模型预测笔记(一):数据清洗及可视化、模型搭建、模型训练和预测代码一体化和对应结果展示(可作为baseline)
模型预测
- 一、导入关键包
- 二、如何载入、分析和保存文件
- 三、修改缺失值
- 3.1 众数
- 3.2 平均值
- 3.3 中位数
- 3.4 0填充
- 四、修改异常值
- 4.1 删除
- 4.2 替换
- 五、数据绘图分析
- 5.1 饼状图
- 5.1.1 绘制某一特征的数值情况(二分类)
- 5.2 柱状图
- 5.2.1 单特征与目标特征之间的图像
- 5.2.2 多特征与目标特征之间的图像
- 5.3 折线图
- 5.3.1 多个特征之间的关系图
- 5.4 散点图
- 六、相关性分析
- 6.1 皮尔逊相关系数
- 6.2 斯皮尔曼相关系数
- 6.3 肯德尔相关系数
- 6.4 计算热力图
- 七、数据归一化
- 八、模型搭建
- 九、模型训练
- 十、评估模型
- 十一、预测模型
一、导入关键包
# 导入数据分析需要的包
import pandas as pd
import numpy as np
# 可视化包
import seaborn as sns
sns.set(style="whitegrid")
import matplotlib.pyplot as plt
%matplotlib inline
# 忽略警告信息
import warnings
warnings.filterwarnings('ignore')
# 导入数据分析需要的包
import pandas as pd
import numpy as np
from datetime import datetime# 构建多个分类器
from sklearn.ensemble import RandomForestClassifier # 随机森林
from sklearn.svm import SVC, LinearSVC # 支持向量机
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.neighbors import KNeighborsClassifier # KNN算法
from sklearn.naive_bayes import GaussianNB # 朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier # 决策树分类器
from xgboost import XGBClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import precision_score, recall_score, f1_score
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV # 网格搜索
np.set_printoptions(suppress=True)# 显示中文
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
二、如何载入、分析和保存文件
df=pd.read_csv('data/dataset.csv')df.head(5)# 查看前几列数据
df.tail() # 返回CSV文件的最后几行数据。
df.info() # 显示CSV文件的基本信息,包括数据类型、列数、行数、缺失值等。
df.describe()# 对CSV文件的数值型数据进行统计描述,包括计数、均值、标准差、最小值、最大值等。
df.shape()# 返回CSV文件的行数和列数。
df.unique() # 返回CSV文件中某一列的唯一值。
df.value_counts()# 计算CSV文件中某一列中每个值的出现次数。
df.groupby() # 按照某一列的值进行分组,并对其他列进行聚合操作,如求和、计数、平均值等。
df.sort_values()# 按照某一列的值进行排序。
df.pivot_table()# 创建透视表,根据指定的行和列对数据进行汇总和分析。# 保存处理后的数据集
df.to_csv('data/Telecom_data_flag.csv')
三、修改缺失值
3.1 众数
# 对每一列属性采用相应的缺失值处理方式,通过分析发现这类数据都可以采用众数的方式解决
df.isnull().sum()
modes = df.mode().iloc[0]
print(modes)
df = df.fillna(modes)
print(df.isnull().sum())
3.2 平均值
mean_values = df.mean()
print(mean_values)
df = df.fillna(mean_values)
print(df.isnull().sum())
3.3 中位数
median_values = df.median()
print(median_values)
df = df.fillna(median_values)
print(df.isnull().sum())
3.4 0填充
df = df.fillna(0)
print(df.isnull().sum())
四、修改异常值
4.1 删除
1.删除DataFrame表中全部为NaN的行
your_dataframe.dropna(axis=0,how='all')
2.删除DataFrame表中全部为NaN的列
your_dataframe.dropna(axis=1,how='all')
3.删除表中含有任何NaN的行
your_dataframe.dropna(axis=0,how='any')
4.删除表中含有任何NaN的列
your_dataframe.dropna(axis=1,how='any')
4.2 替换
这里的替换可以参考前文的中位数,平均值,众数,0替换等。
replace_value = 0.0# 这里设置 inplace 为 True,能够直接把表中的 NaN 值替换掉your_dataframe.fillna(replace_value, inplace=True)# 如果不设置 inplace,则这样写就行# new_dataframe = your_dataframe.fillna(replace_value)五、数据绘图分析
5.1 饼状图
5.1.1 绘制某一特征的数值情况(二分类)
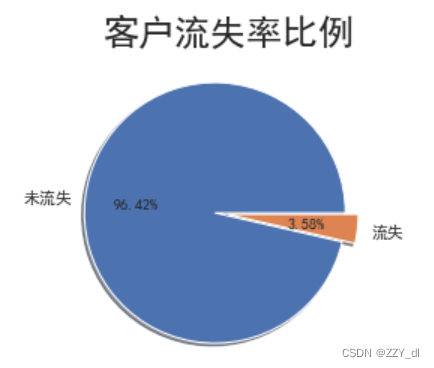
# 查看总体客户流失情况
churnvalue = df["LEAVE_FLAG"].value_counts()
labels = df["LEAVE_FLAG"].value_counts().index
plt.pie(churnvalue,labels=["未流失","流失"],explode=(0.1,0),autopct='%.2f%%', shadow=True,)
plt.title("客户流失率比例",size=24)
plt.show()
# 从饼形图中看出,流失客户占总客户数的很小的比例,流失率达3.58%
5.2 柱状图
5.2.1 单特征与目标特征之间的图像
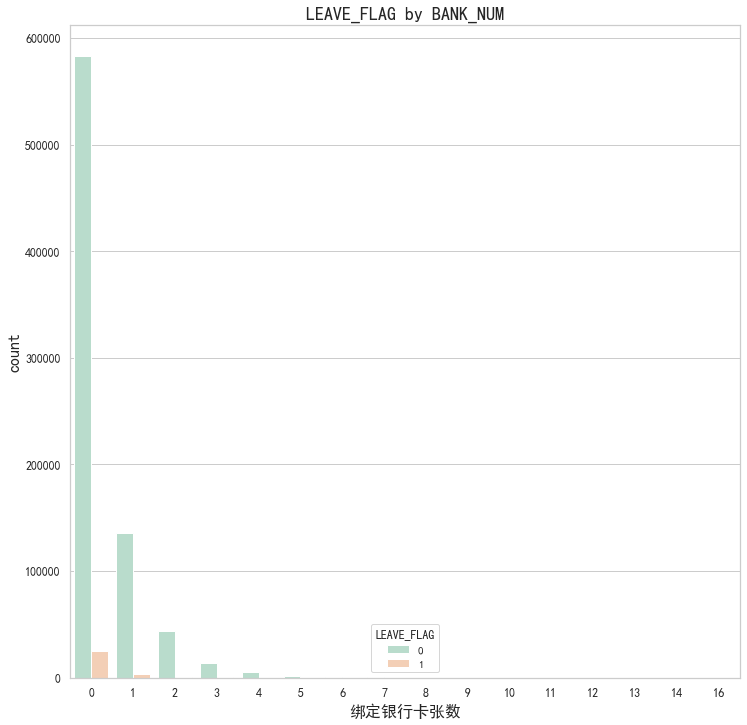
# 粘性/忠诚度分析 包括绑定银行卡张数
fig, axes = plt.subplots(1, 1, figsize=(12,12))
plt.subplot(1,1,1)
# palette参数表示设置颜色
gender=sns.countplot(x='BANK_NUM',hue="LEAVE_FLAG",data=df,palette="Pastel2")
plt.xlabel("绑定银行卡张数",fontsize=16)
plt.title("LEAVE_FLAG by BANK_NUM",fontsize=18)
plt.ylabel('count',fontsize=16)
plt.tick_params(labelsize=12) # 设置坐标轴字体大小
