分布式 - 消息队列Kafka:Kafka生产者发送消息的分区策略
文章目录
- 01. Kafka 分区的作用
- 02. PartitionInfo 分区源码
- 03. Partitioner 分区器接口源码
- 04. 自定义分区器
- 05. 默认分区器 DefaultPartitioner
- 06. 随机分区分配 RoundRobinPartitioner
- 07. 黏性随机分区分配 UniformStickyPartitioner
- 08. 为什么Kafka 2.4 版本后引入黏性分区策略?
01. Kafka 分区的作用
分区的作用就是提供负载均衡的能力,或者说对数据进行分区的主要原因,就是为了实现系统的高伸缩性。不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处理。并且,我们还可以通过添加新的节点机器来增加整体系统的吞吐量。
除了提供负载均衡这种最核心的功能之外,利用分区也可以实现其他一些业务级别的需求,比如实现业务级别的消息顺序的问题。
生产者发送的消息实体 ProducerRecord 的构造方法:
public class ProducerRecord<K, V> {// ....public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) {this(topic, partition, timestamp, key, value, null);}public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) {this(topic, partition, null, key, value, headers);}public ProducerRecord(String topic, Integer partition, K key, V value) {this(topic, partition, null, key, value, null);}public ProducerRecord(String topic, K key, V value) {this(topic, null, null, key, value, null);}public ProducerRecord(String topic, V value) {this(topic, null, null, null, value, null);}}
我们发送消息时可以指定分区号,如果不指定那就需要分区器,这个很重要,一条消息该发往哪一个分区,关系到顺序消息问题。下面我们说说 Kafka 生产者的分区策略。所谓分区策略是决定生产者将消息发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略。
02. PartitionInfo 分区源码
/*** This is used to describe per-partition state in the MetadataResponse.*/
public class PartitionInfo {// 表示该分区所属的主题名称。private final String topic;// 表示该分区的编号。private final int partition;// 表示该分区的领导者节点。private final Node leader;// 表示该分区的所有副本节点。private final Node[] replicas;// 表示该分区的所有同步副本节点。private final Node[] inSyncReplicas;// 表示该分区的所有离线副本节点。private final Node[] offlineReplicas;public PartitionInfo(String topic, int partition, Node leader, Node[] replicas, Node[] inSyncReplicas) {this(topic, partition, leader, replicas, inSyncReplicas, new Node[0]);}public PartitionInfo(String topic,int partition,Node leader,Node[] replicas,Node[] inSyncReplicas,Node[] offlineReplicas) {this.topic = topic;this.partition = partition;this.leader = leader;this.replicas = replicas;this.inSyncReplicas = inSyncReplicas;this.offlineReplicas = offlineReplicas;}// ....
}
03. Partitioner 分区器接口源码
Kafka的Partitioner接口是用来决定消息被分配到哪个分区的。它定义了一个方法partition,该方法接收三个参数:topic、key和value,返回一个int类型的分区号,表示消息应该被分配到哪个分区。
public interface Partitioner extends Configurable {/*** Compute the partition for the given record.** @param topic The topic name* @param key The key to partition on (or null if no key)* @param keyBytes The serialized key to partition on( or null if no key)* @param value The value to partition on or null* @param valueBytes The serialized value to partition on or null* @param cluster The current cluster metadata*/int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);/*** This is called when partitioner is closed.*/default void close() {}
}
Partitioner接口的实现类可以根据不同的业务需求来实现不同的分区策略,例如根据消息的键、值、时间戳等信息来决定分区。
这里的topic、key、keyBytes、value和valueBytes都属于消息数据,cluster则是集群信息。Kafka 给你这么多信息,就是希望让你能够充分地利用这些信息对消息进行分区,计算出它要被发送到哪个分区中。
04. 自定义分区器
只要你自己的实现类定义好了 partition 方法,同时设置partitioner.class 参数为你自己实现类的 Full Qualified Name,那么生产者程序就会按照你的代码逻辑对消息进行分区。
① 实现自定义分区策略 MyPartitioner:
public class MyPartitioner implements Partitioner {private final AtomicInteger counter = new AtomicInteger(0);@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 获取该 topic 可用的所有分区信息List<PartitionInfo> partitionInfos = cluster.availablePartitionsForTopic(topic);int size = partitionInfos.size();if(keyBytes==null){// 如果 keyBytes 为 null,表示该消息没有 key,此时采用 round-robin 的方式将消息均匀地分配到不同的分区中。// 每次调用 getAndIncrement() 方法获取计数器的当前值并自增,然后对可用分区数取模,得到该消息应该被分配到的分区编号。return counter.getAndIncrement() % size;}else{// 如果 keyBytes 不为 null,表示该消息有 key,此时采用 murmur2 哈希算法将 key 转换为一个整数值,并对可用分区数取模,得到该消息应该被分配到的分区编号。return Utils.toPositive(Utils.murmur2(keyBytes) % size);}}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> map) {}
}
② 显式地配置生产者端的参数 partitioner.class:
public class CustomProducer01 {private static final String brokerList = "10.65.132.2:9093";private static final String topic = "test";public static Properties initConfig(){Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,brokerList);properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 使用自定义分区器properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class.getName());return properties;}public static void main(String[] args) {// kafka生产者属性配置Properties properties = initConfig();// kafka生产者发送消息,默认是异步发送方式KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topic, "你好,kafka,使用自定义分区器");kafkaProducer.send(producerRecord, new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if(e==null){System.out.println("recordMetadata发送的分区为:"+recordMetadata.partition());}}});// 关闭资源kafkaProducer.close();}
}
05. 默认分区器 DefaultPartitioner
ProducerRecord对象包含了主题名称、分区、记录的键和值。
① 如果发送的消息ProducerRecord指定了分区,就直接使用该分区,不会使用分区器;
ProducerRecord<String, String> record = new ProducerRecord<>("test",2,"hh","你好");
对应源码:
public class KafkaProducer<K, V> implements Producer<K, V> {// 如果消息记录具有分区,则返回该值,否则调用配置的分区器类来计算分区。private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {// 如果记录中指定了分区,则使用该分区,否则调用分区器计算分区 Integer partition = record.partition();return partition != null ?partition :partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);}
}
② Kafka消息就是一个个的键–值对,ProducerRecord对象可以只包含主题名称和值,键默认情况下是null。不过,大多数应用程序还是会用键来发送消息。键有两种用途:一是作为消息的附加信息与消息保存在一起,二是用来确定消息应该被写入主题的哪个分区。具有相同键的消息将被写入同一个分区。如果一个进程只从主题的某些分区读取数据,那么具有相同键的所有记录都会被这个进程读取。要创建一个包含键和值的记录,只需像下面这样创建一个ProducerRecord即可:
ProducerRecord<String, String> record = new ProducerRecord<>("test","hh","你好");
如果键不为空,并且使用了默认的分区器,那么Kafka会对键进行哈希(使用Kafka自己的哈希算法,即使升级Java版本,哈希值也不会发生变化),然后根据哈希值把消息映射到特定的分区。这里的关键在于同一个键总是被映射到同一个分区,所以在进行映射时,会用到主题所有的分区,而不只是可用的分区。这也意味着,如果在写入数据时目标分区不可用,那么就会出错。不过这种情况很少发生。

