第G1周:生成对抗网络(GAN)入门
🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有)
🍖 作者:[K同学啊]
一、理论基础
生成对抗网络(Generative Adversarial Networks, GAN)是近年来深度学习领域的一个热点方向。GAN并不指代某一个具体的神经网络,而是指一类基于博弈思想而设计的神经网络。GAN由两个分别被称为生成器(Generator)和判别器(Discriminator)的神经网络组成。其中,生成器从某种噪声分布中随机采样作为输入,输出与训练集中真实样本非常相似的人工样本;判别器的输入则为真实样本或人工样本,其目的是将人工样本与真实样本尽可能地区分出来。生成器和判别器交替运行,相互博弈,各自的能力都得到升。理想情况下,经过足够次数的博弈之后,判别器无法判断给定样本的真实性,即对于所有样本都输出50%真,50%假的判断。此时,生成器输出的人工样本已经逼真到使判别器无法分辨真假,停止博弈。这样就可以得到一个具有“伪造”真实样本能力的生成器。
1. 生成器
GANs中,生成器 G 选取随机噪声 z 作为输入,通过生成器的不断拟合,最终输出一个和真实样本尺寸相同,分布相似的伪造样本G(z)。生成器的本质是一个使用生成式方法的模型,它对数据的分布假设和分布参数进行学习,然后根据学习到的模型重新采样出新的样本。
从数学上来说,生成式方法对于给定的真实数据,首先需要对数据的显式变量或隐含变量做分布假设;然后再将真实数据输入到模型中对变量、参数进行训练;最后得到一个学习后的近似分布,这个分布可以用来生成新的数据。从机器学习的角度来说,模型不会去做分布假设,而是通过不断地学习真实数据,对模型进行修正,最后也可以得到一个学习后的模型来做样本生成任务。这种方法不同于数学方法,学习的过程对人类理解较不直观。
2. 判别器
GANs中,判别器 D 对于输入的样本 x,输出一个[0,1]之间的概率数值D(x)。x 可能是来自于原始数据集中的真实样本 x,也可能是来自于生成器 G 的人工样本G(z)。通常约定,概率值D(x)越接近于1就代表此样本为真实样本的可能性更大;反之概率值越小则此样本为伪造样本的可能性越大。也就是说,这里的判别器是一个二分类的神经网络分类器,目的不是判定输入数据的原始类别,而是区分输入样本的真伪。可以注意到,不管在生成器还是判别器中,样本的类别信息都没有用到,也表明 GAN 是一个无监督的学习过程。
3. 基本原理
GAN是博弈论和机器学习相结合的产物,于2014年Ian Goodfellow的论文中问世,一经问世即火爆足以看出人们对于这种算法的认可和狂热的研究热忱。想要更详细的了解GAN,就要知道它是怎么来的,以及这种算法出现的意义是什么。研究者最初想要通过计算机完成自动生成数据的功能,例如通过训练某种算法模型,让某模型学习过一些苹果的图片后能自动生成苹果的图片,具备些功能的算法即认为具有生成功能。但是GAN不是第一个生成算法,而是以往的生成算法在衡量生成图片和真实图片的差距时采用均方误差作为损失函数,但是研究者发现有时均方误差一样的两张生成图片效果却截然不同,鉴于此不足Ian Goodfellow提出了GAN。
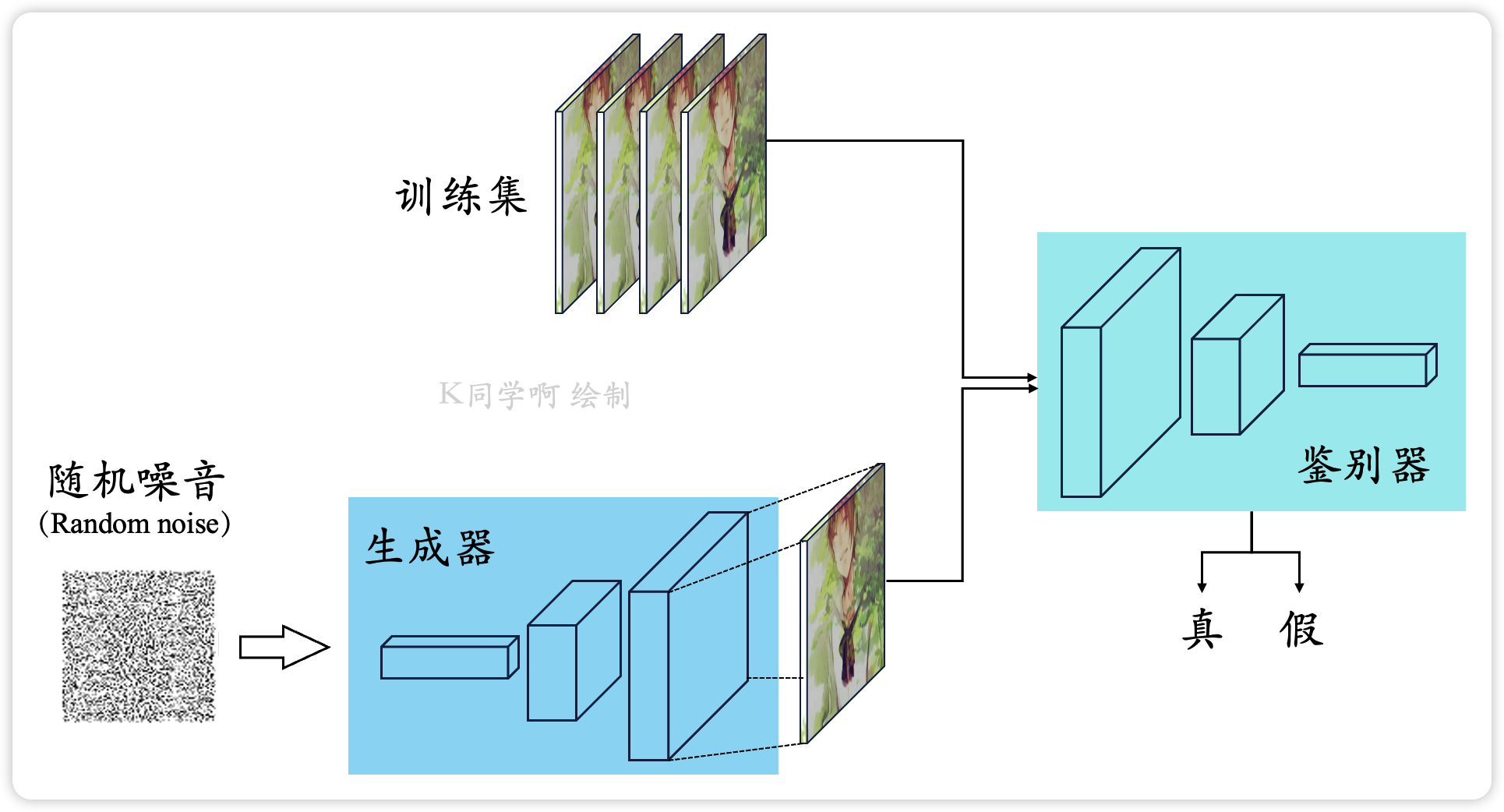
那么GAN是如何完成生成图片这项功能的呢,如图1所示,GAN是由两个模型组成的:生成模型G和判别模型D。首先第一代生成模型1G的输入是随机噪声z,然后生成模型会生成一张初级照片,训练一代判别模型1D另其进行二分类操作,将生成的图片判别为0,而真实图片判别为1;为了欺瞒一代鉴别器,于是一代生成模型开始优化,然后它进阶成了二代,当它生成的数据成功欺瞒1D时,鉴别模型也会优化更新,进而升级为2D,按照同样的过程也会不断更新出N代的G和D。
二、前期准备工作
1. 定义超参数
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch## 创建文件夹
os.makedirs("./images/", exist_ok=True) ## 记录训练过程的图片效果
os.makedirs("./save/", exist_ok=True) ## 训练完成时模型保存的位置
os.makedirs("./datasets/mnist", exist_ok=True) ## 下载数据集存放的位置## 超参数配置
n_epochs=50
batch_size=512
lr=0.0002
b1=0.5
b2=0.999
n_cpu=2
latent_dim=100
img_size=28
channels=1
sample_interval=500## 图像的尺寸:(1, 28, 28), 和图像的像素面积:(784)
img_shape = (channels, img_size, img_size)
