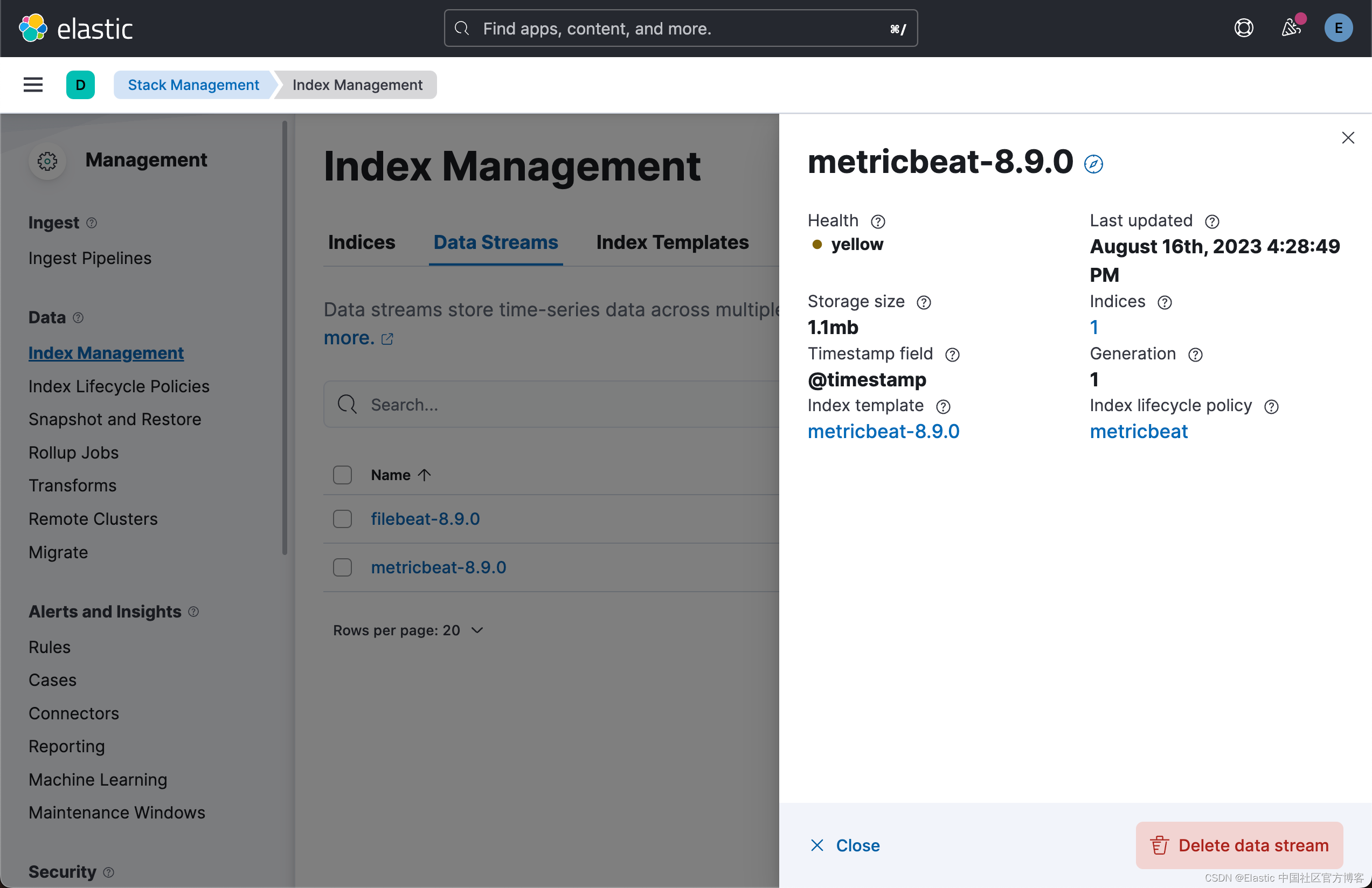
Beats:安装及配置 Metricbeat (一)- 8.x
在我之前的文章: Beats:Beats 入门教程 (一)Beats:Beats 入门教程 (二) 我详细描述了如何在 Elastic Stack 7.x 安装及配置 Beats。在那里的安装,它通常不带有安全及 Elasticsearc…...

openCV使用c#操作摄像头
效果如下: 1.创建一个winform的窗体项目(框架.NET Framework 4.7.2) 2.Nuget引入opencv的c#程序包(版本最好和我一致) 3.后台代码 using System; using System.Collections.Generic; using System.ComponentModel;…...

