华为开源自研AI框架昇思MindSpore应用案例:基于MindSpore框架的UNet-2D案例实现
目录
- 一、环境准备
- 1.进入ModelArts官网
- 2.使用CodeLab体验Notebook实例
- 二、环境准备与数据读取
- 三、模型解析
- Transformer基本原理
- Attention模块
- Transformer Encoder
- ViT模型的输入
- 整体构建ViT
- 四、模型训练与推理
- 模型训练
- 模型验证
- 模型推理
近些年,随着基于自注意(Self-Attention)结构的模型的发展,特别是Transformer模型的提出,极大地促进了自然语言处理模型的发展。由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。
ViT则是自然语言处理和计算机视觉两个领域的融合结晶。在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。
模型结构
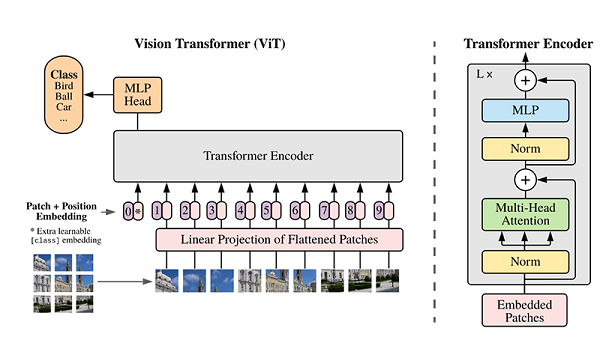
ViT模型的主体结构是基于Transformer模型的Encoder部分(部分结构顺序有调整,如:Normalization的位置与标准Transformer不同),其结构图[1]如下:
模型特点
ViT模型主要应用于图像分类领域。因此,其模型结构相较于传统的Transformer有以下几个特点:
数据集的原图像被划分为多个patch后,将二维patch(不考虑channel)转换为一维向量,再加上类别向量与位置向量作为模型输入。
