SpringBoot的日志信息及Lombok的常用注解
文章目录
- 一. 日志的介绍
- 1. 什么是日志
- 2. 日志的作用
- 二. 日志的使用
- 1. 日志格式说明
- 2. 自定义日志的输出
- 3. 日志级别
- 4. 日志级别的配置
- 5. 日志持久化
- 6. 更简单的输出日志-Lomok
- 7. Lombok框架实现原理以及其他常见注解
一. 日志的介绍
1. 什么是日志
日志是我们程序重要组成部分,它是程序在运行过程当中输出的一些提示或异常信息,我们可以通过日志来观察程序执行的情况,如果程序出现 Bug,我们可以根据日志去发现和排查程序的 Bug。
SpringBoot 项目在启动的时候,就会有默认的日志输出,如下图所示:
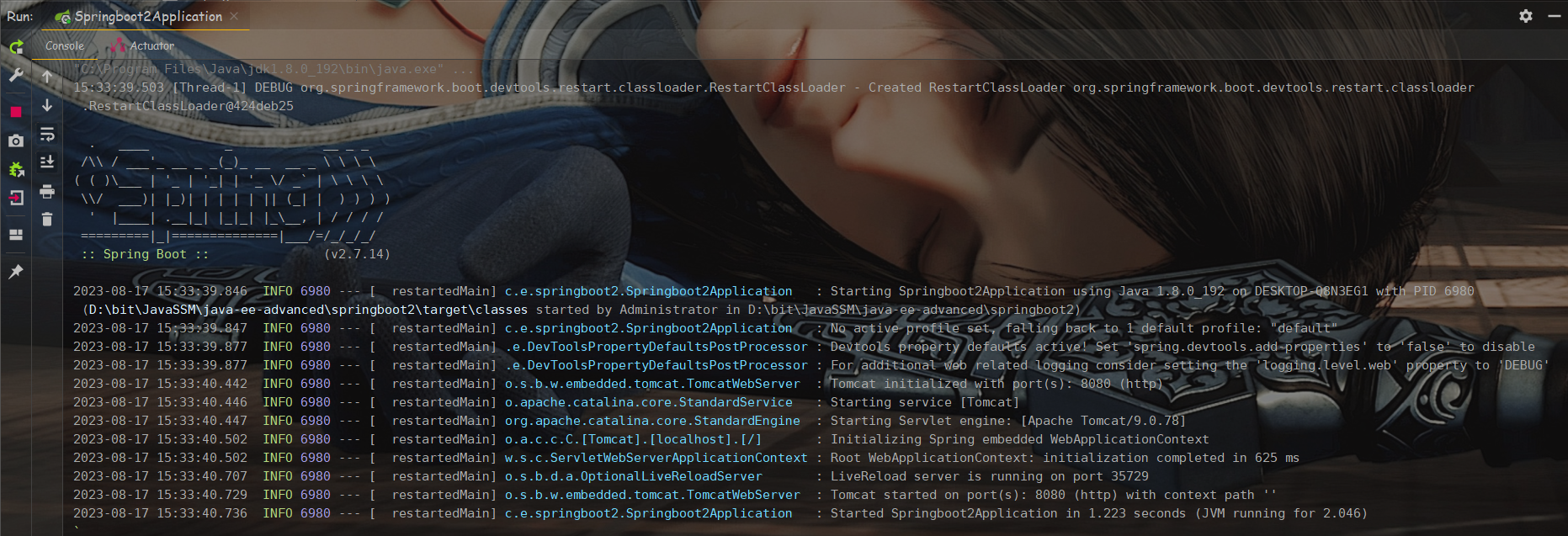
之所以会有上面的输出,是因为 SpringBoot 中内置了日志框架。
SpringBoot 中内置了 SLF4J 和 logback 两个日志框架,用户层面并不是直接操作具体的日志对象,而是使用 SLF4J 提供给用户的 API 进而由 logback 操作具体的日志对象实现日志。

SLF4J 这类框架是使用“门面模式”来实现的,SLF4J 其实和 JDBC 很像,我们知道使用 JDBC 操作数据库,一套 JDBC 代码就可以操作很多种数据库,可以是 MySQL,Oracle,DB2,SqlServer等,而这个JDBC 就相当于代理一样,来代理去操作数据库,我们不必关心各种数据库的实现,只需关注 JDBC 提供给我们的的 API 即可。
类似的,SLF4J 中也并不是真正完成了日志实现的框架,它只是一个门面或者一个代理,我们调用 SLF4J 的 API,SLF4J 中还会去调用 logback 这样的日志实现框架,此时我们就不必关心日志实现的细节,这一层面我们是感知不到的,这就是门面模式所带来的好处,还有一个好处就是如果日志实现层出现了漏洞,只需要修改更换日志实现的框架即可,而 SLF4J 可以匹配相应的日志框架,此时虽然日志实现的框架发生了改变,但我们写的代码仍然不受影响,这样就使得系统的依赖性降低,利于系统更新和维护。

2. 日志的作用
- 能够帮助程序猿排除程序的 Bug。
- 记录用户登录日志,方便分析用户是正常登录还是恶意破解用户。
- 记录系统的操作日志,方便数据恢复和定位操作人。
- 记录程序的执行时间,方便为以后优化程序提供数据支持。
二. 日志的使用
使用日志框架可以配置日志的级别来控制日志的输出,而我们日常使用System.out.printf来输出日志是无法做到这一点的。
1. 日志格式说明
对于控制台输出的日志,它的各部分含义如下:

信息中的包名有部分是简写,取的是包名的第一个字母;
根据这些信息,我们就可以知道日志是发生在什么时间,在哪个线程,哪个类,以及具体的日志信息。
2. 自定义日志的输出
1️⃣第一步,在类中先获取到日志对象,这个日志对象来自于日志框架SLF4J。
假设我们在类LogController设置自定义日志的输出,则日志对象创建代码如下:
每一个类都对应一个日志对象,可以通过日志工厂LoggerFactory获取的,导包的时候要注意Logger对象是在org.slf4j包下的,不要导错。
// 获取日志对象
private static Logger log =LoggerFactory.getLogger(LogController.class);
getLogger()一般传入传入当前类的类型,这里的参数用来定位日志的归属类,以方便日志输出,输出的日志信息中有了日志的定位, 才能更方便、更直观的定位到问题类。
2️⃣第二步,使用日志对象提供的方法来实现自定义日志的打印。
日志对象提供的方法有很多,可以设定不同级别的日志信息输出。
🍂示例代码:
@RestController相当于是将@Controller和@ResponseBody这两个注解合起来的效果。
package com.example.springboot2.controller;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class LogController {// 获取日志对象private static Logger log =LoggerFactory.getLogger(LogController.class);@RequestMapping("/log")public void log() {log.trace("我是trace");log.debug("我是debug");log.info(("我是info"));log.warn("我是warn");log.error("我是error");}
}
我们启动程序后,访问http://127.0.0.1:8080/log后,控制台就有相应的日志输出了。

观察输出结果,我们的代码是写了 5 个级别的日志输出的,为什么这里结果只有 3 个结果呢?这是因为SpringBoot 项目下,默认日志级别为info,低于info日志级别的都不会输出。
3. 日志级别
🍂日志级别分为一下几种:
- trace:微量,少许的意思,级别最低。
- debug:需要调试时候的关键信息打印。
- info:普通的打印信息(默认日志级别)。
- warn:警告,不影响使用,但需要注意的问题。
- error:错误信息,级别较高的错误日志信息。
- fatal:致命的,因为代码异常导致程序退出执行的事件,不支持用户自定义。

