Transformer 相关模型的参数量计算
如何计算Transformer 相关模型的参数量呢?
先回忆一下Transformer模型论文《Attention is all your need》中的两个图。

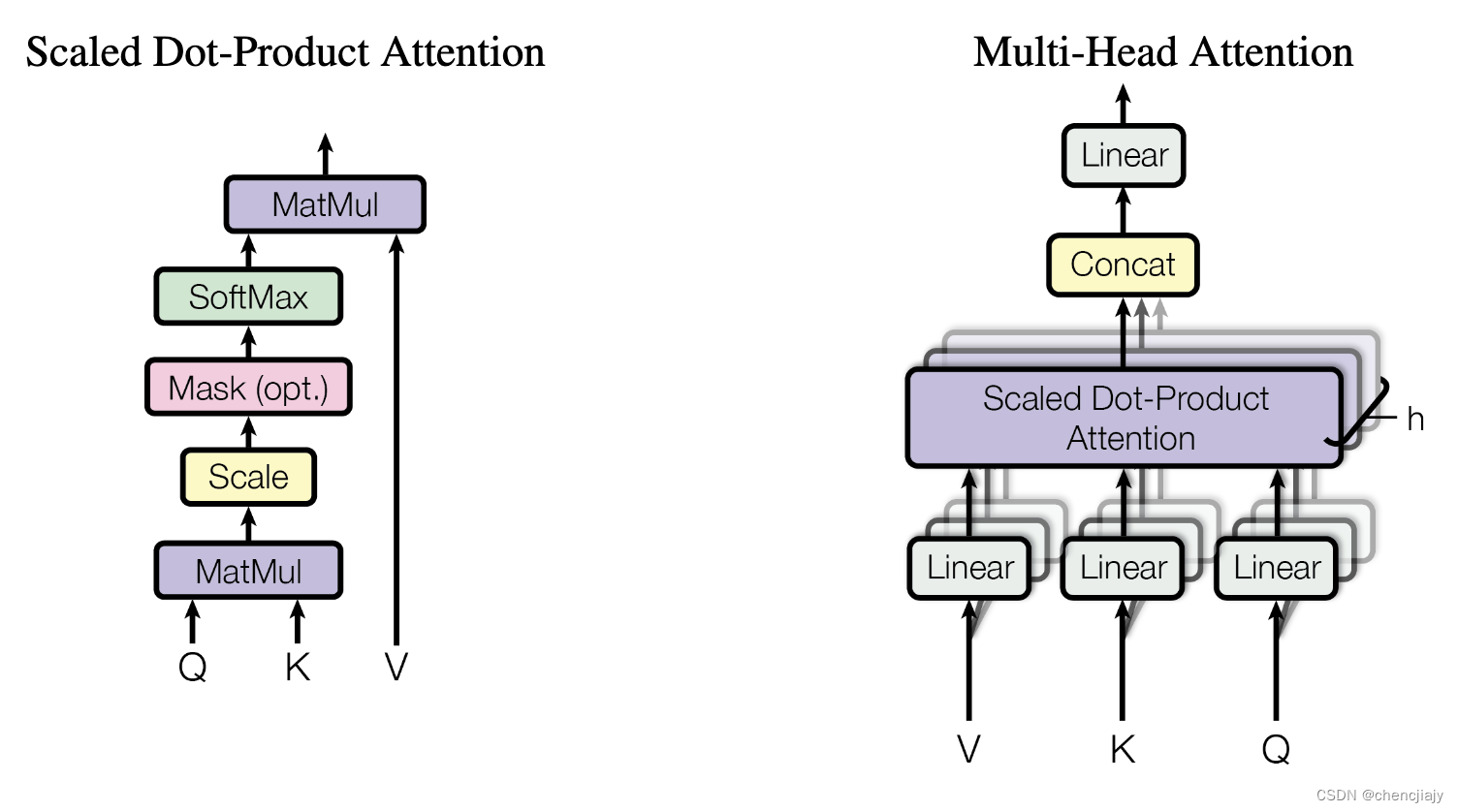
设Transformer模型的层数为N,每个Transformer层主要由self-attention 和 Feed Forward组成。设self-attention模块的head个数为 n h e a d n_{head} nhead,每一个head对应的维度为 d h e a d d_{head} dhead,self-attention输出维度为 d m o d e l = n heads ⋅ d head d_{model}= n_\text{heads}\cdot d_\text{head} dmodel=nheads⋅dhead。我们可以得到一个Transformer层的参数量为 12 d m o d e l 2 + 13 d m o d e l 12 d_{model}^2 + 13 d_{model} 12dmodel2+13dmodel,具体如下:
-
self-attention块的模型参数有Q、K、V的权重矩阵 W Q 、 W K 、 W V W_Q、W_K 、W_V WQ、WK、WV和偏置,输出矩阵 W O W_O WO及其偏置。这4个权重矩阵的大小为 [ d m o d e l , d m o d e l ] [d_{model}, d_{model}] [dmodel,dmodel],4个偏置的大小为 [ d m o d e l ] [d_{model}] [dmodel],所以self-attention块的参数量为 4 d m o d e l 2 + 4 d m o d e l 4 d_{model}^2 + 4 d_{model} 4dmodel2+4dmodel。
-
Feed Forward块一般由2个线性层组成,第一个线性层将维度从 d m o d e l d_{model} dmodel 映射成 4 d m o d e l 4d_{model} 4dmodel, 其权重矩阵 W 1 W_1 W1的大小为 [ d m o d e l , 4 d m o d e l ] [d_{model}, 4d_{model}] [dmodel,4dmodel] ,其偏置的大小为 [ 4 d m o d e l ] [4d_{model}] [4dmodel]。 