③ 如果要创建键为null的消息,那么不指定键就可以了:
ProducerRecord<String, String> record = new ProducerRecord<>("test","你好");
如果键为null,并且使用了默认的分区器,那么记录将被随机发送给主题的分区。分区器使用轮询调度(round-robin)算法将消息均衡地分布到各个分区中。从Kafka 2.4开始,在处理键为null的记录时,默认分区器使用的轮询调度算法具备了黏性。也就是说,在切换到下一个分区之前,它会将同一个批次的消息全部写入当前分区。这样就可以使用更少的请求发送相同数量的消息,既降低了延迟,又减少了broker占用CPU的时间。
如果使用了默认的分区器,那么只有在不改变主题分区数量的情况下键与分区之间的映射才能保持一致。例如,只要分区数量保持不变,就可以保证用户045189的记录总是被写到分区34。这样就可以在从分区读取数据时做各种优化。但是,一旦主题增加了新分区,这个就无法保证了——旧数据仍然留在分区34,但新记录可能被写到了其他分区。如果要使用键来映射分区,那么最好在创建主题时就把分区规划好,而且永远不要增加新分区。
/**默认的分区策略如下:如果记录中指定了分区,则使用该分区。如果未指定分区但存在键,则根据键的哈希值选择一个分区。如果既没有指定分区也没有键,则选择一个“粘性分区”,当批处理满时更改。(kafka 2.4 版本以后)*/
public class DefaultPartitioner implements Partitioner {private final StickyPartitionCache stickyPartitionCache = new StickyPartitionCache();public void configure(Map<String, ?> configs) {}public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {return partition(topic, key, keyBytes, value, valueBytes, cluster, cluster.partitionsForTopic(topic).size());}public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,int numPartitions) {// 如果键为null,则随机选择一个粘性分区 if (keyBytes == null) {return stickyPartitionCache.partition(topic, cluster);}// 如果键不为空,那么Kafka会对键进行哈希,然后根据哈希值把消息映射到特定的分区。// 使用 MurmurHash2 算法计算给定字节数组的哈希值。return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}public void close() {}/*** 如果当前的粘性分区已经完成了一个批次,更改粘性分区。 * 如果尚未确定粘性分区,设置一个粘性分区。*/public void onNewBatch(String topic, Cluster cluster, int prevPartition) {stickyPartitionCache.nextPartition(topic, cluster, prevPartition);}
}
用于粘性分区行为的缓存:
/*** 一个内部类,实现了用于粘性分区行为的缓存。该缓存跟踪任何给定主题的当前粘性分区。 */
public class StickyPartitionCache {// ConcurrentMap类型的indexCache成员变量,用于存储主题和其对应的粘性分区。private final ConcurrentMap<String, Integer> indexCache;public StickyPartitionCache() {this.indexCache = new ConcurrentHashMap<>();}// 获取给定主题的当前粘性分区。如果该主题的粘性分区尚未设置,则返回下一个分区。public int partition(String topic, Cluster cluster) {Integer part = indexCache.get(topic);if (part == null) {return nextPartition(topic, cluster, -1);}return part;}// 获取给定主题的下一个粘性分区。 public int nextPartition(String topic, Cluster cluster, int prevPartition) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);// 获取给定主题的粘性分区Integer oldPart = indexCache.get(topic);Integer newPart = oldPart;if (oldPart == null || oldPart == prevPartition) {// 如果没有可用分区,则从所有分区列表中随机选择一个可用分区List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);if (availablePartitions.size() < 1) {Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());newPart = random % partitions.size();// 如果只有一个可用分区,则选择该分区} else if (availablePartitions.size() == 1) {newPart = availablePartitions.get(0).partition();// 从可用分区列表中随机选择一个分区} else {while (newPart == null || newPart.equals(oldPart)) {int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());newPart = availablePartitions.get(random % availablePartitions.size()).partition();}}if (oldPart == null) {indexCache.putIfAbsent(topic, newPart);} else {indexCache.replace(topic, prevPartition, newPart);}return indexCache.get(topic);}return indexCache.get(topic);}
}
除了默认的分区器,Kafka客户端还提供了RoundRobinPartitioner和UniformStickyPartitioner。在消息不包含键的情况下,可以用它们来实现随机分区分配和黏性随机分区分配。对某些应用程序(例如,ETL应用程序会将数据从Kafka加载到关系数据库中,并使用Kafka记录的键作为数据库的主键)来说,键很重要,但如果负载出现了倾斜,那么其中某些键就会对应较大的负载。这个时候,可以用UniformStickyPartitioner将负载均衡地分布到所有分区。
06. 随机分区分配 RoundRobinPartitioner
RoundRobinPartitioner 分区器使用轮询调度(round-robin)算法将消息均衡地分布到各个分区中。在Kafka 2.4版本之前,在处理键为null的记录时,默认分区器使用的便是轮询调度算法。
轮询调度(round-robin)算法即顺序分配。比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0,就像下面这张图展示的那样。

轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上。RoundRobinPartitioner源码:
/*** The "Round-Robin" partitioner:当用户希望将写操作平均分配到所有分区时,可以使用此分区策略。 */
public class RoundRobinPartitioner implements Partitioner {private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>();public void configure(Map<String, ?> configs) {}@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 获取该 topic 所有的分区List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();int nextValue = nextValue(topic);// 获取该 topic 所有可用的分区List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);if (!availablePartitions.isEmpty()) {// 取模,从可用的分区列表中获取分区// Utils.toPositive(nextValue) 的作用是将传入的参数 nextValue 转换为正数。// 如果 nextValue 是负数,则返回 0,否则返回 nextValue 的值。int part = Utils.toPositive(nextValue) % availablePartitions.size();return availablePartitions.get(part).partition();} else {// no partitions are available, give a non-available partition// 取模,从分区列表中获取分区return Utils.toPositive(nextValue) % numPartitions;}}private int nextValue(String topic) {// 在ConcurrentMap中插入一个键值对,如果该键不存在,则使用AtomicInteger的默认值0初始化值// 如果该键已经存在,则返回与该键关联的AtomicInteger对象。AtomicInteger counter = topicCounterMap.computeIfAbsent(topic, k -> {return new AtomicInteger(0);});// 使用返回的AtomicInteger对象对值进行原子操作,增加值return counter.getAndIncrement();}public void close() {}
}
07. 黏性随机分区分配 UniformStickyPartitioner
黏性分区策略会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成时切换分区。
UniformStickyPartitioner 实现源码:
/*** The partitioning strategy:如果记录中指定了分区,则使用该分区;否则选择粘性分区,当批处理满时会更改该分区。*/
public class UniformStickyPartitioner implements Partitioner {private final StickyPartitionCache stickyPartitionCache = new StickyPartitionCache();public void configure(Map<String, ?> configs) {}public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// StickyPartitionCache 获取粘性分区return stickyPartitionCache.partition(topic, cluster);}public void close() {}/*** 如果当前的粘性分区已经完成了一个批次,请更改粘性分区。* 如果尚未确定粘性分区,设置一个粘性分区。*/public void onNewBatch(String topic, Cluster cluster, int prevPartition) {stickyPartitionCache.nextPartition(topic, cluster, prevPartition);}
}
08. 为什么Kafka 2.4 版本后引入黏性分区策略?
① 提升发送性能(减少碎片化发送请求)
一般情况下,一个Kafka Topic会有多个分区。Kafka Producer客户端在向服务端发送消息时,需要先确认往哪个Topic的哪个分区发送。我们给同一个分区发送多条消息时,Producer客户端将相关消息打包成一个Batch,批量发送到服务端。Producer客户端在处理Batch时,是有额外开销的。一般情况下,小Batch会导致Producer客户端产生大量请求,造成请求队列在客户端和服务端的排队,并造成相关机器的CPU升高,从而整体推高了消息发送和消费延迟。一个合适的Batch大小,可以减少发送消息时客户端向服务端发起的请求次数,在整体上提高消息发送的吞吐和延迟。
Batch机制,Kafka Producer端主要通过两个参数进行控制:
batch.size: 发往每个分区(Partition)的消息缓存量(消息内容的字节数之和,不是条数)。达到设置的数值时,就会触发一次网络请求,然后Producer客户端把消息批量发往服务器。如果batch.size设置过小,有可能影响发送性能和稳定性。建议保持默认值16384。单位:字节。linger.ms: 每条消息在缓存中的最长时间。若超过这个时间,Producer客户端就会忽略batch.size的限制,立即把消息发往服务器。建议根据业务场景, 设置linger.ms在100~1000之间。单位:毫秒。
因此,Kafka Producer客户端什么时候把消息批量发送至服务器是由batch.size和linger.ms共同决定的。您可以根据具体业务需求进行调整。为了提升发送的性能,保障服务的稳定性, 建议您设置batch.size=16384和linger.ms=1000。