# 从此表可知,对于没有绑定银行卡的用户流失情况会更大,应该加强督促用户绑定银行卡
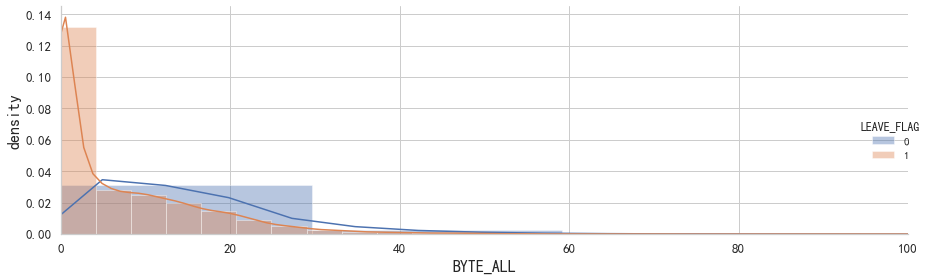
# 查看正常用户与流失用户在上网流量上的差别
plt.figure(figsize=(10,6))
g = sns.FacetGrid(data = df,hue = 'LEAVE_FLAG', height=4, aspect=3)
g.map(sns.distplot,'BYTE_ALL',norm_hist=True)
g.add_legend()
plt.ylabel('density',fontsize=16)
plt.xlabel('BYTE_ALL',fontsize=16)
plt.xlim(0, 100)
plt.tick_params(labelsize=13) # 设置坐标轴字体大小
plt.tight_layout()
plt.show()
# 从上图看出,上网流量少的用户流失率相对较高。
5.2.2 多特征与目标特征之间的图像
这里绘制的多个二分类特征的情况是与目标特征之间的关系
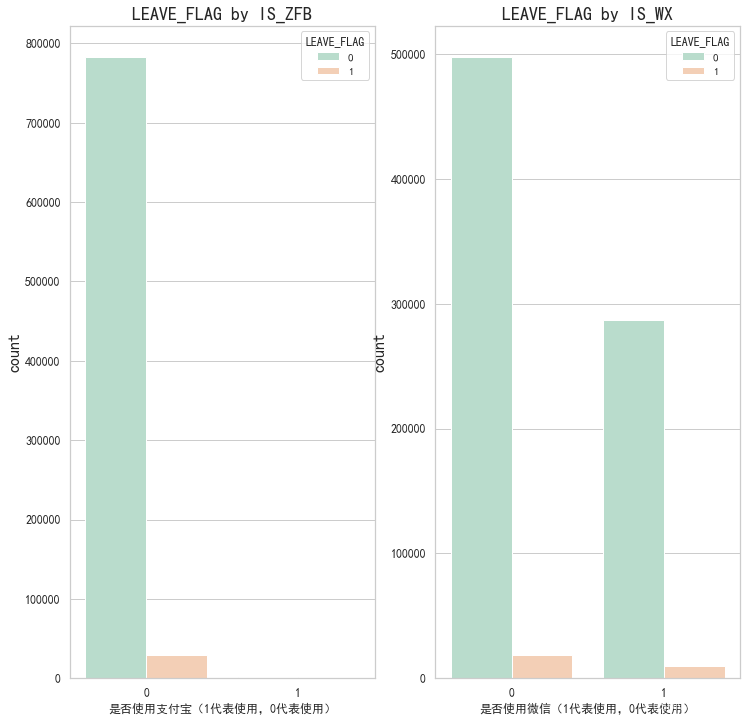
# 粘性/忠诚度分析 包括是否捆绑微信、是否捆绑支付宝
# sns.countplot()函数绘制了"是否使用支付宝"(IS_ZFB)这一列的柱状图,并根据"LEAVE_FLAG"(是否离网)进行了颜色分类。
fig, axes = plt.subplots(1, 2, figsize=(12,12))
plt.subplot(1,2,1)
# palette参数表示设置颜色
partner=sns.countplot(x="IS_ZFB",hue="LEAVE_FLAG",data=df,palette="Pastel2")
plt.xlabel("是否使用支付宝(1代表使用,0代表使用)")
plt.title("LEAVE_FLAG by IS_ZFB",fontsize=18)
plt.ylabel('count',fontsize=16)
plt.tick_params(labelsize=12) # 设置坐标轴字体大小plt.subplot(1,2,2)
seniorcitizen=sns.countplot(x="IS_WX",hue="LEAVE_FLAG",data=df,palette="Pastel2")
plt.xlabel("是否使用微信(1代表使用,0代表使用)")
plt.title("LEAVE_FLAG by IS_WX",fontsize=18)
plt.ylabel('count',fontsize=16)
plt.tick_params(labelsize=12) # 设置坐标轴字体大小
# 从此表可知 支付宝绑定目前对于用户流失没有影响,微信的绑定影响会稍微大点,可能是微信用户用的较多
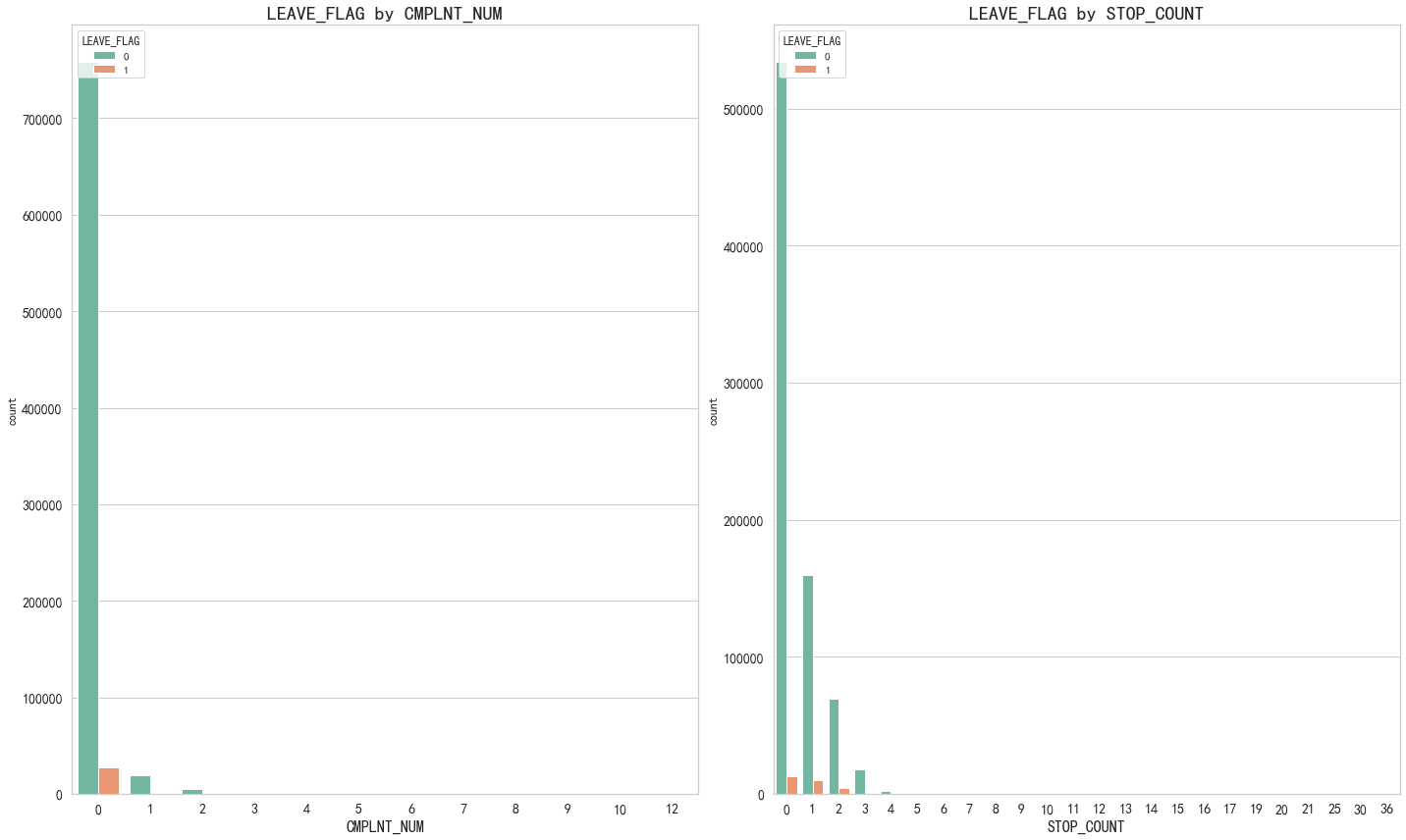
# 异常性 根据用户流失情况来结合判定
covariables=["CMPLNT_NUM", "STOP_COUNT"]
fig,axes=plt.subplots(1,2,figsize=(20,12))
for i, item in enumerate(covariables):'''0,'CMPLNT_NUM'1,'STOP_COUNT''''plt.subplot(1,2,(i+1))ax=sns.countplot(x=item,hue="LEAVE_FLAG",data=df,palette="Set2")plt.xlabel(str(item),fontsize=16)plt.tick_params(labelsize=14) # 设置坐标轴字体大小plt.title("LEAVE_FLAG by "+ str(item),fontsize=20)i=i+1
plt.tight_layout()
plt.show()
# 从此表可知 最近6个月累计投诉次数间接性的决定了用户的流失,停机天数也和用户流失成正相关。
5.3 折线图
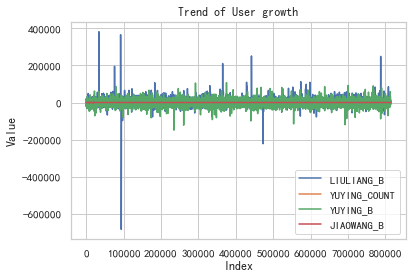
5.3.1 多个特征之间的关系图
# 用户的成长性分析,结合用户流失情况。
# 包括流量趋势、语音通话次数趋势、语音通话时长趋势、交往圈趋势
# 提取特征数据列
feature1 = df["LIULIANG_B"]
feature2 = df["YUYING_COUNT"]
feature3 = df["YUYING_B"]
feature4 = df["JIAOWANG_B"]# 绘制折线图
plt.plot(feature1, label="LIULIANG_B")
plt.plot(feature2, label="YUYING_COUNT")
plt.plot(feature3, label="YUYING_B")
plt.plot(feature4, label="JIAOWANG_B")# 添加标题和标签
plt.title("Trend of User growth")
plt.xlabel("Index")
plt.ylabel("Value")# 添加图例
plt.legend()# 显示图表
plt.show()
# 从此图可以发现针对流量趋势来说,用户的波动是最大的。
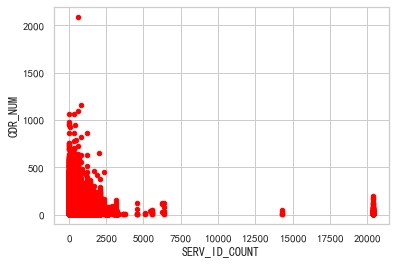
5.4 散点图
df.plot(x="SERV_ID_COUNT", y="CDR_NUM", kind="scatter", c="red")
plt.show()
这段代码的作用是绘制一个以"SERV_ID_COUNT"为横轴,"CDR_NUM"为纵轴的散点图,并将散点的颜色设置为红色。通过这个散点图,可以直观地观察到"SERV_ID_COUNT"和"CDR_NUM"之间的关系。
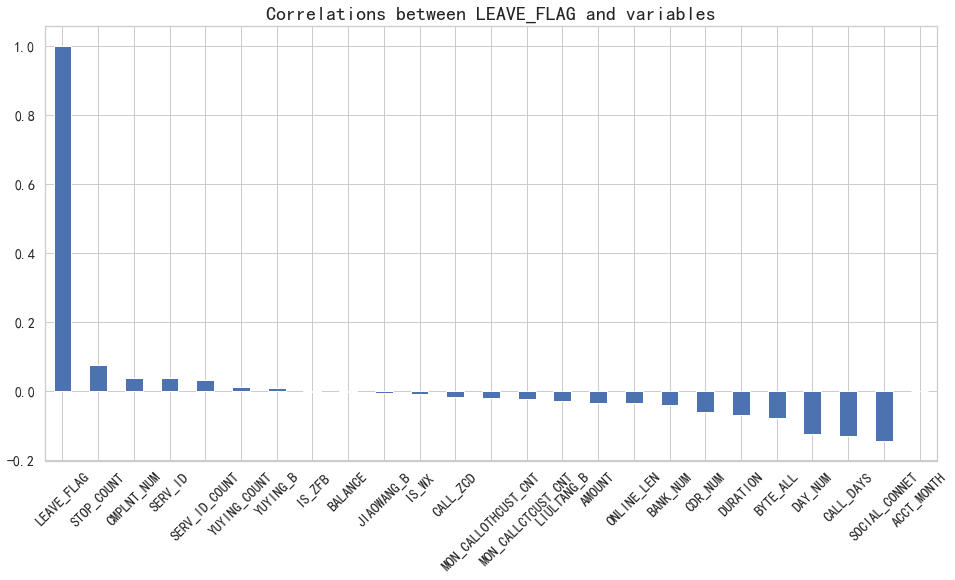
六、相关性分析
6.1 皮尔逊相关系数
plt.figure(figsize=(16,8))
df.corr()['LEAVE_FLAG'].sort_values(ascending = False).plot(kind='bar')
plt.tick_params(labelsize=14) # 设置坐标轴字体大小
plt.xticks(rotation=45) # 设置x轴文字转向
plt.title("Correlations between LEAVE_FLAG and variables",fontsize=20)
plt.show()
# 从图可以直观看出,YUYING_COUNT 、YUYING_B、IS_ZFB、BALANCE、JIAOWANG_B、IS_WX这六个变量与LEAVE_FLAG目标变量相关性最弱。
6.2 斯皮尔曼相关系数
plt.figure(figsize=(16,8))
df.corr(method='spearman')['LEAVE_FLAG'].sort_values(ascending = False).plot(kind='bar')
plt.tick_params(labelsize=14) # 设置坐标轴字体大小
plt.xticks(rotation=45) # 设置x轴文字转向
plt.title("Correlations between LEAVE_FLAG and variables",fontsize=20)
plt.show()
6.3 肯德尔相关系数
plt.figure(figsize=(16,8))
df.corr(method='kendall')['LEAVE_FLAG'].sort_values(ascending = False).plot(kind='bar')
plt.tick_params(labelsize=14) # 设置坐标轴字体大小
plt.xticks(rotation=45) # 设置x轴文字转向
plt.title("Correlations between LEAVE_FLAG and variables",fontsize=20)
