大数据课程K2——Spark的RDD弹性分布式数据集
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 了解Spark的RDD结构;
⚪ 掌握Spark的RDD操作方法;
⚪ 掌握Spark的RDD常用变换方法、常用执行方法;
一、Spark最核心的数据结构——RDD弹性分布式数据集
1. 概述
初学Spark时,把RDD看做是一个集合类型(类似于Array或List),用于存储数据和操作数据,但RDD和普通集合的区别:
1. RDD有分区机制,可以分布式,并行的处理同一个RDD数据集,从而极大提高处理效率。分区数量由程序员自己定。
2. RDD由容错机制。即数据丢失后,可以进行恢复。
2. 创建RDD方法
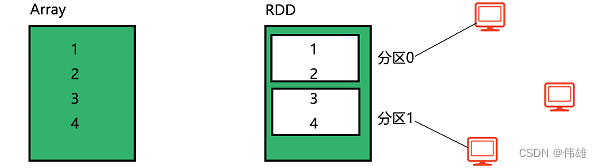
RDD就是带有分区的集合类型
弹性分布式数据集(RDD),特点是可以并行操作,并且是容错的。有两种方法可以创建RDD:
1. 执行Transform操作(变换操作)。即将一个普通集合(Array或List)转变为一个RDD。
例如:val r1 = sc.parallelize(a1,2)
或 val r1 = sc.makeRDD(List(1,2,3,4),2)
查看分区数量:r1.partitions.size。
查看分区数据:r1.glom.collect。
查看RDD整体数据:r1.collect。
2. 读取外部存储系统的数据集,如HDFS,HBase,或任何与Hadoop有关的数据源。
读取Linux本地文件:val r4 = sc.textFile("file:home/1.txt",2)
读取hds文件:val r5 = sc.textFile("hdfs://hadoop01:9000/1.txt",2)
3. RDD入门示例
案例一:
并行化集合可以通过调用 Spark Context 的并行化方法被创建,这个方法是在驱动程序(Scala-Seq)中的现有集合上的。集合里的参数会被拷贝到可以并行执行的分布式数据集里。如下例子就是如何创建一个包含了 1 到 5 的并行化集合。例如:
val data = Array(1, 2, 3, 4, 5)
val r1 = sc.parallelize(data)