img_area = np.prod(img_shape)## 设置cuda:(cuda:0)
cuda = True if torch.cuda.is_available() else False
print(cuda)
## mnist数据集下载
mnist = datasets.MNIST(root='./datasets/', train=True, download=True, transform=transforms.Compose([transforms.Resize(img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]),
)
## 配置数据到加载器
dataloader = DataLoader(mnist,batch_size=batch_size,shuffle=True,
)
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(img_area, 512), # 输入特征数为784,输出为512nn.LeakyReLU(0.2, inplace=True), # 进行非线性映射nn.Linear(512, 256), # 输入特征数为512,输出为256nn.LeakyReLU(0.2, inplace=True), # 进行非线性映射nn.Linear(256, 1), # 输入特征数为256,输出为1nn.Sigmoid(), # sigmoid是一个激活函数,二分类问题中可将实数映射到[0, 1],作为概率值, 多分类用softmax函数)def forward(self, img):img_flat = img.view(img.size(0), -1) # 鉴别器输入是一个被view展开的(784)的一维图像:(64, 784)validity = self.model(img_flat) # 通过鉴别器网络return validity # 鉴别器返回的是一个[0, 1]间的概率
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()## 模型中间块儿def block(in_feat, out_feat, normalize=True): # block(in, out )layers = [nn.Linear(in_feat, out_feat)] # 线性变换将输入映射到out维if normalize:layers.append(nn.BatchNorm1d(out_feat, 0.8)) # 正则化layers.append(nn.LeakyReLU(0.2, inplace=True)) # 非线性激活函数return layers## prod():返回给定轴上的数组元素的乘积:1*28*28=784self.model = nn.Sequential(*block(latent_dim, 128, normalize=False), # 线性变化将输入映射 100 to 128, 正则化, LeakyReLU*block(128, 256), # 线性变化将输入映射 128 to 256, 正则化, LeakyReLU*block(256, 512), # 线性变化将输入映射 256 to 512, 正则化, LeakyReLU*block(512, 1024), # 线性变化将输入映射 512 to 1024, 正则化, LeakyReLUnn.Linear(1024, img_area), # 线性变化将输入映射 1024 to 784nn.Tanh() # 将(784)的数据每一个都映射到[-1, 1]之间)## view():相当于numpy中的reshape,重新定义矩阵的形状:这里是reshape(64, 1, 28, 28)def forward(self, z): # 输入的是(64, 100)的噪声数据imgs = self.model(z) # 噪声数据通过生成器模型imgs = imgs.view(imgs.size(0), *img_shape) # reshape成(64, 1, 28, 28)return imgs # 输出为64张大小为(1, 28, 28)的图像
## 创建生成器,判别器对象
generator = Generator()
discriminator = Discriminator()## 首先需要定义loss的度量方式 (二分类的交叉熵)
criterion = torch.nn.BCELoss()## 其次定义 优化函数,优化函数的学习率为0.0003
## betas:用于计算梯度以及梯度平方的运行平均值的系数
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))## 如果有显卡,都在cuda模式中运行
