【MySQL系列】表内容的基本操作(增删查改)
「前言」文章内容大致是对MySQL表内容的基本操作,即增删查改。
「归属专栏」MySQL
「主页链接」个人主页
「笔者」枫叶先生(fy)

目录
- 一、MySQL表内容的增删查改
- 1.1 Create
- 1.1.1 单行数据+全列插入
- 1.1.2 多行数据+指定列插入
- 1.1.3 插入否则更新
- 1.1.4 数据替换
- 1.2 Retrieve
- 1.2.1 SELECT列
- 1.2.2 SELECT查询加WHERE条件
- 1.2.3 对查询结果排序
- 1.2.4 筛选分页结果
- 1.3 Update
- 1.4 Delete
- 1.4.1 删除数据
- 1.4.2 截断表
- 1.5 插入查询结果
- 1.6 聚合函数
- 1.7 group by子句的使用(分组查询)
一、MySQL表内容的增删查改
- 表内容的增删查改简称
CRUD:Create(新增),Retrieve(查找),Update(修改),Delete(删除) DML【data manipulation language】数据操纵语言,用来对数据进行操作代表指令:insert,delete、update- DML中又单独分了一个
DQL【Data Query Language】,数据查询语言,代表指令:select
1.1 Create
create是用于新增数据,新增数据的SQL语法如下:
INSERT [INTO] table_name [(column [, column] ...)] VALUES (value_list) [, (value_list)] ...
- 大写的表示关键字,[] 是可选项,可以选择不写
table_name是表的名字column列,用于指定每个value_list中的值应该插入到表中的哪一列value_lis的值与column一一对应
语法到下面再一一解释
1.1.1 单行数据+全列插入
先创建一个学生表,表当中包含自增长的主键id、学号、姓名和QQ号。
mysql> create table if not exists student(-> id int unsigned primary key auto_increment,-> stu_id int unsigned not null unique comment '学号',-> name varchar(20) not null,-> qq varchar(20)-> );
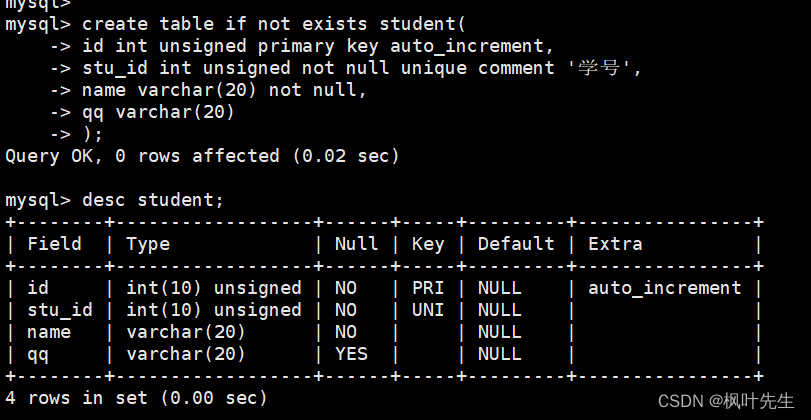
面使用insert语句向学生表中插入记录,每次向表中插入一条记录,并且插入记录时不指定column列,表示按照表中默认的列顺序进行全列插入,因此插入的每条记录中的列值需要按表列顺序依次列出(全列插入)
-- 全列插入
mysql> insert into student values (1, 10001, '张三', 222222);
mysql> insert into student values (2, 10002, '李四', 222223);
注意:value_list数量必须和定义表的列的数量及顺序一致
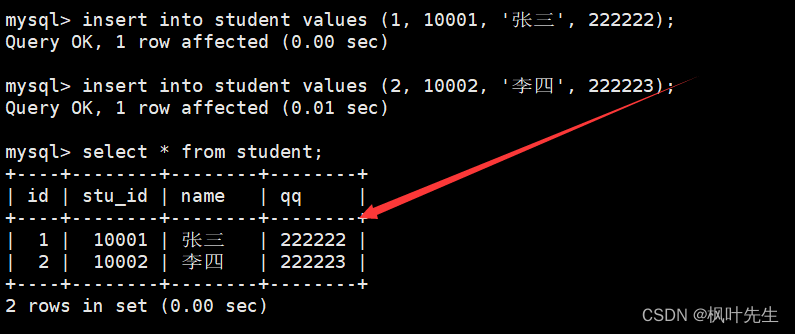
注:into也可以省略,不过为了符号插入语义,一般都写出来。
1.1.2 多行数据+指定列插入
插入的时候,也可以不用指定id(这时候就需要明确插入数据到那些列了,即指定列插入),对于表中的ID来说,mysql会使用默认的值进行自增
insert into student (stu_id, name, qq) values (10003, '王五', 222224);
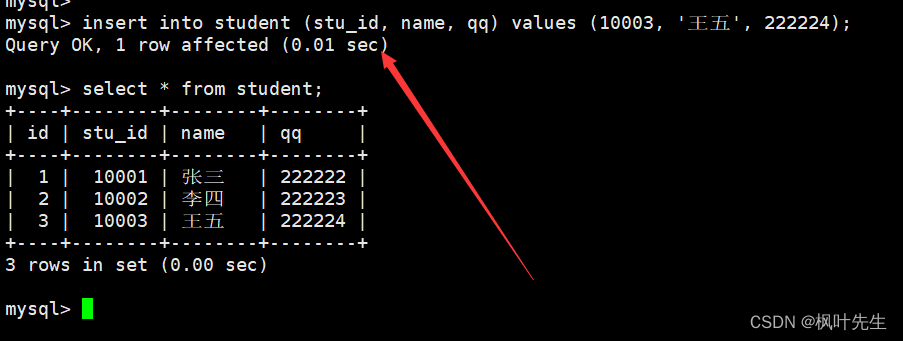
insert语句也可以一次向表中插入多条记录,插入的多条记录之间使用逗号隔开,并且插入记录时可以只指定某些列进行插入。
mysql> insert into student (stu_id, name, qq) values (10004, '赵六', null), (10005, '田七', null);
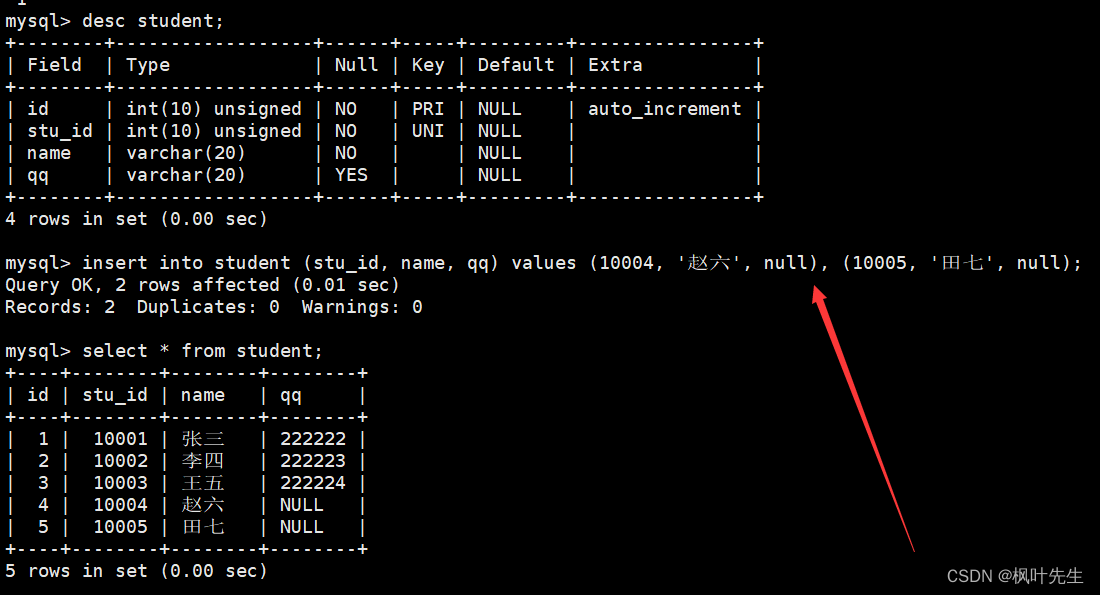
注意:不允许为空一列,必须插入值,否则报错。
1.1.3 插入否则更新
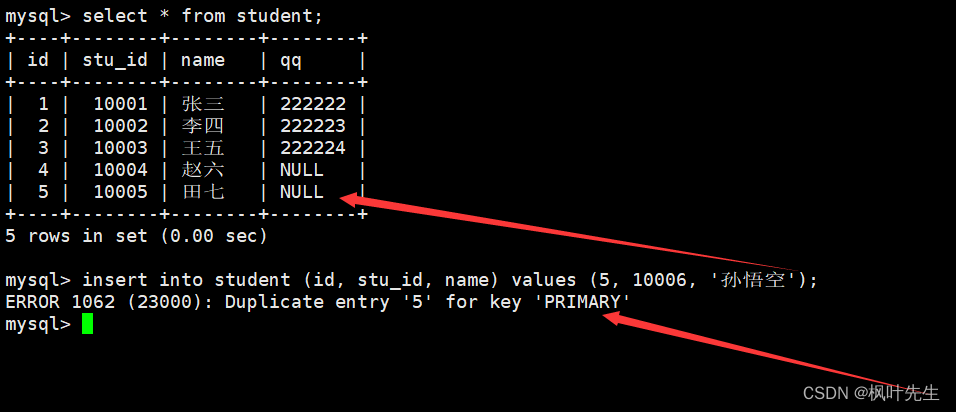
向表中插入记录时,如果待插入记录中的主键或唯一键已经存在,那么就会因为主键冲突或唯一键冲突导致插入失败。
主键冲突
唯一键冲突
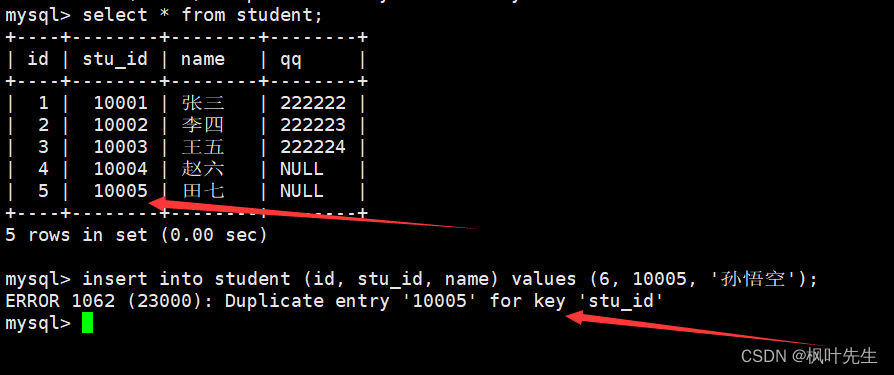
这时可以选择性的进行同步更新操作,语法:
INSERT ... ON DUPLICATE UPDATE column1=value1 [, column2=value2] ...;
注:
- 大写的表示关键字,[ ]中代表的是可选项
ON DUPLICATE KEY当发生重复key的时候,就执行后面的语句- UPDATE后面的column=value,表示当插入记录出现冲突时需要更新的列值
规则:
- 如果表中没有冲突数据,则直接插入数据
- 如果表中有冲突数据,则将表中的数据进行更新
例如,插入的值主键发生冲突,则将表中冲突的列进行更新
mysql> insert into student (id, stu_id, name) values (1, 10001, '孙悟空')-> on duplicate key update stu_id = 10011, name = '孙悟空';
Query OK, 2 rows affected (0.00 sec)
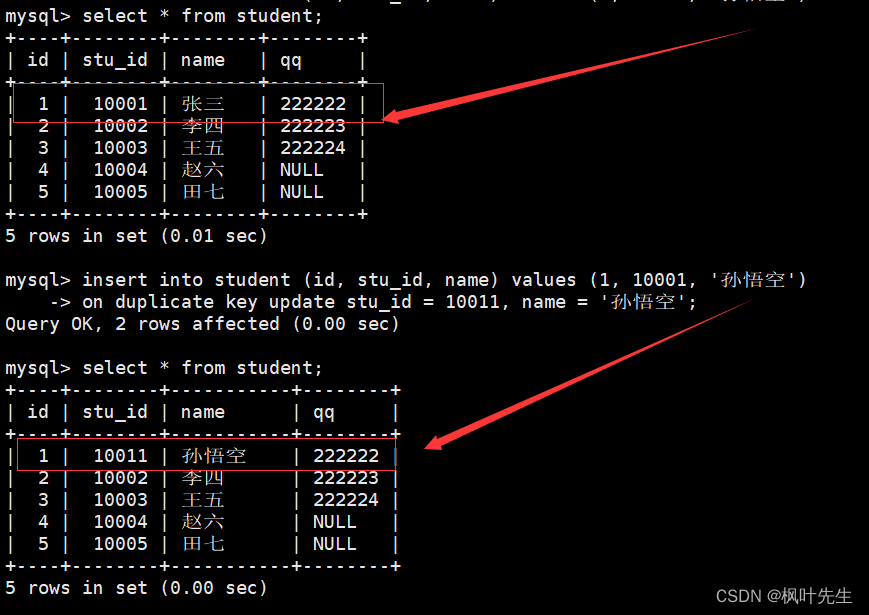
执行插入否则更新的语句,可以通过受影响的数据行数来判断本次数据的插入情况:
0 rows affected:表中有冲突数据,但冲突数据的值和指定更新的值相同1 row affected:表中没有冲突数据,数据直接被插入2 rows affected:表中有冲突数据,并且数据已经被更新