SpringBoot 项目默认的日志级别是info,那么比info日志级别低的是不能输出的,也就是debug与trace的日志是不会输出的,只有大于等于info级别的日志才会输出。
🍂日志级别的作用:
- 日志级别可以帮我们筛选出重要的信息,比如设置日志级别为 error,那么就可以只看程序的报错日志了,对于普通的调试日志和业务日志就可以忽略了,从而节省开发者信息筛选的时间。
- 日志级别可以控制不同环境下,⼀个程序是否需要打印日志,如开发环境我们就需要很详细的日志信息, 而生产环境为了保证性能和安全性就会输⼊尽量少的⽇志,通过日志的级别就可以实现此需求。
简单来说,就是过滤信息,将业务不需要的日志屏蔽掉。
4. 日志级别的配置
日志级别是可以通过配置文件进行设置的,日志级别包括两类,一类是全局日志级别,另一类就是局部日志级别,全局日志级别可以影响全局日志的输出,而局部日志级别只会影响一个局部的日志输出,并且局部日志级别配置大于全局日志级别的配置。
🎯全局日志级别配置,如修改默认日志级别为trace:
properties 日志格式:
# 设置全局日志级别
logging.level.root=trace
yml 日志格式:
logging:level:root: trace
运行上面我们的自定义日志代码,此时就会发现,我们所有的自定义日志信息都会输出,并且随着程序启动相比较默认情况下会有更多的日志信息输出,毕竟这里设置的是全局的配置文件,会影响全局。

🎯下面来介绍局部日志级别的配置,我们将LogController类的日志级别设置为warn,此时只会LogController类中日志输出级别,并不会影响其他位置的日志信息输出。
properties 格式配置文件:
# 设置夹局部的日志级别 (包名/包名+类名)
logging.level.com.example.demo.controller.LogController=warn
yml 格式配置文件:
logging:level:com:example:demo:controller: LogController :warn
控制台结果:

yml 格式配置文件可以一步设置全局和局部的日志级别,比如:
logging:level:root: infocom:example:springboot2:controller: errorservice: warn
root设置的是全局日志级别,项目中所有日志级别都是info;和root同级下可设置局部具体类的日志级别m这里就是com.example.springboot2.controller和com.example.springboot2.service包下的类,级别分别为error和warn。
5. 日志持久化
前面的介绍都是将日志输出在控制台上的,然而我们在生产环境下往往需要将日志保存下来,以便于后续出现问题时去追溯原因,将日志保存下来的过程就称之为持久化。
实现日志持久化的方式就是将日志信息保存到磁盘,同样可以通过设置配置文件实现。
🎯方式1:设置日志保存路径
properties 格式配置文件:
logging.file.path=D:\\bit\\logs
yml 格式配置文件:
logging:file:path: D:\\bit\\logs
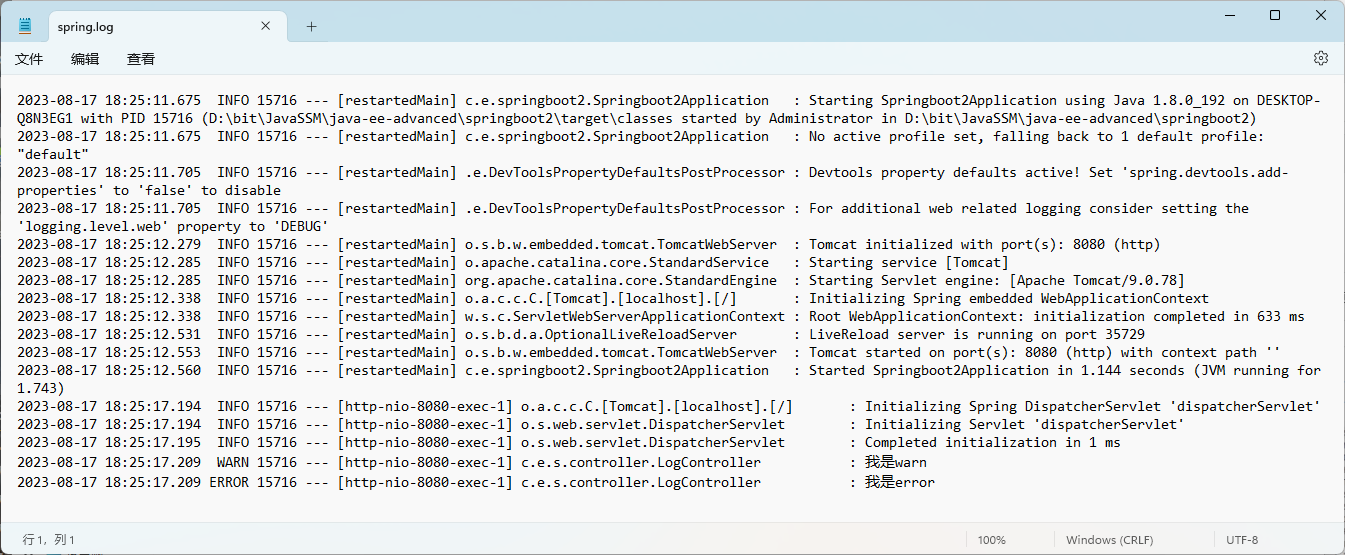
启动程序,此时 SpringBoot 就会将控制台中打印的日志写到对应的目录了,日志文件默认名的为spring.log。

🎯方式2:设置日志保存文件
properties 格式配置文件:
logging.file.name=D:\\bit\\log\\logging.log
yml 格式配置文件:
logging:file:name: D:\\bit\\log\\logging.log
效果如下:

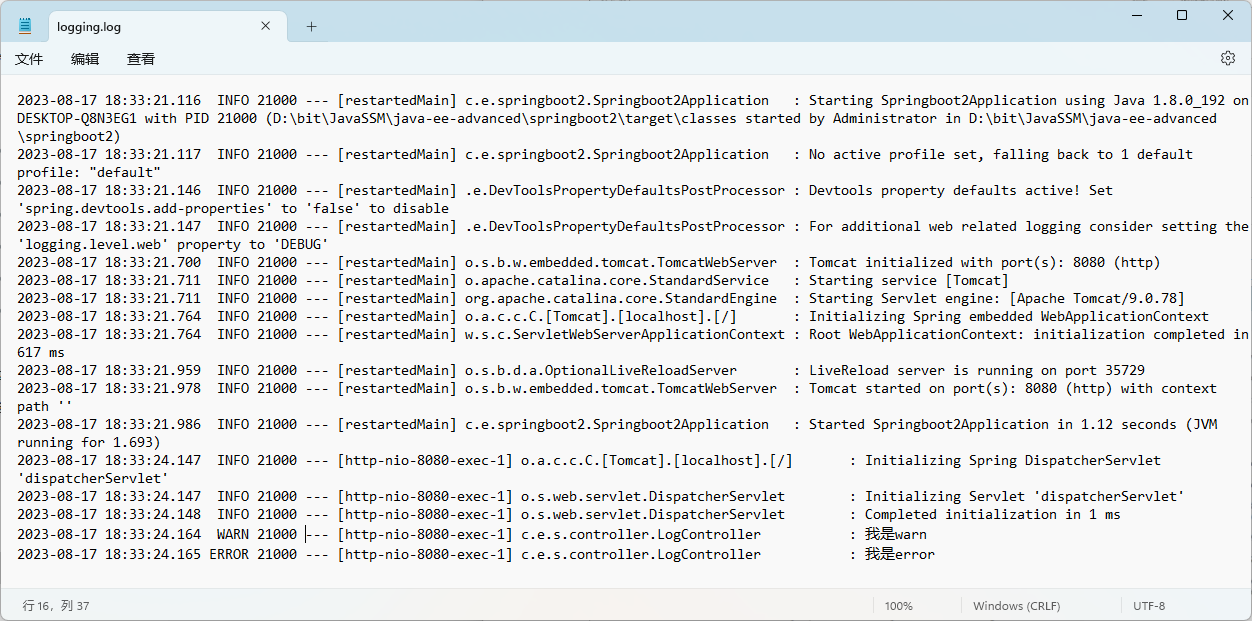
还要注意,多次访问程序产生的日志是以追加的形式保存到日志文件当中的,SpringBoot 默认保存日志文件的大小为10MB**,**超出范围就会自动创建新的日志文件,然后保存到新的日志文件当中。
当然,也可以通过配置文件自定义日志文件的大小,配置方式如下:
# properties格式
logging.logback.rollingpolicy.max-file-size=10MB# yml格式
logging:logback:rollingpolicy:max-file-size: 10MB
6. 更简单的输出日志-Lomok
每次都使⽤ LoggerFactory.getLogger(xxx.class) 很繁琐,且每个类都添加⼀遍,也很麻烦,在 Lombok 中有一个@Slf4j注解,可以使用该注解更简单的输出日志。
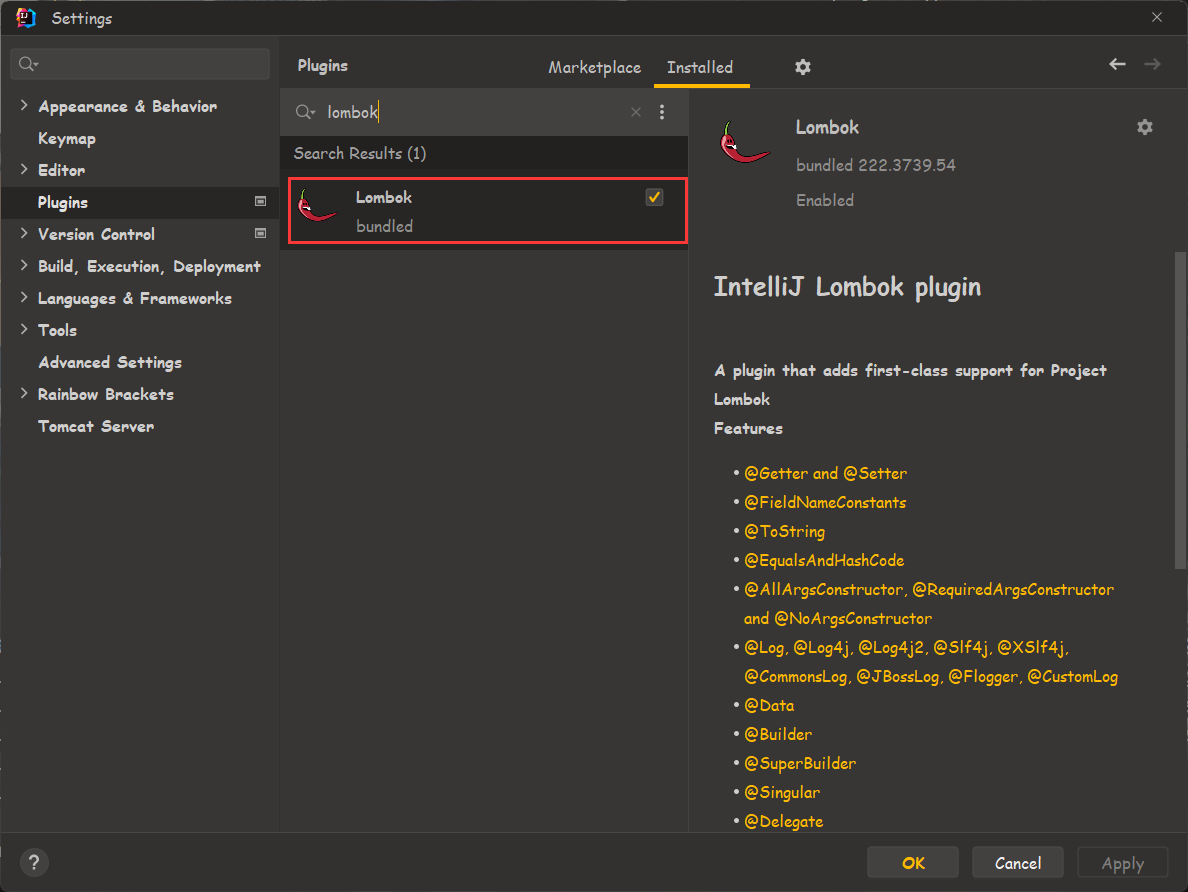
准备工作,首先要确保你的 IDEA 中有 Lombok 这个插件,没有的话去下载一下。
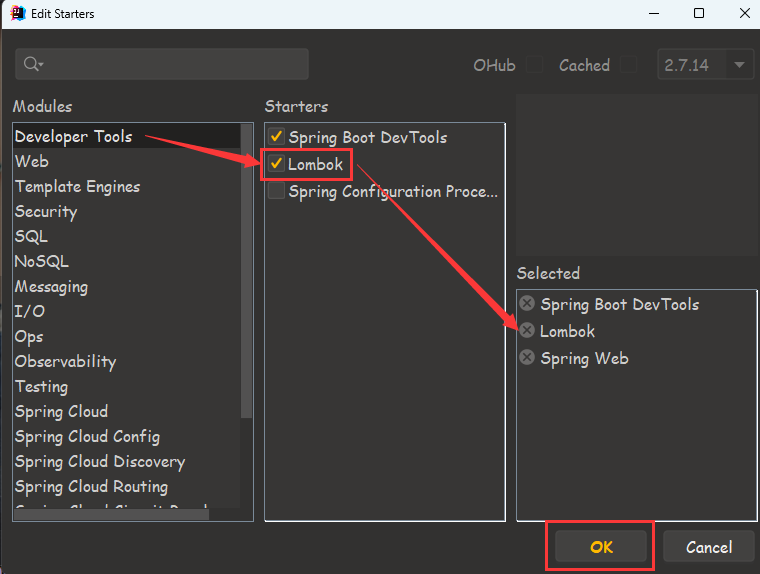
然后,添加 Lombok 依赖,可以使用 Edit Starters 插件快捷添加。
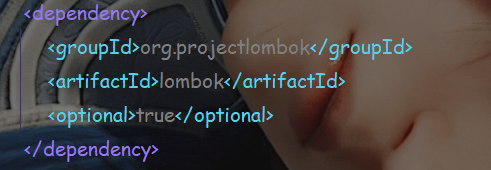
刷新一下,依赖就添加好了。
🍂使用方法:在想打印日志的类上加上 @Slf4j 注解即可,它会为当前类提供一个 log 对象。
要注意使用 @Slf4j 注解,在程序中使用 log 对象即可输⼊⽇志,并且只能使⽤ log 对象才能输出,这是 lombok 提供的对象名;代码中输入 log 后就会有相关方法的提醒(前提是安装了 lombok 插件)。
package com.example.springboot2.controller;import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@Slf4j // 当前的类中就可以直接使用 log 对象, @Slf4j 产生一个 log 对象, 直接使用即可
public class LogController2 {@RequestMapping("/log2")public void log2(){log.trace("我是trace");log.debug("我是debug");log.info(("我是info"));log.warn("我是warn");log.error("我是error");}}
启动程序,访问路路径http://127.0.0.1:8080/log2,同样可以输出日志,代码更简单。