val r2 = sc.parallelize(data,2)
你可以这样理解RDD:它是spark提供的一个特殊集合类。诸如普通的集合类型,如传统的Array:(1,2,3,4,5)是一个整体,但转换成RDD后,我们可以对数据进行Partition(分区)处理,这样做的目的就是为了分布式。
你可以让这个RDD有两个分区,那么有可能是这个形式:RDD(1,2) (3,4)。
这样设计的目的在于:可以进行分布式运算。
注:创建RDD的方式有多种,比如案例一中是基于一个基本的集合类型(Array)转换而来,像parallelize这样的方法还有很多,之后就会学到。此外,我们也可以在读取数据集时就创建RDD。
案例二:
Spark能够从任何基于Hadoop的存储资源,创建分布式数据集。包括本地文件系统、HDFS、Cassandra、HBase、Amazon S3等等。Spark支持TEXT文件格式、SequenceFiles文件格式和其他Hadoop的输入文件格式。
RDD的TEXT文件能够通过SparkContext的方法创建。这个方法获取一个文件的URI路径(可以是本地路径、或者是hdfs://, s3n://等),然后当作一条数据集读取其中内容。例如:
val distFile = sc.textFile("data.txt")
4. 查看RDD
scala>rdd.collect
收集rdd中的数据组成Array返回,此方法将会把分布式存储的rdd中的数据集中到一台机器中组建Array。
在生产环境下一定要慎用这个方法,容易内存溢出。
查看RDD的分区数量:
scala>rdd.partitions.size
查看RDD每个分区的元素:
scala>rdd.glom.collect
此方法会将每个分区的元素以Array形式返回。
5. 分区概念
在下图所示, 一个RDD有item1~item25个数据,共5个分区,分别在3台机器上进行处理。
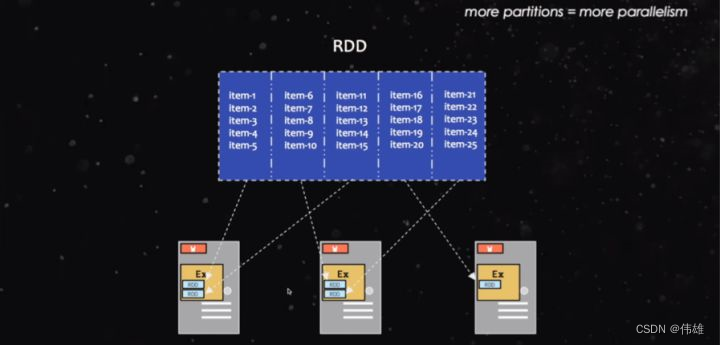
此外,spark并没有原生的提供rdd的分区查看工具我们可以自己来写一个。
案例三:
import org.apache.spark.rdd.RDD
import scala.reflect.ClassTag
object su {