Centos 防火墙命令
查看防火墙状态 systemctl status firewalld.service 或者 firewall-cmd --state 开启防火墙 单次开启防火墙 systemctl start firewalld.service 开机自启动防火墙 systemctl enable firewalld.service 重启防火墙 systemctl restart firewalld.service 防火墙设置开…...
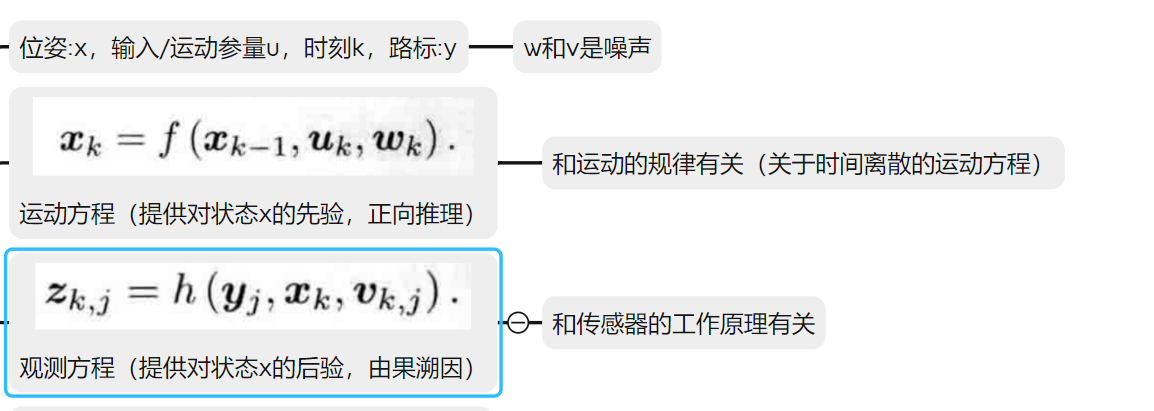
【第二讲---初识SLAM】
SLAM简介 视觉SLAM,主要指的是利用相机完成建图和定位问题。如果传感器是激光,那么就称为激光SLAM。 定位(明白自身状态(即位置))建图(了解外在环境)。 视觉SLAM中使用的相机与常见…...
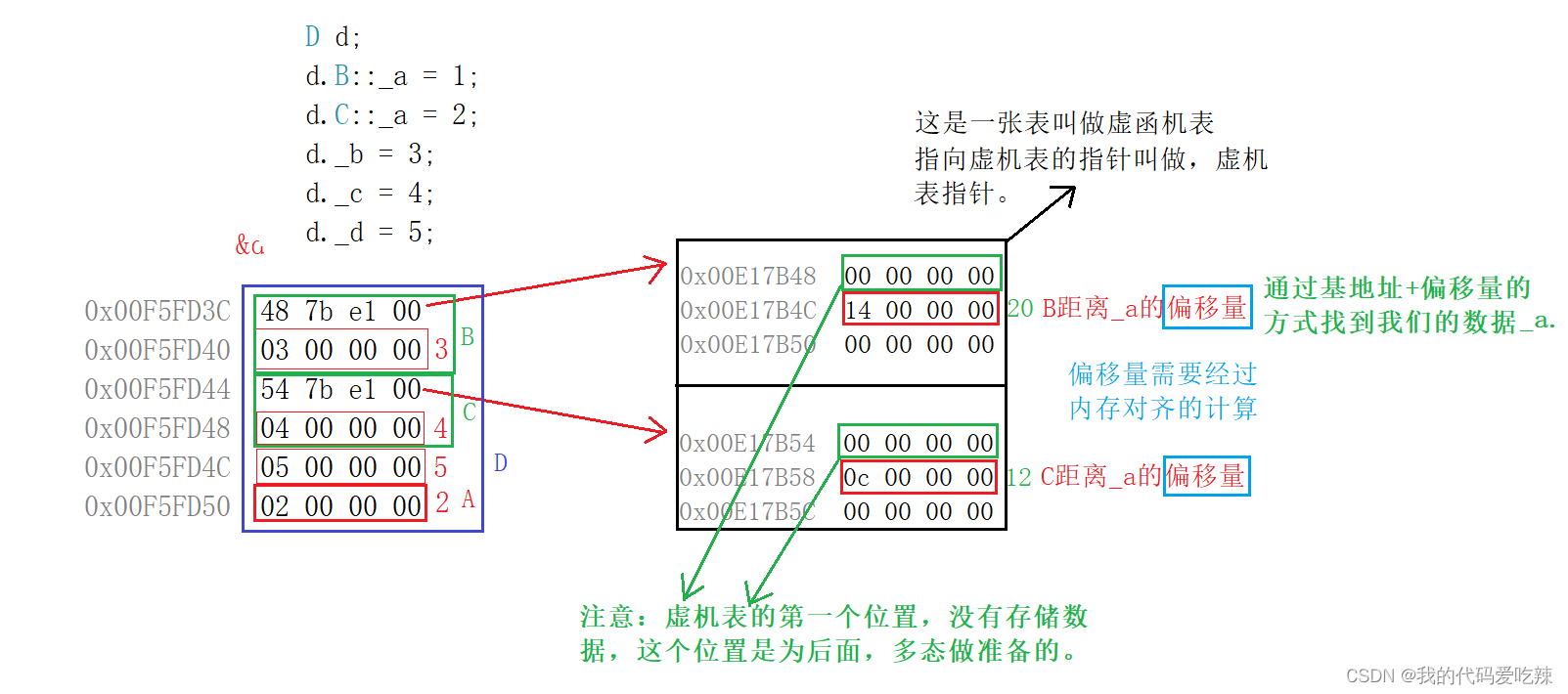
C++ 面向对象三大特性——继承
✅<1>主页:我的代码爱吃辣 📃<2>知识讲解:C 继承 ☂️<3>开发环境:Visual Studio 2022 💬<4>前言:面向对象三大特性的,封装,继承,多态ÿ…...
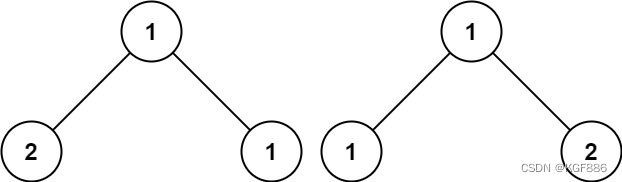
LC-相同的树