第二个线性层将维度从 4 d m o d e l 4d_{model} 4dmodel 映射成 d m o d e l d_{model} dmodel,其权重矩阵 W 2 W_2 W2的大小为 [ 4 d m o d e l , d m o d e l ] [4d_{model}, d_{model}] [4dmodel,dmodel] ,其偏置的大小为 [ d m o d e l ] [d_{model}] [dmodel]。所以Feed Forward的参数量为 8 d m o d e l 2 + 5 d m o d e l 8 d_{model}^2 + 5 d_{model} 8dmodel2+5dmodel。
-
self-attention 和 Feed Forward都跟随着layer normalization,它有两个可训练模型参数,形状都是 [ d m o d e l ] [d_{model}] [dmodel]。所以2个layer normalization的参数量为 4 d m o d e l 4 d_{model} 4dmodel。
除了Transformer层之外的参数有:
- 词embedding矩阵的参数量,embedding的维度通常等于 d m o d e l d_{model} dmodel,设词表的大小为V,则词embedding的参数量为 V d m o d e l Vd_{model} Vdmodel。
- 位置向量相关,有些位置向量表示方式需要学习参数。
所以N层Transformer模型的可训练模型参数量为 N ( 12 d m o d e l 2 + 13 d m o d e l ) + V d m o d e l N(12 d_{model}^2 + 13 d_{model}) + Vd_{model} N(12dmodel2+13dmodel)+Vdmodel。当 d m o d e l d_{model} dmodel较大时,可以忽略一次项,模型参数量近似为 12 N d m o d e l 2 12 N d_{model}^2 12Ndmodel2。
最后试验一下模型参数估计量与论文是否对的上,下表是GPT3和LLaMA的计算对比,可以发现数量级是可以对的上的,因为我们忽略了一次项,所以具体数据与论文不一致。