plt.show()
6.4 计算热力图
# 计算相关性矩阵
corr_matrix = df.corr()# 绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap="coolwarm")
plt.title("Correlation Heatmap", fontsize=16)
plt.show()
七、数据归一化
特征主要分为连续特征和离散特征,其中离散特征根据特征之间是否有大小关系又细分为两类。
- 连续特征:一般采用归一标准化方式处理。
- 离散特征:特征之间没有大小关系。
- 离散特征:特征之间有大小关联,则采用数值映射。
# 通过归一化处理使特征数据标准为1,均值为0,符合标准的正态分布,
# 降低数值特征过大对预测结果的影响
# 除了目标特征全部做归一化,目标特征不用做,归一化会导致预测结果的解释变得困难
from sklearn.preprocessing import StandardScaler
# 实例化一个转换器类
scaler = StandardScaler(copy=False)
target = df["LEAVE_FLAG"]
# 提取除目标特征外的其他特征
other_features = df.drop("LEAVE_FLAG", axis=1)
# 对其他特征进行归一化
normalized_features = scaler.fit_transform(other_features)
# 将归一化后的特征和目标特征重新组合成DataFrame
normalized_data = pd.DataFrame(normalized_features, columns=other_features.columns)
normalized_data["LEAVE_FLAG"] = target
normalized_data.head()
八、模型搭建
# 深拷贝
X=normalized_data.copy()
X.drop(['LEAVE_FLAG'],axis=1, inplace=True)
y=df["LEAVE_FLAG"]
#查看预处理后的数据
X.head()# 建立训练数据集和测试数据集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 0)
print("原始训练集包含样本数量: ", len(X_train))
print("原始测试集包含样本数量: ", len(X_test))
print("原始样本总数: ", len(X_train)+len(X_test))# 使用分类算法
Classifiers=[["RandomForest",RandomForestClassifier()],["LogisticRegression",LogisticRegression(C=1000.0, random_state=30, solver="lbfgs",max_iter=100000)],["NaiveBayes",GaussianNB()],["DecisionTree",DecisionTreeClassifier()],["AdaBoostClassifier", AdaBoostClassifier()],["GradientBoostingClassifier", GradientBoostingClassifier()],["XGB", XGBClassifier()]
]
九、模型训练
from datetime import datetime
import pickle
import joblibdef get_current_time():current_time = datetime.now()formatted_time = current_time.strftime("%Y-%m-%d %H:%M:%S")return current_time, formatted_timeClassify_result=[]
names=[]
prediction=[]
i = 0for name, classifier in Classifiers:start_time, formatted_time = get_current_time()print("**********************************************************************")print("第{}个模型训练开始时间:{} 模型名称为:{}".format(i+1, formatted_time, name))classifier = classifierclassifier.fit(X_train, y_train)y_pred = classifier.predict(X_test)recall = recall_score(y_test, y_pred)precision = precision_score(y_test, y_pred)f1score = f1_score(y_test, y_pred)model_path = 'models/{}_{}_model.pkl'.format(name, round(precision, 5))print("开始保存模型文件路径为:{}".format(model_path))# 保存模型方式1# with open('models/{}_{}_model.pkl'.format(name, precision), 'wb') as file:# pickle.dump(classifier, file)# file.close()# 保存模型方式2joblib.dump(classifier, model_path)end_time = datetime.now() # 获取训练结束时间print("第{}个模型训练结束时间:{}".format(i+1, end_time.strftime("%Y-%m-%d %H:%M:%S")))print("训练耗时:", end_time - start_time)# 打印训练过程中的指标print("Classifier:", name)print("Recall:", recall)print("Precision:", precision)print("F1 Score:", f1score)print("**********************************************************************")# 保存指标结果class_eva = pd.DataFrame([recall, precision, f1score])Classify_result.append(class_eva)name = pd.Series(name)names.append(name)y_pred = pd.Series(y_pred)prediction.append(y_pred)i += 1
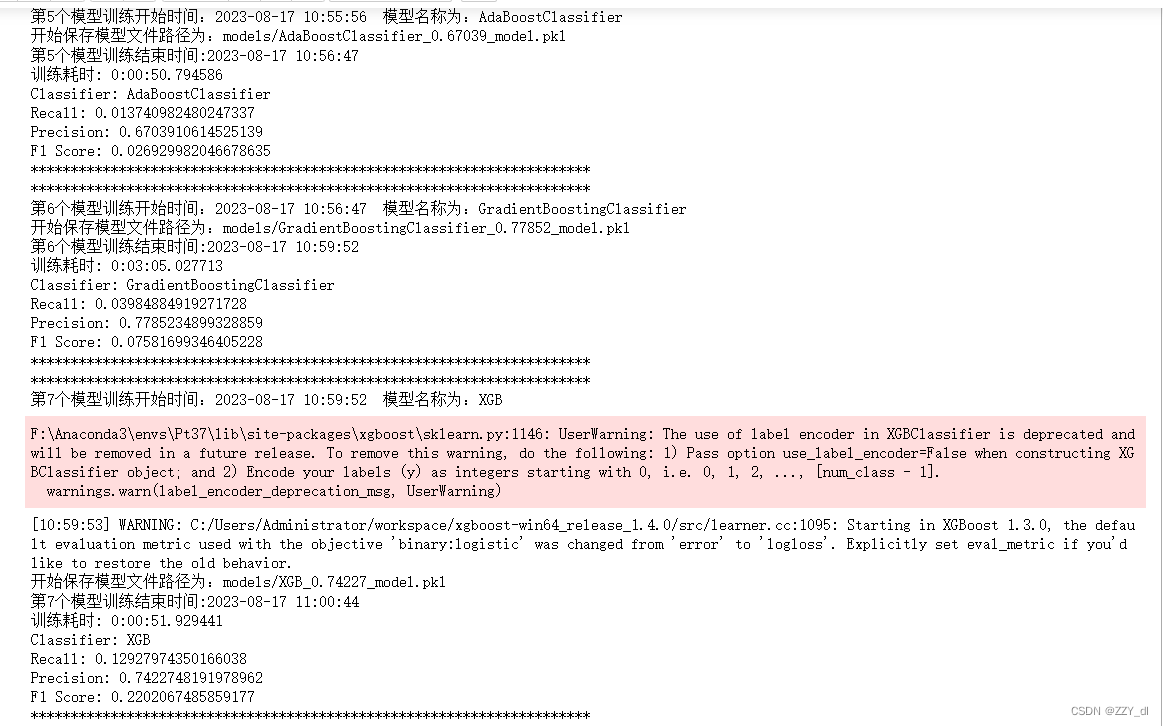
十、评估模型
召回率(recall)的含义是:原本为对的当中,预测为对的比例(值越大越好,1为理想状态)
精确率、精度(precision)的含义是:预测为对的当中,原本为对的比例(值越大越好,1为理想状态)
F1分数(F1-Score)指标综合了Precision与Recall的产出的结果
F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
classifier_names=pd.DataFrame(names)
# 转成列表
classifier_names=classifier_names[0].tolist()
result=pd.concat(Classify_result,axis=1)
result.columns=classifier_names
result.index=["recall","precision","f1score"]
result

