DQL 多表查询
1、多表关系
一对多(多对一)
案例: 部门 与 员工的关系
关系: 一个部门对应多个员工,一个员工对应一个部门
实现: 在从表的一方建立外键,指向主表一方的主键
多对多
案例: 学生 与 课程的关系
关系: 一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现: 建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
一对一
案例: 用户 与 用户详情的关系
关系: 一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率
实现: 在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
2、多表查询简介、笛卡尔积
多表查询就是指从多张表中查询数据。原来查询单表数据,执行的SQL形式为:select * from 表名;那么我们要执行多表查询,就只需要使用逗号分隔多张表即可,如: select * from 表1 , 表2; 在查询时我们看到查询结果中包含了表1所有的记录 与 表2所有记录的所有组合情况,这种现象称之为笛卡尔积。
笛卡尔积: 笛卡尔乘积是指在数学中,两个集合A集合 和 B集合的所有组合情况。
而在多表查询中,我们是需要消除无效的笛卡尔积的,只保留两张表关联部分的数据。
在SQL语句中,如何来去除无效的笛卡尔积呢? 我们可以给多表查询加上连接查询的条件即可。


3、内连接
相当于查询A、B交集部分数据。内连接查询的是两张表交集部分的数据。(也就是绿色部分的数据)

隐式内连接
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;
显示内连接
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ... ;
案例:
A. 查询每一个员工的姓名 , 及关联的部门的名称 (隐式内连接实现)
表结构: emp , dept
连接条件: emp.dept_id = dept.id
select emp.name , dept.name from emp , dept where emp.dept_id = dept.id ;
-- 为每一张表起别名,简化SQL编写
select e.name,d.name from emp e , dept d where e.dept_id = d.id;
B. 查询每一个员工的姓名 , 及关联的部门的名称 (显式内连接实现) — INNER JOIN …ON …
表结构: emp , dept
连接条件: emp.dept_id = dept.id
select e.name, d.name from emp e inner join dept d on e.dept_id = d.id;
-- 为每一张表起别名,简化SQL编写
select e.name, d.name from emp e join dept d on e.dept_id = d.id;
4、外连接
- 左外连接:查询左表所有数据,以及两张表交集部分数据
- 右外连接:查询右表所有数据,以及两张表交集部分数据
左外连接
-- 左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ... ;
右外连接
-- 右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ... ;
案例:
A. 查询emp表的所有数据, 和对应的部门信息。
由于需求中提到,要查询emp的所有数据,所以是不能内连接查询的,需要考虑使用外连接查询。表结构: emp, dept、连接条件: emp.dept_id = dept.id。
select e.*, d.name from emp e left outer join dept d on e.dept_id = d.id;
select e.*, d.name from emp e left join dept d on e.dept_id = d.id;
B. 查询dept表的所有数据, 和对应的员工信息(右外连接)
由于需求中提到,要查询dept表的所有数据,所以是不能内连接查询的,需要考虑使用外连接查询。表结构: emp, dept、连接条件: emp.dept_id = dept.id。
select d.*, e.* from emp e right outer join dept d on e.dept_id = d.id;
select d.*, e.* from dept d left outer join emp e on e.dept_id = d.id;
注意事项:
左外连接和右外连接是可以相互替换的,只需要调整在连接查询时SQL中,表结构的先后顺序就可以了。而我们在日常开发使用时,更偏向于左外连接。
5、自连接
自连接查询,顾名思义,就是自己连接自己,也就是把一张表连接查询多次。我们先来学习一下自连接的查询语法:
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ... ;
案例:
A. 查询员工 及其 所属领导的名字
select a.name , b.name from emp a , emp b where a.managerid = b.id;
B. 查询所有员工 emp 及其领导的名字 emp , 如果员工没有领导, 也需要查询出来
select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid =b.id;
注意事项:
在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底是哪一张表的字段。
6、子查询
SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );
-- 子查询外部的语句可以是INSERT / UPDATE / DELETE / SELECT 的任何一个。
分类:
根据子查询结果不同,分为:
- A. 标量子查询(子查询结果为单个值)
- B. 列子查询(子查询结果为一列)
- C. 行子查询(子查询结果为一行)
- D. 表子查询(子查询结果为多行多列)
根据子查询位置,分为:
- A. WHERE之后
- B. FROM之后
- C. SELECT之后
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符:= <> > >= < <=
案例:
A. 查询 “销售部” 的所有员工信息
①. 查询 “销售部” 部门ID
select id from dept where name = '销售部';
②. 根据 “销售部” 部门ID, 查询员工信息
select * from emp where dept_id = (select id from dept where name = '销售部');
B. 查询在 “方东白” 入职之后的员工信息
①. 查询 方东白 的入职日期
select entrydate from emp where name = '方东白';
②. 查询指定入职日期之后入职的员工信息
select * from emp where entrydate > (select entrydate from emp where name = '方东白');
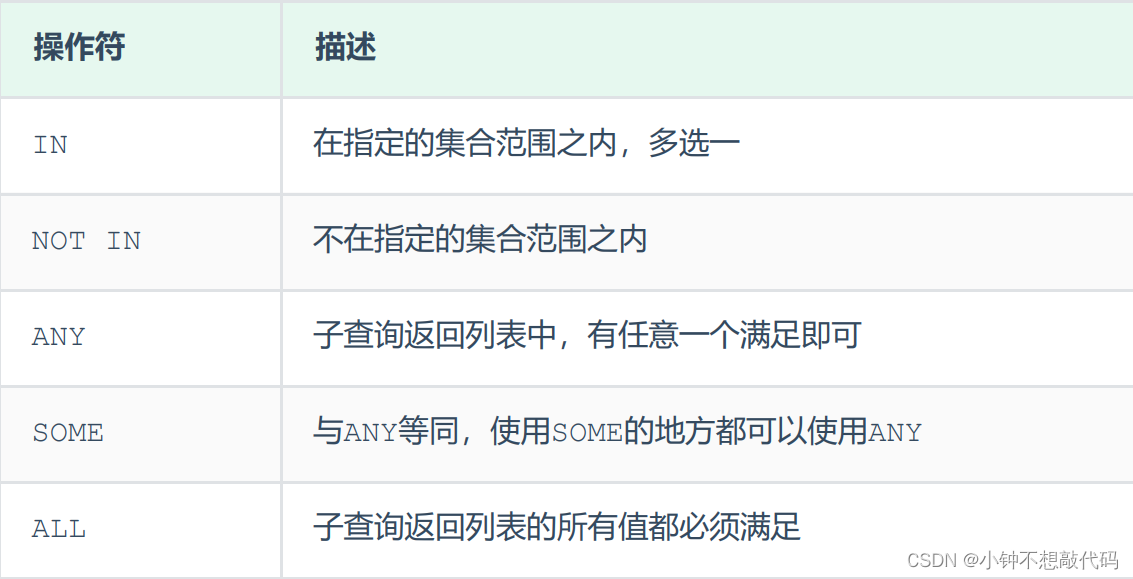
列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
案例:
A. 查询 “销售部” 和 “市场部” 的所有员工信息
①. 查询 “销售部” 和 “市场部” 的部门ID
select id from dept where name = '销售部' or name = '市场部';
②. 根据部门ID, 查询员工信息
select * from emp where dept_id in (select id from dept where name = '销售部' or name = '市场部');
B. 查询比 财务部 所有人工资都高的员工信息
①. 查询所有 财务部 人员工资
select id from dept where name = '财务部';
select salary from emp where dept_id = (select id from dept where name = '财务部');
②. 比 财务部 所有人工资都高的员工信息
select * from emp where salary > all ( select salary from emp where dept_id = (select id from dept where name = '财务部') );
C. 查询比研发部其中任意一人工资高的员工信息
①. 查询研发部所有人工资
select salary from emp where dept_id = (select id from dept where name = '研发部');
②. 比研发部其中任意一人工资高的员工信息
select * from emp where salary > any ( select salary from emp where dept_id = (select id from dept where name = '研发部') );
行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
案例:
A. 查询与 “张无忌” 的薪资及直属领导相同的员工信息 ;
①. 查询 “张无忌” 的薪资及直属领导
select salary, managerid from emp where name = '张无忌';
②. 查询与 “张无忌” 的薪资及直属领导相同的员工信息 ;
select * from emp where (salary,managerid) = (select salary, managerid from emp where name = '张无忌');
表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
案例:
A. 查询与 “鹿杖客” , “宋远桥” 的职位和薪资相同的员工信息