if torch.cuda.is_available():generator = generator.cuda()discriminator = discriminator.cuda()criterion = criterion.cuda()
for epoch in range(n_epochs): # epoch:50for i, (imgs, _) in enumerate(dataloader): # imgs:(64, 1, 28, 28) _:label(64)imgs = imgs.view(imgs.size(0), -1) # 将图片展开为28*28=784 imgs:(64, 784)real_img = Variable(imgs).cuda() # 将tensor变成Variable放入计算图中,tensor变成variable之后才能进行反向传播求梯度real_label = Variable(torch.ones(imgs.size(0), 1)).cuda() ## 定义真实的图片label为1fake_label = Variable(torch.zeros(imgs.size(0), 1)).cuda() ## 定义假的图片的label为0real_out = discriminator(real_img) # 将真实图片放入判别器中loss_real_D = criterion(real_out, real_label) # 得到真实图片的lossreal_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好## 计算假的图片的损失## detach(): 从当前计算图中分离下来避免梯度传到G,因为G不用更新z = Variable(torch.randn(imgs.size(0), latent_dim)).cuda() ## 随机生成一些噪声, 大小为(128, 100)fake_img = generator(z).detach() ## 随机噪声放入生成网络中,生成一张假的图片。fake_out = discriminator(fake_img) ## 判别器判断假的图片loss_fake_D = criterion(fake_out, fake_label) ## 得到假的图片的lossfake_scores = fake_out## 损失函数和优化loss_D = loss_real_D + loss_fake_D # 损失包括判真损失和判假损失optimizer_D.zero_grad() # 在反向传播之前,先将梯度归0loss_D.backward() # 将误差反向传播optimizer_D.step() # 更新参数z = Variable(torch.randn(imgs.size(0), latent_dim)).cuda() ## 得到随机噪声fake_img = generator(z) ## 随机噪声输入到生成器中,得到一副假的图片output = discriminator(fake_img) ## 经过判别器得到的结果## 损失函数和优化loss_G = criterion(output, real_label) ## 得到的假的图片与真实的图片的label的lossoptimizer_G.zero_grad() ## 梯度归0loss_G.backward() ## 进行反向传播optimizer_G.step() ## step()一般用在反向传播后面,用于更新生成网络的参数## 打印训练过程中的日志## item():取出单元素张量的元素值并返回该值,保持原元素类型不变if ( i + 1 ) % 100 == 0:print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [D real: %f] [D fake: %f]"% (epoch, n_epochs, i, len(dataloader), loss_D.item(), loss_G.item(), real_scores.data.mean(), fake_scores.data.mean()))## 保存训练过程中的图像batches_done = epoch * len(dataloader) + iif batches_done % sample_interval == 0:save_image(fake_img.data[:25], "./images/%d.png" % batches_done, nrow=5, normalize=True)
torch.save(generator.state_dict(), './generator.pth')
torch.save(discriminator.state_dict(), './discriminator.pth')
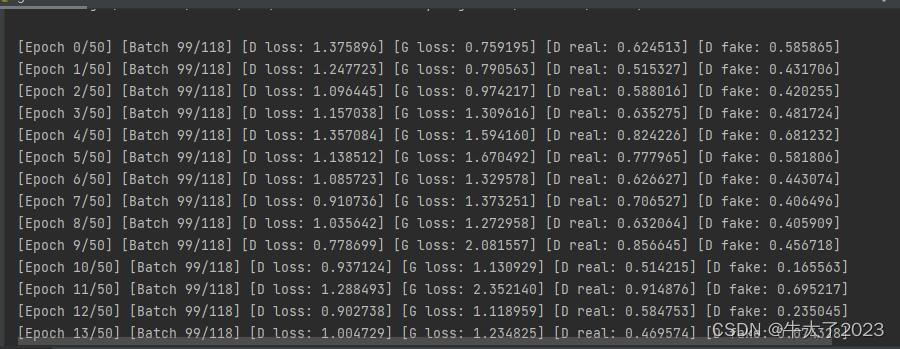
部分运行截图:

相关文章:
第G1周:生成对抗网络(GAN)入门
🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有) 🍖 作者:[K同学啊] 一、理论基础 生成对抗网络(Generative Adversarial Networks, GAN)是近年来深度学习领域…...

Stable Diffusion基础:ControlNet之图片高仿效果
今天继续给大家分享AI绘画中 ControlNet 的强大功能,本次的主角是 Reference,它可以将参照图片的风格迁移到新生成的图片中,这句话理解起来很困难,我们将通过几个实例来加深体会,比如照片转二次元风格、名画改造、AI减…...
TCGA数据下载推荐:R语言easyTCGA包
#使用easyTCGA获取数据 #清空 rm(listls()) gc() # 安装bioconductor上面的R包 options(BioC_mirror"https://mirrors.tuna.tsinghua.edu.cn/bioconductor") if(!require("BiocManager")) install.packages("BiocManager") if(!require("TC…...

JLSX 模版指令导出Excel
1. 官方相关链接 官网:https://jxls.sourceforge.net/reference/if_command.html JxlsAPI: https://jxls.sourceforge.net/javadoc/jxls/index.html Jxls POI: https://jxls.sourceforge.net/javadoc/jxls/index.html Jxls JExcel࿱…...

【制作npm包3】了解 tsconfig.json 相关配置
制作npm包目录 本文是系列文章, 作者一个橙子pro,本系列文章大纲如下。转载或者商业修改必须注明文章出处 一、申请npm账号、个人包和组织包区别 二、了解 package.json 相关配置 三、 了解 tsconfig.json 相关配置 四、 api-extractor 学习 五、npm包…...
【0基础入门Python笔记】一、python 之基础语法、基础数据类型、复合数据类型及基本操作
一、python 之基础语法、基础数据类型、复合数据类型及基本操作 基础语法规则基础数据类型数字类型(Numbers)字符串类型(String)布尔类型(Boolean) 复合数据类型List(列表)Tuple&…...

