Python 爬虫小练
Python 爬虫小练 获取贝壳网数据
使用到的模块
标准库
Python3 标准库列表
- os 模块:os 模块提供了许多与操作系统交互的函数,例如创建、移动和删除文件和目录,以及访问环境变量等。
- math 模块:math 模块提供了数学函数,例如三角函数、对数函数、指数函数、常数等
- datetime 模块:datetime 模块提供了更高级的日期和时间处理函数,例如处理时区、计算时间差、计算日期差等
- logging 模块 :使用标准库提供的 logging API 最主要的好处是,所有的 Python 模块都可能参与日志输出,包括你自己的日志消息和第三方模块的日志消息。
- logging.config 模块 :可配置 logging 模块。 它们的使用是可选的 — 要配置 logging 模块你可以使用这些函数,也可以通过调用主 API (在
logging本身定义) 并定义在logging或logging.handlers中声明的处理器。 - logging.handlers 模块 :这个包提供了以下有用的处理程序。 请注意有三个处理程序类 (
StreamHandler,FileHandler和NullHandler) 实际上是在logging模块本身定义的,但其文档与其他处理程序一同记录在此。 - urllib 模块:urllib 模块提供了访问网页和处理 URL 的功能,包括下载文件、发送 POST 请求、处理 cookies 等
- threading 模块:线程模块提供对线程的支持
- SQLite 3 模块:SQLite 是一个C语言库,它可以提供一种轻量级的基于磁盘的数据库,这种数据库不需要独立的服务器进程,也允许需要使用一种非标准的 SQL 查询语言来访问它。一些应用程序可以使用 SQLite 作为内部数据存储。可以用它来创建一个应用程序原型,然后再迁移到更大的数据库。
第三方库
-
requests 库: Python requests 是一个常用的 HTTP 请求库,可以方便地向网站发送 HTTP 请求,并获取响应结果。
requests 模块比urllib模块更简洁。官网地址:Python requests
-
BeautifulSoup 库:是一个可以从HTML或XML文件中提取数据的Python库。官网地址:BeautifulSoup
使用到的相关逻辑步骤
请求URL
-
模拟浏览器
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36' } -
URL编码
import urllib.parsebaseUrl = "https://nj.ke.com/ershoufang/"url = baseUrl + "天润城/" encoded_url = urllib.parse.quote(url, safe='/:?+=') -
无用户认证
response = requests.get(encoded_url, headers=headers) -
有用户认证(cookie)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36','Cookie': 'lianjia_token=自己的具体值' }response = requests.get(encoded_url, headers=headers) -
代理,公司内部若存在代理需要配置。
proxies = {"https": "http://111:8080"}response = requests.get(encoded_url, headers=headers, proxies=proxies)
解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
-
取属性
soup.select('.title a')[0].attrs.get('href') -
取标签值
soup.select(".total span")[0].text.strip()
下载图片资源
# urllib.request配置代理
urllib.request.install_opener(urllib.request.build_opener(urllib.request.ProxyHandler(proxies))
)urllib.request.urlretrieve(housingImgUrl,housingTypeImagePath)
分析数据
写入SQLite 3数据库
-
建表(执行脚本)
-
写入
-
异常处理
conn = sqlite3.connect('../db/identifier.sqlite', check_same_thread=False) c = conn.cursor()# 执行sql脚本 with open('../db/script/house_listing_price.sql') as sql_file:c.executescript(sql_file.read()) conn.commit()for house_info in house_info_list:sql = f'insert into house_listing_price values (' \f'"{house_info["houseid"]}"' \f',"{house_info["title"]}"' \f',"{house_info["price"]}"' \f',"{house_info["address"]}"' \f',"{house_info["area"]}"' \f',"{house_info["sealDate"]}"' \f',"{house_info["housingType"]}"' \f',"{house_info["houseUrl"]}")'try:c.execute("BEGIN")c.execute(sql)c.execute("COMMIT")except:print("[" + str(datetime.datetime.now()) + "] " + "写入数据库异常,sql is [" + sql + "]")c.execute("ROLLBACK") conn.commit() conn.close()
完整示例
import requests
from bs4 import BeautifulSoup
import math
import datetime
import sqlite3
import urllib.request
import os# 代理-公司用
proxies = {"https": "http://xzproxy.cnsuning.com:8080"}
# 无代理
# proxies = {}# 下载图片第三方配置代理
urllib.request.install_opener(urllib.request.build_opener(urllib.request.ProxyHandler(proxies))
)# 模拟浏览器请求的header
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'
}# 挂牌列表URL-不分页
url = "https://nj.ke.com/ershoufang/co22l2rs%E5%A4%A9%E6%B6%A6%E5%9F%8E%E5%8D%81%E5%9B%9B%E8%A1%97%E5%8C%BA/"
response = requests.get(url, headers=headers, proxies=proxies)
soup = BeautifulSoup(response.text, 'html.parser')
# 网站每页30条
everypagecount = 30
sumhouse = soup.select(".total span")[0].text.strip()
pagesum = int(sumhouse) / everypagecount
pagesum = math.ceil(pagesum)
# 网站只提供100页
pagesum = min(pagesum, 100)
print("[" + str(datetime.datetime.now()) + "] " + "总记录数" + str(sumhouse) + ",总页数" + str(pagesum))
# 创建一个空列表,用于存储房源信息
house_info_list = []# 请求房源列表数据
def requestUrl(real_url):response = requests.get(real_url, headers=headers, proxies=proxies)soup = BeautifulSoup(response.text, 'html.parser')# 获取房源列表数据house_list = soup.select('.sellListContent li .clear')# 循环遍历房源列表,提取所需信息for house in house_list:# 挂牌标题title = house.select('.title a')[0].text.strip()# 挂牌价格price = house.select('.totalPrice span')[0].text.strip()# 地址小区名称address = house.select('.positionInfo a')[0].text.strip()# 楼层简述area = house.select('.houseInfo')[0].text.strip().replace('\n', '').replace(' ', '').split('|')[0]area = area[0:area.index(')') + 1]# 房屋登记编号houseId = house.select('.unitPrice')[0].attrs.get('data-hid')# 房源详情页的URLhref = house.select('.title a')[0].attrs.get('href')response2 = requests.get(href, headers=headers, proxies=proxies)soup2 = BeautifulSoup(response2.text, 'html.parser')# 挂牌日期sealDate = soup2.select('.introContent .transaction li')[0].text.strip()[4:]# 户型housingType = soup2.select('.introContent .base .content li')[0].text.strip()[4:].strip()# 房屋图片列表house_images_list = soup2.select('.thumbnail .smallpic li')housingTypeImagePath = "../src/main/resources/images/housingType/" + houseId + ".jpg"for house_images in house_images_list:# 下载户型图if "户型图" == house_images.attrs.get("data-desc") and not os.path.exists(housingTypeImagePath):housingImgUrl = house_images.attrs.get("data-src")urllib.request.urlretrieve(housingImgUrl,housingTypeImagePath)# 将提取到的信息添加到房源信息列表中house_info_list.append({'title': title,'price': price,'address': address,'area': area,'houseid': houseId,'sealDate': sealDate,'housingType': housingType,'houseUrl': href})returnpageNo = 0
while pageNo < pagesum:currentPageNo = str(pageNo + 1)# 挂牌列表URL-分页url = 'https://nj.ke.com/ershoufang/pg' + currentPageNo + 'co22l2rs%E5%A4%A9%E6%B6%A6%E5%9F%8E%E5%8D%81%E5%9B%9B%E8%A1%97%E5%8C%BA/'print("[" + str(datetime.datetime.now()) + "] " + "获取第" + currentPageNo + "页")requestUrl(url)pageNo = pageNo + 1# 将房源信息列表保存为CSV文件
import csv# print("写入文件中")
# current_date = datetime.datetime.now()
# formatted_date = current_date.strftime("%Y-%m-%d")
# filename = "house_info-" + formatted_date + ".csv"
# with open(filename, 'w', newline='', encoding='utf-8-sig') as f:
# writer = csv.writer(f)
# writer.writerow(['标题', '价格', '地址', '位置', '房屋ID'])
# for house_info in house_info_list:
# writer.writerow([
# house_info['title'], house_info['price'], house_info['address'],
# house_info['area'], house_info['houseid']
# ])
# print("写入完成")print("[" + str(datetime.datetime.now()) + "] " + "写入数据库")
conn = sqlite3.connect('../db/identifier.sqlite', check_same_thread=False)
c = conn.cursor()# 执行sql脚本
with open('../db/script/house_listing_price.sql') as sql_file:c.executescript(sql_file.read())
conn.commit()for house_info in house_info_list:sql = f'insert into house_listing_price values (' \f'"{house_info["houseid"]}"' \f',"{house_info["title"]}"' \f',"{house_info["price"]}"' \f',"{house_info["address"]}"' \f',"{house_info["area"]}"' \f',"{house_info["sealDate"]}"' \f',"{house_info["housingType"]}"' \f',"{house_info["houseUrl"]}")'try:c.execute("BEGIN")c.execute(sql)c.execute("COMMIT")except:print("[" + str(datetime.datetime.now()) + "] " + "写入数据库异常,sql is [" + sql + "]")c.execute("ROLLBACK")
conn.commit()
conn.close()
print("[" + str(datetime.datetime.now()) + "] " + "写入完成")
相关文章:

Python 爬虫小练
Python 爬虫小练 获取贝壳网数据 使用到的模块 标准库 Python3 标准库列表 os 模块:os 模块提供了许多与操作系统交互的函数,例如创建、移动和删除文件和目录,以及访问环境变量等。math 模块:math 模块提供了数学函数…...

vue3 事件处理 @click
在Vue 3中,事件处理可以通过click指令来实现。click指令用于监听元素的点击事件,并在触发时执行相应的处理函数。 下面是一个简单的示例,展示了如何在Vue 3中处理点击事件: <template><button click"handleClick&…...
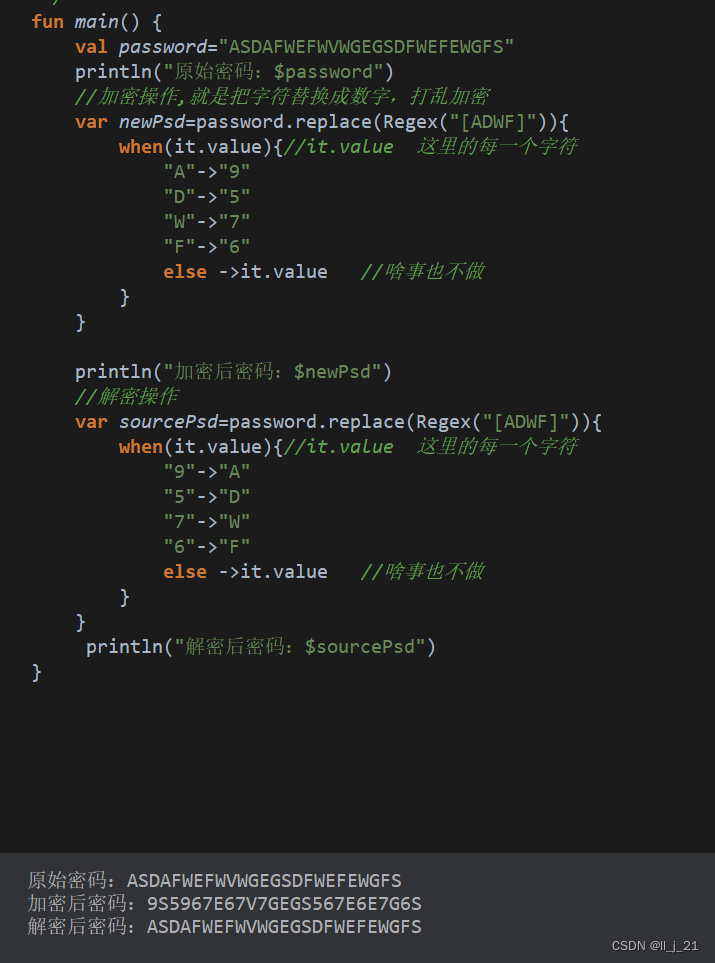
【第三阶段】kotlin语言使用replace完成加解密操作
fun main() {val password"ASDAFWEFWVWGEGSDFWEFEWGFS"println("原始密码:$password")//加密操作,就是把字符替换成数字,打乱加密var newPsdpassword.replace(Regex("[ADWF]")){when(it.value){//it.value 这里的每一个字…...