模型主体的Block结构是基于Transformer的Encoder结构,但是调整了Normalization的位置,其中,最主要的结构依然是Multi-head Attention结构。
模型在Blocks堆叠后接全连接层,接受类别向量的输出作为输入并用于分类。通常情况下,我们将最后的全连接层称为Head,Transformer Encoder部分为backbone。
下面将通过代码实例来详细解释基于ViT实现ImageNet分类任务。
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
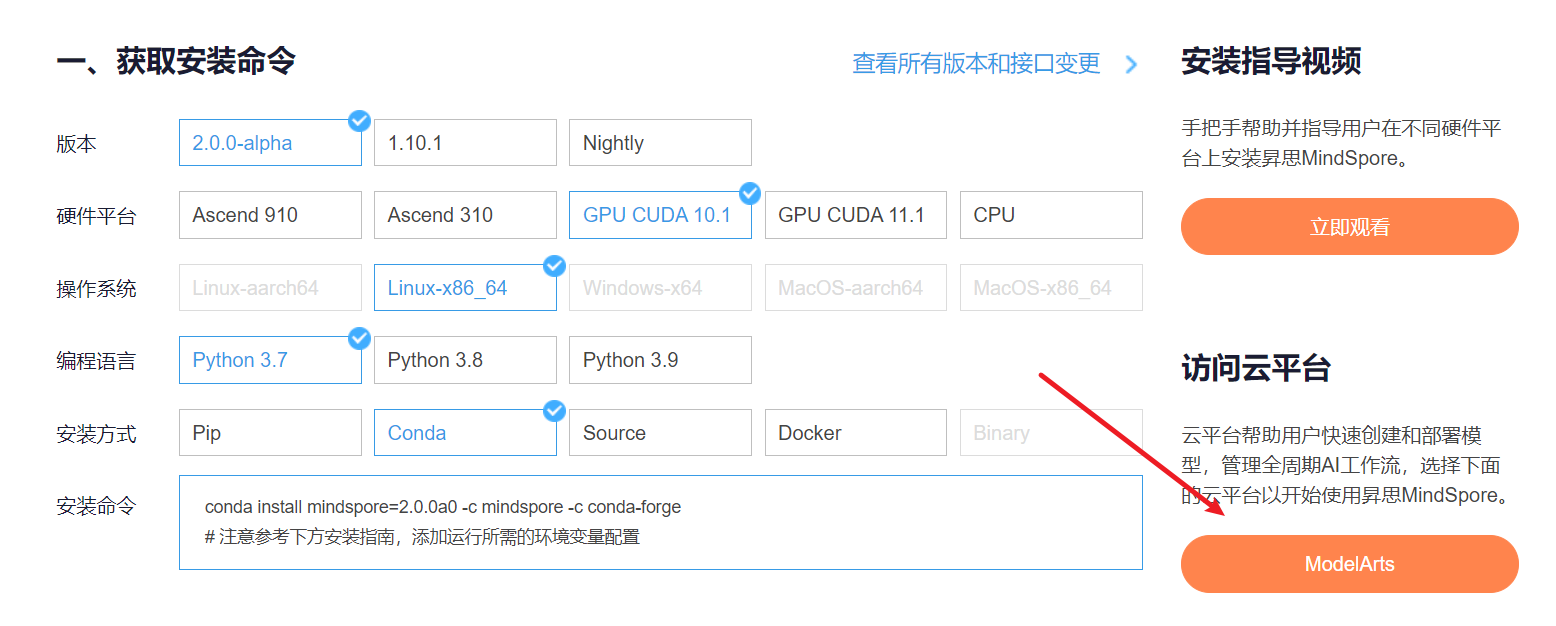
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,获取安装命令,安装MindSpore2.0.0-alpha版本,可以在昇思教程中进入ModelArts官网
选择下方CodeLab立即体验
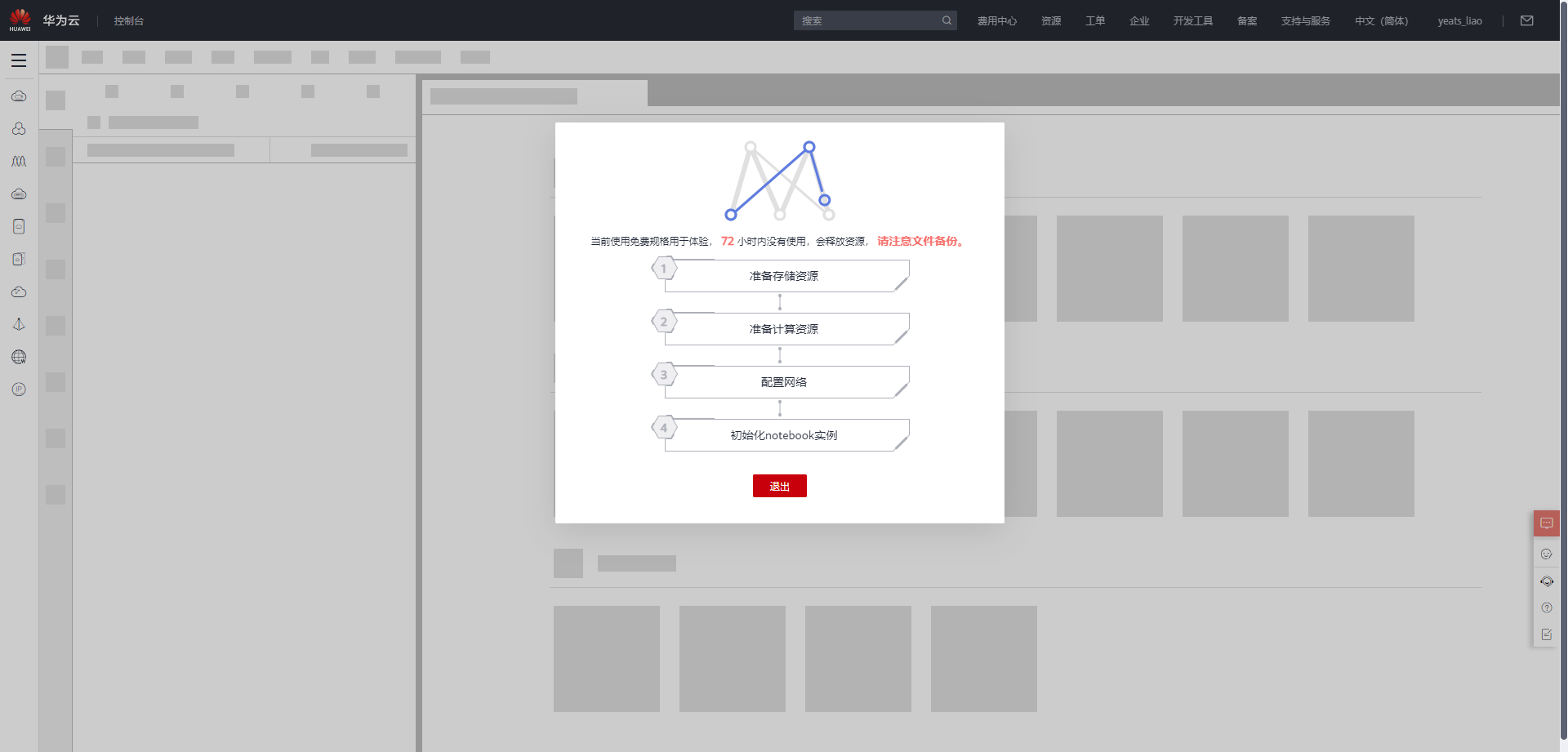
等待环境搭建完成
2.使用CodeLab体验Notebook实例
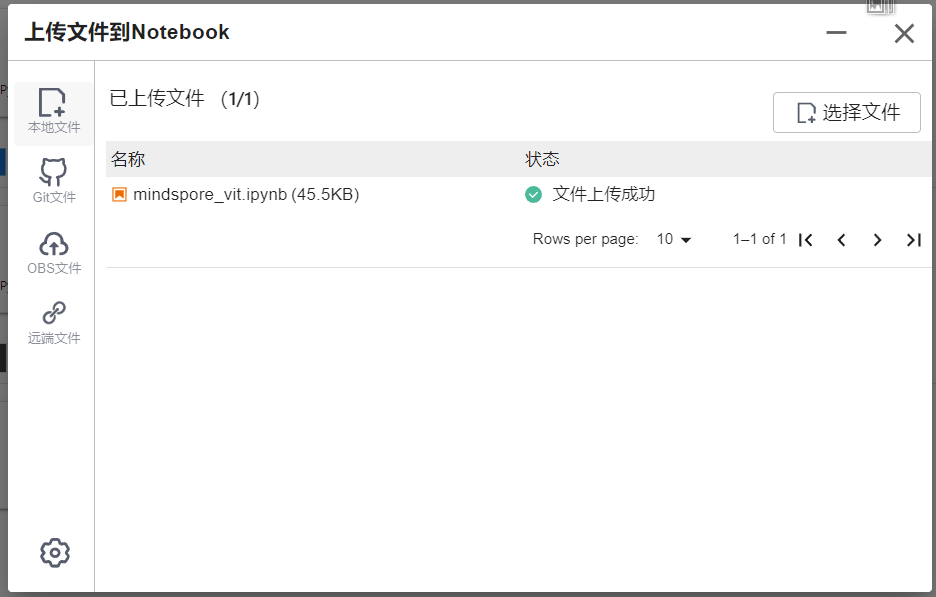
下载NoteBook样例代码,Vision Transformer图像分类 ,.ipynb为样例代码
选择ModelArts Upload Files上传.ipynb文件
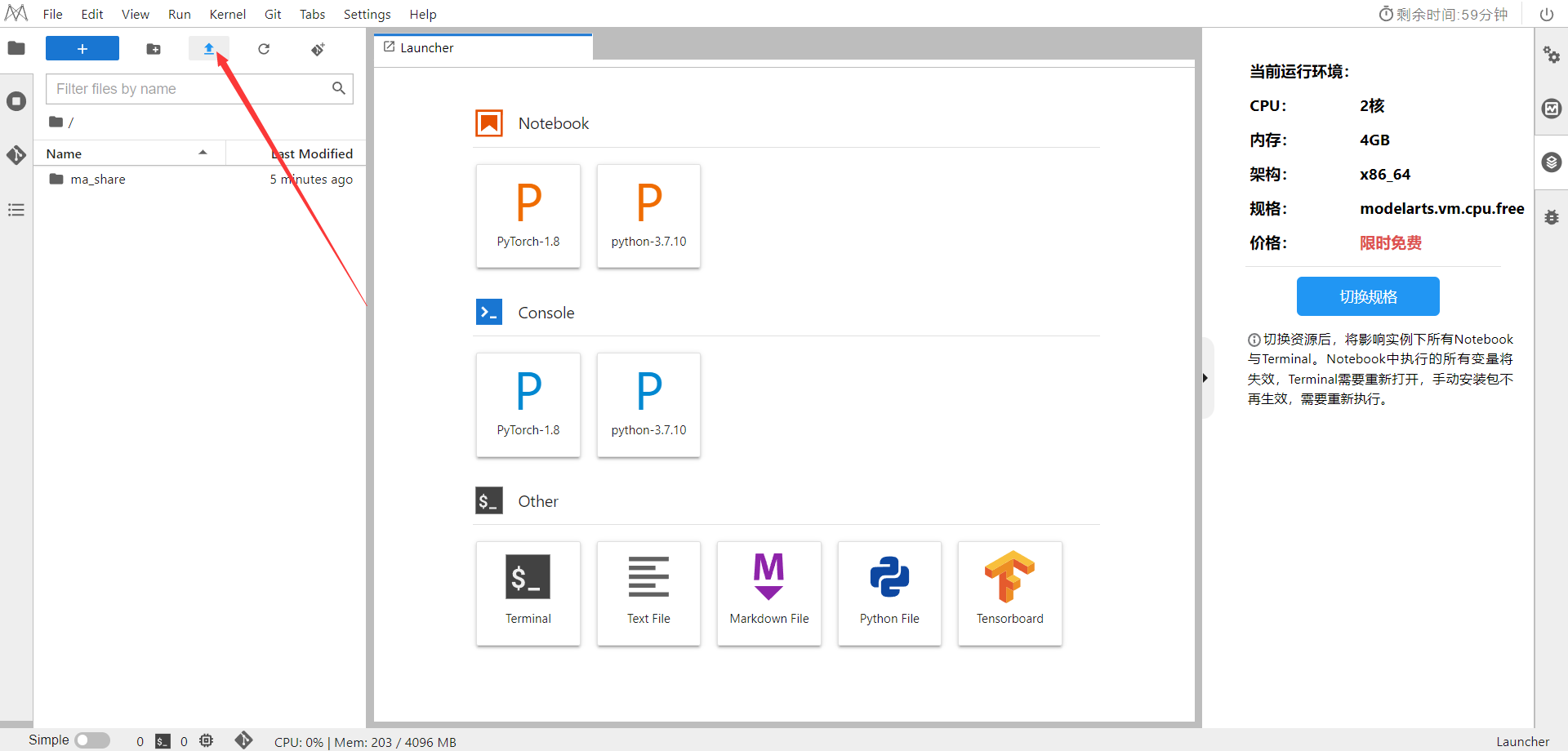
选择Kernel环境
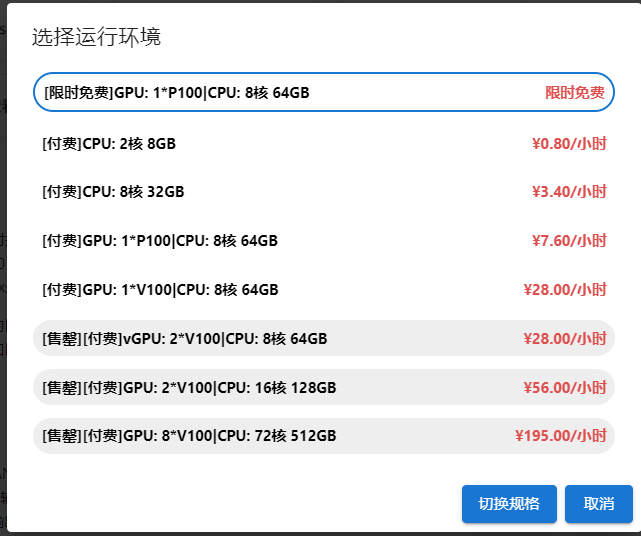
切换至GPU环境,切换成第一个限时免费
进入昇思MindSpore官网,点击上方的安装