② 只有发送到相同分区的消息,才会被放到同一个Batch中,因此决定一个Batch如何形成的一个因素是Kafka Producer端设置的分区策略。 Kafka Producer允许通过设置Partitioner的实现类来选择适合自己业务的分区。
在消息指定Key的情况下,Kafka Producer的默认策略是对消息的Key进行哈希,然后根据哈希结果选择分区,保证相同Key的消息会发送到同一个分区。
在消息没有指定Key的情况下,Kafka 版2.4版本之前的默认策略是循环使用主题的所有分区,将消息以轮询的方式发送到每一个分区上。但是,这种默认策略Batch的效果会比较差,在实际使用中,可能会产生大量的小Batch,从而使得生产者延迟增加。鉴于该默认策略对无Key消息的分区效率低问题,Kafka 在2.4版本引入了黏性分区策略(Sticky Partitioning Strategy)。
黏性分区策略主要解决无Key消息分散到不同分区,造成小Batch问题。其主要策略是如果一个分区的Batch完成后,就随机选择另一个分区,然后后续的消息尽可能地使用该分区。这种策略在短时间内看,会将消息发送到同一个分区,如果拉长整个运行时间,消息还是可以均匀地发布到各个分区上的。这样可以避免消息出现分区倾斜,同时还可以降低延迟,提升服务整体性能。
如果您使用的 KafkaProducer客户端是2.4及以上版本,在未指定分区和消息键的情况下,默认的分区策略就采用黏性分区策略。如果您使用的Producer客户端版本小于2.4,可以根据黏性分区策略原理,自行实现分区策略,然后通过参数partitioner.class设置指定的分区策略。
关于黏性分区策略实现,可以参考如下代码实现:该代码的实现逻辑主要是根据一定的时间间隔,切换一次分区。
public class MyStickyPartitioner implements Partitioner {// 记录上一次切换分区时间。private long lastPartitionChangeTimeMillis = 0L;// 记录当前分区。private int currentPartition = -1;// 分区切换时间间隔,可以根据实际业务选择切换分区的时间间隔。private long partitionChangeTimeGap = 100L;public void configure(Map<String, ?> configs) {}public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 获取所有分区信息。List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();if (keyBytes == null) {List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);int availablePartitionSize = availablePartitions.size();// 判断当前可用分区。if (availablePartitionSize > 0) {handlePartitionChange(availablePartitionSize);return availablePartitions.get(currentPartition).partition();} else {handlePartitionChange(numPartitions);return currentPartition;}} else {// 对于有key的消息,根据key的哈希值选择分区。return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}}private void handlePartitionChange(int partitionNum) {long currentTimeMillis = System.currentTimeMillis();// 如果超过分区切换时间间隔,则切换下一个分区,否则还是选择之前的分区。if (currentTimeMillis - lastPartitionChangeTimeMillis >= partitionChangeTimeGap|| currentPartition < 0 || currentPartition >= partitionNum) {lastPartitionChangeTimeMillis = currentTimeMillis;currentPartition = Utils.toPositive(ThreadLocalRandom.current().nextInt()) % partitionNum;}}public void close() {}
}
相关文章:
分布式 - 消息队列Kafka:Kafka生产者发送消息的分区策略
文章目录 01. Kafka 分区的作用02. PartitionInfo 分区源码03. Partitioner 分区器接口源码04. 自定义分区器05. 默认分区器 DefaultPartitioner06. 随机分区分配 RoundRobinPartitioner07. 黏性随机分区分配 UniformStickyPartitioner08. 为什么Kafka 2.4 版本后引入黏性分区策…...
从源代码编译构建Hive3.1.3
从源代码编译构建Hive3.1.3 编译说明编译Hive3.1.3更改Maven配置下载源码修改项目pom.xml修改hive源码修改说明修改standalone-metastore模块修改ql模块修改spark-client模块修改druid-handler模块修改llap-server模块修改llap-tez模块修改llap-common模块 编译打包异常集合异常…...
探索性测试及基本用例
1 测试决策5要素 测试目标:所有的重要任务都完成了,而剩下没做的事情是比较次要的,我们做到这一点就可以尽早尽可能地降低发布风险。 测试方法:测试是一个不断抉择的过程,测试人员必须理解运行测试用例时和分析现有信…...
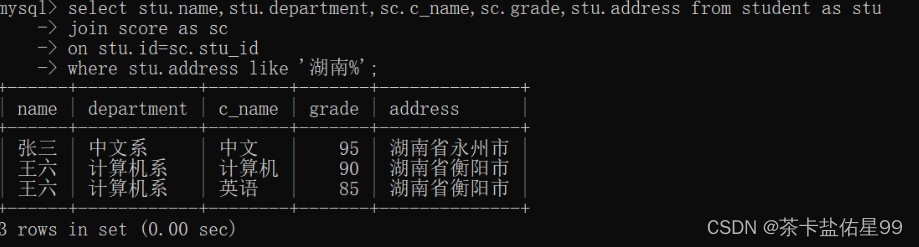
MYSQL 作业三
创建一个student表格: create table student( id int(10) not null unique primary key, name varchar(20) not null, sex varchar(4), birth year, department varchar(20), address varchar(50) ); 创建一个score表格 create table score( id int(10) n…...