def debug[T: ClassTag](rdd: RDD[T]) = {
rdd.mapPartitionsWithIndex((i: Int, iter: Iterator[T]) => {
val m = scala.collection.mutable.Map[Int, List[T]]()
var list = List[T]()
while (iter.hasNext) {
list = list :+ iter.next
}
m(i) = list
m.iterator
}).collect().foreach((x: Tuple2[Int, List[T]]) => {
val i = x._1
println(s"partition:[$i]")
x._2.foreach { println }
})
}
}
二、RDD的操作
1. 概述
对于RDD的操作,总的来分有三种:
1. Transformation变化操作,特点是都是懒操作,调用后并不是马上执行,比如典型的textFile方法。此外,每当调用一次变化操作(懒操作),就会产生一个新的RDD。
2. Action执行操作,特点是会触发执行。
3. Controller控制操作。
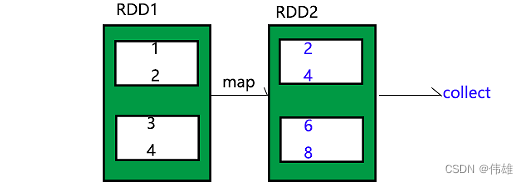
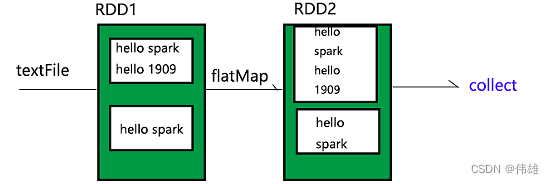
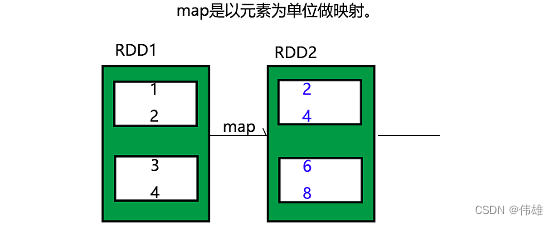
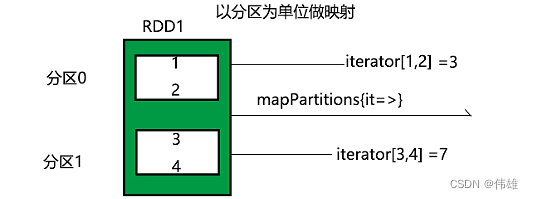
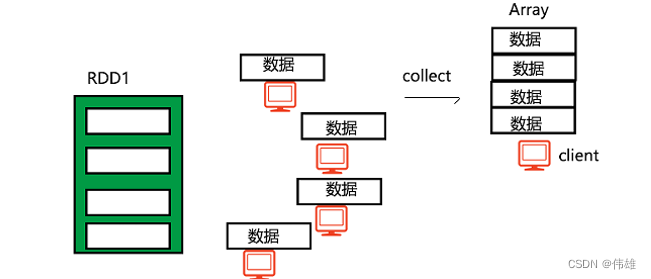
2. 常用的变化方法(懒方法):
| Transformation | Meaning |
| map(func) | Return a new distributed dataset formed by passing each element of the source through a function func. 返回一个新的分布式数据集,通过函数应用于RDD每一个元素,该方法的参数是一个函数。 案例: map 将函数应用到rdd的每个元素中 val rdd = sc.makeRDD(List(1,3,5,7,9) |