①. 查询 “鹿杖客” , “宋远桥” 的职位和薪资
select job, salary from emp where name = '鹿杖客' or name = '宋远桥';
②. 查询与 “鹿杖客” , “宋远桥” 的职位和薪资相同的员工信息
select * from emp where (job,salary) in ( select job, salary from emp where name = '鹿杖客' or name = '宋远桥' );
B. 查询入职日期是 “2006-01-01” 之后的员工信息 , 及其部门信息
①. 入职日期是 “2006-01-01” 之后的员工信息
select * from emp where entrydate > '2006-01-01';
②. 查询这部分员工, 对应的部门信息;
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ;
案例数据:
-- 创建dept表,并插入数据
create table dept
(id int auto_increment comment 'ID' primary key,name varchar(50) not null comment '部门名称'
) comment '部门表';
INSERT INTO dept (id, name)
VALUES (1, '研发部'),(2, '市场部'),(3, '财务部'),(4, '销售部'),(5, '总经办'),(6, '人事部');-- 创建emp表,并插入数据
create table emp
(id int auto_increment comment 'ID' primary key,name varchar(50) not null comment '姓名',age int comment '年龄',job varchar(20) comment '职位',salary int comment '薪资',entrydate date comment '入职时间',managerid int comment '直属领导ID',dept_id int comment '部门ID'
) comment '员工表';
-- 添加外键
alter table empadd constraint fk_emp_dept_id foreign key (dept_id) referencesdept (id);INSERT INTO emp (id, name, age, job, salary, entrydate, managerid, dept_id)
VALUES (1, '金庸', 66, '总裁', 20000, '2000-01-01', null, 5),(2, '张无忌', 20, '项目经理', 12500, '2005-12-05', 1, 1),(3, '杨逍', 33, '开发', 8400, '2000-11-03', 2, 1),(4, '韦一笑', 48, '开发', 11000, '2002-02-05', 2, 1),(5, '常遇春', 43, '开发', 10500, '2004-09-07', 3, 1),(6, '小昭', 19, '程序员鼓励师', 6600, '2004-10-12', 2, 1),(7, '灭绝', 60, '财务总监', 8500, '2002-09-12', 1, 3),(8, '周芷若', 19, '会计', 48000, '2006-06-02', 7, 3),(9, '丁敏君', 23, '出纳', 5250, '2009-05-13', 7, 3),(10, '赵敏', 20, '市场部总监', 12500, '2004-10-12', 1, 2),(11, '鹿杖客', 56, '职员', 3750, '2006-10-03', 10, 2),(12, '鹤笔翁', 19, '职员', 3750, '2007-05-09', 10, 2),(13, '方东白', 19, '职员', 5500, '2009-02-12', 10, 2),(14, '张三丰', 88, '销售总监', 14000, '2004-10-12', 1, 4),(15, '俞莲舟', 38, '销售', 4600, '2004-10-12', 14, 4),(16, '宋远桥', 40, '销售', 4600, '2004-10-12', 14, 4),(17, '陈友谅', 42, null, 2000, '2011-10-12', 1, null);
相关文章:
DQL 多表查询
1、多表关系 一对多(多对一) 案例: 部门 与 员工的关系 关系: 一个部门对应多个员工,一个员工对应一个部门 实现: 在从表的一方建立外键,指向主表一方的主键 多对多 案例: 学生 与 课程的关系 关系: 一个学生可以选修多门课程&am…...
BUUCTF Reverse xor
题目:BUUCTF Reverse xor 一些犯傻后学到了新东西的记录 查壳,没壳,IDA打开 main函数很好理解,输入一个长度为33的字符串,1-32位与前一位异或后与global相等,则判定flag正确 找global 在strings window直…...