LC-相同的树 链接:https://leetcode.cn/problems/same-tree/solutions/363636/xiang-tong-de-shu-by-leetcode-solution/ 描述:给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。 如果两个树在结构上相同,并…...
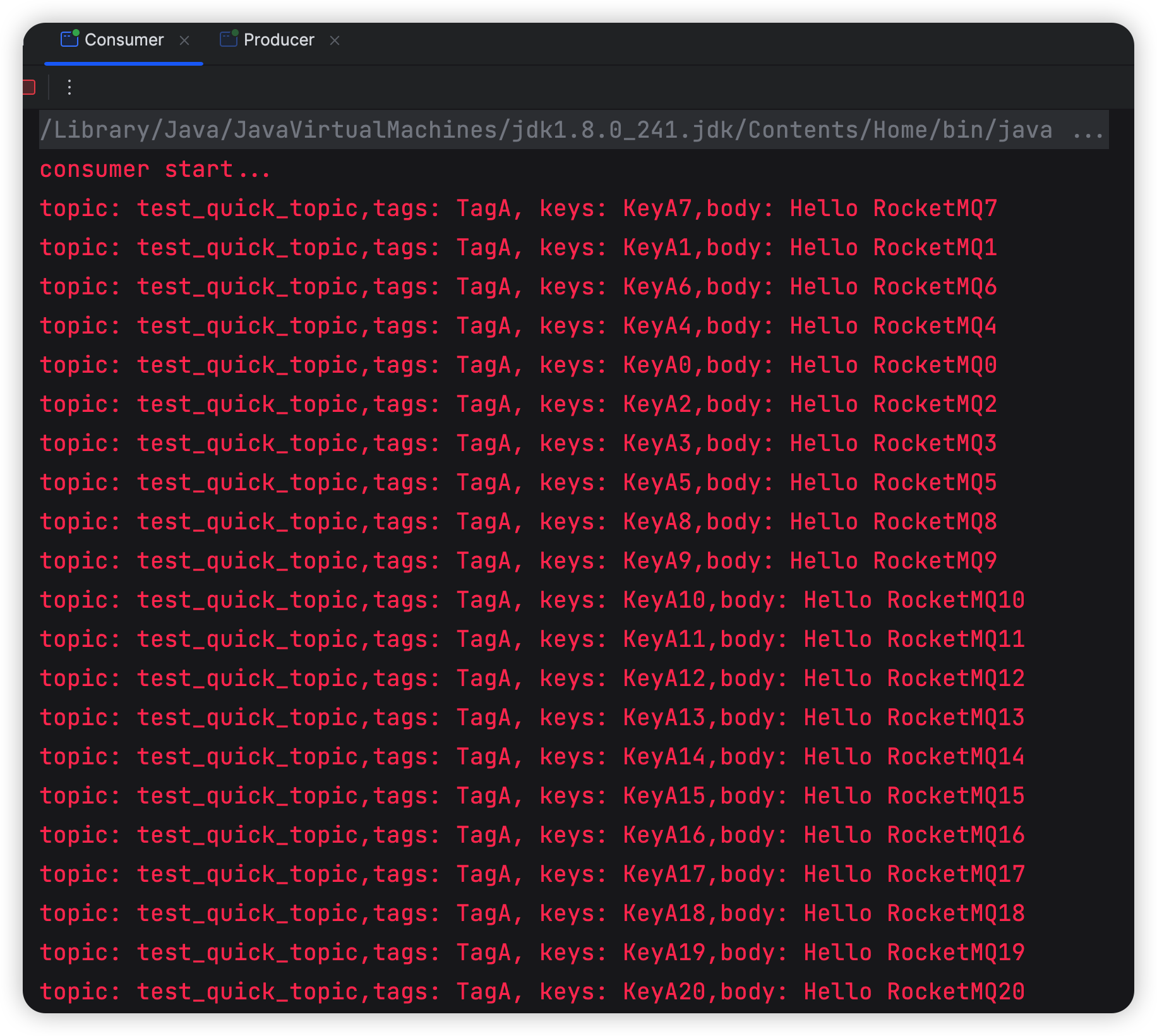
RocketMQ部署 Linux方式和Docker方式
一、Linux部署 准备一台Linux机器,部署单master rocketmq节点 系统ip角色模式CENTOS10.4.7.126Nameserver,brokerMaster 1. 配置JDK rocketmq运行需要依赖jdk,安装步骤略。 2. 下载和配置 从官网下载安装包 https://rocketmq.apache.org/zh/downlo…...
css内容达到最底部但滚动条没有滚动到底部
也是犯了一个傻狗一样的错误 ,滚动条样式是直接复制的蓝湖的代码,有个高度,然后就出现了这样的bug 看了好久一直以为是布局或者overflow的问题,最后发现是因为我给这个滚动条加了个高度,我也是傻狗一样的,…...
机器学习深度学习——transformer(机器翻译的再实现)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——自注意力和位置编码(数学推导代码实现) 📚订阅专栏:机器…...