十一、预测模型
对于h5模型
from keras.models import load_model
model = load_model('lstm_model.h5')
pred = model.predict(X, verbose=0)
print(pred)
对于pkl模型
loaded_model = joblib.load('models/{}_model.pkl'.format(name))
由于没有预测数据集,选择最后n条数为例进行预测。
# 由于没有预测数据集,选择最后n条数为例进行预测。
n = 500
pred_id = SERV_ID.tail(n)
# 提取预测数据集特征(如果有预测数据集,可以一并进行数据清洗和特征提取)
pred_x = X.tail(n)# 使用上述得到的最优模型
model = GradientBoostingClassifier()model.fit(X_train,y_train)
pred_y = model.predict(pred_x) # 预测值# 预测结果
predDf = pd.DataFrame({'SERV_ID':pred_id, 'LEAVE_FLAG':pred_y})
print("*********************原始的标签情况*********************")
print(df.tail(n)['LEAVE_FLAG'].value_counts())
print("*********************预测的标签情况*********************")
print(predDf['LEAVE_FLAG'].value_counts())
print("*********************预测的准确率*********************")
min1 = min(df.tail(n)['LEAVE_FLAG'].value_counts()[0],predDf['LEAVE_FLAG'].value_counts()[0])
min2 = min(df.tail(n)['LEAVE_FLAG'].value_counts()[1],predDf['LEAVE_FLAG'].value_counts()[1])
print("{}%".format(round((min1+min2)/n,3)*100))
# 由于没有预测数据集,选择最后n条数为例进行预测。
n = 500 # 预测的数量
pred_id = SERV_ID.tail(n)
# 提取预测数据集特征(如果有预测数据集,可以一并进行数据清洗和特征提取)
pred_x = X.tail(n)
# 加载模型
loaded_model = joblib.load('models/GradientBoostingClassifier_0.77852_model.pkl')
# 使用加载的模型进行预测
pred_y = loaded_model.predict(pred_x)
# 预测结果
predDf = pd.DataFrame({'SERV_ID':pred_id, 'LEAVE_FLAG':pred_y})
print("*********************原始的标签情况*********************")
print(df.tail(n)['LEAVE_FLAG'].value_counts())
print("*********************预测的标签情况*********************")
print(predDf['LEAVE_FLAG'].value_counts())
print("*********************预测的准确率*********************")
min1 = min(df.tail(n)['LEAVE_FLAG'].value_counts()[0],predDf['LEAVE_FLAG'].value_counts()[0])
min2 = min(df.tail(n)['LEAVE_FLAG'].value_counts()[1],predDf['LEAVE_FLAG'].value_counts()[1])
print("{}%".format(round((min1+min2)/n,3)*100))