获取安装命令

回到Notebook中,在第一块代码前加入命令
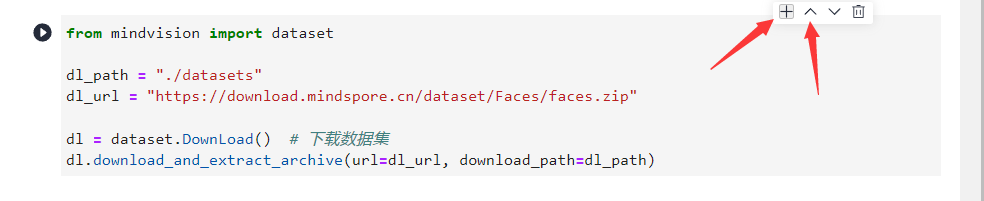
conda update -n base -c defaults conda
安装MindSpore 2.0 GPU版本
conda install mindspore=2.0.0a0 -c mindspore -c conda-forge
安装mindvision
pip install mindvision
安装下载download
pip install download
二、环境准备与数据读取
开始实验之前,请确保本地已经安装了Python环境并安装了MindSpore。
首先我们需要下载本案例的数据集,可通过http://image-net.org下载完整的ImageNet数据集,本案例应用的数据集是从ImageNet中筛选出来的子集。
运行第一段代码时会自动下载并解压,请确保你的数据集路径如以下结构。
.dataset/├── ILSVRC2012_devkit_t12.tar.gz├── train/├── infer/└── val/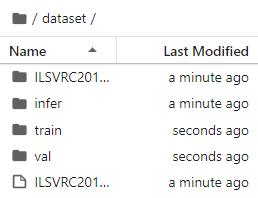
from download import downloaddataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/vit_imagenet_dataset.zip"
path = "./"path = download(dataset_url, path, kind="zip", replace=True)
import osimport mindspore as ms
from mindspore.dataset import ImageFolderDataset
import mindspore.dataset.vision as transformsdata_path = './dataset/'
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]dataset_train = ImageFolderDataset(os.path.join(data_path, "train"), shuffle=True)trans_train = [transforms.RandomCropDecodeResize(size=224,scale=(0.08, 1.0),ratio=(0.75, 1.333)),transforms.RandomHorizontalFlip(prob=0.5),transforms.Normalize(mean=mean, std=std),transforms.HWC2CHW()
]dataset_train = dataset_train.map(operations=trans_train, input_columns=["image"])
dataset_train = dataset_train.batch(batch_size=16, drop_remainder=True)
三、模型解析
下面将通过代码来细致剖析ViT模型的内部结构。
Transformer基本原理
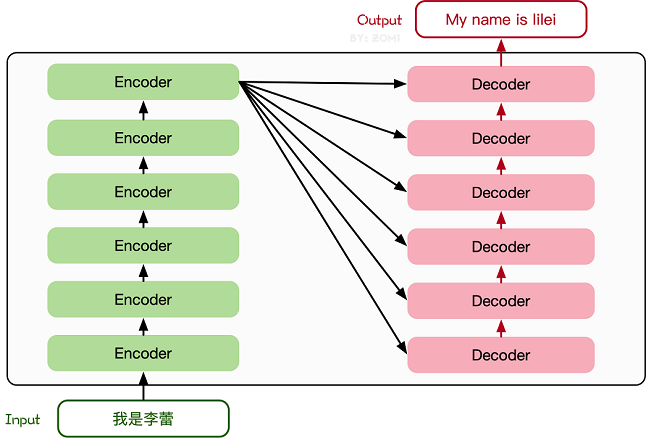
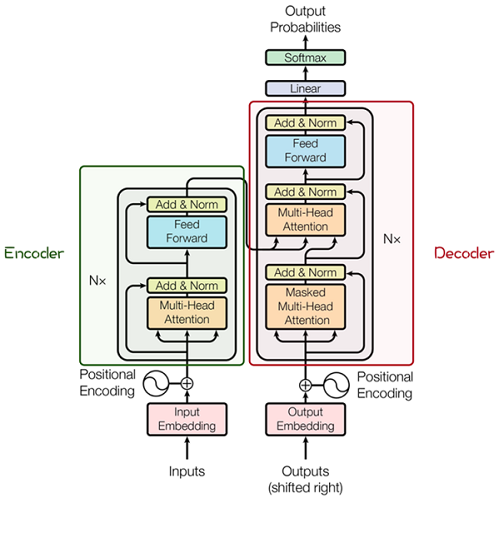
Transformer模型源于2017年的一篇文章[2]。在这篇文章中提出的基于Attention机制的编码器-解码器型结构在自然语言处理领域获得了巨大的成功。模型结构如下图所示:
其主要结构为多个Encoder和Decoder模块所组成,其中Encoder和Decoder的详细结构如下图[2]所示:
Encoder与Decoder由许多结构组成,如:多头注意力(Multi-Head Attention)层,Feed
Forward层,Normaliztion层,甚至残差连接(Residual
Connection,图中的“Add”)。不过,其中最重要的结构是多头注意力(Multi-Head
Attention)结构,该结构基于自注意力(Self-Attention)机制,是多个Self-Attention的并行组成。所以,理解了Self-Attention就抓住了Transformer的核心。
Attention模块
from mindspore import nn, opsclass Attention(nn.Cell):def __init__(self,dim: int,num_heads: int = 8,keep_prob: float = 1.0,attention_keep_prob: float = 1.0):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = ms.Tensor(head_dim ** -0.5)self.qkv = nn.Dense(dim, dim * 3)self.attn_drop = nn.Dropout(p=1.0-attention_keep_prob)self.out = nn.Dense(dim, dim)self.out_drop = nn.Dropout(p=1.0-keep_prob)self.attn_matmul_v = ops.BatchMatMul()self.q_matmul_k = ops.BatchMatMul(transpose_b=True)self.softmax = nn.Softmax(axis=-1)def construct(self, x):"""Attention construct."""b, n, c = x.shapeqkv = self.qkv(x)qkv = ops.reshape(qkv, (b, n, 3, self.num_heads, c // self.num_heads))qkv = ops.transpose(qkv, (2, 0, 3, 1, 4))q, k, v = ops.unstack(qkv, axis=0)attn = self.q_matmul_k(q, k)attn = ops.mul(attn, self.scale)attn = self.softmax(attn)attn = self.attn_drop(attn)out = self.attn_matmul_v(attn, v)out = ops.transpose(out, (0, 2, 1, 3))out = ops.reshape(out, (b, n, c))out = self.out(out)out = self.out_drop(out)return out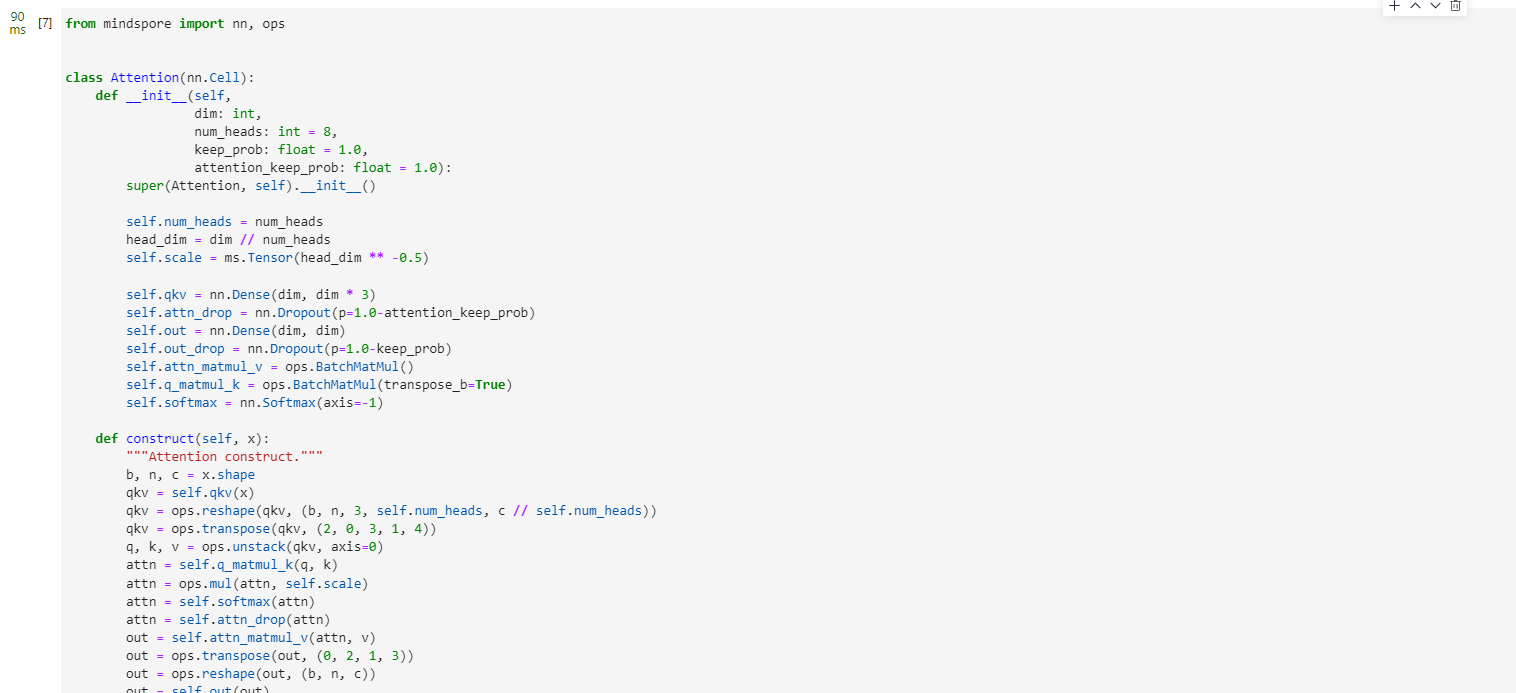
Transformer Encoder
在了解了Self-Attention结构之后,通过与Feed Forward,Residual
Connection等结构的拼接就可以形成Transformer的基础结构,下面代码实现了Feed Forward,Residual
Connection结构。
from typing import Optional, Dictclass FeedForward(nn.Cell):def __init__(self,in_features: int,hidden_features: Optional[int] = None,out_features: Optional[int] = None,activation: nn.Cell = nn.GELU,keep_prob: float = 1.0):super(FeedForward, self).__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.dense1 = nn.Dense(in_features, hidden_features)self.activation = activation()self.dense2 = nn.Dense(hidden_features, out_features)self.dropout = nn.Dropout(p=1.0-keep_prob)def construct(self, x):"""Feed Forward construct."""x = self.dense1(x)x = self.activation(x)x = self.dropout(x)x = self.dense2(x)x = self.dropout(x)return xclass ResidualCell(nn.Cell):def __init__(self, cell):super(ResidualCell, self).__init__()self.cell = celldef construct(self, x):"""ResidualCell construct."""return self.cell(x) + x
接下来就利用Self-Attention来构建ViT模型中的TransformerEncoder部分,类似于构建了一个Transformer的编码器部分,如下图[1]所示:
vit-encoder
ViT模型中的基础结构与标准Transformer有所不同,主要在于Normalization的位置是放在Self-Attention和Feed
Forward之前,其他结构如Residual Connection,Feed
Forward,Normalization都如Transformer中所设计。从Transformer结构的图片可以发现,多个子encoder的堆叠就完成了模型编码器的构建,在ViT模型中,依然沿用这个思路,通过配置超参数num_layers,就可以确定堆叠层数。