vite和esbuild/roolup的优缺点
esbuild 优点 基于go语言,go是纯机器码不使用 AST,优化了构建流程多线程并行 缺点 esbuild 没有提供 AST 的操作能力。所以一些通过 AST 处理代码的 babel-plugin 没有很好的方法过渡到 esbuild 中(比如babel-plugin-import)。…...

32-Golang中的map
Golang中的map基本介绍基本语法map声明的举例map使用的方式map的增删改查操作map的增加和更新map的删除map的查找map的遍历map切片基本介绍map排序map的使用细节基本介绍 map是key-value数据结构,又称为字段或者关联数组。类似其它编程语言的集合,在编程…...
LeetCode-384-打乱数组
1、列表随机 为了能够初始化数组,我们使用nums保存当前的数组,利用orignal保存初始化数组。为了实现等可能随机打乱,考虑到随机数本质上是基于随机数种子的伪随机,我们采用如下的方式实现等可能随机:我们将所有元素压…...

九龙证券|重大利好!期货公司打新再“解绑”:可直接参与首发网下配售!
时隔近7年,期货公司及其财物办理子公司参加首发证券网下询价和配售事务再次“解绑”。 2月17日,为适应全面实行股票发行注册制变革需求,中国证券业协会(以下简称中证协)发布《初次公开发行证券网下出资者办理规矩》&am…...

信号完整性设计规则之串扰最小化
本文内容从《信号完整性与电源完整性分析》整理而来,加入了自己的理解,如有错误,欢迎批评指正。 1. 对于微带线和带状线,保持相邻信号路径的间距至少为线宽的2倍。 减小串扰的一种方式就是增大线间距,使线间距等于线…...

Windows Ubuntu双系统 设置时间同步方式
文章目录0 前言1 系统时间机制1.1 Windows时间机制1.2 Ubuntu时间机制2 设置Ubuntu的时间机制3 参考0 前言 在安装windows与ubuntu的双系统之后,会发现两个系统的时间不一致,如果使用了Ubuntu之后,再使用windows就会发现时间变早。原因是两个…...

【python】英雄联盟电竞观赛引擎 掉落提示 CapsuleFarmerEvolved 「Webhook」「钉钉」
介绍 本项目链接 Github本项目链接 Gitee本项目链接 最近在github上发现一个可以用来自动帮你挂英雄联盟(除国服)电竞引擎(可以开出头像和表情)的项目,CapsuleFarmerEvolved,github原项目链接简单来说就是本来是通过看比赛获取奖励的,它帮助你进行观看. 对这个活动有兴趣的话…...
加油站会员管理小程序实战开发教程11
我们已经用了10篇的篇幅讲解了首页的功能,首页主要是用来展示信息的。那么接下来就要进入我们的功能页面了,会员管理一个比较重要的功能是充值的功能。 要想实现充值功能,首先需要办一张会员卡,那什么时候办理会员卡呢?需要先注册成为会员,然后进行开卡的动作。这里要注…...

Python量化入门:投资的风险有哪些?
在金融资产中,风险是指获得收益的不确定性,通常以实际收益与期望收益的偏离来表示。 影响资产收益的因素有很多,而且不同资产面对的风险也不尽相同,在详细介绍风险度量之前,我们有必要了解一下风险的来源。 资产风险的来源 1. 市场风险 市场风险就是我们常说的系统…...