@Slf4j 注解替代了日志对象获取的代码:
private final static Logger log = LoggerFactory.getLogger(LogController2.class);
7. Lombok框架实现原理以及其他常见注解
Lombok 框架其实在编译的时候,将依据注解去替生成对应的代码,比如就像上面的日志对象创建,加上一个 @Slf4j 注解后,在编译时就会将类似与上面创建日志对象的代码生成到我们所写代码里面去,包括Lombok 其他的注解,如生成 Setter 的注解 @Setter,生成 Getter 的注解 @Getter 等都是通过编译时期间实现的。
🍂Lombok作用:
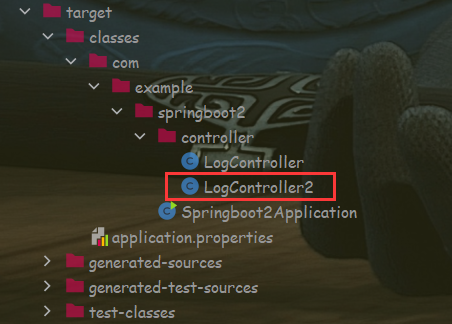
比如上面我们写的代码最终生成相应的字节码文件就在 target 目录中,target 目录中的代码才是项目最终执行的代码,查看 target 目录如下:
我们来对比一下我们LogController2.java原文件代码和程序运行起来后生成LogController2.class文件中的代码(由 IDEA 反编译显示)。
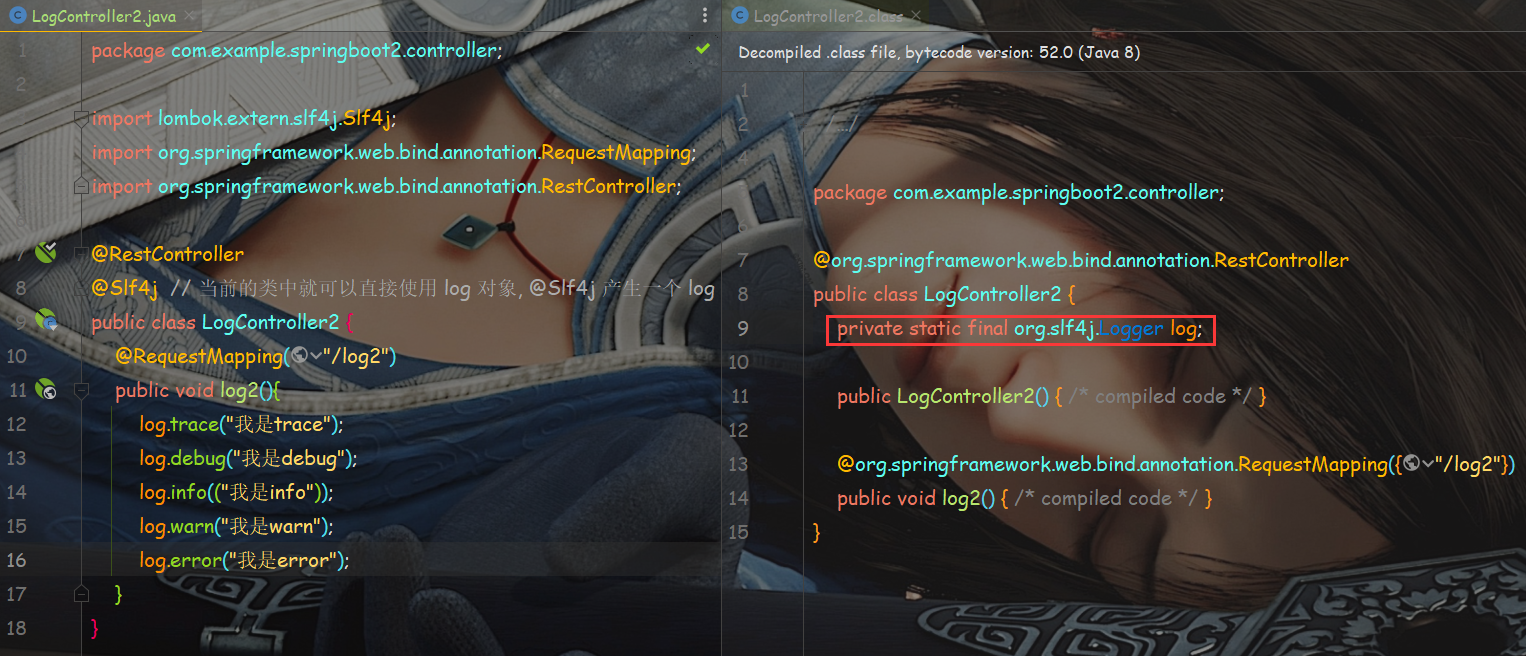
发现代码中的 @Slf4j 注解就不存存在了,被 log 对象替代了,所以,Lombok 是不会影响程序运行的信能的,它要完成的工作都是在编译生成字节码文件前完成的。
🍂其他常用注解:
基本注解:
| 注解 | 作用 |
|---|---|
| @Setter | ⾃动添加 setter 方法 |
| @Getter | ⾃动添加 getter 方法 |
| @ToString | ⾃动添加 toString 方法 |
| @EqualsAndHashCode | ⾃动添加 equals 和 hashCode 方法 |
| @NoArgsConstructor | ⾃动添加⽆参构造方法 |
| @AllArgsConstructor | ⾃动添加全属性构造⽅法,顺序按照属性的定义顺序 |
| @NonNull | 属性不能为 null |
| @RequireArgsConstructor | ⾃动添加必需属性的构造方法,final + @NonNull 的 属性为必需 |
组合注解:
| 注解 | 作用 |
|---|---|
| @Data | @Getter + @Setter + @ToString + @EqualsAndHashCode + @RequiredArgsConstructor + @NoArgsConstructor |
日志注解:
| 注解 | 作用 |
|---|---|
| @Slf4j | 添加⼀个名为 log 的日志,使用 slf4j |
使用 Lombok 提供给我们的这些注释,可以很好的帮助我们消除项目中大量冗余的代码,可以使得我们的 Java 类可以看起来非常的干净整洁。