相关文章:
大数据课程K2——Spark的RDD弹性分布式数据集
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Spark的RDD结构; ⚪ 掌握Spark的RDD操作方法; ⚪ 掌握Spark的RDD常用变换方法、常用执行方法; 一、Spark最核心的数据结构——RDD弹性分布式数据集 1. 概述 初学Spark时,把RDD看…...
Seaborn数据可视化(一)
目录 1.seaborn简介 2.Seaborn绘图风格设置 21.参数说明: 2.2 示例: 1.seaborn简介 Seaborn是一个用于数据可视化的Python库,它是建立在Matplotlib之上的高级绘图库。Seaborn的目标是使绘图任务变得简单,同时产生美观且具有信…...
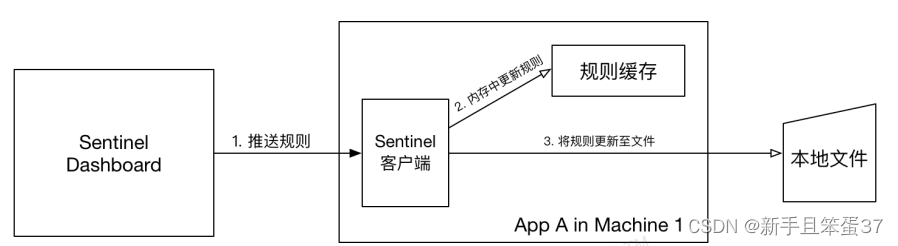
Sentinel规则持久化
首先 Sentinel 控制台通过 API 将规则推送至客户端并更新到内存中,接着注册的写数据源会将新的规则保存到本地的文件中。 示例代码: 1.编写处理类 //规则持久化 public class FilePersistence implements InitFunc {Value("spring.application:n…...
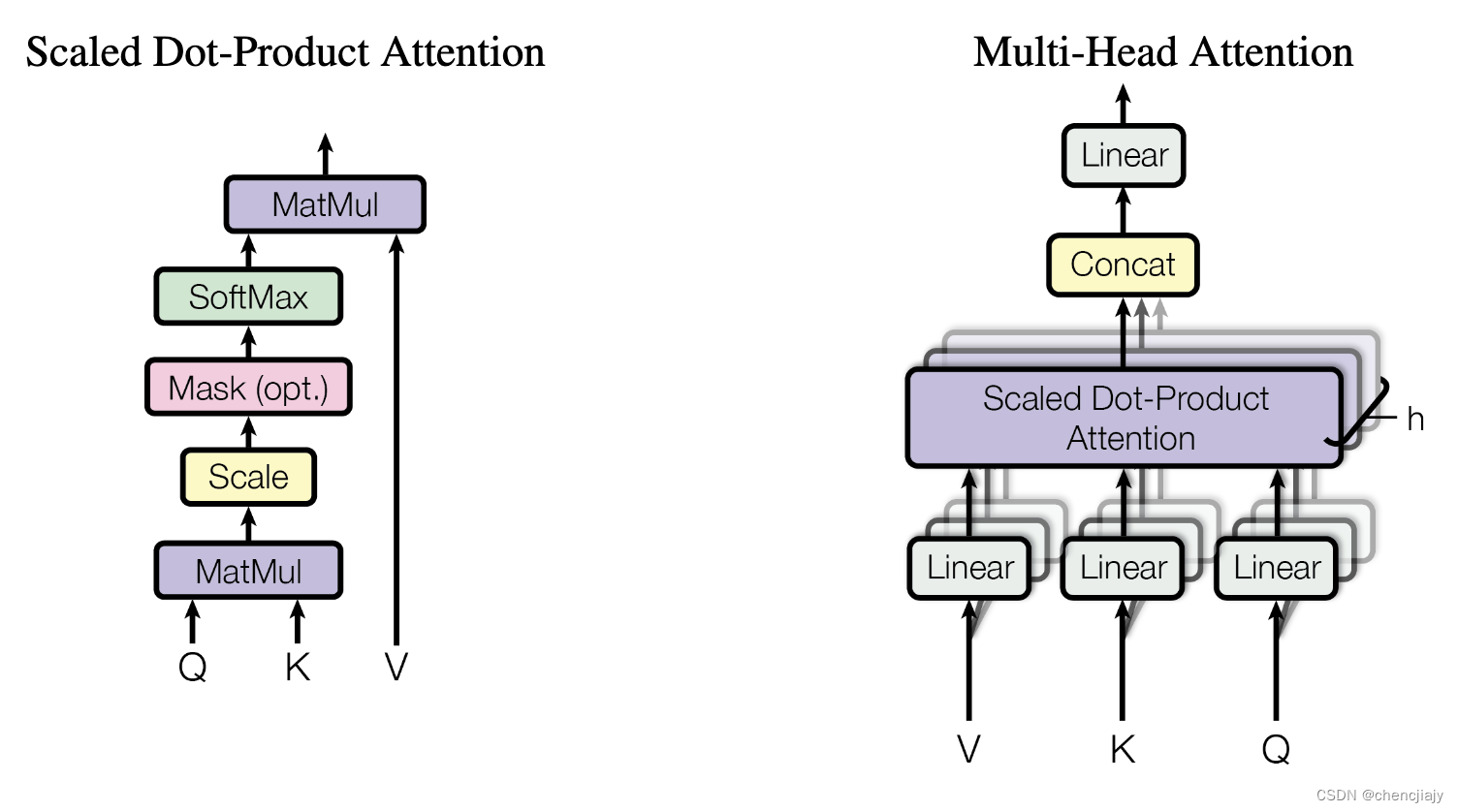
Transformer 相关模型的参数量计算
如何计算Transformer 相关模型的参数量呢? 先回忆一下Transformer模型论文《Attention is all your need》中的两个图。 设Transformer模型的层数为N,每个Transformer层主要由self-attention 和 Feed Forward组成。设self-attention模块的head个数为 …...
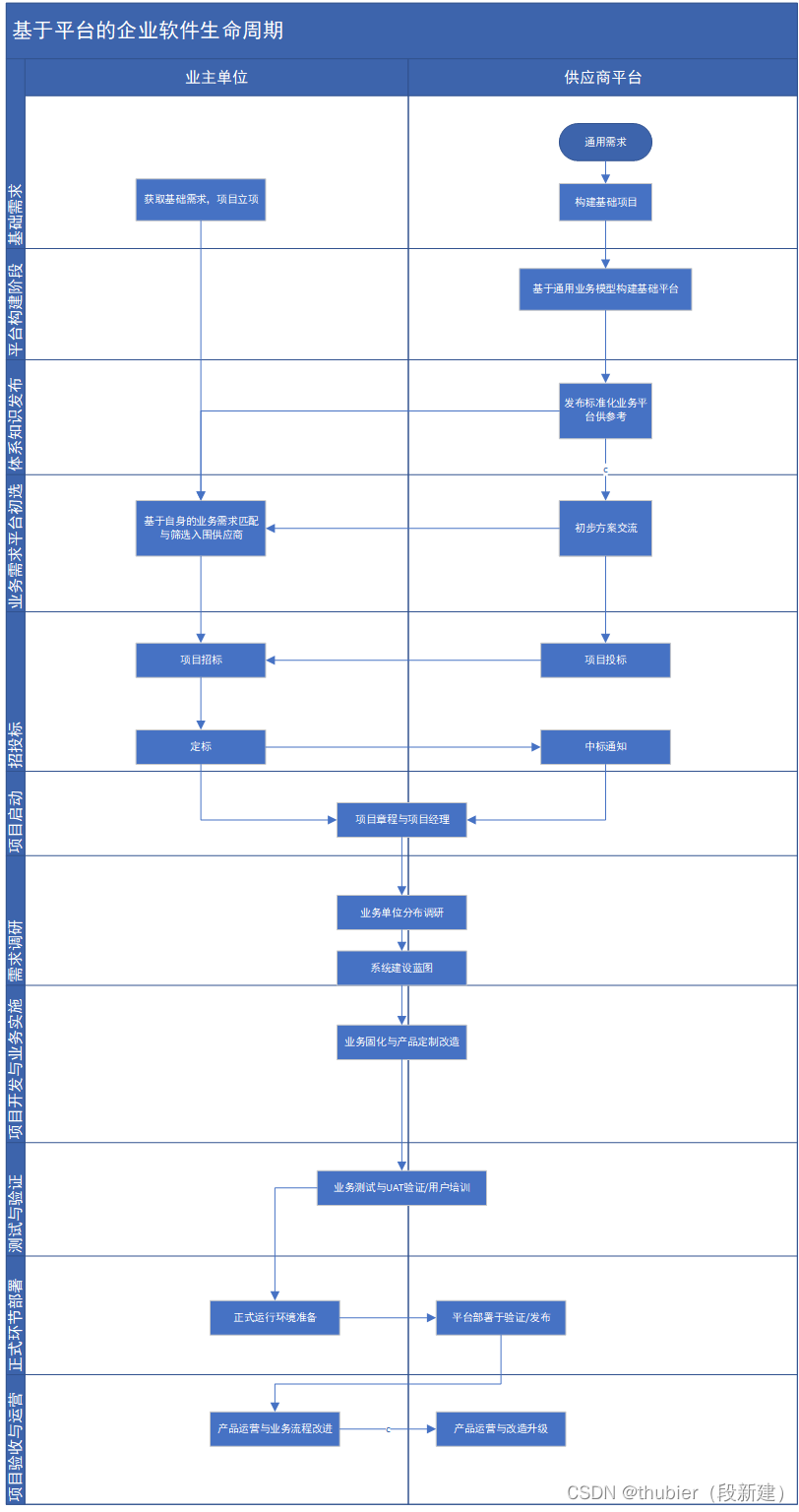
企业信息化过程----应用管理平台的构建过程
1.信息化的概念 信息化是一个过程,与工业化、现代化一样,是一个动态变化的过程。信息化已现代通信,网络、数据库技术为基础,将所有研究对象各个要素汇总至数据库,供特定人群生活、工作、学习、辅助决策等,…...