Residual
Connection,Normalization的结构可以保证模型有很强的扩展性(保证信息经过深层处理不会出现退化的现象,这是Residual
Connection的作用),Normalization和dropout的应用可以增强模型泛化能力。从以下源码中就可以清晰看到Transformer的结构。将TransformerEncoder结构和一个多层感知器(MLP)结合,就构成了ViT模型的backbone部分。
class TransformerEncoder(nn.Cell):def __init__(self,dim: int,num_layers: int,num_heads: int,mlp_dim: int,keep_prob: float = 1.,attention_keep_prob: float = 1.0,drop_path_keep_prob: float = 1.0,activation: nn.Cell = nn.GELU,norm: nn.Cell = nn.LayerNorm):super(TransformerEncoder, self).__init__()layers = []for _ in range(num_layers):normalization1 = norm((dim,))normalization2 = norm((dim,))attention = Attention(dim=dim,num_heads=num_heads,keep_prob=keep_prob,attention_keep_prob=attention_keep_prob)feedforward = FeedForward(in_features=dim,hidden_features=mlp_dim,activation=activation,keep_prob=keep_prob)layers.append(nn.SequentialCell([ResidualCell(nn.SequentialCell([normalization1, attention])),ResidualCell(nn.SequentialCell([normalization2, feedforward]))]))self.layers = nn.SequentialCell(layers)def construct(self, x):"""Transformer construct."""return self.layers(x)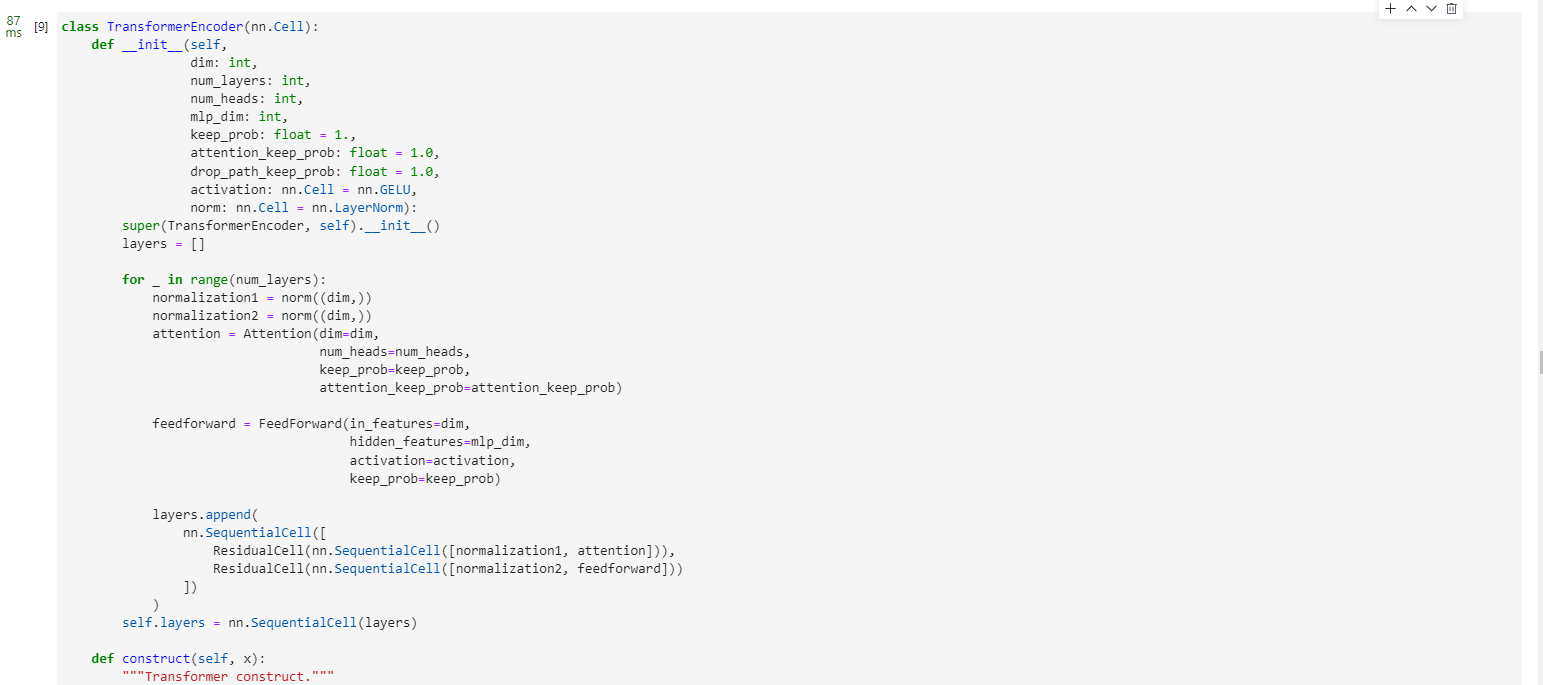
ViT模型的输入
传统的Transformer结构主要用于处理自然语言领域的词向量(Word Embedding or Word Vector),词向量与传统图像数据的主要区别在于,词向量通常是一维向量进行堆叠,而图片则是二维矩阵的堆叠,多头注意力机制在处理一维词向量的堆叠时会提取词向量之间的联系也就是上下文语义,这使得Transformer在自然语言处理领域非常好用,而二维图片矩阵如何与一维词向量进行转化就成为了Transformer进军图像处理领域的一个小门槛。
在ViT模型中:
通过将输入图像在每个channel上划分为16*16个patch,这一步是通过卷积操作来完成的,当然也可以人工进行划分,但卷积操作也可以达到目的同时还可以进行一次而外的数据处理;例如一幅输入224
x 224的图像,首先经过卷积处理得到16 x 16个patch,那么每一个patch的大小就是14 x 14。
再将每一个patch的矩阵拉伸成为一个一维向量,从而获得了近似词向量堆叠的效果。上一步得到的14 x 14的patch就转换为长度为196的向量。
这是图像输入网络经过的第一步处理。具体Patch Embedding的代码如下所示:
class PatchEmbedding(nn.Cell):MIN_NUM_PATCHES = 4def __init__(self,image_size: int = 224,patch_size: int = 16,embed_dim: int = 768,input_channels: int = 3):super(PatchEmbedding, self).__init__()self.image_size = image_sizeself.patch_size = patch_sizeself.num_patches = (image_size // patch_size) ** 2self.conv = nn.Conv2d(input_channels, embed_dim, kernel_size=patch_size, stride=patch_size, has_bias=True)def construct(self, x):"""Path Embedding construct."""x = self.conv(x)b, c, h, w = x.shapex = ops.reshape(x, (b, c, h * w))x = ops.transpose(x, (0, 2, 1))return x
输入图像在划分为patch之后,会经过pos_embedding 和 class_embedding两个过程。
class_embedding主要借鉴了BERT模型的用于文本分类时的思想,在每一个word
vector之前增加一个类别值,通常是加在向量的第一位,上一步得到的196维的向量加上class_embedding后变为197维。增加的class_embedding是一个可以学习的参数,经过网络的不断训练,最终以输出向量的第一个维度的输出来决定最后的输出类别;由于输入是16 x 16个patch,所以输出进行分类时是取 16 x 16个class_embedding进行分类。
pos_embedding也是一组可以学习的参数,会被加入到经过处理的patch矩阵中。
由于pos_embedding也是可以学习的参数,所以它的加入类似于全链接网络和卷积的bias。这一步就是创造一个长度维197的可训练向量加入到经过class_embedding的向量中。
实际上,pos_embedding总共有4种方案。但是经过作者的论证,只有加上pos_embedding和不加pos_embedding有明显影响,至于pos_embedding是一维还是二维对分类结果影响不大,所以,在我们的代码中,也是采用了一维的pos_embedding,由于class_embedding是加在pos_embedding之前,所以pos_embedding的维度会比patch拉伸后的维度加1。
总的而言,ViT模型还是利用了Transformer模型在处理上下文语义时的优势,将图像转换为一种“变种词向量”然后进行处理,而这样转换的意义在于,多个patch之间本身具有空间联系,这类似于一种“空间语义”,从而获得了比较好的处理效果。
整体构建ViT
以下代码构建了一个完整的ViT模型。
from mindspore.common.initializer import Normal
from mindspore.common.initializer import initializer
from mindspore import Parameterdef init(init_type, shape, dtype, name, requires_grad):"""Init."""initial = initializer(init_type, shape, dtype).init_data()return Parameter(initial, name=name, requires_grad=requires_grad)class ViT(nn.Cell):def __init__(self,image_size: int = 224,input_channels: int = 3,patch_size: int = 16,embed_dim: int = 768,num_layers: int = 12,num_heads: int = 12,mlp_dim: int = 3072,keep_prob: float = 1.0,attention_keep_prob: float = 1.0,drop_path_keep_prob: float = 1.0,activation: nn.Cell = nn.GELU,norm: Optional[nn.Cell] = nn.LayerNorm,pool: str = 'cls') -> None:super(ViT, self).