相关文章:
模型预测笔记(一):数据清洗及可视化、模型搭建、模型训练和预测代码一体化和对应结果展示(可作为baseline)
模型预测 一、导入关键包二、如何载入、分析和保存文件三、修改缺失值3.1 众数3.2 平均值3.3 中位数3.4 0填充 四、修改异常值4.1 删除4.2 替换 五、数据绘图分析5.1 饼状图5.1.1 绘制某一特征的数值情况(二分类) 5.2 柱状图5.2.1 单特征与目标特征之间的…...
)
【Pytroch】基于K邻近算法的数据分类预测(Excel可直接替换数据)
【Pytroch】基于K邻近算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理 K最近邻(K-Nearest Neighbors,简称KNN)是一种简单但常用的机器学习算法,用于分类和回归问题。它的核心思想是基于已…...

Centos 7 通过Docker 安装MySQL 8.0.33实现数据持久化及my.cnf配置
要在 CentOS 7 上使用 Docker 启动 MySQL 8.0.33,并配置 MySQL 的 my.cnf 文件,同时实现 MySQL 数据的持久化,可以按照以下步骤进行操作: 1、安装 Docker:确保你在 CentOS 7 上已经安装了 Docker。如果尚未安装&#…...
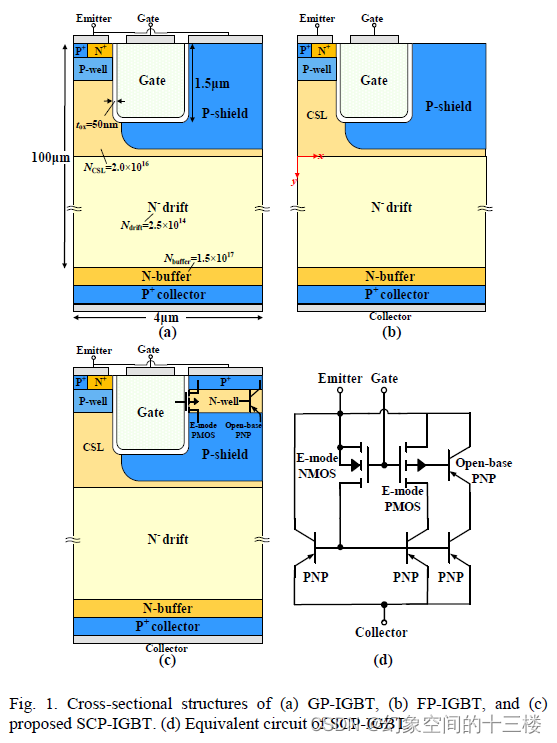
自夹持P型屏蔽型碳化硅沟槽型绝缘栅双极晶体管,用于低开通电压和开关损耗
目录 标题:Self-Clamped P-shield SiC Trench IGBT for Low On-State Voltage and Switching LossProceedings of the 35st International Symposium on Power Semiconductor Devices & ICs摘要信息解释研究了什么文章的创新点文章的研究方法文章的结论 标题&am…...