| 模型名 | 实际参数量 | n l a y e r n_{layer} nlayer | d m o d e l d_{model} dmodel | n h e a d n_{head} nhead | d h e a d d_{head} dhead | 估计参数量 |
|---|---|---|---|---|---|---|
| GPT-3 | 175B | 96 | 12288 | 96 | 128 | 173946175488 |
| LLaMA 6.7B | 6.7B | 32 | 4096 | 32 | 128 | 6442450944 |
| LLaMA 13.0B | 13.0B | 40 | 5120 | 40 | 128 | 12582912000 |
| LLaMA 32.5B | 32.5B | 60 | 6656 | 52 | 128 | 31897681920 |
| LLaMA 65.2B | 65.2B | 80 | 8192 | 64 | 128 | 64424509440 |
参考资料
-
Transformer 论文(模型图来自论文)、GPT3的论文等
-
整理过程中参考的blog: 1. 知乎用户回旋托马斯x 的文章,除了计算量外,还算了计算量、中间激活等 , 2 transformer 参数量计算, 3 flops 计算, 4 transformers 参数量计算公式
-
transfomers 库如何得到参数量
相关文章:
Transformer 相关模型的参数量计算
如何计算Transformer 相关模型的参数量呢? 先回忆一下Transformer模型论文《Attention is all your need》中的两个图。 设Transformer模型的层数为N,每个Transformer层主要由self-attention 和 Feed Forward组成。设self-attention模块的head个数为 …...
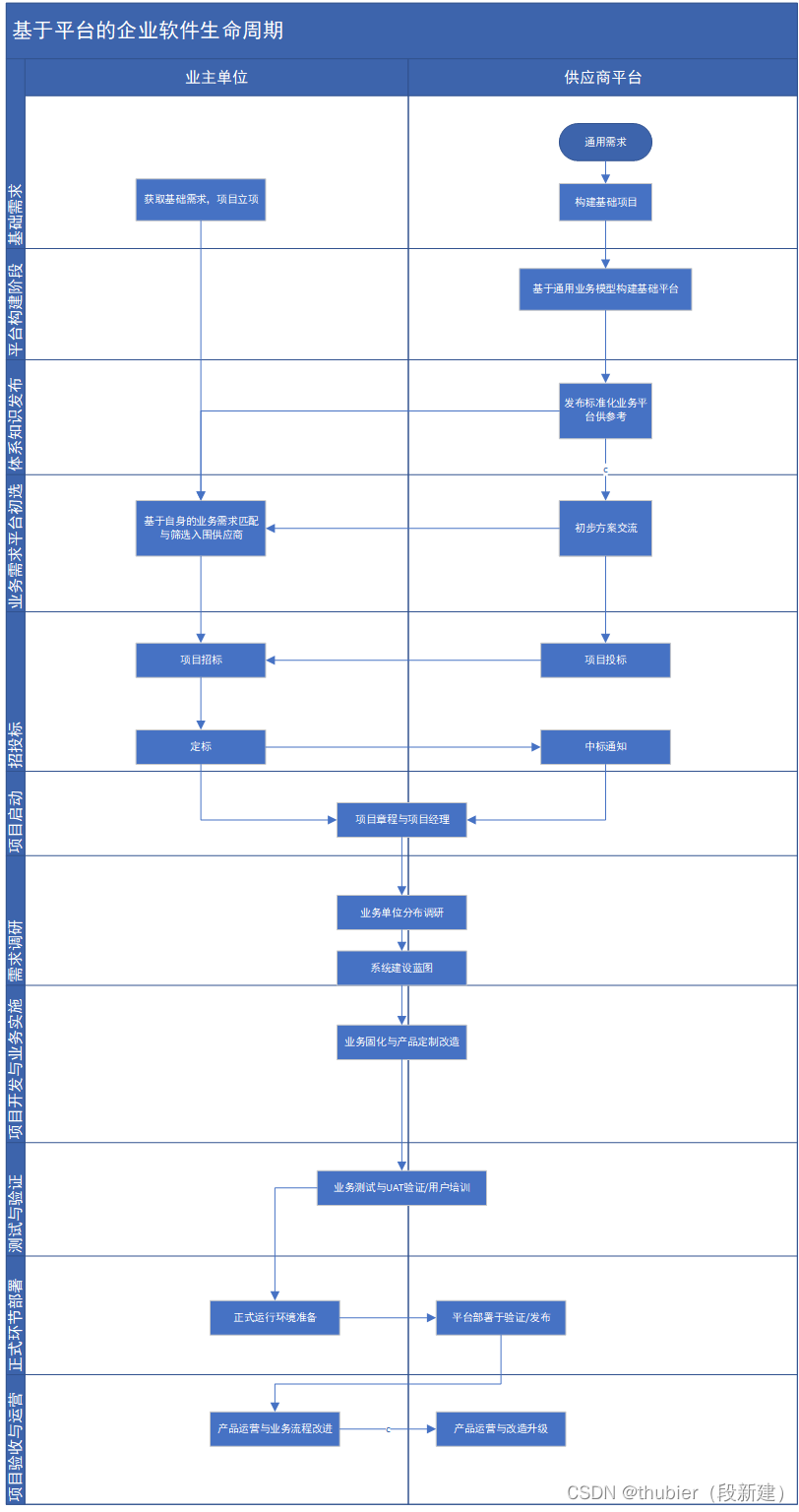
企业信息化过程----应用管理平台的构建过程
1.信息化的概念 信息化是一个过程,与工业化、现代化一样,是一个动态变化的过程。信息化已现代通信,网络、数据库技术为基础,将所有研究对象各个要素汇总至数据库,供特定人群生活、工作、学习、辅助决策等,…...