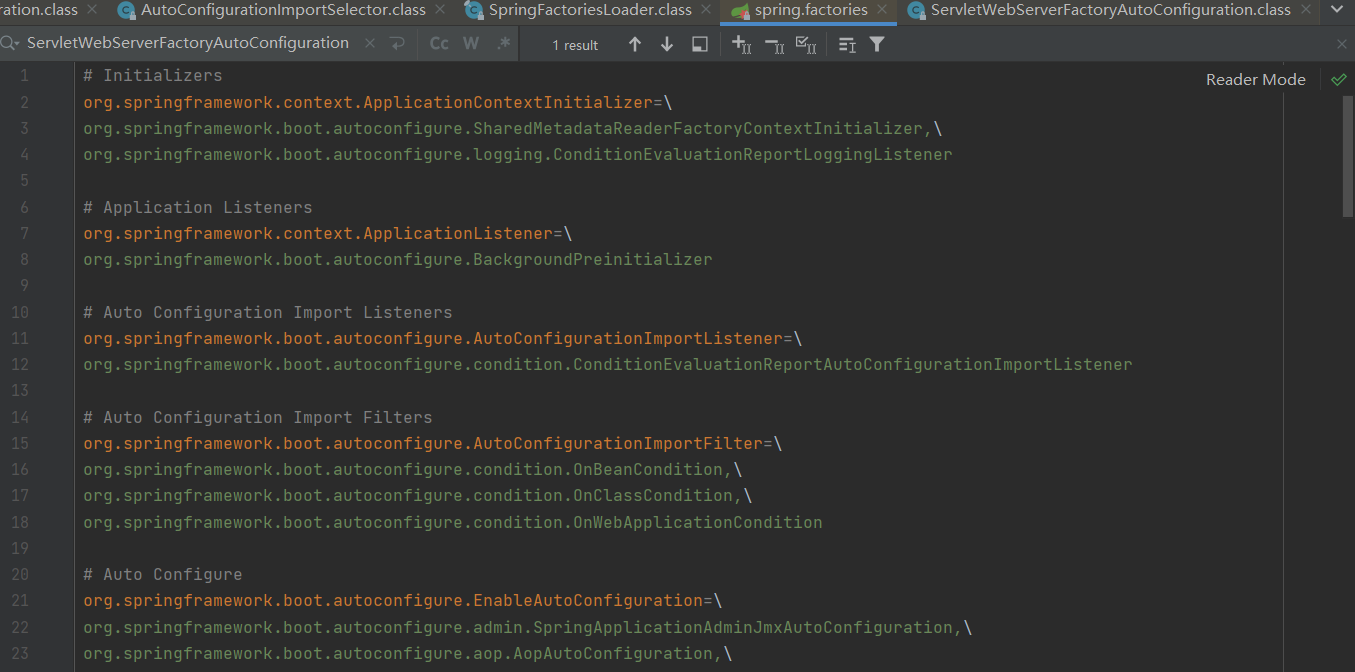
springBoot是如何实现自动装配的
目录 1 什么是自动装配 2 Spring自动装配原理 2.1 SpringBootConfiguration 编辑 2.2 EnableAutoConfiguration 2.2.1 AutoConfigurationPackage 2.2.2 Import({AutoConfigurationImportSelector.class}) 2.3 ComponentScan 1 什么是自动装配 自动装配就是将官方写好的的…...
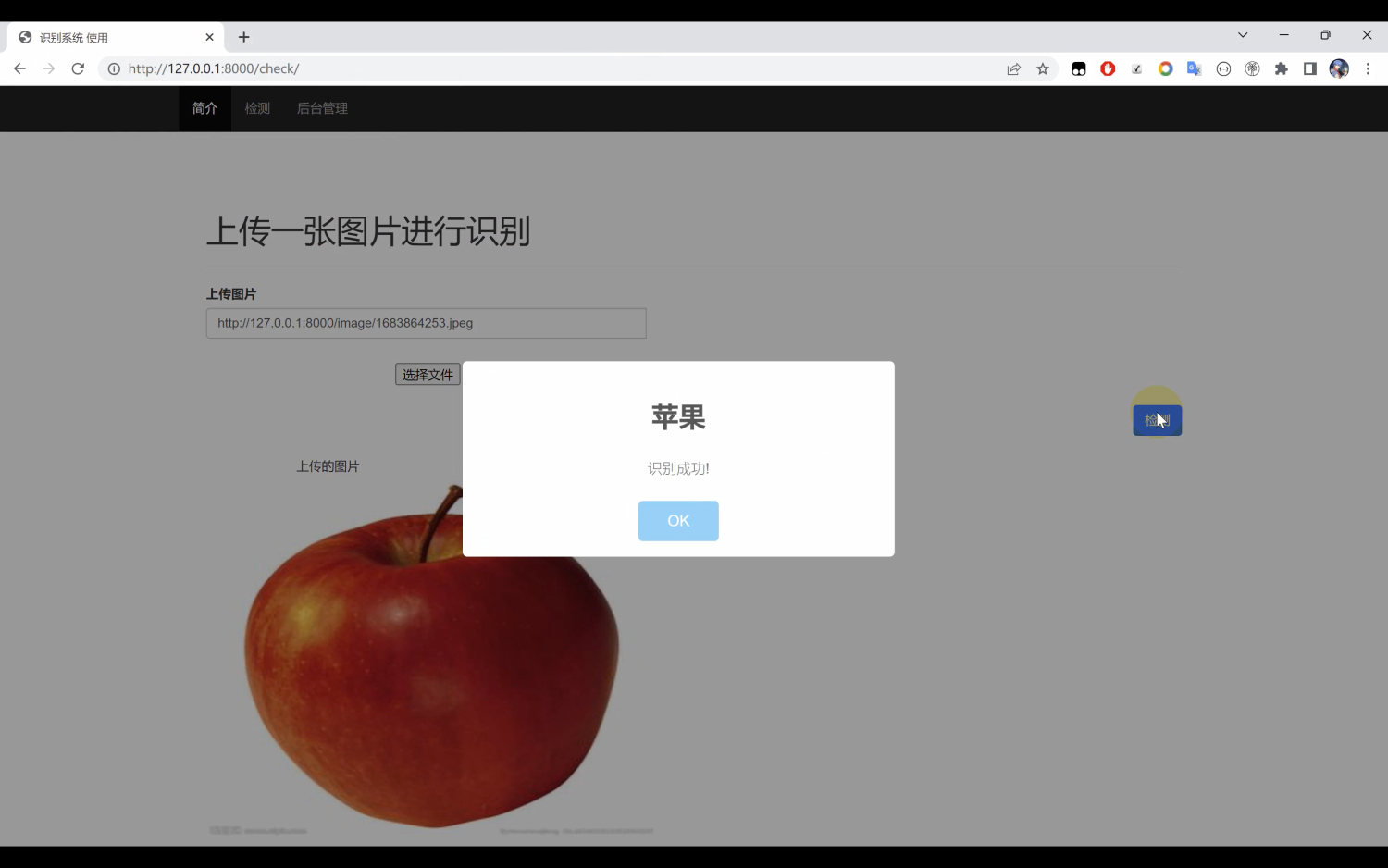
基于python+MobileNetV2算法模型实现一个图像识别分类系统
一、目录 算法模型介绍模型使用训练模型评估项目扩展 二、算法模型介绍 图像识别是计算机视觉领域的重要研究方向,它在人脸识别、物体检测、图像分类等领域有着广泛的应用。随着移动设备的普及和计算资源的限制,设计高效的图像识别算法变得尤为重要。…...