揭秘程序员的鄙视链,你在哪一层?看完我想哭
虽然不同的编程语言都有其优缺点,而且程序员之间的技能和能力更加重要,但是有些程序员可能会因为使用不同的编程语言而产生鄙视链。 以下是一些可能存在的不同编程语言程序员之间的鄙视链: 低级语言程序员鄙视高级语言程序员:使用…...

在docker下进行mysql的主从复制
搭建步骤 1、拉取镜像 docker pull mysql:latest2、查看镜像 docker images3、创建启动容器 Master docker run -p 3306:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD123456 -d mysql:latestSlave docker run -p 3307:3306 --name mysql-slave -e MYSQL_ROOT_PASSWO…...
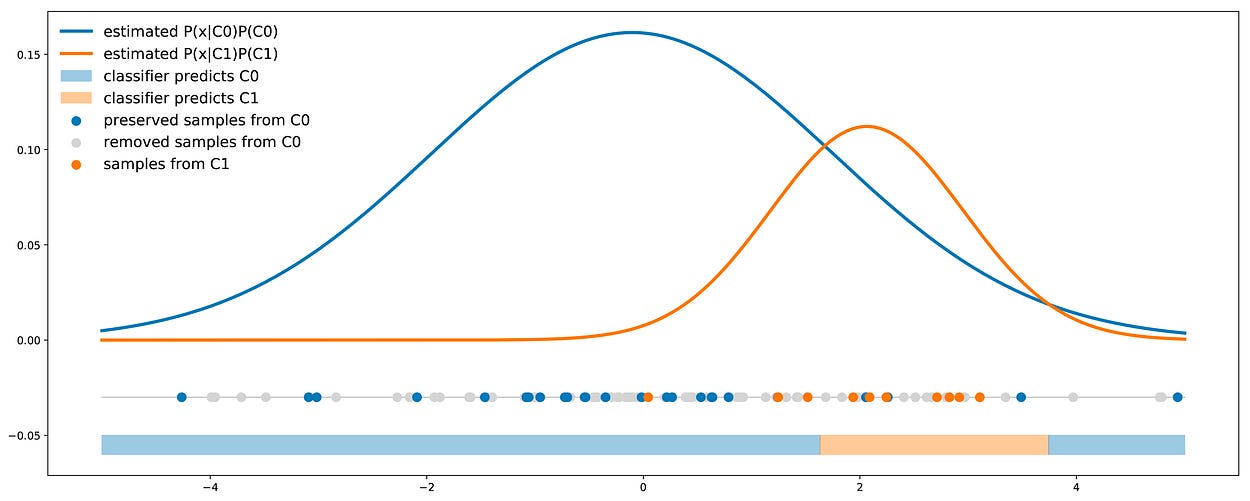
【机器学习】处理不平衡的数据集
一、介绍 假设您在一家给定的公司工作,并要求您创建一个模型,该模型根据您可以使用的各种测量来预测产品是否有缺陷。您决定使用自己喜欢的分类器,根据数据对其进行训练,瞧:您将获得96.2%的准确率! …...
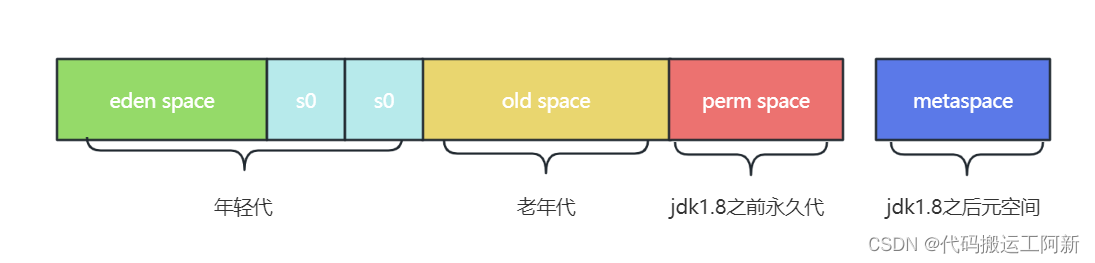
JVM前世今生之JVM内存模型
JVM内存模型所指的是JVM运行时区域,该区域分为两大块 线程共享区域 堆内存、方法区,即所有线程都能访问该区域,随着虚拟机和GC创建和销毁 线程独占区域 虚拟机栈、本地方法栈、程序计数器,即每个线程都有自己独立的区域&#…...