揭秘程序员的鄙视链,你在哪一层?看完我想哭
虽然不同的编程语言都有其优缺点,而且程序员之间的技能和能力更加重要,但是有些程序员可能会因为使用不同的编程语言而产生鄙视链。 以下是一些可能存在的不同编程语言程序员之间的鄙视链: 低级语言程序员鄙视高级语言程序员:使用…...

在docker下进行mysql的主从复制
搭建步骤 1、拉取镜像 docker pull mysql:latest2、查看镜像 docker images3、创建启动容器 Master docker run -p 3306:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD123456 -d mysql:latestSlave docker run -p 3307:3306 --name mysql-slave -e MYSQL_ROOT_PASSWO…...
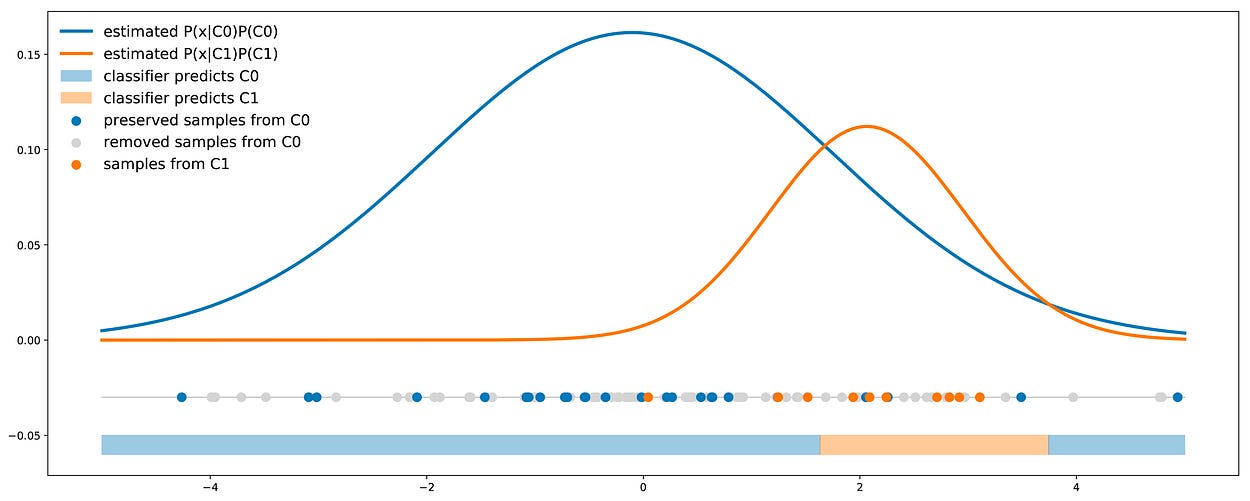
【机器学习】处理不平衡的数据集
一、介绍 假设您在一家给定的公司工作,并要求您创建一个模型,该模型根据您可以使用的各种测量来预测产品是否有缺陷。您决定使用自己喜欢的分类器,根据数据对其进行训练,瞧:您将获得96.2%的准确率! …...
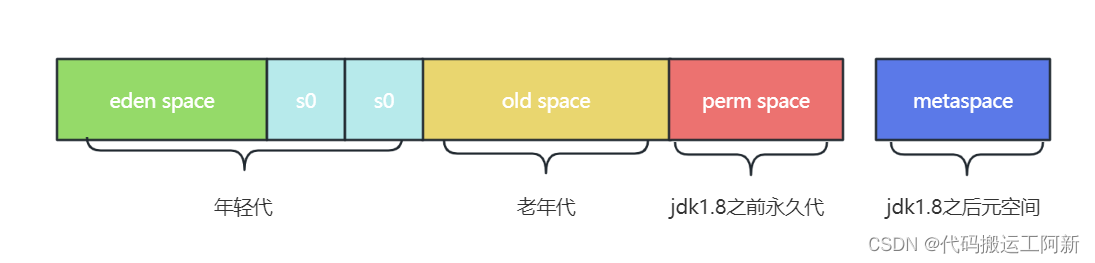
JVM前世今生之JVM内存模型
JVM内存模型所指的是JVM运行时区域,该区域分为两大块 线程共享区域 堆内存、方法区,即所有线程都能访问该区域,随着虚拟机和GC创建和销毁 线程独占区域 虚拟机栈、本地方法栈、程序计数器,即每个线程都有自己独立的区域&#…...

redis事务对比Lua脚本区别是什么
redis官方对于lua脚本的解释:Redis使用同一个Lua解释器来执行所有命令,同时,Redis保证以一种原子性的方式来执行脚本:当lua脚本在执行的时候,不会有其他脚本和命令同时执行,这种语义类似于 MULTI/EXEC。从别…...

Java“牵手”根据店铺ID获取1688店铺所有商品数据方法,1688API实现批量店铺商品数据抓取示例
1688商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取1688整店所有商品详情页面评价内容数据,您可以通过开放平台的接口或者直接访问1688商城的网页来获取店铺所有商品详情信息的数据。以下是两…...

linux-shell脚本收集
创建同步脚本xsync mkdir -p /home/hadoop/bin && cd /home/hadoop/bin vim xsync#!/bin/bash#1. 判断参数个数 if [ $# -lt 1 ] thenecho Not Arguementexit; fi#2. 遍历集群所有机器 for host in node1 node2 node3 doecho $host #3. 遍历所有目录,挨…...