__init__()self.patch_embedding = PatchEmbedding(image_size=image_size,patch_size=patch_size,embed_dim=embed_dim,input_channels=input_channels)num_patches = self.patch_embedding.num_patchesself.cls_token = init(init_type=Normal(sigma=1.0),shape=(1, 1, embed_dim),dtype=ms.float32,name='cls',requires_grad=True)self.pos_embedding = init(init_type=Normal(sigma=1.0),shape=(1, num_patches + 1, embed_dim),dtype=ms.float32,name='pos_embedding',requires_grad=True)self.pool = poolself.pos_dropout = nn.Dropout(p=1.0-keep_prob)self.norm = norm((embed_dim,))self.transformer = TransformerEncoder(dim=embed_dim,num_layers=num_layers,num_heads=num_heads,mlp_dim=mlp_dim,keep_prob=keep_prob,attention_keep_prob=attention_keep_prob,drop_path_keep_prob=drop_path_keep_prob,activation=activation,norm=norm)self.dropout = nn.Dropout(p=1.0-keep_prob)self.dense = nn.Dense(embed_dim, num_classes)def construct(self, x):"""ViT construct."""x = self.patch_embedding(x)cls_tokens = ops.tile(self.cls_token.astype(x.dtype), (x.shape[0], 1, 1))x = ops.concat((cls_tokens, x), axis=1)x += self.pos_embeddingx = self.pos_dropout(x)x = self.transformer(x)x = self.norm(x)x = x[:, 0]if self.training:x = self.dropout(x)x = self.dense(x)return x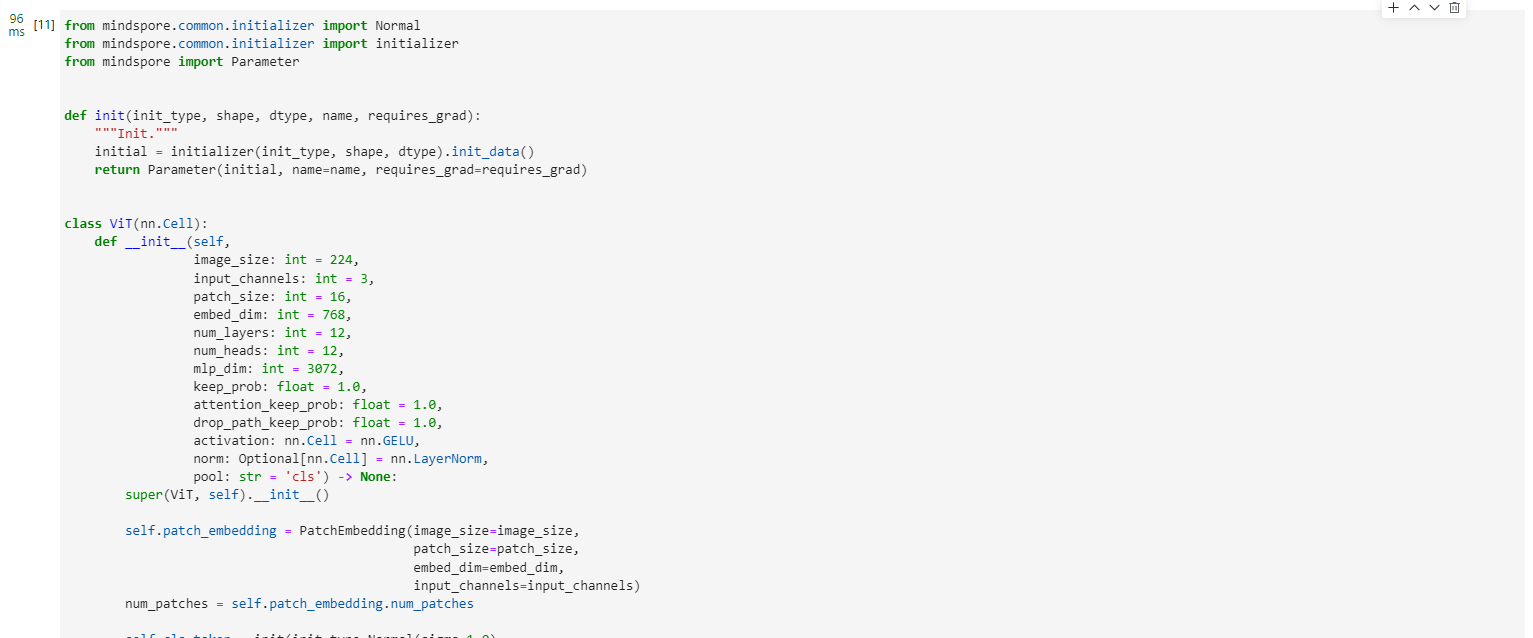
整体流程图如下所示:
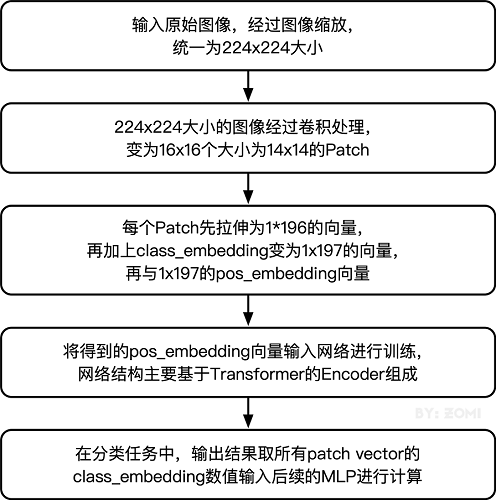
四、模型训练与推理
模型训练
from mindspore.nn import LossBase
from mindspore.train import LossMonitor, TimeMonitor, CheckpointConfig, ModelCheckpoint
from mindspore import train# define super parameter
epoch_size = 10
momentum = 0.9
num_classes = 1000
resize = 224
step_size = dataset_train.get_dataset_size()# construct model
network = ViT()# load ckpt
vit_url = "https://download.mindspore.cn/vision/classification/vit_b_16_224.ckpt"
path = "./ckpt/vit_b_16_224.ckpt"vit_path = download(vit_url, path, replace=True)
param_dict = ms.load_checkpoint(vit_path)
ms.load_param_into_net(network, param_dict)# define learning rate
lr = nn.cosine_decay_lr(min_lr=float(0),max_lr=0.00005,total_step=epoch_size * step_size,step_per_epoch=step_size,decay_epoch=10)# define optimizer
network_opt = nn.Adam(network.trainable_params(), lr, momentum)# define loss function
class CrossEntropySmooth(LossBase):"""CrossEntropy."""def __init__(self, sparse=True, reduction='mean', smooth_factor=0., num_classes=1000):super(CrossEntropySmooth, self).__init__()self.onehot = ops.OneHot()self.sparse = sparseself.on_value = ms.Tensor(1.0 - smooth_factor, ms.float32)self.off_value = ms.Tensor(1.0 * smooth_factor / (num_classes - 1), ms.float32)self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction)def construct(self, logit, label):if self.sparse:label = self.onehot(label, ops.shape(logit)[1], self.on_value, self.off_value)loss = self.ce(logit, label)return lossnetwork_loss = CrossEntropySmooth(sparse=True,reduction="mean",smooth_factor=0.1,num_classes=num_classes)# set checkpoint
ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size, keep_checkpoint_max=100)
ckpt_callback = ModelCheckpoint(prefix='vit_b_16', directory='./ViT', config=ckpt_config)# initialize model
# "Ascend + mixed precision" can improve performance
ascend_target = (ms.get_context("device_target") == "Ascend")
if ascend_target:model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O2")
else:model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O0")# train model
model.train(epoch_size,dataset_train,callbacks=[ckpt_callback, LossMonitor(125), TimeMonitor(125)],dataset_sink_mode=False,)
模型验证
dataset_val = ImageFolderDataset(os.path.join(data_path, "val"), shuffle=True)trans_val = [transforms.Decode(),transforms.Resize(224 + 32),transforms.CenterCrop(224),transforms.Normalize(mean=mean, std=std),transforms.HWC2CHW()
]dataset_val = dataset_val.map(operations=trans_val, input_columns=["image"])
dataset_val = dataset_val.batch(batch_size=16, drop_remainder=True)# construct model
network = ViT()# load ckpt
param_dict = ms.load_checkpoint(vit_path)
ms.load_param_into_net(network, param_dict)network_loss = CrossEntropySmooth(sparse=True,reduction="mean",smooth_factor=0.1,num_classes=num_classes)# define metric
eval_metrics = {'Top_1_Accuracy': train.Top1CategoricalAccuracy(),'Top_5_Accuracy': train.Top5CategoricalAccuracy()}if ascend_target:model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics=eval_metrics, amp_level="O2")
else:model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics=eval_metrics, amp_level="O0")# evaluate model
result = model.eval(dataset_val)
print(result)
模型推理
dataset_infer = ImageFolderDataset(os.path.join(data_path, "infer"), shuffle=True)trans_infer = [transforms.Decode(),transforms.Resize([224, 224]),transforms.Normalize(mean=mean, std=std),transforms.HWC2CHW()
]dataset_infer = dataset_infer.map(operations=trans_infer,input_columns=["image"],num_parallel_workers=1)
dataset_infer = dataset_infer.batch(1)