redis事务对比Lua脚本区别是什么
redis官方对于lua脚本的解释:Redis使用同一个Lua解释器来执行所有命令,同时,Redis保证以一种原子性的方式来执行脚本:当lua脚本在执行的时候,不会有其他脚本和命令同时执行,这种语义类似于 MULTI/EXEC。从别…...

Java“牵手”根据店铺ID获取1688店铺所有商品数据方法,1688API实现批量店铺商品数据抓取示例
1688商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取1688整店所有商品详情页面评价内容数据,您可以通过开放平台的接口或者直接访问1688商城的网页来获取店铺所有商品详情信息的数据。以下是两…...

linux-shell脚本收集
创建同步脚本xsync mkdir -p /home/hadoop/bin && cd /home/hadoop/bin vim xsync#!/bin/bash#1. 判断参数个数 if [ $# -lt 1 ] thenecho Not Arguementexit; fi#2. 遍历集群所有机器 for host in node1 node2 node3 doecho $host #3. 遍历所有目录,挨…...

使用 MBean 和 日志查看 Tomcat 线程池核心属性数据
文章目录 CustomTomcatThreadPoolMBeanCustomTomcatThreadPool CustomTomcatThreadPoolMBean com.qww.config;public interface CustomTomcatThreadPoolMBean {String getStatus(); }CustomTomcatThreadPool package com.qww.config;import com.alibaba.fastjson.JSON; impor…...
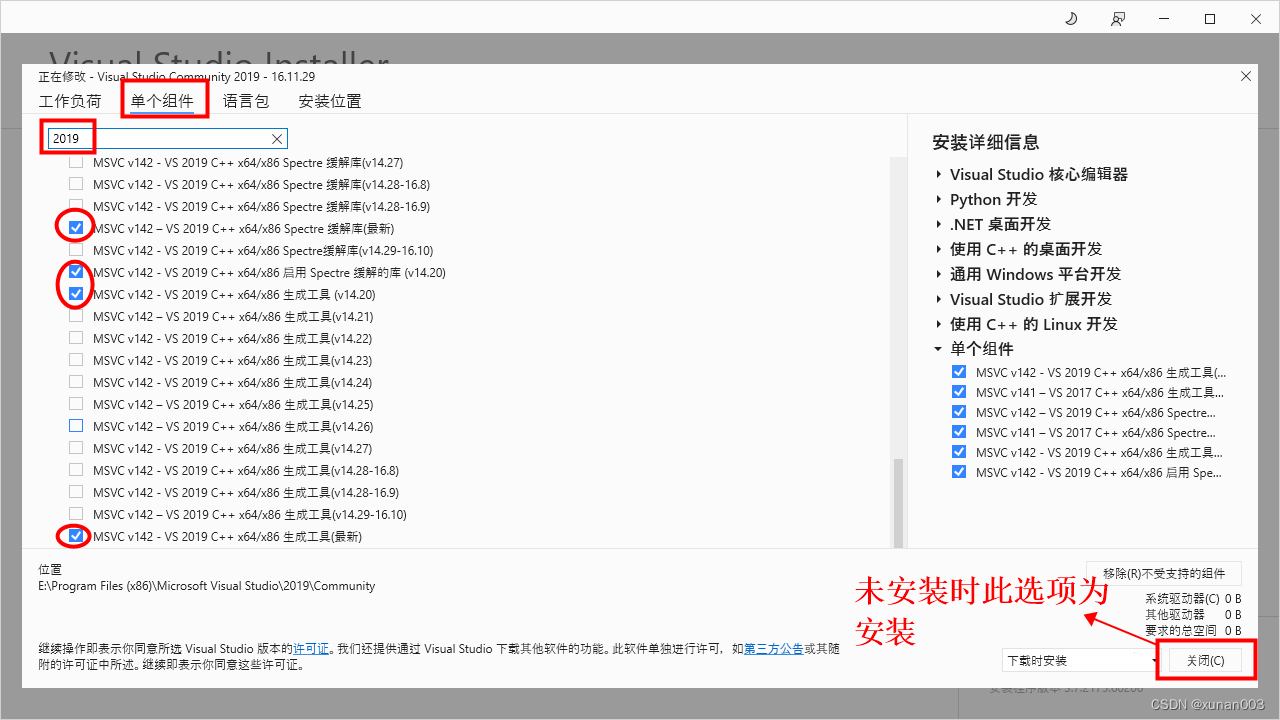
Visual Studio 2019源码编译cpu版本onnxruntime
1.下载onnxruntime源码 源码地址:gitee 》https://gitee.com/mirrors/onnx-runtime github 》https://github.com/microsoft/onnxruntime git clone --recursive https://gitee.com/mirrors/onnx-runtime 2.安装anaconda并配置python环境 安装anaconda时记得勾选默…...

Go和Java实现模板模式
Go和Java实现模板模式 下面通过一个游戏的例子来说明模板模式的使用。 1、模板模式 在模板模式中,一个抽象类公开定义了执行它的方法的方式/模板。它的子类可以按需要重写方法实现,但调用将 以抽象类中定义的方式进行。这种类型的设计模式属于行为型…...