也可以通过 MySQL 函数获取受到影响的数据行数
SELECT ROW_COUNT();
1.1.4 数据替换
- 如果表中没有冲突数据,则直接插入数据
- 如果表中有冲突数据,则先将表中的冲突数据删除,然后再插入数据
语法:只需要在插入数据时将SQL语句中的INSERT改为REPLACE即可,其他相同
例如:主键或者唯一键如果冲突,则删除后再插入
mysql> replace into student (stu_id, name) values (10002, '唐三藏');
Query OK, 2 rows affected (0.00 sec)
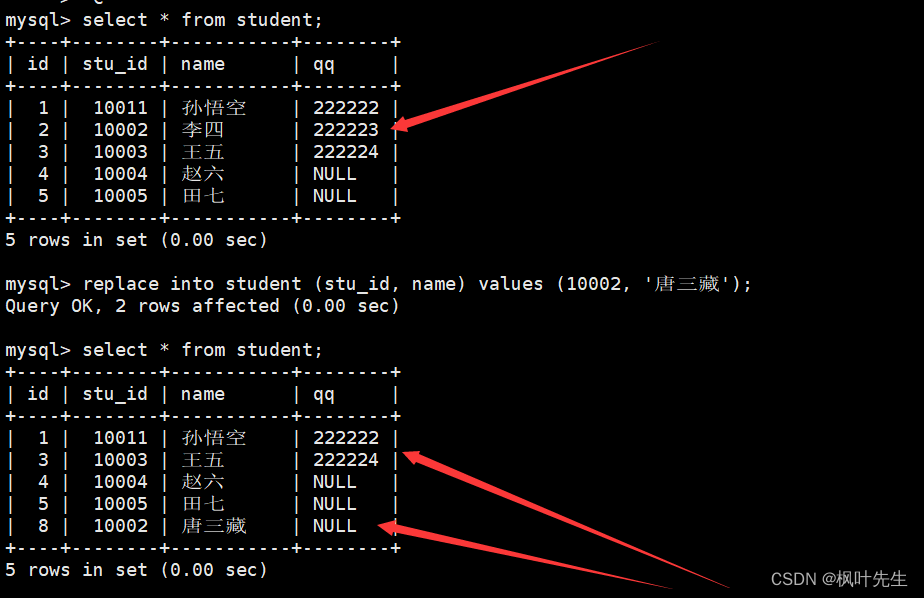
执行该语句后,也可以通过受影响的数据行数来判断本次数据的插入情况:
1 row affected:表中没有冲突数据,数据直接被插入2 rows affected:表中有冲突数据,冲突数据被删除后重新插入
1.2 Retrieve
查找数据的SQL语法如下:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...
说明:
- 大写的表示关键字,[ ]中代表的是可选项
- { }中的 | 代表可以选择左侧的语句或右侧的语句
接下来创建表结构,用于测试
CREATE TABLE exam_result (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT '同学姓名',
chinese float DEFAULT 0.0 COMMENT '语文成绩',
math float DEFAULT 0.0 COMMENT '数学成绩',
english float DEFAULT 0.0 COMMENT '英语成绩'
);
插入测试数据
INSERT INTO exam_result (name, chinese, math, english) VALUES
('唐三藏', 67, 98, 56),
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙权', 70, 73, 78),
('宋公明', 75, 65, 30);
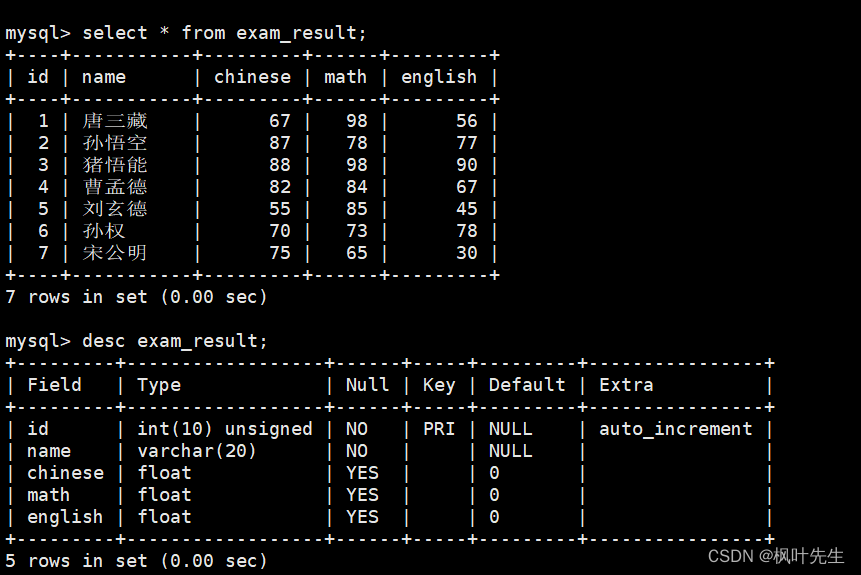
1.2.1 SELECT列
全列查询
查询数据时直接用*代替column列表,表示进行全列查询,这时将会显示被筛选出来的记录的所有列信息
mysql> select * from exam_result;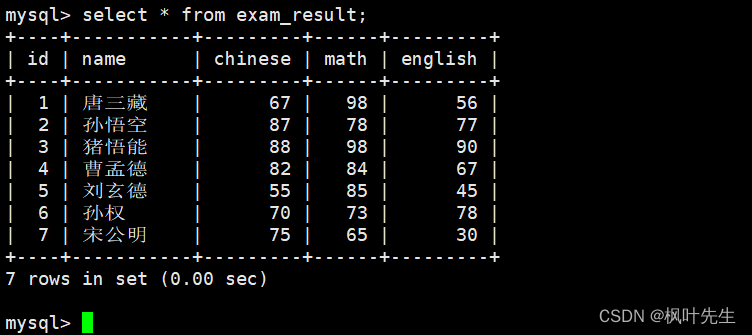
注意:通常情况下不建议使用*进行全列查询,查询的列越多,意味着需要传输的数据量越大,可能会影响到索引的使用
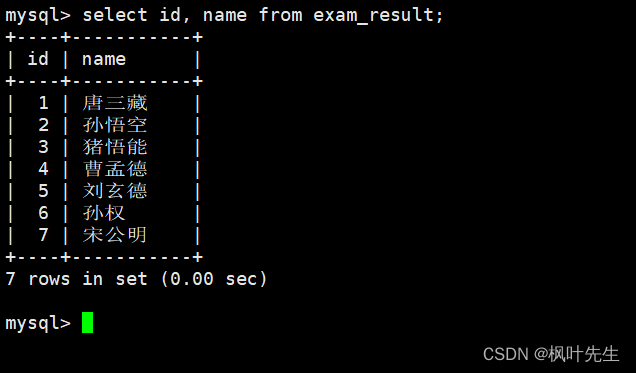
指定列查询
在查询数据时也可以只对指定的列进行查询,这时将需要查询的列在column列表列出即可
注意:指定列的顺序不需要按定义表的顺序来
mysql> select id, name from student;
查询字段为表达式
select不仅能够用来查询数据,还可以用来计算某些表达式或执行某些函数
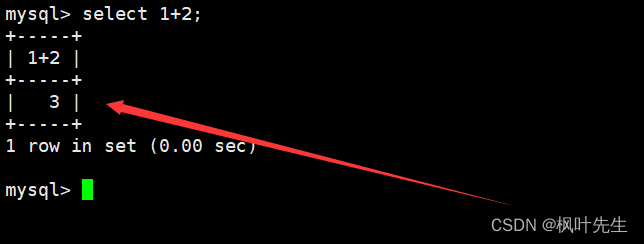
在查询数据时,column列表中除了能罗列表中存在的列名外,也可以将表达式罗列到column列表中
mysql> select id, name, math, 10+20 from exam_result;
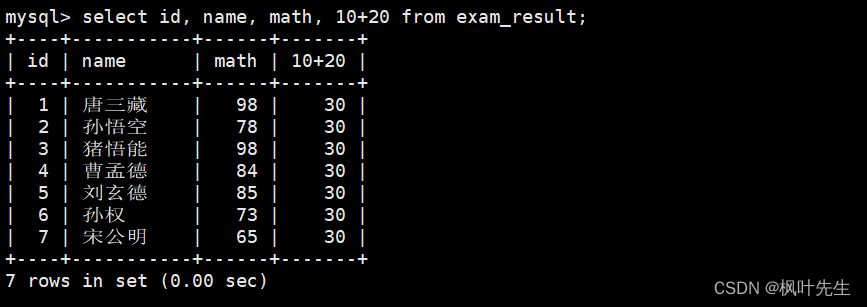
如果将表达式添加到column列表,那么每当一条记录被筛选出来时就会执行这个表达式,然后将表达式的计算结果作为这条记录的一个列值进行显示
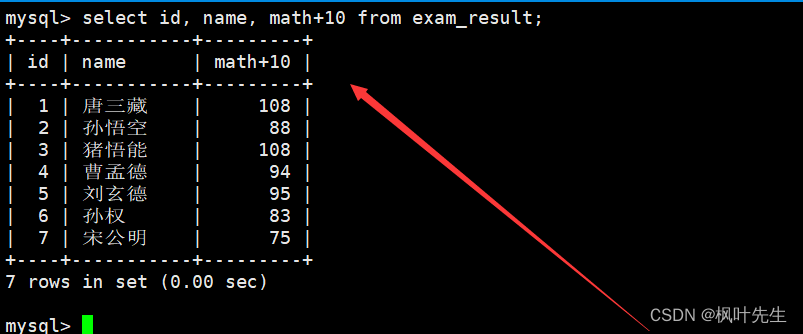
注意:存储的数据依旧没有发生改变
column列表中的表达式中也可以包含多个表中已有的字段
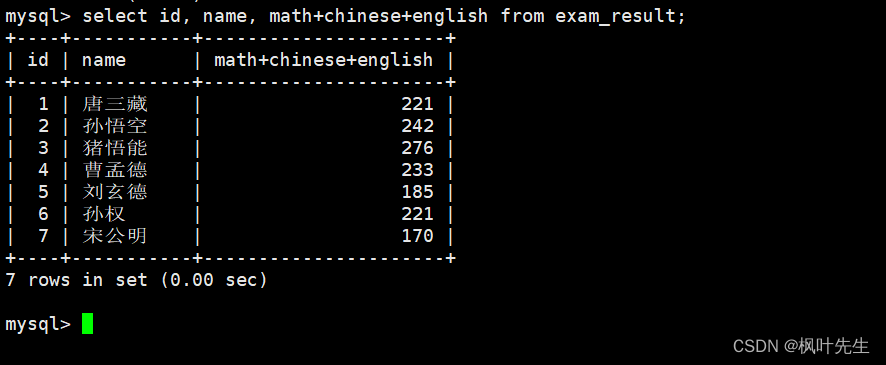
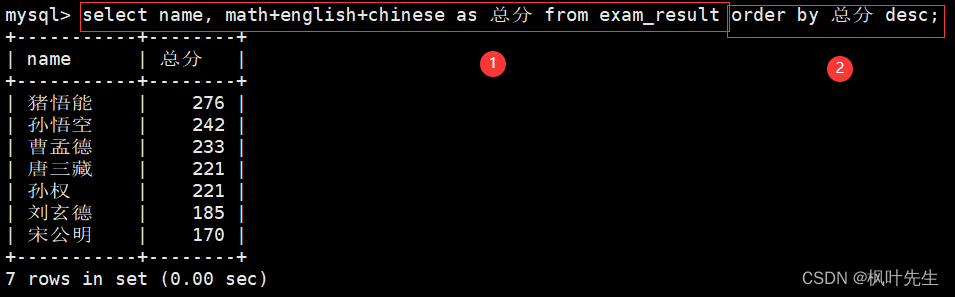
为查询结果指定别名
语法:
SELECT column [AS] alias_name [...] FROM table_name;
说明:
- 大写的表示关键字,[ ]中代表的是可选项
查询结果列名太长了,可以对列名进行重命名
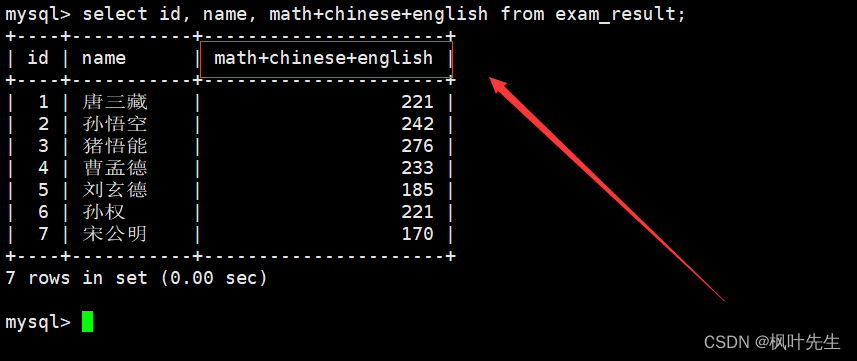
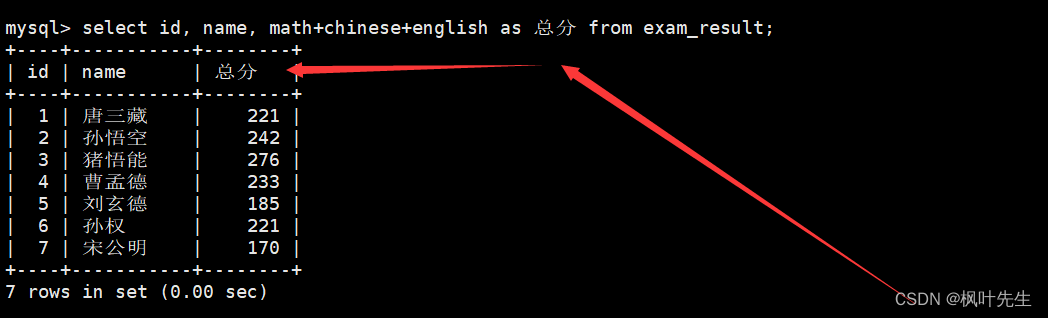
进行对结果重命名
mysql> select id, name, math+chinese+english as 总分 from exam_result;
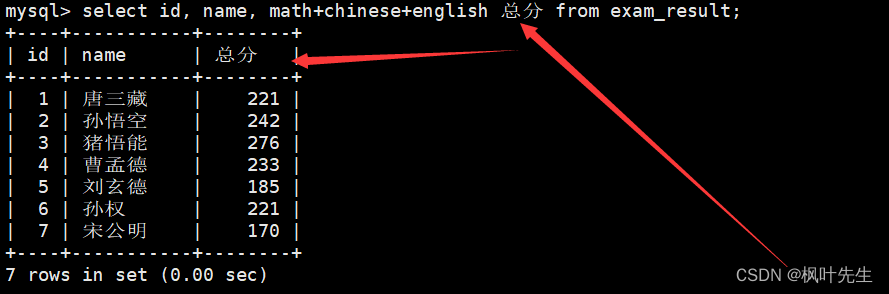
as也可以省略
mysql> select id, name, math+chinese+english 总分 from exam_result;
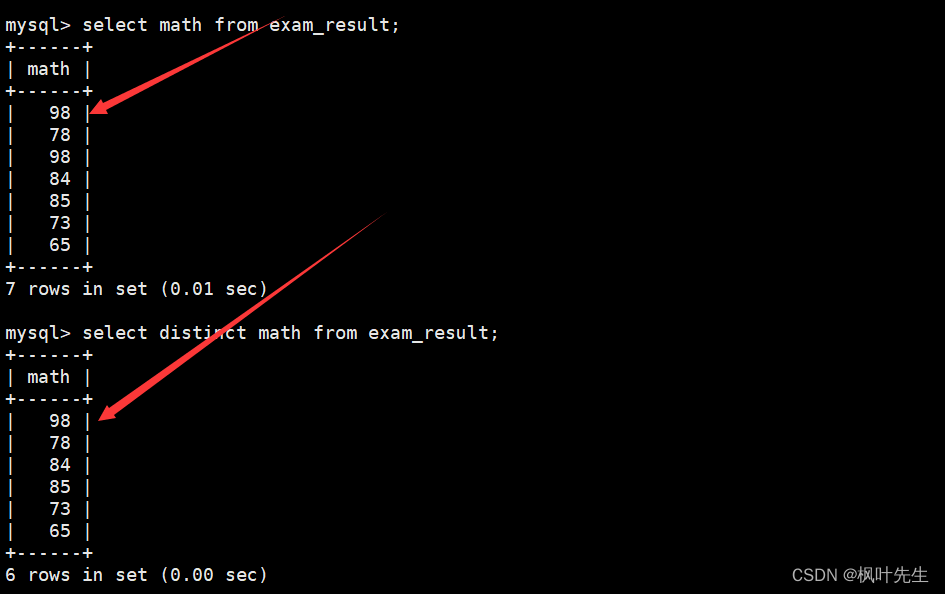
对查询结果去重
如果想要对查询结果进行去重操作,可以在SQL中的select后面带上distinct关键字
mysql> select distinct math from exam_result;
1.2.2 SELECT查询加WHERE条件
- 如果在查询数据时没有指定where子句,那么会直接将表中某一列所有的记录都显示出来
- 如果在查询数据时指定了where子句,那么在查询数据时会先根据where子句筛选出符合条件的记录,查询结果只会显示符合条件的记录
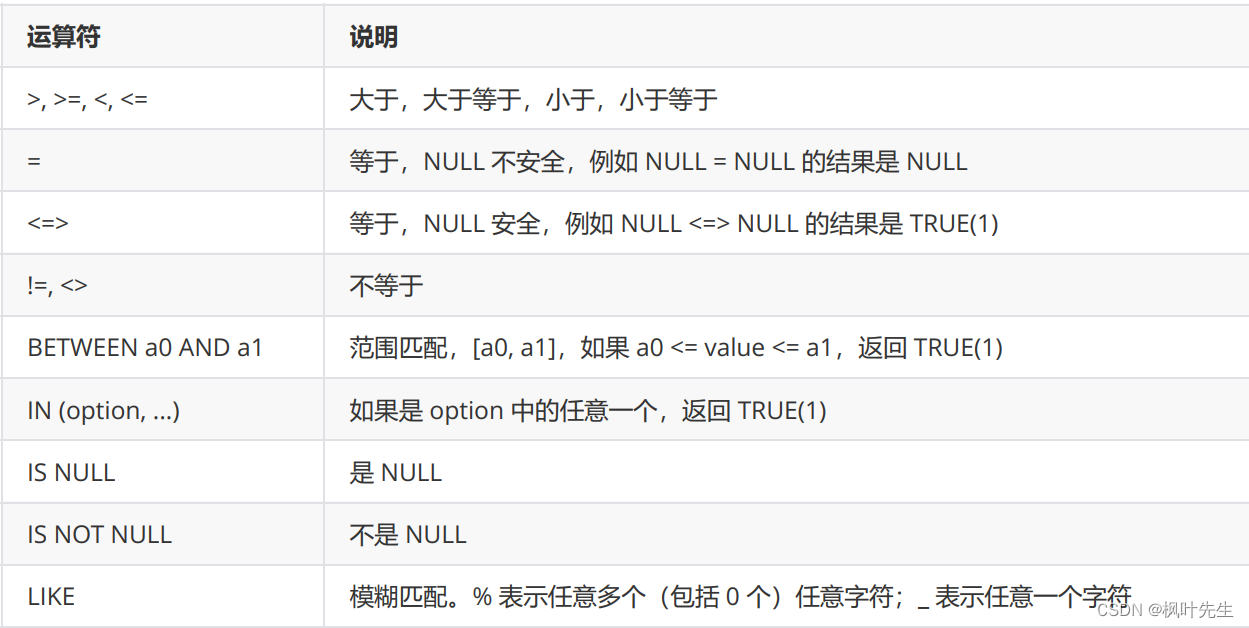
where子句中可以指明一个或多个筛选条件,各个筛选条件之间用逻辑运算符AND或OR进行关联,下面给出了where子句中常用的比较运算符和逻辑运算符。
比较运算符
逻辑运算符
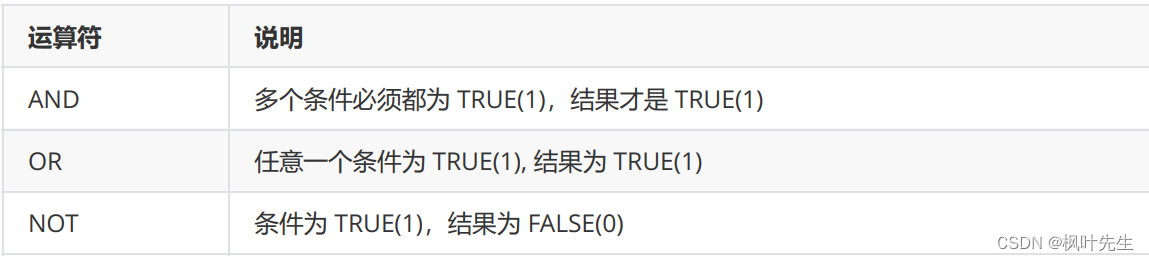
注意:MySQL里面比较相等使用的是一个=,不使用两个等号,与C/C++里面的不一样
测试案例
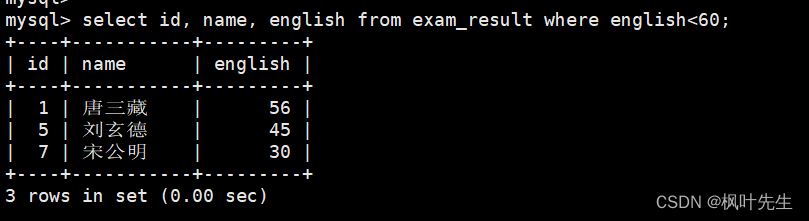
英语不及格的同学及英语成绩 ( < 60 )
在where子句中指明筛选条件为英语成绩小于60
mysql> select id, name, english from exam_result where english<60;
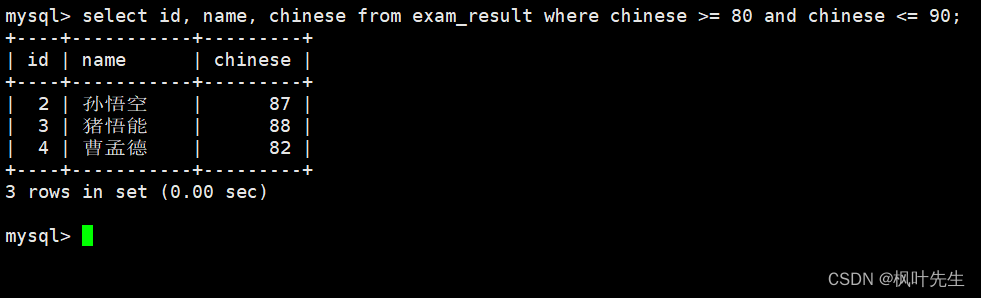
语文成绩在 [80, 90] 分的同学及语文成绩
在where子句中指明筛选条件为语文成绩大于等于80并且小于等于90,使用and进行并列条件
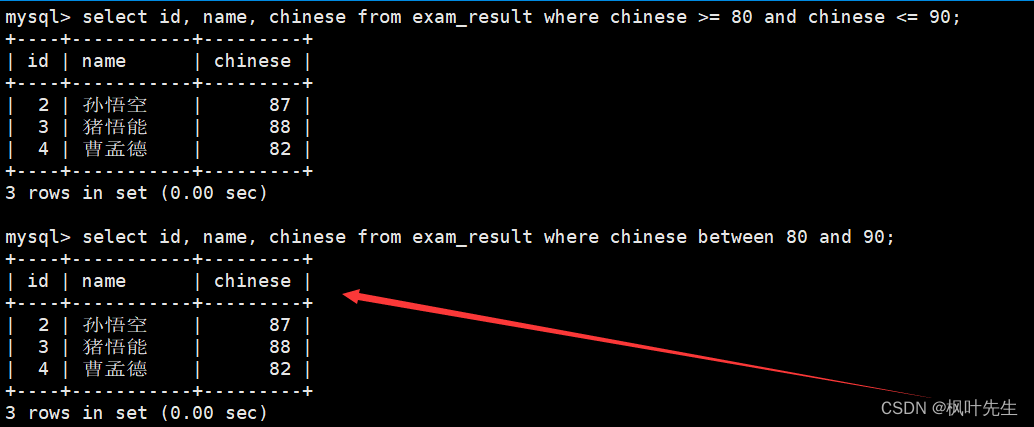
mysql> select id, name, chinese from exam_result where chinese >= 80 and chinese <= 90;
此外,这里也可以使用BETWEEN a0 AND a1来指明语文成绩的的所在区间
mysql> mysql> select id, name, chinese from exam_result where chinese between 80 and 90;
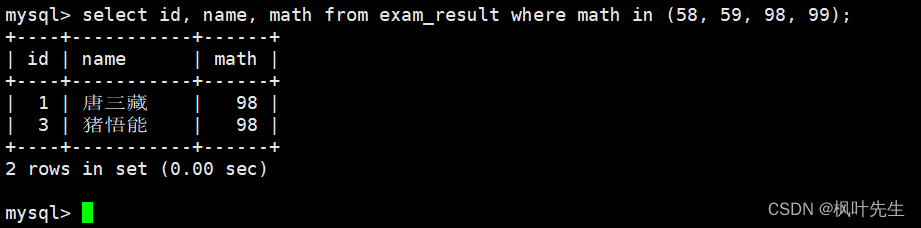
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
在where子句中使用 or 进行条件连接
mysql> select id, name, math from exam_result where math = 58 or math = 59 or math = 98 or math = 99;