【数据结构与算法——TypeScript】树结构Tree
【数据结构与算法——TypeScript】 树结构(Tree) 认识树结构以及特性 什么是树? 🌲 真实的树:相信每个人对现实生活中的树都会非常熟悉 🌲 我们来看一下树有什么特点? ▫️ 树通常有一个根。连接着根的是树干。 ▫️ 树干到…...

多维时序 | MATLAB实现PSO-CNN-BiGRU多变量时间序列预测
多维时序 | MATLAB实现PSO-CNN-BiGRU多变量时间序列预测 目录 多维时序 | MATLAB实现PSO-CNN-BiGRU多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.多维时序 | MATLAB实现PSO-CNN-BiGRU多变量时间序列预测; 2.运行环境为Matlab20…...
Shell 编程基础01
0:目录 1.创建新的虚拟机项目 2.linux常见命令和配置时间同步器 3.文件属性 4.if for while和方法 1.创建新的虚拟机项目 默认下一步到虚拟机命名 默认下一步设置磁盘大小 自定义硬件 删除打印机设置映像地址 启动虚拟机 选择 install centOS 7 选择英文 设置时…...
Cross-Site Scripting
文章目录 反射型xss(get)反射型xss(post)存储型xssDOM型xssDOM型xss-xxss-盲打xss-过滤xss之htmlspecialcharsxss之href输出xss之js输出 反射型xss(get) <script>alert("123")</script>修改maxlength的值 反射型xss(post) 账号admin密码123456直接登录 …...