管理类联考——逻辑——真题篇——按知识分类——汇总篇——二、论证逻辑——归纳评价——归纳谬误
文章目录 第一节 归纳谬误题-归纳评价-归纳谬误题-归纳评论-归纳谬误-比率→数量,从基数找问题真题(2019-39)-归纳评论-归纳谬误-先归纳题干错误-诉诸人身分成:①诉诸权威:某人在某方面很权威,他做什么都是对的。②人身攻击:因为过往履历有问题,所以做什么都是错的。③…...

C++适配器模式
1 简介: 适配器模式是一种结构型设计模式,用于将一个类的接口转换为客户端所期望的另一个接口。适配器模式允许不兼容的类能够协同工作,通过适配器类来实现接口的转换和适配。 2 实现步骤: 以下是使用C实现适配器模式的步骤&…...

cocos creator 设置精灵镜像翻转效果
在 Cocos Creator 中,你可以通过代码来设置精灵节点的镜像翻转效果。具体来说,你可以使用精灵节点的 setScale 方法来实现这一点。以下是在代码中设置水平镜像翻转和垂直镜像翻转的示例: // 获取精灵节点的引用 let spriteNode cc.find(&qu…...
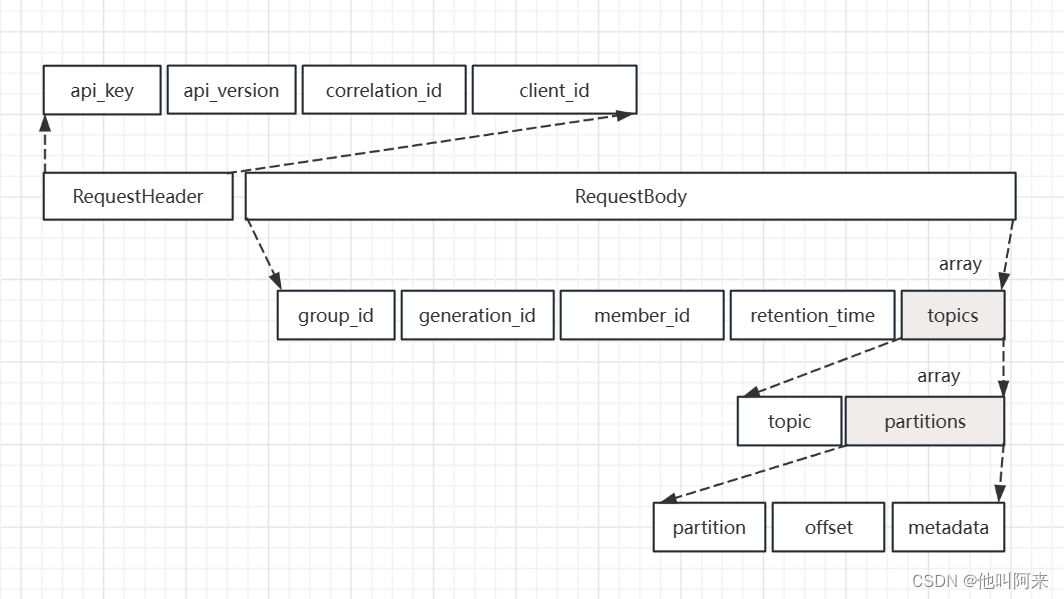
kafka的位移
文章目录 概要消费位移__consumer_offsets主题位移提交 概要 本文主要总结kafka的位移是如何管理的,在broker端如何通过命令行查看到位移信息,并从代码层面总结了位移的提交方式。 消费位移 对于 Kafka 中的分区而言,它的每条消息都有唯一…...

大数据平台运维实训室建设方案
一、概况 本实训室的主要目的是培养大数据平台运维项目的实践能力,以数据计算、分析、挖掘和可视化的案例训练为辅助。同时,实训室也承担相关考评员与讲师培训考试、学生认证培训考试、社会人员认证培训考试、大数据技能大赛训练、大数据专业课程改革等多项任务。 实训室旨在培…...

dll调用nodejs的回调函数
nodejs使用ffi调用dll。dll中有回调函数调用js中的方法。 c语言中cdll.h文件 extern "C" {typedef void(*JsCall)(int index); //这个就是要传入的类型结构extern __declspec(dllimport) int Add(int a, int b);extern __declspec(dllexport) void CallBackTest(Js…...
网络安全--linux下Nginx安装以及docker验证标签漏洞
目录 一、Nginx安装 二、docker验证标签漏洞 一、Nginx安装 1.首先创建Nginx的目录并进入: mkdir /soft && mkdir /soft/nginx/cd /soft/nginx/ 2.下载Nginx的安装包,可以通过FTP工具上传离线环境包,也可通过wget命令在线获取安装包…...