此外,也可以通过IN (option, ...)的方式来判断数学成绩是否符合筛选要求
mysql> select id, name, math from exam_result where math in (58, 59, 98, 99);
姓孙的同学
通过模糊匹配来判断当前同学是否姓孙(需要用到%来匹配任意多个字符),使用到关键字like
mysql> select id, name from exam_result where name like '孙%';
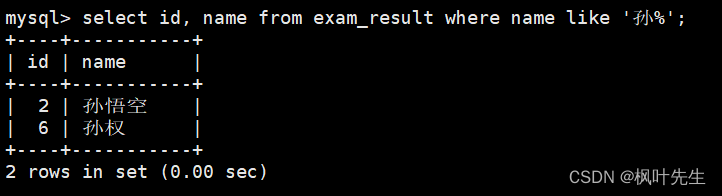
孙某同学
通过模糊匹配来判断当前同学是否为孙某(需要用到_来严格匹配任意单个字符),使用到关键字like
mysql> select id, name from exam_result where name like '孙_';
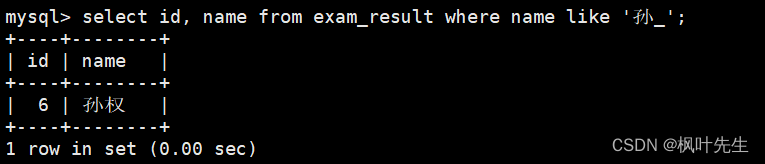
语文成绩好于英语成绩的同学
按照条件使用where子句查询即可
mysql> select id, name, chinese, english from exam_result where chinese > english;
总分在 200 分以下的同学
在select的column列表中添加表达式查询,查询的表达式为语文、数学和英语成绩之和,为了方便观察可以将表达式对应的列指定别名为“总分”,在where子句中指明筛选条件为三科成绩之和小于200
mysql> select id, name, chinese+english+math as 总分 from exam_result where chinese+english+math < 200;

需要注意的是,在where子句中不能使用select中指定的别名:
- 查询数据时是先根据where子句筛选出符合条件的记录。
- 然后再将符合条件的记录作为数据源来再依次执行select语句。
也就说说语句的执行顺序是where子句先执行,在执行select语句