相关文章:
SpringBoot的日志信息及Lombok的常用注解
文章目录 一. 日志的介绍1. 什么是日志2. 日志的作用 二. 日志的使用1. 日志格式说明2. 自定义日志的输出3. 日志级别4. 日志级别的配置5. 日志持久化6. 更简单的输出日志-Lomok7. Lombok框架实现原理以及其他常见注解 一. 日志的介绍 1. 什么是日志 日志是我们程序重要组成部…...
Genoss GPT简介:使用 Genoss 模型网关实现多个LLM模型的快速切换与集成
一、前言 生成式人工智能领域的发展继续加速,大型语言模型 (LLM) 的用途范围不断扩大。这些用途跨越不同的领域,包括个人助理、文档检索以及图像和文本生成。ChatGPT 等突破性应用程序为公司进入该领域并开始使用这项技术进行构建铺平了道路。 大公司正…...
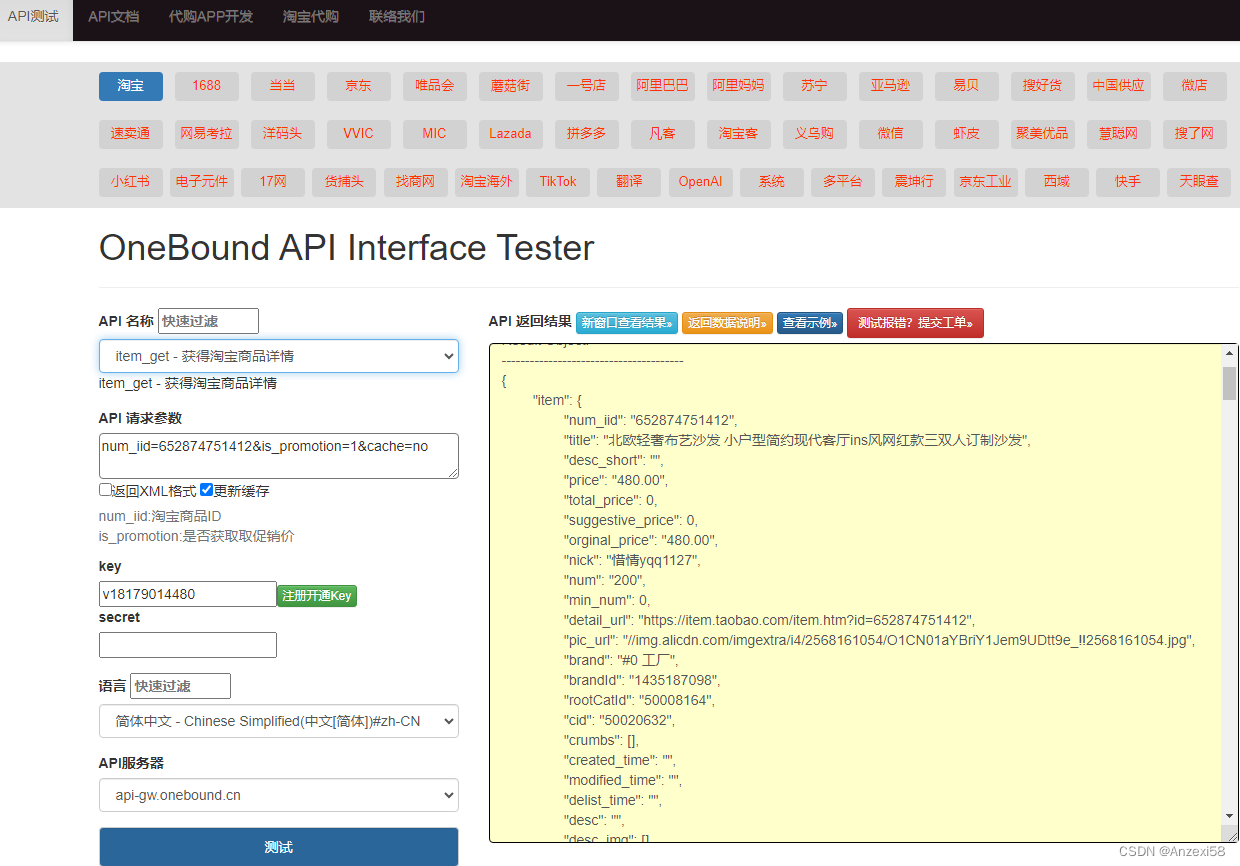
淘宝API接口的实时数据和缓存数据区别
电商API接口实时数据是指通过API接口获取到的与电商相关的实时数据。这些数据可以包括商品库存、订单状态、销售额、用户活跃度等信息。 通过电商API接口,可以实时获取到电商平台上的各种数据,这些数据可以帮助企业或开发者做出及时的决策和分析。例如&…...
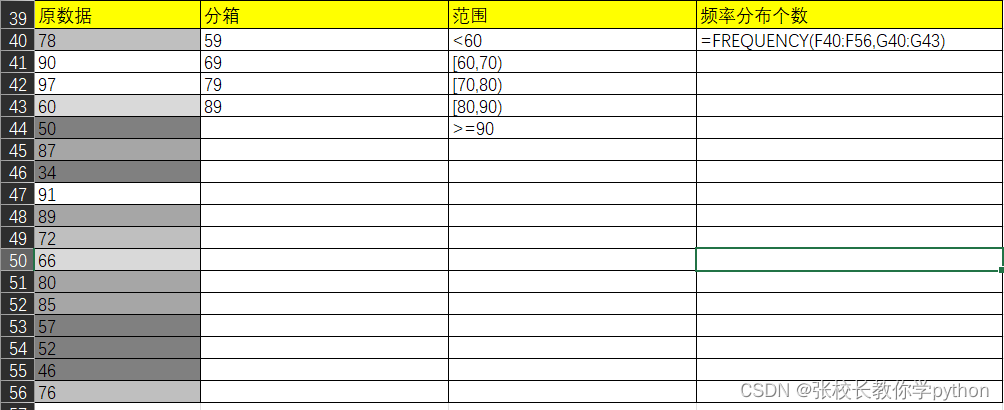
excel统计函数篇1之average系列
一、excel中的统计函数 1、AVERAGE(number1,number2,...):返回其参数的平均值 2、AAVERAGEA(value1,value2,...):返回其参数的平均值,包括数字、文本和逻辑值 可以在括号内手动输入,也可以引用单元格,对序列求平均的…...
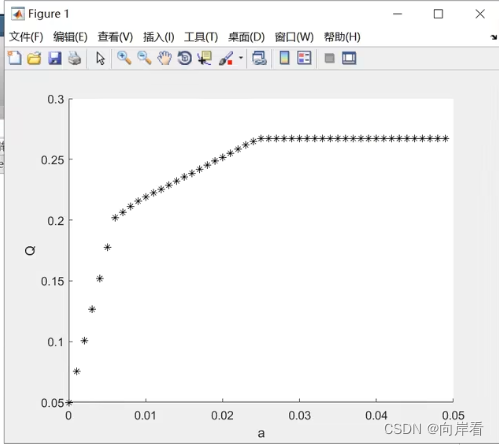
数学建模(二)线性规划
课程推荐:6 线性规划模型基本原理与编程实现_哔哩哔哩_bilibili 目录 一、线性规划的实例与定义 1.1 线性规划的实例 1.2 线性规划的定义 1.3 最优解 1.4 线性规划的Mathlab标准形式 1.5 使用linprog函数 二、线性规划模型建模实战与代码 2.1 问题提出 2.2…...
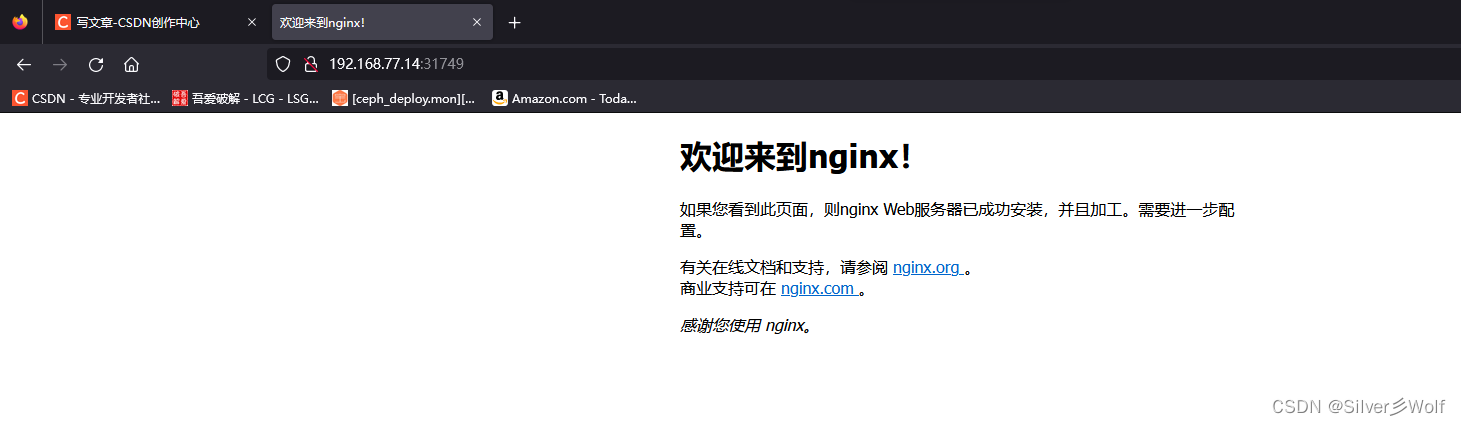
小白到运维工程师自学之路 第七十三集 (kubernetes应用部署)
一、安装部署 1、以Deployment YAML方式创建Nginx服务 这个yaml文件在网上可以下载 cat nginx-deployment.yaml apiVersion: apps/v1 #apiVersion是当前配置格式的版本 kind: Deployment #kind是要创建的资源类型,这里是Deploymnet metadata: #metadata是该资源…...