2023-08-18力扣每日一题
链接: 1388. 3n 块披萨 题意: 一个长度3n的环,选n次数字,每次选完以后相邻的数字会消失,求选取结果最大值 解: 这波是~~(ctrl)CV工程师了~~ 核心思想是选取n个不相邻的元素一定…...

mac M1安装opencv方法及类型报错解决
安装opencv: pip install opencv-python pip install --user opencv-contrib-python pip install opencv-python 4.5.2.54 numpy 1.25.2 安装过程中报错如下: python-类型错误:“numpy._DTypeMeta”对象不可下标 TypeError: ‘numpy._DTypeMeta’ obje…...

Screen终端管理工具
文章目录 Screen终端管理工具背景nohup介绍screen介绍安装screen查看终端新建终端退出终端进入终端删除会话帮助命令 总结 Screen终端管理工具 背景 对大佬只有膜拜,可能永远无法超越,在工作交接中大佬用到了一个screen启动了程序,这是什么…...

【python自动化办公】PysimpleGUI官网案例全部项目代码文件及运行截图
PysimpleGUI官网案例全部项目代码文件及运行截图 0 项目文件整体预览窗口1 pysimpleGUI下面所有元素2 pysimpleGUI下面所有元素示例3 加载多GIF图片4 使用PIL进行动态图片加载5 自动保存关闭时窗口位置信息6 绘制柱状图7 图像编码18 图像编码29 无边界窗口10 设置图片按钮11 按…...

9.处理this和防抖、节流
9.1 this指向-普通函数 普通函数的调用方式决定了this的值,即【谁调用this的值 指向谁】 普通函数没有明确调用者时this值为window,严格模式下没有调用者时this的值为undefined 9.2 this指向-箭头函数 箭头函数中的this与普通函数完全不同࿰…...

Spark操作Hive表幂等性探索
前言 旁边的实习生一边敲着键盘一边很不开心的说:做数据开发真麻烦,数据bug排查太繁琐了,我今天数据跑的有问题,等我处理完问题重新跑了代码,发现报表的数据很多重复,准备全部删了重新跑。 我:你的数据操作具备幂等性吗? 实习生:啥是幂等性?数仓中的表还要考虑幂等…...
【可变形卷积3】 DCNv2 安装
使用RTM3D 代码,CenterTrack代码需要用DCN 1、安装DCNv2 (1)github上最新版的DCNv2源码在"https://github.com/CharlesShang/DCNv2",但是该版本源码不支持PyTorch1.7,如果使其支持PyTorch1.7需要做以下修改…...
归并排序 与 计数排序
目录 1.归并排序 1.1 递归实现归并排序: 1.2 非递归实现归并排序 1.3 归并排序的特性总结: 1.4 外部排序 2.计数排序 2.1 操作步骤: 2.2 计数排序的特性总结: 3. 7种常见比较排序比较 1.归并排序 基本思想: 归并排序(MERGE-SORT)是建立在归并操作上的一种…...

机器学习之逻辑回归
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression # 获得数据 names[Sample code number,Clump Thickness,Uniformity…...

操作符详解上(非常详细)
目录 二进制介绍二进制2进制转10进制10进制转2进制数字2进制转8进制和16进制2进制转8进制2进制转16进制 原码、反码、补码移位操作符左移操作符右移操作符 位操作符:&、|、^逗号表达式 二进制介绍 在初学计算机时我们常常会听到2进制、8进制、10进制、16进制……...

React 高阶组件(HOC)
React 高阶组件(HOC) 高阶组件不是 React API 的一部分,而是一种用来复用组件逻辑而衍生出来的一种技术。 什么是高阶组件 高阶组件就是一个函数,且该函数接受一个组件作为参数,并返回一个新的组件。基本上,这是从 React 的组成…...
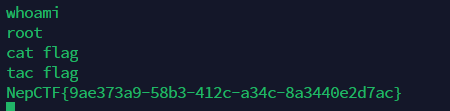
【NepCTF2023】复现
文章目录 【NepCTF2023】复现MISC与AI共舞的哈夫曼codesc语言获取环境变量 小叮弹钢琴陌生的语言你也喜欢三月七么Ez_BASIC_IImisc参考 WEBez_java_checkinPost Crad For You独步天下配置环境独步天下-镜花水月环境变量提权 独步天下-破除虚妄总结 独步天下-破除试炼_加冕成王知…...