AV1编码标准整体概述
本专栏预计将从如下几方面详细介绍AV1 (1)从AV1的发展历史,AV1与MPEG、AVS系列的异同。 (2)AV1标准支持的传统编码工具及引入的机器学习工具 (3)开源的AV1编码器及解码器原理详解 (4)AV1的生态 一、AV1产生背景 2010年,谷歌收购了一家叫On2 Technologies的公司。那时VP8…...

基于springboot+vue的药物咨询平台
基于springbootvue的药物咨询平台 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍&…...

第64章 SQL 主机教程
如果大神想要大神的网站存储数据在database并从database显示数据,大神的 Web server 必须能使用 SQL 语言访问database系统。 如果大神的 Web server 托管在互联网服务提供商(ISP,全称 Internet Service Provider),大…...
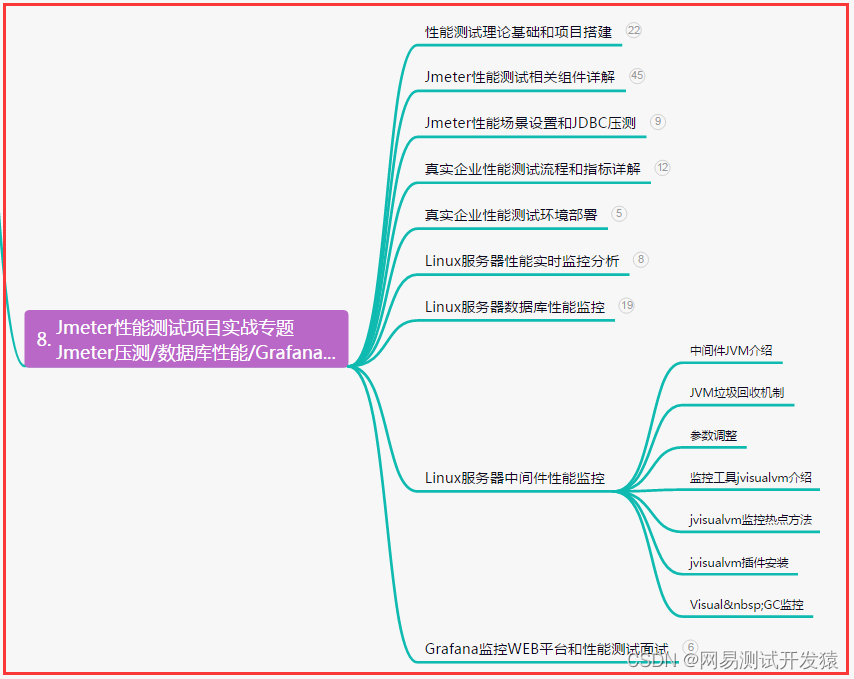