使用 MBean 和 日志查看 Tomcat 线程池核心属性数据
文章目录 CustomTomcatThreadPoolMBeanCustomTomcatThreadPool CustomTomcatThreadPoolMBean com.qww.config;public interface CustomTomcatThreadPoolMBean {String getStatus(); }CustomTomcatThreadPool package com.qww.config;import com.alibaba.fastjson.JSON; impor…...
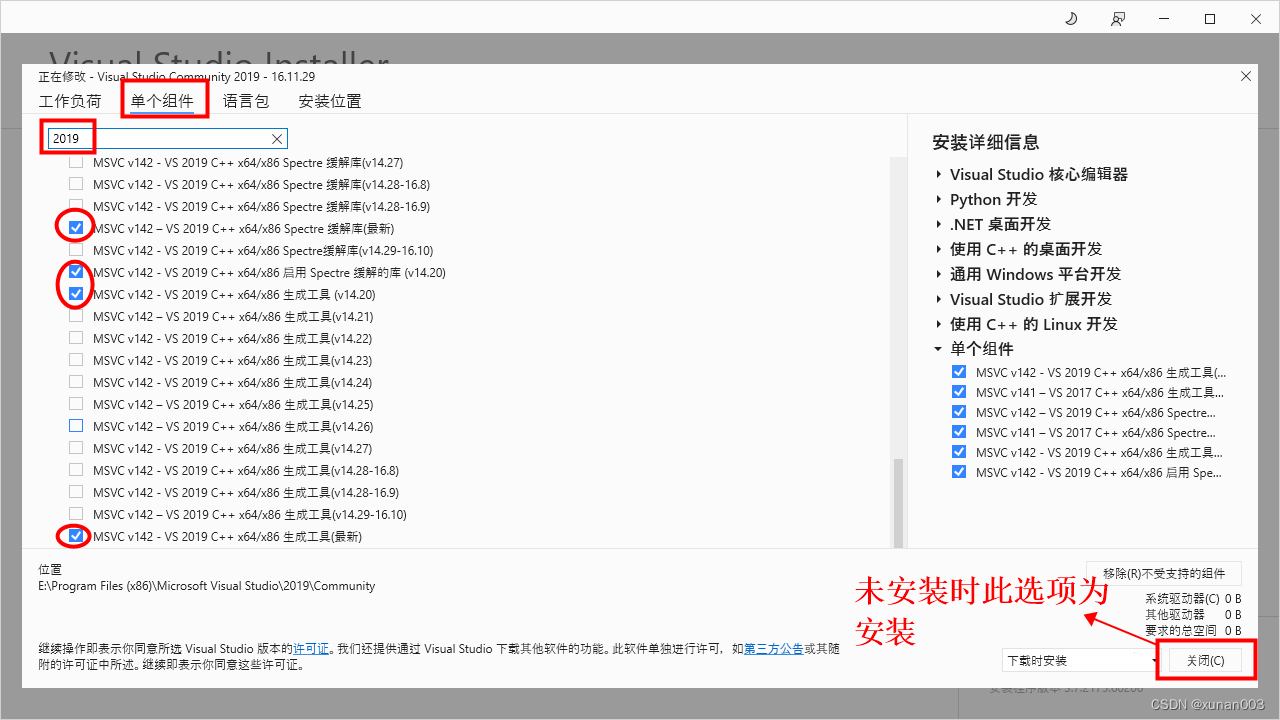
Visual Studio 2019源码编译cpu版本onnxruntime
1.下载onnxruntime源码 源码地址:gitee 》https://gitee.com/mirrors/onnx-runtime github 》https://github.com/microsoft/onnxruntime git clone --recursive https://gitee.com/mirrors/onnx-runtime 2.安装anaconda并配置python环境 安装anaconda时记得勾选默…...

Go和Java实现模板模式
Go和Java实现模板模式 下面通过一个游戏的例子来说明模板模式的使用。 1、模板模式 在模板模式中,一个抽象类公开定义了执行它的方法的方式/模板。它的子类可以按需要重写方法实现,但调用将 以抽象类中定义的方式进行。这种类型的设计模式属于行为型…...