大文件切片上传
创建组件:创建一个组件用于处理文件上传,命名为Upload.vue。 <template><div><input type"file" change"handleFileChange" /><button click"startUpload">开始上传</button></div> …...
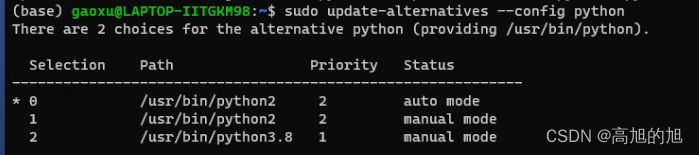
ubuntu切换python版本
在没有安装类似anoconda的管理工具的时候,我们常常会被Ubuntu下的Python版本切换问题所头疼。 可以使用update-alternatives工具进行python版本的任意切换 当使用update-alternatives工具来切换Ubuntu系统上的Python版本时,您实际上是在系统范围内选择…...

用Circuit JS在线模拟器,5分钟搞定欧姆定律和LRC振荡电路实验
用Circuit JS在线模拟器,5分钟搞定欧姆定律和LRC振荡电路实验 在电子工程和物理教学中,理论公式与实验验证的结合一直是提升学习效率的关键。传统实验室受限于设备、场地和时间,而Circuit JS这款基于浏览器的开源电路模拟器,恰好填…...

别再只用DS18B20了!用51单片机和ADC0804做个PT100温度计,从硬件接线到代码调试全流程
从DS18B20到PT100:用51单片机打造工业级温度监测系统 在嵌入式开发领域,温度测量是一个永恒的话题。当大多数初学者还停留在使用DS18B20这类数字温度传感器时,工业领域早已广泛采用PT100铂电阻作为温度测量的主力军。本文将带你跨越数字传感器…...

利用模型广场为你的智能客服场景挑选合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用模型广场为你的智能客服场景挑选合适模型 智能客服是当前许多应用接入大模型的核心场景之一。开发者需要根据业务对响应速度、…...

dropin-minimal-css项目架构深度解析:目录结构与核心组件
dropin-minimal-css项目架构深度解析:目录结构与核心组件 【免费下载链接】dropin-minimal-css Drop-in switcher for previewing minimal CSS frameworks 项目地址: https://gitcode.com/gh_mirrors/dr/dropin-minimal-css dropin-minimal-css是一个用于预览…...

基于红外传感器与CircuitPython的互动声光糖果碗制作指南
1. 项目概述:一个会“尖叫”的互动糖果碗又到了捣鼓点有趣玩意儿的时候了。作为一个喜欢在万圣节搞点小惊喜的创客,我总觉得光是发糖有点平淡。能不能让糖果碗自己“活”过来,在孩子们伸手时,用灯光和声音制造一点既有趣又不会太过…...

从特征稀缺到精准定位:基于HS-FPN与可变形注意力的白细胞检测新范式
1. 白细胞检测的现状与挑战 在医学影像分析领域,白细胞检测一直是个让人头疼的问题。想象一下,医生需要从密密麻麻的血细胞图像中找出白细胞,就像在沙滩上找特定形状的贝壳一样困难。传统方法主要依赖医生手动操作显微镜,不仅效率…...

别只盯着密码爆破:身份认证漏洞的3个“非主流”攻击面与防御思考
身份认证安全的隐秘战场:超越密码爆破的三大高阶攻防实践 在网络安全领域,身份认证机制如同数字世界的门锁系统。当大多数安全从业者将注意力集中在传统的密码爆破防御时,攻击者早已将目光转向那些被忽视的认证薄弱环节。本文将深入剖析三个常…...

【NS-3实战指南】NetAnim可视化调试与网络拓扑分析
1. NetAnim入门:从安装到第一个动画 第一次接触NS-3仿真的人往往会被命令行输出的数字搞得头晕眼花。记得我刚开始做无线网络仿真时,盯着终端里不断跳动的数据包统计数字,完全想象不出节点之间到底是怎么通信的。直到发现了NetAnim这个神器&a…...

5 分钟快速上手 hoist-non-react-statics:提升组件静态属性的完整教程
5 分钟快速上手 hoist-non-react-statics:提升组件静态属性的完整教程 【免费下载链接】hoist-non-react-statics Copies non-react specific statics from a child component to a parent component 项目地址: https://gitcode.com/gh_mirrors/ho/hoist-non-reac…...
)
避坑指南:Tina Linux下MIPI DSI与LVDS屏调试的那些‘坑’(以V853/D1s为例)
Tina Linux下MIPI DSI与LVDS屏调试实战避坑指南(V853/D1s开发板为例) 1. 高速差分接口调试的"死亡陷阱" 当V853开发板首次连接那块7英寸MIPI屏时,我遭遇了职业生涯最诡异的显示故障——屏幕上半部正常显示,下半部却呈现…...