【深度学习 | 感知器 MLP(BP神经网络)】掌握感知的艺术: 感知器和MLP-BP如何革新神经网络
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...

Kali Linux中常用的渗透测试工具有哪些?
今天我们将继续探讨Kali Linux的应用,这次的重点是介绍Kali Linux中常用的渗透测试工具。Kali Linux作为一款专业的渗透测试发行版,拥有丰富的工具集,能够帮助安全专家和渗透测试人员检测和评估系统的安全性。 1. 常用的渗透测试工具 以下是…...
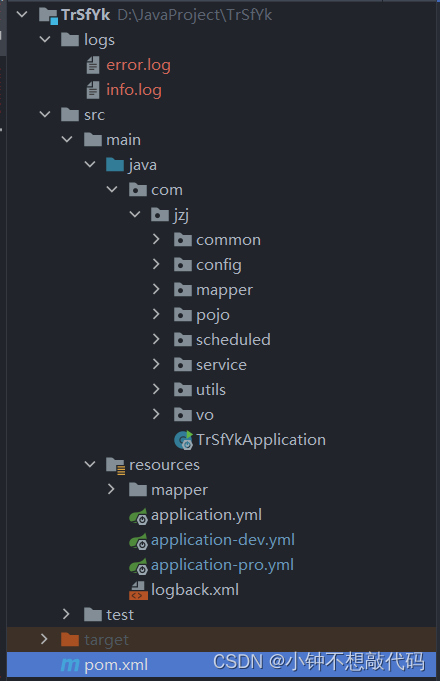
SpringBoot案例 调用第三方接口传输数据
一、前言 最近再写调用三方接口传输数据的项目,这篇博客记录项目完成的过程,方便后续再碰到类似的项目可以快速上手 项目结构: 二、编码 这里主要介绍HttpClient发送POST请求工具类和定时器的使用,mvc三层架构编码不做探究 pom.x…...