所以在where子句中不能使用别名select的别名,如果在where子句中使用别名,那么在查询数据时就会产生报错

语文成绩 > 80 并且不姓孙的同学
where子句要使用AND与NOT的关键字和通过模糊匹配like
mysql> select id, name, chinese from exam_result where chinese > 80 and name not like '孙%';
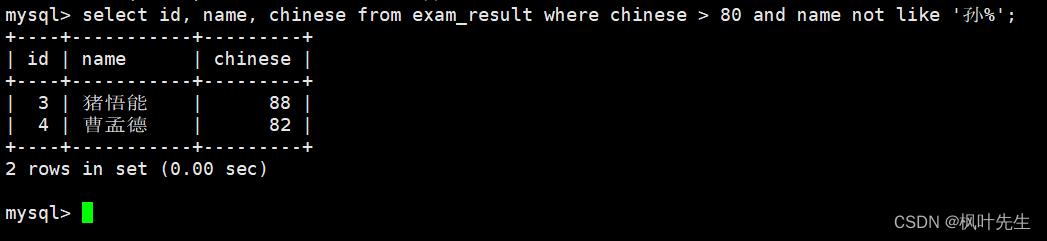
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
mysql> select id, name, chinese+english+math as 总分 from exam_result where name like '孙_' or (-> chinese+math+english > 200 and chinese < math and english > 80);
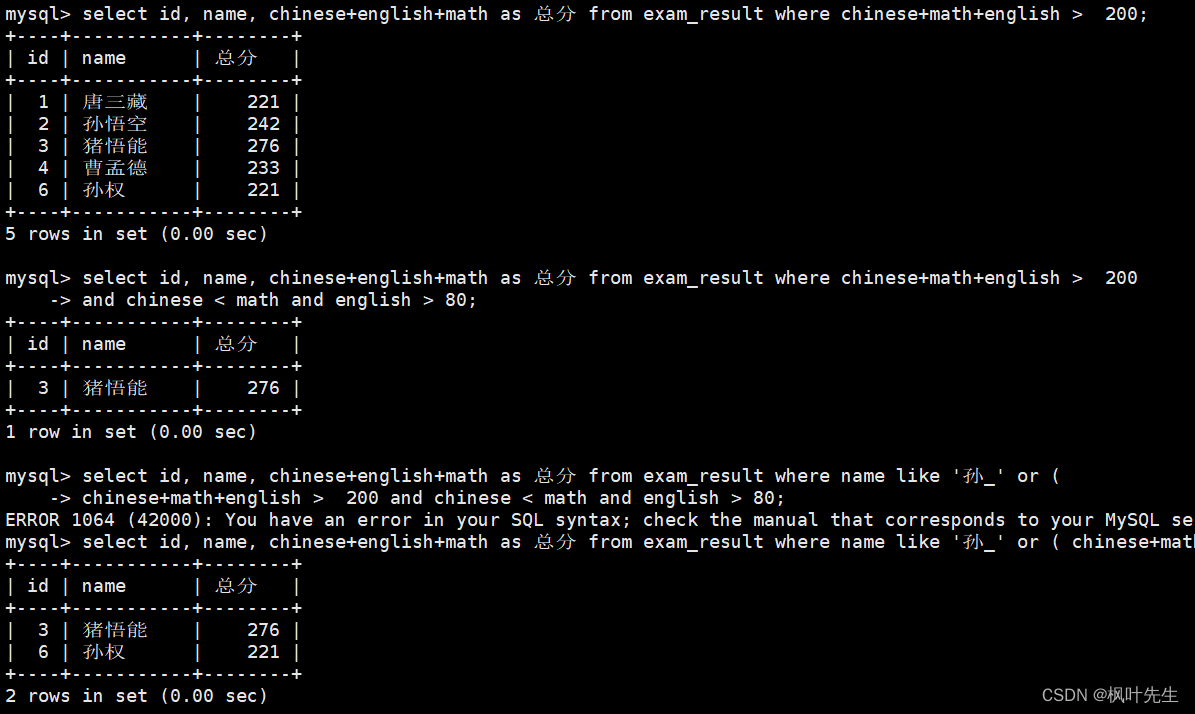
NULL的查询
使用的测试表是上面的student表
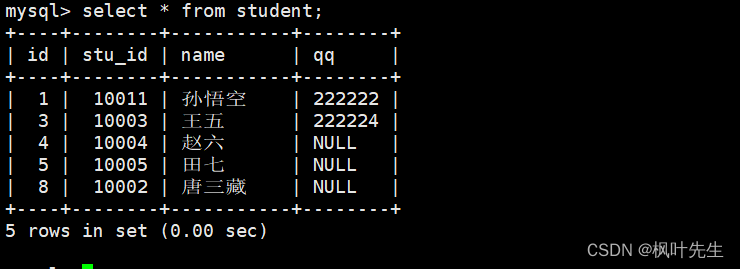
查询qq号已知的同学姓名
mysql> select name, qq from student where qq is not null;
查询QQ号未知的同学
mysql> select name, qq from student where qq is null;
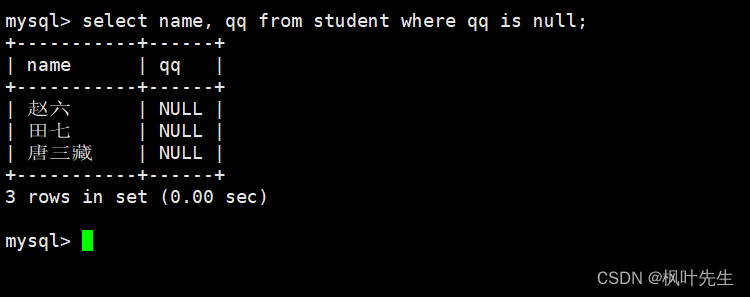
需要注意的是,在与NULL值作比较的时候应该使用<=>运算符,使用=运算符无法得到正确的查询结果,不过都不怎么使用<=>运算符,判断为空或者不为空常使用is null或is not null
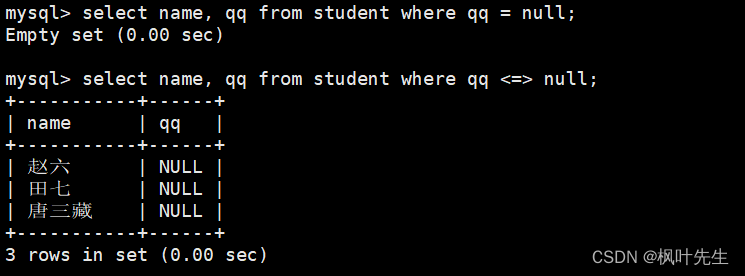
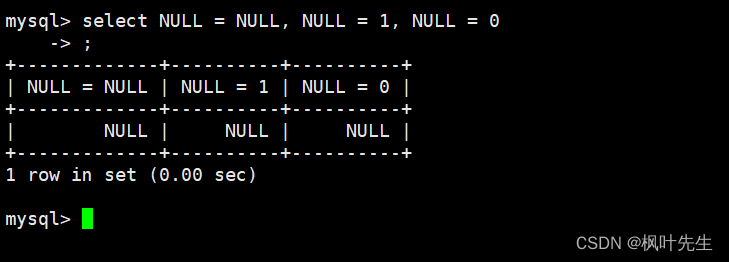
=运算符是NULL不安全的,使用=运算符将任何值与NULL作比较,得到的结果都是NULL
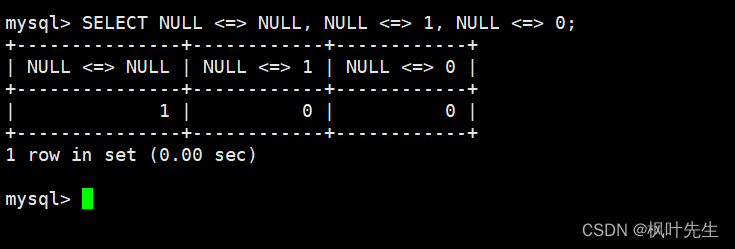
<=>运算符是NULL安全的,使用<=>运算符将NULL和NULL作比较得到的结果为TRUE(1),将非NULL值与NULL作比较得到的结果为FALSE(0)
1.2.3 对查询结果排序
排序语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...] ORDER BY column [ASC|DESC], [...];
说明:
- 大写的表示关键字,[ ]中代表的是可选项
注意:没有ORDER BY子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
查询所有同学及数学成绩,按数学成绩升序显示
下面使用的测试表是上面的exam_result表
mysql> select name, math from exam_result order by math;
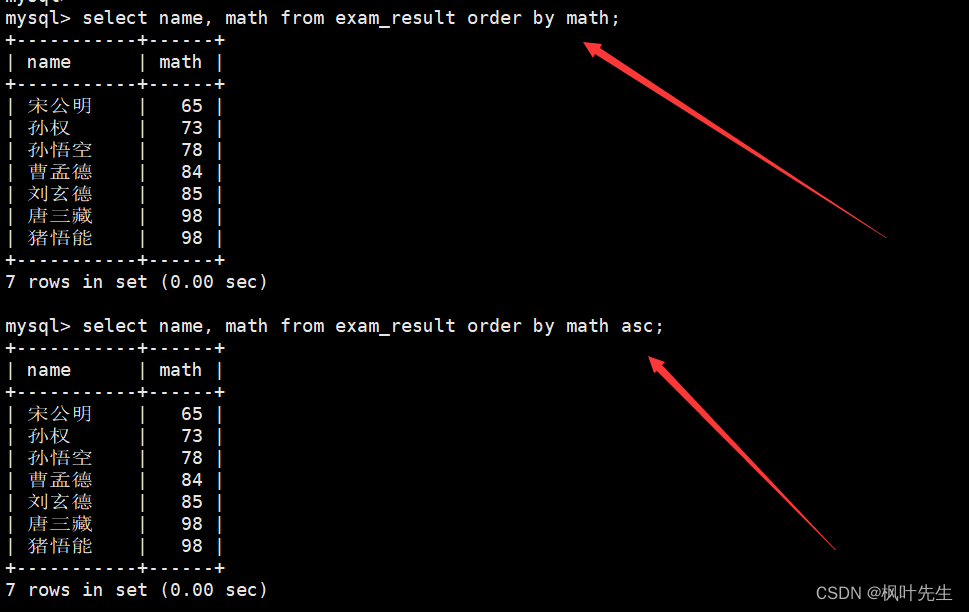
查询所有同学及 qq 号,按 qq 号排序按升序显示
使用的测试表是上面的student表
mysql> select name, qq from student order by qq asc;
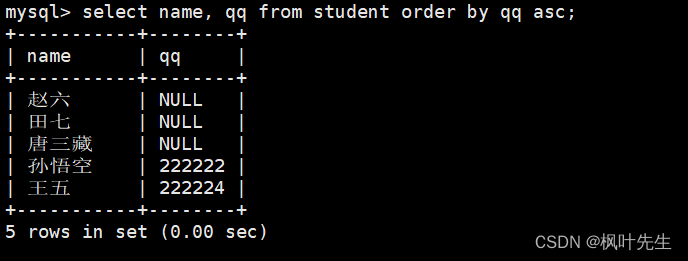
注意: NULL值视为比任何值都小,因此排升序时出现在最上面。
查询所有同学及 qq 号,按 qq 号排序按降序显示
mysql> select name, qq from student order by qq desc;
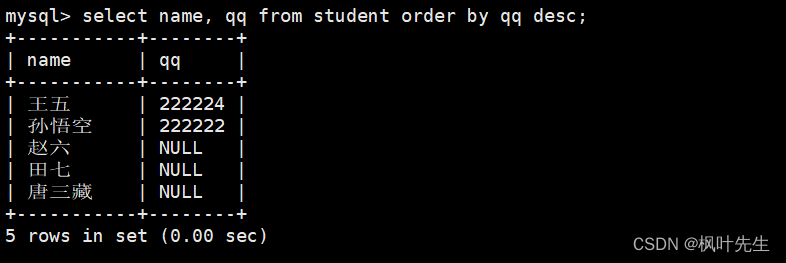
注意: NULL值视为比任何值都小,因此降序时出现在最下面。
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
mysql> select name, math, english, chinese from exam_result order by math desc, english asc, chinese asc;
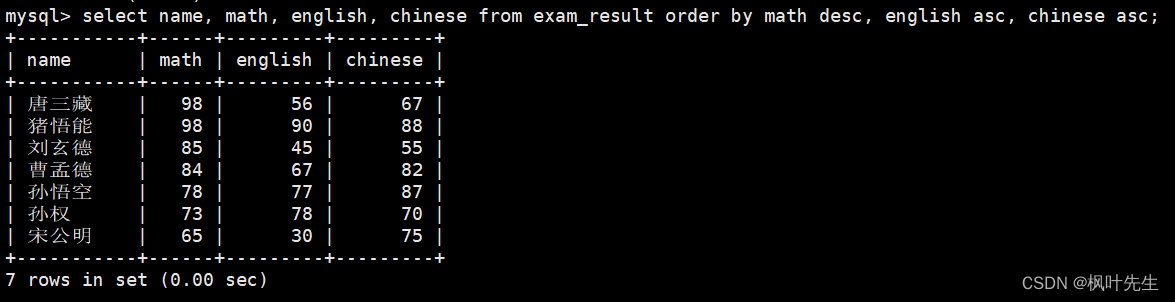
这里说明一下,首先排序的是数学,数学成绩进行降序排序的,只有满足了数学降序,然后才到英语升序排序
比如,当两条记录的数学成绩相同时就会按照英语成绩进行排序,如果这两条记录的英语成绩也相同就会继续按照语文成绩进行排序,以此类推
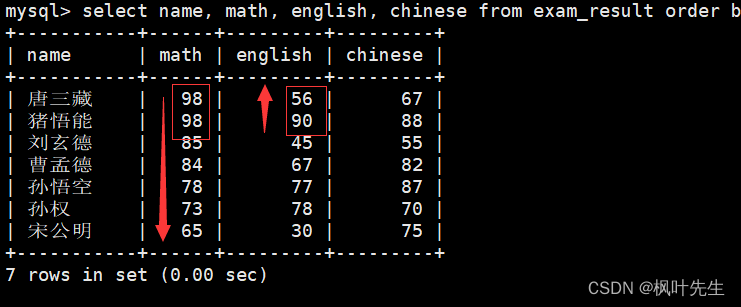
查询同学及总分,由高到低
mysql> select name, math+english+chinese from exam_result order by math+english+chinese desc;
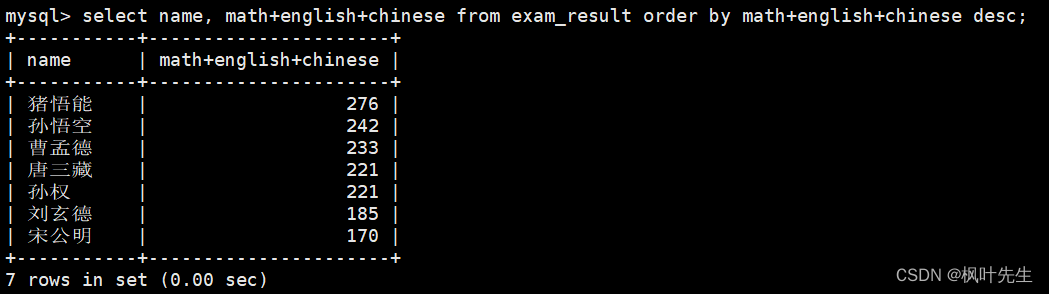
需要注意的是,在order by子句中可以使用select中指定的别名:
- 查询数据时是先根据where子句筛选出符合条件的记录(如果有where子句)
- 然后再将符合条件的记录作为数据源来依次执行select语句
- 最后再通过order by子句对select语句的执行结果进行排序
也就是说,order by子句的执行是在select语句之后的,所以在order by子句中可以使用别名
mysql> select name, math+english+chinese as 总分 from exam_result order by 总分 desc;
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
mysql> select name, math from exam_result where name like '孙%' or name like '曹%' order by math desc;