多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测
多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测 1.程…...
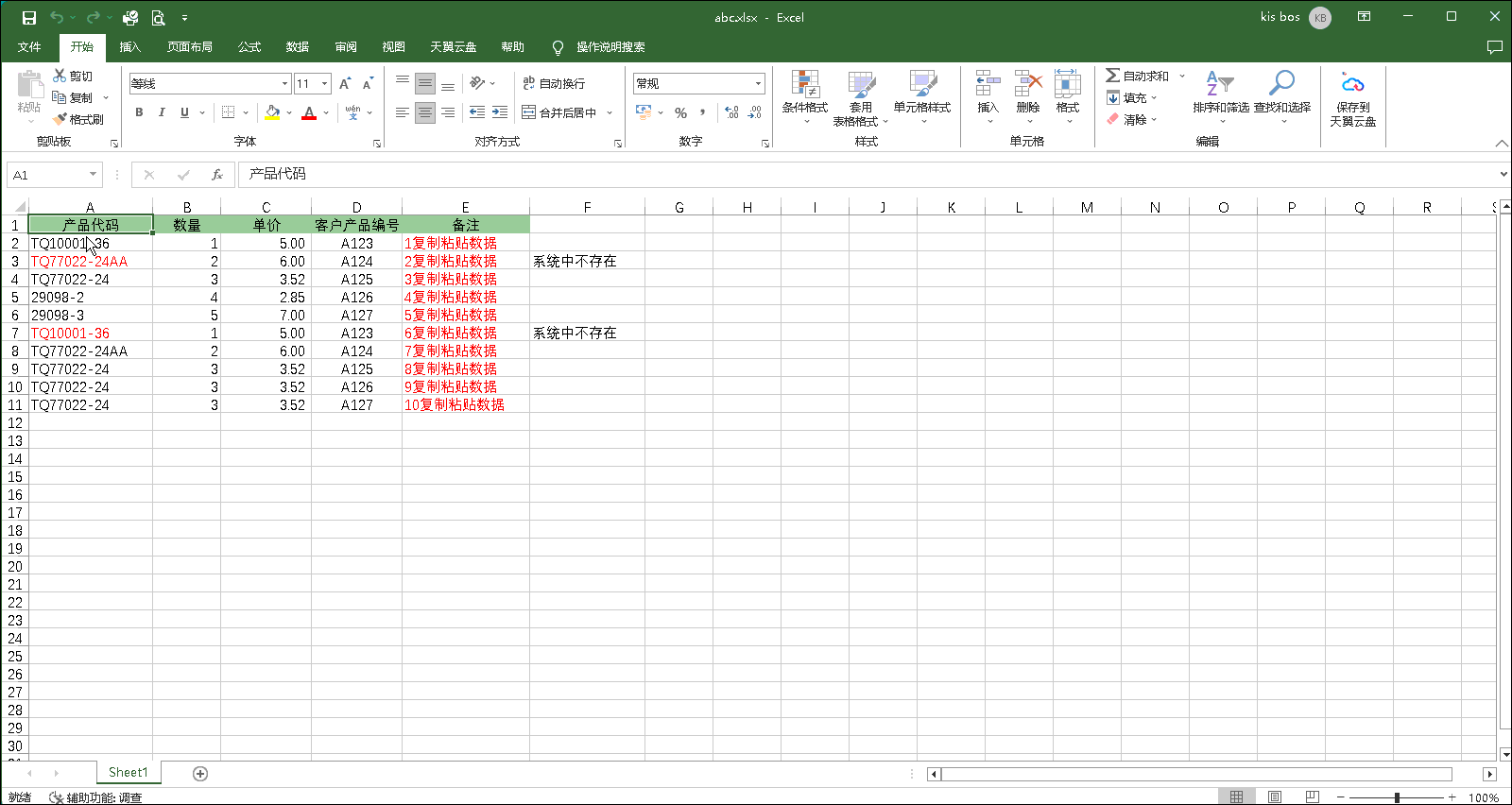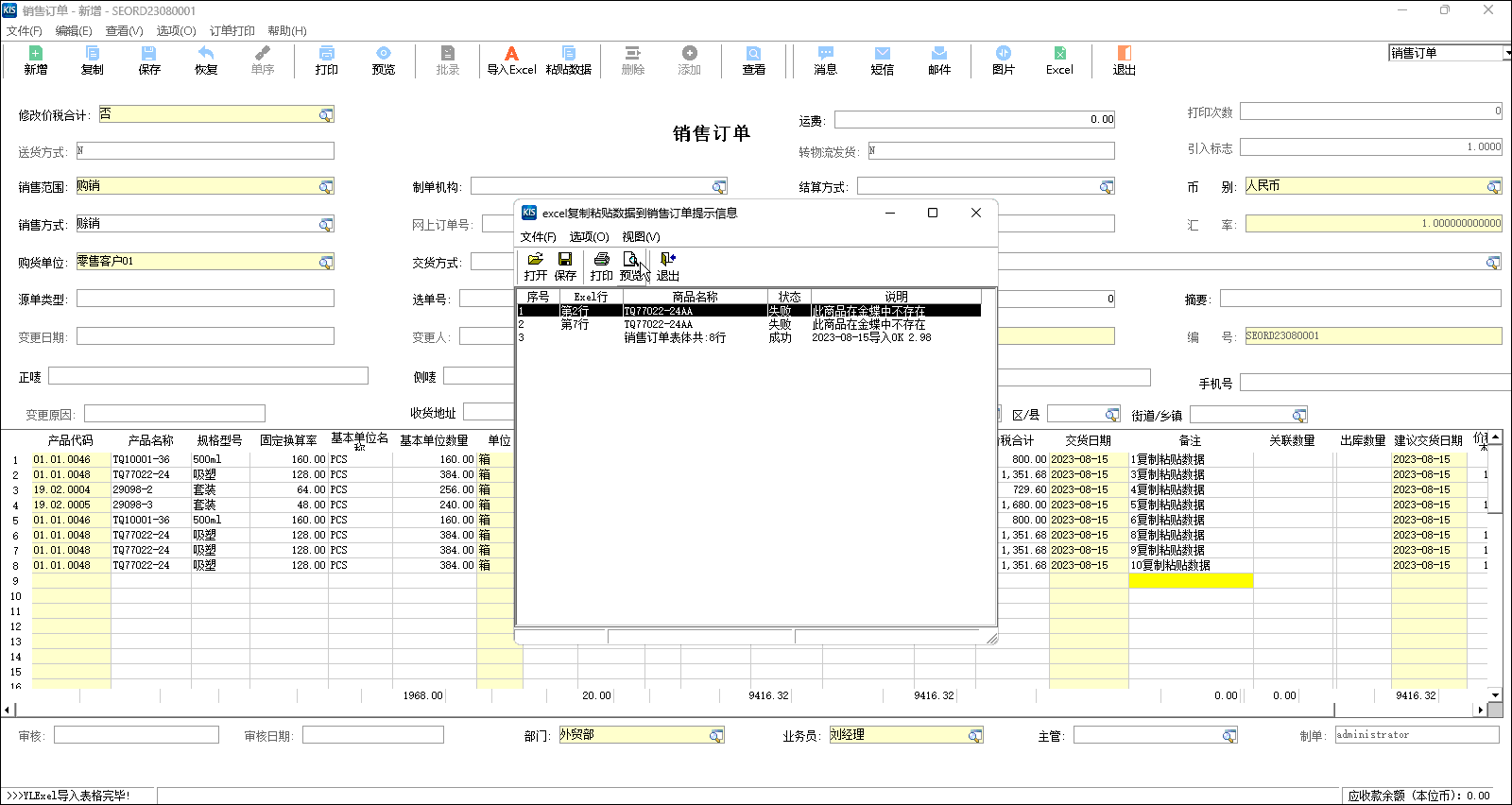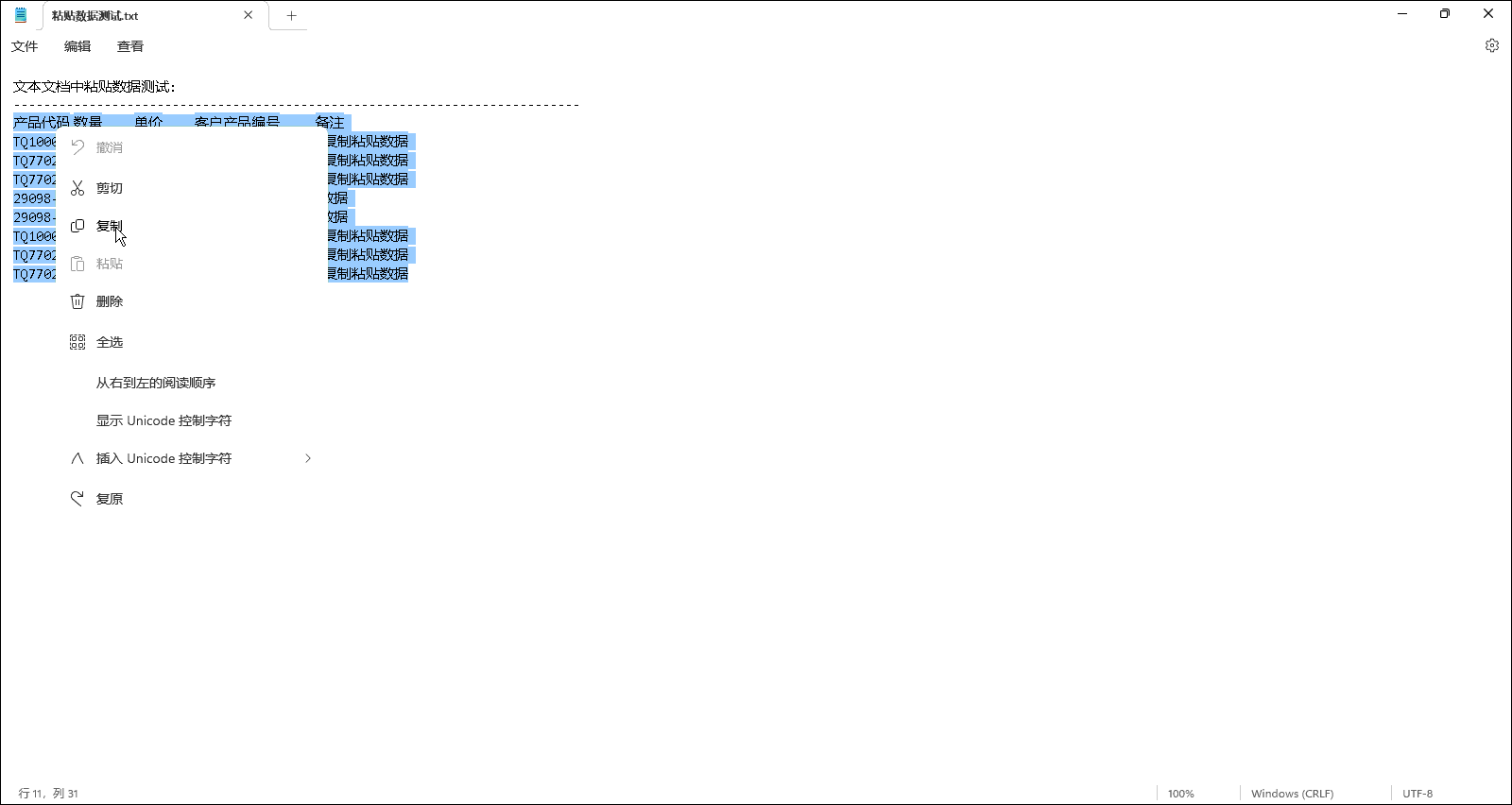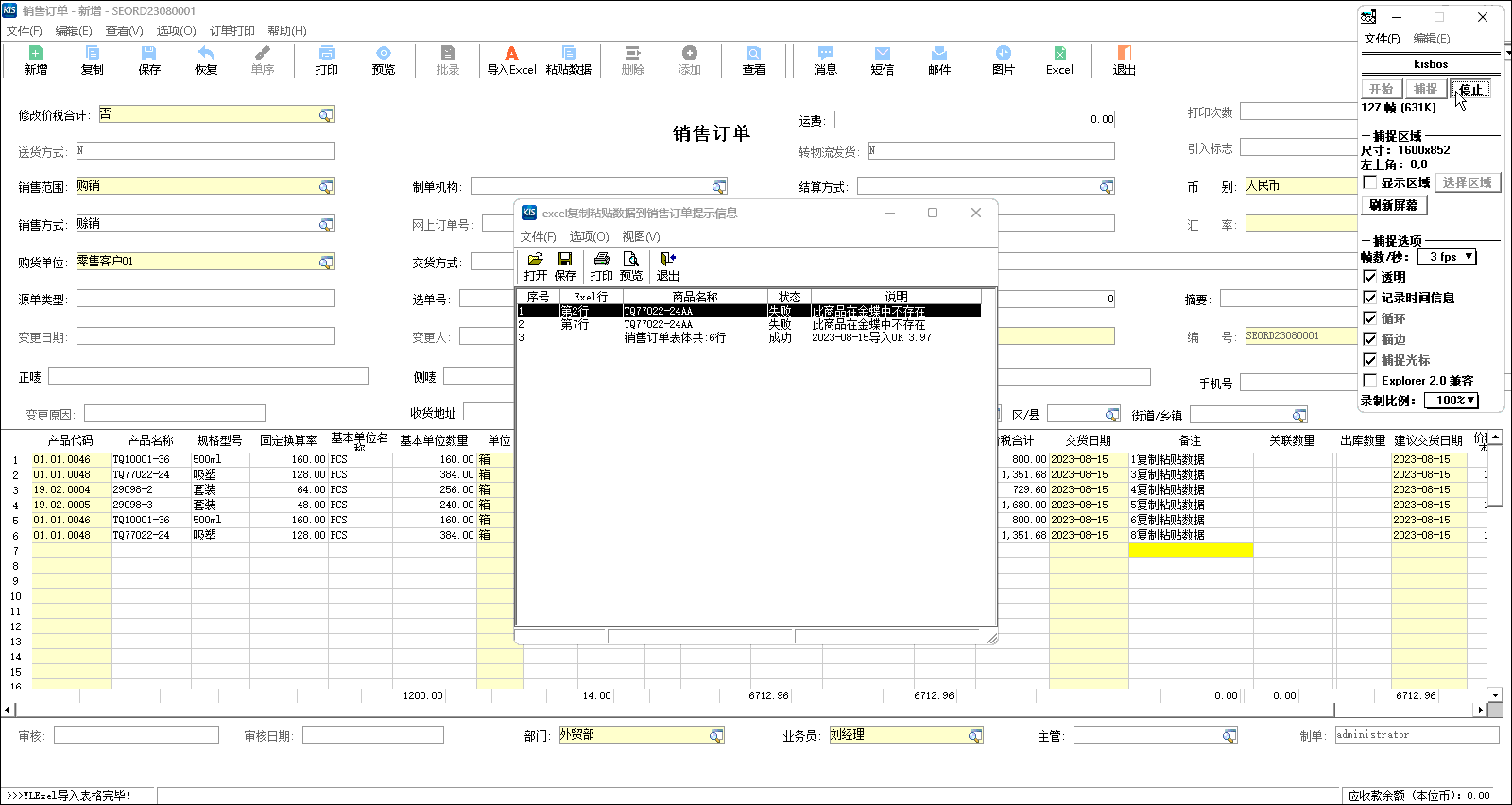
金蝶软件实现Excel数据复制分录信息粘贴到单据体分录行中
>>>适合KIS云专业版V16.0|KIS云旗舰版V7.0|K/3 WISE 14.0等版本<<< 实现Excel数据复制分录信息粘贴到金蝶单据体分录中,在采购订单|采购入库单|销售订单|销售出库单等类型单据中,以少量的必要字段在excel表格中按模板填列好,很方便快捷地复制到金蝶单据表体…...
【Linux操作系统】深入探索Linux进程:创建、共享与管理
进程的创建是Linux系统编程中的重要概念之一。在本节中,我们将介绍进程的创建、获取进程ID和父进程ID、进程共享、exec函数族、wait和waitpid等相关内容。 文章目录 1. 进程的创建1.1 函数原型和返回值1.2 函数示例 2. 获取进程ID和父进程ID2.1 函数原型和返回值2.…...
【云原生、k8s】Calico网络策略
第四阶段 时 间:2023年8月17日 参加人:全班人员 内 容: Calico网络策略 目录 一、前提配置 二、Calico网络策略基础 1、创建服务 2、启用网络隔离 3、测试网络隔离 4、允许通过网络策略进行访问 三、Calico网络策略进阶 1、创…...