基于java企业员工绩效考评系统设计与实现
摘 要 时代的变化速度实在超出人类的所料,21世纪,计算机已经发展到各行各业,各个地区,它的载体媒介-计算机,大众称之为的电脑,是一种特高速的科学仪器,比人类的脑袋要灵光无数倍,什么…...
SpringBoot 操作Redis、创建Redis文件夹、遍历Redis文件夹
文章目录 前言依赖连接 RedisRedis 配置文件Redis 工具类操作 Redis创建 Redis 文件夹查询数据遍历 Redis 文件夹 前言 Redis 是一种高性能的键值存储数据库,支持网络、可基于内存亦可持久化的日志型,而 Spring Boot 是一个简化了开发过程的 Java 框架。…...
c++11 标准模板(STL)(std::basic_stringbuf)(六)
定义于头文件 <sstream> template< class CharT, class Traits std::char_traits<CharT>, class Allocator std::allocator<CharT> > class basic_stringbuf : public std::basic_streambuf<CharT, Traits> std::basic_stringbu…...

iceberg系列之 hadoop catalog 小文件合并实战
背景 flink1.15 hadoop3.0pom文件 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://mave…...

神经网络基础-神经网络补充概念-25-深层神经网络
简介 深层神经网络(Deep Neural Network,DNN)是一种具有多个隐藏层的神经网络,它可以用来解决复杂的模式识别和特征学习任务。深层神经网络在近年来的机器学习和人工智能领域中取得了重大突破,如图像识别、自然语言处…...
MySQL— 基础语法大全及操作演示!!!(上)
MySQL—— 基础语法大全及操作演示(上) 一、MySQL概述1.1 、数据库相关概念1.1.1 MySQL启动和停止 1.2 、MySQL 客户端连接1.3 、数据模型 二、SQL2.1、SQL通用语法2.2、SQL分类2.3、DDL2.3.1 DDL — 数据库操作2.3.1 DDL — 表操作 2.4、DML2.4.1 DML—…...
[golang gin框架] 46.Gin商城项目-微服务实战之后台Rbac客户端调用微服务权限验证以及Rbac微服务数据库抽离
一. 根据用户的权限动态显示左侧菜单微服务 1.引入 后台Rbac客户端调用微服务权限验证功能主要是: 登录后显示用户名称、根据用户的权限动态显示左侧菜单,判断当前登录用户的权限 、没有权限访问则拒绝,参考[golang gin框架] 14.Gin 商城项目-RBAC管理,该微服务功能和上一节[g…...