1.2.4 筛选分页结果
语法如下:
-- 起始下标为 0-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
说明:
- 大写的表示关键字,[ ]中代表的是可选项
- 查询SQL中各语句的执行顺序为:
where、select、order by、limit - limit子句在筛选记录时,不加限制,记录的下标从0开始
注意:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死
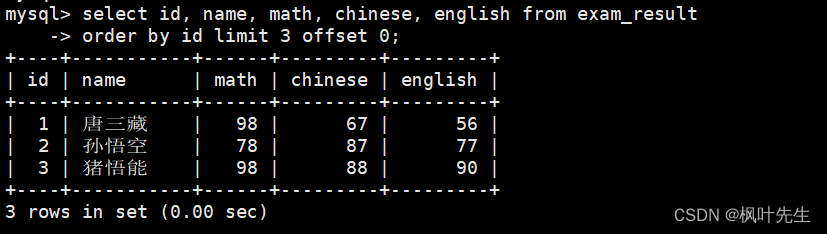
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
mysql> select id, name, math, chinese, english from exam_result-> order by id limit 3 offset 0;
从第3条记录开始,向后筛选出3条记录
mysql> select id, name, math, chinese, english from exam_result order by id limit 3 offset 3;
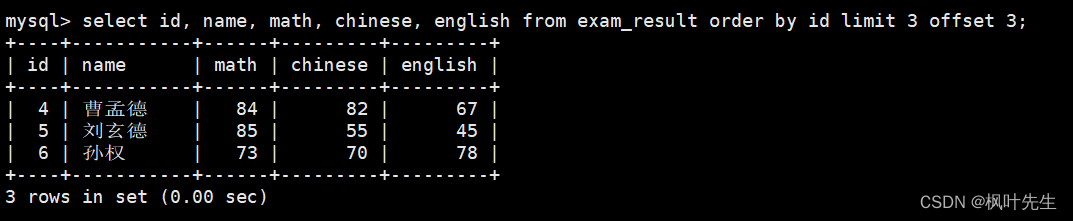
从第6条记录开始,向后筛选出3条记录(如果结果不足 3 个,不会有影响)
select id, name, math, chinese, english from exam_result order by id limit 3 offset 6;

1.3 Update
修改表中数据语法如下:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
说明:
- 大写的表示关键字,[ ]中代表的是可选项
column=expr,表示将记录中列名为column的值修改为expr- 在修改数据之前需要先找到待修改的记录,update语句中的where、order by和limit就是用来定位数据的,不进行条件限制,表中一列数据都会被修改
- 所以要慎用该命令
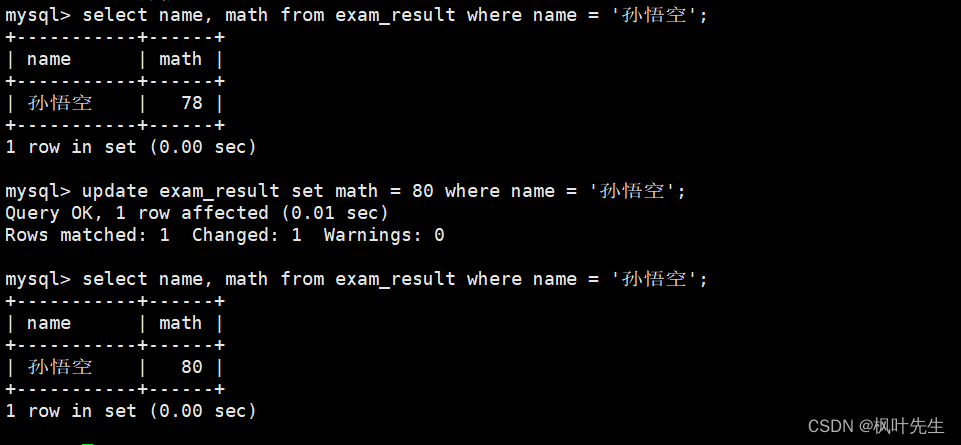
将孙悟空同学的数学成绩变更为 80 分
先查看原数据,再进行修改,最后再查询是否已修改
mysql> update exam_result set math = 80 where name = '孙悟空';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
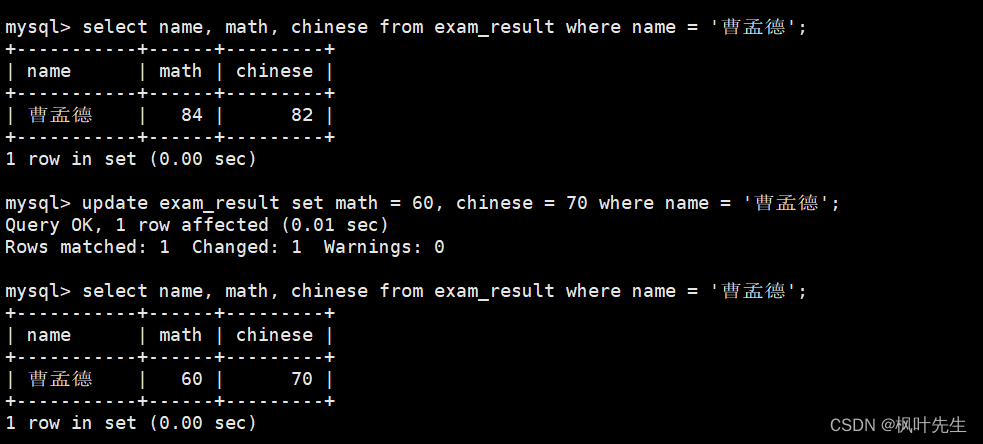
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
也是如此,先查看原数据,再进行修改,最后再查询是否已修改
mysql> update exam_result set math = 60, chinese = 70 where name = '曹孟德';
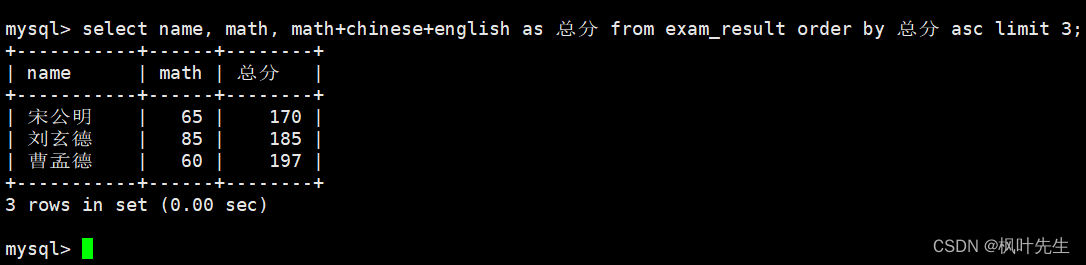
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
先查看原数据
mysql> select name, math, math+chinese+english as 总分 from exam_result order by 总分 asc limit 3;
再进行修改,在update语句中指明要将筛选出来的记录的数学成绩加上30分,最后再查询是否已修改
mysql> update exam_result set math = math+30 order by math+chinese+english asc limit 3;
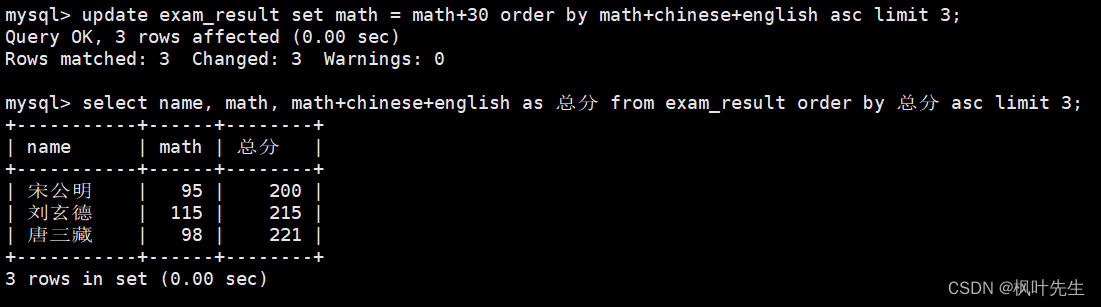
需要注意的是,MySQL中不支持+=这种复合赋值运算符,此外,这里在查看更新后的数据时不能查看总成绩倒数前三的3位同学,因为之前总成绩倒数前三的3位同学,数学成绩加上30分后可能就不再是倒数前三了
mysql> select name, math, math+chinese+english as 总分 from exam_result where name in('宋公明', '刘玄德', '曹孟德');
将所有同学的语文成绩更新为原来的 2 倍
查看原始数据
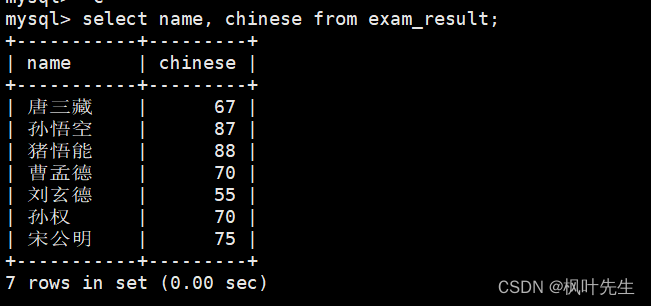
在update语句中指明要将筛选出来的记录的语文成绩变为原来的2倍,并在修改后再次查看数据确保数据成功被修改
mysql> update exam_result set chinese = chinese*2;
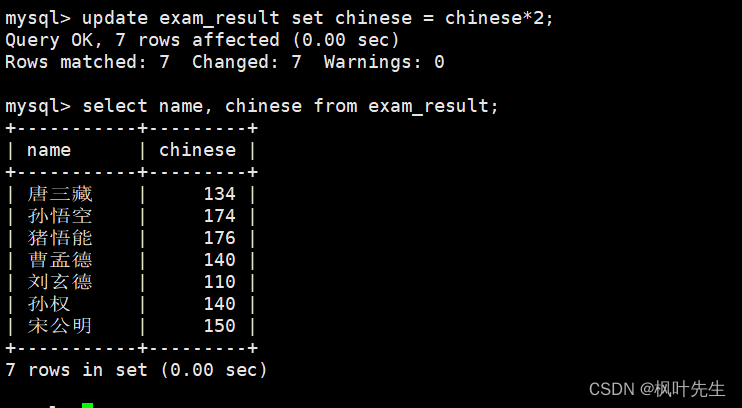
注意:更新全表的语句慎用,没有条件限制,则会更新全表
1.4 Delete
1.4.1 删除数据
删除数据语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
说明:
- 大写的表示关键字,[ ]中代表的是可选项
- 在删除数据之前需要先找到待删除的记录,delete语句中的where、order by和limit就是用来定位数据的
删除孙悟空同学的考试成
先查看原数据,再删除数据,再查看数据是否存在