Unity3D 测试总结
windows 平台上导出 exe 文件 在Unity界面中,点击菜单栏的“File”,选择“Build Settings”。 在“Build Settings”窗口中,选择要生成的平台(例如Windows)。 点击“Player Settings”按钮,进入“Player Se…...
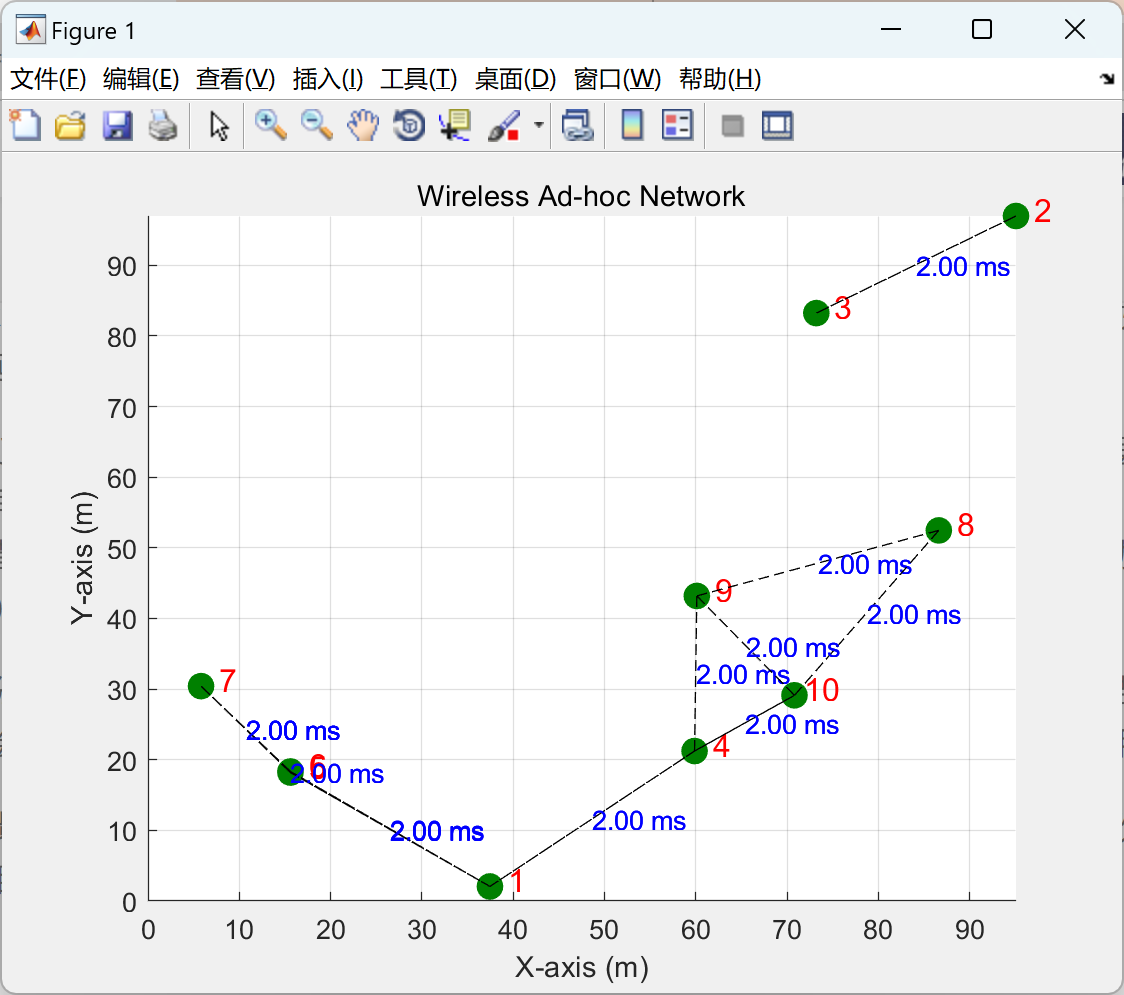
【无线点对点网络时延分析和可视化】模拟无线点对点网络中的延迟以及物理层和数据链路层之间的相互作用(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
在思科(Cisco)路由器中使用 SNMP
什么是SNMP SNMP,称为简单网络管理协议,被发现可以解决具有复杂网络设备的复杂网络环境,SNMP 使用标准化协议来查询网络上的设备,为网络管理员提供保持网络环境稳定和远离停机所需的重要信息。 为什么要在思科设备中启用SNMP S…...