【软件测试】python接口自动化测试编写脚本,资深测试总结方法,你的实用宝典......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 接口测试࿰…...
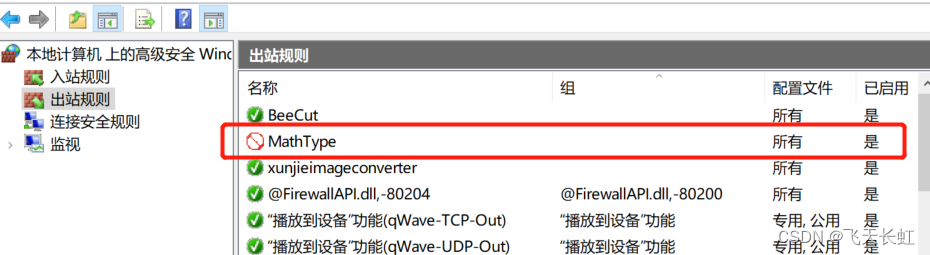
MathType公式编辑器过期(禁止联网)的解决方案
MathType公式编辑器过期(禁止联网)的解决方案 Mathtype公式编辑器无法使用解决方案 MathType联网后显示证书失效,需要重新认证或者购买。或者是MathType成了精简版,只剩两行了。 1. 打开控制面板 方法1 首先大家在电脑中打开W…...
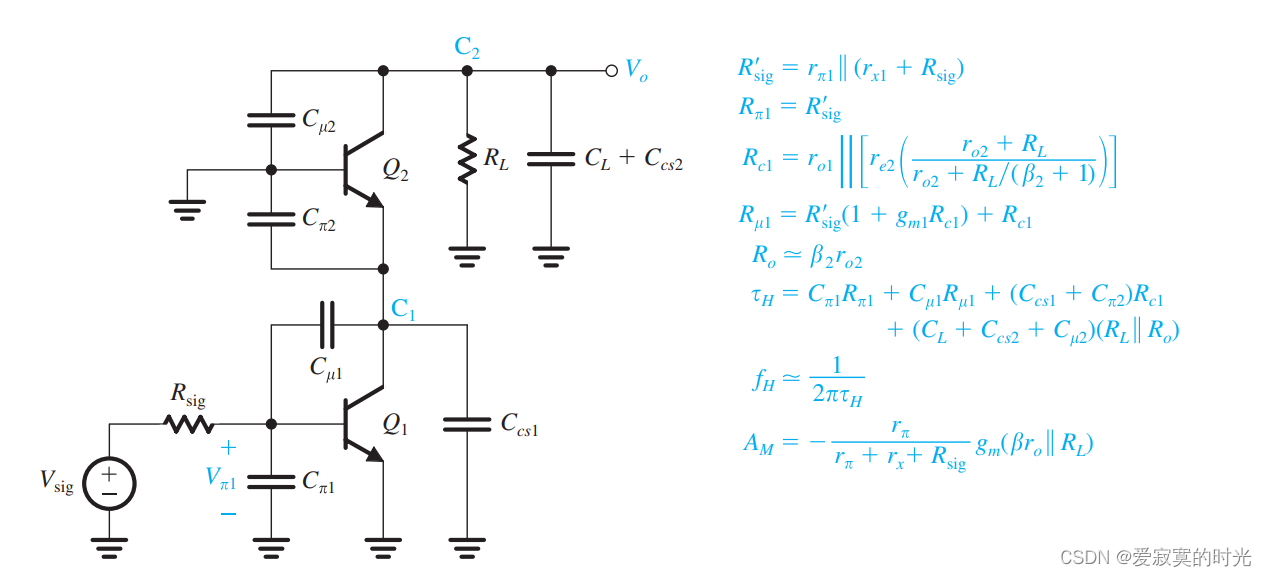
电子技术——共栅和共源共栅放大器的高频响应
电子技术——共栅和共源共栅放大器的高频响应 我们在之前学过无论是是CS放大器还是CE放大器,都可以看做是一个带通(IC低通)滤波器。在高频处的响应收到输入电容 CinC_{in}Cin 的限制(主要是米勒效应)。因此ÿ…...