联合仿真 ADAMS 和 SIMULINK步骤
1、把 control 中的 ball_beam 文件 copy 到另外一个文件夹下, 同时设置adams和matlab的默认路径即为ball_beam文件夹, 这样可以省略很多不必要的麻烦! 2、用 aview 打开 ball_beam.cmd 文件,先试试仿真一下,可 以看到…...
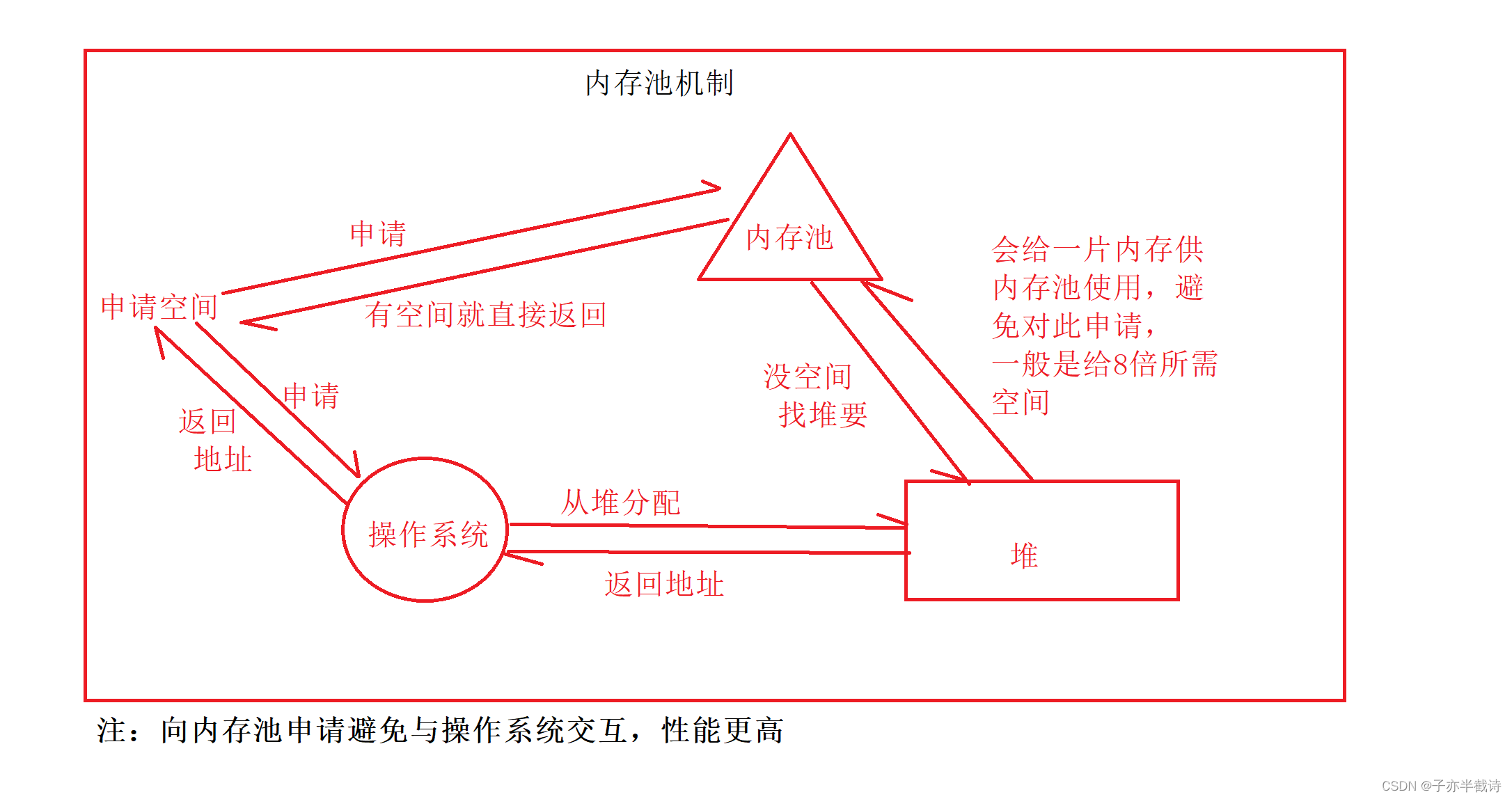
【C++精华铺】7.C++内存管理
目录 1. C语言动态内存管理 2. C内存管理方式 2.1 new/delete和new T[]/delete[] 2.1.1 操作内置类型 2.1.2 操作自定义类型 2.2 new/delete和new T[]/delete[]的原理 2.2.1 原理 2.2.2 operator new和operator delete 2.2.3 new T[]的特殊处理(可以…...