神经网络基础-神经网络补充概念-30-搭建神经网络块
概念 搭建神经网络块是一种常见的做法,它可以帮助你更好地组织和复用网络结构。神经网络块可以是一些相对独立的模块,例如卷积块、全连接块等,用于构建更复杂的网络架构。 代码实现 import numpy as np import tensorflow as tf from tens…...

在线吉他调音
先看效果(图片没有声,可以下载源码看看,比这更好~): 再看代码(查看更多): <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8&quo…...
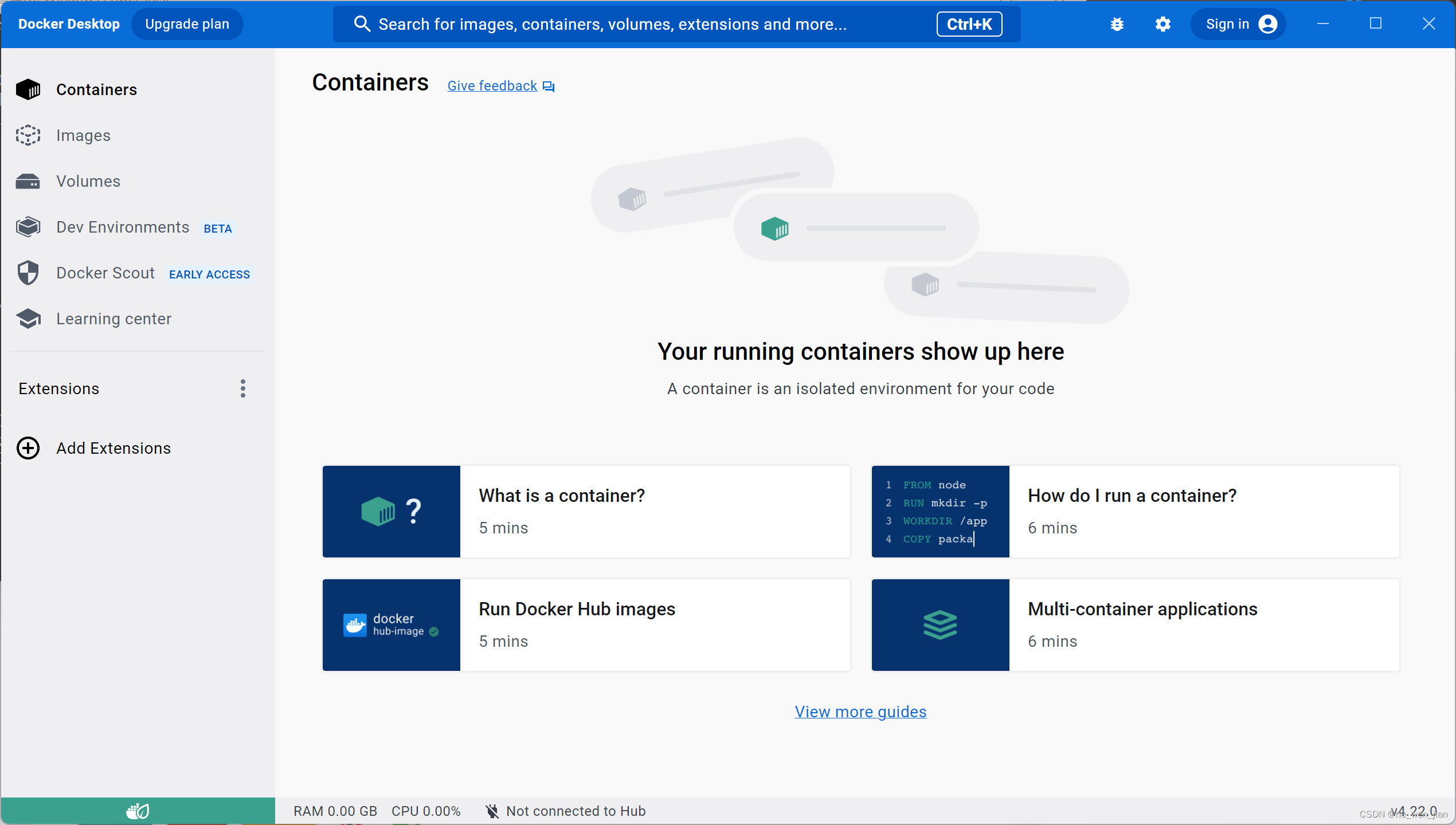
Windows11 Docker Desktop 启动 -wsl kernel version too low
系统环境:windows11 1:docker下载 Docker: Accelerated Container Application Development 下载后双击安装即可 安装后启动Docker提示:Docker Desktop -wsl kernel version too low 处理起来也是非常方便 1:管理员身份启动:…...