基于jsplumb构建的流程设计器
项目背景 最近在准备开发工作流引擎相关模块,完成表结构设计后开始着手流程设计器的技术选型,调研了众多开源项目后决定基于jsplumb.js开源库进行自研开发,保证定制化的便捷性,相关效果图及项目地址如下 项目地址:ht…...

解析从Linux零拷贝深入了解Linux-I/O(下)
接上文解析从Linux零拷贝深入了解Linux-I/O(上) 大文件传输场景 零拷贝还是最优选吗 在大文件传输的场景下,零拷贝技术并不是最优选择;因为在零拷贝的任何一种实现中,都会有「DMA 将数据从磁盘拷贝到内核缓存区——P…...

【学习笔记2.19】动态规划、MySQL、Linux、Redis(框架)
动态规划 343整数拆分 class Solution {public int integerBreak(int n) {int dp [] new int [n 1];//dp[i]:正整数i拆分后的最大乘积dp[2] 1;for(int i 2;i < n ;i ){for(int j 1;j < i;j ){dp[i] Math.max(dp[i],Math.max(j * (i - j),j * dp[i - j]));} …...

【花雕学编程】Arduino BLDC 之使用互补滤波进行姿态控制的机器人
从专业工程视角来看,基于Arduino、使用互补滤波进行姿态控制的BLDC(无刷直流电机)机器人,是一个典型的嵌入式实时闭环控制系统。它集成了传感器数据融合、控制算法和电机驱动,广泛应用于对姿态稳定性有要求的场景。 1、…...

AIVideo一站式AI长视频工具与Visual Studio的深度集成开发
AIVideo一站式AI长视频工具与Visual Studio的深度集成开发 1. 引言 作为一名长期使用Visual Studio进行开发的程序员,我经常遇到这样的痛点:想要录制一段代码演示视频,需要反复切换多个软件;想要制作项目介绍视频,得…...

告别手动!用Python+GDAL批量处理GlobeLand30影像:下载、去黑边、镶嵌裁剪全自动
用PythonGDAL打造GlobeLand30全自动处理流水线 遥感影像处理一直是地理信息科学领域的核心工作之一。对于需要处理大范围GlobeLand30数据的科研人员和开发者来说,传统的手动操作不仅效率低下,还容易引入人为错误。想象一下,当你需要处理覆盖整…...

SiameseUIE部署指南:test.py中custom_entities字段详解
SiameseUIE部署指南:test.py中custom_entities字段详解 1. 概述 如果你正在使用SiameseUIE模型进行信息抽取,那么test.py脚本中的custom_entities字段就是你最需要关注的核心配置。这个看似简单的字段,实际上决定了模型如何精准地从文本中抽…...

AIVideo效果对比展示:不同参数下的视频生成质量评测
AIVideo效果对比展示:不同参数下的视频生成质量评测 1. 开场白:参数设置对视频效果的影响 你有没有遇到过这样的情况:用AI生成视频时,明明输入的内容一样,但出来的效果却天差地别?有时候画面模糊不清&…...
)
Isaac Sim 4.1.0 国内网络环境下的三种下载与安装提速方案(含离线包处理)
Isaac Sim 4.1.0 国内网络环境下的高效安装指南 对于国内开发者而言,安装NVIDIA Isaac Sim往往面临下载速度缓慢、连接不稳定等问题。本文将提供三种经过验证的解决方案,帮助您快速完成安装。 1. 直链下载加速方案 通过分析Omniverse Launcher的日志文件…...
)
手把手教你用Simulink和Carsim 2019搭建车辆动力学模型(附二自由度模型源码)
从零构建车辆动力学联合仿真模型:Simulink与Carsim 2019实战指南 当你第一次打开Carsim和Simulink时,面对两个庞大软件的无缝对接需求,很容易陷入"从哪开始"的困惑。本文将带你一步步搭建完整的车辆动力学仿真环境,从软…...

TextGrad部署与性能优化:生产环境最佳实践
TextGrad部署与性能优化:生产环境最佳实践 【免费下载链接】textgrad Automatic Differentiation via Text -- using large language models to backpropagate textual gradients. 项目地址: https://gitcode.com/gh_mirrors/te/textgrad TextGrad是一款基于…...

【限时开源】FastAPI 2.0 AI流式SDK v1.0:内置token计数、流控限速、断点续传、前端SSE自动重连——仅开放首批200个GitHub Star领取资格
第一章:FastAPI 2.0 异步 AI 流式响应的核心演进与架构定位FastAPI 2.0 将原生异步流式响应能力从实验性支持升级为一级公民,彻底重构了 AI 应用服务端的实时交互范式。其核心演进体现在对 StreamingResponse 的深度重写、对 ASGI 3.0 协议的精准适配&am…...

从HTTP到字节流:ESP32与App Inventor通信协议的效率优化实践
1. 为什么需要优化ESP32与App Inventor的通信协议? 当你用ESP32和App Inventor做一个遥控小车时,最让人抓狂的就是按下按钮后小车要等半秒才有反应。这种延迟问题在HTTPJSON通信方案中非常典型。我去年做过一个智能家居控制系统,最初用的就是…...