牛客网华为OD前端岗位,面试题库练习记录02
题目一 删除字符串中出现次数最少的字符(HJ23) JavaScript Node ACM 模式 const rl require("readline").createInterface({ input: process.stdin }); var iter rl[Symbol.asyncIterator](); const readline async () > (await iter.next()).value;void (asyn…...

数据库动态增删数据,导致分页查询数据出现重复或遗漏的问题分析及解决方案
一、问题分析 1. 请求数据 一般情况下,为了减少服务器的压力或方便展示,前端通过分页方式来请求数据,调用 API 接口时会带上参数 page 与 pageSize。例如请求某个班级的学生数据,获取第一页的 10 个学生的数据 ,假设按…...

神经网络基础-神经网络补充概念-44-minibatch梯度下降法
概念 小批量梯度下降法(Mini-Batch Gradient Descent)是梯度下降法的一种变体,它结合了批量梯度下降(Batch Gradient Descent)和随机梯度下降(Stochastic Gradient Descent)的优点。在小批量梯…...
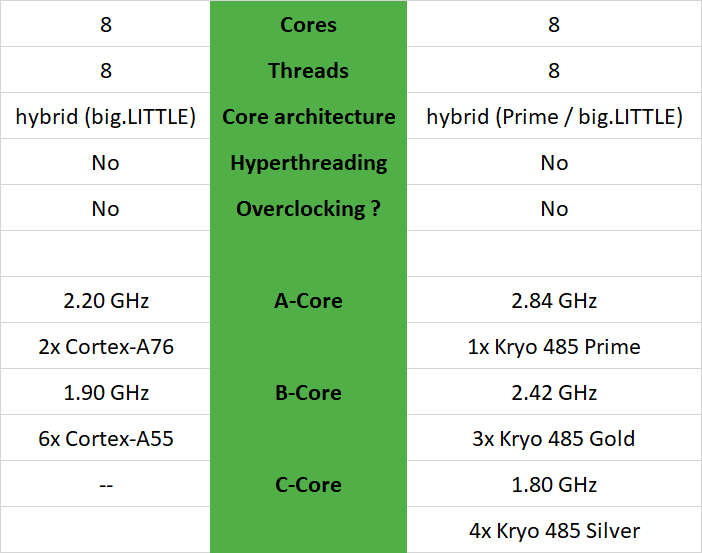
比较海思麒麟810与高通骁龙855的优劣
海思麒麟810与高通骁龙855可以从以下几方面进行比较: 一、CPU比较 海思麒麟810还是高通骁龙855——哪个处理器更快?在这个比较中,我们观察了差异,并分析了这两个CPU中哪一个更好。我们比较了技术数据和基准测试结果。 海思麒麟810有8个内核和8个线程,时钟最高频率为2.2…...

计算机机房的管理
1 电源问题 不稳定的电源对电脑的使用寿命是一个极大的威胁,特别是对于机房来说危害 性更大。为此,学校要添置必要的稳压器,设置其正常供电的电压为 220 伏、电流 为 l6 安对电脑室供电。如有电压发生偏差,要及时检查供电情况&…...
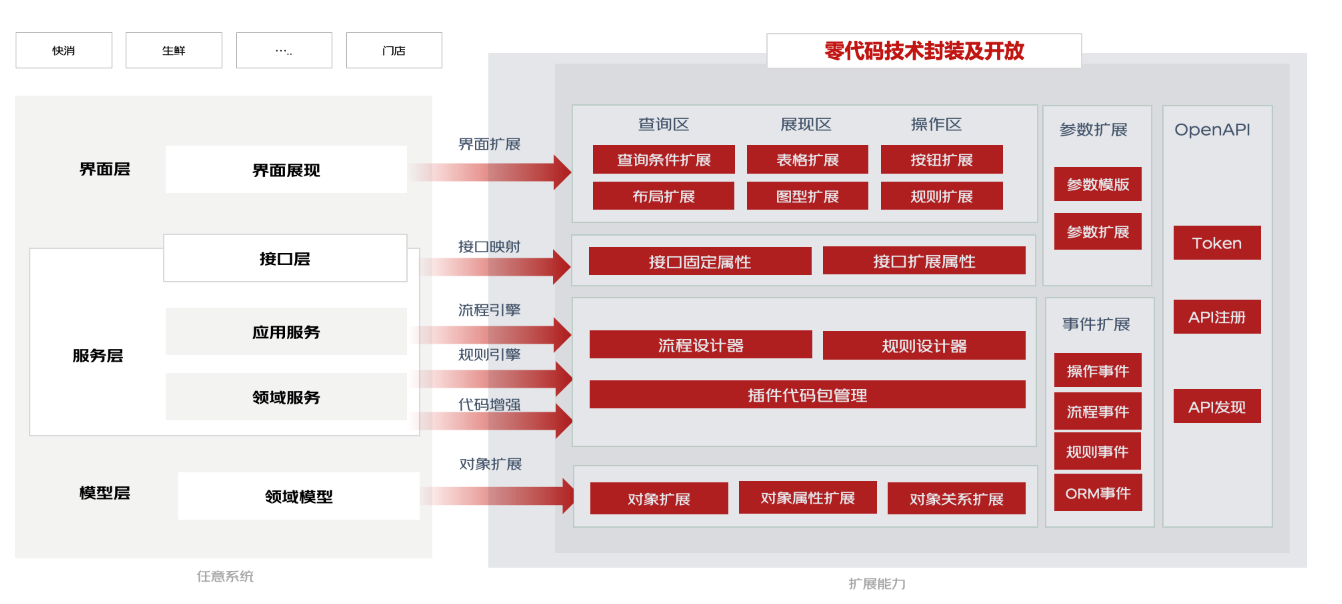
软件架构生态化-多角色交付的探索实践
作为一个技术架构师,不仅仅要紧跟行业技术趋势,还要结合研发团队现状及痛点,探索新的交付方案。在日常中,你是否遇到如下问题 “ 业务需求排期长研发是瓶颈;非研发角色感受不到研发技改提效的变化;引入ISV …...
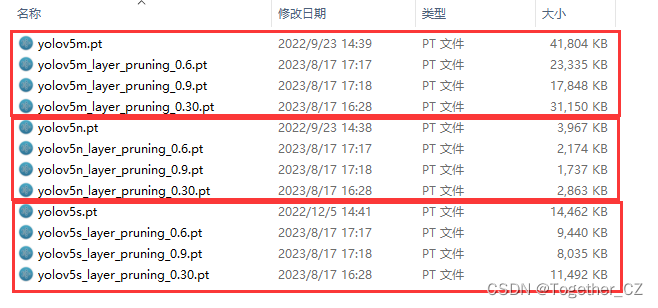
基于YOLOv5n/s/m不同参数量级模型开发构建茶叶嫩芽检测识别模型,使用pruning剪枝技术来对模型进行轻量化处理,探索不同剪枝水平下模型性能影响【续】
这里主要是前一篇博文的后续内容,简单回顾一下:本文选取了n/s/m三款不同量级的模型来依次构建训练模型,所有的参数保持同样的设置,之后探索在不同剪枝处理操作下的性能影响。 在上一篇博文中保持30的剪枝程度得到的效果还是比较理…...
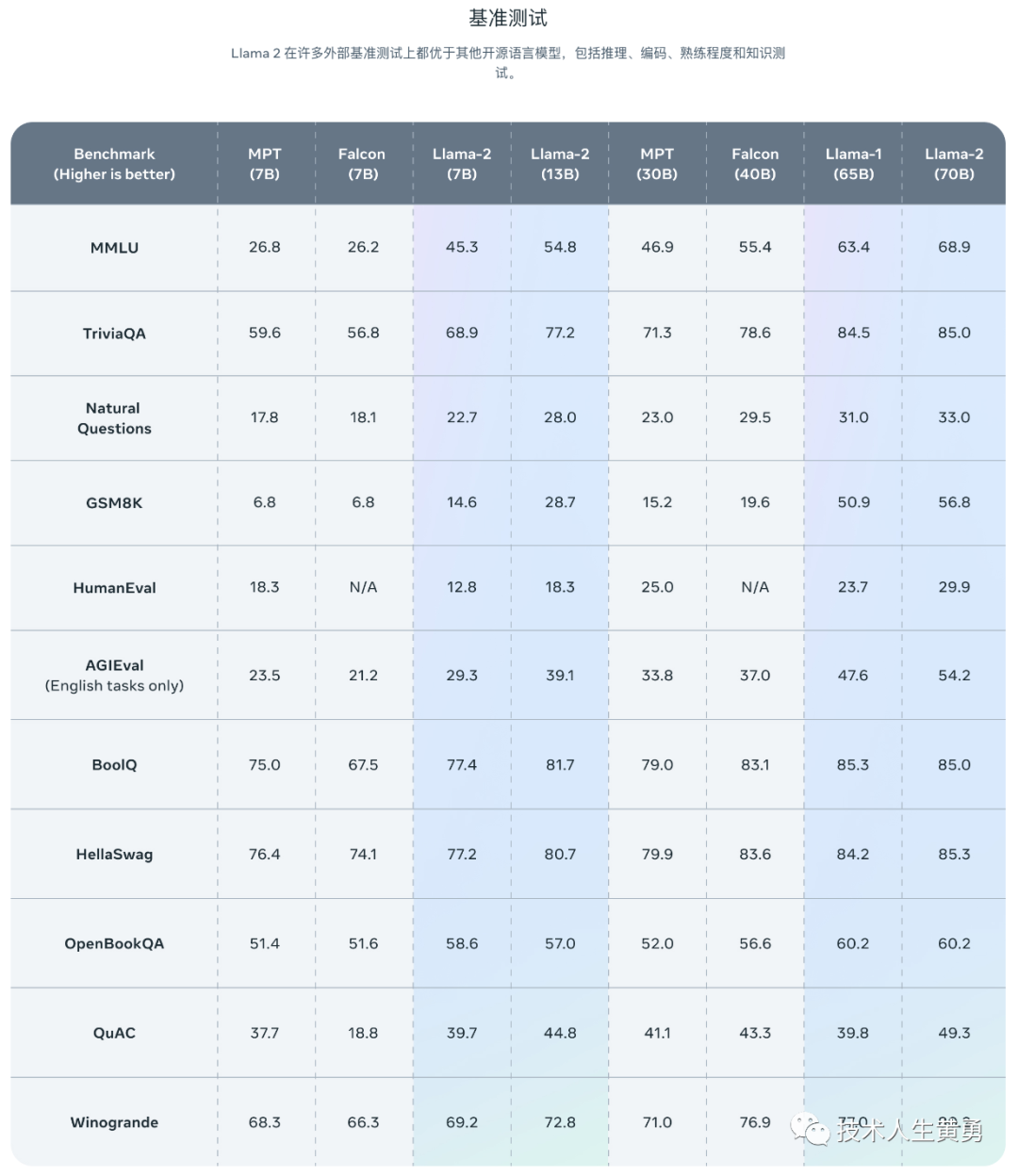
深度解析 Llama 2 的资源汇总:不容错过
“ 探索 Llama 2 背后的过程,包括了模型的全面解析,在线体验,微调,部署等,这份资源汇总将带您深入了解其内涵。” 01 — 周二发布了文章《中文大模型 Chinese-LLaMA-Alpaca-2 开源且可以商用》后,不少朋友们…...
Git 删除 GitHub仓库的文件
新建文件夹 git bash here 在新建的文件夹里右键git bash here打开终端,并执行git init初始化仓库 git clone <你的地址> 找到github上要删除的仓库地址,并复制,在终端里输入git clone <你的地址> 要删除文件的库里右键git b…...