import os
import pathlib
import cv2
import numpy as np
from PIL import Image
from enum import Enum
from scipy import ioclass Color(Enum):"""dedine enum color."""red = (0, 0, 255)green = (0, 255, 0)blue = (255, 0, 0)cyan = (255, 255, 0)yellow = (0, 255, 255)magenta = (255, 0, 255)white = (255, 255, 255)black = (0, 0, 0)def check_file_exist(file_name: str):"""check_file_exist."""if not os.path.isfile(file_name):raise FileNotFoundError(f"File `{file_name}` does not exist.")def color_val(color):"""color_val."""if isinstance(color, str):return Color[color].valueif isinstance(color, Color):return color.valueif isinstance(color, tuple):assert len(color) == 3for channel in color:assert 0 <= channel <= 255return colorif isinstance(color, int):assert 0 <= color <= 255return color, color, colorif isinstance(color, np.ndarray):assert color.ndim == 1 and color.size == 3assert np.all((color >= 0) & (color <= 255))color = color.astype(np.uint8)return tuple(color)raise TypeError(f'Invalid type for color: {type(color)}')def imread(image, mode=None):"""imread."""if isinstance(image, pathlib.Path):image = str(image)if isinstance(image, np.ndarray):passelif isinstance(image, str):check_file_exist(image)image = Image.open(image)if mode:image = np.array(image.convert(mode))else:raise TypeError("Image must be a `ndarray`, `str` or Path object.")return imagedef imwrite(image, image_path, auto_mkdir=True):"""imwrite."""if auto_mkdir:dir_name = os.path.abspath(os.path.dirname(image_path))if dir_name != '':dir_name = os.path.expanduser(dir_name)os.makedirs(dir_name, mode=777, exist_ok=True)image = Image.fromarray(image)image.save(image_path)def imshow(img, win_name='', wait_time=0):"""imshow"""cv2.imshow(win_name, imread(img))if wait_time == 0: # prevent from hanging if windows was closedwhile True:ret = cv2.waitKey(1)closed = cv2.getWindowProperty(win_name, cv2.WND_PROP_VISIBLE) < 1# if user closed window or if some key pressedif closed or ret != -1:breakelse:ret = cv2.waitKey(wait_time)def show_result(img: str,result: Dict[int, float],text_color: str = 'green',font_scale: float = 0.5,row_width: int = 20,show: bool = False,win_name: str = '',wait_time: int = 0,out_file: Optional[str] = None) -> None:"""Mark the prediction results on the picture."""img = imread(img, mode="RGB")img = img.copy()x, y = 0, row_widthtext_color = color_val(text_color)for k, v in result.items():if isinstance(v, float):v = f'{v:.2f}'label_text = f'{k}: {v}'cv2.putText(img, label_text, (x, y), cv2.FONT_HERSHEY_COMPLEX,font_scale, text_color)y += row_widthif out_file:show = Falseimwrite(img, out_file)if show:imshow(img, win_name, wait_time)def index2label():"""Dictionary output for image numbers and categories of the ImageNet dataset."""metafile = os.path.join(data_path, "ILSVRC2012_devkit_t12/data/meta.mat")meta = io.loadmat(metafile, squeeze_me=True)['synsets']nums_children = list(zip(*meta))[4]meta = [meta[idx] for idx, num_children in enumerate(nums_children) if num_children == 0]_, wnids, classes = list(zip(*meta))[:3]clssname = [tuple(clss.split(', ')) for clss in classes]wnid2class = {wnid: clss for wnid, clss in zip(wnids, clssname)}wind2class_name = sorted(wnid2class.items(), key=lambda x: x[0])mapping = {}for index, (_, class_name) in enumerate(wind2class_name):mapping[index] = class_name[0]return mapping# Read data for inference
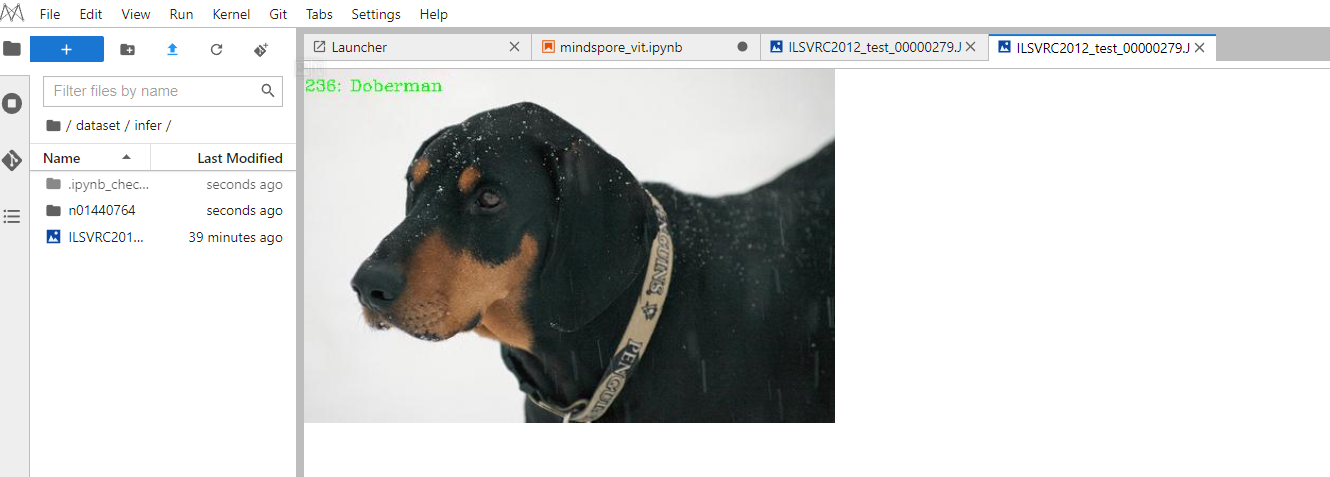
for i, image in enumerate(dataset_infer.create_dict_iterator(output_numpy=True)):image = image["image"]image = ms.Tensor(image)prob = model.predict(image)label = np.argmax(prob.asnumpy(), axis=1)mapping = index2label()output = {int(label): mapping[int(label)]}print(output)show_result(img="./dataset/infer/n01440764/ILSVRC2012_test_00000279.JPEG",result=output,out_file="./dataset/infer/ILSVRC2012_test_00000279.JPEG")
推理过程完成后,在推理文件夹下可以找到图片的推理结果,可以看出预测结果是Doberman,与期望结果相同,验证了模型的准确性。
相关文章:
华为开源自研AI框架昇思MindSpore应用案例:基于MindSpore框架的UNet-2D案例实现
目录 一、环境准备1.进入ModelArts官网2.使用CodeLab体验Notebook实例 二、环境准备与数据读取三、模型解析Transformer基本原理Attention模块 Transformer EncoderViT模型的输入整体构建ViT 四、模型训练与推理模型训练模型验证模型推理 近些年,随着基于自注意&…...
Python入门【TCP建立连接的三次握手、 TCP断开连接的四次挥手、套接字编程实战、 TCP编程的实现、TCP双向持续通信】(二十七)
👏作者简介:大家好,我是爱敲代码的小王,CSDN博客博主,Python小白 📕系列专栏:python入门到实战、Python爬虫开发、Python办公自动化、Python数据分析、Python前后端开发 📧如果文章知识点有错误…...