angular:quill align的坑
上一行设置了align为center,换行后下一个会继承上一行的格式,我想使用Quill.formatLine(newLineIndex, 0, ‘align’, left)来左对齐,发现始终不能生效。 参看quill.js源码,发现align没有left的配置 var config {scope: _parch…...
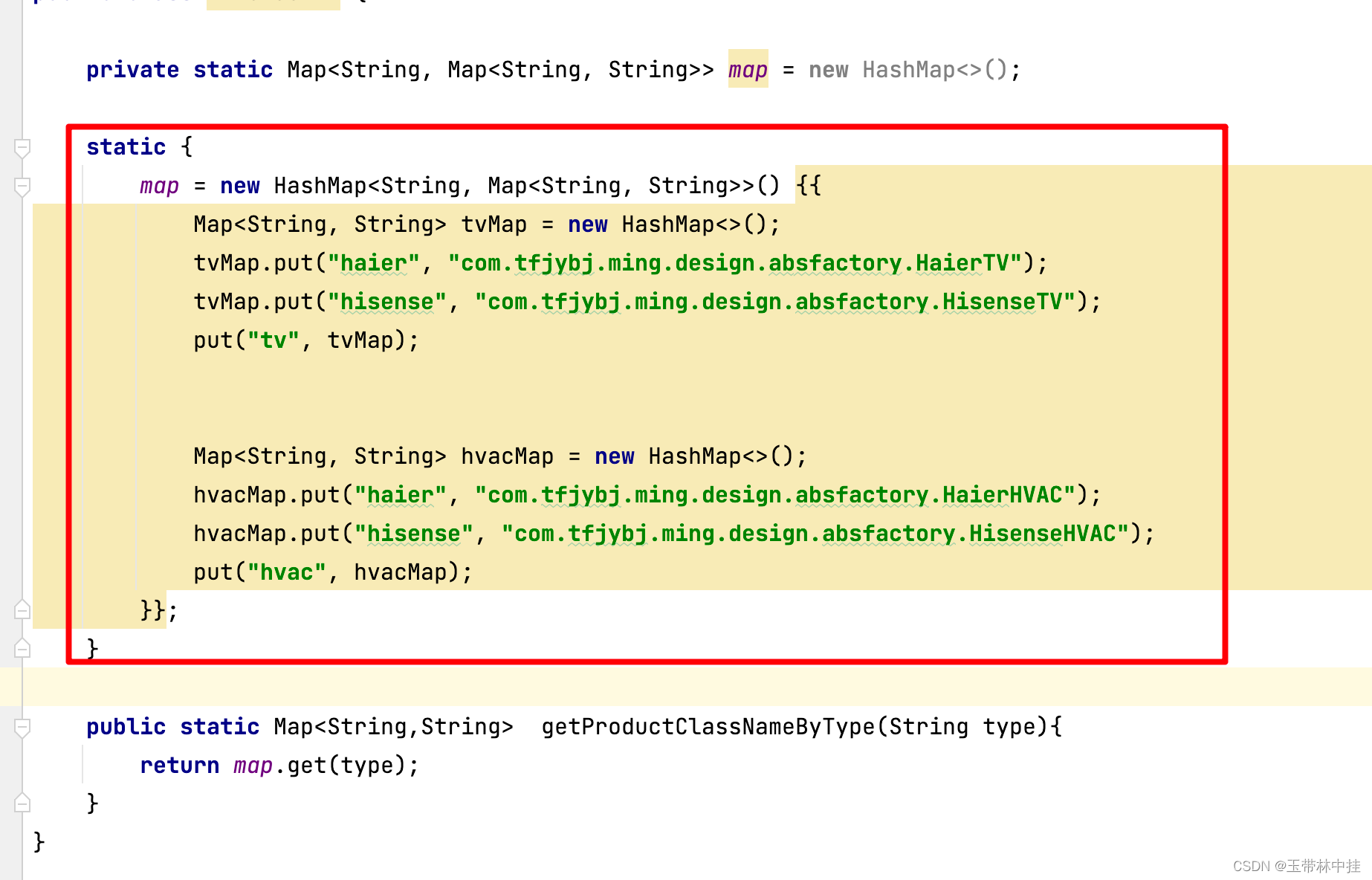
设计模式篇---抽象工厂(包含优化)
文章目录 概念结构实例优化 概念 抽象工厂:提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。 工厂方法是有一个类型的产品,也就是只有一个产品的抽象类或接口,而抽象工厂相对于工厂方法来说,是有…...
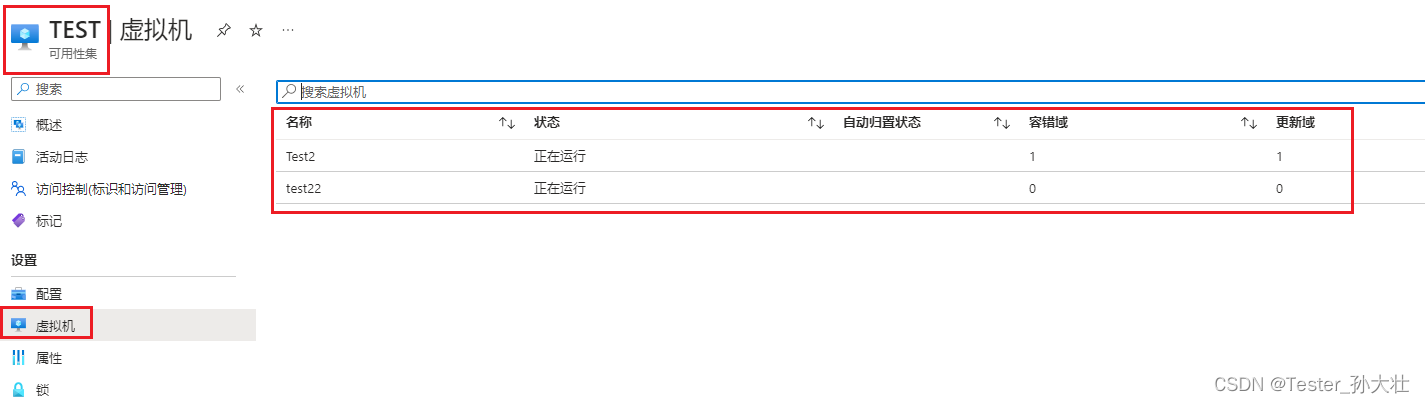
Azure创建可用性集
什么是可用性集 在Azure中,可用性集(Availability Set)是一种用于提高虚拟机(VM)可用性和可靠性的功能。它通过将虚拟机分布在不同的物理硬件和故障域中来提供高可用性。每个故障域都是一个独立的电力和网络故障区域&…...