第三章,矩阵,08-矩阵的秩及相关性质
第三章,矩阵,08-矩阵的秩及相关性质 秩的定义1最高阶非零子式定理秩的定义2秩的性质性质1性质2性质3性质4性质5性质6性质7性质8性质9性质10性质11性质12性质12的推论 玩转线性代数(20)矩阵的秩的笔记,相关证明以及例子见原文 秩的定义1 设矩…...
VS2019 + Qt : setToolTip的提示内容出现乱码
VS2019 Qt : setToolTip的提示内容出现乱码 在使用setToolTip()时, setToolTip(QString("asd你好!");标签提示只有英文是对的,中文是乱码! 应该是编码出了问题。默认情况下,Qt使用的是UTF-8编码…...

PO、BO、VO、DTO、DAO、POJO
文章目录 PO(Persistant Object)持久对象DO(Data Object)数据对象AO(Application Object)应用对象BO(Business Object)业务对象VO(Value Object)表现对象DTO&…...
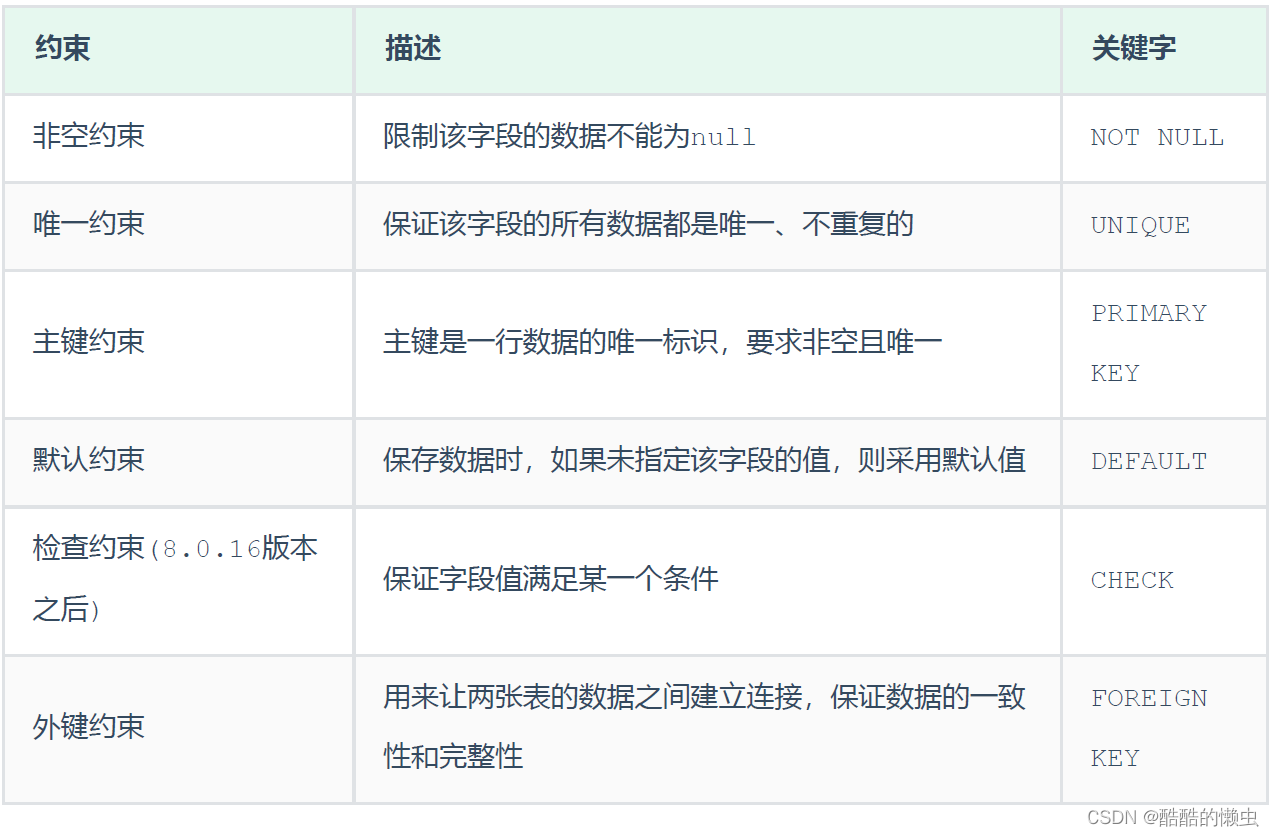
MySQL— 基础语法大全及操作演示!!!(下)
MySQL—— 基础语法大全及操作演示(下)—— 持续更新 三、函数3.1 字符串函数3.2 数值函数3.3 日期函数3.4 流程函数 四、约束4.1 概述4.2 约束演示4.3 外键约束4.3.1 介绍4.3.2 语法4.3.3 删除/更新行为 五、多表查询5.1 多表关系5.1.1 一对多5.1.2 多对…...