React笔记-React入门
主要是现在要改一个开源项目,需要学习下React入门,在此记录一下。 几个关键的库 React底层核心:react.development.js React操作DOM库:react-dom.development.js 解析ES6语法:babel.min.js React.createElement() …...

SD WebUI 扩展:prompt-all-in-one
sd-webui-prompt-all-in-one 是一个基于 Stable Diffusion WebUI 的扩展,旨在提高提示词/反向提示词输入框的使用体验。它拥有更直观、强大的输入界面功能,它提供了自动翻译、历史记录和收藏等功能,它支持多种语言,满足不同用户的…...

Go和Java实现中介者模式
Go和Java实现中介者模式 下面通过一个同事之间相互通信的例子来说明中介者模式的使用。 1、中介者模式 中介者模式是用来降低多个对象和类之间的通信复杂性。这种模式提供了一个中介类,该类通常处理不同类之间的 通信,并支持松耦合,使代码…...

CentOS系统环境搭建(十五)——CentOS安装Kibana
centos系统环境搭建专栏🔗点击跳转 关于Elasticsearch的安装请看CentOS系统环境搭建(十二)——CentOS7安装Elasticsearch。 CentOS安装Kibana 文章目录 CentOS安装Kibana1.下载2.上传3.解压4.修改kibana配置文件5.授予es用户权限6.kibana 后台…...

简单的洗牌算法
目录 前言 问题 代码展现及分析 poker类 game类 Text类 前言 洗牌算法为ArrayList具体使用的典例,可以很好的让我们快速熟系ArrayList的用法。如果你对ArrayList还不太了解除,推荐先看本博主的ArrayList的详解。 ArrayList的详解_WHabcwu的博客-CSD…...

vscode用ssh远程连接linux
1、vscode是利用ssh远程连接linux的,所以首先确保vscode已经安装了这两个插件 2、点击左下角的连接 3、选择Connect to Host…… 5、按格式输入 ssh 主机名ip 比如我的:ssh mnt192.168.198.128 6、选择第一个打开配置文件,确保输入正确 7、…...
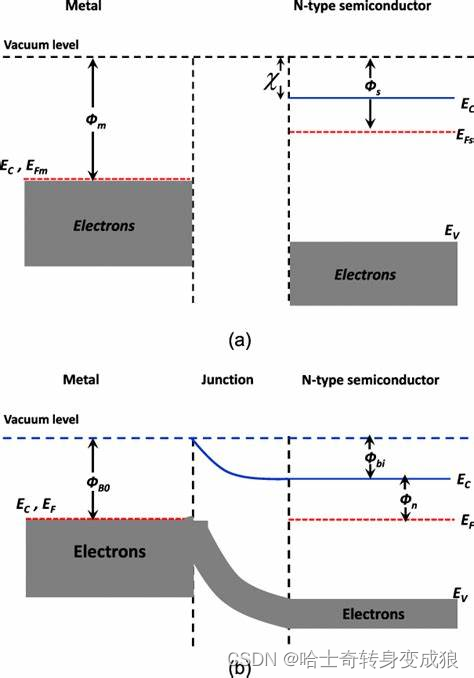
chapter 3 Free electrons in solid - 3.2 量子自由电子理论对一些现象的解释
3.2 自由电子气的热容 Heat capacity of free electron gas 3.2.1 计算自由电子的热容 Calculation of Heat Capacity of free Electrons T>0K, total energy of free electrons: E ∫ E d N 3 5 N e E F 0 [ 1 5 12 π 2 ( k B T E F 0 ) 2 ] E \int EdN \frac{3}{5}…...

vue实现打印功能
在Vue应用中调用打印机功能,可以使用JavaScript的window.print()方法。这个方法会打开打印对话框,然后让我们选择打印设置并打印文档,但是尼这种方法依赖于浏览器的打印功能。 以下是一个简单的示例,演示如何在Vue组件中调用打印…...

golang—面试题大全
目录标题 sliceslice和array的区别slice扩容机制slice是否线程安全slice分配到栈上还是堆上扩容过程中是否重新写入go深拷贝发生在什么情况下?切片的深拷贝是怎么做的copy和左值进行初始化区别slice和map的区别 mapmap介绍map的key的类型map对象如何比较map的底层原…...