SpringBoot中优雅的实现隐私数据脱敏(提供Gitee源码)
前言:在实际项目开发中,可能会对一些用户的隐私信息进行脱敏操作,传统的方式很多都是用replace方法进行手动替换,这样会由很多冗余的代码并且后续也不好维护,本期就讲解一下如何在SpringBoot中优雅的通过序列化的方式去…...

Elasticsearch集群shard过多后导致的性能问题分析
1.问题现象 上午上班以后发现ES日志集群状态不正确,集群频繁地重新发起选主操作。对外不能正常提供数据查询服务,相关日志数据入库也产生较大延时 2.问题原因 相关日志 查看ES集群日志如下: 00:00:51开始集群各个节点与当时的master节点…...
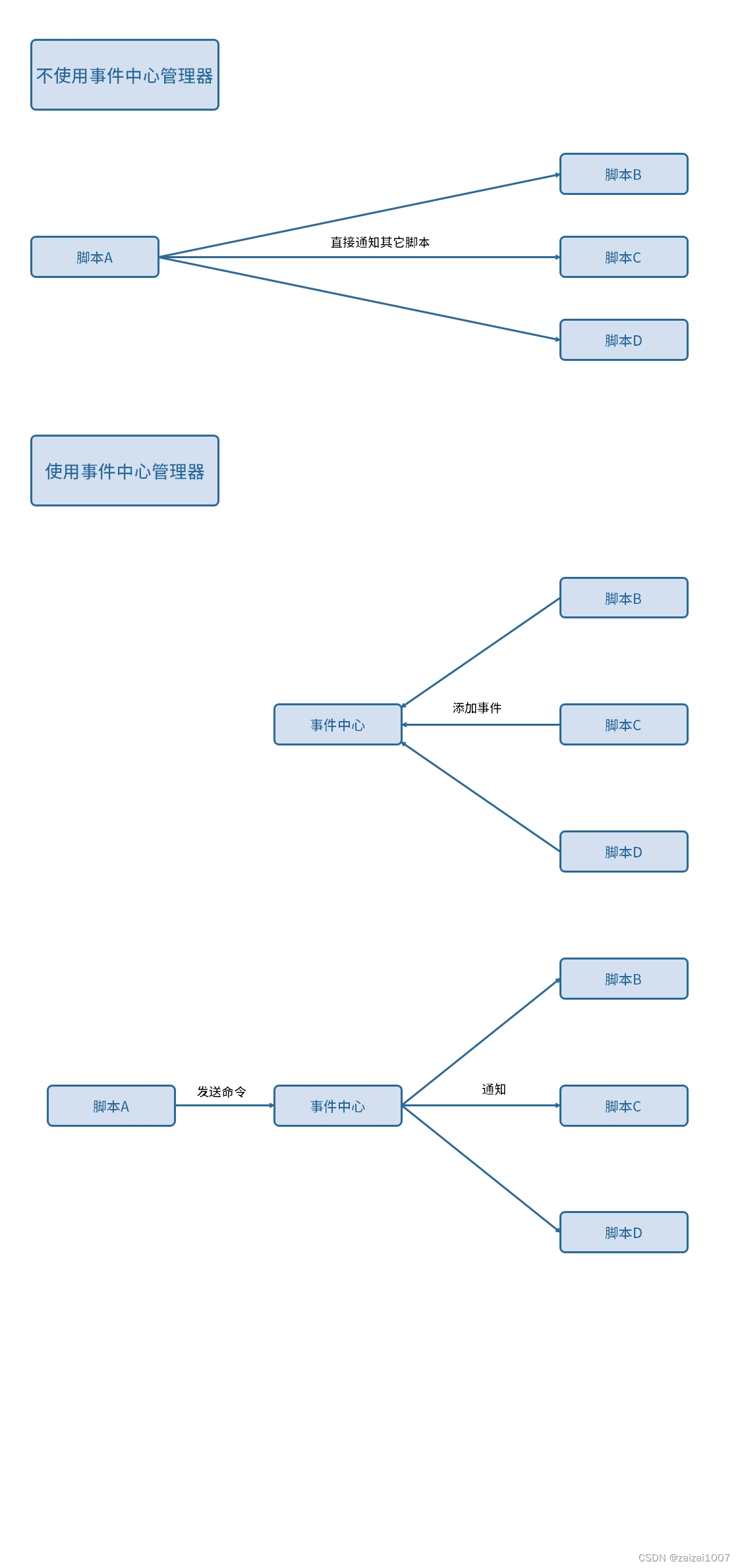
Unity框架学习--5 事件中心管理器
作用:访问其它脚本时,不直接访问,而是通过发送一条“命令”,让监听了这条“命令”的脚本自动执行对应的逻辑。 原理: 1、让脚本向事件中心添加事件,监听对应的“命令”。 2、发送“命令”,事件…...
结构型模式:3、过滤器模式(Filter、Criteria Pattern)(C++示例))
(二)结构型模式:3、过滤器模式(Filter、Criteria Pattern)(C++示例)
目录 1、过滤器模式(Filter、Criteria Pattern)含义 2、过滤器模式应用场景 3、过滤器模式主要几个关键角色 4、C实现过滤器模式的示例 1、过滤器模式(Filter、Criteria Pattern)含义 (1)过滤器模式是…...
谷歌在Chrome浏览器中推进抗量子加密技术
近日,Chromium博客上发表的一篇博文称,为了加强网络安全,应对迫在眉睫的量子计算机威胁,谷歌各个团队密切合作,为网络向抗量子密码学的过渡做好准备。 谷歌的Chrome团队在博客中写道,该项目涉及修订技术标准…...
)
ssm高校学生综合测评管理系统(10029)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