Springboot+vue网上招聘系统
系统的首页,头部有三个选项框,第一个是主页,第二个是才艺技能平台,第三个是登录注册。1.1.2 登录注册模块 系统的登录注册包括登录和注册两个部分。所有系统用户使用后台管理功能都需要经行登录,根据选择不同的身份进入…...

奥威BI数据可视化工具:报表就是平台,随时自助分析
别的数据可视化工具,报表就只是报表,而奥威BI数据可视化工具,一张报表就约等于一个平台,可随时展开多维动态自助分析,按需分析,立得数据信息。 奥威BI是一款多维立体分析数据的数据可视化工具。它可以帮助…...

iPhone(iPad)安装deb文件
最简单的方法就是把deb相关的文件拖入手机对应的目录,一般是DynamicLibraries文件夹 参考:探讨手机越狱和安装deb文件的几种方式研究 1、在 Mac 上安装 dpkg 命令 打包 deb 教程之在 Mac 上安装 dpkg 命令_xcode打包root权限deb_qq_34810996的博客-CS…...
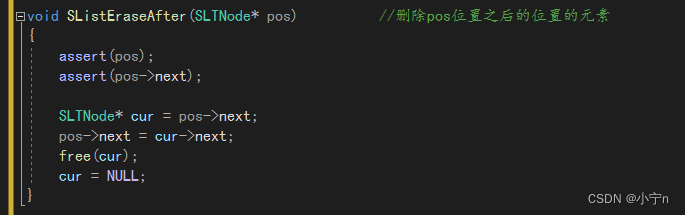
手撕单链表
目录 链表的概念和结构 单链表的实现 申请新结点 打印 尾插 头插 尾删 头删 编辑 查找 在pos位置前插入元素 在pos位置后插入元素 删除pos位置的元素 删除pos位置之后的位置的元素编辑 完整代码 SListNode.h SListNode.c 链表的概念和结构 链表是一种物理存储…...
Spring-aop特点,专业术语及案例演示
一.aop简介 AOP(Aspect-Oriented Programming)是Spring框架的一个重要特性,它通过将横切关注点(cross-cutting concerns)从核心业务逻辑中分离出来,以模块化的方式在整个应用程序中重复使用。以下是关于AOP…...