Spring、Springboot、SpringCloud--包含的知识点大全
类型难度AOPspring-自定义AOP面向切面注解--统一切面处理-登陆信息采集快速入门SpringbootAOP实现切面处理请求Demo线程池通俗易懂的线程池底层原理,一文知所有数据结构数据结构-链表篇数据结构--数组篇数据结构之-concurrentHashMap源码分析JVMJVM调优及各种问题处…...
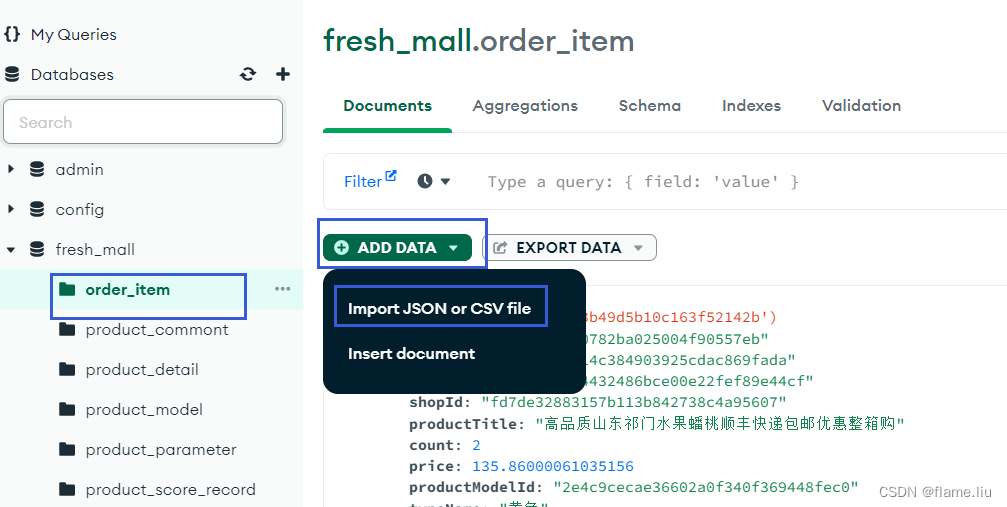
MongoDB:数据库初步应用
一.连接MongoDB 1.MongoDBCompass连接数据库 连接路径:mongodb://用户名:密码localhost:27017/ 2.创建数据库(集合) MongoDB中数据库被称为集合. MongoDBCompass连接后,点击红色框加号创建集合,点击蓝色框加号创建文档(数据表) 文档中的数据结构(相当于表中的列)设计不用管…...

C#之枚举中的按位与()按位或(|)。
一些基础定义: 按位或运算符(|)是一种位运算符,用来对两个二进制数进行操作。对于每个位上的1,如果至少有一个二进制数中的对应位为1,则结果为1;否则,结果为0。按位与运算符&#x…...
Blazor前后端框架Known-V1.2.12
V1.2.12 Known是基于C#和Blazor开发的前后端分离快速开发框架,开箱即用,跨平台,一处代码,多处运行。 Gitee: https://gitee.com/known/KnownGithub:https://github.com/known/Known 概述 基于C#和Blazo…...

bug记录:微信小程序 给button使用all: initial重置样式
场景:通过uniapp开发微信小程序 ,使用uview的u-popup弹窗,里面内嵌了一个原生button标签,因为微信小程序的button是有默认样式的,所以通过all: initial重置样式 。但是整个弹窗的点击事件都会被button上面的点击事件覆…...
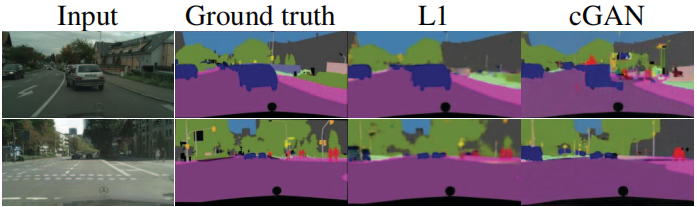
【计算机视觉|生成对抗】带条件的对抗网络进行图像到图像的转换(pix2pix)
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处 标题:Image-to-Image Translation with Conditional Adversarial Networks 链接:Image-to-Image Translation with Conditional Adversarial Networks | IEEE Conference Publicati…...

[时序数据库]:InfluxDB进阶
文章目录 1 摘要2 背景2.1 问题一:针对Influx V2.0工具2.2 问题二:针对Influx查询语言 3 需求分析4 快速入门4.1 客户端驱动版本选择4.2 连接influx4.2.1 influx配置信息4.2.2 influx连接配置4.2.3 测试连通情况 5 Influx工具类5.1 InfluxQL工具类5.1.1 …...
uniapp编写微信小程序遇到的坑总结
1、阻止事件冒泡 使用uniapp开发微信小程序的时候,发现使用click.stop来阻止事件冒泡没有作用,点击了之后发现仍然会触发父组件或者祖先组件的事件。 在网上查阅,发现使用tap.stop才能阻止事件冒泡。 2、二维码生成 在网上找了很多&…...

Binary operator ‘*‘ cannot be applied to two ‘Double?‘ operands
在 swift 中声明 Double 类型参数变量在进行运算处理时抛出了如下异常 Binary operator * cannot be applied to two Double? operands 情况一 参数类型不匹配,需将参数类型进行匹配 self.max height / (length * width) // 初始 self.max height / (length * Double(wid…...

告别C盘爆满!Windows 11下ESP-IDF 5.3.2环境安装与路径优化全攻略
告别C盘爆满!Windows 11下ESP-IDF 5.3.2环境安装与路径优化全攻略 你是否经历过C盘空间告急的恐慌?当红色进度条填满磁盘图标时,那种窒息感堪比程序员面对满屏报错。对于嵌入式开发者而言,ESP-IDF环境安装往往成为C盘的"隐形…...

LVGL模拟器不止能看Demo:在Ubuntu里用VSCode调试和修改官方例程的实战技巧
LVGL模拟器深度开发指南:在Ubuntu与VSCode中实现高效UI调试 当你在嵌入式设备上开发LVGL界面时,是否经历过反复烧录、调试的漫长等待?模拟器开发可以彻底改变这种低效的工作流程。本文将带你超越简单的Demo演示,探索如何将LVGL模…...

【PyO3/Rust-Python测试权威框架】:Rust生态下Python扩展的零信任CI流水线设计
第一章:Python 扩展模块测试Python 扩展模块(如用 C/C、Rust 或 Cython 编写的模块)在提升性能的同时,也引入了跨语言交互的复杂性。对其开展系统性测试,是保障功能正确性、内存安全性和 ABI 兼容性的关键环节。测试环…...

STM32的ADC+DMA还能这么玩?深入剖析定时器触发与波形显示的性能边界与优化
STM32的ADCDMA性能极限探索:从定时器触发到波形显示的深度优化 在嵌入式数据采集领域,ADC与DMA的协同工作一直是性能优化的关键战场。当我们需要在资源受限的MCU上实现高精度波形采集时,如何榨取STM32的每一分性能潜力?本文将带您…...

CoPaw代码生成能力展示:从自然语言描述到可运行Python脚本
CoPaw代码生成能力展示:从自然语言描述到可运行Python脚本 1. 开篇:当自然语言遇上代码生成 "能不能帮我写个Python脚本,把文件夹里的图片都转成灰度图?"这样的需求,现在可以直接说给CoPaw听。作为一款专注…...

OpenClaw学习路径:从nanobot镜像入门到开发自定义技能
OpenClaw学习路径:从nanobot镜像入门到开发自定义技能 1. 为什么选择OpenClaw作为自动化助手 第一次听说OpenClaw时,我正在为重复性的文件整理工作头疼。作为一个经常需要处理大量技术文档的开发者,每天要花费数小时在机械的文件分类、重命…...

广汽埃安品牌车型AION UT在奥地利麦格纳工厂正式量产启动并成功下线 | 美通社头条
、美通社消息:3月18日,广汽欧洲业务发展迎来重要里程碑——旗下埃安品牌车型AION UT在奥地利麦格纳(Magna)工厂正式实现量产启动(SOP)并成功下线,标志着广汽在欧洲本地化战略迈入实质性推进阶段。AION UT是广汽欧洲本地化战略的重要核心车型&…...
)
游戏开发必备:Unity中三维坐标系转换的5种实战技巧(附代码)
Unity三维坐标系转换实战指南:从原理到代码实现 在游戏开发中,三维物体的旋转和坐标系转换是构建沉浸式体验的核心技术。无论是角色转向、镜头跟随还是物理模拟,开发者都需要精准控制物体在三维空间中的方位。Unity作为主流游戏引擎ÿ…...
)
【独家首发】Python WASM安全白皮书:XSS绕过、WASI权限逃逸、沙箱逃逸——3类高危漏洞POC及修复代码(限前500名开发者获取)
第一章:Python WASM安全白皮书导论 WebAssembly(WASM)正迅速成为云原生、边缘计算与浏览器沙箱场景中关键的安全执行载体。随着 Python 生态对 WASM 的支持逐步成熟(如 Pyodide、WASI-SDK 与 GraalPy 的跨编译能力)&am…...

力扣994. 腐烂的橘子
题目:腐烂的橘子https://leetcode.cn/problems/rotting-oranges/description/在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一: 0 代表空单元格;1 代表新鲜橘子;2 代表腐烂的橘子。 每分钟,腐…...