删除整张表数据
创建测试表
CREATE TABLE for_delete (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
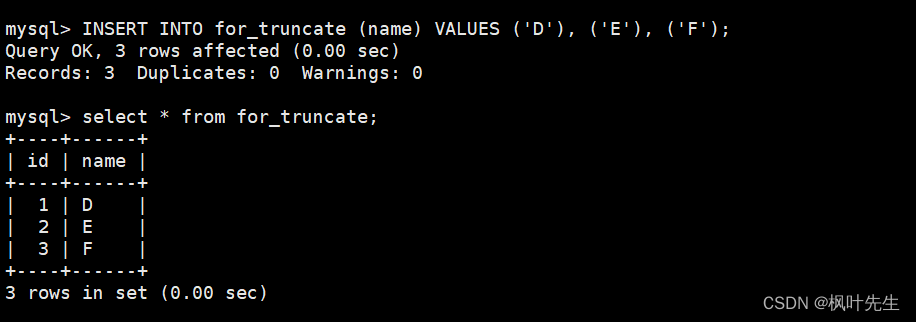
插入测试数据
INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
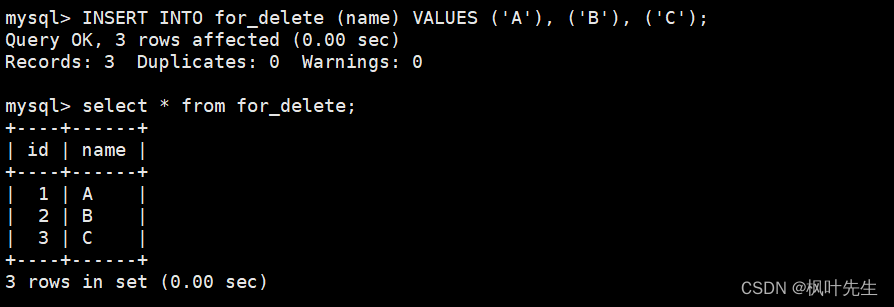
在delete语句中只指明要删除数据的表名,而不通过where、order by和limit指明筛选条件,这时将会删除整张表的数据。
mysql> delete from for_delete;
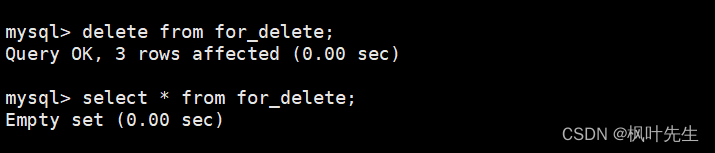
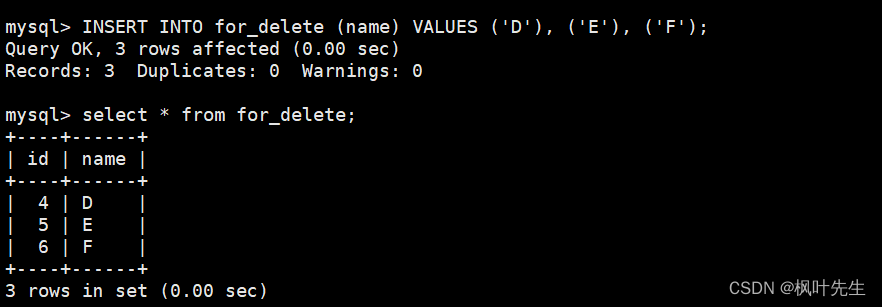
再向表中插入一些数据,在插入数据时不指明自增长字段的值,这时会发现插入数据对应的自增长id值是在之前的基础上继续增长的
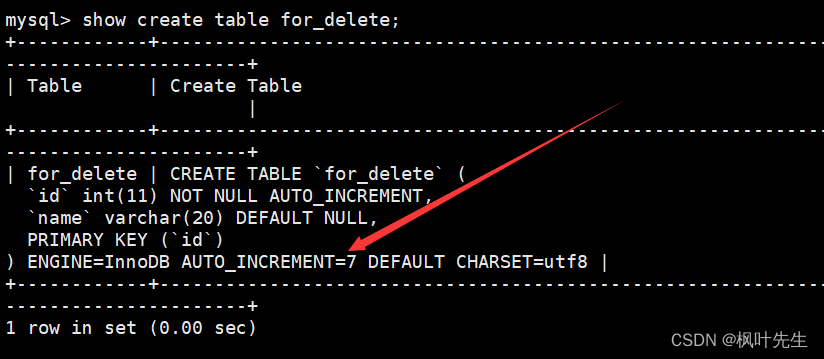
查看创建表时的相关信息时可以看到,有一个AUTO_INCREMENT=n的字段,当通过delete语句删除整表数据时,不会重置AUTO_INCREMENT=n字段,因此删除整表数据后插入数据对应的自增长id值会在原来的基础上继续增长。
注意: 删除整表操作要慎用!
1.4.2 截断表
截断表语法如下:
TRUNCATE [TABLE] table_name
说明:
- 大写的表示关键字,[ ]中代表的是可选项
truncate只能对整表操作,不能像delete一样针对部分数据操作- truncate实际上不对数据操作,所以比delete更快
- 但是truncate在删除数据的时候,并不经过真正的事物,所以无法回滚
- truncate会重置
AUTO_INCREMENT=n字段
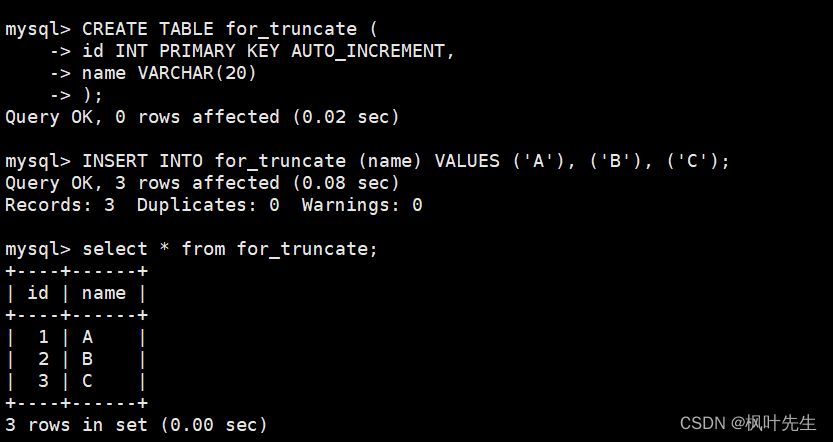
创建一张测试表
CREATE TABLE for_truncate (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)-- 插入测试数据
INSERT INTO for_truncate (name) VALUES ('A'), ('B'), ('C');
);
在truncate语句中只指明要删除数据的表名,这时便会删除整张表的数据,但由于truncate实际不对数据操作,因此执行truncate语句后看到影响行数为0
mysql> truncate table for_truncate;
Query OK, 0 rows affected (0.01 sec)
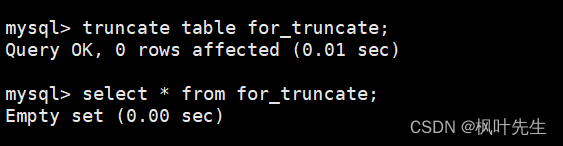
再向表中插入一些数据,在插入数据时不指明自增长字段的值,这时会发现插入数据对应的自增长id值是重新从1开始增长的
注意: 截断表操作要慎用
1.5 插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
说明:
- 大写的表示关键字,[ ]中代表的是可选项
- 该SQL的作用是将筛选出来的记录插入到指定的表当中
删除表中的的重复复记录,重复的数据只能有一份
-- 创建原数据表
CREATE TABLE duplicate_table (id int, name varchar(20));
-- 插入测试数据
INSERT INTO duplicate_table VALUES
(100, 'aaa'),
(100, 'aaa'),
(200, 'bbb'),
(200, 'bbb'),
(200, 'bbb'),
(300, 'ccc');
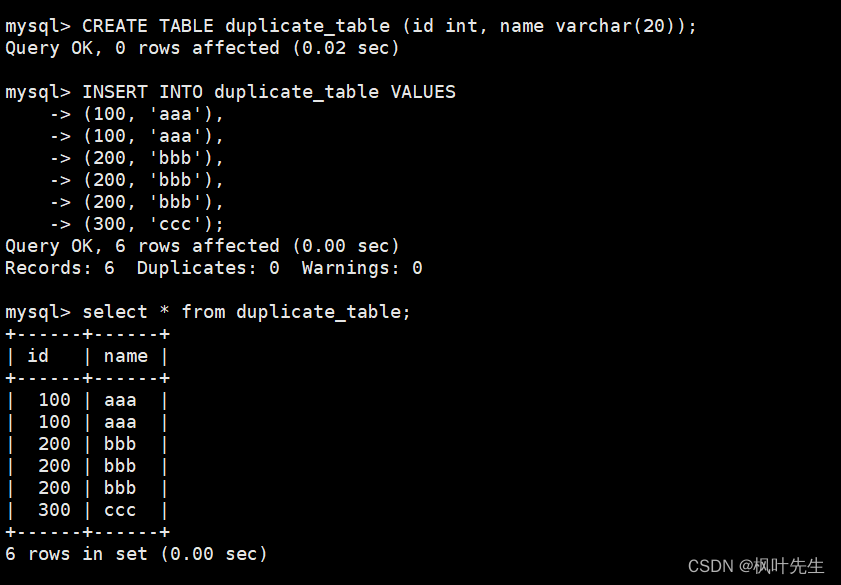
思路:
- 创建一张临时表,该表的结构与测试表的结构相同。
- 以去重的方式查询测试表中的数据,并将查询结果插入到临时表中。
- 将测试表重命名为其他名字,再将临时表重命名为测试表的名字,实现原子去重操作。
-- 创建一张空表 no_duplicate_table,结构和 duplicate_table 一样
mysql> create table no_duplicate_table like duplicate_table;-- 将 duplicate_table 的去重数据插入到 no_duplicate_table
mysql> insert into no_duplicate_table select distinct * from duplicate_table;-- 通过重命名表,实现原子的去重操作
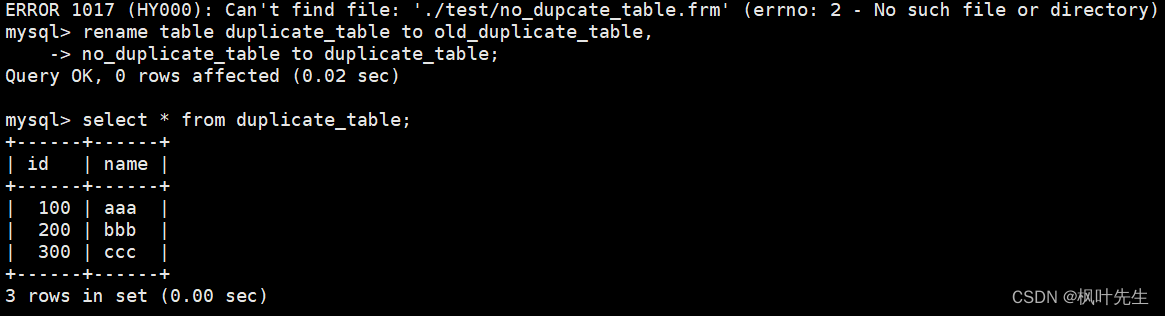
mysql> rename table duplicate_table to old_duplicate_table, -> no_duplicate_table to duplicate_table;
临时表的结构与测试表相同,因此在创建临时表的时候可以借助like进行创建
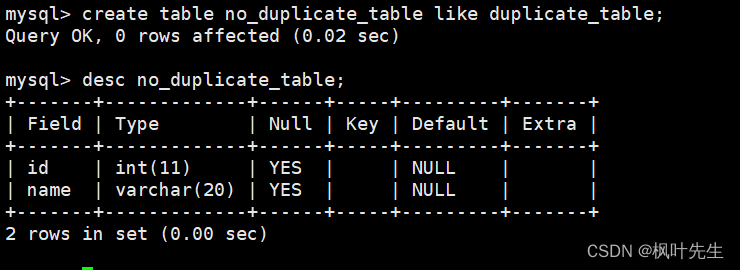
通过插入查询语句将去重查询后的结果插入到临时表中,由于临时表和测试表的结构相同,并且select进行的是全列查询,因此在插入时不用在表名后指明column列表
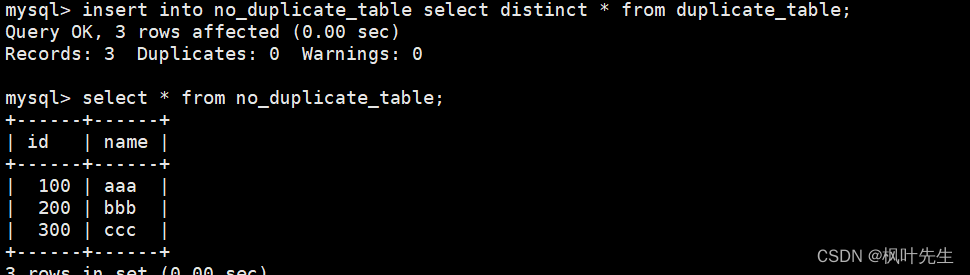
将测试表重命名为其他名字(相当于对去重前的数据进行备份),将临时表重命名为测试表的名字,这时便完成了表中数据的去重操作
1.6 聚合函数
聚合函数对一组值执行计算并返回单一的值,常用的聚合函数如下:
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的最小值,不是数字没有意义 |
注意:聚合函数可以在select语句中使用,此时select每处理一条记录时都会将对应的参数传递给这些聚合函数
统计班级共有多少同学
这里用之前的student表来进行演示
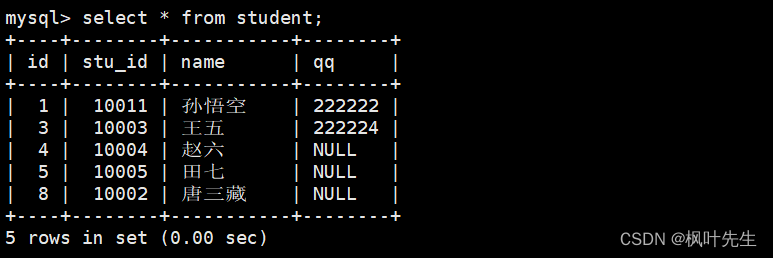
使用*做统计,不受 NULL 影响,将*作为参数传递给count函数,这时便能统计出表中的记录条数
mysql> select count(*) from student;
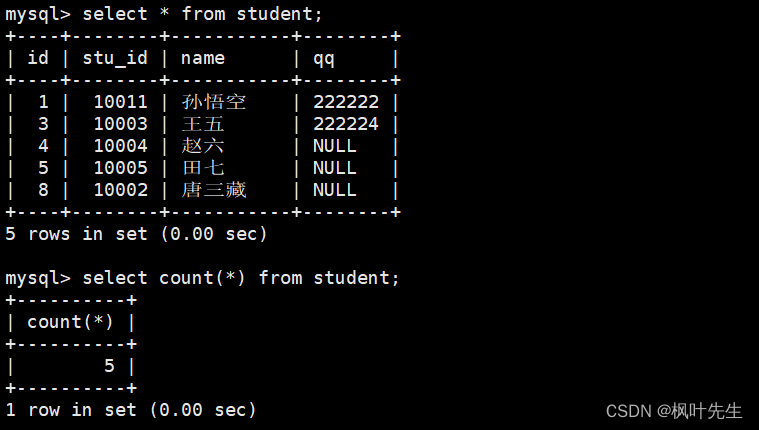
也可以使用表达式做统计,使用count函数,并将表达式作为参数传递给count函数,这时也可以统计出表中的记录条数
mysql> select count(1) from student;
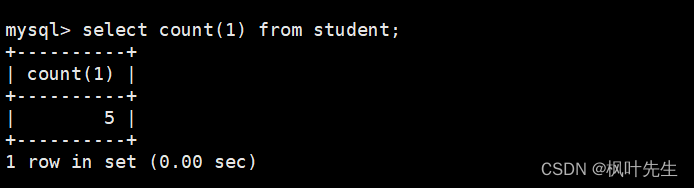
这种写法相当于在查询表中数据时,自行新增了一列列名为特定表达式的列,我们就是在用count函数统计该列中有多少个数据,等价于统计表中有多少条记录
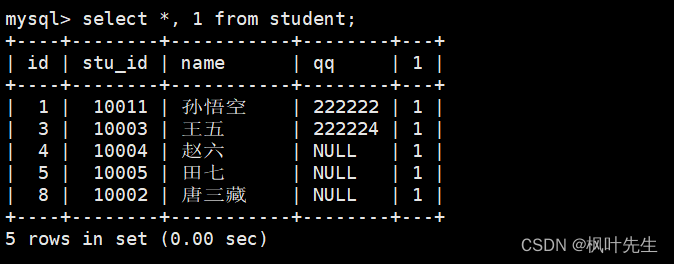
统计班级收集的 qq 号有多少
使用count函数统计qq列中数据的个数,NULL不会计入结果
mysql> select count(qq) from student;