angular:quill align的坑
上一行设置了align为center,换行后下一个会继承上一行的格式,我想使用Quill.formatLine(newLineIndex, 0, ‘align’, left)来左对齐,发现始终不能生效。 参看quill.js源码,发现align没有left的配置 var config {scope: _parch…...
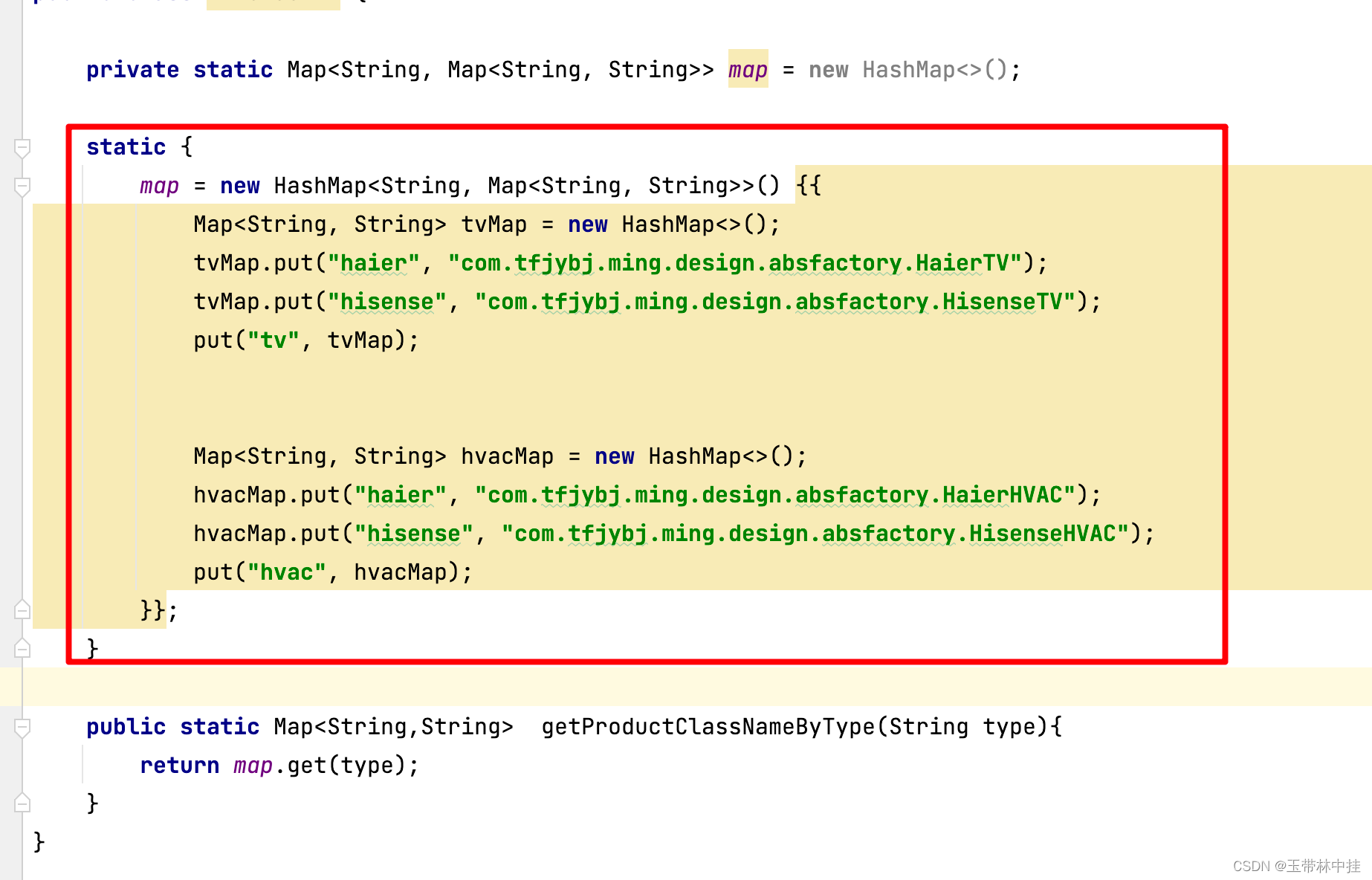
设计模式篇---抽象工厂(包含优化)
文章目录 概念结构实例优化 概念 抽象工厂:提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。 工厂方法是有一个类型的产品,也就是只有一个产品的抽象类或接口,而抽象工厂相对于工厂方法来说,是有…...
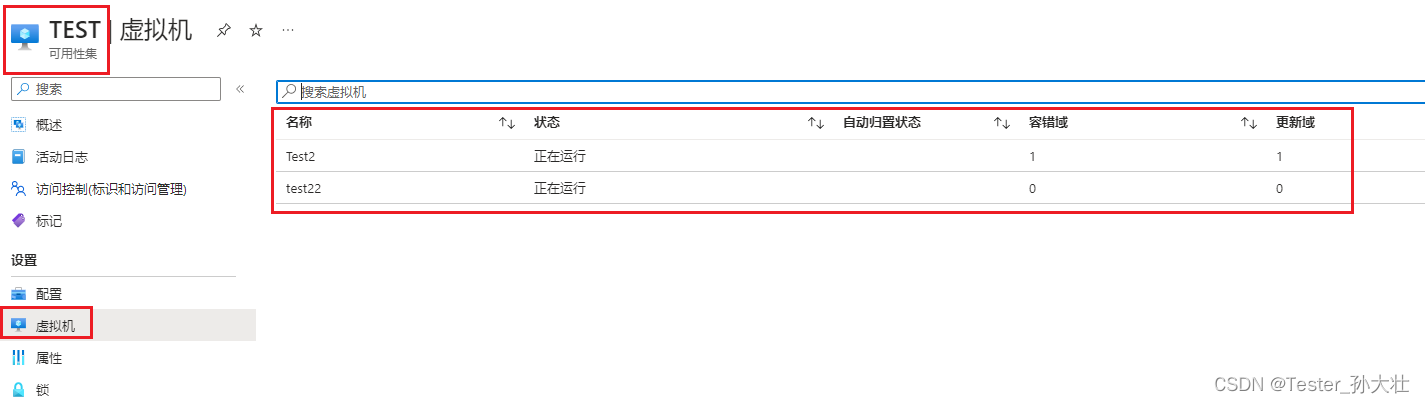
Azure创建可用性集
什么是可用性集 在Azure中,可用性集(Availability Set)是一种用于提高虚拟机(VM)可用性和可靠性的功能。它通过将虚拟机分布在不同的物理硬件和故障域中来提供高可用性。每个故障域都是一个独立的电力和网络故障区域&…...