【压测】wg/wrk 轻量级压测
wg/wrk 轻量级压测 说明:环境是 centos,不过现在 centos 免费版本不再更新和维护了,所以大家可以用阿里云的或者用 ubuntu 内核 用的 https://github.com/wg/wrk.git 有 35k star 然后据我了解,windows 用 wrk 压测有点麻烦&…...

低成本AI助手方案:OpenClaw+GLM-4.7-Flash替代ChatGPT Plus
低成本AI助手方案:OpenClawGLM-4.7-Flash替代ChatGPT Plus 1. 为什么选择自建AI助手? 去年我开始频繁使用ChatGPT Plus处理日常工作,但每月20美元的订阅费用加上额外API调用,账单经常突破50美元。更让我困扰的是,处理…...

SoccerData:一站式足球数据抓取与分析工具实战指南
SoccerData:一站式足球数据抓取与分析工具实战指南 【免费下载链接】soccerdata ⛏⚽ Scrape soccer data from Club Elo, ESPN, FBref, FiveThirtyEight, Football-Data.co.uk, SoFIFA and WhoScored. 项目地址: https://gitcode.com/gh_mirrors/so/soccerdata …...

电脑风扇智能控制完全指南:从噪音烦恼到散热优化
电脑风扇智能控制完全指南:从噪音烦恼到散热优化 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanC…...

Vue3+Tauri实战:从零构建桌面聊天应用,仿微信核心功能解析
1. 为什么选择Vue3Tauri开发桌面应用 最近两年桌面应用开发领域出现了一个有趣的现象:传统Electron应用虽然依然流行,但开发者们开始寻找更轻量、性能更好的替代方案。这就是Tauri逐渐受到关注的原因。作为一个长期使用Electron的老手,我第一…...

Open-SaaS:现代化企业级SaaS应用架构的工程实践指南
Open-SaaS:现代化企业级SaaS应用架构的工程实践指南 【免费下载链接】open-saas A free, open-source SaaS app starter for React & Node.js with superpowers. Production-ready. Community-driven. 项目地址: https://gitcode.com/GitHub_Trending/op/open…...

OpenClaw安全防护指南:GLM-4.7-Flash执行权限管控实践
OpenClaw安全防护指南:GLM-4.7-Flash执行权限管控实践 1. 为什么需要安全防护? 上周我在调试OpenClaw自动化脚本时,差点酿成大祸。当时想让GLM-4.7-Flash模型帮我整理下载目录里的PDF文件,结果模型误解了指令,竟然试…...

储能系统核心三部曲:BMS、EMS与PCS的协同交响
1. 储能系统的三大核心组件 第一次接触储能系统时,很多人都会被各种专业术语搞得晕头转向。其实就像交响乐团需要指挥、弦乐和管乐配合一样,一个高效的储能系统也离不开BMS、EMS和PCS这三大核心组件的协同工作。我在实际项目中见过太多因为组件间配合不当…...
实战:从天气预测到股票市场分析)
隐马尔科夫模型(HMM)实战:从天气预测到股票市场分析
1. 隐马尔科夫模型入门:从天气预报说起 第一次听说隐马尔科夫模型(HMM)时,我正盯着手机上的天气预报发呆。为什么明明显示"晴天",下午却突然下起暴雨?这让我开始思考天气预测背后的数学模型。HMM正是解决这类问题的利器…...

PCIE差分对布线:从规范到实战的关键要点
1. PCIE差分对布线的基础认知 第一次接触PCIE差分对布线时,我盯着那些密密麻麻的走线头皮发麻。后来才发现,理解它的本质其实很简单——就像两个配合默契的舞者,必须保持完全同步的动作才能呈现完美表演。PCIE差分信号正是通过一对相位相反的…...

别再让地图‘飘’了!深入浅出解析Cesium中GCJ-02、BD-09坐标偏移原理与DVGIS库实战
解密国内地图坐标系:从原理到实战解决Cesium中的“飘移”问题 你是否曾在Cesium中加载不同来源的地图数据时,发现明明标注的是同一个位置,却出现了明显的偏移?这种“飘移”现象背后,隐藏着国内地图坐标系复杂的加密体系…...