Golang 中的 unsafe 包详解
Golang 中的 unsafe 包用于在运行时进行低级别的操作。这些操作通常是不安全的,因为可以打破 Golang 的类型安全性和内存安全性,使用 unsafe 包的程序可能会影响可移植性和兼容性。接下来看下 unsafe 包中的类型和函数。 unsafe.Pointer 类型 通常用于…...

linux 的swap、swappiness及kswapd原理【转+自己理解】
本文讨论的 swap基于Linux4.4内核代码 。Linux内存管理是一套非常复杂的系统,而swap只是其中一个很小的处理逻辑。 希望本文能让读者了解Linux对swap的使用大概是什么样子。阅读完本文,应该可以帮你解决以下问题: swap到底是干嘛的…...

如何用applera1n免费绕过iOS激活锁:完整指南与操作教程
如何用applera1n免费绕过iOS激活锁:完整指南与操作教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone或iPad,却发现设备被原主人的Apple ID锁定&a…...
)
极简风项目交付倒计时!:紧急修复MJ --v 6.2中隐藏的1.33倍宽高比偏移Bug,避免客户验收驳回(含补救Prompt包)
更多请点击: https://intelliparadigm.com 第一章:极简风项目交付倒计时! 当交付周期压缩至 72 小时,极简风不再是一种美学选择,而是工程效率的刚性约束。我们摒弃冗余文档、跳过非核心评审环节,聚焦于可…...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...

终极解密指南:Windows平台NCM音频文件一键转换实战
终极解密指南:Windows平台NCM音频文件一键转换实战 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾因网易云音乐的NCM加密格式而烦恼&…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库
5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 凌晨两点,小林还在为明…...

如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南
如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_…...

Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南
Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or Ker…...
)
ElevenLabs葡语语音私密训练技巧(仅限白名单客户使用的SSML扩展语法+方言权重微调指令集)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs葡语语音私密训练的核心价值与白名单准入机制 ElevenLabs 的葡语语音私密训练(Private Voice Fine-tuning for Portuguese)专为高合规性场景设计,面向金融…...

开源AI代码助手实践:从数据到部署的全链路解析
1. 项目概述:从“copaw-code”看AI代码助手的开源实践最近在GitHub上看到一个挺有意思的项目,叫“QSEEKING/copaw-code”。光看这个名字,可能有点摸不着头脑。“copaw”这个词,听起来像是“co-pilot”(副驾驶ÿ…...