SpringBoot中优雅的实现隐私数据脱敏(提供Gitee源码)
前言:在实际项目开发中,可能会对一些用户的隐私信息进行脱敏操作,传统的方式很多都是用replace方法进行手动替换,这样会由很多冗余的代码并且后续也不好维护,本期就讲解一下如何在SpringBoot中优雅的通过序列化的方式去…...

Elasticsearch集群shard过多后导致的性能问题分析
1.问题现象 上午上班以后发现ES日志集群状态不正确,集群频繁地重新发起选主操作。对外不能正常提供数据查询服务,相关日志数据入库也产生较大延时 2.问题原因 相关日志 查看ES集群日志如下: 00:00:51开始集群各个节点与当时的master节点…...

不想做程序员了,听说网络安全前景好,现在转行还来得及吗?
不想做程序员了,听说网络安全前景好,现在转行还来得及吗? 我去年四月份被裁员,找了两个月工作,面试寥寥无几,就算有也都是外包,而且外包也没面试通过。我经历了挫败,迷茫࿰…...

使用 Taotoken 后模型 API 响应延迟与稳定性效果实测观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 后模型 API 响应延迟与稳定性效果实测观察 作为一名需要频繁调用大模型 API 的开发者,模型服务的响应速…...

MASA模组汉化包终极指南:3分钟告别Minecraft英文界面困扰
MASA模组汉化包终极指南:3分钟告别Minecraft英文界面困扰 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 你是否曾在Minecraft中使用Litematica、Minihud等MASA模组时&#…...

终极指南:3分钟掌握Mouse Jiggler鼠标模拟器完整使用方法
终极指南:3分钟掌握Mouse Jiggler鼠标模拟器完整使用方法 【免费下载链接】mousejiggler Mouse Jiggler is a very simple piece of software whose sole function is to "fake" mouse input to Windows, and jiggle the mouse pointer back and forth. …...

LightGlue深度解析:自适应神经网络特征匹配架构剖析与性能优化
LightGlue深度解析:自适应神经网络特征匹配架构剖析与性能优化 【免费下载链接】LightGlue LightGlue: Local Feature Matching at Light Speed (ICCV 2023) 项目地址: https://gitcode.com/gh_mirrors/li/LightGlue LightGlue作为ICCV 2023提出的革命性特征…...

Airtable MCP服务器:AI与数据协作的自动化新范式
1. 项目概述:当Airtable遇上MCP,数据协作的自动化新范式 如果你和我一样,日常工作中重度依赖Airtable来管理项目、追踪任务、甚至搭建轻量级的业务系统,那你一定也遇到过这样的痛点:数据是活的,但流程是死…...

命令行控制中心:提升开发效率的聚合与自动化工具
1. 项目概述:一个面向开发者的命令行控制中心最近在GitHub上看到一个挺有意思的项目,叫jendrypto/command-center。光看名字,你可能会联想到科幻电影里那种布满屏幕、控制一切的舰桥。但在开发者的世界里,它其实是一个更接地气、更…...

AMD NPU加速GPT-2微调:边缘AI训练实战解析
1. AMD NPU与客户端AI训练的技术背景在AI模型部署领域,边缘计算正经历着从单纯推理到完整训练工作流的范式转变。传统上,像GPT-2这样的语言模型训练完全依赖云端GPU集群,但这种方式存在数据隐私泄露、网络延迟和持续服务依赖等固有缺陷。AMD …...

DRAM读干扰机制:RowHammer与RowPress的实验研究
1. DRAM读干扰问题概述DRAM(动态随机存取存储器)是现代计算系统中最主要的主存技术,其可靠性和安全性对整个系统的稳定运行至关重要。然而,DRAM存在一个被称为"读干扰"(Read Disturbance)的固有缺…...

Play Integrity API Checker:5分钟快速掌握Android设备安全检测终极指南
Play Integrity API Checker:5分钟快速掌握Android设备安全检测终极指南 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-chec…...