如何使用 ChatGPT 将文本转换为 PowerPoint 演示文稿
推荐:使用 NSDT场景编辑器 助你快速搭建可二次编辑的3D应用场景 步骤 1:将文本转换为幻灯片演示文稿 第一步涉及指示 ChatGPT 根据给定的文本生成具有特定数量幻灯片的演示文稿。首先,您必须向 ChatGPT 提供要转换的文本。 使用以下提示指示…...

html(七)meta标签
一 meta标签 1、背景:发现自带某些请求头2、本文没有实际的生产应用场景,仅仅作为技术积累 ① meta标签含义 1、metadata: 元数据,是用于描述数据的数据,它不会显示在页面上,但是机器却可以识别2、应用场景: [1]、SEO搜索引擎优化[2]、定义页面使用…...
)
《Go 语言第一课》课程学习笔记(五)
入口函数与包初始化:搞清 Go 程序的执行次序 main.main 函数:Go 应用的入口函数 Go 语言中有一个特殊的函数:main 包中的 main 函数,也就是 main.main,它是所有 Go 可执行程序的用户层执行逻辑的入口函数。 Go 程序在…...

【设计模式】行为型-模板方法模式
文章目录前言一、概念二、核心结构三、Java 代码实现(订单支付流程)1. 抽象类(定义模板)2. 具体子类:微信支付3. 具体子类:支付宝支付4. 客户端调用四、钩子方法(Hook)—— 让模板更…...

筑牢数据安全底座!百度智能云数据库GaiaDB分布式版通过『国密认证』
近日,百度智能云自研的关系型数据库GaiaDB分布式版获得由国家密码管理局商用密码检测认证中心颁发的《商用密码产品认证证书》,通过GM/T 0028《密码模块安全技术要求》安全等级第二级认证。这一认证标志着GaiaDB分布式版密码模块在密码安全设计、密钥管理…...

智汇云舟亮相2026中关村论坛 联合发起“通智行业大脑”联盟
3月29日,作为中关村论坛年会的重要组成部分,“迈向通用人工智能”平行论坛在中关村国家自主创新示范区展示交易中心隆重举行。本次论坛由北京市科学技术委员会、中关村科技园区管理委员会、北京市海淀区人民政府联合主办,北京通用人工智能研究…...

3种方案解锁Unity游戏潜力:MelonLoader全平台模组加载器实战指南
3种方案解锁Unity游戏潜力:MelonLoader全平台模组加载器实战指南 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 一…...

aibye爱毕业推出六大顶尖平台评测,智能润色与高效创作功能一键实现,科研领域不可或缺的AI助手
工具名称 核心功能 特色优势 Aibiye 论文生成降AI率 全学科覆盖、仿写优化、自动图表生成 Aicheck AI检测文献综述辅助 精准查新、3分钟高效成文 GPT学术版 润色/翻译/代码解释 多模型协同、PDF深度解析 摆平论文 大纲生成降重改写 三步出稿、本硕博通用 QuillB…...

嵌入式开发问题解决:从复现到根治的实战指南
1. 嵌入式开发问题解决之道:从复现到根治 搞嵌入式开发这些年,踩过的坑比写过的代码还多。每次遇到系统崩溃、数据异常或者外设抽风,都像在玩侦探游戏——证据支离破碎,真凶隐藏极深。今天就把我这些年总结的"破案"方法…...

引线框架市场前瞻:预计至2032年将增长至338.8亿元
据恒州诚思调研统计,2025年全球引线框架市场规模达273.7亿元,预计至2032年将增长至338.8亿元,2026-2032年复合增长率(CAGR)为2.3%。作为半导体封装的核心组件,引线框架(由芯片安装板与引线指构成…...

HarmonyOS6 半年磨一剑 - RcCheckbox 组件事件体系与交互逻辑
文章目录前言一、点击处理链1.1 核心点击处理函数1.2 两个点击入口二、三事件分层设计2.1 三个事件的对比2.2 事件使用示例三、labelDisabled 局部禁止机制3.1 设计意图3.2 适用场景四、RcCheckboxGroup 的数量限制拦截4.1 min/max 拦截机制4.2 数量限制示例总结前言 一个看似…...
的负载均衡策略?)
OpenClaw 的模型架构中,是否使用了混合专家(MoE)的负载均衡策略?
关于OpenClaw模型架构中是否采用了混合专家(MoE)的负载均衡策略,这个问题其实触及了当前大模型设计里一个相当有意思的细节。直接说结论的话,从目前公开的论文和技术报告来看,OpenClaw并没有明确声明在其MoE层中使用了…...
)
UniAD高版本环境实战:CUDA11.6+PyTorch1.12避坑全记录(附完整依赖清单)
UniAD高版本环境实战:CUDA11.6PyTorch1.12避坑全记录(附完整依赖清单) 当计算机视觉工程师尝试复现前沿论文时,环境配置往往成为第一道门槛。UniAD作为自动驾驶领域的统一大模型,其官方文档推荐的环境配置(…...