统计本次考试的数学成绩分数个数
这里用之前的exam_result表来进行演示
先使用count函数统计math列中数据的个数(包含重复的)
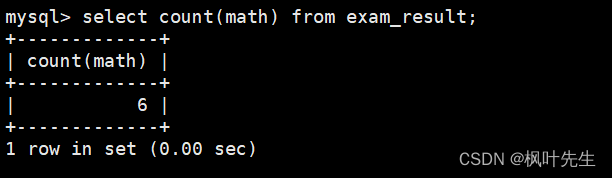
使用count函数时(包括其他聚合函数),在传递的参数之前加上distinct,这时便能统计出表中数学成绩去重后的个数。
mysql> select count(distinct math) from exam_result;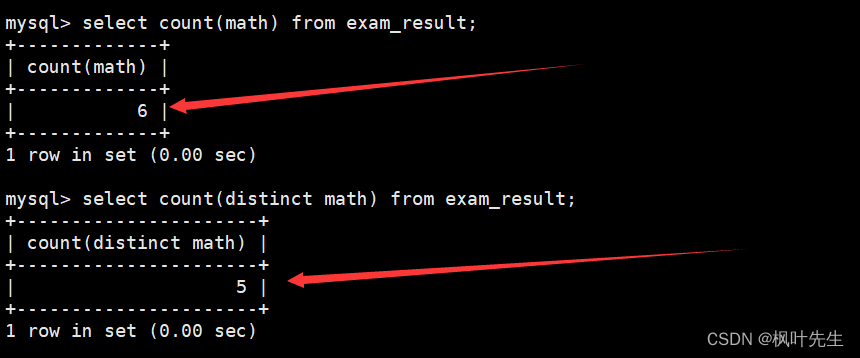
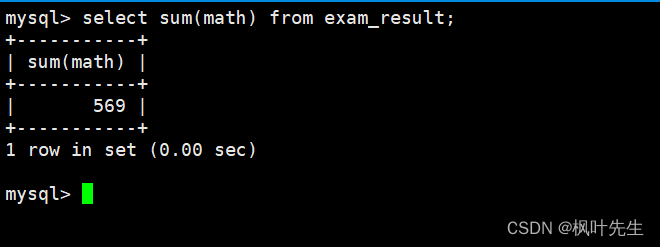
统计数学成绩总分
可以使用sum函数统计math列中数据的总和
mysql> select sum(math) from exam_result;
统计不及格的数学成绩总分
使用where子句中指明筛选条件为数学成绩小于60分
mysql> select sum(math) from exam_result where math < 60;
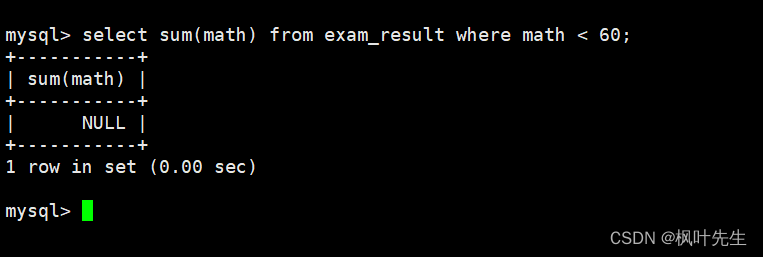
注意:如果没有结果,返回 NULL
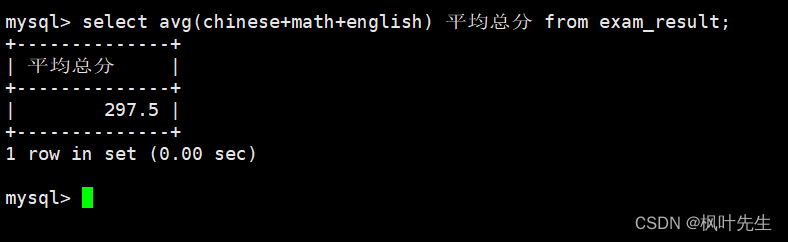
统计平均总分
可以使用avg函数计算总分的平均值
mysql> select avg(chinese+math+english) 平均总分 from exam_result;
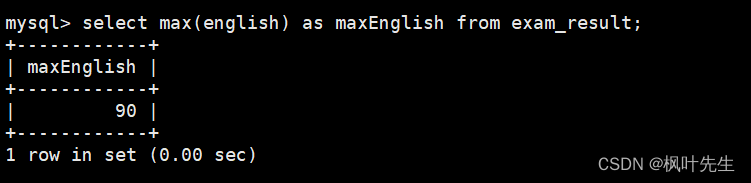
返回英语最高分
可以使用max函数查询英语成绩最高分
mysql> select max(english) as maxEnglish from exam_result;
返回 > 70 分以上的数学最低分
使用where子句中指明筛选条件为英语成绩大于70分,在select语句中使用min函数查询英语成绩最低分
mysql> select min(english) as minEnglish from exam_result where english > 70;

1.7 group by子句的使用(分组查询)
在select中使用group by 子句可以对指定列进行分组查询,语法:
select column1, column2, .. from table group by column;
说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项
- 查询SQL中各语句的执行顺序为:
where、group by、select、order by、limit group by后面的列名,表示按照指定列进行分组查询
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
雇员信息表中包含三张表,分别是员工表(emp)、部门表(dept)和工资等级表(salgrade)
员工表(emp)中包含如下字段:
- 雇员编号(empno)
- 雇员姓名(ename)
- 雇员职位(job)
- 雇员领导编号(mgr)
- 雇佣时间(hiredate)
- 工资月薪(sal)
- 奖金(comm)
- 部门编号(deptno)
部门表(dept)中包含如下字段:
- 部门编号(deptno)
- 部门名称(dname)
- 部门所在地点(loc)
工资等级表(salgrade)中包含如下字段:
- 等级(grade)
- 此等级最低工资(losal)
- 此等级最高工资(hisal)
雇员信息表SQL代码
已上传至下载,主页的资源页面即可找到
然后上传文件,在MySQL中使用source命令依次执行文件中的SQL
source SQL文件路径
-- 例如
mysql> source /home/fy/mysql/scott_data.sql
使用该数据库
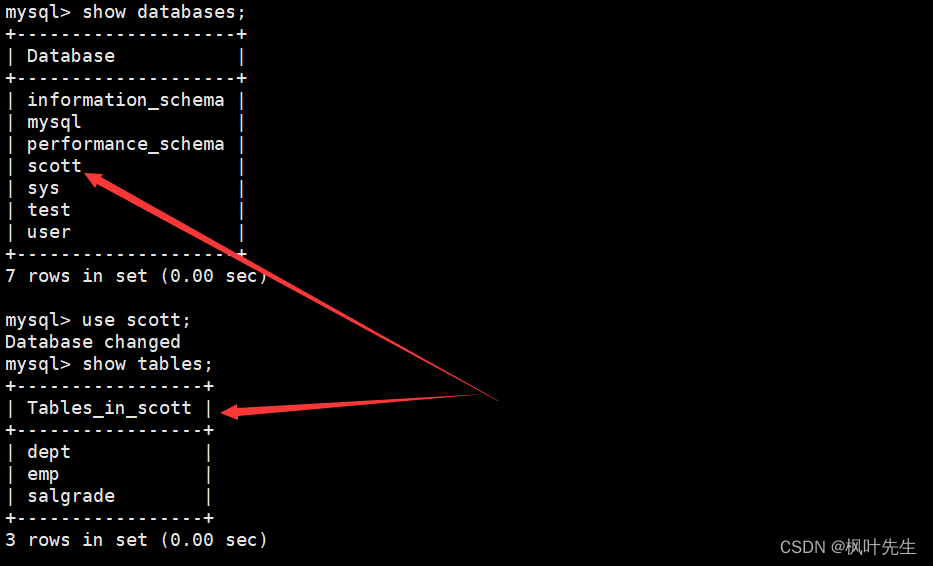
部门表(dept)的表结构和表中的内容如下:
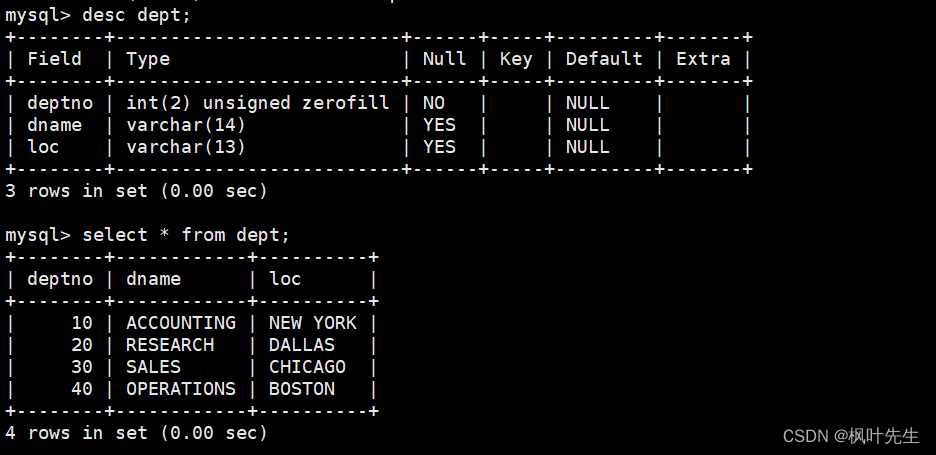
员工表(emp)的表结构和表中的内容如下:
工资等级表(salgrade)的表结构和表中的内容如下:
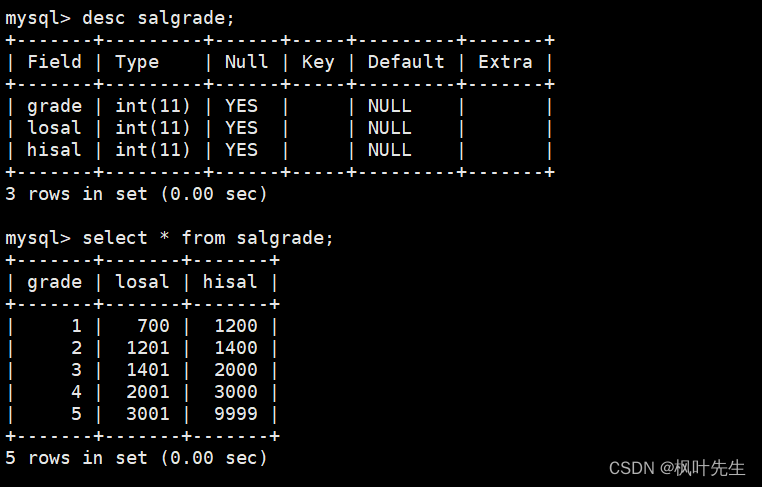
显示每个部门的平均工资和最高工资
在group by子句中指明按照部门号进行分组,在select语句中使用avg函数和max函数,分别查询每个部门的平均工资和最高工资
mysql> select deptno, avg(sal) as 平均工资, max(sal) as 最高工资 from emp group by deptno;
注意:是先执行分组语句,然后各自在组内做聚合查询得到每个组的平均工资和最高工资
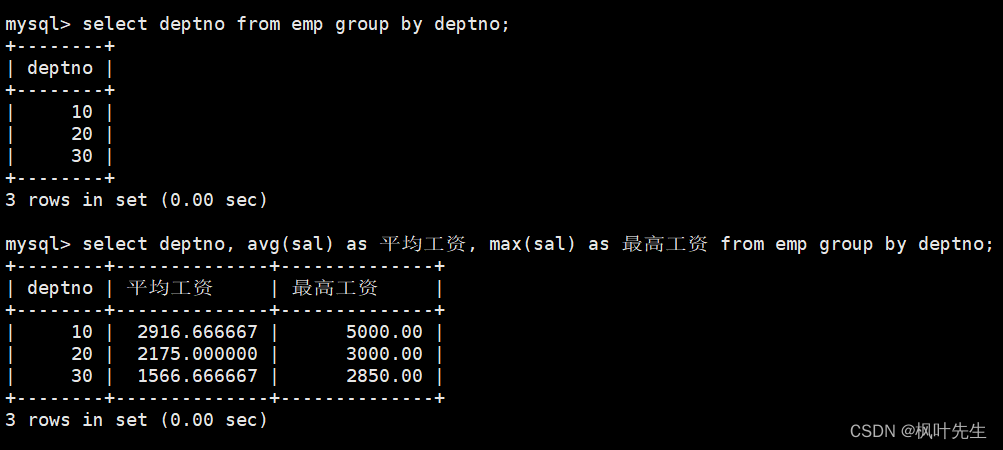
显示每个部门的每种岗位的平均工资和最低工资
在group by子句中指明依次按照部门号和岗位进行分组,在select语句中使用avg函数和min函数,分别查询每个部门的每种岗位的平均工资和最低工资
mysql> select deptno, job, avg(sal) 平均工资, min(sal) 最低工资 from emp group by deptno, job;
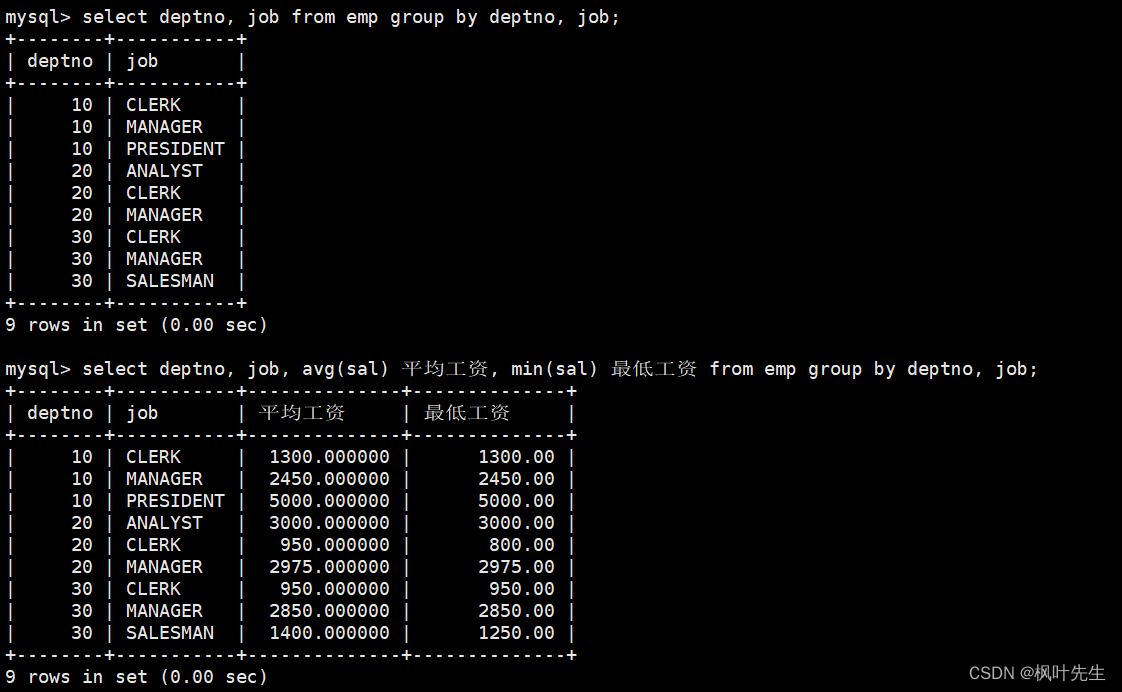
注意:group by子句中可以指明按照多个字段进行分组,各个字段之间使用逗号隔开,分组优先级与书写顺序相同,比如,当两条记录的部门号相同时,将会继续按照岗位进行分组。
显示平均工资低于2000的部门和它的平均工资
这里要使用到HAVING条件,语法如下:
SELECT ... FROM table_name [WHERE ...] [GROUP BY ...] [HAVING ...] ...;
说明:
- 大写的表示关键字,[ ]中代表的是可选项
- SQL中各语句的执行顺序为:
where、group by、select、having、order by、limit having子句中可以指明一个或多个筛选条件having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where
先统计每个部门的平均工资,在group by子句中指明按照部门号进行分组
mysql> select deptno, avg(sal) 平均工资 from emp group by deptno;
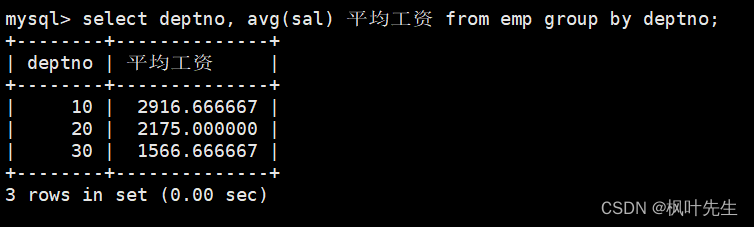
然后通过having子句筛选出平均工资低于2000的部门
mysql> select deptno, avg(sal) 平均工资 from emp group by deptno having 平均工资 < 2000;