探秘Java的Map集合:键值映射的奇妙世界
文章目录 1. 单列集合 vs. 双列集合2. Map接口:键与值的契约3. 深入探索HashMap3.1 特性与构造方法3.2 常用方法3.3 遍历HashMap 4. 美妙的LinkedHashMap 在Java编程中,集合是不可或缺的重要部分,它为我们提供了各种数据结构和算法的实现。其…...

git权限问题解决方法Access denied fatal: Authentication failed
文章目录 遇到Access denied 的权限问题解决方法1、git的密码修改过,但是本地没更新。2、确定问题,然后增加配置① 查询用户信息②如果名称和email不对,设置名称:③ 检查ssh-add是否链接正常④ 设置不要每次都输入用户名密码 3、配…...
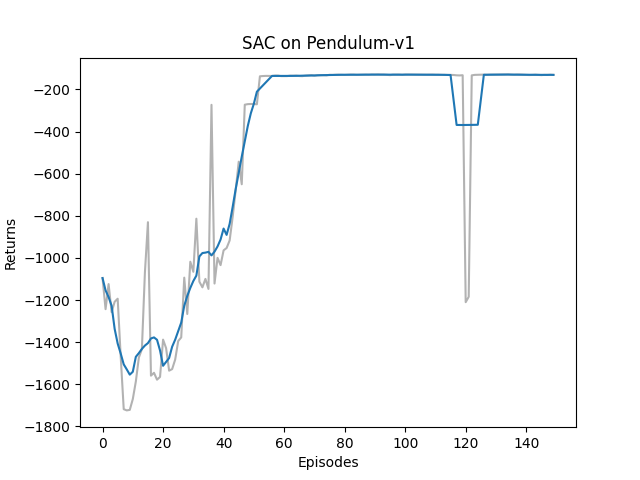
Hands on RL 之 Off-policy Maximum Entropy Actor-Critic (SAC)
Hands on RL 之 Off-policy Maximum Entropy Actor-Critic (SAC) 文章目录 Hands on RL 之 Off-policy Maximum Entropy Actor-Critic (SAC)1. 理论基础1.1 Maximum Entropy Reinforcement Learning, MERL1.2 Soft Policy Evaluation and Soft Policy Improvement in SAC1.3 Tw…...

JavaScript中的this指向,call、apply、bind的简单实现
JavaScript中的this this是JavaScript中一个特殊关键字,用于指代当前执行上下文中的对象。它的难以理解之处就是值不是固定的,是再函数被调用时根据调用场景动态确定的,主要根据函数的调用方式来决定this指向的对象。this 的值在函数被调用时…...

mRNA疫苗序列生物信息学分析:从密码子优化到免疫原性预测
1. 项目概述:解码两大mRNA疫苗的“核心蓝图”作为一名在生物信息学和基因组学领域摸爬滚打了十多年的“老码农”,我见过太多令人兴奋的数据集,但当我第一次在GitHub上看到这个名为“Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-se…...

ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题
ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI动画创作中,ComfyUI的Vi…...

从PUMA560到你的项目:手把手教你将经典DH建模流程迁移到自定义机械臂
从PUMA560到自定义机械臂:DH建模实战迁移指南 当机械臂从教科书案例走向真实项目时,最令人头疼的莫过于面对一个全新构型却不知如何下手。本文将以工业界经典的PUMA560为跳板,拆解一套可迁移的DH建模方法论,带您跨越从理论到实践的…...

VHD2VL:破解硬件描述语言转换难题的开源解决方案
VHD2VL:破解硬件描述语言转换难题的开源解决方案 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA和ASIC设计领域,技术团队常常面临VHDL与Verilog两种硬件描述语言之间的转换挑战。当项目需要跨语言协作、工…...

Flutter GetX实战:从Provider迁移到GetX,我的开发效率提升了多少?
Flutter GetX实战:从Provider迁移到GetX的效率革命 当Flutter开发团队面临状态管理方案的选择时,往往会陷入一种甜蜜的烦恼——官方推荐的Provider虽然稳定可靠,但第三方库GetX却以"全家桶"式的解决方案不断吸引开发者的目光。作为…...

如何快速免费管理游戏DLSS版本?DLSS Swapper终极指南
如何快速免费管理游戏DLSS版本?DLSS Swapper终极指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的开源工具,专为PC游戏玩家设计,能够智能管理、下载和…...

如何快速解密网易云NCM文件:终极免费转换工具指南
如何快速解密网易云NCM文件:终极免费转换工具指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲,…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧
窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的应用程序窗口而束手无策吗?是…...

本地化AI代码助手LLMDog:模块化框架与开源模型集成实践
1. 项目概述:一个为开发者设计的本地化AI代码助手最近在GitHub上闲逛,发现了一个挺有意思的项目叫“LLMDog”,作者是doganarif。乍一看这个名字,可能会联想到“AI狗”或者某种宠物,但它的全称其实是“Large Language M…...