从0到4倍:一次产品冷启动的完整复盘
近期终于有了大块的时间,打算把自己做开发者关系的一些经历都梳理出来。背景:我们做了一个类似 Windows 注册表的配置管理模块,并在上面增加了配置叠加和分层权限管控。它的核心价值是这样的:之前之后系统集成团队想改某个应用的行…...

ARM ETMv4跟踪寄存器架构与调试实践
1. ARM ETMv4 跟踪寄存器架构概述ARM嵌入式跟踪宏单元(ETM)是处理器调试架构中的关键组件,ETMv4作为其第四代架构,提供了更强大的指令和数据跟踪能力。与传统的断点调试不同,ETM采用实时跟踪技术,能够在不中断处理器运行的情况下&…...

S7-1500 PLC做高速数据采集?一个32位微秒时间戳的完整实现与避坑指南
S7-1500 PLC微秒级时间戳工程实践:从硬件同步到数据拼接的完整方案 在工业自动化领域,毫秒级响应已是基础要求,而微秒级精度正成为高端装备的标配。当一台数控机床以8000转/分钟的速度运行时,每个刀具接触工件的瞬间都需被精确记录…...

从零到生产:构建百万并发分布式 IM 系统的架构全解
从零到生产:构建百万并发分布式 IM 系统的架构全解 如何设计一套真正能落地的分布式即时通讯系统?本文不只讨论“能跑起来”的 Demo,而是从连接接入、消息路由、存储模型、一致性语义、群聊扇出、限流熔断、可观测性、容灾与工程化交付等维度,完整拆解一套可支撑百万长连接…...

循证研发怎么做?五阶段路径S、A、B、C分级,2026团标给出量化答案
2026年,在博鳌健康食品科学大会暨博览会上,一项由仙乐健康WelMax联合中国保健协会食物营养与安全专业委员会、拜耳、赫力昂等机构共同制定的团体标准正式亮相。该标准编号为T/CS 283-2026,全称为《营养健康产品循证研发技术规范》,…...

植物大战僵尸杂交版手机版最新版v3.16.1安卓2026最新下载分享
作为长期沉迷植物大战僵尸改版的老玩家,我近期完整体验了杂交版全新V3.16版本,从植物、关卡到平台适配,逐一实测验证。 整体来说,这是一次诚意满满的更新——既有新鲜玩法创新,又兼顾不同玩家需求。 下载链接&#x…...

COMSOL声学建模实战:从无源特征频率到有源辐射边界
1. COMSOL声学建模基础:从理论到实践 声学建模在工程领域应用广泛,无论是建筑声学设计、噪声控制还是音频设备开发,都需要对声波传播特性有深入理解。COMSOL Multiphysics作为一款强大的多物理场仿真软件,提供了完整的声学建模解决…...

Taotoken 的用量看板如何帮助个人开发者清晰掌握月度支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的用量看板如何帮助个人开发者清晰掌握月度支出 对于个人开发者或独立工作室而言,在项目开发与迭代过程中&am…...

tcpdive性能评估报告:CPU占用率与QPS影响分析终极指南
tcpdive性能评估报告:CPU占用率与QPS影响分析终极指南 【免费下载链接】tcpdive A TCP performance profiling tool. 项目地址: https://gitcode.com/gh_mirrors/tc/tcpdive tcpdive作为一款专业的TCP性能分析工具,在生产环境中的性能表现至关重要…...