having子句和where子句的区别
where子句放在表名后面,而having子句必须搭配group by子句使用,放在group by子句的后面where子句是对整表的数据进行筛选,having子句是对分组后的数据进行筛选where子句中不能使用聚合函数和别名,而having子句中可以使用聚合函数和别名
总结一下,SQL中各语句的执行顺序
- 根据
where子句筛选出符合条件的记录 - 根据
group by子句对数据进行分组 - 将分组后的数据依次执行
select语句 - 根据
having子句对分组后的数据进行进一步筛选 - 根据
order by子句对数据进行排序 - 根据
limit子句筛选若干条记录进行显示
--------------------- END ----------------------
「 作者 」 枫叶先生
「 更新 」 2023.8.18
「 声明 」 余之才疏学浅,故所撰文疏漏难免,或有谬误或不准确之处,敬请读者批评指正。
相关文章:
【MySQL系列】表内容的基本操作(增删查改)
「前言」文章内容大致是对MySQL表内容的基本操作,即增删查改。 「归属专栏」MySQL 「主页链接」个人主页 「笔者」枫叶先生(fy) 目录 一、MySQL表内容的增删查改1.1 Create1.1.1 单行数据全列插入1.1.2 多行数据指定列插入1.1.3 插入否则更新1.1.4 数据替换 1.2 Ret…...

docker搭建LNMP
docker安装 略 下载镜像 nginx:最新版php-fpm:根据自己需求而定mysql:根据自己需求定 以下是我搭建LNMP使用的镜像版本 rootVM-12-16-ubuntu:/docker/lnmp/php/etc# docker images REPOSITORY TAG IMAGE ID CREATED SIZE mysql 8.0…...

未出现过的最小正整数
给定一个长度为 n 的整数数组,请你找出未在数组中出现过的最小正整数。 样例 输入1:[-5, 3, 2, 3]输出1:1输入2:[1, 2, 3]输出2:4数据范围 1≤n≤105 , 数组中元素的取值范围 [−109,109]。 代码: c…...

易服客工作室:WordPress是什么?初学者的解释
目录 什么是WordPress? WordPress可以制作什么类型的网站? 谁制作了WordPress?它已经存在多久了? 谁使用 WordPress? 白宫网站 微软 滚石乐队 为什么要使用 WordPress? WordPress 是免费且…...
2019年9月全国计算机等级考试真题(C语言二级)
2019年9月全国计算机等级考试真题(C语言二级) 第1题 1、“商品”与“顾客”两个实体集之间的联系一般是 A. 一对一 B. 一对多 C. 多对一 D. 多对多 正确答案:D 第2题 定义学生选修课程的关系模式:SC(S#,…...

LLaMA模型泄露 Meta成最大受益者
一份被意外泄露的谷歌内部文件,将Meta的LLaMA大模型“非故意开源”事件再次推到大众面前。“泄密文件”的作者据悉是谷歌内部的一位研究员,他大胆指出,开源力量正在填平OpenAI与谷歌等大模型巨头们数年来筑起的护城河,而最大的受益…...
企业中商业智能BI,常见的工具和技术
商业智能(Business Intelligence,简称BI)数据可视化是通过使用图表、图形和其他可视化工具来呈现和解释商业数据的过程。它旨在帮助组织更好地理解和分析他们的数据,从而做出更明智的商业决策。 常见的商业智能数据可视化工具和技…...
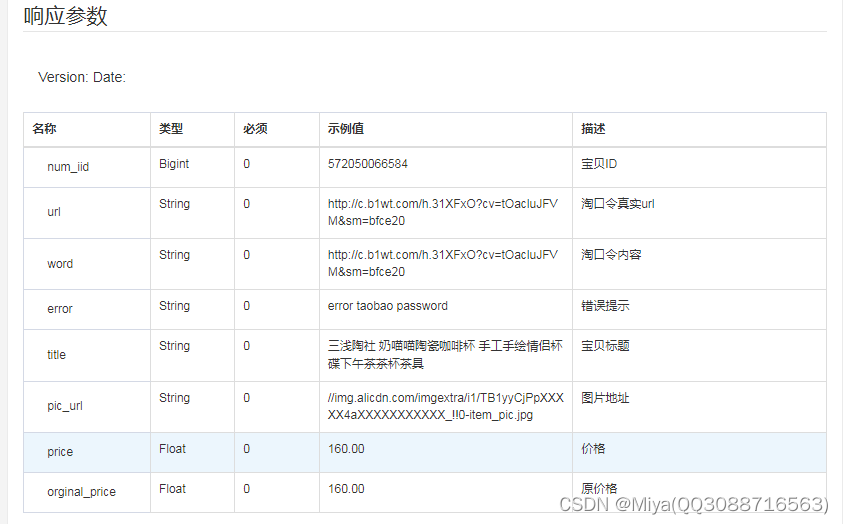
item_password-获得淘口令真实url
一、接口参数说明: item_password-获得淘口令真实url ,点击更多API调试,请移步注册API账号点击获取测试key和secret 公共参数 请求地址: https://api-gw.onebound.cn/taobao/item_password 名称类型必须描述keyString是调用key(…...
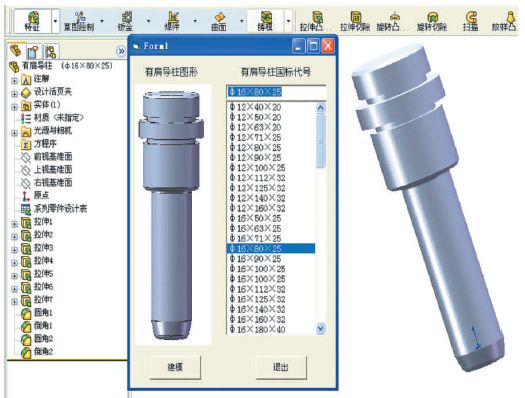
基于SOLIDWORKS配置功能建立塑料模具标准件库
在塑料模具的设计过程中,建立其三维模型对于后续进行CAE分析和CAM加工是非常重要的。除了型腔和型芯以外,塑料模具中的标准件很多,如推杆、导柱、导套、推板、限位钉等,这些对于不同的产品是需要反复调用的。目前,我国…...
1.物联网LWIP网络,TCP/IP协议簇
一。TCP/IP协议簇 1.应用层:FTP,HTTP,Telent,DNS,RIP 2.传输层:TCP,UDP 3.网络层:IPV4,IPV6,OSPF,EIGRP 4.数据链路层:Ethernet&#…...

拷贝公钥文件后,ssh 服务器仍提示输入密码
我们因为工作需要,可能在本地包含多个公私钥对,且每个公私钥对在生成时,指定的邮箱也不相同,所以我们在登录一些机器时,会指定不同的公钥文件,但是,有时候就算我们指定了正确的公钥文件…...
算法|Day45 动态规划13
LeetCode 300.最长递增子序列 题目链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 题目描述:给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除&…...

基于随机森林的手写体数字识别,基于RF的手写体数字识别,基于RF的MNIST数据集分类识别
目录 背影 摘要 随机森林的基本定义 随机森林实现的步骤 基于随机森林的MNIST数据集分类识别 代码下载链接: 随机森林的手写体数字分类识别,随机森林的MNIST手写体数据集分类识别,卷积神经网络的手写体数字识别(代码完整,数据完整)资源-CSDN文库 https://download.csdn.n…...

vite初始化vue3项目(配置自动格式化工具与git提交规范工具)
初始化项目 vite构建vue项目还是比较简单的,简单配置选择一下就行了 初始化命令 npm init vuelatest初始化最新版本vue项目 2. 基本选项含义 Add TypeScript 是否添加TSADD JSX是否支持JSXADD Vue Router是否添加Vue Router路由管理工具ADD Pinia 是否添加pinia…...

leetcode473. 火柴拼正方形(回溯算法-java)
火柴拼正方形 leetcode473 火柴拼正方形题目描述回溯算法 上期经典算法 leetcode473 火柴拼正方形 难度 - 中等 原题链接 - leetcode473 火柴拼正方形 题目描述 你将得到一个整数数组 matchsticks ,其中 matchsticks[i] 是第 i 个火柴棒的长度。你要用 所有的火柴棍…...

git-fatal: No url found for submodule path ‘packages/libary‘ in .gitmodules
文章目录 前言一、git submodule功能使用二、错误信息:三、解决方法:四、.gitmodules配置文件:总结 前言 最近在做vue项目,因为项目比较复杂,把功能拆分成很多子模块,我们使用Git的submodule功能。遇到错误…...

Android开发之性能优化:过渡绘制解决方案
1. 过渡绘制 屏幕上某一像素点在一帧中被重复绘制多次,就是过渡绘制。 下图中多个卡片跌在一起,但是只有第一个卡片是完全可见的。背后的卡片只有部分可见。但是Android系统在绘制时会将下层的卡片进行绘制,接着再将上层的卡片进行绘制。但其…...

Wireshark 抓包过滤命令汇总
Wireshark 抓包过滤命令汇总 Wireshark 是一个强大的网络分析工具,它可以帮助网络管理员和安全专家监控和分析网络流量。通过捕获网络数据包,Wireshark 能够帮助我们识别网络中的问题、瓶颈以及潜在的安全威胁。在使用 Wireshark 进行网络数据包分析时&…...

配资平台app(正规股票配资软件)架构是怎么搭建的?
随着股票市场的发展,越来越多的投资者开始尝试使用股票配资平台进行杠杆炒股,因此,搭建一套稳定、可靠的配资平台app架构显得尤为重要。本文将介绍配资平台app架构设计的关键要素,以及建立一个正规的配资平台app所需考虑的问题。 …...

【实用黑科技】如何 把b站的缓存视频弄到本地——数据恢复软件WinHex 和 音视频转码程序FFmpeg
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:效率…...

怎么安装OpenClaw?2026年4月本地配置Coding Plan零门槛流程
怎么安装OpenClaw?2026年4月本地配置Coding Plan零门槛流程。本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程,包含环境配置、服务启动、Skills集成、阿里云…...

烽火HG5143D光猫破解实战:用Fiddler抓包获取超级密码,开启Telnet保姆级教程
烽火HG5143D光猫深度配置指南:安全获取管理权限与网络优化方案 家里新装了电信宽带,配套的烽火HG5143D光猫却锁死了路由模式,想接自己的路由器拨号都成问题?这种情况在电信家庭网关用户中并不少见。作为一款采用Linux系统的智能光…...

Python之@dataclass
一、dataclass 到底是什么 staticmethod、property 这类装饰器大家比较熟悉,dataclass 也是装饰器的一种。它来自标准库 dataclasses 模块,在 Python 3.7 中正式加入,核心目标是: 让“以数据为中心”的类更简洁。自动生成常见魔术…...

从《倘若鸟儿回还》看无障碍设计:如何用技术为轮椅用户打造真正的“独立出行”体验
从《倘若鸟儿回还》看无障碍设计:如何用技术为轮椅用户打造真正的“独立出行”体验 艾米的故事让我们看到,残障人士对独立性的渴望往往被善意所掩盖。查尔斯希望成为她"唯一的推椅人",却忽略了轮椅对她而言不是束缚,而是…...

终极免费PCB查看器:3分钟掌握OpenBoardView电路板分析技巧
终极免费PCB查看器:3分钟掌握OpenBoardView电路板分析技巧 【免费下载链接】OpenBoardView View .brd files 项目地址: https://gitcode.com/gh_mirrors/op/OpenBoardView 还在为复杂的.brd文件头疼吗?面对密密麻麻的电路板元件不知所措ÿ…...

Windows平台安卓应用安装难题的完美解决方案:APK Installer全面指南
Windows平台安卓应用安装难题的完美解决方案:APK Installer全面指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows电脑无法直接安装安卓应用…...
)
【日常做题】 代码随想录(岛屿最大面积+寻宝)
👨💻 关于作者:会编程的土豆 “不是因为看见希望才坚持,而是坚持了才看见希望。” 你好,我是会编程的土豆,一名热爱后端技术的Java学习者。 📚 正在更新中的专栏: 《数据结构与算…...

新手避坑指南:用RK3576开发板点亮MIPI-DSI屏幕,从接线到配置的完整流程
RK3576开发板实战:MIPI-DSI屏幕连接与配置避坑手册 第一次拿到RK3576开发板和MIPI-DSI屏幕时,那种既兴奋又忐忑的心情我至今记忆犹新。作为嵌入式开发的新手,面对密密麻麻的接口和陌生的术语,最担心的莫过于一个不小心就把几千块的…...

零基础玩转Sambert语音合成:开箱即用版,5分钟搭建AI配音系统
零基础玩转Sambert语音合成:开箱即用版,5分钟搭建AI配音系统 1. 引言:为什么选择开箱即用的语音合成? 想象一下,你正在制作一个短视频,需要给画面配上生动的旁白。传统方法要么自己录音,要么花…...

终极游戏存档备份方案:Ludusavi让你的游戏进度永不丢失 [特殊字符]
终极游戏存档备份方案:Ludusavi让你的游戏进度永不丢失 🎮 【免费下载链接】ludusavi Backup tool for PC game saves 项目地址: https://gitcode.com/gh_mirrors/lu/ludusavi 你是否曾因系统重装、硬盘故障或意外删除而失去宝贵的游戏进度&#…...