域名和ip的关系
域名和ip的关系 一:什么是域名 域名,简称域名、网域,是由一串用点分隔的名字组成的上某一台计算机或计算机组的名称,用于在数据传输时标识 计算机的电子方位(有时也指地理位置)。网域名称系统,有时也简称为域名…...

excel日期函数篇1
1、DAY(serial_number):返回序列数表示的某月的天数 在括号内给出一个时间对象或引用一个时间对象(年月日),返回多少日 下面结果都为20 2、MONTH(serial_number):返回序列数表示的某年的月份 在括号内给出一个时间对…...

Leetcode151 翻转字符串中的单词
给你一个字符串 s ,请你反转字符串中 单词 的顺序。 单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。 返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。 注意:输入字符串 s中可能会存在前导空格、尾随空格…...

PHP FTP的相关函数及简单使用示例
简介 FTP是ARPANet的标准文件传输协议,该网络就是现今Internet的前身。 PHP FTP函数是通过文件传输协议提供对文件服务器的客户端访问,FTP函数用于打开、登陆以及关闭连接,也用于上传、下载、重命名、删除以及获取服务器上文件信息。 安装 …...
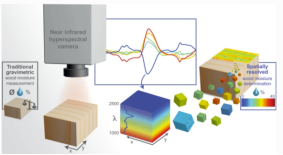
高光谱 | 矿物识别和分类标签数据制作、农作物病虫害数据分类、土壤有机质含量回归与制图、木材含水量评估和制图
本课程提供一套基于Python编程工具的高光谱数据处理方法和应用案例。 本课程涵盖高光谱遥感的基础、方法和实践。基础篇以学员为中心,用通俗易懂的语言解释高光谱的基本概念和理论,旨在帮助学员深入理解科学原理。方法篇结合Python编程工具,…...

OpCore Simplify:三步搞定黑苹果EFI配置的智能工具
OpCore Simplify:三步搞定黑苹果EFI配置的智能工具 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑苹果的复杂EFI配置而烦恼吗&am…...

Youtu-Parsing镜像免配置:预置outputs目录权限+日志轮转自动配置
Youtu-Parsing镜像免配置:预置outputs目录权限日志轮转自动配置 1. 引言:告别繁琐配置,专注文档解析 如果你用过一些AI模型,肯定遇到过这样的麻烦:好不容易把服务跑起来了,结果发现生成的图片没地方保存&…...
)
Windows下用CMake和MinGW编译NLopt 2.6.2的完整指南(附测试代码)
Windows平台下NLopt 2.6.2源码编译与实战应用全解析 在科学计算与工程优化领域,NLopt作为一款开源的非线性优化库,因其丰富的算法支持和跨平台特性而广受欢迎。本文将深入探讨如何在Windows系统中从零开始构建NLopt 2.6.2开发环境,并通过完整…...
)
告别反复插拔SD卡:迪文DGUS II屏串口下载与仿真调试全攻略(附T5L实战技巧)
告别反复插拔SD卡:迪文DGUS II屏串口下载与仿真调试全攻略(附T5L实战技巧) 在工业控制、智能家居和物联网设备的开发中,迪文DGUS II系列串口屏因其高性价比和强大的组态功能,已成为众多开发者的首选。然而,…...

5步攻克MZmine 3质谱数据分析:从问题解决到专业应用的实战指南
5步攻克MZmine 3质谱数据分析:从问题解决到专业应用的实战指南 【免费下载链接】mzmine3 MZmine 3 source code repository 项目地址: https://gitcode.com/gh_mirrors/mz/mzmine3 MZmine 3作为开源质谱数据分析领域的核心工具,在代谢组学、蛋白质…...

Jetson Orin上YOLOv8推理慢?手把手教你安装GPU版PyTorch并导出TensorRT引擎
Jetson Orin加速YOLOv8推理:从环境配置到TensorRT引擎优化实战 当你第一次在Jetson Orin上运行YOLOv8时,是否也被那令人窒息的推理速度震惊了?一张图片300多毫秒的处理时间,别说实时视频分析,就连批量处理图片都显得力…...

Inner-IoU: More Effective Intersection over Union Loss with Auxiliary Bounding Box——基于辅助边界框的更有效交并比损失
这篇题为《Inner-IoU: More Effective Intersection over Union Loss with Auxiliary Bounding Box》的论文,主要研究了目标检测中边界框回归(BBR)损失函数的改进问题。以下是其核心研究内容的全面总结概括: 1. 研究背景与问题 现…...

Kubernetes Python Client批量管理秘籍:1000+Pod运维实战
Kubernetes Python Client批量管理秘籍:1000Pod运维实战 【免费下载链接】python Official Python client library for kubernetes 项目地址: https://gitcode.com/gh_mirrors/python1/python Kubernetes Python Client是管理Kubernetes集群的官方Python客户…...

从理论到实践:几何完备扩散模型GCDM在SBDD任务中的实战评测与性能剖析
1. 几何完备扩散模型GCDM的核心原理 GCDM(Geometry-Complete Diffusion Model)作为新一代3D分子生成模型,其核心创新在于解决了传统方法无法有效学习分子几何特性的痛点。想象一下搭积木的场景:普通模型只能看到积木的颜色&#x…...

解锁RePKG的7个实战维度:从资源提取到合规创作的完整指南
解锁RePKG的7个实战维度:从资源提取到合规创作的完整指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 一、问题象限:资源处理的真实困境叙事 1.1 独立游…...